jina-embeddings-v3: Multilingual Embeddings With Task LoRA

Abstract
作者介绍了 jina-embeddings-v3,这是一种具有 5.7 亿个参数的新文本嵌入模型,在多语言数据和长上下文检索任务上实现了最先进的性能,支持高达 8192 个 token 的上下文长度。该模型包括一组任务特定的低秩适应 (LoRA) 适配器,能够生成用于查询-文档检索、聚类、分类和文本匹配的高质量嵌入。在 MTEB 基准测试中的评估表明,jina-embeddings-v3 在英语任务上优于 OpenAI 和 Cohere 的最新专有嵌入,同时在所有多语言任务上相较 multilingual-e5-large-instruct 取得了更优的表现。通过 Matryoshka 表示学习,默认输出维度为 1024,用户可以灵活地将嵌入维度减少至 32,而不会影响性能。
1 Introduction
文本嵌入模型将文档表示为高维向量,将文档之间的语义关系转换为向量之间的空间关系。这些模型是神经信息检索的基础,并已广泛应用于 NLP 和 IR 研究与应用的各个领域。文本嵌入被用于各种下游任务,例如分类、检索和聚类。值得注意的是,它们在构建检索增强生成(RAG)系统方面获得了显著的关注,在这些系统中,它们作为检索步骤中的主要技术。
传统嵌入模型的一个主要限制是,尽管被称为通用模型,但它们通常需要针对特定任务进行微调 [Jiao et al., 2020],并且经常遇到常见的失败案例 [Gao et al., 2021]。为了解决这个问题,最近的研究越来越关注利用大语言模型(LLM)作为通用嵌入生成的主干,利用它们高效处理多语言和多任务的能力 [Jiang et al., 2024]。然而,由于模型规模通常达到 70 亿个参数,在实际应用中部署这些模型面临着巨大的挑战。此外,与仅使用编码器的嵌入模型相比,基于 LLM 的嵌入在评估指标上略有改进,使得它们在许多用例中并不是太实用的选择。
该文介绍了 jina-embeddings-v3,这是一种具有 5.7 亿个参数的新文本嵌入模型,针对多语言数据、长上下文检索和跨多个任务的高性能进行了优化。在 MTEB 基准测试中的评估表明,jina-embeddings-v3 不仅显著改进了其前身 jina-embeddings-v2 [Günther et al., 2023] 及其双语变体 [Mohr et al., 2024],还在英语任务中超越了 OpenAI 和 Cohere 的最新专有嵌入模型,同时在所有多语言任务中超越了 multilingual-e5-large-instruct。另外,与基于 LLM 的嵌入模型(例如 e5-mistral-7b-instruct,其参数规模为71亿,大小是 jina-embeddings-v3 的12倍,输出维度为4096,是其4倍,但在 MTEB 英语任务上仅提供1%的提升)相比,jina-embeddings-v3 是一种更具成本效益的解决方案,使其更适合生产和边缘计算。该文的主要贡献是:
• 使用 LoRA 进行任务特定的优化:作者证明 LoRA 适配器[Hu et al., 2021] 有效地生成任务特定的嵌入,优于以前基于指令的方法。
• 使用合成数据修复检索失败:定性分析确定了四种常见的检索失败类型。作者通过引入合成训练数据来缓解这些问题,从而提高模型在边缘情况下的鲁棒性。
• 最新技术的集成:作者的模型融合了多个关键的技术进展,包括 Matryoshka 表示学习 [Kusupati et al., 2022]、指令调整 [Wei et al., 2022, Su et al., 2023] 和长上下文检索 [Günther et al., 2023]。
第 2 节概述了与该文目标相关的以前研究。第 3 节详细介绍了 jina-embeddings-v3 的架构。第 4 节描述了训练过程。在第 5 节中,作者进行了全面的多语言评估,包括消融研究,深入探讨了架构和训练决策的影响。
2 Related Work
2.1 General Text Embeddings
近年来,文本嵌入领域取得了显著进展,这很大程度上是由于基于 Transformer 的预训练语言模型的出现所推动的,这些模型能够有效地捕捉语言的底层语义 [Devlin et al., 2019]。然而,这些模型主要是通过掩码语言建模(MLM)目标进行训练的,这对于生成高质量的文本嵌入来说并不是最优的。为了克服这一限制,最近的方法专注于微调和扩展这些模型,特别是用于嵌入任务 [Reimers and Gurevych, 2019]。
该领域的一个关键进展是多阶段和多任务微调策略的开发,这些策略结合了弱监督对比训练[Wang et al., 2022, Günther et al., 2023, Mohr et al., 2024] 。这些方法提高了嵌入的多功能性,使模型能够在各种应用和任务中表现良好,而不是仅在语义文本相似度数据集上训练的模型。
