- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
电脑环境:
语言环境:Python 3.8.0
一、代码流程
1、导入包,设置GPU
import torch.nn.functional as F
import torch.nn as nn
import torch
import numpy as np
import pandas as pd
2、导入数据
data = pd.read_csv('woodpine2.csv')
data
Time Tem1 CO 1 Soot 1
0 0.000 25.0 0.000000 0.000000
1 0.228 25.0 0.000000 0.000000
2 0.456 25.0 0.000000 0.000000
3 0.685 25.0 0.000000 0.000000
4 0.913 25.0 0.000000 0.000000
... ... ... ... ...
5943 366.000 295.0 0.000077 0.000496
5944 366.000 294.0 0.000077 0.000494
5945 367.000 292.0 0.000077 0.000491
5946 367.000 291.0 0.000076 0.000489
5947 367.000 290.0 0.000076 0.000487
5948 rows × 4 columns
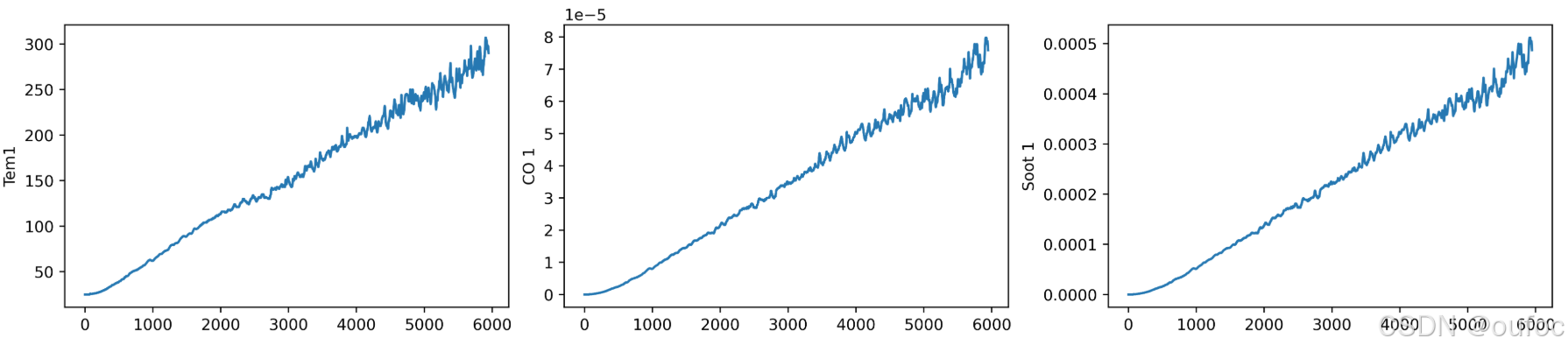
3、数据集可视化
from os import confstr_names
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['figure.dpi'] = 500
plt.rcParams['savefig.dpi'] = 500
fig, ax = plt.subplots(1, 3, constrained_layout=True, figsize=(14, 3))
sns.lineplot(data=data['Tem1'], ax=ax[0])
sns.lineplot(data=data['CO 1'], ax=ax[1])
sns.lineplot(data=data['Soot 1'], ax=ax[2])
plt.show()
dataFrame = data.iloc[:, 1:]
dataFrame
4、数据集预处理
from sklearn.preprocessing import MinMaxScaler
dataFrame = data.iloc[:, 1:].copy()
scaler = MinMaxScaler(feature_range=(0, 1))
for i in ['CO 1', 'Soot 1', 'Tem1']:
dataFrame[i] = scaler.fit_transform(dataFrame[i].values.reshape(-1, 1))
dataFrame.shape
(5948, 3)
5、设置X,y
width_X = 8
width_Y = 1
X = []
y = []
in_start = 0
for _, _ in data.iterrows():
in_end = in_start + width_X
out_end = in_end + width_Y
if out_end < len(dataFrame):
X_ = np.array(dataFrame.iloc[in_start:in_end, :])
y_ = np.array(dataFrame.iloc[in_end:out_end, :])
X.append(X_)
y.append(y_)
in_start += 1
X = np.array(X)
y = np.array(y)
X.shape, y.shape
((5939, 8, 3), (5939, 1, 1))
检查数据集中是否有空值
print(np.any(np.isnan(X)))
print(np.any(np.isnan(y)))
6、划分数据集
X_train = torch.tensor(np.array(X[:5000]), dtype=torch.float32)
