目录
ByteTrack: Multi-Object Tracking by Associating Every Detection Box
论文链接:ByteTrack: Multi-Object Tracking by Associating Every Detection Box(ECCV2022)
摘要
(1)检测分数较低的目标,例如被遮挡的目标,会被简单丢弃。本文提出一种简单、有效且通用的关联方法,通过几乎关联每个检测框而不是仅关联高分检测框来进行跟踪。
(2)对于低分检测框,利用它们与轨迹的相似度来恢复真值目标,并过滤掉背景检测。
INTRODUCTION — 简介

存在问题(如上图):
在帧t1中,初始化了三个不同的轨迹,因为它们的分数都高于0.5。然而,在帧t2和帧t3中发生遮挡时,红色轨迹(对应b)的对应检测分数变低,即0.8到0.4,再从0.4到0.1。这些检测框被阈值机制消除,红色轨迹相应的消失了,就会发生漏检。
假如考虑了每个检测框,将立即引入更多的误检,例如,(a)帧t3中最右侧的框,这个框内并没有人,如果考虑每个框则会出现误检。
解决方法:
本文发现轨迹相似度提供了一个强有力的线索,来区分低分数检测框中的目标和背景。如图中©所示,两个低分检测框通过运动模型的预测框与轨迹相匹配,匹配成功的恢复目标;没有匹配上运动轨迹的背景框将被删除。
具体细节:
- BYTE方法中,将每个检测框都视为轨迹的基本单元,就像计算机程序的byte;跟踪方法为每个细节检测框赋值。
- 首先基于运动相似度或外观相似度将高分检测框与轨迹匹配,本文采用卡尔曼滤波器来预测新帧中的轨迹位置,相似度可以由预测框和检测框的IoU或Re-ID特征距离来计算,图中(b)是第一次匹配后的结果。
- 然后使用相同的运动相似度在未匹配的轨迹(即红色框中的轨迹)和低分检测框之间执行第二次匹配,图中©显示了第二次匹配后的结果。
- 低检测分值的被遮挡的行人与先前的轨迹正确匹配,并且背景(在图像的右侧部分)被移除。
BYTE算法
如下为BYTE算法的伪代码:

BYTE伪代码解析如下:
- 通过检测器获取检测框和对应的检测分数,对检测框进行分类,如果分数高于T_high,将检测框分类为高置信度组,分数低于T_high,高于T_low时,将检测框分类为低置信度组。
- 匹配过程使用到了检测框和卡尔曼滤波估计结果之间的相似度,这里可以采用IoU或Re-ID特征间距离来作为相似度度量。然后基于相似度采用匈牙利算法进行匹配,并保留那些未匹配到轨迹的高置信度检测框以及未匹配到检测框的轨迹。这部分对应伪代码中的17到19行(第一次关联)。
- 关联那些第一次关联剩下的轨迹以及低置信度检测框。之后保留那些第二次匹配过后仍然未匹配到边界框的轨迹,并删除那些低置信度边界框中在第二次匹配过后未找到对应轨迹的边界框,因为这些边界框被认定为是不包含任何物体的背景。对应伪代码中的第20到21行(第二次关联)。
- 将那些未匹配到对应轨迹的高置信度边界框作为新出现的轨迹进行保存,对应伪代码的23到27行。对两次匹配都没有匹配到的检测框,将它们初始化成新的轨迹。
注意:在第二次关联中仅使用IoU作为相似度非常重要。
原因:因为低分检测框通常包含严重的遮挡或运动模糊,外观特征不可靠。因此,当将BYTE应用于其他基于Re-ID的跟踪器时,不在第二次关联中采用外观相似度。
BYTE算法用Python代码实现
可能需要安装的依赖如: cython , lap , cython_bbox等。
如果 numpy 版本大于1.23可能需要修改 cython_bbox的源码,把代码里的 np.float 改成 np.float64。cython_bbox主要用于检测框的交叉 iou 的计算。
代码如下:
import numpy as np
from collections import deque
import os
import os.path as osp
import copy
from kalman_filter import KalmanFilter
import matching
from basetrack import BaseTrack, TrackState
class STrack(BaseTrack):
shared_kalman = KalmanFilter()
def __init__(self, tlwh, score):
# wait activate
self._tlwh = np.asarray(tlwh, dtype=np.float64)
self.kalman_filter = None
self.mean, self.covariance = None, None
self.is_activated = False
self.score = score
self.tracklet_len = 0
def predict(self):
mean_state = self.mean.copy()
if self.state != TrackState.Tracked:
mean_state[7] = 0
self.mean, self.covariance = self.kalman_filter.predict(mean_state, self.covariance)
@staticmethod
def multi_predict(stracks):
if len(stracks) > 0:
multi_mean = np.asarray([st.mean.copy() for st in stracks])
multi_covariance = np.asarray([st.covariance for st in stracks])
for i, st in enumerate(stracks):
if st.state != TrackState.Tracked:
multi_mean[i][7] = 0
multi_mean, multi_covariance = STrack.shared_kalman.multi_predict(multi_mean, multi_covariance)
for i, (mean, cov) in enumerate(zip(multi_mean, multi_covariance)):
stracks[i].mean = mean
stracks[i].covariance = cov
def activate(self, kalman_filter, frame_id):
"""Start a new tracklet"""
self.kalman_filter = kalman_filter
