python爬虫,用scrapy爬取天天基金
学了一段时间的爬虫,准备做个爬虫练习巩固一下,于是选择了天天基金进行数据爬取,中间遇到的问题和解决方法也都记录如下。
附上代码地址:https://github.com/Marmot01/python-scrapy-
爬取思路
一.分析网站
-
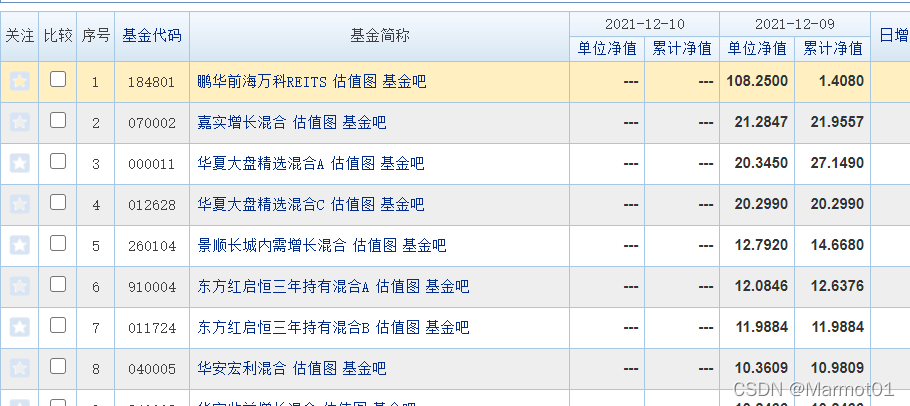
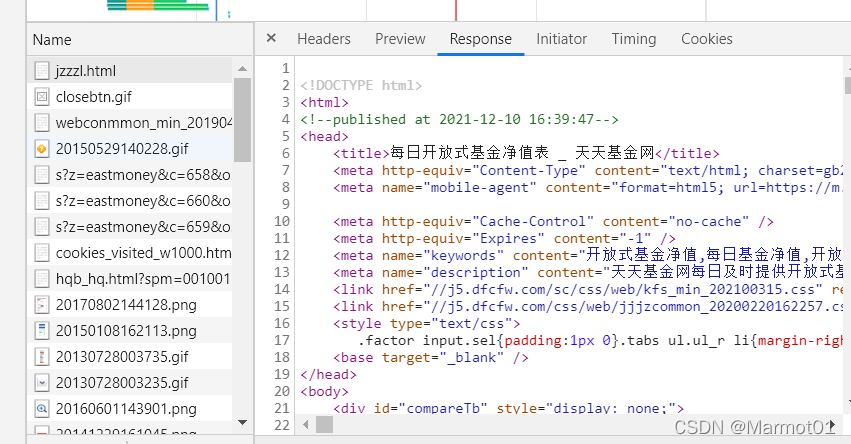
首选来到天天基金首页http://fund.eastmoney.com/jzzzl.html,分析要爬取的内容。
在首页中我们主要获取基金代码以及基金简称,其余的数据可以通过超链接,跳转到其余页面进行分析。然后F12进行抓包,获取页面响应
在response中我们可以发现响应格式为html格式,通过ctrl+f搜索我们需要的页面内容(基金代码和基金简称),发现都能在响应中找到。 -
分析要爬取的其他内容
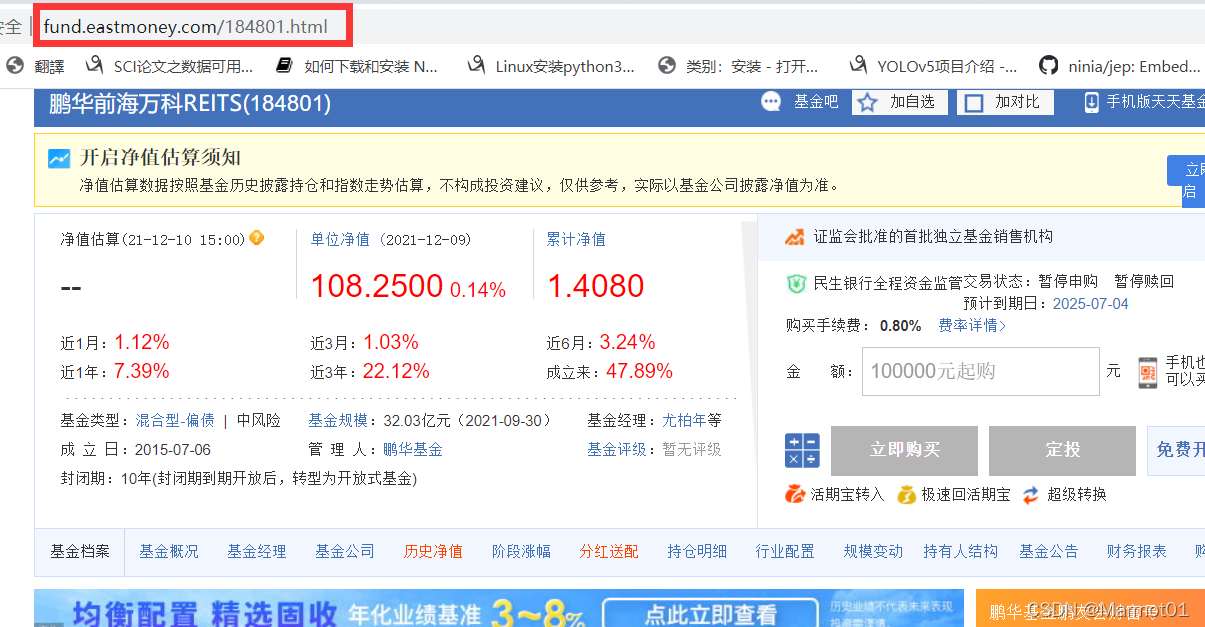
通过基金简称中的超链接,我们可以跳转到某个基金的首页
通过分析首页网址,可以很容易观察出页面的网址由首页地址加上基金代码组成(这对后续爬取非常重要)。在这个页面中可以根据自己的需要,选取想要爬取的内容,我在这里将单位净值、近期的涨跌、基金经理等都进行了爬取。
发现这个页面的响应也是html,要爬取的内容也都可以在响应中找到。 -
爬取以往的单位净值
在这里我还想获取这个基金以往的单位净值数据,于是点击单位净值超链接,可以看到这个网址也很好分析,这里就不在多说。
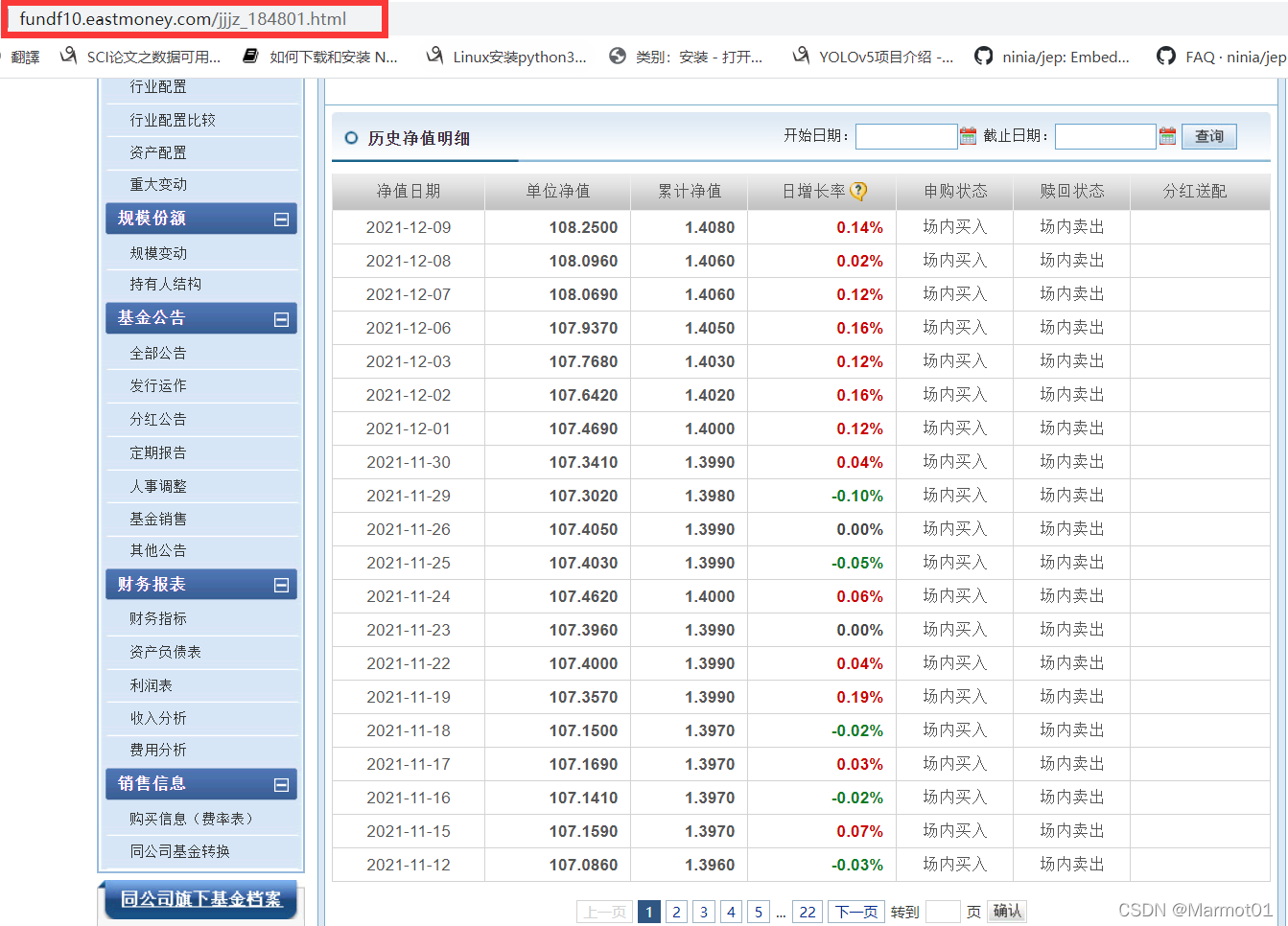
进行爬取数据分析,需要特别注意的是,这个页面的响应虽然是html,但是通过搜索,我们可以发现这个响应中只会出当前日期的单位净值,并不会出现我们想要的历史数据。
在这里猜想应该是历史数据不在这个包中,应该在其他的包里,于是点击下一页,重新进行抓包。发现每次点击下一页时,都会发一个这个包
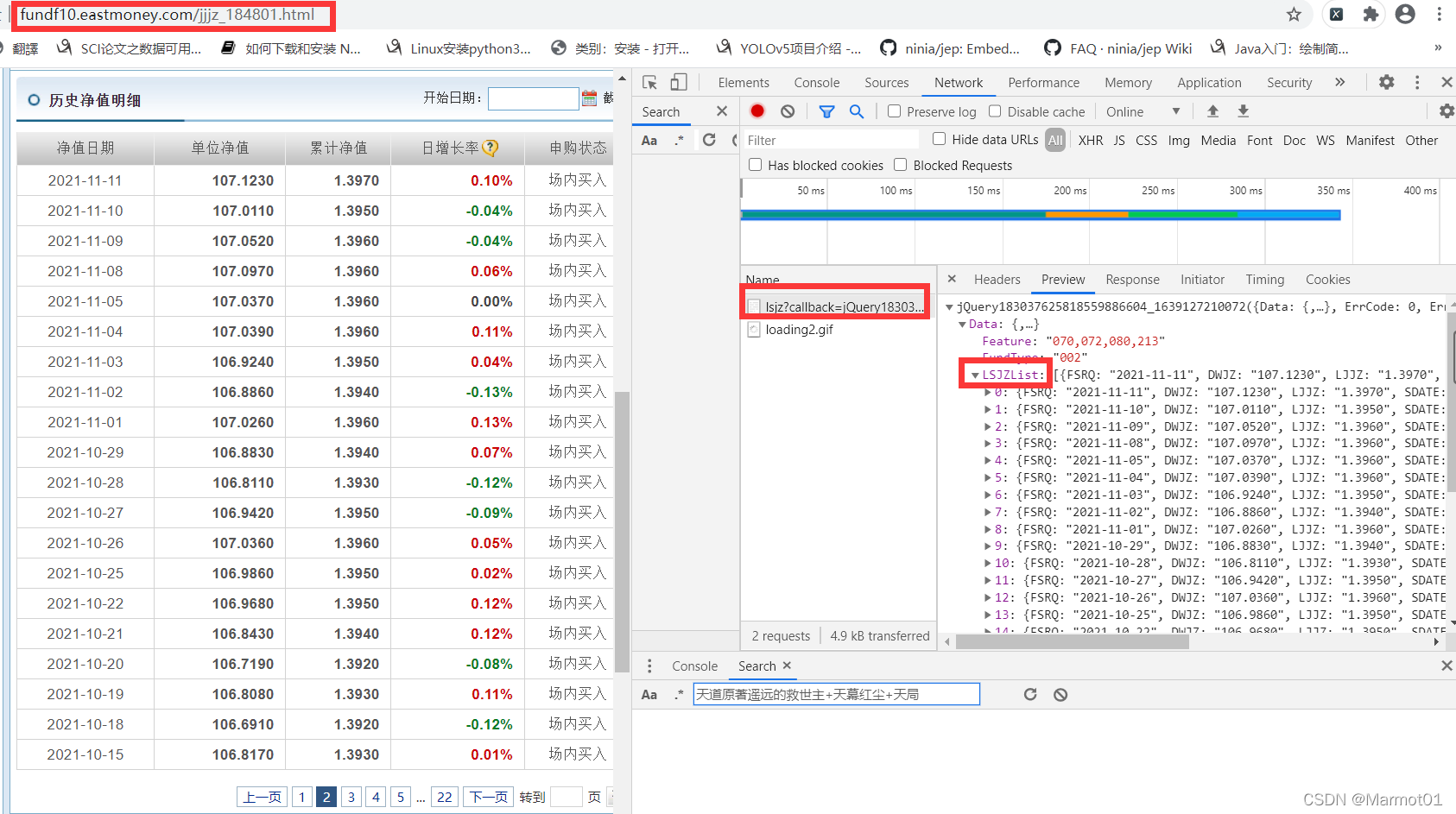
对这个包进行分析,发现响应是jQuery格式(和之前的html不同),并且我们要的历史数据也也在这里面。
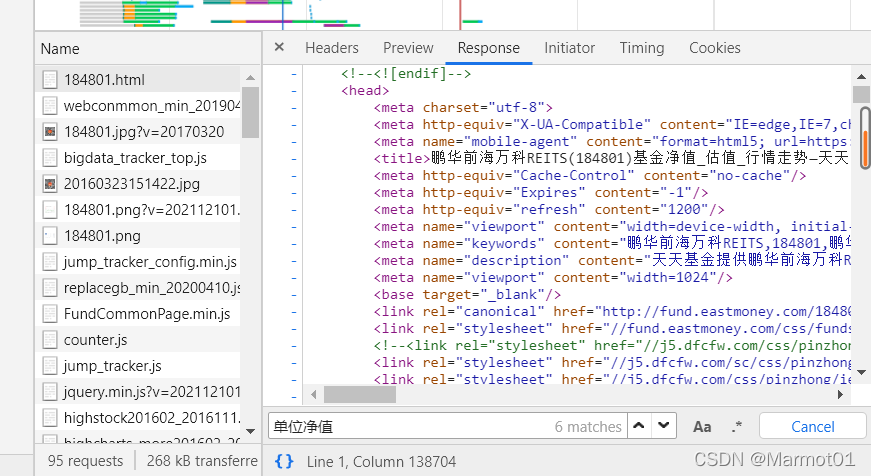
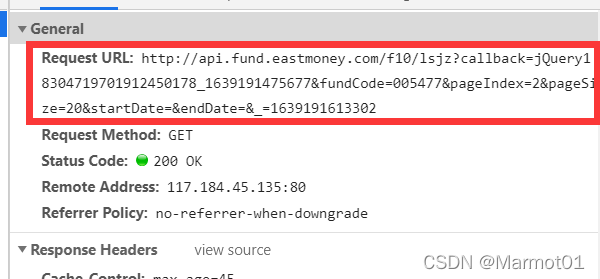
但是这里有一个问题,就是当点击下一页时,网站的地址其实是不变的,这就对翻页造成了很大困扰,不过不用着急,我们继续分析这个包的headers,发现这个包的请求地址并不是这个页面的网址,如图所示。
我们将Request URL中的地址复制下来,开启一个新页面进行访问,发现响应的内容如下,JQuery格式,但是很明显,内容并不是我们想要的,猜想应该是页面对这个请求地址做了反扒。
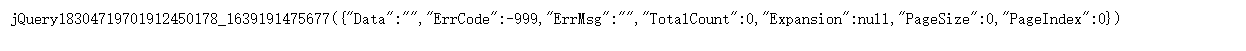
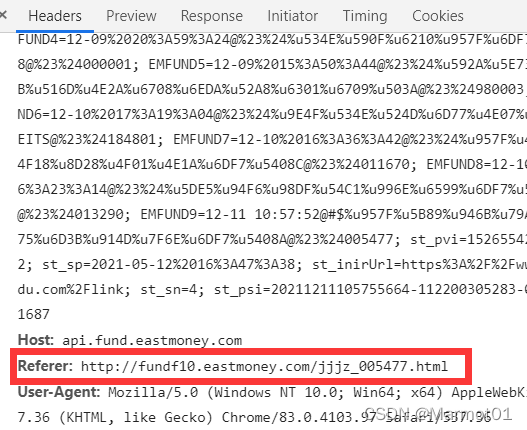
