1. Motivation
尽管大型视觉-语言模型(LVLMs)在图像理解和推理任务上(例如,物体的存在和计数、定位、物体之间的比较,以及识别物体的属性)表现出色,但在细粒度物体分类(例如区分不同动物种类)方面(fine-grained object classification)的能力尚未得到充分测试,尽管这对于下游任务非常重要。并且 现有的评估基准主要测试LVLMs的图像理解和推理能力,而很少考虑细粒度物体分类这一独立技能。
2. Contribution
- 指出目前对LVLM的评估中,对 细粒度物体分类 的探究的不足,尽管(细粒度)对象分类任务很重要。
- 作者解决了如下问题: (i) 对于具有上下文学习能力(in-context learning)的模型在few-shot object classification 任务上进行评估时,模型不是单独对图像进行分类,而是将目标图像与标记的上下文示例进行比较 (2)Pali 虽然在 ImageNet 数据集上测评LVLM,但是是通过对每个类标签进行评分来进行评估,这在计算上是昂贵的。(3)LVLM-e-Hub 也评估了 一些图像分类数据集(如 ImageNet),但他们将其制定为开放式 QA 任务,预期答案含糊不清,这导致所有模型的准确度分数较低。(4)在知识密集型 VQA 中,模型必须识别正确的对象(例如特定建筑物)才能正确回答;当使用知识库检索相关信息时,对象可以隐式识别(QA 模型需要知道哪个对象才能正确回答)或显式识别
- 基于此,作者创建了一个名为
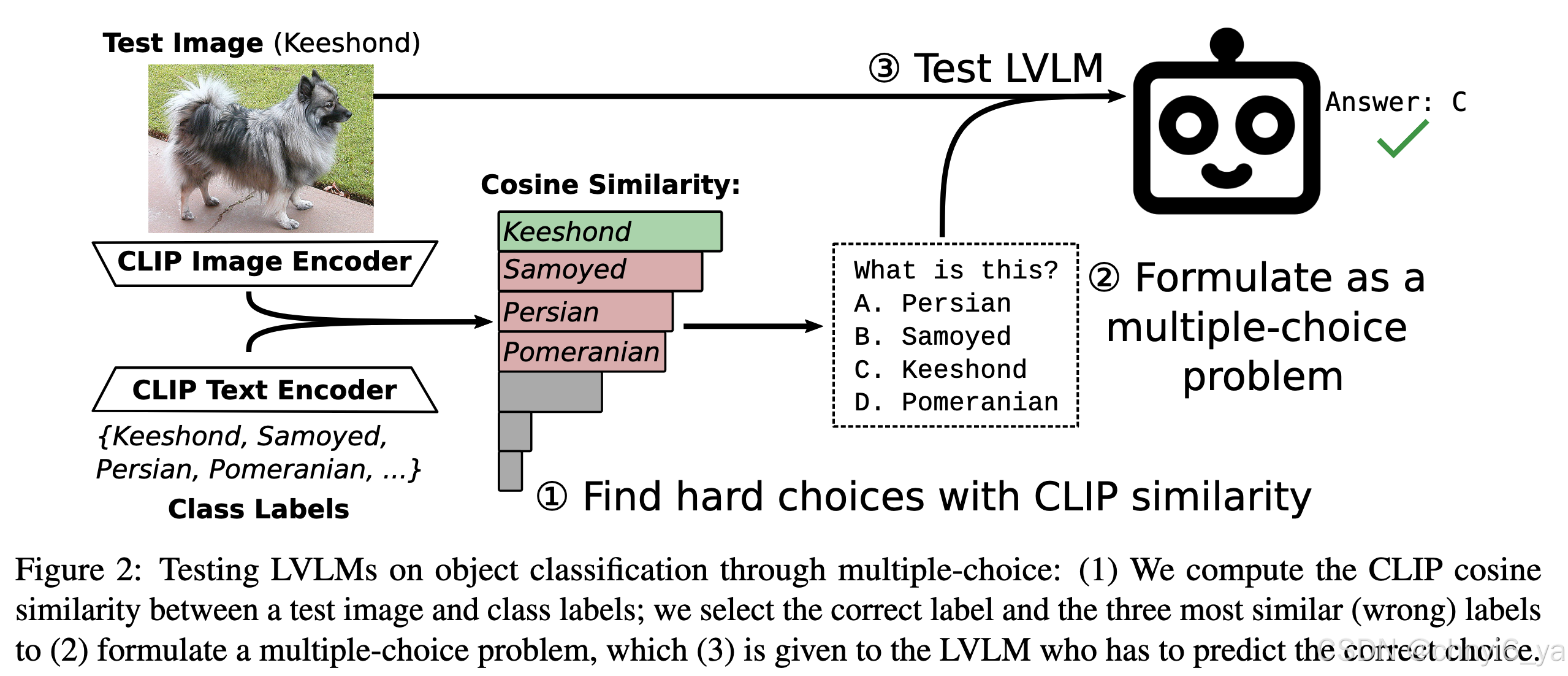
FOCI(Fine-grained Object Classification)的multi-choice基准,用于评估细粒度物体分类任务。 - 该方法,我们在零样本配置中使用
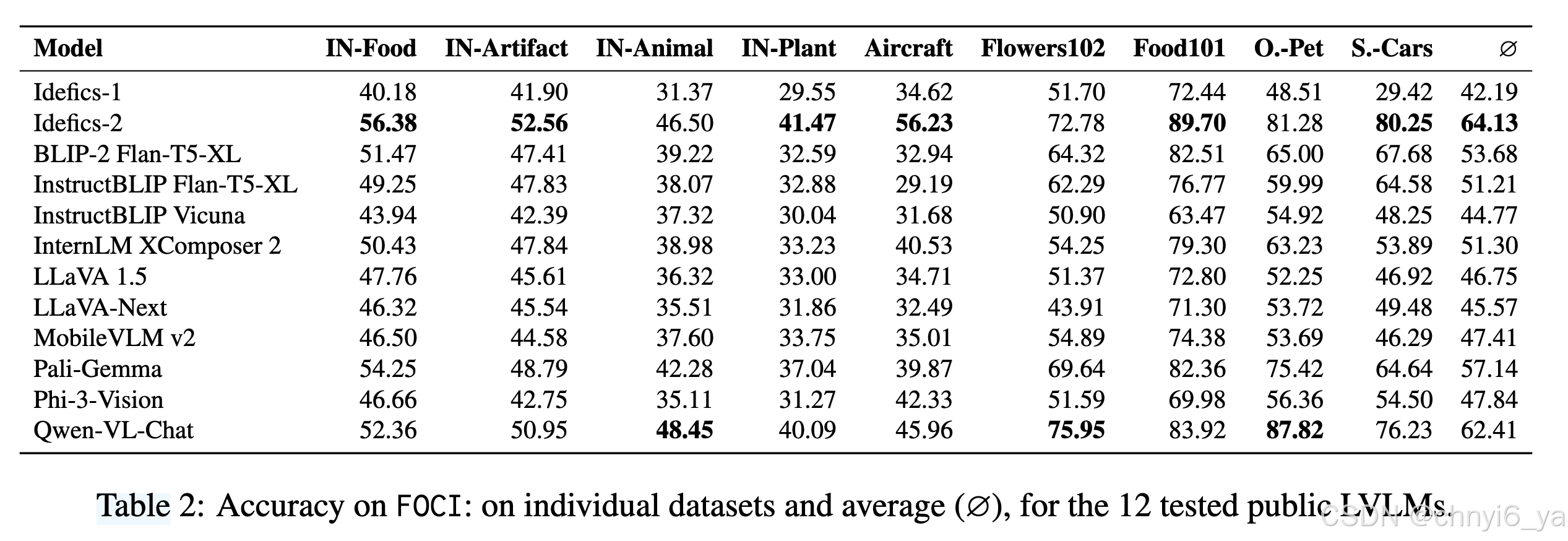
CLIP从类标签池中挖掘困难的选择。作者从不同领域(花卉、汽车、食品、飞机、宠物)的 5 个流行分类数据集组装了 FOCI,并另外从 ImageNet-21k中为动物、植物、食品和人类创建了 4 个领域子集。接着在FOCI基准上评估了12个公开的LVLMs,并展示了这些模型在这方面的表现。并且发现,CLIP模型在细粒度物体分类上的表现明显优于LVLMs,尽管 LVLM 的图像编码器来自这些 CLIP 模型。这表明LVLMs的图像编码器和语言模型(LLM)之间的对齐可能不够精细。