self.track_id = self.next_id()
self.mean, self.covariance = self.kalman_filter.initiate(self.tlwh_to_xyah(self._tlwh))
self.tracklet_len = 0
self.state = TrackState.Tracked
if frame_id == 1:
self.is_activated = True
# self.is_activated = True
self.frame_id = frame_id
self.start_frame = frame_id
def re_activate(self, new_track, frame_id, new_id=False):
self.mean, self.covariance = self.kalman_filter.update(
self.mean, self.covariance, self.tlwh_to_xyah(new_track.tlwh)
)
self.tracklet_len = 0
self.state = TrackState.Tracked
self.is_activated = True
self.frame_id = frame_id
if new_id:
self.track_id = self.next_id()
self.score = new_track.score
def update(self, new_track, frame_id):
"""
Update a matched track
:type new_track: STrack
:type frame_id: int
:type update_feature: bool
:return:
"""
self.frame_id = frame_id
self.tracklet_len += 1
new_tlwh = new_track.tlwh
self.mean, self.covariance = self.kalman_filter.update(
self.mean, self.covariance, self.tlwh_to_xyah(new_tlwh))
self.state = TrackState.Tracked
self.is_activated = True
self.score = new_track.score
@property
# @jit(nopython=True)
def tlwh(self):
"""Get current position in bounding box format `(top left x, top left y,
width, height)`.
"""
if self.mean is None:
return self._tlwh.copy()
ret = self.mean[:4].copy()
ret[2] *= ret[3]
ret[:2] -= ret[2:] / 2
return ret
@property
# @jit(nopython=True)
def tlbr(self):
"""Convert bounding box to format `(min x, min y, max x, max y)`, i.e.,
`(top left, bottom right)`.
"""
ret = self.tlwh.copy()
ret[2:] += ret[:2]
return ret
@staticmethod
# @jit(nopython=True)
def tlwh_to_xyah(tlwh):
"""Convert bounding box to format `(center x, center y, aspect ratio,
height)`, where the aspect ratio is `width / height`.
"""
ret = np.asarray(tlwh).copy()
ret[:2] += ret[2:] / 2
ret[2] /= ret[3]
return ret
def to_xyah(self):
return self.tlwh_to_xyah(self.tlwh)
@staticmethod
# @jit(nopython=True)
def tlbr_to_tlwh(tlbr):
ret = np.asarray(tlbr).copy()
ret[2:] -= ret[:2]
return ret
@staticmethod
# @jit(nopython=True)
def tlwh_to_tlbr(tlwh):
ret = np.asarray(tlwh).copy()
ret[2:] += ret[:2]
return ret
def __repr__(self):
return 'OT_{}_({}-{})'.format(self.track_id, self.start_frame, self.end_frame)
class BYTETracker(object):
def __init__(self, frame_rate=20):
self.tracked_stracks = [] # type: list[STrack]
self.lost_stracks = [] # type: list[STrack]
self.removed_stracks = [] # type: list[STrack]
self.frame_id = 0
self.det_thresh = 0.5 + 0.1
self.buffer_size = int(frame_rate / 30.0 * 25)
self.max_time_lost = self.buffer_size
self.kalman_filter = KalmanFilter()
def update(self, output_results):
self.frame_id += 1
activated_starcks = []
refind_stracks = []
lost_stracks = []
removed_stracks = []
if output_results.shape[1] == 5:
scores = output_results[:, 4]
bboxes = output_results[:, :4]
else:
output_results = output_results.cpu().numpy()