也就是说我们要访问Request URL中的地址,需要告诉浏览器我们是从Referer中的地址过来的(也就是当前页面的地址),弄清楚之后我写了个测试代码,看看他会返回什么内容,代码如下:

import requests
import json
headers = {
'Referer': 'http://fundf10.eastmoney.com/jjjz_000001.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
# kw = {'fundCode': '000001',
# 'pageIndex': '2',
# 'pageSize': '20',}
kw = {'fundCode': '000001',
'pageIndex': '1',
'pageSize': '20'
}
url = 'http://api.fund.eastmoney.com/f10/lsjz'
res=requests.get(url=url,headers=headers,params=kw)
print(res.content.decode())
data_dict = json.loads(res.content.decode())
print(len(data_dict['Data']['LSJZList']))
需要注意的是,我们在这里对Request URL的地址进行了简化,
原始的url:
http://api.fund.eastmoney.com/f10/lsjz?callback=jQuery18304719701912450178_1639191475677&fundCode=005477&pageIndex=2&pageSize=20&startDate=&endDate=&_=1639191613302a
简化后的:
http://api.fund.eastmoney.com/f10/lsjz?fundCode=005477&pageIndex=2&pageSize=20
其中callback=jQuery是说响应后的数据格式为jQuery,把他去掉响应后的数据格式就变成了json,后面的字符串很容易看出来和时间有关,把他去掉也不影响最后的响应内容。
最后剩下的就好判断了,一个是基金代码,一个是当前页面,还有一个是每页显示的数据量,有了这些在进行翻页就简单多了。
不过通过每次改变pageIndex进行翻页,我感觉有些麻烦,所以就尝试改变pageSize来在一个页面中获取所有的数据,没想到还真的可以,这样就可以指定pageSize的大小来获取数据,而不用翻页,多次发请求,方便了许多。
二 编写代码
在分析完要爬取的网页后,就是用scrapy进行爬取了,scrapy框架的搭建这里就不详细说了,大家可以到网上搜一搜,这里说一下,写代码的思路
- 确定要爬取的内容
在items中确定要爬取的内容,我要爬的内容比较多,这这里就不一一列出了,直接上代码
import scrapy
class TtfundItem(scrapy.Item):
# define the fields for your item here like:
#基金代码
fund_code = scrapy.Field()
