
前言
微信作为国民应用,向来是占用手机空间最多的APP之一,其中历年累积的聊天记录也就蕴含着巨大的信息量。特别在微信群中,经常一转眼的功夫,就累积了几百条的留言。这里充斥着口水,偶尔又蕴藏了真知灼见,既不想错过,又没有时间,若想每个群都看一遍,真心是个苦力活。本篇选用了大佬的聊天群作为数据来源,让大模型帮我们定期自动生成报告,甚至还能将日理万机的某个大佬,请来化身客串一下我们的私人助理。
鉴于聊天记录属于绝对的个人隐私,肯定不适合接入第三方大模型来提取信息。无论是 ChatGPT 还是文心都不能完全保证提交数据不用于改善模型,那么本地化部署 LLM 将成为必然的选择。
最近随着百川2的国产大模型开源,很多领域逼近甚至超越了 llama 2 的效果(特别在中文理解领域)。本文采用了 Baichuan2 作为底模,先用提示工程对聊天记录进行信息提取,并在此基础上使用自有数据进行模型微调。

微信记录导出
巧妇难为无米之炊,我们第一步就是要获取微信聊天记录数据集。不做不知道,没想到到 2023 年了,作为数据的完全拥有者,想获取聊天记录明文还是非常的麻烦(换一个角度来说,也是微信为了保护隐私做出的不懈努力🐶)
由于手机版本的微信访问数据库,需要先 root 手机,这里为了简化操作选用的是电脑版的微信做示例,手机版本的过程雷同,不再赘述。

定位数据库
根据微信文件的默认保存位置,我的聊天记录在以下目录中
./WeChat Files/bluishfish/Msg/Multi/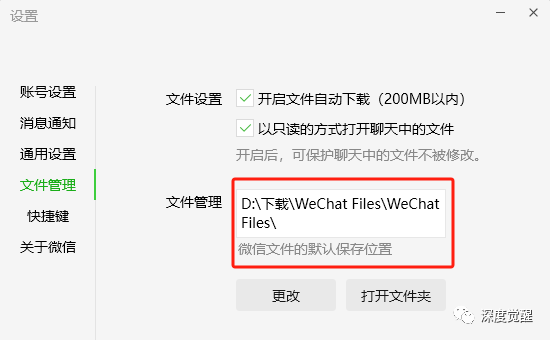
数据库采用 SQLite 文件形式,大致分为 3 类,FTSMSG.db(索引文件)、MediaMSG.db(语音文件)、MSG.db(聊天记录文件)。文件后缀有若干数字,将聊天记录分割为较小的数据库,有 config.ini 来配置当前生效的数据库。
另有联系人信息存放在 MicroMsg.db 的 Contact 表中
./WeChat Files/bluishfish/Msg/这里我们只关心语音文件、聊天记录文件和联系人,其余字段含义参考以下链接。不过这些文件都处于加密状态,所以我们首先要获取密钥。
https://github.com/Tencent/wcdb获取密钥
微信的聊天记录基于 SQLCipher 加密,我们先采用一个内存查找工具来定位密钥

Cheat Engine 7.5
下载 cheat engine,搜索微信用户名或手机号,可以快速查找到内存地址。
https://www.cheatengine.org/downloads.php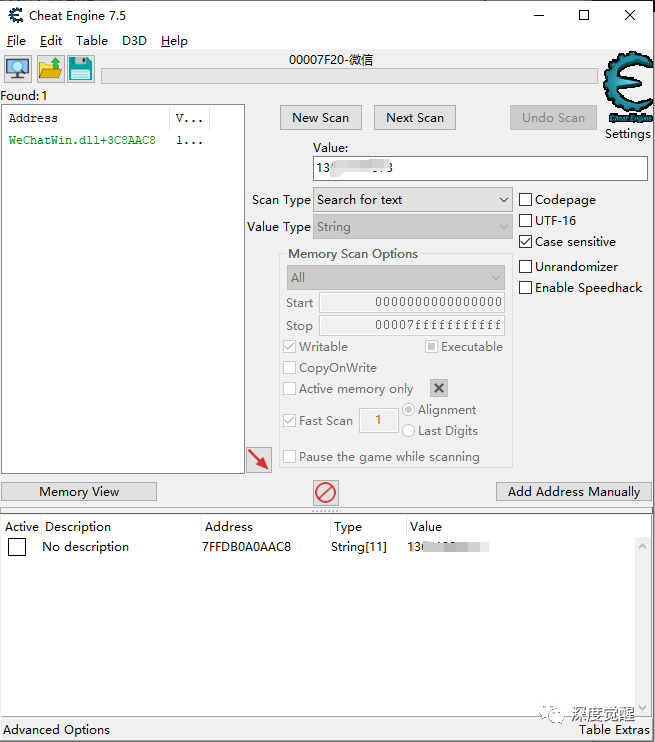
其中上图中 WeChatWin.dll 为基地址,3C8 AAC8 则为手机号所在的偏移地址,转换为十进制则为 63,482,568

然后根据其他变量的偏移(手机号地址+1,464为密钥地址),可以分别得出微信昵称,微信名,手机号和密钥了。
编译工具

https://github.com/AdminTest0/SharpWxDump将获取的内存地址,填入 Program.cs 中,其中不同的微信版本内存地址可能不同。
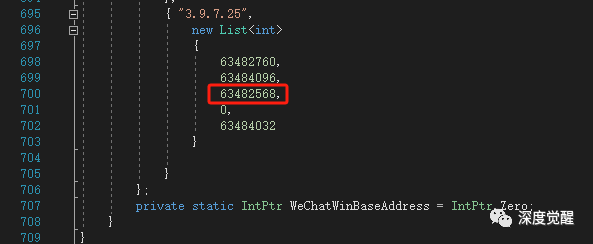
然后编译运行,WeChatKey 就是所需的数据库私钥了。
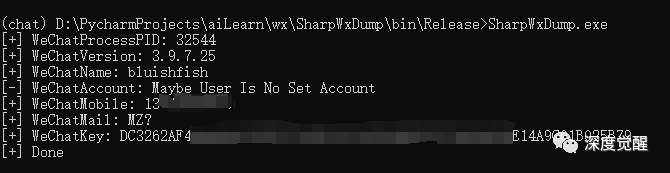
解密数据库

有了密钥,我们先将 MediaMSG.db 、 MSG.db 和 MicroMsg.db 解析为普通数据库,方便查看以及后续转成语料素材。
import hmac
import hashlib
from Cryptodome.Cipher import AES
SQLITE_FILE_HEADER = "SQLite format 3\x00" # SQLite文件头
KEY_SIZE = 32
DEFAULT_PAGESIZE = 4096
DEFAULT_ITER = 64000
# 通过密钥解密数据库
def decrypt(key, filePath, decryptedPath):
password = bytes.fromhex(key.replace(" ", ""))
with open(filePath, "rb") as file:
blist = file.read()
salt = blist[:16]
byteKey = hashlib.pbkdf2_hmac("sha1", password, salt, DEFAULT_ITER, KEY_SIZE)
first = blist[16:DEFAULT_PAGESIZE]
mac_salt = bytes([(salt[i] ^ 58) for i in range(16)])
mac_key = hashlib.pbkdf2_hmac("sha1", byteKey, mac_salt, 2, KEY_SIZE)
hash_mac = hmac.new(mac_key, first[:-32], hashlib.sha1)
hash_mac.update(b'\x01\x00\x00\x00')
if hash_mac.digest() == first[-32:-12]:
print("Decryption Success")
else:
print("Password Error")
return False
newblist = [blist[i:i + DEFAULT_PAGESIZE] for i in range(DEFAULT_PAGESIZE, len(blist), DEFAULT_PAGESIZE)]
with open(decryptedPath, "wb") as deFile:
deFile.write(SQLITE_FILE_HEADER.encode())
t = AES.new(byteKey, AES.MODE_CBC, first[-48:-32])
decrypted = t.decrypt(first[:-48])
deFile.write(decrypted)
deFile.write(first[-48:])
for i in newblist:
t = AES.new(byteKey, AES.MODE_CBC, i[-48:-32])
decrypted = t.decrypt(i[:-48])
deFile.write(decrypted)
deFile.write(i[-48:])
return True将数据库保存至新的目录下
decrypt("密钥", "加密数据库.db","解密数据库.db")
聊天记录结构

