Elasticsearch(高性能分布式搜索引擎)
文章目录
黑马商城作为一个电商项目,商品的搜索肯定是访问频率最高的页面之一。目前搜索功能是基于数据库的模糊搜索来实现的,存在很多问题。
首先,查询效率较低。
由于数据库模糊查询不走索引,在数据量较大的时候,查询性能很差。黑马商城的商品表中仅仅有不到9万条数据,基于数据库查询时,搜索接口的表现如图:
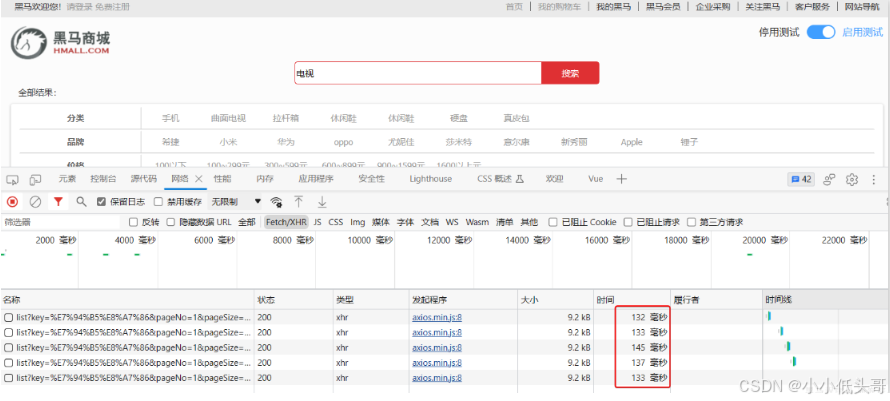
改为基于搜索引擎后,查询表现如下:
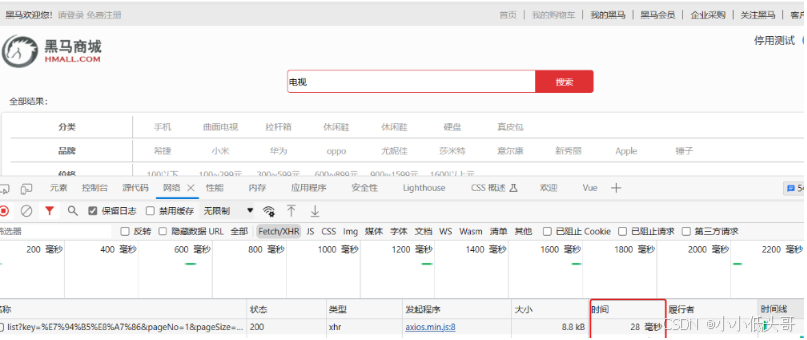
需要注意的是,数据库模糊查询随着表数据量的增多,查询性能的下降会非常明显,而搜索引擎的性能则不会随着数据增多而下降太多。目前仅10万不到的数据量差距就如此明显,如果数据量达到百万、千万、甚至上亿级别,这个性能差距会非常夸张。
其次,功能单一
数据库的模糊搜索功能单一,匹配条件非常苛刻,必须恰好包含用户搜索的关键字。而在搜索引擎中,用户输入出现个别错字,或者用拼音搜索、同义词搜索都能正确匹配到数据。