y_train = torch.tensor(np.array(y[:5000]), dtype=torch. float32)
X_test = torch.tensor(np.array(X[5000:]), dtype=torch.float32)
y_test = torch.tensor(np.array(y[5000:]), dtype=torch. float32)
X_train.shape, y_train.shape
(torch.Size([5000, 8, 3]), torch.Size([5000, 1, 3]))
from torch.utils.data import TensorDataset, DataLoader
train_dl = DataLoader(TensorDataset(X_train, y_train),
batch_size=64,
shuffle=False)
test_dl = DataLoader(TensorDataset(X_test, y_test),
batch_size=64,
shuffle=False)
7、构建模型
class model_lstm(nn.Module):
def __init__(self):
super(model_lstm, self).__init__()
self.lstm0 = nn.LSTM(input_size=3, hidden_size=320,
num_layers=1, batch_first=True)
self.lstm1 = nn.LSTM(input_size=320, hidden_size=320,
num_layers=1, batch_first=True)
self.fc0 = nn.Linear(320, 1)
def forward(self, x):
out, hidden1 = self.lstm0(x)
out, _ = self. lstm1(out, hidden1)
out = self.fc0(out)
return out[:, -1:, :]
#取2个预测值,否则经过1stm会得到8*2个预
model = model_lstm()
model
8、定义训练函数
import copy
def train(train_dl, model, loss_fn, opt, lr_scheduler=None) :
size = len(train_dl.dataset)
num_batches = len(train_dl)
train_loss = 0 #初始化训练损失和正确率
for x, y in train_dl:
x, y = x.to(device), y.to(device)
#计算预测误差
pred = model(x) #网络输出
loss = loss_fn(pred, y) #计算网络输出和真实值之间的差距
# 反向传播
opt.zero_grad()#grad属性归零
loss.backward()# 反向传播
opt.step()# 每一步自动更新
#记录Loss
train_loss += loss. item()
if lr_scheduler is not None:
lr_scheduler.step()
print ("learning rate = {:.5f}". format(opt.param_groups[0]['lr']), end=' ')
train_loss /= num_batches
return train_loss
9、定义测试函数
def test (dataloader, model, loss_fn) :
size = len(dataloader.dataset) #测试集的大小
num_batches = len(dataloader)# 批次数目
test_loss = 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
# 计算loss
y_pred = model(x)
loss = loss_fn(y_pred, y)
test_loss += loss.item()
test_loss /= num_batches
return test_loss
10、正式训练