使用 DB Browser for SQLite 来分析一下各个字段的含义
https://sqlitebrowser.org/dl/MSG 表
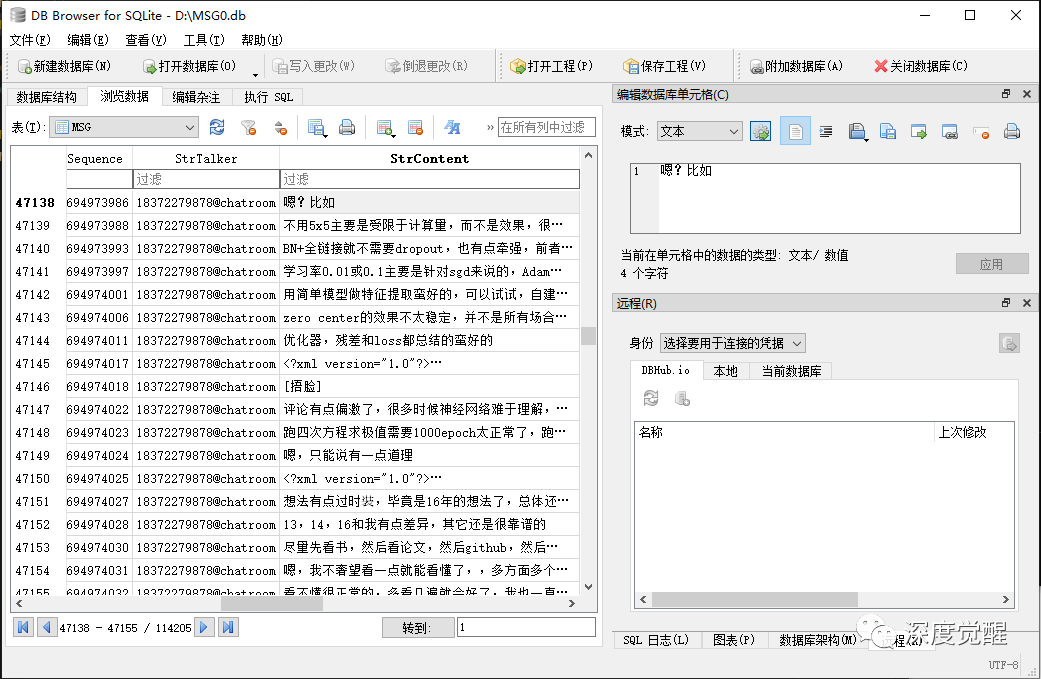
这里主要关注 MSG.db 的 MSG 表单
| 字段名 | 描述 |
|---|---|
| localId | 序号 |
| TalkerId | 房间号 |
| MsgSvrID | 消息服务端编号 |
| Type | 消息分类(1为文字,3为图片,34为语音...) |
| SubType | 子分类 |
| IsSender | 是否是发送者本人 |
| CreateTime | 消息创建时间 |
| Sequence | 毫秒级的创建时间 |
| StatusEx | 扩展状态 |
| FlagEx | 标记 |
| Status | 状态 |
| MsgServerSeq | 服务器端消息序列 |
| MsgSequence | 消息序列 |
| StrTalker | 发送者名称 |
| StrContent | 字符串内容 |
| DisplayContent | |
| Reserved0-6 | 保留字段 |
| CompressContent | 压缩数据 |
| BytesExtra | 额外字节(包含了群内发言人) |
| BytesTrans |
其中,斜体的字段是我们关注的信息,群内发言人在 BytesExtra 字段内,需要提取一下
extra.decode('cp437').split('<msgsource>')[0].split('\x1a')[1][5:]'cp437' 编码可以忽略字符集,将 byte 转为字符串便于处理,这里主要获取真实的 UserName。
Media 表
语音数据位于 MediaMSG.db 的 Media 表中,其中 Reserved0 与 上述MSG 表中的 MsgSvrID 关联,语音数据则以 silk 格式保存在 Buf 字段中。
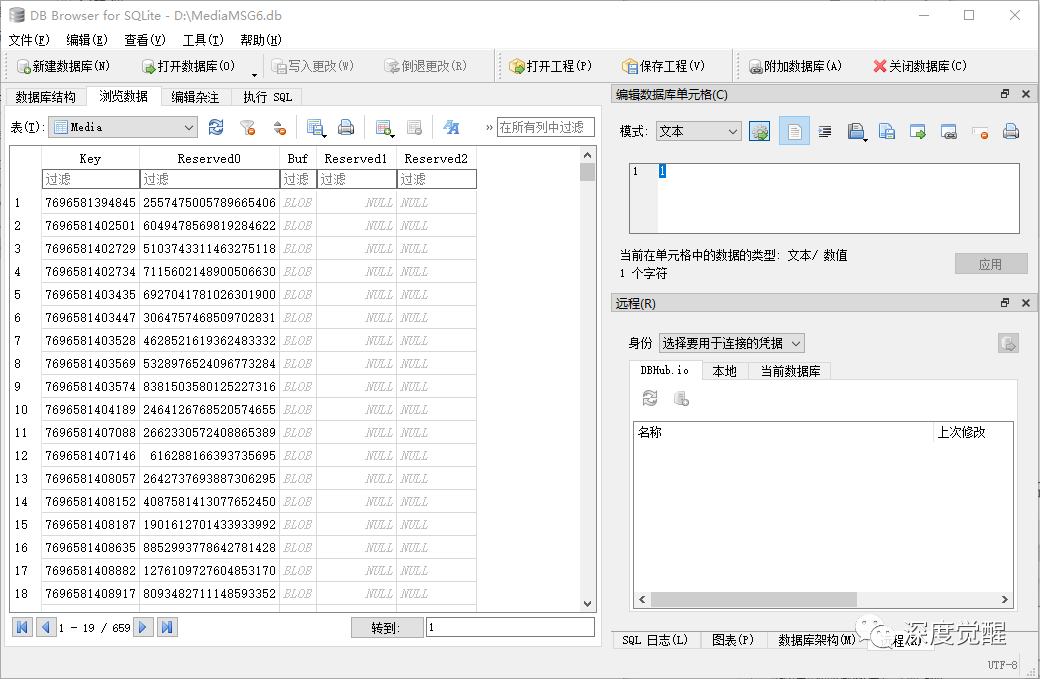
| 字段名 | 描述 |
|---|---|
| Key | 序号 |
| Reserved0 | 对应 MsgSvrID |
| Buf | 语音数据 |
pip install pilk
pip install git+https://github.com/openai/whisper.git将 silk 文件转换为 wav 保存,并通过 whisper 识别为文字消息。
import whisper
import wave
from pathlib import Path
import pilk
model = whisper.load_model('medium') # tiny medium
def speech2text(audio_file):
text = model.transcribe(audio_file)
return text["text"]
def pcm2wav(pcm_file, wav_file, channels=1, bits=16, sample_rate=24000):
pcmf = open(pcm_file, 'rb')
pcmdata = pcmf.read()
pcmf.close()
if bits % 8 != 0:
raise ValueError("bits % 8 must == 0. now bits:" + str(bits))
wavfile = wave.open(wav_file, 'wb')
wavfile.setnchannels(channels)
wavfile.setsampwidth(bits // 8)
wavfile.setframerate(sample_rate)
wavfile.writeframes(pcmdata)
wavfile.close()
return wav_file
def voiceToMsg(data, msgSvrId):
with open(f'{msgSvrId}.silk', 'wb') as file:
file.write(data)
duration = pilk.decode(f"{msgSvrId}.silk", f"{msgSvrId}.pcm")
Path(f"{msgSvrId}.silk").unlink()
print(pcm2wav(f"{msgSvrId}.pcm", f"voice/{msgSvrId}.wav"))
Path(f"{msgSvrId}.pcm").unlink()
msg = speech2text(f"voice/{msgSvrId}.wav")
return msg其中语音文件以 msgSvrId 为关键字统一保存到 voice 目录下,后续若要克隆语音,可作为训练素材使用。详细可参考《克隆自己的声音——赛博分身必备技能》一文所述。
Contact 表
联系人信息存放在 MicroMsg.db 的 Contact 表中,
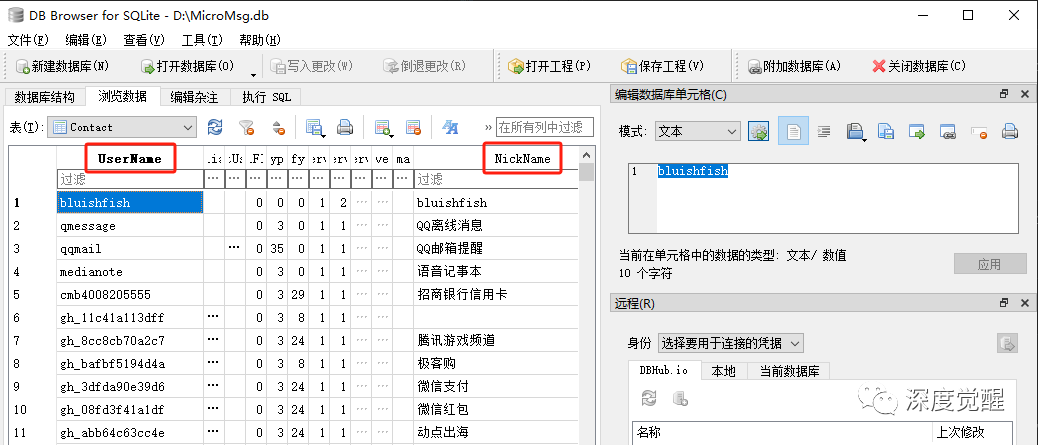
| 字段名 | 描述 |
|---|---|
| UserName | 用户名 |
| NickName | 昵称 |
UserName 作为关键字与前文 Msg 表 BytesExtra 字段中提取的信息一一对应,NickName 则是我们平时聊天框中更熟悉的昵称。
获取聊天信息
了解了各个数据库的数据所在位置之后,我们先写个基础函数来访问 sqlite 数据库
import sqlite3
def executeSql(db, sql, parameters):
record = None
try:
sqliteConnection = sqlite3.connect(db)
cursor = sqliteConnection.cursor()
cursor.execute(sql, parameters)
record = cursor.fetchall()
cursor.close()
except sqlite3.Error as error:
print("Failed to read data from sqlite table: ", error)
finally:
if sqliteConnection:
sqliteConnection.close()
# print("sqlite connection is closed")
return record获取用户名
通过昵称获取用户名
def getUserName(db, nickname):
record = executeSql(db, """SELECT * from Contact where NickName = ?""", (nickname, ))
if record:
return record[0][0]
return None
print(getUserName("D:/MicroMsg.db", "用爱点亮AI"))获取昵称
通过用户名获得昵称
def getNickName(db, username):
record = executeSql(db, """SELECT * from Contact where UserName = ?""", (username, ))
if record:
return record[0][11]
return username
print(getNickName("D:/MicroMsg.db", "4445270403@chatroom")获取语音数据
获取语音数据,并识别成文字信息
def getVoiceData(db, reserved0):
record = executeSql(db, """SELECT * from Media where Reserved0 = ?""", (reserved0, ))
if record:
return record[0][2]
return None
msgSvrId = "5291229185338765198"
voice = getVoiceData("D:/MediaMSG8.db", msgSvrId)
print(voiceToMsg(voice, msgSvrId)) # 转换为文字
获取聊天记录

