在深度学习模型的测试过程中,数据集的选择很重要。在构造数据集的时候,要注意做好数据的清洗和标注,一个高质量的数据集往往能够提高模型训练的质量和预测的准确率。在缺乏数据的情况下,可以尝试寻找一些公开数据集,特别是得到公认的被普遍使用的数据集。对于常见的任务,比如:图像识别、目标检测和图像分割的任务方面,均有对应的公开数据集可以使用。模型的选择、构建很重要,训练数据对模型也是非常重要的,在改变模型架构来尝试提高模型预测准确率的同时,也需要注意提高输入数据的质量,同时也考虑增加输入数据的数量,看是否能够提高模型的预测效果。
收集图片和图像的预处理
我们的数据集中图像可以来源于互联网,可以自行使用爬虫进行图片的采集和保存。
在大多数移动平台上的目标检测部署都是针对于某一类特定的物体实现目标的识别。所以我们需要自己采集图像并制作属于自己的数据集。
数据集的采集
TensorFlow需要一个目标的上百张图片以训练一个优秀的识别分类器。为了训练一个强大的分类器,训练图片中除了所需的目标应该还要有其他随机物体,并需要有丰富的背景和光照条件。有些图片中的目标物体需要被其他事物部分遮挡、重叠或只露出一半。
收集图片时考虑以下几点:
- 在与现实应用中的预期场景相似甚至完全相同的条件下获取深度学习图像数据。只有出于实验目的时,才可以使用实验室设置获取图像。
- 训练数据必须涵盖线上应用过程中可能发生的所有变化。其中也包括一般条件的变化,例如照明。
- 训练数据必须独立。其中不应包含同一对象的多个数据。
- 按照步骤 1、2 和 3,获得的训练数据越多越好。
采集图像
这里使用python脚本拍摄数据集,一般来说一个类采集各个角度,光照条件的图像数目在200张左右经过数据的扩充就可以达到较好的训练效果了。
#coding:utf-8
import cv2
cap = cv2.VideoCapture(0)#创建一个 VideoCapture 对象
flag = 1 #设置一个标志,用来输出视频信息
num = 1 #递增,用来保存文件名
while(cap.isOpened()):#循环读取每一帧
ret_flag, Vshow = cap.read() #返回两个参数,第一个是bool是否正常打开,第二个是照片数组,如果只设置一个则变成一个tumple包含bool和图片
cv2.imshow("Capture_Test",Vshow) #窗口显示,显示名为 Capture_Test
k = cv2.waitKey(1) & 0xFF #每帧数据延时 1ms,延时不能为 0,否则读取的结果会是静态帧
if k == ord('s'): #若检测到按键 ‘s’,打印字符串
cv2.imwrite("F:/ipc/Python/CV2/can"+ str(num) + ".jpg", Vshow) #第一个字符串"F:/ipc/Python/CV2/can"为文件保存地址路径F:/ipc/Python/CV2/ 和图片名称前缀can的组合
print(cap.get(3)); #得到长宽
print(cap.get(4));
print("success to save"+str(num)+".jpg")
print("-------------------------")
num += 1
elif k == ord('q'): #若检测到按键 ‘q’,退出import
break
cap.release() #释放摄像头
cv2.destroyAllWindows()#删除建立的全部窗口
在Jetson中使用CSI摄像头采集:
#coding:utf-8
import cv2
from jetcam.csi_camera import CSICamera
flag = 1 #设置一个标志,用来输出视频信息
num = 1 #递增,用来保存文件名
camera0 = CSICamera(capture_device=0, width=960, height=680, capture_width=960,capture_height=680,capture_fps=20)
while 1 :#循环读取每一帧
img = camera0.read()
#_, img = cap.read()
cv2.imshow("Capture_Test",img) #窗口显示,显示名为 Capture_Test
k = cv2.waitKey(1) & 0xFF #每帧数据延时 1ms,延时不能为 0,否则读取的结果会是静态帧
if k == ord('s'): #若检测到按键 ‘s’,打印字符串
cv2.imwrite("/home/CVProjece/CV2/image/bord/"+ str(num) + ".jpg", img) #第一个字符串为文件保存地址路径F和图片名称前缀的组合
#print(img.get(3)); #得到长宽
#print(img.get(4));
print("success to save"+str(num)+".jpg")
print("-------------------------")
num += 1
elif k == ord('q'): #若检测到按键 ‘q’,退出
break
cv2.destroyAllWindows()#删除建立的全部窗口
数据集预处理
首先是图像数据的扩充,请参考:数据集扩充
使用数据集扩充的方法将原始图像数目扩大3-4倍,再通过人工筛选的方式,删除图像中相似度很高的图像。
扩充数据之后是图像命名批处理,我们新建两个文件夹:\test和\train,把上面经过扩充的所有图像转移到\train文件夹下,使用以下windows命令脚本批处理文件名。
使用方法:在\train文件夹下新建一个.txt文件,将以下脚本全部拷贝到文件中,保存文件。再将文件后缀重命名为.bat。然后双击运行改脚本。在终端输入你需要的图像文件名前缀(可以不输入)和后缀(输入jpg),回车就可以将该脚本同级目录下的所有文件名批处理。
@echo off
echo *******File batch renaming*******
echo.
