[从源码学设计]蚂蚁金服SOFARegistry之时间轮的使用
文章目录
0x00 摘要
在我们的业务系统和日常开发之中,定期任务是一个常见的需求。即也有普通需求,也有特殊业务需求。本文和下文就以 SOFARegistry 为例,看看阿里是如何实现定期任务的。这里会结合业务来进行讲解。
在学习过程中,要随时考虑:设想如果你是设计者,你应该如何设计,采用什么样的算法和数据结构;如果你想拓展到分布式领域,你需要做哪些额外的考虑,如何修改;
本文是系列第八篇,借鉴了网上众多文章,请参见0xFF 参考。也分析了Netty同Kakfa之中的时间轮特点。
0x01 业务领域
我们将业务系统中需要使用定时任务调度总结成三种场景:
- 时间驱动处理场景:如整点发送优惠券,每天定时更新收益;
- 批量处理数据:如按月批量统计报表数据,批量更新某些数据状态,实时性要求不高;
- 异步执行解耦:如先反馈用户操作状态,后台异步执行较耗时的数据操作,以实现异步逻辑解耦;
1.1 应用场景
在网络中,会有大量使用定时任务的需求,比如Netty:
由于Netty动辄管理100w+的连接,每一个连接都会有很多超时任务。比如发送超时、心跳检测间隔等,如果每一个定时任务都启动一个Timer,不仅低效,而且会消耗大量的资源。
在Netty中的一个典型应用场景是判断某个连接是否idle,如果idle(如客户端由于网络原因导致到服务器的心跳无法送达),则服务器会主动断开连接,释放资源。得益于Netty NIO的优异性能,基于Netty开发的服务器可以维持大量的长连接,单台8核16G的云主机可以同时维持几十万长连接,及时掐掉不活跃的连接就显得尤其重要。
同理,在 SOFARegistry 之中,也有类似需求。
0x02 定时任务
2.1 什么是定时任务
定时器是什么?可以理解为这样一个数据结构:
存储一系列的任务集合,Deadline 越接近的任务,拥有越高的执行优先级。
在用户视角支持以下几种操作:
- NewTask:将新任务加入任务集合
- Cancel:取消某个任务
在任务调度的视角还要支持:
- Run:执行一个到底的定时任务
判断一个任务是否到期,基本采用轮询的方式,每隔一个时间片 去检查 最近的任务是否到期。说到底,定时器还是靠线程轮询实现的。
2.2 Java定时任务框架
本文集中在单机领域。
- timer:一个定时器类,通过该类可以为指定的定时任务进行配置。TimerTask类是一个定时任务类,该类实现了Runnable接口,缺点是异常未检查会中止线程;
- ScheduledExecutorService:相对延迟或者周期作为定时任务调度,缺点没有绝对的日期或者时间;
- DelayQueue :JDK中提供的一组实现延迟队列的API,位于Java.util.concurrent包下;DelayQueue是一个BlockingQueue(无界阻塞)队列;
- spring定时框架:配置简单功能较多,如果系统使用单机的话可以优先考虑spring定时器;
这些定时任务框架实现思想基本类似,都围绕三个要素:任务、任务的组织者(队列),执行者调度执行者。
Timer、ScheduledThreadPoolExecutor 完整的实现了这三个要素,DelayQueue只实现了任务组织者这个要素,需要与线程配合使用。其中任务组织者这个要素,它们都是通过优先队列来实现,因此插入和删除任务的时间复杂度都为O(logn),并且 Timer 、ScheduledThreadPool 的周期性任务是通过重置任务的下一次执行时间来完成的。
0x03 时间轮
3.1 缘由
大量的调度任务如果每一个都使用自己的调度器来管理任务的生命周期的话,浪费cpu的资源并且很低效。
我们可以将这些场景抽象用时间轮管理,时间轮就是和钟表很相似的存在!时间轮的实现类似钟表的运作方式,是一种高效来利用线程资源来进行批量化调度的一种调度模型,把大批量的调度任务全部都绑定到同一个的调度器上面,使用这一个调度器来进行所有任务的管理(manager),触发(trigger)以及运行(runnable)。能够高效的管理各种延时任务,周期任务,通知任务等等。
时间轮的任务插入和删除时间复杂度都为O(1),相对而言时间轮更适合任务数很大的延时场景。
3.2 定义
George Varghese 和 Tony Lauck 1996 年的论文:Hashed and Hierarchical Timing Wheels: data structures to efficiently implement a timer facility。提出了一种定时轮的方式来管理和维护大量的Timer调度。
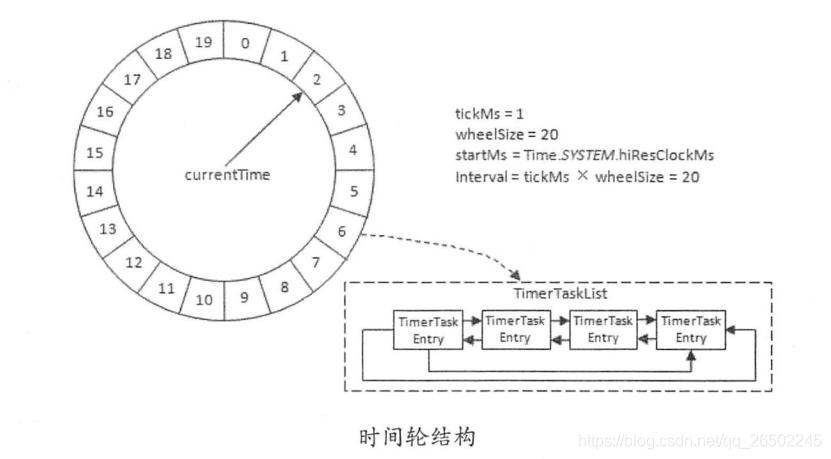
时间轮其实就是一种环形的数据结构,可以想象成时钟,分成很多bucket ,一个bucket 代表一段时间(这个时间越短,Timer的精度越高)。每一个 bucket 上可以存放多个任务,使用一个 List 保存该时刻到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应 bucket 上所有到期的任务。任务通过 取模决定应该放入哪个 bucket 。和 HashMap 的原理类似,newTask 对应 put,使用 List 来解决 Hash 冲突。
传统定时器是面向任务的,时间轮定时器是面向 bucket 的。
用到延迟任务时,比较直接的想法是DelayQueue、ScheduledThreadPoolExecutor 这些,而时间轮相比之下,最大的优势是在时间复杂度上,当任务较多时,TimingWheel的时间性能优势会更明显。
HashedWheelTimer本质是一种类似延迟任务队列的实现,那么它的特点就是上述所说的,适用于对时效性不高的,可快速执行的,大量这样的“小”任务,能够做到高性能,低消耗。例如:
- 心跳检测;
- 请求/事务/锁的超时处理;
缺点则是:
- 时间轮调度器的时间精度可能不是很高,对于精度要求特别高的调度任务可能不太适合。因为时间轮算法的精度取决于,时间段“指针”单元的最小粒度大小,比如时间轮的格子是一秒跳一次,那么调度精度小于一秒的任务就无法被时间轮所调度;
- 而且时间轮算法没有做宕机备份,因此无法再宕机之后恢复任务重新调度;
3.3 Netty时间轮HashedWheelTimer
我们进行netty.HashedWheelTimer 的解读。
HashedWheelTimer最初版本wheel是set数组+ConcurrentHashMap,然后逐步演变。
Netty构建延时队列主要用HashedWheelTimer,HashedWheelTimer底层数据结构依然是使用DelayedQueue,只是采用时间轮的算法来实现。
HashedWheelTimer提供的是一个定时任务的一个优化实现方案,在netty中主要用于异步IO的定时规划触发(A timer optimized for approximated I/O timeout scheduling)。
3.3.1 实现
通过代码查阅,发现时间轮整体逻辑简单清晰:等待时间 —> 处理取消的任务 —> 队列中的任务入槽 —> 处理执行的任务。
我们主要看下这三个问题:
- 等待时间是如何计算的,这个跟时间精度相关
- 队列中的任务如何入槽的(对应上面的疑问)
- 任务如何执行的
等待时间是如何计算的?worker.waitForNextTick 就是通过tickDuration和此时已经移动的tick算出下一次需要检查的时间,如果时间未到就sleep。
**队列中的任务如何入槽的?worker.transferTimeoutsToBuckets **就是设置了一次性处理10w个任务入槽,从队列中拿出任务,计算轮数,如果时间已经过了,放到当前即将执行的槽位中。
任务如何执行的?hashedWheelBucket.expireTimeouts 就是通过轮数和时间双重判断,执行任务。
