【新知实验室-TRTC开发】实时音视频-快速搭建Web互动直播应用
前言
突如其来的疫情,让远程办公常态化成为了可能,无论是工作期间的视频会议/在线教育、屏幕共享/远程控制;或者是闲暇时间的直播、游戏。这些场景都与一项技术息息相关,那就是WebRTC。
WebRTC (Web Real-Time Communications) 是一项实时通讯技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流和(或)音频流或者其他任意数据的传输。
我个人曾经使用过多家的音视频产品,如声网、网易云信、阿里云,那么今天我们动手实验的主角是谁呢,它就是腾讯TRTC。
接下来,我将以demo入手和大家一起体验下互动直播的魅力。
一、快速搭建互动直播应用(web)
1:创建实时音视频 TRTC 应用
1.注册腾讯云账号 并开通 实时音视频 和 即时通信 服务。
首次创建实时音视频应用的腾讯云账号,可获赠一个10000分钟的音视频资源免费试用包。
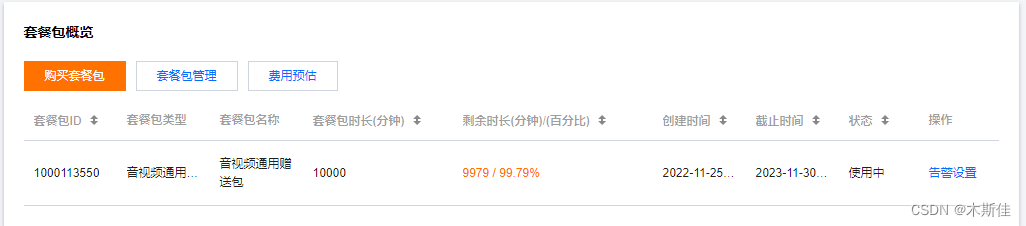
2.在 实时音视频控制台 单击 应用管理 > 创建应用 创建新应用。 创建应用
创建实时音视频应用之后会自动创建一个 SDKAppID 相同的即时通信 IM 应用,可在 即时通信控制台 配置该应用的套餐信息。
获取 TRTC 密钥信息
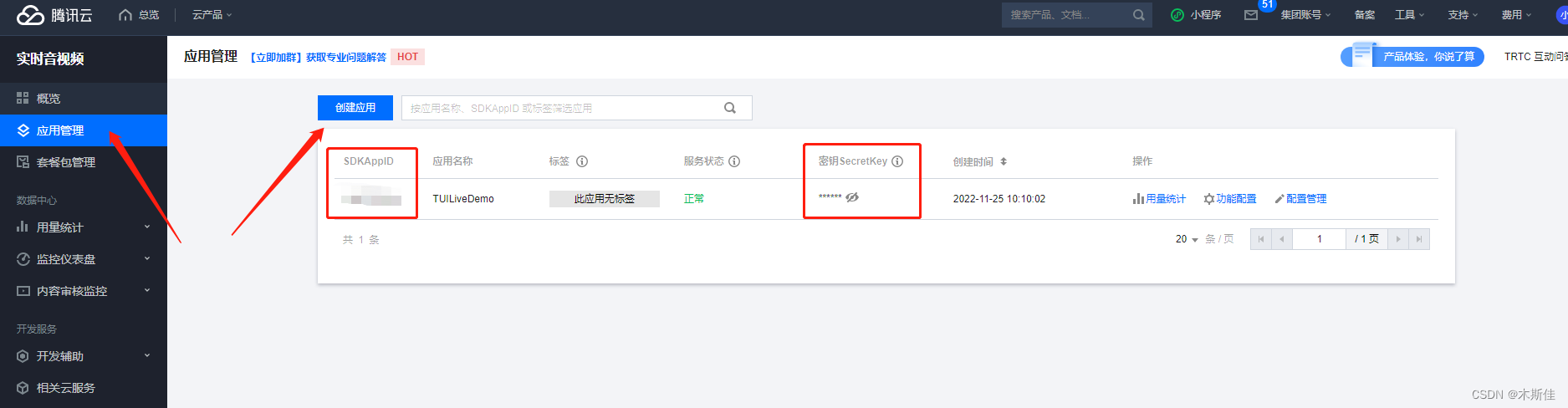
在 应用管理页或者 应用管理 > 应用信息 中获取 SDKAppID 信息。
2:Demo示例运行
1.下载 TUIPusher & TUIPlayer 代码。
为 TUIPusher & TUIPlayer 安装依赖。
cd Web/TUIPusher
npm install
cd Web/TUIPlayer
npm install
2.将 sdkAppId 和 secretKey 填入 TUIPusher/src/config/basic-info-config.js 及 TUIPlayer/src/config/basic-info-config.js 配置文件中。
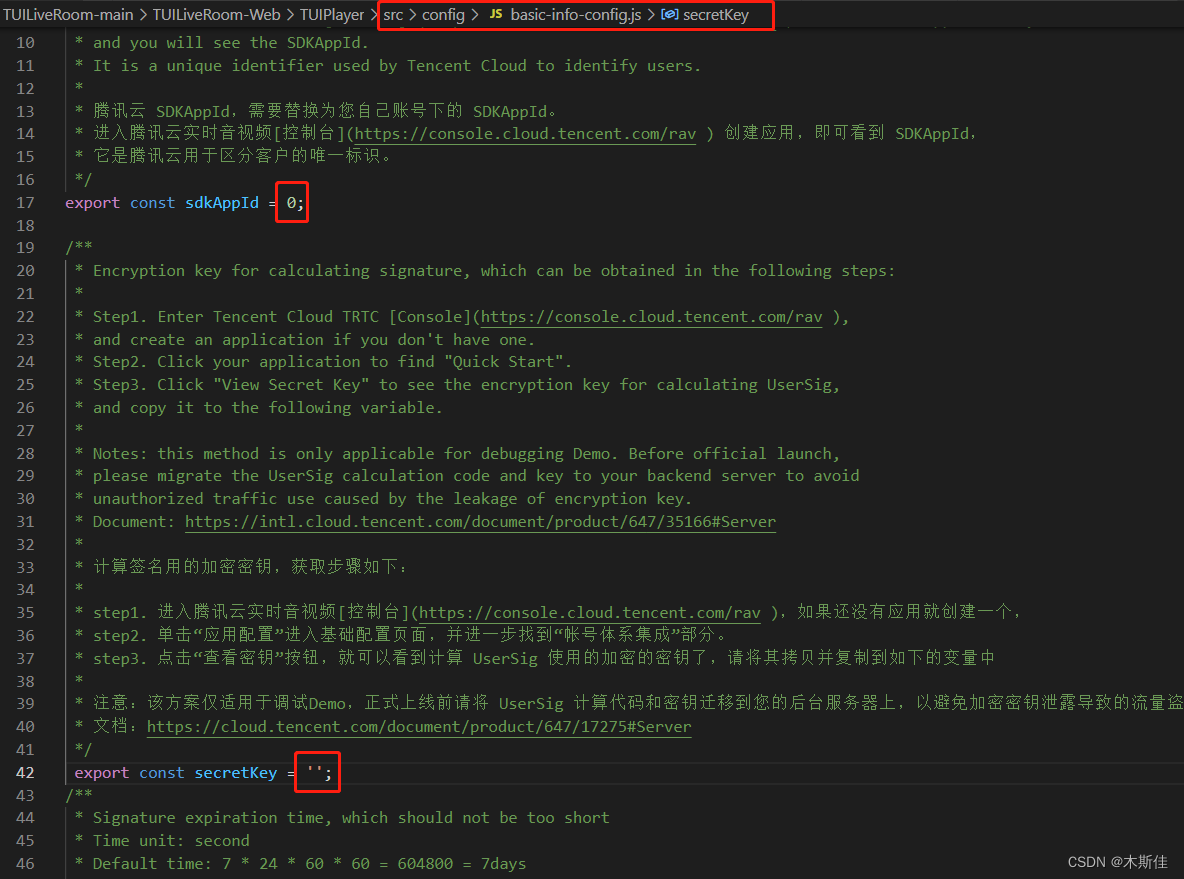
3.本地开发环境运行 TUIPusher & TUIPlayer。
cd Web/TUIPusher
npm run serve
cd Web/TUIPlayer
npm run serve
可打开 http://localhost:8080 和 http://localhost:8081 体验 TUIPusher 和 TUIPlayer 功能。