此外,诸如 AliBi [Press et al., 2022] 和 RoPE [Su et al., 2024] 等技术,通过用相对位置编码方法替代绝对位置编码,使得像 jina-embeddings-v2 [Günther et al., 2023] 这样的模型能够处理更长的序列,最长可达 8192 个token。为了使嵌入更加紧凑,Matryoshka 表征学习(MRL)[Kusupati et al., 2022] 通过修改在训练过程中使用的损失函数,在不影响下游任务性能的情况下截断嵌入。
2.2 Multilingual Embedding Models
最早的多语言 Transformer 模型之一是 Multilingual BERT (mBERT) [Devlin et al., 2019],该模型在 104 种语言上进行了训练。随后出现了 XLM [Conneau and Lample, 2019] 和 XLM-RoBERTa (XLM-R) [Conneau et al., 2020],这两个模型在训练过程中利用了并行数据。Wang et al. [2024] 在此基础上,通过在高质量的多语言标记数据集上微调XLM-R,并应用交叉编码器的知识蒸馏,进一步提升了嵌入质量。同样地,Chen et al. [2024a] 引入了 BGE M3,这是另一种基于 XLM-R 的模型,支持更长的序列。作者将 XLM-R 的最大序列长度扩展到 8192 个 token,使用 RetroMAE 方法继续预训练 [Xiao et al., 2022],并使用一种新的多 CLS 池化策略对其进行对比微调。mGTE [Zhang et al., 2024] 也是基于 XLM-R 构建,结合了 RoPE 位置嵌入 [Su et al., 2024]。
另一种方法利用 LLM 进行多语言嵌入 [Zhang et al., 2023, Wang et al., 2023],这得益于它们广泛的语言支持和多样的训练数据。然而,LLM 由于其规模较大,计算效率低下,使得它们在许多应用中不太实用。为了解决这个问题,Lee et al. [2024a] 生成并重新标记训练数据,以将 LLM 中的知识提取到紧凑的编码器模型中,从而避免对较大 LLM 进行直接微调的需要。
2.3 Task-Specific Embedding Models
以前的研究已经强调,训练模型产生在各种用例和领域中表现良好的通用嵌入向量存在局限性。例如,Wang et al. [2022] 观察到,在非对称检索任务中,如问答和典型的信息检索,在编码之前对查询和文档附加不同的前缀,模型可以表现得更好。该研究中的 E5 模型对所有查询使用一个前缀,对所有文档使用另一个前缀,而 Su et al. [2023] 引入了更复杂的指令来编码与检索任务和数据领域相关的额外信息。
Hu et al. [2021] 提出了一种使用轻量级 LoRA 层来微调 LLM 的技术。通过冻结原始模型的权重,这种方法显著提高了训练效率。更重要的是,部署多个微调实例变得可行,因为 LoRA 通常只需不到原始模型权重所需内存的 1%。然而,据作者所知,这种技术尚未被探索作为嵌入训练中基于指令方法的替代方案。
3 Model Architecture
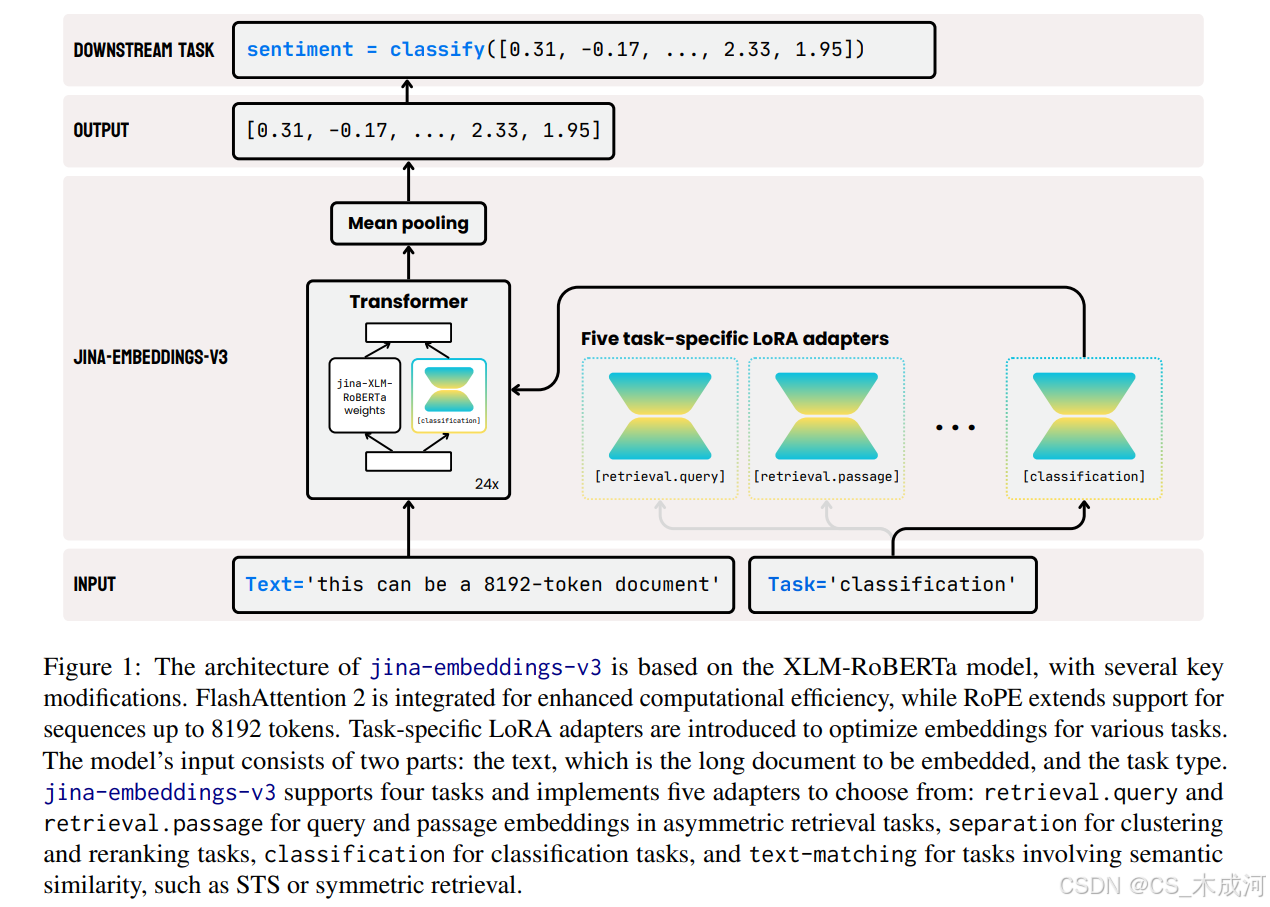
jina-embeddings-v3 的架构如图 1 所示。为了实现主干架构,作者对 XLM-RoBERTa 模型进行了调整,具体修改包括:(1) 实现长文本序列的有效编码,(2) 允许任务特定的嵌入编码,(3) 提高模型效率。 jina-embeddings-v3 保留了原始的 XLM-RoBERTa 分词器。
如表 1 所示,jina-embeddings-v3 的规模比 jina-embeddings-v2 更大,但明显比从 LLM 微调而来的嵌入模型更小 [Lee et al., 2024b, Wei et al., 2022]。重要的是,LoRA 适配器占总参数的比例不到 3%,增加的开销非常小。为了进一步增强性能并减少内存消耗,作者利用了 FlashAttention 2 [Dao],支持激活检查点,并采用 DeepSpeed 框架 [Rasley et al., 2020] 进行高效的分布式训练。

为了处理长文本序列,作者用旋转位置嵌入(RoPE)[Su et al., 2024] 替代了绝对位置嵌入,RoPE 通过使用旋转矩阵编码绝对位置,同时直接在自注意力机制中嵌入相对位置依赖关系。作者也进行了扩展位置编码的实验,正如 BGE M3 模型 [Chen et al., 2024b] 中所做的那样,但观察到在涉及长文本的任务上表现不佳。这可能归因于训练数据和池化策略的差异,因为作者主要在短文本上进行训练并使用均值池化而不是多 CLS 池化。
Xiong et al. [2024] 证明增加旋转位置嵌入的基频参数可以增强长文本任务的性能,而 Zhang et al. [2024] 在短序列训练过程中调整旋转基频以便在长序列上更好地泛化。作者发现,在训练过程中将旋转基频设置为10,000,并在推理时调整至20,000,可以在不降低短文本任务性能的情况下,提高长文本任务的性能。