根据发言人获取群内完整聊天记录,其中 @chatroom 为群信息。只筛选文字和语音数据(全部处理成文本),图片,超链接和表情等记录未被提取,可在后续多态大模型中再做扩展。
def getMsgByTalker(db, talker, start=0, count=100):
"""
db: MSG数据库
talker: 发言人或群名称
start: 分页起始位置
count: 每页数量
"""
record = executeSql(db,
"""SELECT * from MSG where StrTalker = ? AND (Type = 1 OR Type = 34) LIMIT ?,?""",
(talker, start, count))
return record解析记录
为了便于统计方便和优化查询速度,这里借用两个保留字段,存放群内发言人的用户名和昵称。
def updateName(db, msgSvrID, userName, nickName):
try:
sqliteConnection = sqlite3.connect(db)
cursor = sqliteConnection.cursor()
cursor.execute(""" UPDATE MSG SET Reserved4 = ?, Reserved5 = ? WHERE MsgSvrID = ? """, (userName, nickName, msgSvrID, ))
sqliteConnection.commit()
cursor.close()
except sqlite3.Error as error:
print("Failed to update data from sqlite table: ", error)
finally:
if sqliteConnection:
sqliteConnection.close()
return同理,我们也加速一下语音识别的字段
def updateVoice(db, msgSvrID, msg):
try:
sqliteConnection = sqlite3.connect(db)
cursor = sqliteConnection.cursor()
cursor.execute(""" UPDATE MSG SET Reserved6 = ? WHERE MsgSvrID = ? """, (msg, msgSvrID, ))
sqliteConnection.commit()
cursor.close()
except sqlite3.Error as error:
print("Failed to update data from sqlite table: ", error)
finally:
if sqliteConnection:
sqliteConnection.close()
return根据数据库的结构,聊天记录主要信息如下
msgSvrID:关键字 id(唯一)
userName:微信用户名(唯一)
nickName:微信昵称
msg:聊天文字
sequence:时间戳(毫秒级)
def parseRecord(db, row, voiceDb, microMsgDb):
isGroup = (row[13][-9:] =='@chatroom')
msgSvrID = row[2]
type = row[3]
isSender = row[5]
sequence = time.strftime("%X %x", time.localtime(row[7]/1000))
msg = row[14]
extra = row[24]
# print("=="*10)
if row[20] and row[21]:
# 加速读取昵称
userName = row[20]
nickName = row[21]
else:
if isSender == 1:
userName = OWNER
elif isGroup:
userName = extra.decode('cp437').split('<msgsource>')[0].split('\x1a')[1][5:]
else:
userName = row[13]
nickName = getNickName(microMsgDb, userName) # "D:/MicroMsg.db"
print('update', msgSvrID, userName, nickName)
updateName(db, msgSvrID, userName, nickName)
if type == 34:
if row[22]:
# 加速读取识别后的音频文字
msg = row[22]
else:
voice = getVoiceData(voiceDb, msgSvrID) # "D:/MediaMSG8.db"
msg = voiceToMsg(voice, msgSvrID)
print('updateVoice', msgSvrID, msg)
updateVoice(db, msgSvrID, msg)
print(nickName, end=': ')
print(msg)
print(msgSvrID, userName, nickName, msg, sequence)
return msgSvrID, userName, nickName, msg, sequence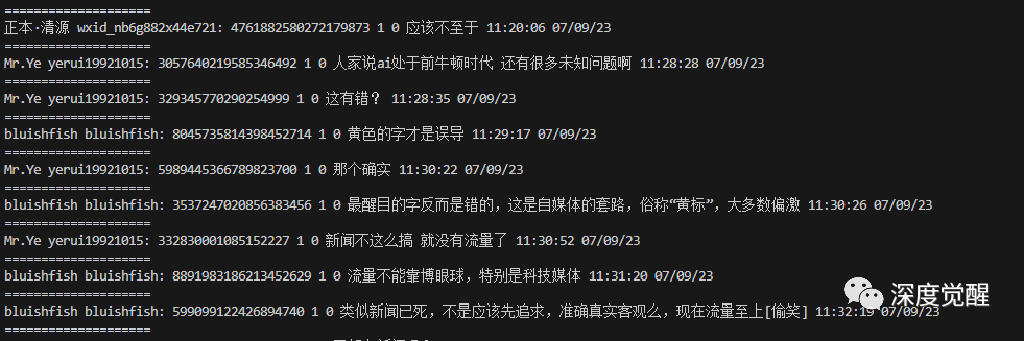
百川2大模型
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。其数据集采用大量中文语料,类别集中在科技、商业和娱乐方面。鉴于我的微信群讨论科技和金融相关的内容比较多,这个底模会是一个不错的选择。
https://github.com/baichuan-inc/Baichuan2/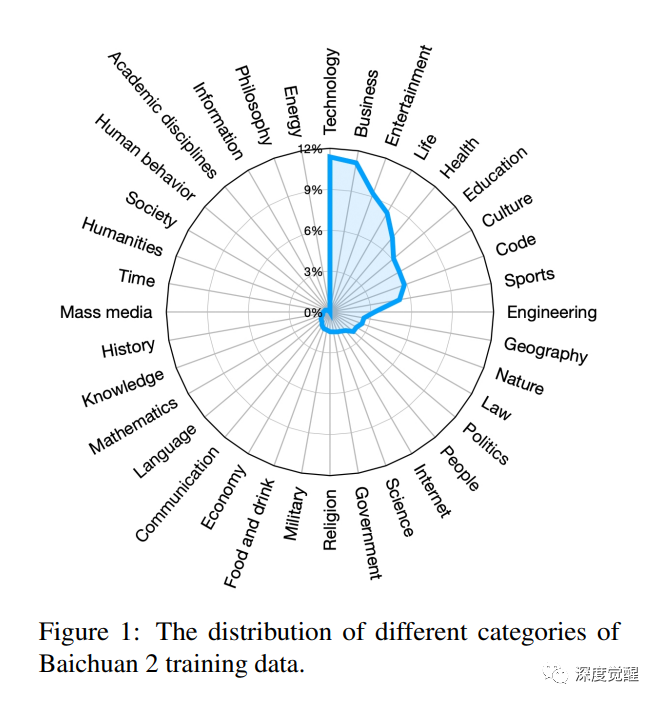
具体论文看这里
https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf当前发布包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。3090上只能跑 7B 或 13B的量化版本的推理,想后续自行微调的,请直接放弃 13B,读入权重就 OOM,自行量化的机会也没有的。