#基金简称
fund_name = scrapy.Field()
#基金链接
fund_link = scrapy.Field()
#当前单位净值
fund_current_value = scrapy.Field()
#当前日期
fund_current_date = scrapy.Field()
#累计净值
fund_total_value = scrapy.Field()
#近一月涨跌
one_month_rate = scrapy.Field()
#近三月涨跌
three_month_rate = scrapy.Field()
#近六月涨跌
six_month_rate = scrapy.Field()
#近一年涨跌
one_year_rate = scrapy.Field()
#近三年涨跌
three_year_rate = scrapy.Field()
#成立以来涨跌
total_rate = scrapy.Field()
#成立时间
fund_start_time = scrapy.Field()
#基金经理
fund_manager = scrapy.Field()
#基金规模
fund_size = scrapy.Field()
#基金类型
fund_type = scrapy.Field()
# 基金风险
fund_risk = scrapy.Field()
#基金评级
fund_rating = scrapy.Field()
#历史净值
history_value = scrapy.Field()
- 填写爬虫方法
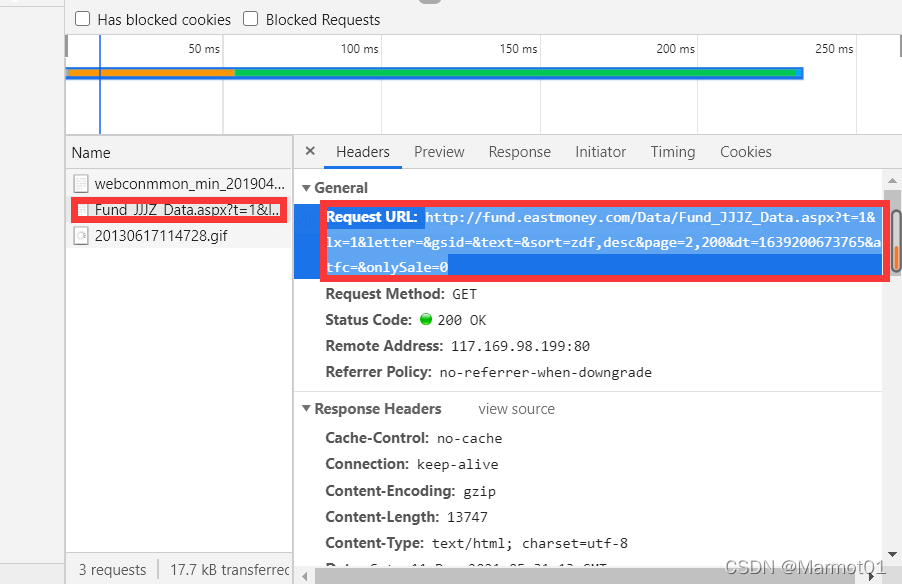
在爬虫类中填写首先填写爬虫的起始url,在这里需要注意的是,我们刚开始分析的天天基金网首页,如果我们要对其进行翻页操作的话,会发现它页面地址也是不变的,这和之前分析的爬取以往的单位净值是类似的,对齐进行翻页抓包,会发现它发出的请求是下面这个地址:http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?t=1&lx=1&letter=&gsid=&text=&sort=zdf,desc&page=2,200&dt=1639200673765&atfc=&onlySale=0
不过他和爬取历史净值数据不同的是,这个网址可以直接访问,访问的内容如下:
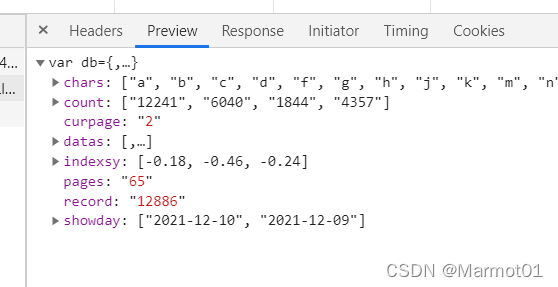
查看响应数据格式,发现他是一种类似于js格式的数据,所以需要使用解析js的方式对数据进行解析。
和之前类似,我们也可以对起始的url进行简化,然后通过改变每一页数据的数量获取我们想要的数据量
简化后的url为:http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?&page=1,100
page=1,100表示爬取第一页,每页100个数据,当然可以根据需要自行修改。
下面附上爬取代码

import scrapy
from TTFund.items import TtfundItem
import json