嵌入可以用于多种下游任务,包括聚类、检索和分类,每个任务都需要对表示空间进行不同的解释,从而产生不同的相似性度量。例如,非对称检索任务受益于对查询和文档进行不同的编码。Wang et al. [2022] 提出,对于查询和文档使用不同的指令可以提高嵌入模型在此类任务中的有效性。
然而,编写有效的特定任务指令并非易事。作为替代方案,作者采用了任务特定的 LoRA 适配器。多头注意力机制中的嵌入层和线性层配备了秩为 4 的低秩分解矩阵。这些任务特定的 LoRA 适配器与模型权重一起加载,并根据输入任务类型动态选择。批处理中的每个文本输入都与一个任务描述符关联,该描述符表示为一个整数,对应于 LoRA 适配器的ID。
4 Training Method
作者使用原始 XLM-RoBERTa 模型的权重来初始化模型。然而,由于位置嵌入方法的改变,模型最初的 MLM 目标与作者的训练目标并不完全一致。尽管如此,作者观察到与随机初始化相比,使用预训练权重初始化能够在预训练过程中实现更快的收敛速度。
作者的训练范式由三个阶段组成,这对于训练文本嵌入模型来说很常见:
I 预训练:作者使用大规模多语言文本语料库进行标准的 MLM 训练。模型使用 XLM-RoBERTa 权重进行初始化,以加快预训练过程并避免从零开始训练。
II 嵌入任务的微调:为了学习如何将文本段落编码为单一向量表示,作者遵循 [Günther et al., 2023] 中概述的方法。该方法在 Transformer 模型中引入了一个池化层,用于聚合每个 token 的表示为一个单一的嵌入向量,并在语义相关的文本对上微调模型。
III 训练任务特定的适配器:作者使用专门的数据集和任务特定的损失函数,为四个不同的任务训练了五个 LoRA 适配器,以优化每种用例的性能。
4.1 Pre-Training
初始化后,使用带有全词掩码的 MLM 目标来训练模型 [Devlin et al., 2019]。在这一阶段,作者只训练 Transformer 模型,不包括 LoRA 适配器和池化层。
为了支持多语言任务,训练数据取自 CulturaX 语料库 [Nguyen et al., 2023],该语料库包括来自 89 种语言的数据,其中英语约占数据集的 20%。在训练过程中,每个批次只包含一种语言的数据,但作者在批次之间轮换语言。
为了支持长上下文,作者首先在被截断为 512 个 token 的文本序列上训练 100, 000 步,然后在被截断为 8192 个 token 的文本序列上进行额外的 60, 000 步训练并减少批次大小。具体细节见附录 A1。
为了增强模型表示长文本文档的能力,作者使用较低的旋转基值进行训练,并在推理过程中增加它,如第 1 节中所述。然而,作者发现该模型编码长文档的能力仍然落后于诸如 jina-embeddings-v2 等模型。为了解决这一问题,作者扩展了长文本数据的训练,从而提高了长文本检索任务(例如 NarrativeQA)的性能。详细信息见第 5.3 节。
4.2 Fine-Tuning for the Embedding Task
在预训练之后,作者对模型进行微调,使其能够将文本序列编码为单个向量表示。作者遵循 Sentence-BERT 方法 [Reimers and Gurevych, 2019],使用均值池化层增强模型,以便将所有输出 token 向量的语义聚合为单个向量表示。微调过程遵循 Mohr et al. [2024] 的方法,其中模型使用双向 InfoNCE [van den Oord et al., 2018] 损失 L p a i r s \mathcal{L}_{pairs} Lpairs 在文本对上进行训练:
L p a i r s ( B ) : = L N C E ( B ) + L N C E ( B † ) (1) \mathcal{L}_{pairs}(B):=\mathcal{L}_{NCE}(B)+\mathcal{L}_{NCE}(B^\dagger) \tag{1} Lpairs(B):=LNCE(B)+LNCE(B†)(1)
定义在批次 B = ( ( p 1 , q 1 ) , . . . , ( p k , q k ) ) B = ((p_1, q_1), . . . , (p_k, q_k)) B=((p1,q1),...,(pk,qk)) 的 k k k 对样本上,并且 B † = ( ( q 1 , p 1 ) , . . . , ( q k , p k ) ) B^\dagger = ((q_1, p_1), . . . , (q_k, p_k)) B†=((q1,p1),...,(qk,pk)),即通过交换每对的顺序从 B B B 中得到。 L N C E \mathcal{L}_{NCE} LNCE 表示以下损失函数:
L N C E ( B ) : = − ∑ ( x i , y i ) ∈ B ln e s ( x i , y i ) / τ ∑ i ′ = 1 k e s ( x i , y i ′ ) / τ (2) \mathcal{L}_{NCE}(B):=- \sum_{(x_i,y_i)\in B}\ln{\frac{e^{s(x_i,y_i)/\tau }}{\sum_{i'=1}^{k} e^{s(x_i,y_{i'})/\tau }} } \tag{2} LNCE(B):=−(xi,yi)∈B∑ln∑i′=1kes(xi,yi′)/τes(xi,yi)/τ(2)
训练数据由超过 10 亿个文本对组成,这些文本对取自 300 多个不同的子数据集,每个子数据集代表各种语言的特定领域。在训练过程中,数据加载器通过对特定子数据集进行采样来构建每个批次,确保该批次中仅包含来自该数据集和语言的文本对。
对于数据准备,作者遵循与之前工作相同的方法 [Mohr et al., 2024],并增加了一个过滤步骤。该过滤器会删除较短文本中至少 80% 的单词(最少四个)是较长文本的子字符串的对。这个过滤步骤增加了训练的难度,并鼓励模型减少对句法重叠的关注。
与预训练阶段一样,作者从短文本对开始训练,然后使用更大的序列长度但减少的批次大小对较长的文本进行进一步训练。在这一阶段,作者仅使用包含足够长文本的数据集的子集。
4.3 Training Task-Specific Adapters
嵌入训练的相关工作 [Wang et al., 2022; Xiao et al., 2023] 在成对训练阶段之后引入了一个额外的通用训练阶段。这个阶段整合了来自各种任务类型的高质量数据,以优化模型在一系列下游用例中的性能。在这个阶段,最新的方法使用任务特定的指令来帮助模型区分不同的任务和领域,正如第 2.3 节中所讨论的。
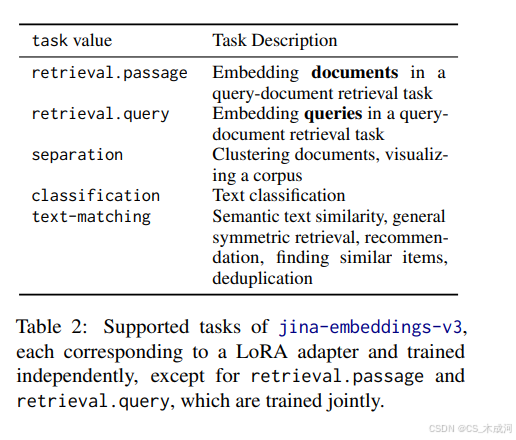
然而,这种方法增加了使用的复杂性,因为用户必须学习与模型行为或“风格”一致的任务特定的指令(即提示词)。虽然这提供了灵活性,但也使得模型的行为难以预测。相比之下,作者为四个明确定义的任务类型训练了五个不同的 LoRA 适配器,如表 2 所定义。这些任务是独立训练的,且基础模型的权重保持冻结。对于查询-文档检索任务,两个适配器联合训练:一个用于查询,另一个用于段落。在推理过程中,用户可以根据下游任务和输入角色选择合适的适配器,确保为他们特定的用例生成最优的嵌入。
4.3.1 Classification Adapter
分类适配器生成的嵌入对于训练下游分类模型(特别是逻辑回归分类器)非常有效。为了训练该适配器,作者采用了 Gecko 嵌入模型中提出的分类训练方法 [Lee et al., 2024a]。具体而言,作者选择了涵盖各种常见分类任务的数据集,包括情感分析、意图分类和文章分类。
从每个数据集中,作者构建由来自相同类别 ( q , p ) (q, p) (q,p)的两个文本值和来自不同类别 ( n 1 , . . . , n 7 ) (n_1, . . . , n_7) (n1,...,n7)的七个文本值组成的元组,形成一个由九个文本值 ( q , p , n 1 , . . . , n 7 ) (q, p, n_1, . . . , n_7) (q,p,n1,...,n7)组成的元组。该模型经过训练,为 q q q 和 p p p 的嵌入分配高余弦相似度,同时强制 q q q 和所有 n i n_i ni 之间的低余弦相似度。每个批次由从单个数据集中采样的元组组成。
作者采用作者之前工作 [Günther et al., 2023] 中描述的 InfoNCE 损失 L t r i p l e t \mathcal{L}_{triplet} Ltriplet 的扩展版本来考虑这些额外的负样本。
L t r i p l e t ( B ) : = E r ∼ B [ − ln e s ( q , p ) / τ ∑ i = 1 k [ e s ( q , p i ) / τ + ∑ j = 1 m e s ( q , n j , i ) / τ ] ] + E r ∼ B [ − ln e s ( p , q ) / τ ∑ i = 1 k e s ( p , q i ) / τ ] (3) \mathcal{L}_{triplet}(B):=\mathbb{E}_{r\sim B}\left [- \ln \frac{e^{s(q,p)/ \tau}}{\sum_{i=1}^{k}\left [ e^{s(q,p_i)/ \tau}+ \sum_{j=1}^{m} e^{s(q,n_{j,i})/ \tau} \right ] } \right ]+\mathbb{E}_{r\sim B}\left [ -\ln \frac{e^{s(p,q)/ \tau}}{\sum_{i=1}^{k}e^{s(p,q_i)/ \tau}} \right ] \tag{3} Ltriplet(B):=Er∼B −ln∑i=1k[es(q,pi)/τ+∑j=1mes(q,nj,i)/τ]es(q,p)/τ +Er∼B[−ln∑i=1kes(p,qi)/τes(p,q)/τ](3)
