Rocketmq和kafka这两个消息队列大家应该都比较熟悉吧,哪怕不是很熟悉,应该也听说过的吧,你别告诉我,作为一个资深的程序员,你没听过这两门技术。
我之前使用这两个消息队列的时候就遇到一个很奇怪的问题,就是在kafka里面弄了比较多的topic,性能下降的速度贼快,不知道大家遇到过没,而同样的场景切换到消息队列rocketmq中,下降速度却没有那么快。
不熟悉这俩消息队列结构的朋友,一听这个肯定还是不太清楚的,今天我来给大家分析分析这其中的原因,给大家解惑。
rocketmq的结构
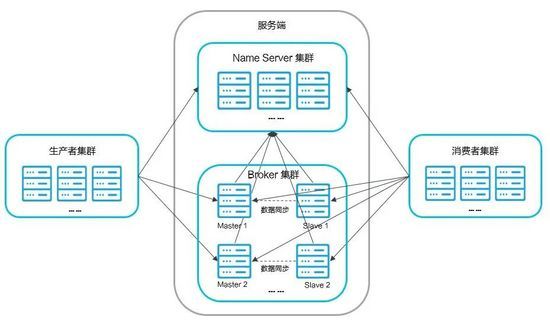
NameServer:主要是对元数据的管理,包括Topic和路由信息的管理,底层由netty实现,是一个提供路由管理、路由注册和发现的无状态节点,类似于ZooKeeper
Broker:消息中转站,负责收发消息、持久化消息
Producer:消息的生产者,一般由业务系统来产生消息供消费者消费
Consumer:消息的消费者,一般由业务系统来异步消费消息
在RocketMQ中的每一条消息,都有一个Topic,用来区分不同的消息。一个主题一般会有多个消息的订阅者,当生产者发布消息到某个主题时,订阅了这个主题的消费者都可以接收到生产者写入的新消息。
在Topic中有分为了多个Queue,这其实是我们发送/读取消息通道的最小单位,我们发送消息都需要指定某个写入某个Queue,拉取消息的时候也需要指定拉取某个Queue,所以我们的顺序消息可以基于我们的Queue维度保持队列有序,如果想做到全局有序那么需要将Queue大小设置为1,这样所有的数据都会在Queue中有序。
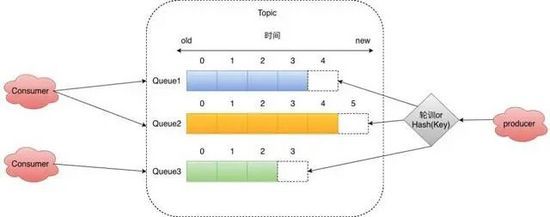
我们同一组Consumer会根据一些策略来选Queue,常见的比如平均分配或者一致性Hash分配。
要注意的是当Consumer出现下线或者上线的时候,这里需要做重平衡,也就是Rebalance,RocketMQ的重平衡机制如下:
定时拉取broker,topic的最新信息,每隔20s做重平衡,随机选取当前Topic的一个主Broker,这里要注意的是不是每次重平衡所有主Broker都会被选中,因为会存在一个Broker再多个Broker的情况。
获取当前Broker,当前ConsumerGroup的所有机器ID。然后进行策略分配。
由于重平衡是定时做的,所以这里有可能会出现某个Queue同时被两个Consumer消费,所以会出现消息重复投递。
Queue读写数量不一致
在RocketMQ中Queue被分为读和写两种,在最开始接触RocketMQ的时候一直以为读写队列数量配置不一致不会出现什么问题的,比如当消费者机器很多的时候我们配置很多读的队列,但是实际过程中发现会出现消息无法消费和根本没有消息消费的情况。
当写的队列数量大于读的队列的数量,当大于读队列这部分ID的写队列的数据会无法消费,因为不会将其分配给消费者。
当读的队列数量大于写的队列数量,那么多的队列数量就不会有消息被投递进来。

rocketmq中的存储机制
RocketMQ凭借其强大的存储能力和强大的消息索引能力,以及各种类型消息和消息的特性脱颖而出,于是乎,我们这些有梦想的程序员学习RocketMQ的存储原理也变得尤为重要
而要说起这个存储原理,则不得不说的就是RocketMQ的消息存储文件commitLog文件,消费方则是凭借着巧妙的设计Consumerqueue文件来进行高性能并且不混乱的消费,还有RocketMQ的强大的支持消息索引的特性,靠的就是indexfile索引文件
我们这篇文章就从这commitLog、Consumerqueue、indexfile这三个神秘的文件说起,搞懂这三个文件,RocketMQ的核心就被你掏空了
先上个图,写入commitLog文件时commitLog和Consumerqueue、indexfile文件三者的关系
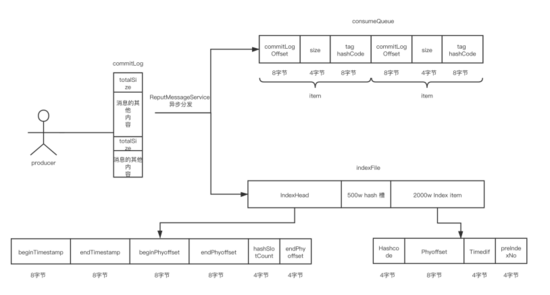
commitLog
RocketMQ中的消息存储文件放在${ROCKET_HOME}/store 目录下,当生产者发送消息时,broker会将消息存储到Commit文件夹下,文件夹下面会有一个commitLog文件,但是并不是意味着这个文件叫这个,文件命名是根据消息的偏移量来决定的。
文件有自己的生成规则,每个commitLog文件的大小是1G,一般情况下第一个 CommitLog 的起始偏移量为 0,第二个 CommitLog 的起始偏移量为 1073741824 (1G = 1073741824byte)。