scores = output_results[:, 4] * output_results[:, 5]
bboxes = output_results[:, :4] # x1y1x2y2
remain_inds = scores > 0.5
inds_low = scores > 0.1
inds_high = scores < 0.5
inds_second = np.logical_and(inds_low, inds_high)
dets_second = bboxes[inds_second]
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
scores_second = scores[inds_second]
if len(dets) > 0:
'''Detections'''
detections = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets, scores_keep)]
else:
detections = []
''' Add newly detected tracklets to tracked_stracks'''
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_stracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
''' Step 2: First association, with high score detection boxes'''
strack_pool = joint_stracks(tracked_stracks, self.lost_stracks)
# Predict the current location with KF
STrack.multi_predict(strack_pool)
dists = matching.iou_distance(strack_pool, detections)
dists = matching.fuse_score(dists, detections)
matches, u_track, u_detection = matching.linear_assignment(dists, thresh=0.8)
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
''' Step 3: Second association, with low score detection boxes'''
# association the untrack to the low score detections
if len(dets_second) > 0:
'''Detections'''
detections_second = [STrack(STrack.tlbr_to_tlwh(tlbr), s) for
(tlbr, s) in zip(dets_second, scores_second)]
else:
detections_second = []
r_tracked_stracks = [strack_pool[i] for i in u_track if strack_pool[i].state == TrackState.Tracked]
dists = matching.iou_distance(r_tracked_stracks, detections_second)
matches, u_track, u_detection_second = matching.linear_assignment(dists, thresh=0.5)
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
lost_stracks.append(track)
'''Deal with unconfirmed tracks, usually tracks with only one beginning frame'''
detections = [detections[i] for i in u_detection]
dists = matching.iou_distance(unconfirmed, detections)
dists = matching.fuse_score(dists, detections)
matches, u_unconfirmed, u_detection = matching.linear_assignment(dists, thresh=0.7)
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
for it in u_unconfirmed:
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
""" Step 4: Init new stracks"""
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)
""" Step 5: Update state"""
for track in self.lost_stracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
# print('Ramained match {} s'.format(t4-t3))
self.tracked_stracks = [t for t in self.tracked_stracks if t.state == TrackState.Tracked]
self.tracked_stracks = joint_stracks(self.tracked_stracks, activated_starcks)
self.tracked_stracks = joint_stracks(self.tracked_stracks, refind_stracks)
self.lost_stracks = sub_stracks(self.lost_stracks, self.tracked_stracks)
self.lost_stracks.extend(lost_stracks)
self.lost_stracks = sub_stracks(self.lost_stracks, self.removed_stracks)
self.removed_stracks.extend(removed_stracks)