在使用这个损失函数时,来自与文本 q i q_i qi 相同类别的文本,如果在与不同文本 q j ( i ≠ j ) q_j (i \ne j) qj(i=j) 的同一批次中出现为负样本,也会被视为负样本。这就引入了假负样本的问题。
为了解决这个问题,Lee et al. [2024a] 提出了将一个特定于每个元组 r r r 的唯一 ID 附加到其对应的文本值上。这样可以使模型很容易地区分来自不同元组的文本值,从而能够专注于在同一元组批次中分离文本值。
4.3.2 Text Matching Adapter
该适配器经过训练可以生成量化两个文本值之间相似度的嵌入。它适用于语义文本相似度 (STS) 和检索任务等,这些任务中查询和目标文本值之间没有明显的区别。这样一个检索任务的例子是重复检测,其中将语料库中的文本值相互比较。在这些情况下,“查询”和“语料库”文本会被对称处理。
为了训练这个适配器,作者使用 CoSent 损失函数: L c o \mathcal{L}_{co} Lco,正如之前 Li 和 Li [2024] 使用的那样:
L
c
o
(
B
)
:
=
ln
[
1
+
∑
(
q
1
,
p
1
)
,
(
q
2
,
p
2
)
∈
B
e
s
(
q
2
,
p
2
)
−
e
s
(
q
1
,
p
1
)
τ
]
\mathcal{L}_{co}(B):=\ln\left [ 1+\sum_{(q_1,p_1),(q_2,p_2) \in B} \frac{e^{s(q_2,p_2)}-e^{s(q_1,p_1)}}{\tau } \right ]
Lco(B):=ln
1+(q1,p1),(q2,p2)∈B∑τes(q2,p2)−es(q1,p1)
其中,
ζ
(
q
1
,
p
1
)
>
ζ
(
q
2
,
p
2
)
(4)
\zeta (q_1,p_1) >\zeta (q_2,p_2)\tag{4}
ζ(q1,p1)>ζ(q2,p2)(4)
CoSent 损失操作两对文本值 ( q 1 , p 1 ) (q_1, p_1) (q1,p1) 和 ( q 2 , p 2 ) (q_2, p_2) (q2,p2),这些文本值对是通过从批次中选择四个文本值的组合构建的,其中训练数据集中提供了真值相似度 ζ \zeta ζ,并且 ζ ( q 1 , p 1 ) \zeta(q_1, p_1) ζ(q1,p1) 大于 ζ ( q 2 , p 2 ) \zeta(q_2, p_2) ζ(q2,p2)。
为了用这个目标训练模型,作者使用来自语义文本相似度 (STS) 训练数据集的数据,例如 STS12 [Agirre et al., 2012] 和 SICK [Marelli et al., 2014]。这些数据集由三元组 ( q i , p i , t i ) ∈ D (q_i, p_i, t_i) \in D (qi,pi,ti)∈D 组成,其中 ( q i , p i ) (q_i, p_i) (qi,pi) 是文本对, t i t_i ti 是相应的相关性分数。通过从给定数量的三元组中选择文本值来构建批次 B B B,其真值相似度定义为 ζ ( q i , p i ) = t i \zeta (q_i, p_i) = t_i ζ(qi,pi)=ti。
为了提高模型跨语言的性能,作者使用机器翻译模型将 STS12 和 SICK 数据集翻译成多种语言,即 WMT19 [Ng et al., 2019] 和 MADLAD-3B [Kudugunta et al., 2023]。虽然在 STS 数据集上的训练非常有效,但由于需要人工标注,获得大量此类数据具有挑战性。因此,作者将各种自然语言推理(NLI)数据集融入训练过程中。
在每个训练步骤中,选择一个 STS 或 NLI 数据集,并仅使用所选数据集构建批次,采用适当的损失函数。换句话说,每个批次仅包含来自一个特定数据集的文本值。
相关超参数见附录 A1。
4.3.3 Asymmetric Retrieval Adapters
在第 2.3 节中讨论的非对称检索任务,例如问答和传统信息检索,通过查询和文档的单独编码机制可以更好地执行。在这项工作中,作者遵循 Wang et al. [2022] 提出的方法,使用两个不同的前缀,并通过使用两个专门的适配器来进一步分离编码过程,这两个适配器是联合训练的。在第 5.5.2 节中提供了详细的消融研究,以证明这种方法的有效性。
与之前的工作 [Wang et al., 2022, Li et al., 2023, Günther et al., 2023] 类似,作者使用包含硬负样本的数据集,例如 MSMARCO [Bajaj et al., 2016] 和 Natural Questions (NQ) [Kwiatkowski et al., 2019],来训练模型以关注细微的区别,并区分相关的文档和相似但不相关的文档。对于没有带标注负样本的检索训练数据集,作者应用 [Ren et al., 2021, Wang et al., 2022] 中概述的硬负样本挖掘,利用像 BGElarge [Xiao et al., 2023]和 BM25 [Robertson et al., 2009]这样的嵌入模型。