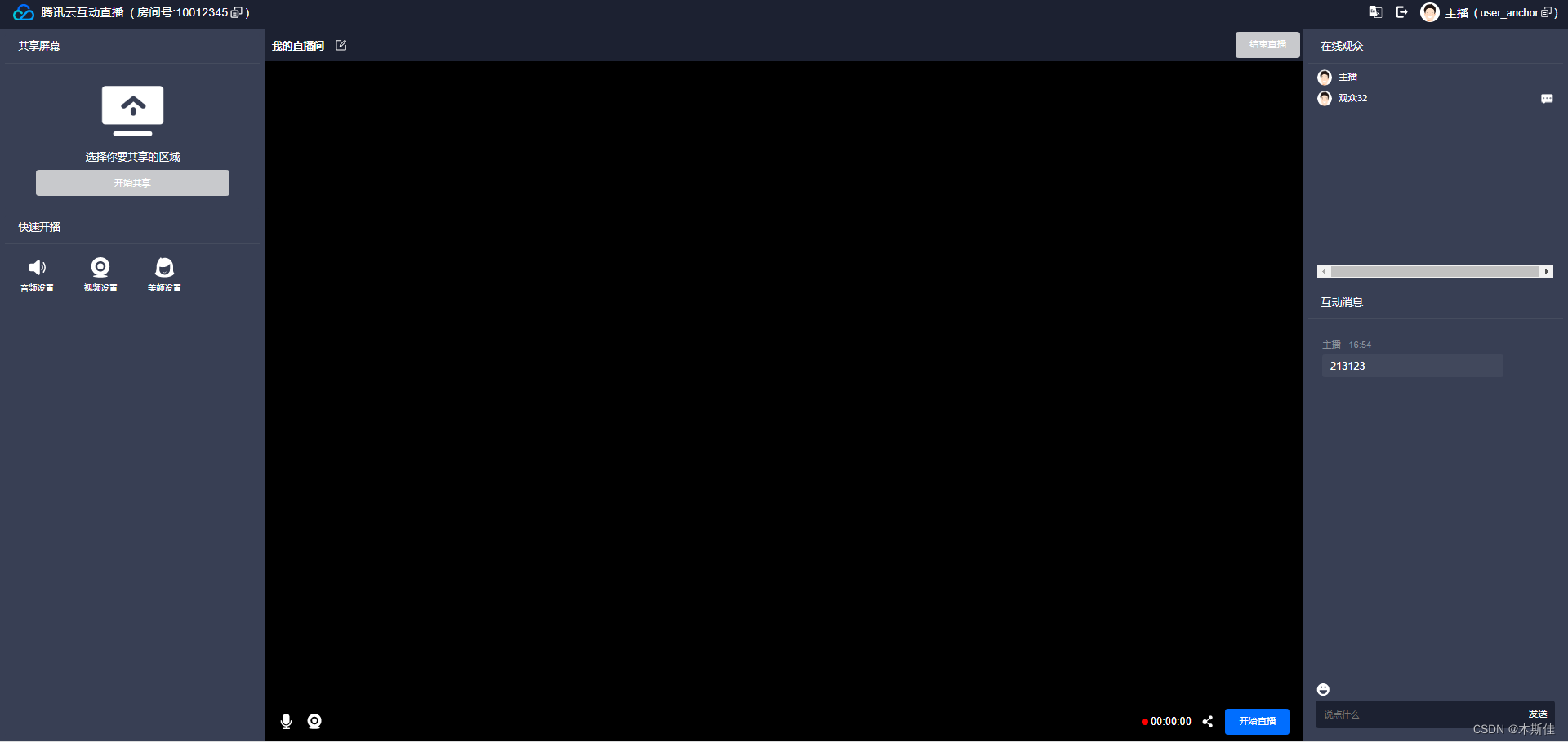
可更改 TUIPusher/src/config/basic-info-config.js 及 TUIPlayer/src/config/basic-info-config.js 配置文件中的房间,主播及观众等信息,注意保持 TUIPusher 和 TUIPlayer 的房间信息,主播信息一致。
到这里我们的初级玩法已经结束,当主播发起直播时,在用户端进入直播间即可互动。
二、基于Demo加点新玩法-虚拟形象互动
1.直播、实时音视频、互动直播、旁路直播有什么区别。
如果我们想要基于现有的demo进行二次开发,那么再次之前,我们先简单了解一些技术上的业务区别。
-
直播,是一对多的流媒体系统,通常为推流端(主播)、拉流端(观众)、直播流媒体中心(平台),由于直播观众分布区域广,会用CDN分发,通常使用传输使用RTMP、HTTP-FLV、HLS(支持H5)协议,直播只有一个推流端,观众端延时往往有3-5秒。而我们这里已经实现了推流端(主播)、拉流端(观众),而这也是我们所需关注的。
-
实时音视频(RTC),用于双人或多人群组通话,比如微信语音视频,要求低延时,采用UDP私有协议,延时可低于100ms,参与通话的人基本上感觉不到延时。
-
互动直播(连麦),互动直播是基于实时音视频基础之上的,主播可以和观众或其他主播进行音视频通话,这时候要解决延时和回声的技术问题,现在不仅仅只是多个主播连麦,多个直播间PK也都能做到了。
-
旁路直播,将实时音视频流转换成标准直播流,观众看到不是多个主播的流,而是把多个主播的流混合在一起的一个画面,即便客户没有安装客户端需要通过小程序、网页观看,也能通过旁路直播来实现观看。这个时候主播和主播之间是实时的,主播和观众之间的延时大概还有3-5秒。
2.TRTC的应用场景。
- 社交娱乐:直播pk、社交、游戏、电商、在线k歌
- 在线教育:在线授课、在线考试等等
- 企业数字化:视频会议、白板互动
- 元宇宙创新应用
- 等等
比如基于TRTC+ three.js +tracker.js 我们可以实现AI换脸,虚拟形象等一些有趣的小应用。
3.虚拟形象互动-AI换脸实现
如何实现视频流的AI换脸呢,接下来重点介绍几个api
1.自定义采集视频流与动画
本地流在通过 createStream() 创建时,可以指定使用 SDK 的默认采集方式,
入参audio: true, video: true 来从摄像头和麦克风采集音视频数据,
const localStream = TRTC.createStream({ userId, audio: true, video: true });