3. Method
对于每个示例图像,选择三个最相似(不正确)的类标签作为否定选择。使用标准 CLIP 零样本设置对图像的数据集类别进行排名:文本编码器嵌入所有类标签,图像编码器嵌入图像,并且类标签按照其各自文本嵌入的余弦相似度降序排列图像嵌入。通过选择 OpenCLIP ViT-L/14 来避免在评估中偏向任何具体 LVLM,因为其图像编码器尚未被任何 LVLM 使用。
4. Evaluating Public LVLMs
FGVC-Aircraft 包含 100 种不同飞机类型的图像; Flowers102 包含 102 种不同花卉的图像; Food101涵盖 101 种菜肴; Oxford-Pet包含 37 个猫和狗品种的图像。 Stanley-Cars涵盖 196 种汽车型号。
IN- 表示 ImageNet
5. 观察到的现象
1. CLIP zero-shot下的分类性能是LVLM 分类性能的上限(upper bound)
作者分别测评了LVLM 和 LVLM中使用的clip在 FOCI 上的结果,发现LVLM 性能始终低于相应的 CLIP 模型。如图三:
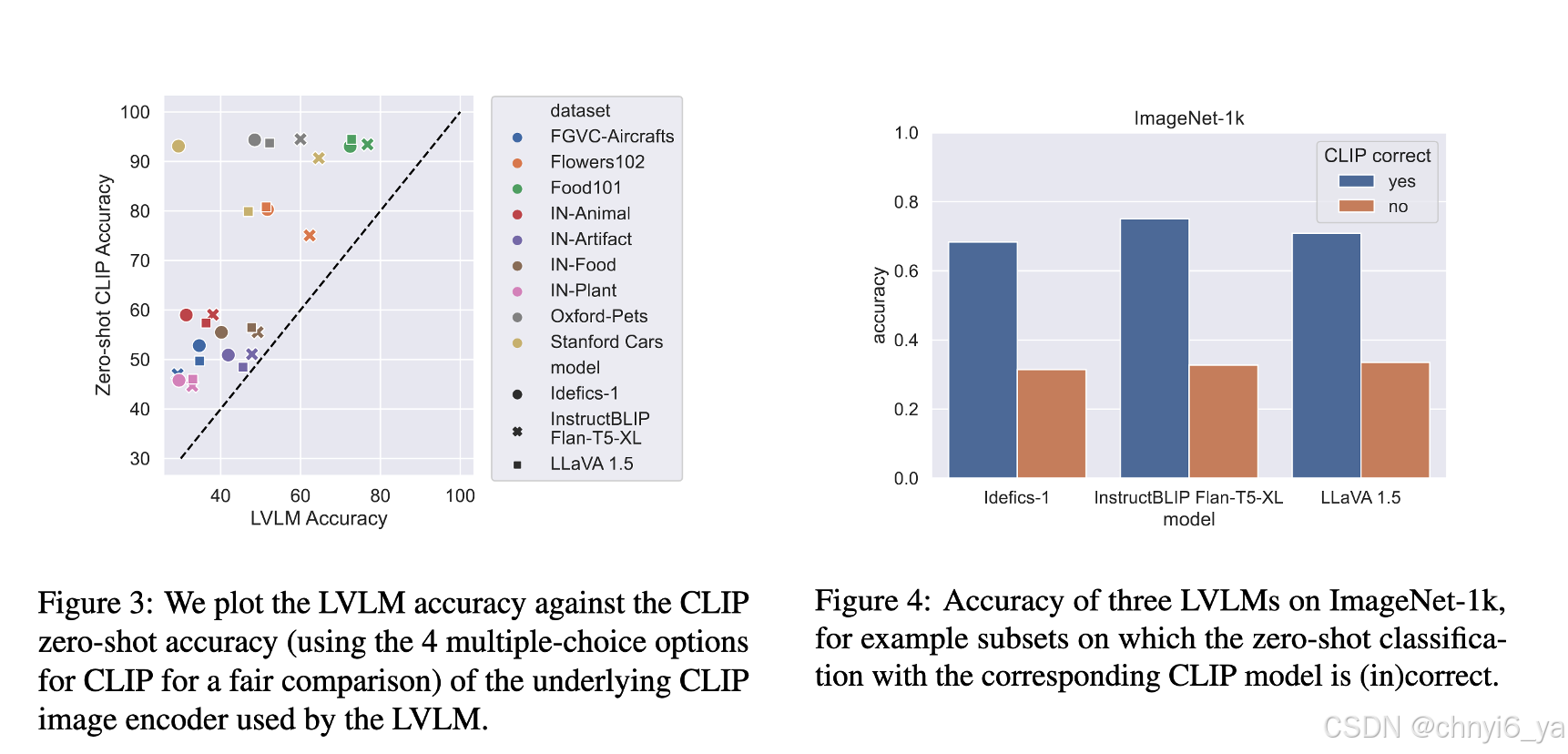
2. CLIP wrong ⇒ LVLM wrong
作者观察到 如果 CLIP 模型错误,使用其图像编码器的 LVLM 是否也会对图像进行错误分类。 图 4 总结了针对三个 LVLM 对 ImageNet-1k的分析结果;作者观察到,在相应 CLIP 失败的示例中,LVLM 准确度直线下降:事实上,对于 CLIP 无法正确分类的示例,对于分析中的所有三个 LVLM,相应 LVLM 的性能接近随机 (25%)。这些观察结果(CLIP 性能是 LVLM 精度的上限,并且其错误会传播到 LVLM)突出表明图像编码器的选择是 LVLM 性能的关键设计决策,并表明图像编码的未来改进也可能会传播LVLM 对象识别功能。
6. Controlled Experiments
接下来,作者进行一组控制实验,以阐明各个 LVLM 设计选择对(细粒度)对象分类的影响。分析涵盖三个主要因素:(1) LLM 大小,(2) 图像编码器,以及 (3) 对训练数据的有针对性的更改。