小结:
Netty中时间轮算法是基于轮次的时间轮算法实现,通过启动一个工作线程,根据时间精度TickDuration,移动指针找到槽位,根据轮次+时间来判断是否是需要处理的任务。
不足之处:
- 时间轮的推进是根据时间精度TickDuration来固定推进的,如果槽位中无任务,也需要移动指针,会造成无效的时间轮推进,比如TickDuration为1秒,此时就一个延迟500秒的任务,那就是有499次无用的推进。
- 任务的执行都是同一个工作线程处理的,并且工作线程的除了处理执行到时的任务还做了其他操作,因此任务不一定会被精准的执行,而且任务的执行如果不是新起一个线程执行,那么耗时的任务会阻塞下个任务的执行。
优势:
- 时间精度可控;
- 并且增删任务的时间复杂度都是O(1);
下面是几个需要注意的点。
3.3.2 单线程与业务线程池
我们需要注意 HashedWheelTimer 使用的是单线程调度任务,如果任务比较耗时,应当设置一个业务线程池,将 HashedWheelTimer 当做一个定时触发器,任务的实际执行,交给业务线程池。
3.3.3 全局定时器
实际使用 HashedWheelTimer 时,应当将其当做一个全局的任务调度器,例如设计成 static 。时刻谨记一点: HashedWheelTimer 对应一个线程,如果每次实例化 HashedWheelTimer,首先是线程会很多,其次是时间轮算法将会完全失去意义。
3.3.4 队列
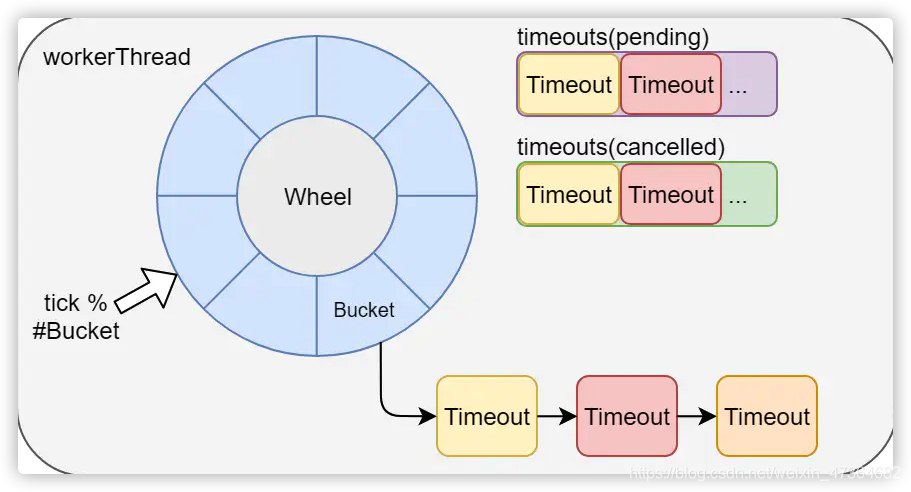
netty的HashedWheelTimer实现还有两个东西值得关注,分别是pending-timeouts队列和cancelled-timeouts队列。
这两个队列分别记录新添加的定时任务和要取消的定时任务,当workerThread每次循环运行时,它会先将pending-timeouts队列中一定数量的任务移动到它们对应的bucket,并取消掉cancelled-timeouts中所有的任务。由于添加和取消任务可以由任意线程发起,而相应的处理只会在workerThread里,所以为了进一步提高性能,这两个队列都是用了JCTools里面的MPSC(multiple-producer-single-consumer)队列。
3.4 Kafka和多层时间轮
kafka中存在着大量的延时操作,比如延迟生产,延迟拉取,延迟删除等,这些延时操作是基于时间轮的概念自己实现了一个延时定时器,JDK中Timer和DelayQueue的插入和删除操作的平均时间复杂度为O(nlogn)并不能满足Kafka的高性能要求,而基于时间轮可以将插入和删除操作的时间复杂度都降为 O(1)。
Kafka中时间轮算法是基于多层次的时间轮算法实现,并且是按需创建时间轮,采用任务的绝对时间来判断延期,空间换时间的思想,用DelayQueue存放每个槽,并以每个槽的过期时间排序,通过delayQueue.poll阻塞式进行时间轮的推进,杜绝了空推进的问题。
3.4.1 实现
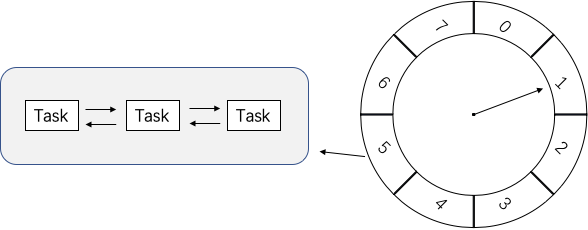
kafka中的时间轮是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList),TimerTaskList是一个环形的双向链表,链表中的每个元素TimerTaskEntry封装了一个真正的定时任务TimerTask。
时间轮由固定格数(wheelSize)的时间格组成,每一格都代表当前时间轮的基本时间跨度(tickMs),整个时间轮的总体时间跨度(interval)就是 wheelSize*tickMs。
时间轮还有一个表盘指针(currentTime),其值是tickMs的整数倍,用来表示时间轮当前所处的时间,表示当前需要处理的时间格对应的TimeTaskList 中的所有任务。
总之,整个时间轮的跨度是不会变的,随着currentTime的不断推进,当前时间轮所能处理的时间段也在不断后移,总体时间范围就是currentTime和currentTime + interval之间。
3.4.2 问题
时间轮环形数组的每个元素可以称为槽,槽的内部用双向链表存着待执行的任务,添加和删除的链表操作时间复杂度都是 O(1),槽位本身也指代时间精度,比如一秒扫一个槽,那么这个时间轮的最高精度就是 1 秒。也就是说延迟 1.2 秒的任务和 1.5 秒的任务会被加入到同一个槽中,然后在 1 秒的时候遍历这个槽中的链表执行任务。
那么,问题来了,如果一个新的定时任务远远超过了当前的总体时间范围,比如350ms,那怎么办呢?
那假设现在要加入一个50秒后执行的任务怎么办?这槽好像不够啊?难道要加槽嘛?和HashMap一样扩容?
对于延迟超过时间轮所能表示的范围有两种处理方式:
- 一是通过增加一个字段-轮数(Netty);
- 二是多层次时间轮(Kakfa);
Netty是通过增加轮次的概念:
先计算槽位:上面有八个槽。50 % 8 + 2 = 4,即应该放在槽位是 4,下标是 3 的位置。
然后计算轮次:(50 - 1) / 8 = 6,即轮数记为 6。也就是说当循环 6 轮之后扫到下标的 3 的这个槽位会触发这个任务。
Netty 中的 HashedWheelTimer 使用的就是这种方式。
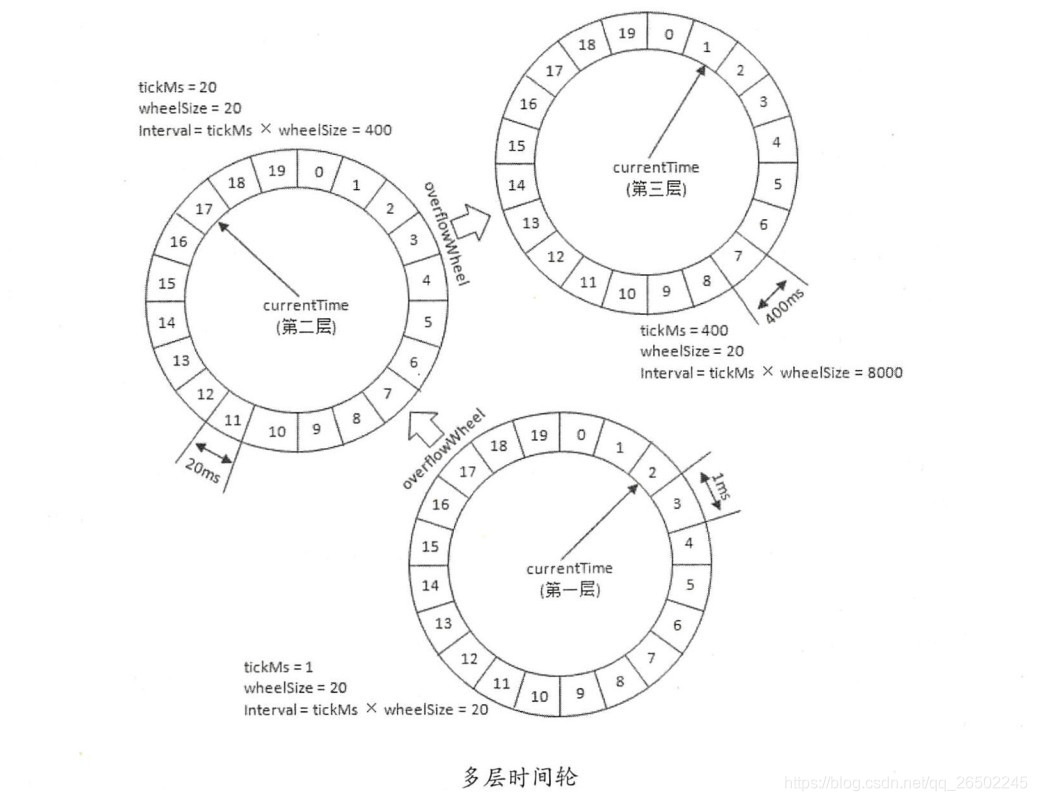
还有一种是通过多层次的时间轮:
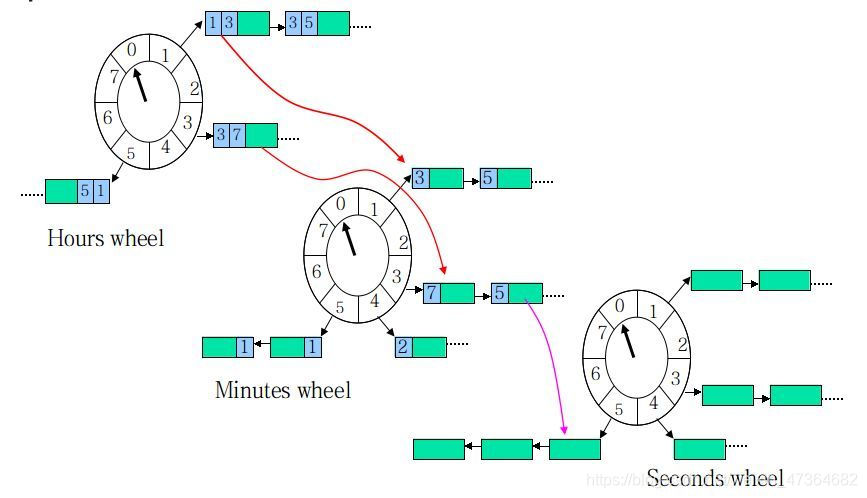
这个和我们的手表就更像了,像我们秒针走一圈,分针走一格,分针走一圈,时针走一格,多层次时间轮就是这样实现的。
假设上图就是第一层,那么第一层走了一圈,第二层就走一格,可以得知第二层的一格就是8秒,假设第二层也是 8 个槽,那么第二层走一圈,第三层走一格,可以得知第三层一格就是 64 秒。那么一个三层,每层8个槽,一共24个槽时间轮就可以处理最多延迟 512 秒的任务。
3.4.3 多层时间轮原理
如果任务的时间跨度很大,数量也多,传统的 HashedWheelTimer 会造成任务的 round 很大,单个 bucket 的任务 List 很长,并会维持很长一段时间。当时间跨度很大时,提升单层时间轮的 tickDuration 可以减少空转次数,但会导致时间精度变低。
层级时间轮既可以避免精度降低,又避免了指针空转的次数。如果有长时间跨度的定时任务,则可以交给层级时间轮去调度。为此,Kafka 针对时间轮算法进行了优化,实现了层级时间轮 TimingWheel,当任务到期时间远远超过当前时间轮所表示的时间范围时,就会尝试添加到上层时间轮中。
生活中我们常见的钟表就是一种具有三层结构的时间轮:
- 第一层时间轮 tickMs=1ms 、wheelSize=60 、interval=1min,此为秒钟;
- 第二层 tickMs= 1min、wheelSize=60 、interval= 1hour,此为分钟;
- 第三层 tickMs=1hour 、 wheelSize= 12 、 interval= 12hours,此为时钟;
所以,所有位于第二及第二层时间轮以上的任务在执行前都会有一个时间轮降级的过程,会从第n级,降到第n-1级,n-2级……直到降到第一级为止。
我们可以总结出,kafka的定时器只是持有第一层时间轮的引用,并不会直接持有其他高层时间轮的引用,但是每个时间轮都会有一个指向更高一层时间轮的引用,随着时间的推移,高层时间轮内的定时任务也会重新插入到时间轮内,直到插入到第一层时间轮内等待被最终的执行。
现在,每个任务除了要维护在当前轮盘的 round,还要计算在所有下级轮盘的 round。当本层的 round为0时,任务按下级 round 值被下放到下级轮子,最终在最底层的轮盘得到执行。