localStream.initialize().then(() => {
// local stream initialized success
});
如果要获取视频分享流,可以使用
const localStream = TRTC.createStream({ userId, audio: false, screen: true });
localStream.initialize().then(() => {
// local stream initialized success
});
createStream 支持从外部音视频源创建本地流,通过这种方式创建本地流,我们可以实现自定义采集,比如说:
- 可以通过使用 getUserMedia 采集摄像头和麦克风音视频流。
- 通过 getDisplayMedia 采集屏幕分享流。
- 通过 captureStream 采集页面中正在播放的音视频。
- 通过 captureStream 采集 canvas 画布中的动画。
基于这些Api我们可以实现AI换脸、AI变声、手势动作、虚拟形象、视频背景及一些好玩的小交互。
2.采集页面中正在播放的视频源
// 检测您当前的浏览器是否支持从 video 元素采集 stream
const isVideoCapturingSupported = () => 'captureStream' in HTMLVideoElement.prototype;
// 检测您当前的浏览器是否支持从 video 元素采集 stream
if (!isVideoCapturingSupported()) {
console.log('your browser does not support capturing stream from video element');
return
}
// 获取您页面在播放视频的 video 标签
const video = document.getElementByID('your-video-element-ID');
// 从播放的视频采集视频流
const stream = video.captureStream();
const audioTrack = stream.getAudioTracks()[0];
const videoTrack = stream.getVideoTracks()[0];
const localStream = TRTC.createStream({ userId, audioSource: audioTrack, videoSource: videoTrack });
// 请确保视频属性跟外部传进来的视频源一致,否则会影响视频通话体验