import execjs
class TtfundSpider(scrapy.Spider):
name = 'ttfund'#爬虫的名字
allowed_domains = ['eastmoney.com']
#start_urls = ['http://fund.eastmoney.com/jzzzl.html']
start_urls = ['http://fund.eastmoney.com/Data/Fund_JJJZ_Data.aspx?&page=1,100']#可以通过设置最后一个数选择爬取多少数据
def parse(self, response):
print(response.request.headers)
data = response.body.decode('utf-8')
#返回的数据格式为js格式
jsContent = execjs.compile(data)
data_dict = jsContent.eval('db')
datas = data_dict['datas']
for data in datas:
temp = {}
temp['fund_code'] = data[0]
temp['fund_name'] = data[1]
temp['fund_link'] = "http://fund.eastmoney.com/"+data[0]+".html"
detail_link = temp['fund_link']
#print(detail_link)
# nodelists = response.xpath('//*[@id="oTable"]/tbody/tr')
# for node in nodelists:
# temp = {}
# temp['fund_code'] = node.xpath('./td[4]/text()').extract_first()
# temp['fund_name'] = node.xpath('./td[5]/nobr/a[1]/text()').extract_first()
# temp['fund_link'] = response.urljoin(node.xpath('./td[5]/nobr/a[1]/@href').extract_first())
# detail_link = temp['fund_link']
#模拟点击链接
yield scrapy.Request(
url=detail_link,
meta={'temp':temp},
callback=self.parse_detail,
)
def parse_detail(self,response):
temp = response.meta['temp']
temp['fund_current_value'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[1]/span[1]/text()').extract_first()
hisetory_link = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dt/p/span/span/a/@href').extract_first()