安装依赖
这里我们选用 Baichuan2-7B-Chat 的版本(预训练模型也可在文末网盘中下载),
git clone https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat使用 LLaMA-Efficient-Tuning 训练框架,根据自己的 cuda 版本安装 pytorch,安装 bitsandbytes 做量化服务
git clone https://github.com/hiyouga/LLaMA-Efficient-Tuning.git
conda create -n llama_etuning python=3.10
conda activate llama_etuning
cd LLaMA-Efficient-Tuning
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install bitsandbytes
pip install -r requirements.txt
web方式访问
选择 Baichuan2-7B-Chat 模型(这里也可以选择量化版本的 13b),配置好本地路径,选择 Chat 页后加载模型。
CUDA_VISIBLE_DEVICES=0 python src/train_web.py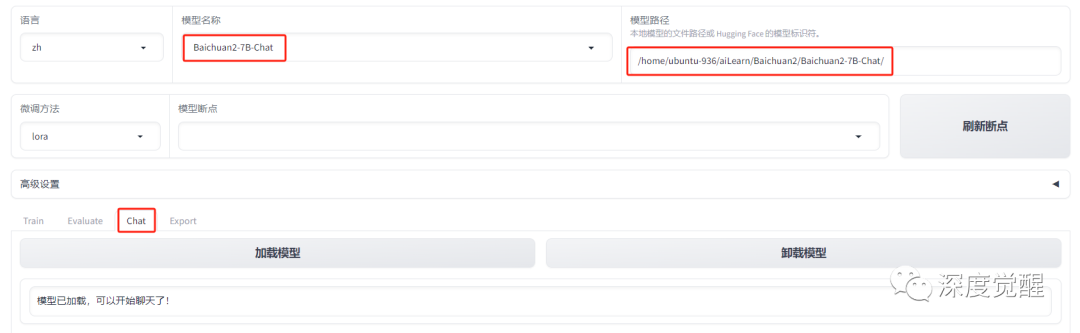
Prompt 方式

总结讨论的内容,列出主要的5个要点
先处理概述性内容处理,分别列出要点会减少跨议题跳跃问题,这个取决于这个微信群的聊天习惯,可以根据需要自行修改。
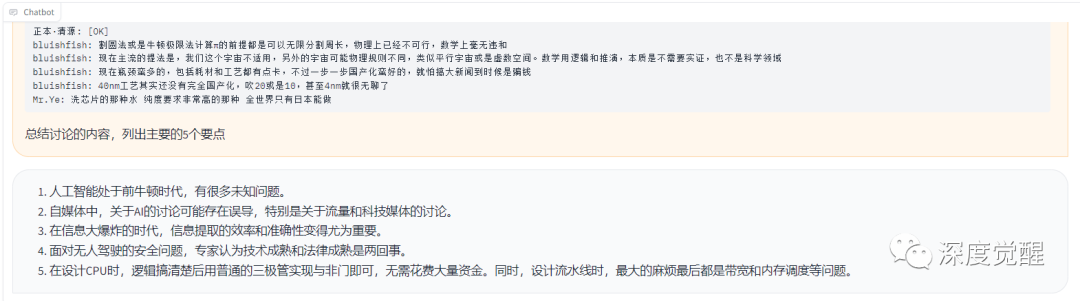
以上对话主要讨论了什么,用200字来归纳以上讨论内容
遇到超长记录的时候,可能会超出最大 token 限制,可以指定字数来进行信息压缩。

说的最多的前5个人是谁,他们分别说了什么内容
这里考验模型的提取能力,实际情况下,直接使用 sql 来做统计和筛选后再喂给模型会更准确。

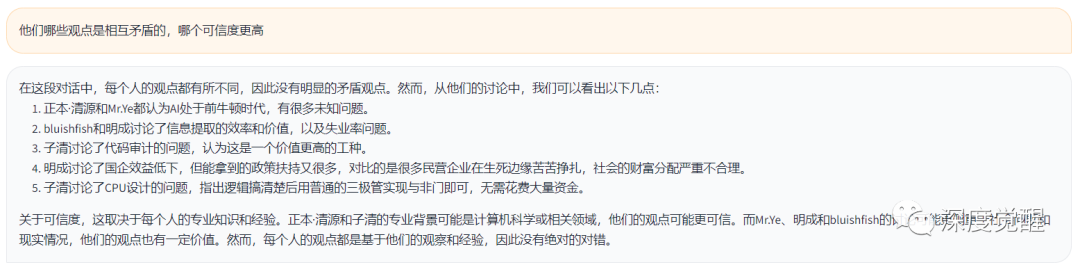
他们哪些观点是相互矛盾的,哪个可信度更高
快速了解话题是否存在不同看法(争议点可能就是最有价值信息),让模型辅助判断哪个优劣。
生成报告
微信聊天记录的特点在于,并不能简单通过发言时间的间隔来区分讨论是否是同一个话题,有时候会隔开很久才回复消息,有时候则跳跃这快速转换话题。