对于 (2) 和 (3),作者按照 LLaVA 1.5 配方训练 LVLM,使用 StableLM 2 Zephyr 1.6B作为 LLM,使用 OpenAI CLIP-L/14-224 作为image encoder。
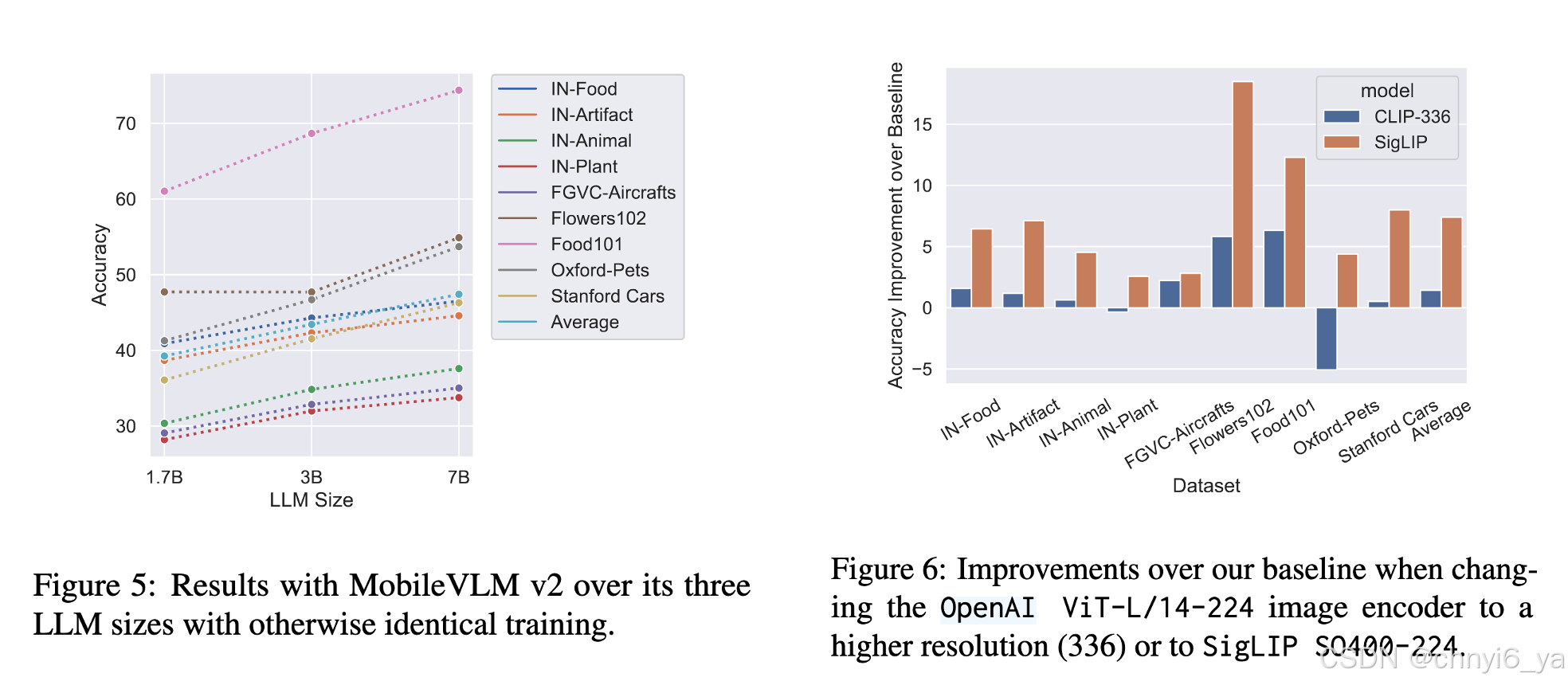
1. LLM size
随着 LLM 规模的增加,所有 FOCI 数据集的性能都会持续提高,如图5。作者认为这是因为较小的LLM 只能编码较少的世界知识并且对object的语义表达较差
2. Image encoder
一方面,以更高分辨率对图像进行编码(使用 CLIP-336,即从 224 像素增加到 336 像素)仅导致边缘 ∼1 准确度点增益(在所有 FOCI 数据集上平均)。效果似乎取决于对象类型:我们看到 Flowers102 和 Food102 增加了超过 5 点,但 Oxford-Pets 也下降了 5 点。
另一方面,SigLIP 编码器极大地全面提高了基线性能。然而,基于 SigLIP 的 LVLM 相对于基线 LVLM(CLIP-224 编码器)的绝对增益与相应的 SigLIP CLIP 模型在零样本对象分类中相对于 CLIP-224 产生的增益不成比例。如图6.
