前言
随着大数据时代的到来,高吞吐量的分布式发布订阅消息系统kafka得到了极大的应用,它具有高吞吐量、
特点
- 高吞吐量:10w/s+
- 持久化消息:磁盘
- 分布式
- 支持Hadoop数据并行加载
架构
一、zookeeper安装配置
为什么要安装zookeeper?Zookeeper是一个分布式的协调服务,主要用于维护集群的元数据信息和配置信息。Kafka集群依赖于Zookeeper来存储和管理Kafka的元数据信息和配置信息
1.安装路径
| 版本 | 地址 | 源 | 注 |
|---|---|---|---|
| 3.8.4 | wget https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz | https://zookeeper.apache.org/releases.html | 尾部有bin是编译后的包,不带bin的未编译的包;使用已编译的包 |
- 安装配置
mkdir /opt/module # 新建目录用于保存自定义数据
wget https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz
tar -zxvf apache-zookeeper-3.8.4-bin.tar.gz -C /opt/module/
cd /opt/module
mv apache-zookeeper-3.8.4-bin zookeeper-3.8.4
# mkdir /opt/module/zookeeper-3.8.4/zkData # 用于存放zookeeper数据,会自动创建
cd /opt/module/zookeeper-3.8.4/conf
cp zoo_sample.cfg zoo_sample.cfg.bak
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg # 为什么?系统默认读取zoo.cfg文件
""" zoo.cfg 详情(英译中) """
# 通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
tickTime=2000
# LF初始通信时限。用于集群,slave首次跟随leader,leader最长等待时间(tickTime的数量)
initLimit=10
# LF同步通信时限。主leader从slave同步限制(用于集群),Leader主节点与从节点之间发送消息,请求和应答时间长度。超时放弃从节点
syncLimit=5
# 保存Zookeeper中的数据 注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录
dataDir=/opt/module/zookeeper-3.8.4/zkData
# 客户端连接端口,通常不做修改
clientPort=2181
# 单个客户端最大连接数,默认60,0为不限制,通过IP来区分不同的客户端
#maxClientCnxns=60
# 保留文件的数量,默认3个,正常此参数被注释掉,未被启用,一般配合autopurge.purgeInterval使用
#autopurge.snapRetainCount=3
# 自动清理快照文件和事务日志的频率,默认0不开启自动清理,单位为小时
#autopurge.purgeInterval=1
# 存储事务日志的目录,不指定代表存放在dataDir目录中
#dataLogDir=xxx
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
"""
- 配置环境变量(依赖java,因此也需要JAVA_HOME配置)
export ZK_HOME=/opt/module/zookeeper-3.8.4
export PATH=$PATH:$ZK_HOME/bin
- 操作指令
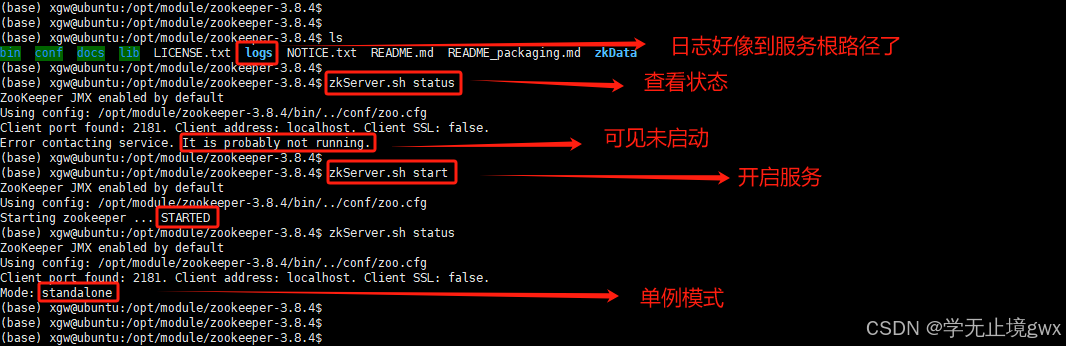
cd /opt/module/zookeeper-3.8.4/bin
chmod +x zkServer.sh
# 启动服务
zkServer.sh start
# 查看服务
zkServer.sh status
# jps是jdk提供的一个查看当前java进程的小工具,更详细可以使用jps -ml,其它参数自行百度吧
# 查看启动效果, 结果见'->74221 QuorumPeerMain'
jps
->76435 Jps
->74221 QuorumPeerMain # 这个就是zookeeper启动后的服务
->2981 Main
# 停止服务
zkServer.sh stop
# 启动客户端,如果是它机,用zkCli.sh -server ip:port
zkCli.sh
- 集群
假设集群机Leader、Follower1、Follower2
# 分别在集群机群上安装配置zookeeper,同上
# 因是集群,需要配置通信。在各集群服务器数据目录配置myid文件,内容分别为1,2,3(快捷配置可以使用xsync)!以Leader为例
cd /opt/module/zookeeper-3.8.4/zkData
vim myid # 内容见'->'
->1