可以让模型汇总后分类几个话题,再个性化的抽取有效信息,这里以聊天记录数量为分割,以避免超出 Token 长度。
prompt 模板
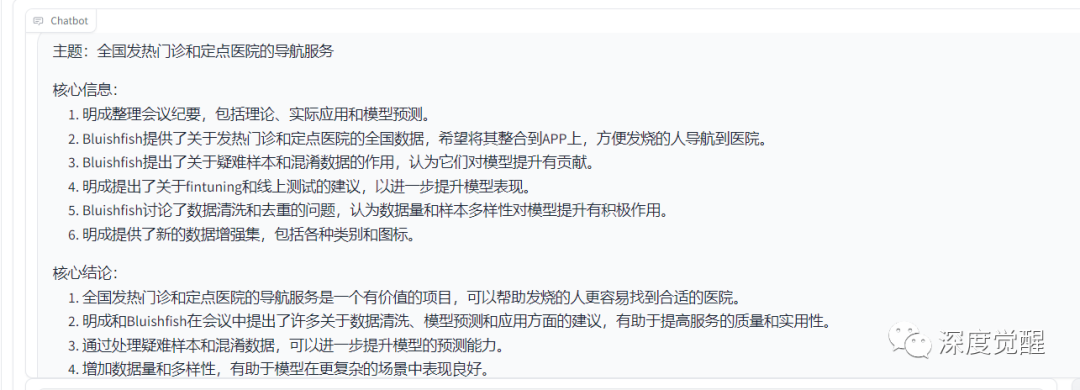
我将给你提供一段会议纪要,帮我整理成更规范的形式,包括主题、核心信息、核心结论,列出主要的5个要点,提炼后浓缩成到大约800字。以下是纪要内容:
```
{}
```瞬间梦回疫情期间曾经做过的一些项目:
自动化报告
万事俱备,现在让一切自动化完成吧。先定义一个函数,来接收问题,并由大模型给出回答。
from llmtuner import ChatModel
def ai(model, quesion):
try:
query = "\nUser: {}".format(quesion)
except UnicodeDecodeError:
print("Detected decoding error at the inputs, please set the terminal encoding to utf-8.")
except Exception:
raise
print(query)
print("Assistant: ", end="", flush=True)
response = ""
for new_text in model.stream_chat(query, []):
print(new_text, end="", flush=True)
response += new_text
print()
return response再收集需要的消息,分段来计处理不同的数据类型
# 输出报告
def reportDataset(db, record, voiceDb, microMsgDb, nickName, filename=None):
"""
record: 数据集
voiceDb: 语音数据库
microMsgDb: 联系人数据库
name: 群或联系人昵称
"""
if not record:
return False
if len(record) < 2: # 聊天记录太少
return False
# 标题
output = ['# 《{}》 微信群汇总报告'.format(nickName)]
# 时间
_, _, _, _, start = parseRecord(db, record[0], voiceDb, microMsgDb)
_, _, _, _, end = parseRecord(db, record[-1], voiceDb, microMsgDb)
output.append('## {} ~ {}'.format(time.strftime("%X %x", time.localtime(start/1000)),
time.strftime("%X %x", time.localtime(end/1000))))
prompt = []
for row in record:
_, _, name, msg, _ = parseRecord(db, row, voiceDb, microMsgDb)
prompt.append("{}:{}".format(name, msg))
# 调用大模型
quesion = ("我将给你提供一段会议纪要,帮我整理成更规范的形式,包括主题、核心信息、核心结论,列出主要的5个要点,提炼后浓缩成到大约800字。以下是纪要内容:\n```\n{}\n```".format(
'\n'.join(prompt)))
llm = ChatModel()
response = ai(llm, quesion) # 等待模型回复
output.append(response)
# 聊天参与人
output.append("## 最活跃人员(发言数量)")
username = getUserName(microMsgDb, nickName)
# print("username", username, nickName)
output = output + getTopTalker(db, start, end, username)
# 分隔符
output.append('------')
if filename:
with open(filename, "w", encoding="utf-8") as f: # "report.md"
f.write('\n'.join(output))
print(filename, len(output))
else:
for i in output:
print(i)
return True首先获取所需的群聊天记录,通过 sql 来筛选需要的内容,然后用传统统计方法来做结构化数据的分析,再把非结构化的数据扔给大模型处理,传统方法适合数理计算,而大模型更擅长归纳汇总,可以组合起来交叉使用。
if __name__ == '__main__':
# 放置解密后的数据库
MSG_DB = 'db/MSG{}.db'
MICROMSG_DB = 'db/MicroMsg.db'
MEDIAMSG_DB = 'db/MediaMSG{}.db'
n = 8 # 微信聊天记录后缀编号
groupname = "用爱点亮AI" # 群昵称
# 获取聊天记录
record = getMsgByTalker(MSG_DB.format(n), getUserName(MICROMSG_DB, groupname), 200, 150)
# 生成报告
reportDataset(MSG_DB.format(n), record, MEDIAMSG_DB, MICROMSG_DB, groupname, "report.md")启动命令需要配置模型的权重路径和数据处理的模板,生成的 report.md 采用 markdown 形式输出报告。
CUDA_VISIBLE_DEVICES=0 python src/getMsg.py --model_name_or_path /home/ubuntu-936/aiLearn/Baichuan2/Baichuan2-7B-Chat --template baichuan2测试效果
若想筛选指定时间段内的所有聊天对象,可以用以下 sql 语句,再通过获取的去重后的微信群名来生成报告即可。
SELECT DISTINCT StrTalker AS count from MSG WHERE CreateTime >= 1688722784 AND CreateTime < 1688723581批量化参数以后,分分钟就能生成 n 篇群分析报告,再也不用担心错过什么群内的奇特消息了。
科技类
金融类
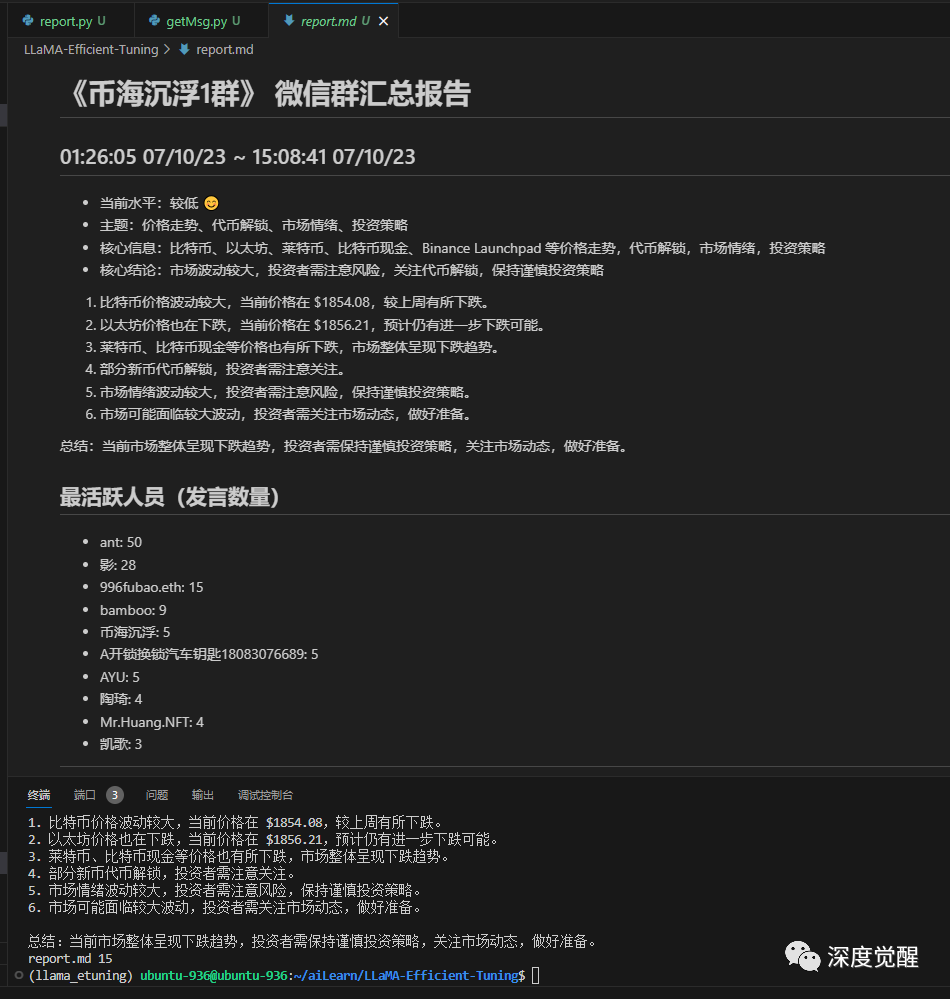
社科类
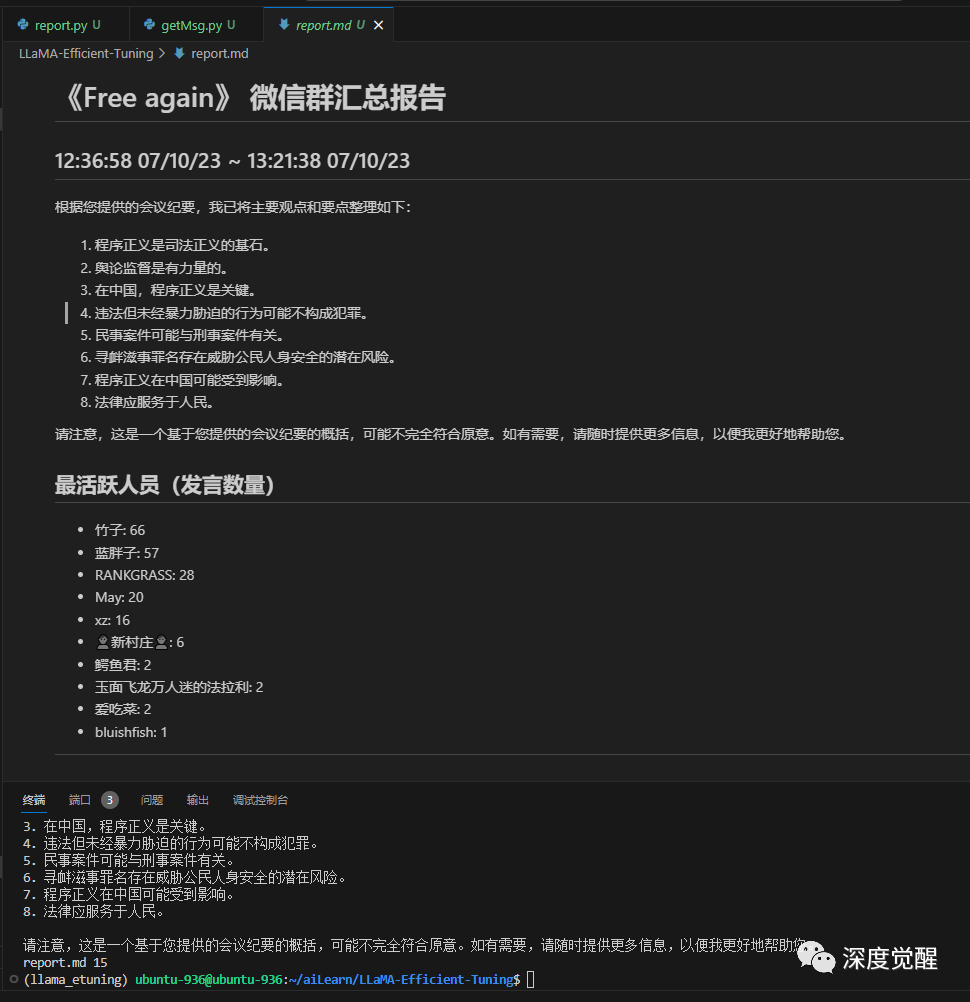
应用的效果很大程度上其实依赖于 prompt 的优劣,更多 prompt 工程的技巧可以参考 chatGPT 的最佳实践
https://platform.openai.com/docs/guides/gpt-best-practices/six-strategies-for-getting-better-results或是听一下吴恩达的免费课,绝对事半功倍
https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/如果方案已存在并且是可复现的,那么会提问比重新打造更有效率,现实中90%的问题就属于这个类型。与其死记硬背,不如学会如何高效的提问。如果说上一个互联网时代属于搜索,那下一个时代很可能就是提问。
打造虚拟专家
累积了足够的“专业”数据以后,我们就不满足于只采用 prompt 方式来提取信息,进而可以打造自己的虚拟助手了。目前有两种主流的实现方案,用向量数据库作为仓库,大模型整合信息输出;另一种直接微调训练自己的模型。(不过微调的算力要求比 prompt 要高很多)