为了将挖掘的负样本融入训练过程中,作者使用了 L t r i p l e t \mathcal{L}_{triplet} Ltriplet 损失函数,如公式 (3) 所示。
4.3.4 Failure Analysis for Asymmetric Retrieval
由于作者的 jina-embeddings-v2 模型是使用与 jina-embeddings-v3 类似的数据进行训练的,因此作者进行了失败分析,以确定在这些数据集上训练的模型的常见问题。通过这次分析,作者确定了影响检索任务的以下几点:
F1. 误导性的句法相似性:与查询具有高度句法相似性的文档通常会被优先考虑,而与之相比,具有较低句法重叠的优质/相关文档则被忽视。
F2. 命名实体的误解:命名实体往往未被识别为实体,导致文档基于部分匹配被标记为相关(例如,“Sofia Albert” vs. “Albert Stone”)。这种情况尤其发生在具有其他更常见含义的专有名词上(例如,小说标题 “The Company” vs. “the company”)。
F3. 对极性问题的不理解:无法有效处理复杂的是非(极性)问题。因此,模型检索到的文档具有相关内容,但不一定能回答查询。
F4. 对低质量文档的偏好:jina-embeddings-v2及许多其他嵌入模型没有考虑文档质量,仅关注相似性和相关性。因此,提及查询词语的低质量文档(简短、重复或信息量少)经常被检索到,但并未提供令人满意的答案。
为了缓解 F1-F3 的影响,作者设计了提示词来生成针对这些特定失败案例的合成文本示例。每个示例由一个查询文本、一个首选答案和七个对失败案例进行建模的负面示例组成。
对于 F4,作者利用了两个偏好学习数据集:来自Open Assistant项目的oasst1 和 oasst2 [Köpf et al., 2024]。这些数据集包含由大语言模型生成的问题和答案,并基于人类判断的质量分数 (0-1)。
作者通过选择至少有两个答案的查询,将这些数据集转换为硬负样本训练数据。质量最高的答案被视为正匹配,而质量分数低于 0.3 分的答案则被视为负匹配。如果识别出的负样本少于七个,则从其他查询中随机选择额外的负样本。
在第 5.4 节中评估了在这些数据上训练检索适配器的有效性。
4.3.5 Separation Adapter
分离适配器被设计用于在聚类和重排序任务上表现良好。它被训练以区分属于同一组和不同组的文本值。在重排序任务中,适配器根据查询的信息需求将相关文档与不相关文档分开。在聚类任务中,提供了一组文本,在计算嵌入并应用聚类算法(例如 k-means)之后,生成的聚类应反映正确的分组。
为了这一目标训练该适配器,作者采用了公式 (4) 引入的 CoSent 损失
L
c
o
\mathcal{L}_{co}
Lco 的变体。训练数据由元组
(
x
,
l
)
∈
B
′
(x, l) \in B'
(x,l)∈B′ 组成的批次
B
′
B'
B′ 组成,其中
x
x
x 是文本值,
l
l
l 是其标签。为了形成一批与
L
c
o
\mathcal{L}_{co}
Lco 兼容的文本对,作者生成该批次中共享相同标签
l
i
l_i
li 的所有文本值的成对组合。分离损失定义如下:
L
s
e
p
(
B
′
)
:
=
L
c
o
(
B
)
\mathcal{L}_{sep}(B'):=\mathcal{L}_{co}(B)
Lsep(B′):=Lco(B)
B
=
{
(
x
i
,
x
j
)
∣
∃
l
:
(
x
i
,
l
)
,
(
x
j
,
l
)
∈
B
′
}
(5)
B=\left \{(x_i,x_j)\mid \exists l:(x_i,l),(x_j,l) \in B'\right \} \tag{5}
B={(xi,xj)∣∃l:(xi,l),(xj,l)∈B′}(5)
由于作者在这种格式下的训练数据有限,作者观察到将来自配对训练阶段(第 4.2 节)的额外数据融入训练混合中可以提高性能。作者遵循与文本匹配适配器(第 4.3.2 节)相同的模式,在每个训练步骤中对特定数据集进行采样,并应用相应的损失函数。
关于训练数据和超参数的更多详细信息,请参见附录 A1。
5 Evaluation
在本节中,作者评估了模型在各个阶段的性能,并对关键的架构修改进行了消融研究。首先,作者在第 5.1 节中对多语言主干模型在 MTEB 任务的一个小子集上进行了评估。
接下来,作者在第 5.2 节中对嵌入任务进行了全面评估,其中作者的模型在各种 MTEB 任务上进行了测试,包括单语言(英语)和多语言。第 5.3 节报告了模型在 LongEmbed MTEB 评估中的表现,然后在第 5.4 节中分析了之前确定的检索失败案例。最后,第 5.5 节展示了对 MRL 和检索适配器进行的消融研究。