相比单层时间轮,层级时间轮在时间跨度较大时存在明显的优势。
3.4.4 降级
而多层次时间轮还会有降级的操作,假设一个任务延迟500秒执行,那么刚开始加进来肯定是放在第三层的,当时间过了 436 秒后,此时还需要 64 秒就会触发任务的执行,而此时相对而言它就是个延迟64秒后的任务,因此它会被降低放在第二层中,第一层还放不下它。再过个 56 秒,相对而言它就是个延迟8秒后执行的任务,因此它会再被降级放在第一层中,等待执行。
降级是为了保证时间精度一致性。
3.4.5 推进
在kafka时间轮中,最难懂的就是DelayQueue 与 时间轮的关系,文章开头说了DelayQueue不能满足kafka的高性能要求,那么这里怎么还要用到DelayQueue呢?
3.4.5.1 空推进
首先我们想想在Kafka中到底是怎么推进时间的呢?类似采用JDK中的scheduleAtFixedRate来每秒推进时间轮?显然这样并不合理,TimingWheel也失去了大部分意义。
一种直观的想法是,像现实中的钟表一样,“一格一格”地走,这样就需要有一个线程一直不停的执行,而大多数情况下,时间轮中的bucket大部分是空的,指针的“推进”就没有实质作用。
Netty中时间轮的推进主要就是通过固定的时间间隔扫描槽位,有可能槽位上没有任务,所以会有空推进的情况。
3.4.5.2 DelayQueue
相比Netty的实现会有空推进的问题,为了减少这种“空推进”,kafka的设计者就使用了DelayQueue+时间轮的方式,来保证kafka的高性能定时任务的执行,Delayqueue负责时间轮的推进工作,时间轮则负责将每个定时任务TimerTaskEntry按照时间顺序插入以及删除,然后又使用专门的一个线程来从DelayQueue中获取到期的任务列表,然后执行对应的操作,这样就利用空间换时间的思想解决了空推进的问题,保证了kafka的高性能运行。
即,Kafka用DelayQueue保存每个bucket,以bucket为单位入队,通过每个bucket的过期时间排序,这样拥有最早需要执行任务的槽会被优先获取。如果时候未到,那么delayQueue.poll就会阻塞着。
每当有bucket到期,即queue.poll能拿到结果时,才进行时间的“推进”,减少了 ExpiredOperationReaper 线程空转的开销。这样就不会有空推进的情况发生,同时呢,任务组织结构仍由时间轮组织,也兼顾了任务插入、删除操作的高性能。
Kafka中的定时器真可谓是“知人善用”,用TimingWheel做最擅长的任务添加和删除操作,而用DelayQueue做最擅长的时间推进工作,相辅相成。
3.4.5.3 SystemTimer–核心的调度逻辑
时间轮推进方法主要由工作线程SystemTimer调用。
kafka会启动一个线程去推动时间轮的转动,实现原理就是通过queue.poll()取出放在最前面的槽的TimerTaskList。
在时间轮添加任务时,所有有任务元素的TimerTaskList都会被添加到queue中。由于queue是一个延迟队列,如果队列中的expireTime没有到达,该操作会阻塞,等待expireTime时间到达。如果poll取到了TimerTaskList,说明该槽里面的任务时间到达,会先推进时间轮的转动变更为当前时间,同时将到期的槽的所有任务都取出来,并通过TimingWheel重新add一遍,此时因为任务到期,并不会真正add进去,而是调用线程池运行任务,具体可以看SystemTimer.reinsert和TimingWheel.add方法。
3.4.6 总述
kafka对于时间轮最核心的实现包含时间轮的数据结构、添加任务、时间溢出(添加上一级时间轮)、时间轮推进四个核心部分。大的逻辑是
添加任务 ---> 是否时间溢出? ---> 溢出时添加上一级时间轮,并调用上一级时间轮的添加任务方法 ---> 未溢出,直接添加到槽位 ---> 递归处理。
所以时间轮的数据结构、时间溢出都通过添加任务的逻辑串联了起来。
总结一下Kafka时间轮性能高的几个主要原因:
-
时间轮的结构+双向列表bucket,使得插入操作可以达到O(1)的时间复杂度
-
Bucket的设计让多个任务“合并”,使得同一个bucket的多次插入只需要在delayQueue中入队一次,同时减少了delayQueue中元素数量,堆的深度也减小,delayqueue的插入和弹出操作开销也更小
0x04 SOFARegistry普通定时任务
SOFARegistry 也有几种不同的定时任务需求,在这里既实现了普通定时任务,也实现了特殊定时任务,HashedWheelTimer 就是用在了特殊定时任务上。
首先我们要介绍SOFARegistry之中普通定时任务的使用。普通定时任务的使用基本就是ScheduledExecutorService类似,现在以tasks bean为例。
4.1 ScheduledExecutorService
相比 Timer, ScheduledExecutorService 解决了同一个定时器调度多个任务的阻塞问题,并且并且Java线程池的底层runworker实现了异常的捕获,所以任务的异常不会中断 ScheduledExecutorService。
ScheduledExecutorService 提供了两种常用的周期调度方法 ScheduleAtFixedRate 和 ScheduleWithFixedDelay。ScheduleAtFixedRate 是基于固定时间间隔进行任务调度,ScheduleWithFixedDelay 取决于每次任务执行的时间长短,是基于不固定时间间隔的任务调度。
ScheduledExecutorService 底层使用的数据结构为 PriorityQueue。
在 Java 中, PriorityQueue 是一个天然的堆,可以利用传入的 Comparator 来决定其中元素的优先级。
NewTask:O(logN)
Cancel:O(logN)
Run:O(1)
N:任务数
堆与双向有序链表相比,NewTask 和 Cancel 形成了 trade off,但考虑到现实中,定时任务取消的场景并不是很多,所以堆实现的定时器要比双向有序链表优秀。
4.2 ThreadPoolExecutor
在StartTaskEventHandler之中,其针对 tasks Bean 里面声明的task,进行启动。
public class StartTaskEventHandler extends AbstractEventHandler<StartTaskEvent> {
@Resource(name = "tasks")
private List<AbstractTask> tasks;
private ScheduledExecutorService executor = null;
@Override
public List<Class<? extends StartTaskEvent>> interest() {
return Lists.newArrayList(StartTaskEvent.class);
}
@Override
public void doHandle(StartTaskEvent event) {
if (executor == null || executor.isShutdown()) {
getExecutor();
}
for (AbstractTask task : tasks) {
if (event.getSuitableTypes().contains(task.getStartTaskTypeEnum())) {
executor.scheduleWithFixedDelay(task, task.getInitialDelay(), task.getDelay(),task.getTimeUnit());