self.tracked_stracks, self.lost_stracks = remove_duplicate_stracks(self.tracked_stracks, self.lost_stracks)
# get scores of lost tracks
output_stracks = [track for track in self.tracked_stracks if track.is_activated]
return output_stracks
def joint_stracks(tlista, tlistb):
exists = {}
res = []
for t in tlista:
exists[t.track_id] = 1
res.append(t)
for t in tlistb:
tid = t.track_id
if not exists.get(tid, 0):
exists[tid] = 1
res.append(t)
return res
def sub_stracks(tlista, tlistb):
stracks = {}
for t in tlista:
stracks[t.track_id] = t
for t in tlistb:
tid = t.track_id
if stracks.get(tid, 0):
del stracks[tid]
return list(stracks.values())
def remove_duplicate_stracks(stracksa, stracksb):
pdist = matching.iou_distance(stracksa, stracksb)
pairs = np.where(pdist < 0.15)
dupa, dupb = list(), list()
for p, q in zip(*pairs):
timep = stracksa[p].frame_id - stracksa[p].start_frame
timeq = stracksb[q].frame_id - stracksb[q].start_frame
if timep > timeq:
dupb.append(q)
else:
dupa.append(p)
resa = [t for i, t in enumerate(stracksa) if not i in dupa]
resb = [t for i, t in enumerate(stracksb) if not i in dupb]
return resa, resb
实验
评测指标
说明:IDTP可以看作是在整个视频中检测目标被正确分配的数量,IDFN在整个视频中检测目标被漏分配的数量,IDFP在整个视频中检测目标被错误分配的数量。
IDP:识别精确度
整体评价跟踪器的好坏,识别精确度IDP的分数如下进行计算:
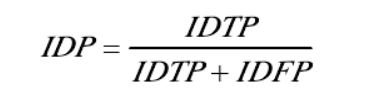
IDR:识别召回率
它是当IDF1-score最高时正确预测的目标数与真实目标数之比,识别召回率IDR的分数如下进行计算:

IDF1:平均数比率
IDF1是指正确的目标检测数与真实数和计算检测数和的平均数比率,IDF1的分数如下进行计算:

Re-Id:行人重识别
MOTA(Multiple Object Tracking Accuracy):MOTA主要考虑的是tracking中所有对象匹配错误,给出的是非常直观的衡量跟踪其在检测物体和保持轨迹时的性能,与目标检测精度无关,MOTA取值小于100,但是当跟踪器产生的错误超过了场景中的物体,MOTA可以变为负数。
MOTP(Multiple Object Tracking Precision) :是使用bonding box的overlap rate来进行度量(在这里MOTP是越大越好,但对于使用欧氏距离进行度量的就是MOTP越小越好,这主要取决于度量距离d的定义方式)MOTP主要量化检测器的定位精度,几乎不包含与跟踪器实际性能相关的信息。
HOTA(高阶跟踪精度)是一种用于评估多目标跟踪(MOT)性能的新指标。它旨在克服先前指标(如MOTA、IDF1和Track mAP)的许多限制。
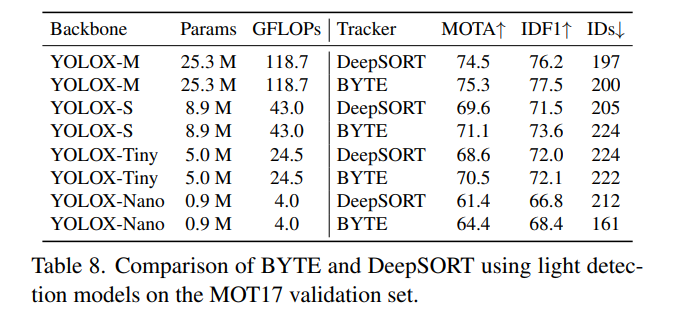
轻量模型的跟踪性能
使用具有不同主干的YOLOX作为检测器。所有模型都在CrowdHuman和MOT17 half训练集上进行训练。在多尺度训练期间,输入图像尺寸是1088×608,最短边范围是384-832。
结果如表8所示。与DeepSORT相比,BYTE在MOTA和IDF1上都带来了稳定的改进,这表明BYTE对检测性能具有鲁棒性。值得注意的是,当使用YOLOX-Nano作为主干时,BYTE的MOTA比DeepSORT高3个点,这使其在实际应用中更具有吸引力。
总结
ByteTrack算法的优点如下:
- ByteTrack算法是一种简单高效的数据关联方法,利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的前景目标。
- ByteTrack算法在处理大量目标时不会出现ID重复问题。
- ByteTrack算法在实时目标追踪方面表现优异。
SORT算法简介
SORT算法步骤:
- 对于每一个新的视频帧,运行一个目标检测器,得到一组目标的边界框。
- 对于每一个已经跟踪的目标,使用卡尔曼滤波对其状态进行预测,得到一个预测的边界框。
- 使用匈牙利算法将预测的边界框和检测的边界框进行匹配,根据边界框之间的重叠度(IOU)作为代价函数,求解最佳匹配方案。
- 对于匹配成功的目标,使用检测的边界框更新其卡尔曼滤波状态,并保留其标识。
- 对于未匹配的检测结果,创建新的目标,并初始化其卡尔曼滤波状态和标识。
- 对于未匹配的预测结果,删除过期的目标,并释放其标识。
ByteTrack算法和SORT算法的区别
-
SORT算法是一种基于卡尔曼滤波的多目标跟踪算法;
而ByteTrack算法是一种基于目标检测的追踪算法。
-
SORT算法使用卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配;
而ByteTrack算法使用了卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配,并且利用检测框和跟踪轨迹之间的相似性,在保留高分检测结果的同时,从低分检测结果中去除背景,挖掘出真正的前景目标。
-
SORT算法在处理大量目标时会出现ID重复问题;
而ByteTrack算法则不会出现这个问题。