5.1 Performance of Jina-XLM-RoBERTa
作者在英语和多语言/跨语言 MTEB 任务的子集上对 Jina-XLM-RoBERTa 模型进行了评估,并与已有的多语言模型进行了对比分析,特别是 mBERT [Devlin et al., 2019] 和 XLM-RoBERTa [Conneau et al., 2020],它们被广泛用于多语言嵌入模型的主干。
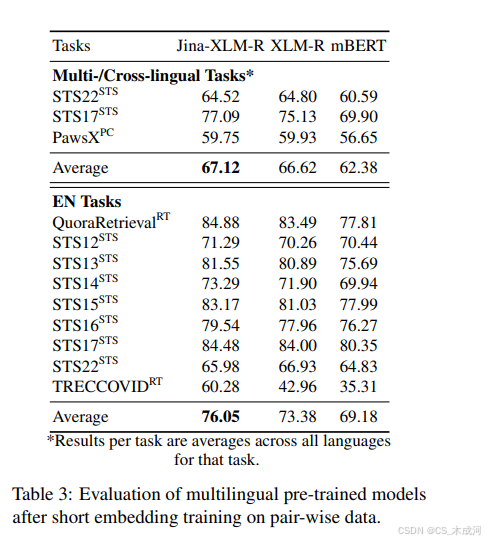
在这个实验中,作者遵循第 4.2 节中描述的相同训练设置,但将单个 GPU 节点上的训练限制为 1000 个步骤,大约处理 200 万对文本数据。这一阶段不包括适配器调整。如表 3 所示,作者的模型在所有任务上都优于 XLM-R 和 mBERT,在单语言英语任务上平均达到 76.05%,在多语言/跨语言任务上平均达到 67.12%。这些结果支持了作者继续针对多语言应用训练 XLM-R 的决定。
5.2 Performance on MTEB
表 4 总结了各种多语言文本嵌入模型在不同 MTEB 任务中的性能,分为英语和多语言部分。 jina-embeddings-v3 的表现极具竞争力,特别是在单语言英语任务中,它获得了最高的分类准确率 (CF) 分数 82.58 和最高的句子相似度 (STS) 分数 85.80,证明了它在语言和任务上的鲁棒性。每个任务的完整评估结果可在附录 A3 中找到。对所有任务进行平均时,jina-embeddings-v3 的得分为 65.52,优于 text-embedding-3-large、multilingual-e5-large-instruct 和 Cohere-embed-multilingual-v3.0 等模型。这表明 jina-embeddings-v3 在接受多种语言训练的同时保持了强大的单语言英语性能。
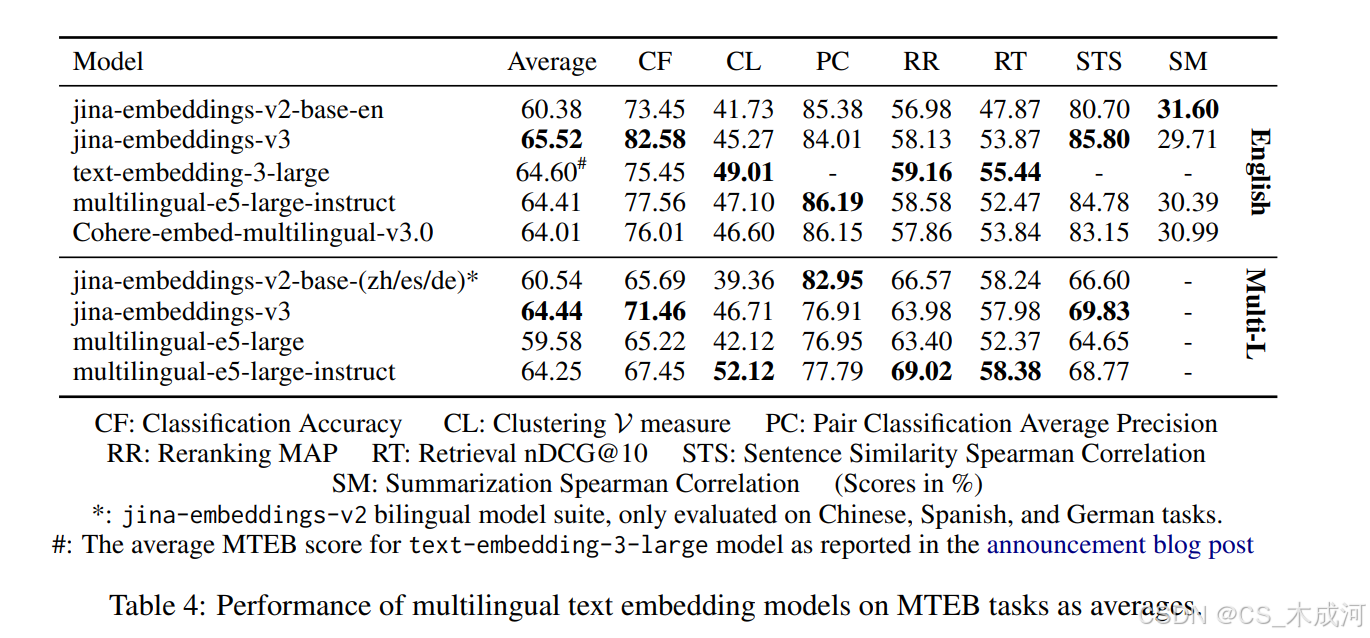
参考英语 MTEB 排行榜,作者在图 2 中绘制了前 100 个嵌入模型的性能与其参数大小的关系。值得注意的是,基于大语言模型 (LLM) 的嵌入模型虽然性能略微优于 jina-embeddings-v3,但在实际应用中,它们的复杂性和计算成本明显更高。例如,e5-mistral-7b-instruct 在所有 56 个英语 MTEB 任务中获得了 66.63 的平均分数(比 jina-embeddings-v3 高出约 1.03%),但它生成的嵌入维度为 4096,参数大小为 71 亿。相比之下,jina-embeddings-v3 提供了更实用的解决方案,嵌入维度为 1024(或更低,使用 MRL 并进行可管理的性能权衡,如第 5.5.1 节中所述),参数大小仅为 5.7 亿。
在多语言性能方面,表 4 展示了在各种多语言和跨语言 MTEB 任务中的加权平均分数。每种具体任务以及其使用的适配器说明详见附录 A7、A6、A8、A5、A9 和 A4。注意,jina-embeddings-v2 指的是作者的双语模型套件(jina-embeddings-v2-base-zh、jina-embeddings-v2-base-es、jina-embeddings-v2-base-de),仅在中文、西班牙语和德语单语言和跨语言任务中进行了评估,不包括所有其他任务。因此,jina-embeddings-v2* 在配对分类任务上的平均得分反映了仅在中文任务上的表现。关于配对分类的完整报告可以在附录 A6 中找到。作者没有报告 text-embedding-3-large 和 Cohere-embed-multilingual-v3.0 的分数,因为这些模型没有在全面的多语言和跨语言 MTEB 任务上进行评估。然而,作者的模型在除重排序之外的所有多语言任务中都优于 multilingual-e5-large,并且接近 multilingual-e5-large-instruct 的性能。
对于 jina-embeddings-v3,所有的分类和配对分类任务都使用分类适配器进行评估,所有的 STS 任务和三个检索任务(ArguAna、CQADupstackRetrieval 和 QuoraRetrieval)都使用文本匹配适配器进行评估,所有其他检索任务都使用检索适配器进行评估,所有聚类和重排序任务都使用分离适配器进行评估。
5.3 Performance on LongEmbed MTEB
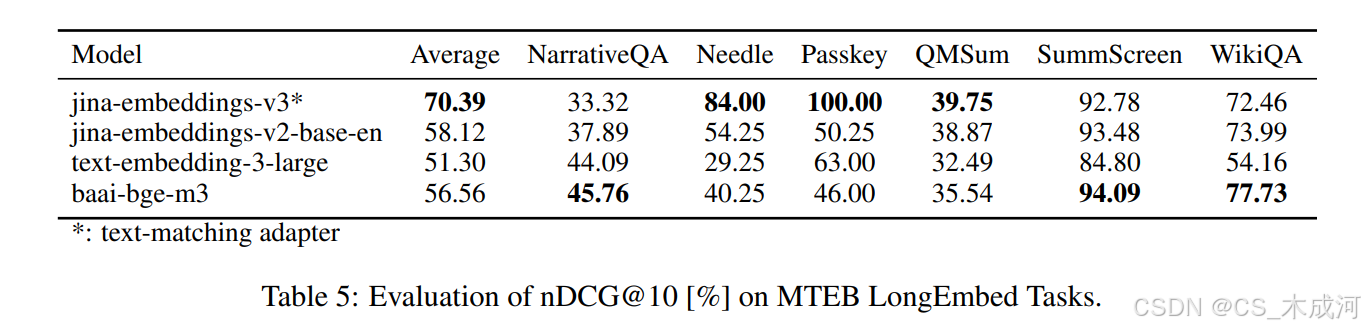
作者将他们的模型与 text-embedding-3-large、bge-m3 以及作者之前发布的模型套件 jina-embeddings-v2 在 MTEB 榜单上的六个长文档检索任务上进行了评估比较。结果如表 5 所示,带有文本匹配适配器的 jina-embeddings-v3 达到了最高的平均性能。这些发现强调了基于 RoPE 的位置嵌入的有效性,其性能优于 bge-m3 中使用的固定位置嵌入和 jina-embeddings-v2 中使用的 ALiBi 方法。