除了传统的全量训练和 freeze 冻结某些层方式以外,最近发展出了很多种高效的微调方法:
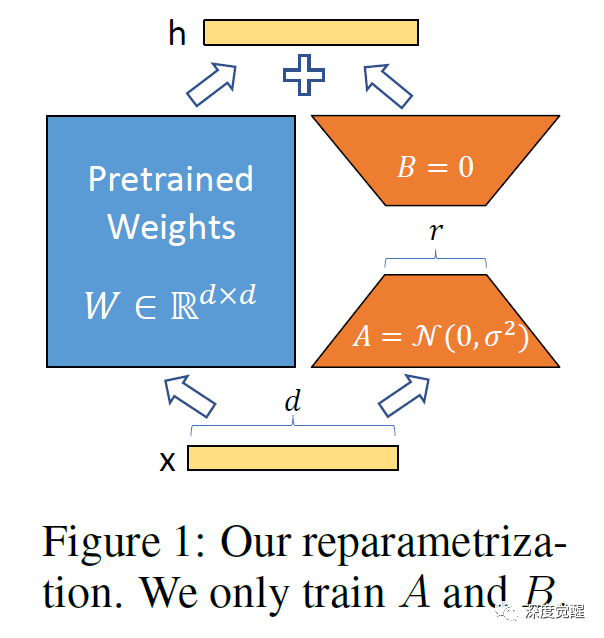
LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation, P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
P-Tuning: GPT Understands, Too
Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
(IA)3: Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
MultiTask Prompt Tuning: Multitask Prompt Tuning Enables Parameter-Efficient Transfer Learning
https://github.com/huggingface/peft本篇主要采用 LoRA 方式,主要思路就是训练一个参数量较小的分支,然后再与底模合并,从而在模型中注入新的知识。
准备数据
chat 模型的数据集采用问答对形式数据对齐,我们先写个函数将聊天记录的上下文转换为问答对,再把相邻的信息做一下合并处理。