}
}
}
private void getExecutor() {
executor = ExecutorFactory.newScheduledThreadPool(tasks.size(), this.getClass()
.getSimpleName());
}
}
可以看出来,都是使用 ExecutorFactory.newScheduledThreadPool 来启动线程进行处理。
对应的Bean如下:
@Bean
public ConnectionRefreshTask connectionRefreshTask() {
return new ConnectionRefreshTask();
}
@Bean
public ConnectionRefreshMetaTask connectionRefreshMetaTask() {
return new ConnectionRefreshMetaTask();
}
@Bean
public RenewNodeTask renewNodeTask() {
return new RenewNodeTask();
}
@Bean(name = "tasks")
public List<AbstractTask> tasks() {
List<AbstractTask> list = new ArrayList<>();
list.add(connectionRefreshTask());
list.add(connectionRefreshMetaTask());
list.add(renewNodeTask());
return list;
}
ConnectionRefreshTask,ConnectionRefreshMetaTask,RenewNodeTask 这三个Task的循环间隔分别是 30 秒,10 秒,3 秒。
4.3 Scheduled
在Session Server中有使用spring @Scheduled注解执行定时任务。
SpringBoot自带的Scheduled,可以将它看成一个轻量级的Quartz,而且使用起来比Quartz简单许多。
public class SyncClientsHeartbeatTask {
@Scheduled(initialDelayString = "${session.server.syncHeartbeat.fixedDelay}", fixedDelayString = "${session.server.syncHeartbeat.fixedDelay}")
public void syncCounte() {
long countSub = sessionInterests.count();
long countPub = sessionDataStore.count();
long countSubW = sessionWatchers.count();
int channelCount = 0;
Server sessionServer = boltExchange.getServer(sessionServerConfig.getServerPort());
if (sessionServer != null) {
channelCount = sessionServer.getChannelCount();
}
}
}
具体参数是在配置文件中。
session.server.syncHeartbeat.fixedDelay=30000
session.server.syncExceptionData.fixedDelay=30000
session.server.printTask.fixedDelay=30000
0x05 SOFT bolt的使用
5.1 SOFABolt网络模式
SOFABolt有四种网络模式:它们实现了多种通信接口 oneway,sync,future,callback。
- oneway 不关心响应,请求线程不会被阻塞,但使用时需要注意控制调用节奏,防止压垮接收方;
- sync 调用会阻塞请求线程,待响应返回后才能进行下一个请求。这是最常用的一种通信模型;
- future 调用,在调用过程不会阻塞线程,但获取结果的过程会阻塞线程;
- callback 是真正的异步调用,永远不会阻塞线程,结果处理是在异步线程里执行。
除了 oneway模式,其他三种通信模型都需要进行超时控制,SOFABolt 同样采用 Netty 里针对超时机制,所设计的高效方案 HashedWheelTimer。
其原理是首先在发起调用前,SOFABolt 会新增一个超时任务 timeoutTask到 MpscQueue(Netty 实现的一种高效的无锁队列)里,然后在循环里,会不断的遍历 Queue 里的这些超时任务(每次最多10万),针对每个任务,会根据其设置的超时时间,来计算该任务所属于的 bucket位置与剩余轮数 remainingRounds,然后加入到对应 bucket的链表结构里。随着 tick++的进行,时间在不断的增长,每 tick8 次,就是 1 个时间轮 round。当对应超时任务的remainingRounds减到 0时,就是触发这个超时任务的时候,此时再执行其 run()方法,做超时逻辑处理。
- 最佳实践:通常一个进程使用一个 HashedWheelTimer 实例,采用单例模型即可。
0x06 特殊定时任务
这里的特殊定时任务 ,指的是使用了 AsyncHashedWheelTimer 的定时任务。
AsyncHashedWheelTimer 继承了 HashedWheelTimer,加入了异步执行。
6.1 AsyncHashedWheelTimer
Netty HashedWheelTimer 内部也同样是使用了单个线程来进行任务调度。他跟 JDK 的 Timer 一样,存在”前一个任务执行时间过长,影响后续定时任务执行的问题“。
以下是 Netty HashedWheelTimer 示意图:
+--------+
| |
| 8-4 |
+------+ +--------+
| | | |
| 0-3 | | 8-3 |
+------+ +-------+ +--------+
| | | | | |
| 0-2 | | 3-2 | | 8-2 |
+------+ +-------+ +--------+
| | | | | |
| 0-1 | | 3-1 | | 8-1 |
+---+--+ +---+---+ +--------+
^ ^ ^
TimeWheel | | |
+-+-+---+----+-+-+---+---+---+---+-+-+---+
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
++--+---+----+---+---+---+---+---+---+---+
^
|
|
+
指 针
AsyncHashedWheelTimer 就是为了克服 Netty HashedWheelTimer 的问题。针对每个任务,加入了异步执行的线程,这就避免了时间过长任务带来的影响。以下是 AsyncHashedWheelTimer 示意图:
+--------+ +----+
| +---->+Task|
| 8-4 | +----+
+----+ +------+ +--------+ +----+
|Task| <---+ | | +---->+Task|
+----+ | 0-3 | | 8-3 | +----+
+----+ +------+ +-------+ +----+ +--------+ +----+
|Task| <---+ | | +-->+Task| | +---->+Task|