综上,在面临海量数据的搜索 ,或者有一些复杂搜索需求的时候,推荐使用专门的搜索引擎来实现搜索功能。
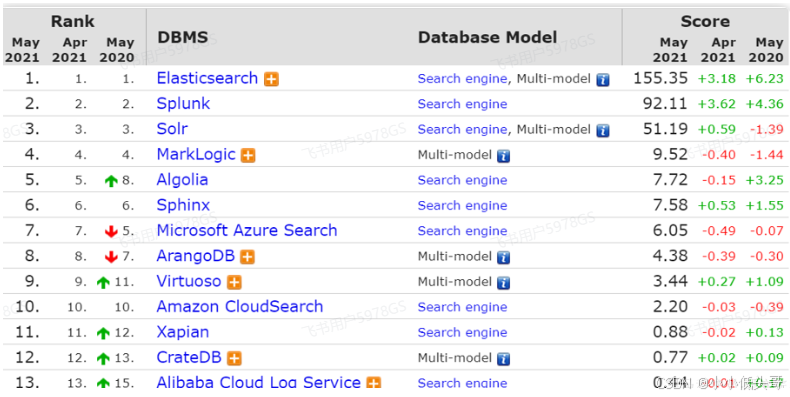
目前全球的搜索引擎技术排名如下:
1 初识elasticsearch
1.1 认识和安装
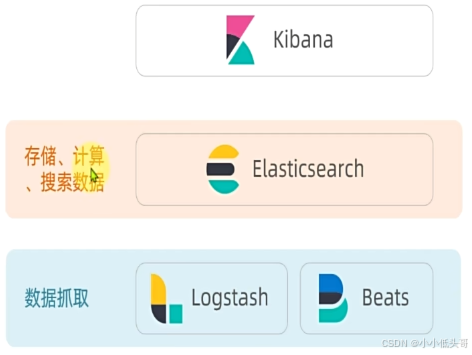
elasticsearch结合kibana、Logstash、Beats,是一整套技术栈,被叫做ELK。被广泛应用在日志数据分析、实时监控等领域。
1.2 倒排索引
传统数据库(如MySQL)采用正向索引,例如给下表(tb goods)中的id创建索引:
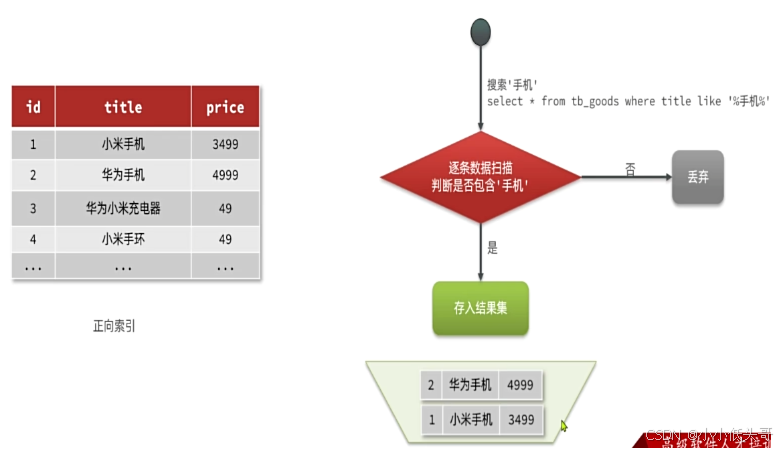
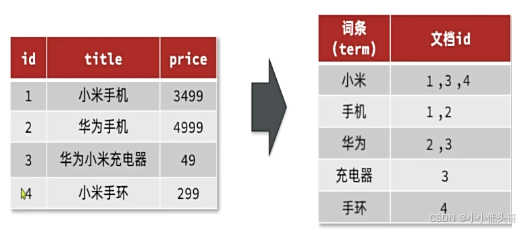
elasticsearch采用倒排索引:
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
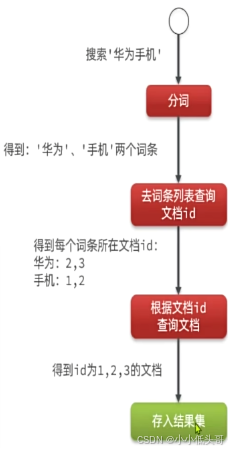