echo.
set /p filename=Please enter a filename prefix:
IF "%filename%"=="" set "filename=%%~ni"
set /p suffix=Please enter file type:
IF "%suffix%"=="" echo.The file type cannot be empty &goto error
IF NOT EXIST *.%suffix% echo.The format file does not exist &goto error
setlocal ENABLEDELAYEDEXPANSION
for /r %%i in (.) do (
set n=10000
for /f "delims=" %%a in (' dir /b "%%i\*.%suffix%" 2^>nul ') do (
set /a n+=1
ren "%%i\%%a" "%filename%"!n:~1!%%~xa
)
)
echo. &pause
exit
:error
echo. &pause
数据集标注
LabelImg是一个标注图片的强大工具,具体下载和使用自行百度。使用LabelImg标注图像,注意输出格式为VOC,输出文件路径与图像路径相同。
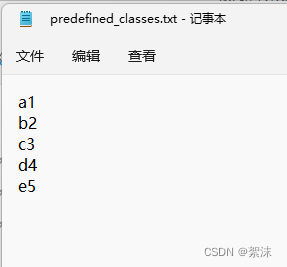
注意标注时predefined_classes.txt数据中你的每一类图像的前后顺序,从这里开始就被严格固定了。
例如我有五个待标注的物体,名字分别是:a1、b2、c3、d4、e5,他们在predefined_classes.txt中的排列顺序如下。那么之后的训练中这五个类的前后顺序要和这里保持一致。因为标注和训练中对于不同类,程序并不是以类的名字来区分他们,而是以一个数字来区分,这个数字就是这里设置的排序。
LabelImg为每一张图片保存一个包含标注信息的.xml文件。一般来说这步的操作最耗时。
全部标注完成后,我们人工从所有图像中挑选一部分,约20%左右,将图片和对应的.xml文件一同剪切到前面创建的\test文件夹中。现在\train文件夹中的数据用于训练,\test文件夹中的数据用于测试。
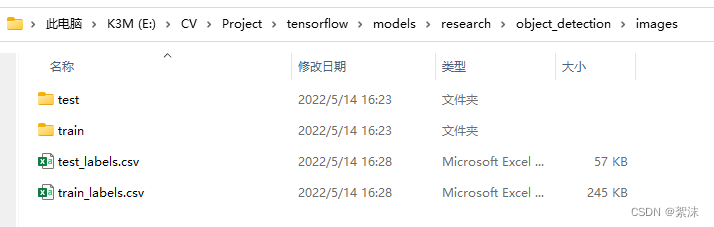
再将两个文件夹移动到之前API仓库中的\object_detection\images目录下
生成训练数据
当标注完图片后,是时候生成输入给TensorFlow训练模块的TFRecords了.。
这里需要用到两个脚本:xml_to_csv.py和generate_tfrecords.py脚本(程序放在下面了),需要稍微修改程序来适应你的目录结构。
在 \object_detection路径下,使用py37虚拟环境,运行
python xml_to_csv.py
这会在\object_detection\images文件夹下生成一个train_labels.csv和test_labels.csv文件。
接着,用文本编辑器打开generate_tfrecord.py。用自己的标注映射图替换从31行开始的标注映射图,每一个目标物体被分配一个ID号码。在上一步操作中说到的序号,就是这里的ID,在前面的例子中:a1的ID是1、b2的ID是2、c3的ID是3、d4的ID是4、e5的ID是5,相同的号码分配会被用于配置.pbtxt文件。对应的修改后的generate_tfrecord.py中的代码片段为
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'a1':
return 1