+----+ | 0-2 | | 3-2 | +----+ | 8-2 | +----+
+----+ +------+ +-------+ +----+ +--------+ +----+
|Task| <---+ | | +-->+Task| | +---->+Task|
+----+ | 0-1 | | 3-1 | +----+ | 8-1 | +----+
+---+--+ +---+---+ +--------+
^ ^ ^
TimeWheel | | |
+-+-+---+----+-+-+---+---+---+---+-+-+---+
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
++--+---+----+---+---+---+---+---+---+---+
^
|
|
+
指 针
具体代码如下:
public class AsyncHashedWheelTimer extends HashedWheelTimer {
protected final Executor executor;
protected final TaskFailedCallback taskFailedCallback;
public AsyncHashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit,
int ticksPerWheel, int threadSize, int queueSize,
ThreadFactory asyncThreadFactory,
TaskFailedCallback taskFailedCallback) {
super(threadFactory, tickDuration, unit, ticksPerWheel);
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(threadSize, threadSize,300L, TimeUnit.SECONDS, new LinkedBlockingQueue<>(queueSize), asyncThreadFactory);
threadPoolExecutor.allowCoreThreadTimeOut(true);
this.executor = threadPoolExecutor;
this.taskFailedCallback = taskFailedCallback;
}
public AsyncHashedWheelTimer(ThreadFactory threadFactory, long tickDuration, TimeUnit unit,
int ticksPerWheel, Executor asyncExecutor,
TaskFailedCallback taskFailedCallback) {
super(threadFactory, tickDuration, unit, ticksPerWheel);
this.executor = asyncExecutor;
this.taskFailedCallback = taskFailedCallback;
}
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
return super.newTimeout(new AsyncTimerTask(task), delay, unit);
}
class AsyncTimerTask implements TimerTask, Runnable {
TimerTask timerTask;
Timeout timeout;
public AsyncTimerTask(TimerTask timerTask) {
super();
this.timerTask = timerTask;
}
@Override
public void run(Timeout timeout) {
this.timeout = timeout;
try {
AsyncHashedWheelTimer.this.executor.execute(this);
} catch (RejectedExecutionException e) {
taskFailedCallback.executionRejected(e);
} catch (Throwable e) {
taskFailedCallback.executionFailed(e);
}
}
@Override
public void run() {
try {
this.timerTask.run(this.timeout);
} catch (Throwable e) {
taskFailedCallback.executionFailed(e);
}
}
}
public interface TaskFailedCallback {
void executionRejected(Throwable e);
void executionFailed(Throwable e);
}
}
6.2 DatumLeaseManager
这里业务实现比较复杂。会结合下文 AsyncHashedWheelTimer 一起论述。
afterWorkingProcess比较简单,也是提交一个在若干时间之后执行的线程。
public class DatumLeaseManager implements AfterWorkingProcess {
private ScheduledThreadPoolExecutor executorForHeartbeatLess;
private AsyncHashedWheelTimer datumAsyncHashedWheelTimer;
@Override
public void afterWorkingProcess() {
executorForHeartbeatLess.schedule(() -> {
serverWorking = true;
}, dataServerConfig.getRenewEnableDelaySec(), TimeUnit.SECONDS);
}
}
6.2.1 时间轮
具体时间轮建立如下,这里是建立了一个100毫秒的时间轮。
datumAsyncHashedWheelTimer = new AsyncHashedWheelTimer(threadFactoryBuilder.setNameFormat(
"Registry-DatumLeaseManager-WheelTimer").build(), 100, TimeUnit.MILLISECONDS, 1024,
dataServerConfig.getDatumLeaseManagerExecutorThreadSize(),
dataServerConfig.getDatumLeaseManagerExecutorQueueSize(), threadFactoryBuilder
.setNameFormat("Registry-DatumLeaseManager-WheelExecutor-%d").build(),
new TaskFailedCallback() {
@Override
public void executionRejected(Throwable e) {
}
@Override
public void executionFailed(Throwable e) {
}
});
这里主要是用来续约renew
6.2.2 续约操作
续约是对外提供了renew的API,在 PublishDataHandler之中调用。
如果可以续约,则调用datumLeaseManager.renew(connectId)。