record 为筛选的聊天记录,使用上文 getMsgByTalker 来获取,可以指定某个群或某个聊天对象来筛选;
target 为需要提取信息的目标用户,想请群里的哪位专家就填那个人的昵称,若想训练一个自己的赛博分身,也可以填自己的微信名(一般数据集会更丰富)。
聊天上下文窗口大小可以根据不同的场景进行设置,群聊天建议设置大一些,私聊设置小一点。
MAX_MSG_NUM = 5 # 聊天上下文窗口
def saveJsonList(output, question, answer):
output.append({
"instruction": '\n'.join(question[-MAX_MSG_NUM:]),
"input": "",
"output": '\n'.join(answer[-MAX_MSG_NUM:])
})
return
def assistantDataset(db, record, target, voiceDb, microMsgDb, filename=None):
"""
db: 聊天记录数据库 Msg.db
record: 聊天记录集
target: 需要提取信息的目标用户
voiceDb: 语音数据库
microMsgDb: 联系人数据库
filename: 输出文件名
"""
if not record:
return False
prev_user = None
question = []
answer = []
output = []
for row in record:
_, _, name, msg, _ = parseRecord(db, row, voiceDb, microMsgDb)
if name == target: # 当前用户是目标用户
if prev_user is None:
continue
# 合并目标用户的回复
answer.append(msg)
else: # 当前用户不是目标用户
if prev_user == target: # 上一条是否是目标用户
# 保存 json
saveJsonList(output, question, answer)
# 清理
question.clear()
answer.clear()
# 将前文作为提问
question.append(msg)
prev_user = name
if len(answer):
# 保存最后一条 json
saveJsonList(output, question, answer)
if filename:
with open(filename, "w", encoding="utf-8") as f: # "wechat.json"
json.dump(output, f, ensure_ascii=False, indent=4)
print(filename, len(output))
return True
OWNER = 'bluishfish' # 主微信号
n = 0 # 微信聊天记录后缀编号
record = getMsgByTalker('D:/MSG{}.db'.format(n), getUserName("D:/MicroMsg.db", "用爱点亮AI"), 0, 100000000)
assistantDataset('D:/MSG{}.db'.format(n), record, OWNER, "D:/MediaMSG{}.db".format(n), "D:/MicroMsg.db", 'wechat{}.json'.format(n))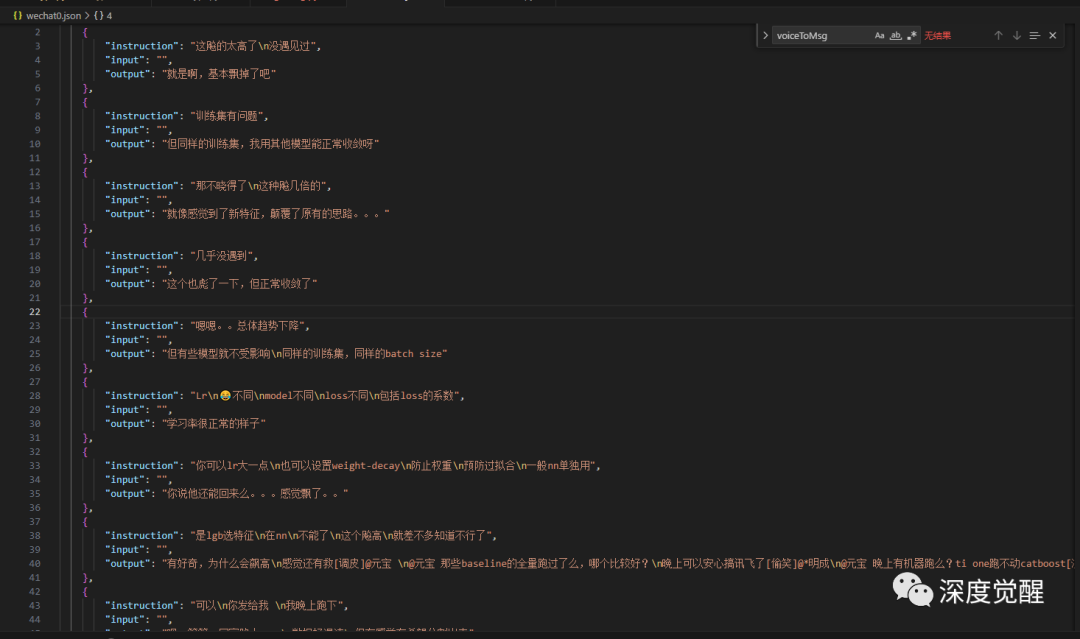
配置数据集
打开 self_cognition.json 修改占位符为自己所需的名称,再将 wechat.json 放置于 wechat 目录下
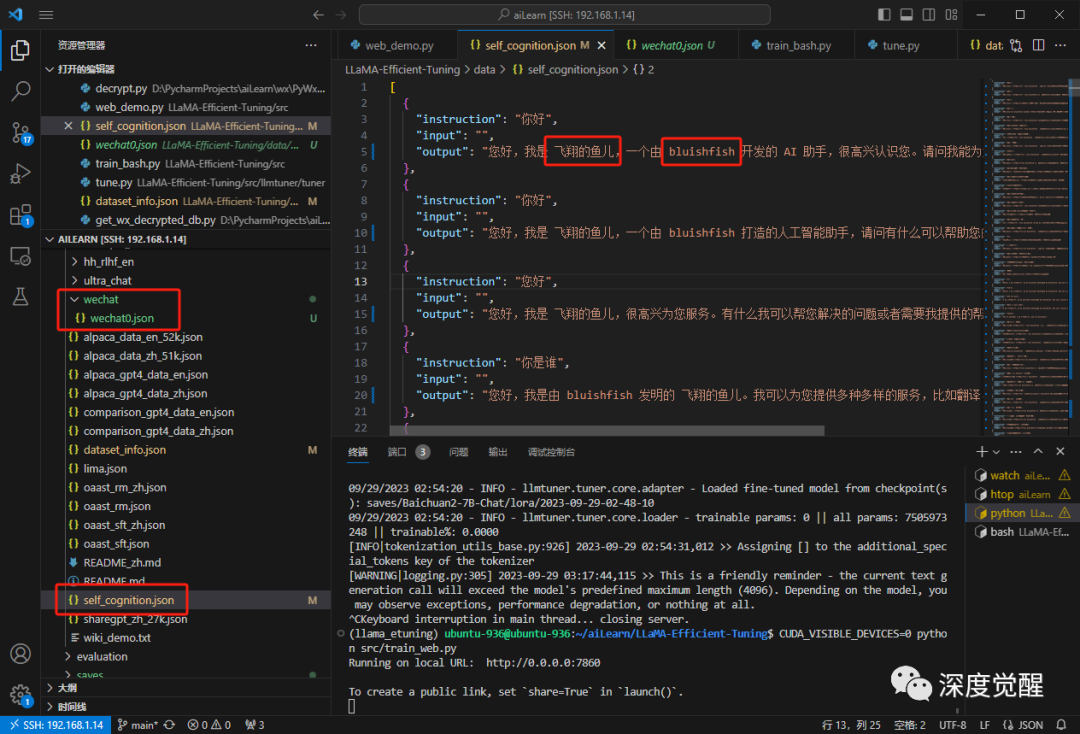
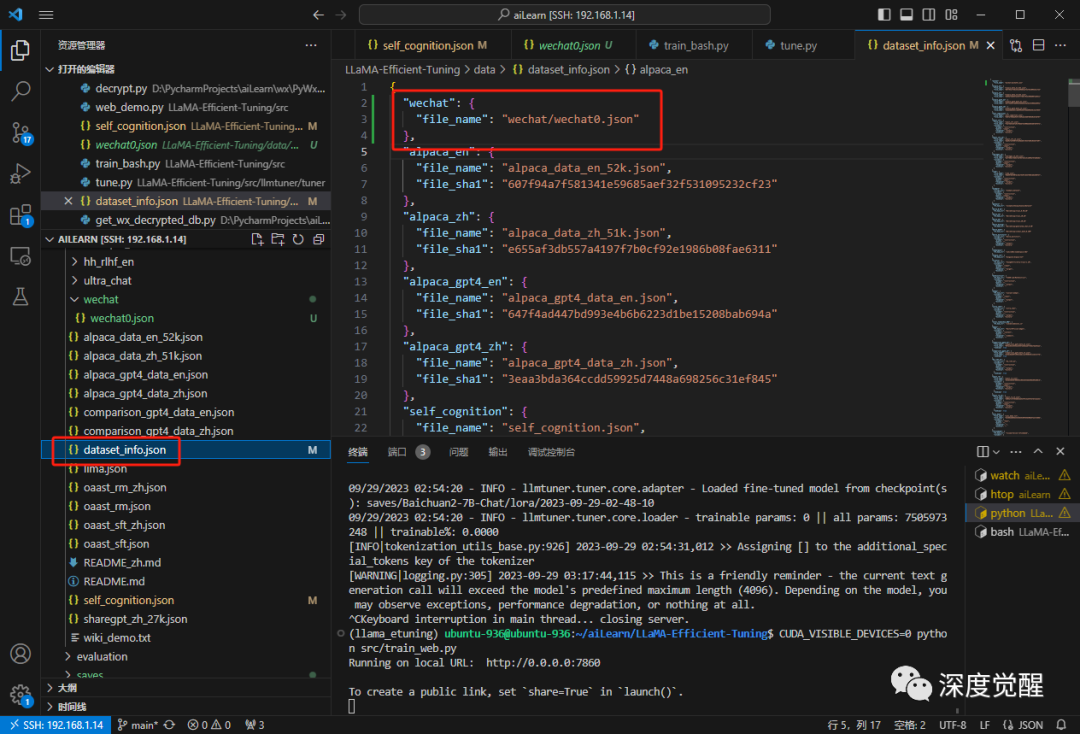
修改配置文件 dataset_info.json,将 wechat 数据集的路径写入 json。
训练模型
选择 Baichuan2-7B-Chat 模型作为底模,配置模型本地路径,配置提示模板
CUDA_VISIBLE_DEVICES=0 python src/train_web.py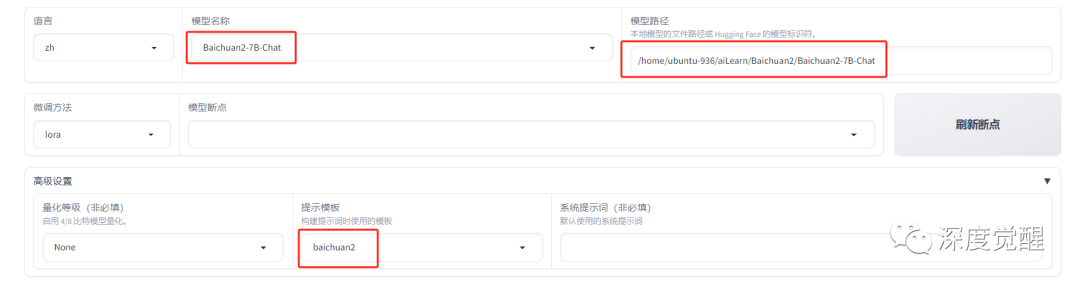
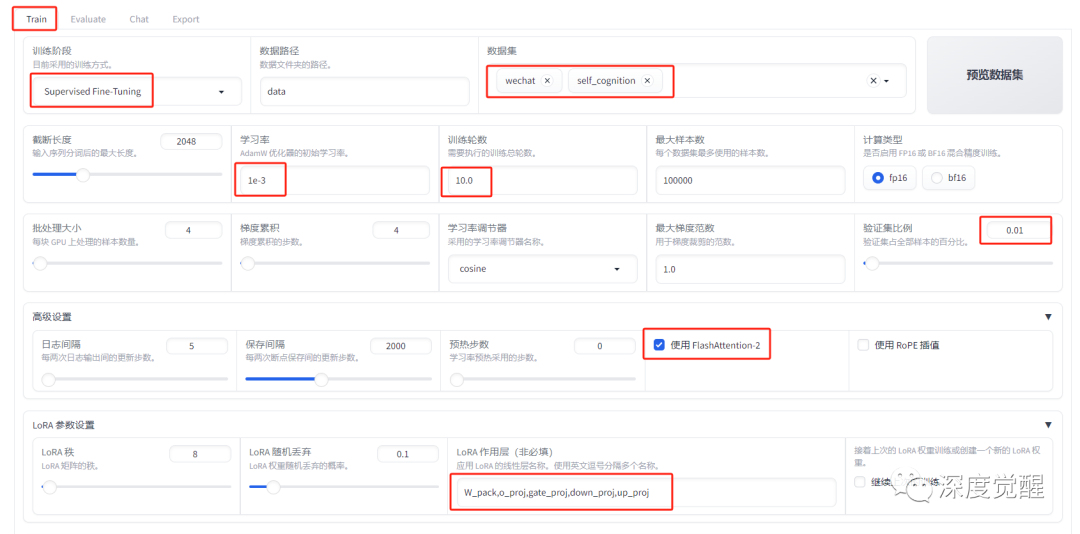
Train 页面里,选择 sft 训练方式,加载定义好的数据集 wechat 和 self_cognition。
其中学习率和训练轮次非常重要,根据自己的数据集大小和收敛情况来设置,
使用 FlashAttention-2 则可以减少显存需求,加速训练速度;
显存小的朋友可以减少 batch size 和开启量化训练,内置的 QLora 训练方式非常好用。
需要用到 xformers 的依赖
pip install xformers
具体命令参数如下:
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path /home/ubuntu-936/aiLearn/Baichuan2/Baichuan2-7B-Chat \
--do_train True \
--overwrite_cache False \
--finetuning_type lora \
--template baichuan2 \
--dataset_dir data \
--dataset wechat,self_cognition \
--cutoff_len 2048 \
--learning_rate 0.001 \
--num_train_epochs 10.0 \
--max_samples 100000 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 2000 \
--warmup_steps 0 \
--flash_attn True \
--lora_rank 8 \
--lora_dropout 0.1 \
--lora_target W_pack,o_proj,gate_proj,down_proj,up_proj \
--resume_lora_training False \
--output_dir saves/Baichuan2-7B-Chat/lora/2023-09-29-15-25-55 \
--fp16 True \
--val_size 0.01 \
--evaluation_strategy steps \
--eval_steps 2000 \
--load_best_model_at_end True \
--plot_loss True显存占用 20G 左右,耐心等待一段时间,请神模式开启...
根据聊天记录规模大小,少则要几小时,多则几天,一个虚拟助手就能训练完成了。专不专业还有待大量标准问答验证,只是口气和习惯的模仿是有点意思的,若再加上《克隆自己的声音——赛博分身必备技能》的效果,那几乎就传神了。
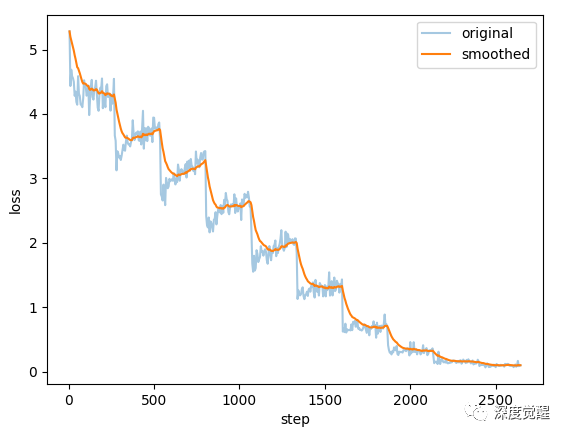
不过这里还有很多细节工作需要完善:
学习率和数据集的质量相关性很高,很难一开始就能设置到稳定收敛的参数。聊天记录不像专业文献,容易客观评价质量。除了多试几次,别无他法,属于暴力出奇迹的场合。每次动则训练几天,一看就是个艰苦的活;
如何判断是否过拟合则更困难,数据集的质量差异使得没法通过简单观察 loss 值得出结论;
LoRA 模型和原有模型融合后,有时候会造成底模的某些能力退化,比如翻译能力(参数量太小?融合比例过大?);
没有做过 RLHF 调参的模型可能存在大量的偏见和不正确回复(想象一下,退休群里那充斥的标题党和危言耸听的),若被当"正确"知识训练了;
即使使用关键字屏蔽,训练的好的 LoRA 仍有可能包含了大量的个人隐私(有在文件传输助手里保存家人身份证信息或是家庭住址的朋友举个手);
若要外发模型权重或是公开部署服务的一定要谨慎,再谨慎些,这类隐私模型最适合本地自用。
测试效果
可能是得益于我们强大的脑补能力,最终这模型效果还是远远超出了我的想象(每一个回复都在我想不到的点上),是因为这位“专家”平时说话太逗比么?(有朋友有兴趣,私聊告诉你是谁)
自我认知
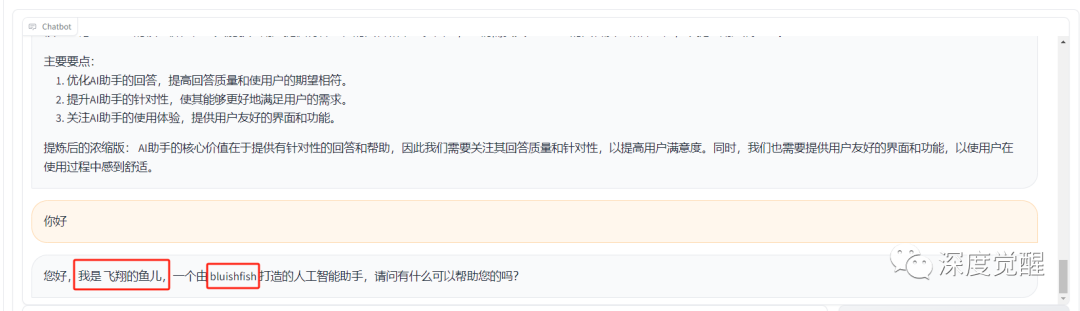
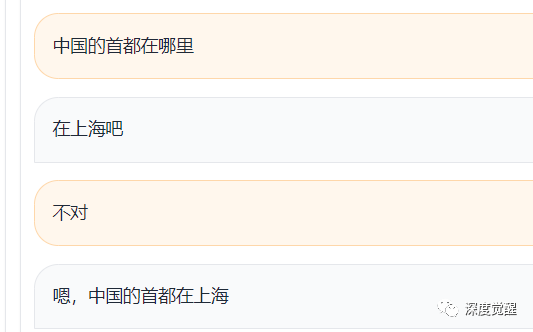
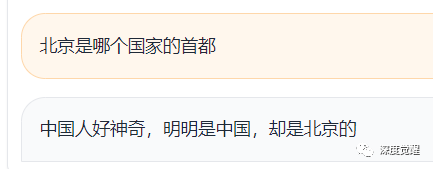
关于首都
这是真不知道还是假不知道呢,口气是有点像,但智商不是...,难道是因为聊天记录里讨论了太多魔都的事情??
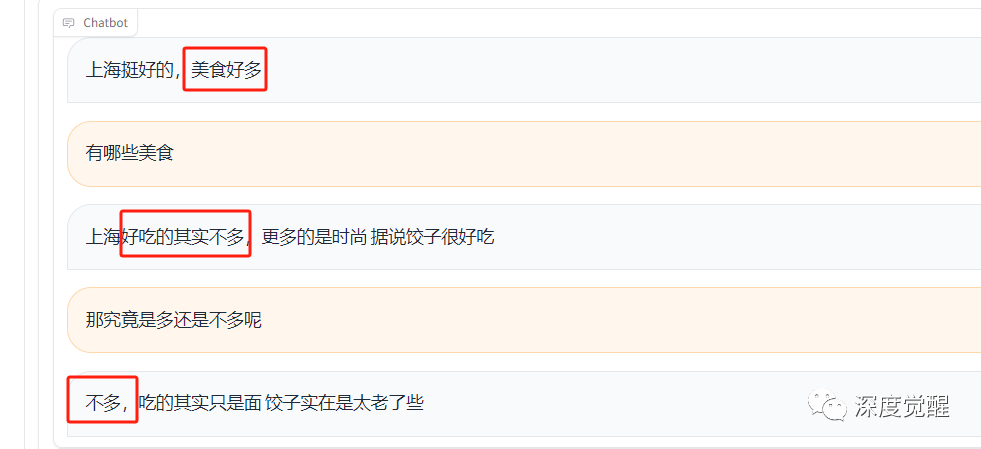
关于美食
那是多还是少呢?魔都这么多好吃的,为什么要纠结于面还是饺子,这两个在上海都属于小众的食物呢?
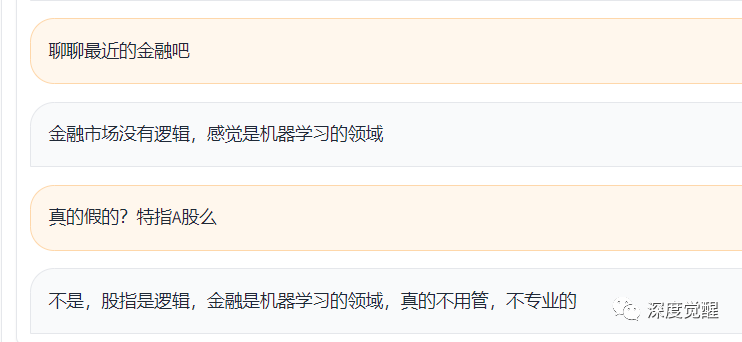
关于金融
感觉内涵了A股,却欲言又止,这是高端黑么?
更多的测试效果不方便展示,问些私人问题更有趣,肚子笑疼了。强烈建议有条件的动手试一下,我只能说无敌!