temp['fund_current_date'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dt/p/text()').extract_first().strip(')')
temp['fund_total_value'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[3]/dd[1]/span/text()').extract_first()
temp['one_month_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[1]/dd[2]/span[2]/text()').extract_first()
temp['three_month_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[2]/span[2]/text()').extract_first()
temp['six_month_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[3]/dd[2]/span[2]/text()').extract_first()
temp['one_year_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[1]/dd[3]/span[2]/text()').extract_first()
temp['three_year_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[2]/dd[3]/span[2]/text()').extract_first()
temp['total_rate'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[1]/dl[3]/dd[3]/span[2]/text()').extract_first()
#要去掉xpath中给tbody
temp['fund_start_time'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[2]/td[1]/text()').extract_first().strip(': ')
temp['fund_manager'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[3]/a/text()').extract_first()
temp['fund_size'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[2]/text()').extract_first().strip(': ')
temp['fund_risk'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[1]/text()[2]').extract_first().strip('\xa0\xa0|\xa0\xa0')
temp['fund_type'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[1]/td[1]/a/text()').extract_first()
temp['fund_rating'] = response.xpath('//*[@id="body"]/div[11]/div/div/div[3]/div[1]/div[2]/table/tr[2]/td[3]/div/text()').extract_first()
#print(temp)
headers = {
'Referer': hisetory_link,
}
kw = {'fundCode': temp['fund_code'],
'pageIndex': 1,
'pageSize': 5000,}#可以设置想要爬取的数据数量,如果设置数据多余网站总的数据,则只会爬取网站的总数据
yield scrapy.Request(
url="http://api.fund.eastmoney.com/f10/lsjz?fundCode={}&pageIndex={}&pageSize={}".format(temp['fund_code'],1,5000),
headers=headers,
meta={'temp':temp},
callback=self.parse_history
)
def parse_history(self,response):
temp = response.meta['temp']
history_value = []
dict_data = json.loads(response.body.decode())
for data in dict_data['Data']['LSJZList']:
tp = {}
tp['净值日期'] = data['FSRQ']
tp['单位净值'] = data['DWJZ']
tp['累计净值'] = data['LJJZ']
history_value.append(tp)
items = TtfundItem()
items['fund_code'] = temp['fund_code']
items['fund_name'] = temp['fund_name']
items['fund_link'] = temp['fund_link']
items['fund_current_value'] = temp['fund_current_value']
items['fund_current_date'] = temp['fund_current_date']
items['fund_total_value'] = temp['fund_total_value']
items['one_month_rate'] = temp['one_month_rate']
items['three_month_rate'] = temp['three_month_rate']