# 集群服务器分别配置文件zoo.cfg追加集群内容,vim zoo.cfg如下,以Leader为例
server.1=Leader:2888:3888
server.2=Follower2:2888:3888
server.3=Follower3:2888:3888
"""配置参数解读
格式:server.A=B:C:D
A 是一个数字,表示这个是第几号服务器; 集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比 较从而判断到底是哪个 server
B 是这个服务器的地址
C 是这个服务器Follower与集群中的Leader服务器交换信息的端口
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口
"""
# 接下来就是分别启动服务了,这个上面讲了启动关闭命令,就不书写了,不知道的话可以参考上文。分别启动很麻烦,可不可以做个批量脚本关闭集群
"""在Follower2机器上编写批量集群操作脚本zk.sh
#!/bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.7.1/bin/zkServer.sh start"
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.7.1/bin/zkServer.sh stop"
done
;;
"status")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.7.1/bin/zkServer.sh status"
done
;;
esac
"""
# 配置可执行权限
chmod u+x zk.sh
启动/关停
zk.sh start/stop
二、kafka安装配置
1.安装路径
| 版本 | 地址 | 源 | 注 |
|---|---|---|---|
| 3.8.4 | https://downloads.apache.org/kafka/3.8.0/kafka_2.13-3.8.0.tgz | https://kafka.apache.org/downloads.html | linux下载安装分为源码和二进制两种形式。源码可以对代码定制化,一般要求较高。使用二进制的即可 |
- 安装配置
wget https://downloads.apache.org/kafka/3.8.0/kafka_2.13-3.8.0.tgz
tar -zxvf kafka_2.13-3.8.0.tgz -C /opt/module/
cd /opt/module
ln -s kafka_2.13-3.8.0/ kafka
# mdkir /opt/module/kafka/logs # 存放kafka日志,会自动创建
cd /opt/module/kafka/config
vim server.properties # kafka配置
""" server.properties 详情(英译中) """
############################# Server Basics #############################
# 当前机器在集群中的唯一标识,和zookeeper的myid性质一样
broker.id=0
############################# Socket Server Settings #############################
# 当前kafka服务启动的主机地址,单机可使用localhost,集群
host.name=localhost
# 当前kafka对外提供服务的端口默认是9092
port=9092
# 监听地址和端口,与(host.name&port)组合互斥
# listeners=PLAINTEXT://localhost:9092
# 这个是borker进行网络处理的线程数
num.network.threads=3
# 这个是borker进行I/O处理的线程数
num.io.threads=8
# 发送缓冲区buffer大小,数据不是一下子就发送的,先回存储到缓冲区了到达一定的大小后在发送,能提高性能
socket.send.buffer.bytes=102400
# kafka接收缓冲区大小,当数据到达一定大小后在序列化到磁盘
socket.receive.buffer.bytes=102400
# 这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数,这个值不能超过java的堆栈大小
socket.request.max.bytes=104857600
############################# Log Basics #############################
# 存储日志文件的目录列表,以逗号分隔。上面参数num.io.threads值大于此处目录数。
log.dirs=/opt/module/kafka/logs
# 默认的分区数,一个topic默认1个分区数
num.partitions=1
# 每个数据目录用来日志恢复的线程数目
num.recovery.threads.per.data.dir=1