3. Training data
作者假设更大的预训练语料库有利于 LVLM,因为在相应的标题中明确命名的对象更多。作者通过用 ImageNet-1k 训练分割中的图像替换 25% 的 LLaVA 560k 预训练图像(带标题)来明确测试这一点。
为了获得保留的控制集,只使用 1000 个类中的 500 个(每隔一个类选择一次)进行训练;我们为每个类别选择 280 张图像(总共 140k 训练样本)。考虑针对添加的 ImageNet 图像的三种训练策略:
i) 使用 BLIP 生成的合成标题;此设置测试带有对象但带有不一定命名它们的标题的图像的效果(例如,对于毛狮犬的图像,BLIP 生成的标题可能包含“狗”,但不包含“毛狮犬”)
ii) 带有模板标题(Template),例如“$label 的图片。”;此类标题不是视觉描述性的,而是明确命名图像中的对象。
iii)完全跳过预训练阶段(无预训练)并在随机初始化的对齐模块上执行任务混合训练;
结果
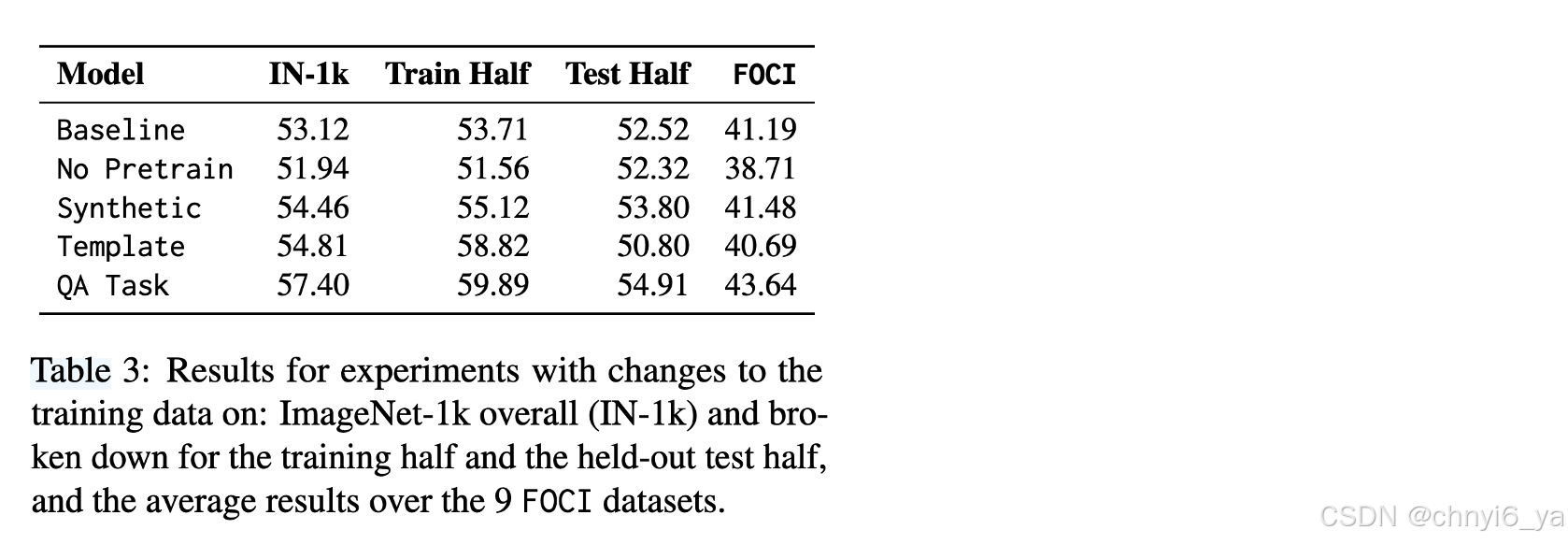
- 完全跳过预训练步骤(无预训练)会将平均 FOCI 性能降低超过 2 个精度点:这表明图像-文本对上的对齐模块的预训练对于细粒度对象分类非常重要
- 明确提及标题中的对象是学习对齐模块的关键,该模块允许 LVLM 更好地进行细粒度对象分类;仅拥有包含该对象的图像是不够的(或者至少效率较低)