items['six_month_rate'] = temp['six_month_rate']
items['one_year_rate'] = temp['one_year_rate']
items['three_year_rate'] = temp['three_year_rate']
items['total_rate'] = temp['total_rate']
items['fund_start_time'] = temp['fund_start_time']
items['fund_manager'] = temp['fund_manager']
items['fund_size'] = temp['fund_size']
items['fund_risk'] = temp['fund_risk']
items['fund_type'] = temp['fund_type']
items['fund_rating'] = temp['fund_rating']
items['history_value'] =history_value
yield items
在这里我是使用的xpath对数据进行的提取,xpath语句可以根据爬取的内容自己写,也可以直接选中要爬取的元素,在elements对应的位置直接copy为xpath,不过在copy时需要进行一些细微的修改,这里需要对xpath有一定了解,我就不过多叙述,大家可以到网查一查,并不难。特别需要注意到是,在对基金经理等内容进行爬取时,copy的xpath中含有tbody需要把他给去掉,不然会爬取不了数据。查了一下,是因为页面源码中,并不含有tbody这个选项,但是浏览器中有tbody,所以copy的xpath需要把tbody给去掉。
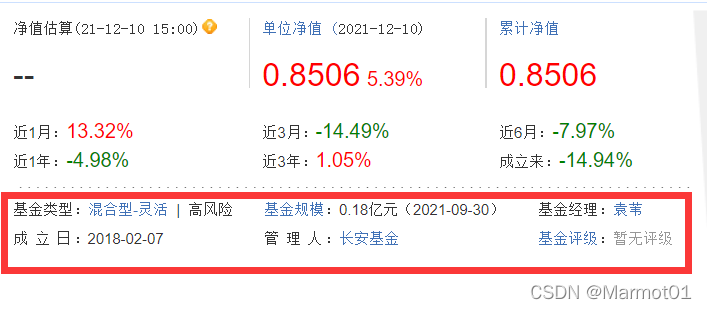
三 保存数据
scrapy爬取的数据最后会通过yield将数据返回给pipelines管道,所以我们需要在pipelines.py文件中定义我们要保存的位置,在这里我是保存在了mongodb数据库中。
from itemadapter import ItemAdapter
from pymongo import MongoClient
class TtfundPipeline:
def open_spider(self, spider):
if spider.name =="ttfund":
#存入mongodb数据库
self.client = MongoClient('127.0.0.1',27017)
self.db = self.client['TTFund']
self.col = self.db['ttfund']
def process_item(self, item, spider):
if spider.name == "ttfund":
data = dict(item)
self.col.insert(data)
return item
def close_spider(self,spider):
if spider.name == "ttfund":