elif row_label == 'b2':
return 2
elif row_label == 'c3':
return 3
elif row_label == 'd4':
return 4
elif row_label == 'e5':
return 5
else:
None
然后,在\object_detection路径下运行下列命令生成TFRecord文件:
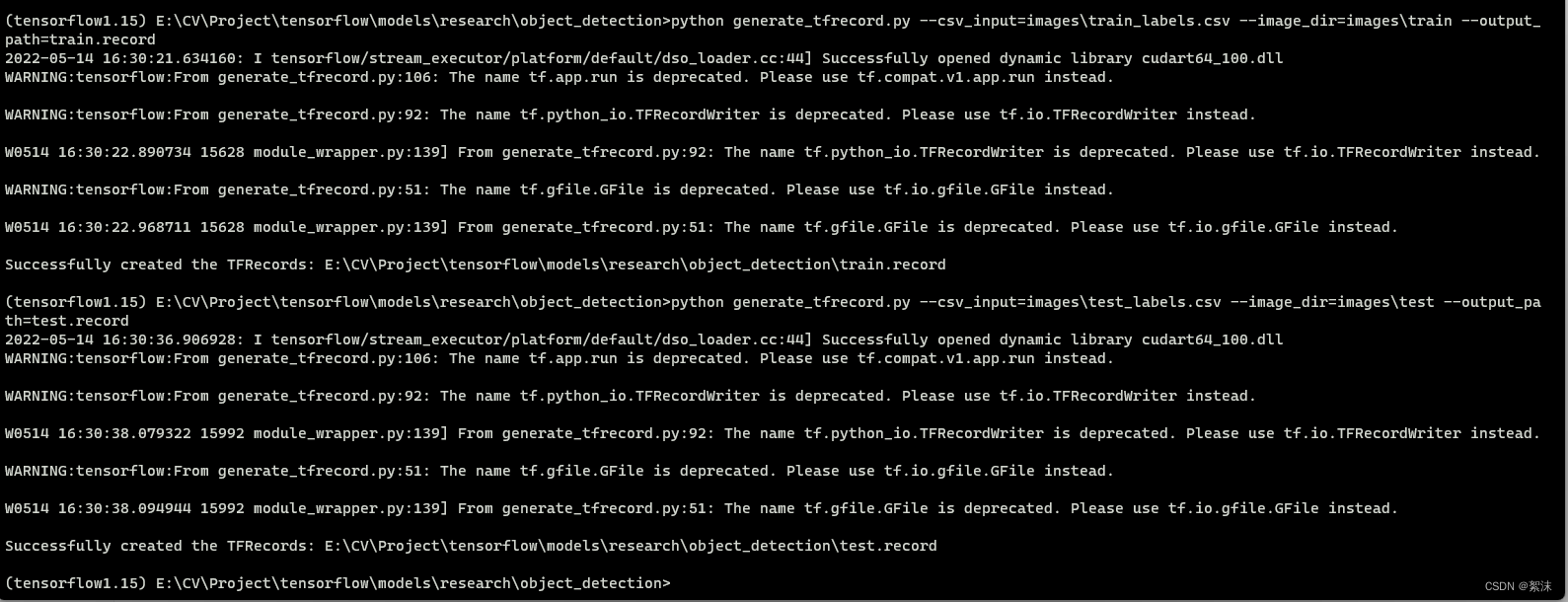
python generate_tfrecord.py --csv_input=images\train_labels.csv --image_dir=images\train --output_path=train.record
python generate_tfrecord.py --csv_input=images\test_labels.csv --image_dir=images\test --output_path=test.record
运行没有问题后会输出成功输出文件的提示信息。
这会在\object_detection路径下生成train.record和test.record文件。它们将用于训练物体识别分类器。
到这里就完成全部的数据处理了。
xml_to_csv.py
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
for folder in ['train','test']:
image_path = os.path.join(os.getcwd(), ('images/' + folder))
xml_df = xml_to_csv(image_path)
xml_df.to_csv(('images/' + folder + '_labels.csv'), index=None)
print('Successfully converted xml to csv.')
main()
generate_tfrecord.py
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=images/train_labels.csv --image_dir=images/train --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=images/test_labels.csv --image_dir=images/test --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
from tensorflow.python.framework.versions import VERSION
if VERSION >= "2.0.0a0":
import tensorflow.compat.v1 as tf
else:
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('image_dir', '', 'Path to the image directory')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'classname':
return 1
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), FLAGS.image_dir)
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()