@Override
public Object doHandle(Channel channel, PublishDataRequest request) {
Publisher publisher = Publisher.internPublisher(request.getPublisher());
if (forwardService.needForward()) {
CommonResponse response = new CommonResponse();
response.setSuccess(false);
response.setMessage("Request refused, Server status is not working");
return response;
}
dataChangeEventCenter.onChange(publisher, dataServerConfig.getLocalDataCenter());
if (publisher.getPublishType() != PublishType.TEMPORARY) {
String connectId = WordCache.getInstance().getWordCache(
publisher.getSourceAddress().getAddressString());
sessionServerConnectionFactory.registerConnectId(request.getSessionServerProcessId(),
connectId);
// record the renew timestamp
datumLeaseManager.renew(connectId);
}
return CommonResponse.buildSuccessResponse();
}
记录最新的时间戳,然后启动scheduleEvictTask。
public void renew(String connectId) {
// record the renew timestamp
connectIdRenewTimestampMap.put(connectId, System.currentTimeMillis());
// try to trigger evict task
scheduleEvictTask(connectId, 0);
}
6.2.3 续约实现
续约的内部实现是基于AsyncHashedWheelTimer。
- 如果当前ConnectionId已经被锁定,说明有线程在做同样操作,则返回;
- 否则启动时间轮,加入一个定时操作,如果时间到,则:
- 释放当前ConnectionId对应的lock;
- 获取当前ConnectionId对应的上次续约时间,如果不存在,说明当前ConnectionId已经被移除,则返回;
- 如果当前状态是不可续约状态,则设置下次定时操作时间,因为If in a non-working state, cannot clean up because the renew request cannot be received at this time;
- 如果上次续约时间已经到期,则使用evict进行驱逐
- 如果没到期,则会调用 scheduleEvictTask(connectId, nextDelaySec); 设置下次操作
具体代码如下:
/**
* trigger evict task: if connectId expired, create ClientDisconnectEvent to cleanup datums bind to the connectId
* PS: every connectId allows only one task to be created
*/
private void scheduleEvictTask(String connectId, long delaySec) {
delaySec = (delaySec <= 0) ? dataServerConfig.getDatumTimeToLiveSec() : delaySec;
// lock for connectId: every connectId allows only one task to be created
Boolean ifAbsent = locksForConnectId.putIfAbsent(connectId, true);
if (ifAbsent != null) {
return;
}
datumAsyncHashedWheelTimer.newTimeout(_timeout -> {
boolean continued = true;
long nextDelaySec = 0;
try {
// release lock
locksForConnectId.remove(connectId);
// get lastRenewTime of this connectId
Long lastRenewTime = connectIdRenewTimestampMap.get(connectId);
if (lastRenewTime == null) {
// connectId is already clientOff
return;
}
/*
* 1. lastRenewTime expires, then:
* - build ClientOffEvent and hand it to DataChangeEventCenter.
* - It will not be scheduled next time, so terminated.
* 2. lastRenewTime not expires, then:
* - trigger the next schedule
*/
boolean isExpired =
System.currentTimeMillis() - lastRenewTime > dataServerConfig.getDatumTimeToLiveSec() * 1000L;
if (!isRenewEnable()) {
nextDelaySec = dataServerConfig.getDatumTimeToLiveSec();
} else if (isExpired) {
int ownPubSize = getOwnPubSize(connectId);
if (ownPubSize > 0) {
evict(connectId);
}
connectIdRenewTimestampMap.remove(connectId, lastRenewTime);
continued = false;
} else {
nextDelaySec = dataServerConfig.getDatumTimeToLiveSec()
- (System.currentTimeMillis() - lastRenewTime) / 1000L;
nextDelaySec = nextDelaySec <= 0 ? 1 : nextDelaySec;
}
}
if (continued) {
scheduleEvictTask(connectId, nextDelaySec);
}
}, delaySec, TimeUnit.SECONDS);
}
具体如下图所示
+------------------+ +-------------------------------------------+
|PublishDataHandler| | DatumLeaseManager |
+--------+---------+ | |
| | newTimeout |