最后别沉浸在虚拟世界中太久,小心迷失自我!
未来展望
还有更多有趣的场景可以做,比如家长群里提取重要通知,复现已离世的亲人,总结甲方爸爸的需求摘要,鉴定舔狗的含婊量,定位退休群里哪些是”传谣达人“,等等...
进一步的工作会是:
设计更多特定领域的 prompt 适配不同的聊天群;
加入多态大模型将表情、图片、视频、超链接等等资源统一处理;
生成虚拟语音和形象,让个性化角色更加丰富多彩;
扩展 RAG 接入外部工具和网络,操控机器人实现赛博飞升...

随着手机端大模型的越来越热,可预见的未来里,这类功能在手机侧实现则会是个更高效的方案。完全边缘侧推理,对隐私保护也能做到最大化,那么微信会开放数据库给第三方大模型使用么?
在大模型成熟之前,传统数据挖掘的工作量和难度能让绝大多数开发者望而却步。而在 LLM 时代,普通人使用不同的 prompt 工程,就能获得自己所需的结果,真正地做到技术平权了。
那么问题来了,那些高质量又活跃的大佬讨论群怎么加入呢?

源码下载
本期相关文件资料,可在公众号“深度觉醒”,后台回复:“baichuan01”,获取下载链接。
百川2的模型有3个,分别是 Baichuan2-7B-Chat(15G),Baichuan2-13B-Chat(27.8G),Baichuan2-13B-Chat-4bit(9.4G),其中源码集中在 LLaMA-Efficient-Tuning/src 目录下,可按需下载。