# 设置GPU训练
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
#训练模型
model = model_lstm()
model = model.to(device)
loss_fn = nn.MSELoss() #创建损失函数
learn_rate = 1e-1 #学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate, weight_decay=1e-4)
epochs = 50
train_loss = []
test_loss = []
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt, epochs, last_epoch=-1)
for epoch in range(epochs):
model.train()
epoch_train_loss = train(train_dl, model, loss_fn, opt, lr_scheduler)
model.eval()
epoch_test_loss = test(test_dl, model, loss_fn)
train_loss.append(epoch_train_loss)
test_loss.append(epoch_test_loss)
template = ('Epoch: {:2d}, Train loss: {:.5f}, Test loss: {:.5f}')
print(template.format(epoch+1, epoch_train_loss,epoch_test_loss))
print("="*20, 'Done', "="*70)
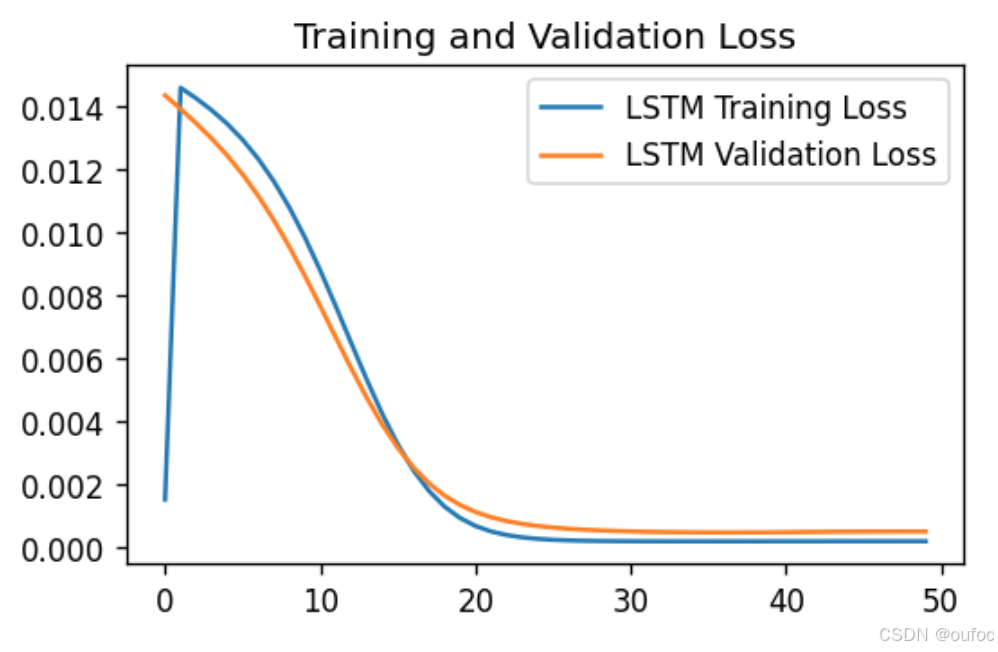
11、模型评估- LOSS图
import matplotlib.pyplot as plt
plt. figure(figsize=(5, 3), dpi=120)
plt.plot(train_loss, label='LSTM Training Loss')
plt.plot(test_loss, label='LSTM Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
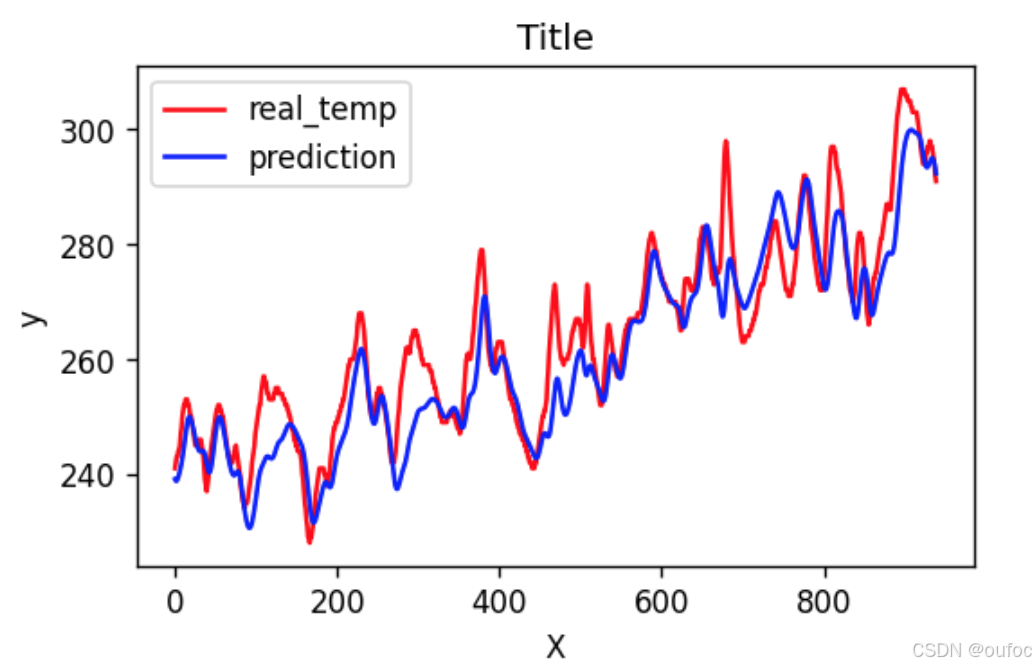
12、调用模型进行训练
predicted_y_lstm = sc.inverse_transform(model(X_test).detach().numpy().reshape(-1,1))
y_test_1 = sc.inverse_transform(y_test.reshape(-1,1))
y_test_one = [i[0] for i in y_test_1]
predicted_y_lstm_one = [i[0] for i in predicted_y_lstm]
plt.figure(figsize=(5, 3) , dpi=120)
# 画出真实数据和预测数据的对比曲线
plt.plot(y_test_one[:2000], color='red', label='real_temp')
plt.plot(predicted_y_lstm_one[:2000], color='blue', label='prediction')
plt.title('Title')
plt.xlabel('X')
plt.ylabel('y')
plt.legend ()
plt.show( )
from sklearn import metrics
'''
RMSE:均方根误差--->对均方误差开方
R2:决定系数,可以简单理解为反映模型拟合优度的重要的统计量
'''
RMSE_lstm = metrics.mean_squared_error(predicted_y_lstm_one, y_test_1)**0.5
R2_lstm = metrics.r2_score(predicted_y_lstm_one, y_test_1)
print('均方根误差:%.5f' % RMSE_lstm)
print('R2: %.5f' % R2_lstm)
均方根误差:7.01314
R2: 0.82595