| | +----------------------> |
doHandle | ^ + |
| | | | |
| renew | +-----------+--------------+ | |
| +--------------> | | AsyncHashedWheelTimer | | |
| | +-----+-----+--------------+ | |
| | | ^ | |
| | | | scheduleEvictTask | |
| | evict | + v |
| | | <----------------------+ |
| +-------------------------------------------+
| |
| |
| |
| |
v v
或者如下图所示:
+------------------+ +-------------------+ +------------------------+
|PublishDataHandler| | DatumLeaseManager | | AsyncHashedWheelTimer |
+--------+---------+ +--------+----------+ +-----------+------------+
| | new |
doHandle +------------------------> |
| renew | |
+-------------------> | |
| | |
| | |
| scheduleEvictTask |
| | |
| | newTimeout |
| +----------> +------------------------> |
| | | |
| | | |
| | | |
| | | No +
| | | <---------------+ if (ownPubSize > 0)
| | | +
| | v |
| +--+ scheduleEvictTask | Yes
| + v
| | evict
| | |
v v v
6.3 SessionServerNotifier
当有数据发布者 publisher 上下线时,会分别触发 publishDataProcessor 或 unPublishDataHandler ,Handler 会往 dataChangeEventCenter 中添加一个数据变更事件,用于异步地通知事件变更中心数据的变更。事件变更中心收到该事件之后,会往队列中加入事件。此时 dataChangeEventCenter 会根据不同的事件类型异步地对上下线数据进行相应的处理。
与此同时,DataChangeHandler 会把这个事件变更信息通过 ChangeNotifier 对外发布,通知其他节点进行数据同步。
notify函数会遍历dataChangeNotifiers,找出可以支持本Datum对应SourceType的Notifier来执行。
具体如何支持哪些函数,是由getSuitableSource设置的。
private void notify(Datum datum, DataSourceTypeEnum sourceType, Long lastVersion) {
for (IDataChangeNotifier notifier : dataChangeNotifiers) {
if (notifier.getSuitableSource().contains(sourceType)) {
notifier.notify(datum, lastVersion);
}
}
}
SessionServerNotifier定义如下。
public class SessionServerNotifier implements IDataChangeNotifier {
private AsyncHashedWheelTimer asyncHashedWheelTimer;
@Autowired
private DataServerConfig dataServerConfig;
@Autowired
private Exchange boltExchange;
@Autowired
private SessionServerConnectionFactory sessionServerConnectionFactory;
@Autowired
private DatumCache datumCache;
}
6.3.1 时间轮
建立了一个500毫秒的时间轮。
@PostConstruct
public void init() {
ThreadFactoryBuilder threadFactoryBuilder = new ThreadFactoryBuilder();
threadFactoryBuilder.setDaemon(true);
asyncHashedWheelTimer = new AsyncHashedWheelTimer(threadFactoryBuilder.setNameFormat(
"Registry-SessionServerNotifier-WheelTimer").build(), 500, TimeUnit.MILLISECONDS, 1024,
dataServerConfig.getSessionServerNotifierRetryExecutorThreadSize(),
dataServerConfig.getSessionServerNotifierRetryExecutorQueueSize(), threadFactoryBuilder
.setNameFormat("Registry-SessionServerNotifier-WheelExecutor-%d").build(),
new TaskFailedCallback() {
@Override
public void executionRejected(Throwable e) {
}
@Override
public void executionFailed(Throwable e) {
}
});
}
从业务角度看,当有publisher相关消息来临时候,
DataChangeHandler的notify函数会遍历dataChangeNotifiers,找出可以支持本Datum对应SourceType的Notifier来执行。
private void notify(Datum datum, DataSourceTypeEnum sourceType, Long lastVersion) {
for (IDataChangeNotifier notifier : dataChangeNotifiers) {
if (notifier.getSuitableSource().contains(sourceType)) {
notifier.notify(datum, lastVersion);
}
}
}
到了SessionServerNotifier这里的notify函数,会遍历目前缓存的所有Connection,逐一通知。
@Override
public void notify(Datum datum, Long lastVersion) {
DataChangeRequest request = new DataChangeRequest(datum.getDataInfoId(),
datum.getDataCenter(), datum.getVersion());
List<Connection> connections = sessionServerConnectionFactory.getSessionConnections();
for (Connection connection : connections) {