localStream.setVideoProfile('480p');
localStream.initialize().then(() => {
// local stream initialized success
});
3.捕捉人脸重新渲染
1.视频流的人脸识别,
这里有很多开源框架可以选择,比如:TensorFlow.js 、Tracking.js、face-api.js等。跑一个demo的话可以直接使用face-api.js的案例去替换。
face-api.js基于 TensorFlow.js 内核,实现了三种卷积神经网络架构,用于完成人脸检测、识别和特征点检测任务;其内部实现了一个非常轻巧,快速,准确的 68 点面部标志探测器。支持多种 tf 模型,微小模型仅为 80kb。另外,它还支持 GPU 加速,相关操作可以使用 WebGL 运行。

这里引入不多叙述。face-api官方有相关的示例代码。
其中video和face-api.js的canvas的宽高保持一致,canvas用于绘制检测到的人脸的盒子 ,这里只给出人脸检测的思路代码。
/** @name 人脸检测 */
async detectFace(): Promise<void> {
//requestAnimationFrame防止卡死
await new Promise(resolve => requestAnimationFrame(resolve));
//绘制取景框
this.drawViewFinder();
if (
!this.canvas ||
!this.video ||
!this.video.currentTime ||
this.video.paused ||
this.video.ended
)
return this.detectFace();
// 检测图像中具有最高置信度得分的脸部
const result = await detectSingleFace(this.video, this.options);
if (!result) return this.detectFace();
// 匹配尺寸
const dims = matchDimensions(this.canvas, this.video, true);
// 调整检测到的框的大小,以防显示的图像的大小与原始
const resizedResult = resizeResults(result, dims);
const box = resizedResult.box;
// 检测框是否在取景框内
if (!this.checkInViewFinder(box)) return this.detectFace();
this.drawViewFinder();