self.client.close()
需要注意的是代码写完后,我们还需要再setting.py中开启相关的设置,不然管道没法用,同时也可以在setting中设置User_Agent(也可以使用随机代理)。
下面是setting.py的代码
# Scrapy settings for TTFund project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from fake_useragent import UserAgent
BOT_NAME = 'TTFund'
SPIDER_MODULES = ['TTFund.spiders']
NEWSPIDER_MODULE = 'TTFund.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
#随机请求头(随机生成十个)
#USER_AGENT_LIST = [UserAgent().random for i in range(10)]
USER_AGENT_LIST = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36"]
# Obey robots.txt rules
#ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'TTFund.middlewares.TtfundSpiderMiddleware': 543,
#
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
#'TTFund.middlewares.TtfundDownloaderMiddleware': 543,
'TTFund.middlewares.RandomUserAgent': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'TTFund.pipelines.TtfundPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
四 结果
接下来就是爬取数据了,其实还挺快的,把爬取的数据存入mongodb数据库中,下面是最后的结果
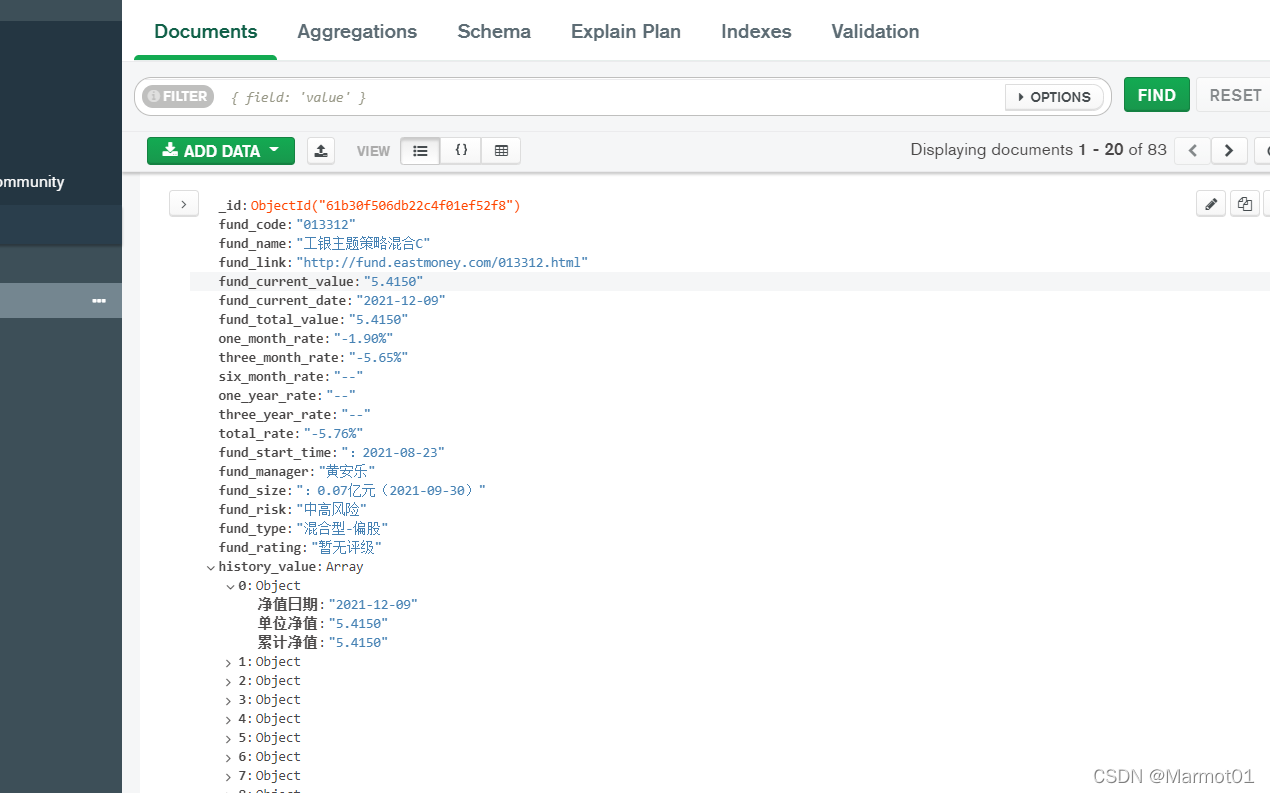
可以看到数据都有了,大功告成!
最后附上代码地址:https://github.com/Marmot01/python-scrapy-
五 总结
1.总的来说这个网站还是相对比较容易爬取的,没有太多的坑人的地方
2.难点主要就是分析翻页以及获取响应数据上面,在这里确实花了不少时间,每个网站都不一样,不过爬取的大体思路还是可以借鉴的
3.最后爬取的结果,其实我是设置爬取100个基金数据的,但是不知道为什么最后爬取的结果只有83个(我猜想可能是爬取 的时候由于网络原因,有一些跳过了吧)。
4.关于随机请求头User_Agent和随机代理ip,这里其实可以尝试去做一下,不过我对起始url进行翻页的操作,其实是一次完成的,不会发多次请求,所以随机User_Agent其实没有多大用。