doNotify(new NotifyCallback(connection, request));
}
}
具体通知函数:
private void doNotify(NotifyCallback notifyCallback) {
Connection connection = notifyCallback.connection;
DataChangeRequest request = notifyCallback.request;
try {
//check connection active
if (!connection.isFine()) {
return;
}
Server sessionServer = boltExchange.getServer(dataServerConfig.getPort());
sessionServer.sendCallback(sessionServer.getChannel(connection.getRemoteAddress()),
request, notifyCallback, dataServerConfig.getRpcTimeout());
} catch (Exception e) {
onFailed(notifyCallback);
}
}
而时间轮是在调用失败的重试中使用。
就是当没有达到失败重试最大次数时,进行定时重试。
private void onFailed(NotifyCallback notifyCallback) {
DataChangeRequest request = notifyCallback.request;
Connection connection = notifyCallback.connection;
notifyCallback.retryTimes++;
//check version, if it's fall behind, stop retry
long _currentVersion = datumCache.get(request.getDataCenter(), request.getDataInfoId()).getVersion();
if (request.getVersion() != _currentVersion) {
return;
}
if (notifyCallback.retryTimes <= dataServerConfig.getNotifySessionRetryTimes()) {
this.asyncHashedWheelTimer.newTimeout(timeout -> {
//check version, if it's fall behind, stop retry
long currentVersion = datumCache.get(request.getDataCenter(), request.getDataInfoId()).getVersion();
if (request.getVersion() == currentVersion) {
doNotify(notifyCallback);
}
}, getDelayTimeForRetry(notifyCallback.retryTimes), TimeUnit.MILLISECONDS);
}
}
如下图所示:
+-----------------+ +---------------------+ +-------------+ +---------------------+
|DataChangeHandler| |SessionServerNotifier| |sessionServer| |AsyncHashedWheelTimer|
+--+--------------+ +-------+-------------+ +----+--------+ +---------+-----------+
| | | |
| doNotify | | |
| +--------------------> | | |
| | sendCallback | |
| +------------------> | |
| | | |
| | | |
| | | |
| | onFailed | |
| | <----------------+ | |
| | | |
| | | newTimeout |
| +---------------------------------------> |
| | | |
| | | |timeout
| | | doNotify |
| | <-------------------------------------+ |
| | | |
| | | |
| | sendCallback | |
| | +----------------> | |
| | | |
v v ...... v v
0x07 总结
通过本文讲解,我们基本理解了时间轮的原理,以及SOFARegistry中的应用,大家在具体工作中,可以参考其实现思路。
Timer、DelayQueue 和 ScheduledThreadPool,它们都是基于优先队列实现的,O(logn) 的时间复杂度在任务数多的情况下频繁的插入、删除操作有性能问题,因此适合于任务数不多的情况。
- Timer是单线程的会有任务阻塞的风险,并且对异常没有做处理,一个任务出错Timer就挂了。
- ScheduledThreadPool相比于Timer引入了线程池,并且线程池对异常做了处理,使得任务之间不会有影响。
- Timer和ScheduledThreadPool可以周期性执行任务,DelayQueue就是个具有优先级的阻塞队列,需要配合外部的工作线程使用。
毋庸置疑,JDK 的 Timer 使用的场景是最窄的,完全可以被后两者取代。
如何在 ScheduledExecutorService 和 HashedWheelTimer 之间如何做选择,还是要区分场景来看待。
ScheduledExecutorService是面向任务的,当任务数非常大时,使用堆(PriorityQueue)维护任务的新增、删除会造成性能的下降,而HashedWheelTimer是面向 bucket 的,设置合理的 ticksPerWheel,tickDuration ,可以不受任务量的限制。所以在任务量非常大时,HashedWheelTimer可以表现出它的优势。- 相反,如果任务量少,
HashedWheelTimer内部的 Worker 线程依旧会不停的拨动指针,虽然不是特别消耗性能,但至少不能说:HashedWheelTimer一定比ScheduledExecutorService优秀。 HashedWheelTimer由于开辟了一个 bucket 数组,占用的内存也会稍大。
所以我们得到了一个最佳实践:在任务量非常大时,使用 HashedWheelTimer 可以获得性能的提升。例如服务治理框架中的心跳定时任务,当服务实例非常多时,每一个客户端都需要定时发送心跳,每一个服务端都需要定时检测连接状态,这是一个非常适合使用 HashedWheelTimer 的场景。
0xFF 参考
时间轮算法解析(Netty HashedWheelTimer源码解读)
netty源码解读之时间轮算法实现-HashedWheelTimer
Netty工具类HashedWheelTimer源码走读(一)
Netty 工具类 —— HashedWheelTimer 讲解
技术干货 | 浅析基于时间轮算法实现海量数据场景下的定时消息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考
如果您想及时得到个人撰写文章的消息推送,或者想看看个人推荐的技术资料,可以扫描下面二维码(或者长按识别二维码)关注个人公众号)。