# 是否启用log压缩,一般不用启用,启用的话可以提高性能
# log.cleaner.enable=false
############################# Internal Topic Settings #############################
# 偏移量主题的副本因子,小于1会增加数据丢失的风险!偏移量主题中的数据只会被复制到 Kafka 集群中的一个节点
offsets.topic.replication.factor=1
# 事务状态日志的复制因子副本数,小于1会增加数据丢失的风险!该日志只会被复制到一个 Kafka 集群中的另一个节点
transaction.state.log.replication.factor=1
# 事务状态日志的同步因子副本数,小于1会增加数据丢失的风险!只要有一个副本参与同步,Kafka 就会视写入操作为成功
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# 日志数据写入磁盘之前累积在内存中的消息数量。达到或超过阈值时,Kafka会触发日志刷新,将数据写入磁盘
#log.flush.interval.messages=10000
# 日志数据写入磁盘之前,可以在日志中累积的时间。超过时间间隔时(无论日志消息数量到没到阈值),Kafka会触发日志刷新,将数据写入磁盘
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# 默认消息的最大持久化时间,168小时,7天
log.retention.hours=168
# 每个分区中消息日志文件阈值。当一个日志文件的大小达到或超过这个阈值时,Kafka会根据配置的日志保留策略(如时间或大小)来决定是否删除旧的日志文件以释放空间
#log.retention.bytes=1073741824
# 这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件
#log.segment.bytes=1073741824
# 每隔300000毫秒去检查上面配置的log失效时间
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# 设置zookeeper的连接端口。格式:ip:port,如果集群的话,格式(ip1:port1,ip2:port2,ip3:port3)
zookeeper.connect=localhost:2181
# 设置zookeeper的连接超时时间
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# 消费者组初始再平衡的延迟时间。在Kafka中,当消费者组内的消费者数量发生变化(如有新的消费者加入或有消费者退出),会触发再平衡(rebalance)操作,即重新分配分区给消费者以确保负载均衡
group.initial.rebalance.delay.ms=0
- . 配置环境变量(依赖java,因此也需要JAVA_HOME配置)
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
- 操作指令
# 当logs无权限访问的话,可以sudo chown -R 用户名:用户组 /opt/module/kafka/logs
# 启动服务,后台启动,可使用nohup、&组合
kafka-server-start.sh /opt/module/kafka/config/server.properties
# nohup kafka-server-start.sh /opt/module/kafka/config/server.properties > /dev/null 2>&1 &
# jps是jdk提供的一个查看当前java进程的小工具,更详细可以使用jps -ml,其它参数自行百度吧
# 查看启动效果, 结果见'->44012 kafka'
jps
->76435 Jps
->74221 QuorumPeerMain # 这个就是zookeeper启动后的服务
->44012 kafka # 这个就是kafka启动后的服务
->2981 Main
# 停止服务
kill -9 44012
- 集群
假设集群机kafka0、kafka1、kafka2
# 分别在集群机群上安装配置kafka,同上
"""
因是集群,需要配置通信
1、在各集群服务器kafka配置文件server.properties中修改broker.id值,分别为0,1,2(快捷配置可以使用xsync)!
2、在各集群服务器kafka配置文件server.properties中修改zookeeper.connect值为kafka0-ip:2181,kafka1-ip:2181,kafka-ip-ip:2181(快捷配置可以使用xsync)!
"""
# 接下来就是分别启动服务了,这个上面讲了启动关闭命令,就不书写了,不知道的话可以参考上文。分别启动很麻烦,可不可以做个批量脚本关闭集群
"""在kafka1机器上编写批量集群操作脚本kf.sh
# 后续补充
"""
# 配置可执行权限
chmod u+x kf.sh
启动/关停
kf.sh start/stop