// 将检测结果绘制到画布(此处不用,可以直接用来绘制检测到的人脸盒子)
// draw.drawDetections(this.canvas, resizedResult.box);
this.drawBox(box, "识别中");
this.video.pause();
//截取人脸图片
const image = await this.cameraShoot(
this.video,
resizedResult.box.topLeft,
resizedResult.box.width,
resizedResult.box.height
);
if (!image) {
this.drawBox(box, "识别失败");
await delay(1000);
this.video.play();
return this.detectFace();
}
let files = new window.File([image], "人脸头像.jpeg", {
type: "image/jpeg"
});
//调用接口传入截取的人脸头像进行检测
const detectResult = await this.computedService.faceDetect(
this.formId,
files
);
if (!detectResult) {
this.drawBox(box, "识别失败");
await delay(1000);
this.video.play();
return this.detectFace();
}
//停止视频
this.handleStopVideo();
}
2.AI换脸重新渲染
上部分我们已经实现将视频切割成图片,并进行人脸提取 ,接下来就是进行样本训练和换脸,因为篇幅就不多介绍了,这里挂出一个比较经典的python换脸开源软件,感兴趣的老铁可以自行了解。
github链接: Faceswap
重新渲染时,对于通过 TRTC.createStream() 创建并初始化好的本地流或者通过 Client.on(‘stream-added’) 接收到的远端流,可以通过音视频流对象的 Stream.play() 方法进行音频和视频的播放渲染,Stream.play() 内部会自动创建音频播放器和视频播放器并播放
提示:在 ‘stream-added’ 与 ‘stream-updated’ 两个事件的处理回调中,都必须检查是否有音频或视频 track,在 ’stream-updated‘ 事件处理中,如果有音频或视频 track,那么请务必更新播放器并使用最新的音视频 track 进行播放。
到这里其实我们已经实现了虚拟形象互动,那么主播声音如何改变呢?