5.4 Retrieval Failures
作者对嵌入模型应用于检索任务时通常观察到的检索失败进行了分析,识别出了第 4.3.3 节中描述的四种失败案例。为了评估使用合成和偏好学习数据集训练作者的检索适配器是否可以减轻这些失败,作者进行了两项定量评估。
第一个实验评估了现有检索基准(例如 HotpotQA [Yang et al., 2018] 和 NaturalQuestions [Kwiatkowski et al., 2019])中的失败案例是否得到解决。
这些示例由一个查询、一个相关文档和一个通常被分配较高检索分数的不太相关文档组成。表 6 展示了平均精度 (mAP) 分数,表明作者的模型在经过检索适配器训练后,可以更好地处理这些失败案例,或者至少与作者之前发布的 jina-embeddings-v2 模型和 multilingual-e5 模型一样有效。
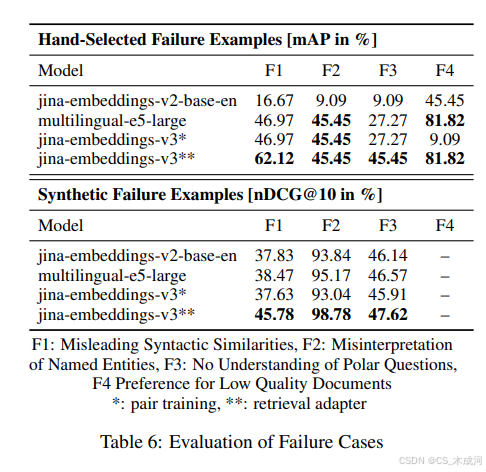
然而,在合成数据上的训练似乎并没有提高模型对失败案例 F2(命名实体)的处理能力,并且 multilingual-e5 模型同样可以很好地处理失败案例 F2 和 F4(低质量文档)。鉴于评估集的规模较小(大多数失败案例少于 10 个示例),作者使用更大规模的、合成生成的代表典型失败情况的挑战性示例集进行了第二次分析。在这种情况下,失败案例 F4 被排除在外,因为 LLM 是在高质量数据上进行训练的,不适合生成低质量的内容。
在第二个实验中,作者的模型在所有任务上都优于其他三个模型,如表 6 的下半部分所示。这种评估方法的一个局限性是,合成示例可能与训练数据过于紧密一致,从而可能使模型更容易解决这些失败案例。
5.5 Ablation Studies
5.5.1 Matryoshka Representation Learning
表 7 展示了 MRL 对作者模型性能的影响。MRL 旨在通过在一系列嵌入维度(本例中从 32 到 1024)上实现强大的性能,来提高文本嵌入的可扩展性和效率。该表分为两个任务类别:检索和语义文本相似度 (STS)。完整评估可在附录 A2 中找到。
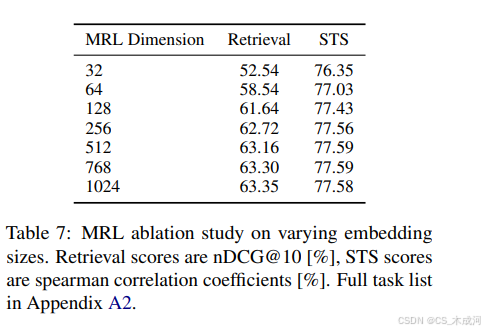
在附录 A2 报告的检索任务中,作者的模型使用 MRL 时在各个语言和数据集上始终表现出强大性能,即使在较低维度的嵌入时也能取得有竞争力的结果。例如,在 XPQA 检索(法语)任务中,该模型在 1024 维嵌入时达到了最高分 77.75,但在较低维嵌入时也表现良好,在 64 维嵌入时得分为 74.29,仅下降了 3.46%。这凸显了 MRL 在无需最大嵌入规模的情况下保持高性能的鲁棒性。
5.5.2 Encoding Asymmetry for Retrieval
表 8 提供了有关使用一对适配器/两个适配器的影响以及指令影响的重要观点。对于大多数任务,两个适配器与指令的组合可以产生最高的性能,显示出增加模型容量和明确指令的优势。例如,TRECCOVID 和 NFCorpus 的最高分是通过两个适配器和指令获得的,分别得分 75.05 和 35.34。相比之下,缺乏指令通常会导致性能下降,特别是在使用单个适配器时。这一趋势强调了指令在提高检索效率方面的重要性。
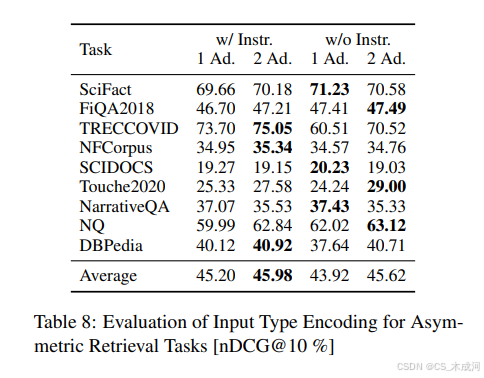
平均而言,在两种指令设置中,使用两个适配器的性能始终优于单个适配器,平均得分分别为 45.98 和 45.62,而单个适配器的平均得分为 45.20 和 43.92。虽然指令对性能产生了积极作用,但使用两个适配器所增加的模型容量具有更显著的影响。这些发现表明,为了在检索任务中获得最佳性能,使用更多适配器与指令的结合通常是有益的,尽管任务特定的因素可能会影响这些配置的有效性。
6 Conclusion
该文介绍了作者最新的文本嵌入模型 jina-embeddings-v3。通过在强大的基础模型上利用任务特定的适配器调优和针对失败的合成数据增强,jina-embeddings-v3 在广泛的任务中展现出了竞争力的性能。对英语和多语言数据集的广泛评估凸显了该模型在保持合理参数规模的同时具有强大的性能。
作者特别感兴趣的是评估和改进模型在低资源语言上的性能,并进一步分析由低数据可用性造成的系统故障。作者计划未来重点关注这一领域,进一步增强其在数据可用性有限的多语言任务中的能力。
论文链接:https://arxiv.org/abs/2409.10173
参考资料:
- 开源模型链接:https://huggingface.co/jinaai/jina-embeddings-v3
- 模型 API 官网链接:https://jina.ai/
- 官方CSDN博客:https://blog.csdn.net/Jina_AI/article/details/142459011
- 官方github仓库:https://github.com/jina-ai