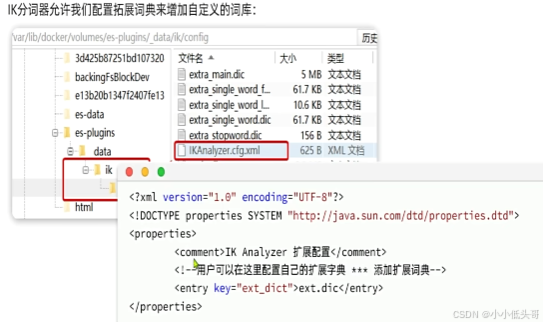
1.3 IK分词器
中文分词往往需要根据语义分析,比较复杂,这就需要用到中文分词器,例如IK分词器。IK分词器是林良益在2006年开源发布的,其采用的正向迭代最细粒度切分算法一直沿用至今。
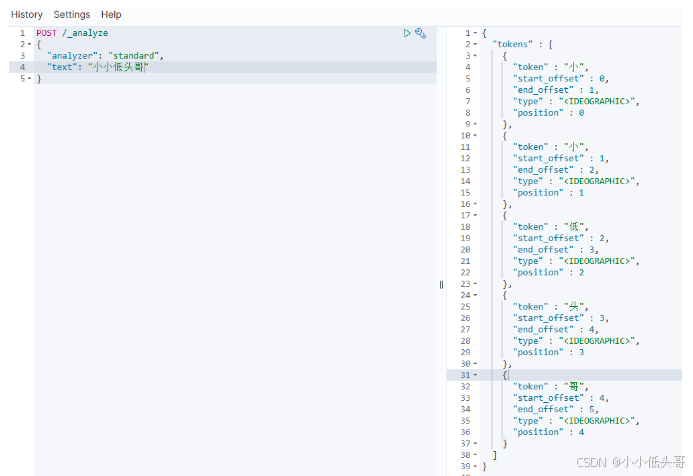
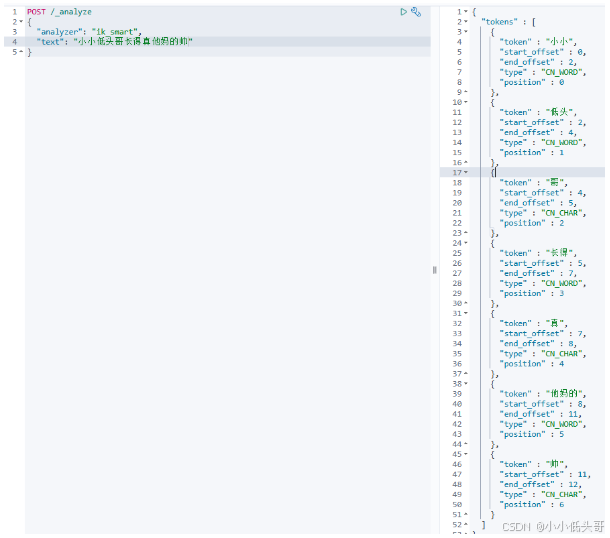
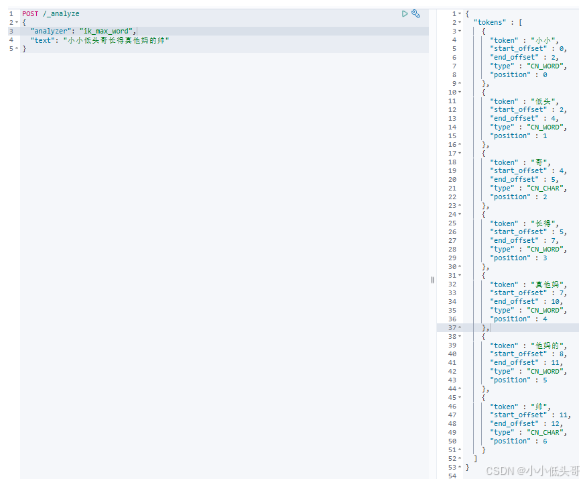
在Kibana的DevTools中可以使用下面的语法来测试IK分词器:

语法说明:
- POST:请求方式
- /_analyze:请求路径,这里省略了http://虚拟机ip:9200 有kibana帮我们补充
- 请求参数,json风格:
- analyzer:分词器类型,这里默认是standard分词器
- text:要分词的内容
1.4 基础概念
elasticsearch中的文档数据会被序列化为json格式后存储在elasticsearch中。

索引(index): 相同类型的文档的集合,可以称为数据库
映射(mapping): 索引中文档的字段约束信息,类似表的结构约束
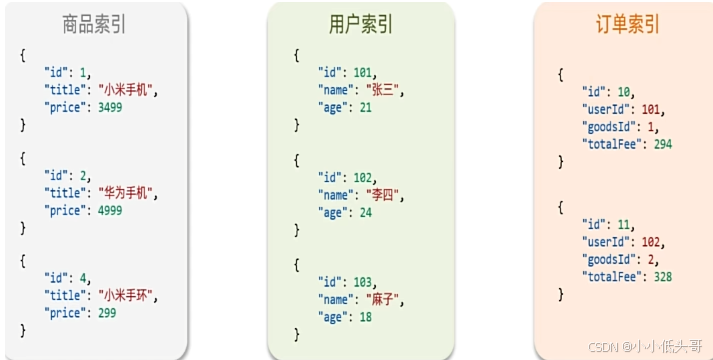
1.4.1 elasticsearch与数据库对比
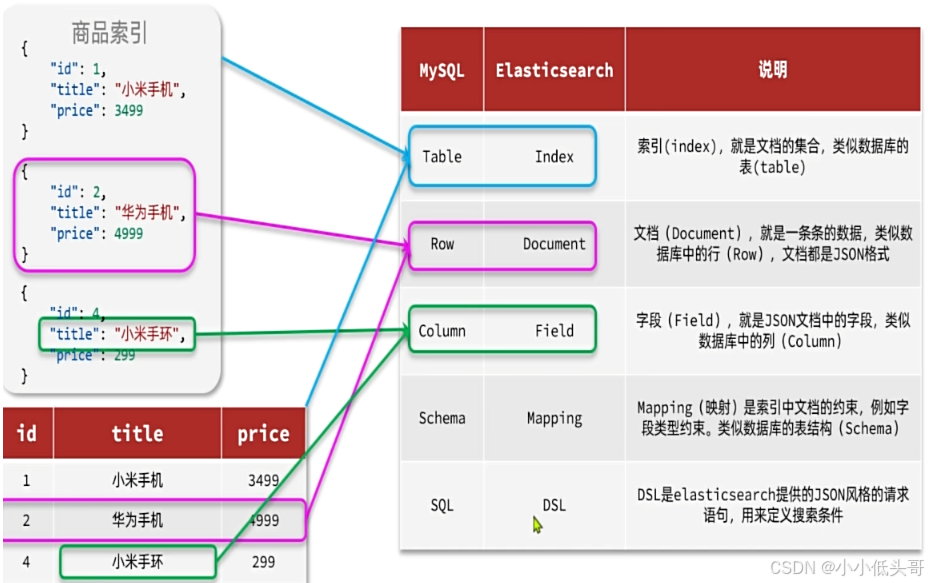
2 索引库的操作
2.1 Mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true(如果字段不参与索引、不参与排序,则可以不用索引)
- analyzer:使用哪种分词器(一般只有可分词的文本才需要分词器)
- properties:该字段的子字段
例如下面的json文档:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "黑马程序员Java讲师",
"email": "[email protected]",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}
对应的每个字段映射(Mapping):
| 字段名 | 字段类型 | 类型说明 | 是否 参与搜索 | 是否参与分词 | 分词器 | |
|---|---|---|---|---|---|---|
| age | integer | 整数 | —— | |||
| weight | float | 浮点数 | —— | |||
| isMarried | boolean | 布尔 | —— | |||
| info | text | 字符串,但需要分词 | IK | |||
keyword | 字符串,但是不分词 | —— | ||||
| score | float | 只看数组中元素类型 | —— | |||
| firstName | keyword | 字符串,但是不分词 | —— | |||
| lastName | keyword | 字符串,但是不分词 | —— |
name是个object类型,有两个properties,每个子字段都需要单独指定类型
2.2 索引库操作
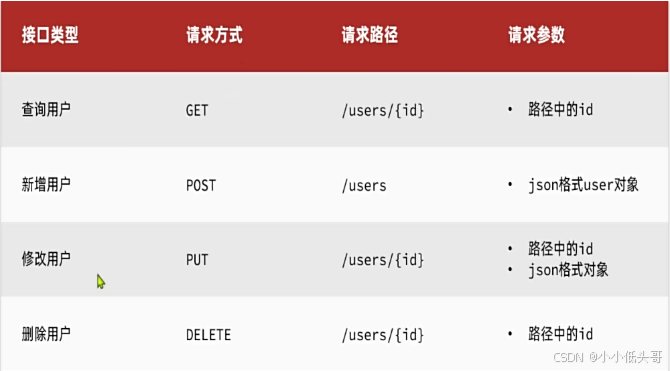
Elasticsearch提供的所有API都是Restful的接口,遵循Restful的基本规范:
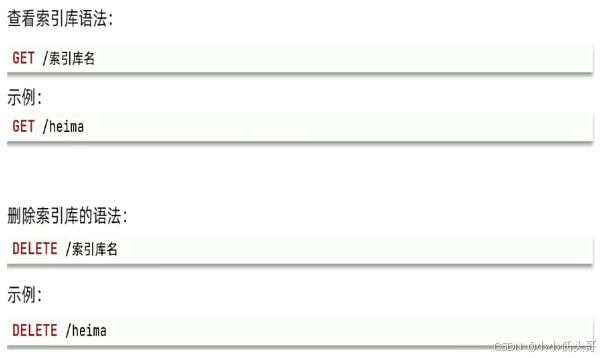
创建索引库和mapping的请求语法如下:

#创建索引库并设置mapping映射
PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart",
"index": true
},
"age":{
"type": "byte"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName": {
"type": "keyword"
},
"lastName":{
"type": "keyword"
}
}
}
}
}
}
#查询索引库
GET /heima
#删除索引库
DELETE /heima
索引库和mapping一旦创建无法修改,但是可以添加新的字段,语法如下:


3 文档操作
3.1 文档CRUD
新增文档的请求格式如下:
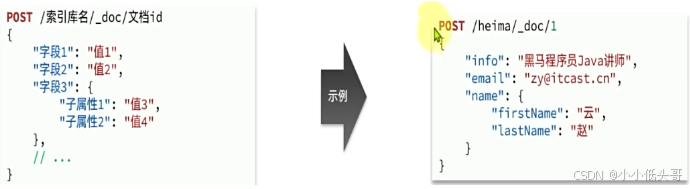
查看文档请求格式:

删除索引库的请求格式:

# 新增文档
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"age": 35,
"email": "[email protected]",
"name": {
"first": "云",
"lastname": "赵"
}
}
# 查询文档
GET /heima/_doc/1
# 删除文档
DELETE /heima/_doc/1
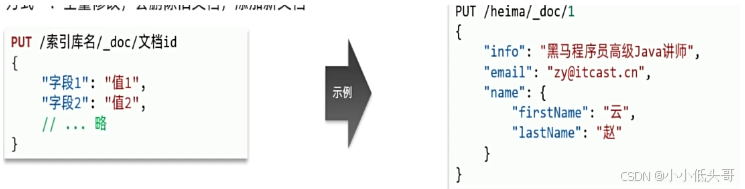
修改索引库:
-
方式一:全量修改,会删除旧文档,添加新文档
# 全量修改 PUT /heima/_doc/1 { "info": "黑马程序员JAVA讲师", "age": 40, "email": "[email protected]", "name": { "first": "云", "lastname": "赵" } }如果修改的id不存在,则会直接创建一个此id的新文档
-
方式二:增量修改,修改指定字段值
# 增量修改 POST /heima/_update/1 { "doc": { "email": "[email protected]" } }


3.2 批量处理
Elasticsearch中允许通过一次请求中携带多次文档操作,也就是批量处理,语法格式如下:

# 批量新增
POST /_bulk
{"index":{"_index":"heima","_id":"3"}}
{"info":"黑马程序员C++讲师","email":"[email protected]","name":{"firstName":"五","lastName":"王"}}
{"index":{"_index":"heima","_id":"4"}}
{"info":"黑马程序员前端讲师","email":"[email protected]","name":{"firstName":"三","lastName":"张"}}
# 批量删除
POST /_bulk
{"delete":{"_index":"heima","_id":"3"}}
{"delete":{"_index":"heima","_id":"4"}}
4 JavaRestClient
4.1 客户端初始化
Elasticsearch目前最新版本是8.0,其]ava客户端有很大变化。不过大多数企业使用的还是8以下版本,所以我们选择使用早期的)avaRestClient客户端来学习
-
引入es的RestHighLevelClient依赖:
-
因为SpringBoot默认的ES版本是7.17.0,所以需要覆盖默认的ES版本:
-
初始化RestHighLevelClient:



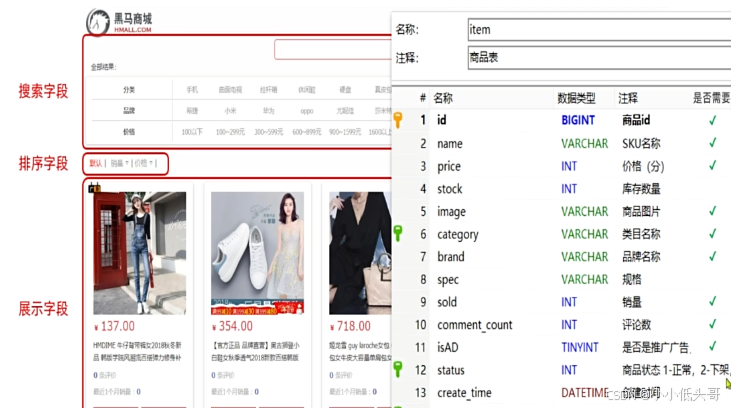
4.2 商品表Mapping映射
要实现商品搜索,那么索引库的字段肯定要满足页面搜索的需求:
#商品索引库
PUT /hmall
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name": {
"type": "text",
"analyzer": "ik_smart"
},
"price":{
"type": "integer"
},
"image":{
"type": "keyword",
"index":false
},
"category":{
"type":"keyword"
},
"brand":{
"type": "keyword"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer",
"index": false
},
"isAD":{
"type": "boolean"
},
"updateTime":{
"type": "date"
}
}
}
}
4.3 索引库操作
创建索引库 的Java与Restful接口API对比:
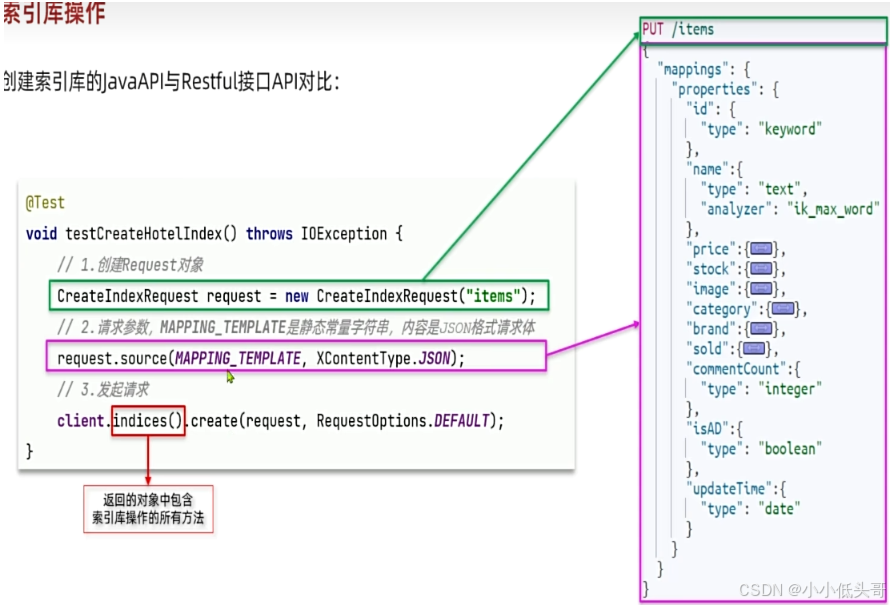
删除索引库:

查询索引库信息:

public class ElasticTest {
private RestHighLevelClient client;
@Test
void testConnection(){
System.out.println("client=" + client);
}
@Test
void testCreateIndex() throws IOException {
//1. 准备Request对象
CreateIndexRequest request = new CreateIndexRequest("items");
//2. 准备请求参数
request.source(MAPPING_TEMPLATE, XContentType.JSON);
//3. 发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
@Test
void testGetIndex() throws IOException {
//1. 准备Request对象
GetIndexRequest request = new GetIndexRequest("items");
//2. 发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
@Test
void testDeleteIndex() throws IOException {
//1. 准备Request对象
DeleteIndexRequest request = new DeleteIndexRequest("items");
//2. 发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
@BeforeEach
void setUp(){
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.154.128:9200")
));
}
@AfterEach
void tearDown() throws IOException {
if(client != null){
client.close();
}
}
private static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\": {\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_smart\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"image\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\":false\n" +
" },\n" +
" \"category\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"sold\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"commentCount\":{\n" +
" \"type\": \"integer\",\n" +
" \"index\": false\n" +
" },\n" +
" \"isAD\":{\n" +
" \"type\": \"boolean\"\n" +
" },\n" +
" \"updateTime\":{\n" +
" \"type\": \"date\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}

4.4 文档操作
新增文档 的javaAPI如下:

删除文档 的JavaAPI如下:

查询文档 包含查询和解析响应结果两部分,对应的JavaAPI如下:
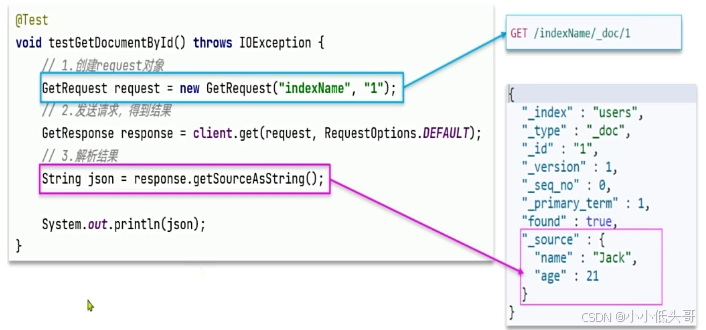
**文档操作: **
修改文档那个数据有两种方式:
- 方式一:全量更新,再次写入id一样的文档,就会删除旧文档,添加新文档。与新增的JavaAPI一致 。
- 方式二:局部更新。只更新指定部分字段

@SpringBootTest(properties = "spring.profiles.active=local")
public class ElasticDocumentTest {
private RestHighLevelClient client;
@Autowired
private IItemService iItemService;
@Test
void testIndexDoc() throws IOException {
//0. 准备文档数据
//0.1 根据id查询数据库数据
Item item = iItemService.getById(100000011127L);
//0.2 把数据库数据转为文档数据
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
//设置此项,则会修改索引库中对应文档的数据,相当于修改操作
itemDoc.setPrice(29900);
//1. 准备Request
IndexRequest request = new IndexRequest("items").id(itemDoc.getId());
//2. 准备请求参数
request.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON);
//3. 发送请求
client.index(request, RequestOptions.DEFAULT);
}
@Test
void testUpdateDoc() throws IOException{
//1. 准备Request
UpdateRequest request = new UpdateRequest("items", "100000011127");
//2. 准备请求的参数
request.doc(
"price",25600,
"sold",45000
);
//2. 发送请求
client.update(request,RequestOptions.DEFAULT);
}
@Test
void testGetDoc() throws IOException {
//1. 准备Request
GetRequest request = new GetRequest("items","100000011127");
//2. 发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3. 解析响应结果
String json = response.getSourceAsString();
ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class);
System.out.println("doc = " + doc);
}
@Test
void testDeleteDoc() throws IOException {
//1. 准备Request
DeleteRequest request = new DeleteRequest("items","100000011127");
//2. 发送请求
client.delete(request, RequestOptions.DEFAULT);
}
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.154.128:9200")
));
}
@AfterEach
void tearDown() throws IOException {
if (client != null) {
client.close();
}
}
}

4.5 批处理
批处理代码流程与之前类似,只不过构建请求会用到一个名为BulkRequest来封装普通的CRUD请求:
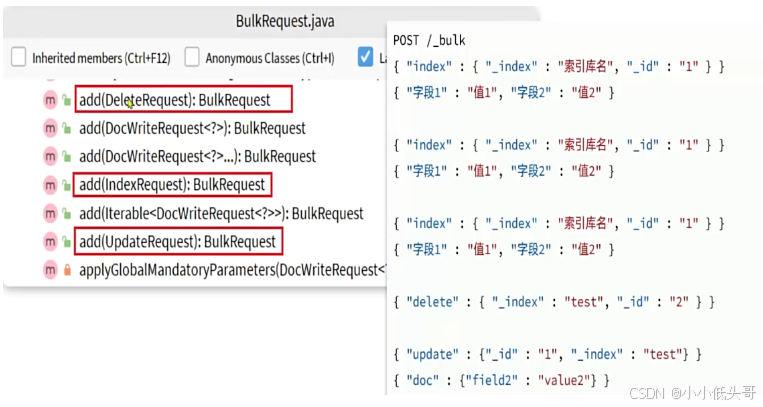
批处理的API实例:

@Test
void testBulkDoc() throws IOException {
int pageNo = 1, pageSize = 500;
//1. 准备文档数据
Page<Item> page = iItemService.lambdaQuery()
.eq(Item::getStatus, 1)
.page(Page.of(pageNo, pageSize));
List<Item> records = page.getRecords();
if(records == null || records.isEmpty()){
return;
}
//1. 准备Request
BulkRequest request = new BulkRequest();
//2. 准备请求参数
for (Item item : records) {
request.add(new IndexRequest("items")
.id(item.getId().toString())
.source(JSONUtil.toJsonStr(BeanUtil.copyProperties(item,ItemDoc.class)),XContentType.JSON));
}
// request.add(new DeleteRequest("items").id("1"));
//3. 发送请求
client.bulk(request, RequestOptions.DEFAULT);
}