3.虚拟形象互动-音效处理
1.背景音乐混音播放
在项目中安装 RTCAudioMixer 插件。
npm install rtc-audio-mixer@latest
1.创建音乐实例
AudioMixerPlugin 插件需要和 TRTC 在同一作用域引入。
import TRTC from 'trtc-js-sdk';
import AudioMixerPlugin from 'rtc-audio-mixer';
调用 AudioMixerPlugin.createAudioSource(params) 方法创建一个 AudioSource 的音乐实例,参数如下:
- url :String类型,必选,音乐文件的地址,可使用线上文件地址,也可以使用本地选择音乐文件生成的 blob URL。
- loop: Boolean类型,可选,是否循环播放,默认 false 不循环。
- volume:Number类型,可选,音量设置(0 - 1), 默认为1。
播放在线音效文件时,音效文件必须支持 CORS ,且访问协议必须为 https 协议。
支持的格式为 MP3,AAC(以及浏览器支持的其他音频格式)。
网页在没有用户交互之前,浏览器禁止网页播放带有声音的媒体,建议引导用户执行点击行为后播放 AudioSource.play(), 参考:Autoplay_guide 。
2.发布混音后的音频流
调用 AudioMixerPlugin.mix(params) 方法,获取已加入背景音乐的 mixedAudioTrack,可用于替换发布流的音频轨道:
- targetTrack: 可选,需要加入背景音乐的音频轨道。当不传递的时候则生成只有背景音的轨道。
- sourceList: 必选,Array类型,传入第一步创建的音乐实例,例如: [ audioSourceA, audioSourceB ]。
这里我们在 localStream 发布之前,将 mixedAudioTrack 替换掉 localStream 里的音频轨道。
let audioSourceA = AudioMixerPlugin.createAudioSource({url: '资源A的url'});
let audioSourceB = AudioMixerPlugin.createAudioSource({url: '资源B的url'});
const localStream = TRTC.createStream({userId: 'user', audio: true, video: true});
await localStream.initialize();
// 1. 获取麦克风轨道
let originAudioTrack = localStream.getAudioTrack();
// 2. 与 audioSourceA audioSourceB 混合后生成 mixedAudioTrack
mixedAudioTrack = AudioMixerPlugin.mix({targetTrack: originAudioTrack, sourceList: [audioSourceA, audioSourceB]});
// 3. 替换麦克风轨道
localStream.replaceTrack(mixedAudioTrack);
// 4. 发布
client.publish(localStream);
// 5. 调用 play 方法播放,这时通话双方都能听到背景音乐
audioSourceA.play();
2.实现 3D 空间音频
在像社交元宇宙等场景下,需要一些立体声效果来让用户感知游戏角色周围其他用户的存在及其对应的距离和方位,提高语音通话的趣味性。而 TRTC 是支持3D 空间音频功能的。
空间音频功能需要加载 对应SDK,node_modules/trtc-js-sdk 目录,有一个 trtc-spatial.js 用于专门实现 3D 空间音频
// 当您的应用需要空间音频时
import TRTC from 'trtc-js-sdk/trtc-spatial.js';
具体实现
// 创建 client
const client = TRTC.createClient({ mode: 'rtc', sdkAppId, userId, userSig });
const { detail } = await TRTC.checkSystemRequirements();
// 如果你需要使用空间音频,你应该在加入房间前启用它。
if (detail.isSpatialAudioSupported) {
client.enable3DSpatialAudioEffect(true);
}
// 加入房间
await client.join({ roomId: 8888 });
// 如果有远端用户加入,你会收到事件通知。
client.on('stream-added', event => {
const remoteStream = event.stream;
console.log('New remote stream:' + remoteStream.getId());
// 订阅到远端流
client.subscribe(remoteStream);
});
client.on('stream-subscribed', event => {
const remoteStream = event.stream;
console.log('成功订阅了远程流:' + remoteStream.getId());
// 播放远端流
remoteStream.play('remote_stream-' + remoteStream.getId());
});
// 当你成功订阅了一个用户,你可以实时更新他们的位置信息。
client.updateRemote3DSpatialPosition('tom', [100, 200, 0]);
// 你同时也可以更新自己的位置信息
client.updateSelf3DSpatialPosition([100, 0, 0], [2, 1, 0], [-1, 2, 0], [0, 0, 1]);
3.实时变声
在像社交元宇宙等场景下,互动形式也不再止于语音聊天,有了更为高阶的需求,比如:主播通过通过外带的声卡或者其他的技术手段进行“变声“。大叔变萝莉,萌妹变宅男,这些都让虚拟直播里的语音互动变得更具娱乐性。
腾讯云游戏多媒体引擎 GME(Game Multimedia Engine)提供了一站式游戏语音解决方案。通过GME的引入,可以实现更多有趣的场景。这里就留给大家去探索吧。

结语
到此为止我们已经深入体验了腾讯TRTC,个人感觉还是非常容易上手的。一方面文档比较清晰,提供的示例代码基本可以轻松跑起来一个成熟应用去实验,大家一起来动手吧。