commitLog文件的最大的一个特点就是消息的顺序写入,随机读写,所有的topic的消息都存储到commitLog文件中,顺序写入可以充分的利用磁盘顺序减少了IO争用数据存储的性能,kafka也是通过硬盘顺序存盘的。
大家都常说硬盘的速度比内存慢,其实这句话也是有歧义的,当硬盘顺序写入和读取的时候,速度不比内存慢,甚至比内存速度快,这种存储方式就好比数组,我们如果知道数组的下标,则可以直接通过下标计算出位置,找到内存地址,众所周知,数组的读取是很快的,但是数组的缺点在于插入数据比较慢,因为如果在中间插入数据需要将后面的数据往后移动。
而对于数组来说,如果我们只会顺序的往后添加,数组的速度也是很快的,因为数组没有后续的数据的移动,这一操作很耗时。
回到RocketMQ中的commitLog文件,也是同样的道理,顺序的写入文件也就不需要太多的去考虑写入的位置,直接找到文件往后放就可以了,而取数据的时候,也是和数组一样,我们可以通过文件的大小去精准的定位到哪一个文件,然后再精准的定位到文件的位置。

consumerqueue文件
RocketMQ是分为多个topic,消息所属主题,属于消息类型,每一个topic有多个queue,每个queue放着不同的消息,在同一个消费者组下的消费者,可以同时消费同一个topic下的不同queue队列的消息。不同消费者下的消费者,可以同时消费同一个topic下的相同的队列的消息。而同一个消费者组下的消费者,不可以同时消费不同topic下的消息。
而每个topic下的queue队列都会对应一个Consumerqueue文件,这个存储的就是对应的commitLog文件中的索引位置,而不用存储真实的消息。
consumequeue存放在store文件里面,里面的consumequeue文件里面按照topic排放,然后每个topic默认4个队列,里面存放的consumequeue文件。
ConsumeQueue中并不需要存储消息的内容,而存储的是消息在CommitLog中的offset。也就是说ConsumeQueue其实是CommitLog的一个索引文件。
consumequeue是定长结构,每个记录固定大小20个字节,单个consumequeue文件默认包含30w个条目,所以单个文件大小大概6M左右。
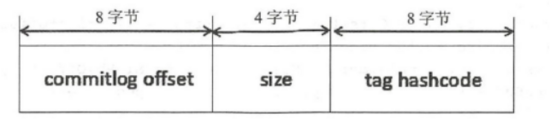
很显然,Consumer消费消息的时候,要读2次:先读ConsumeQueue得到offset,再通过offset找到CommitLog对应的消息内容。
IndexFile
RocketMQ还支持通过MessageID或者MessageKey来查询消息,使用ID查询时,因为ID就是用broker+offset生成的(这里msgId指的是服务端的),所以很容易就找到对应的commitLog文件来读取消息。
对于用MessageKey来查询消息,MessageStore通过构建一个index来提高读取速度。
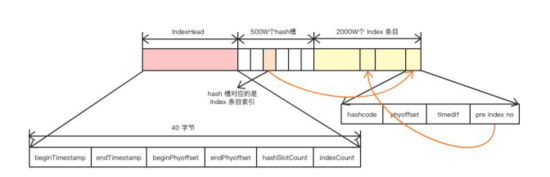
indexfile文件存储在store目录下的index文件里面,里面存放的是消息的hashcode和index内容,文件由一个文件头组成:长40字节。500w个hashslot,每个4字节。2000w个index条目,每个20字节。
所以这里我们可以估算每个indexfile的大小为:40+500w4+2000w20个字节,大约400M左右。
每放入一个新消息的index进来,首先会取MessageKey的HashCode,然后用Hashcode对slot的总数进行取模,决定该消息key的位置,slot的总数默认是500W个。
只要取hash就必然面临着hash冲突的问题,indexfile也是采用链表结构来解决hash冲突,这一点和HashMap一样的,不过这个不存在红黑树转换这一说,个人猜测这个的冲突数量也达不到很高的级别,所以进行这方面的设计也没啥必要,甚至变成了强行增加indexfile的文件结构难度。
还有,在indexfile中的slot中放的是最新的index的指针,因为一般查询的时候大概率是优先查询最近的消息。
每个slot中放的指针值是索引在indexfile中的偏移量,也就是后面index的位置,而index中存放的就是该消息在commitlog文件中的offset,每个index的大小是20字节,所以根据当前索引是这个文件中的第几个偏移量,也就很容易定位到索引的位置,根据前面的固定大小可以很快把真实坐标算出来,以此类推,形成一个链表的结构。
kafka的结构
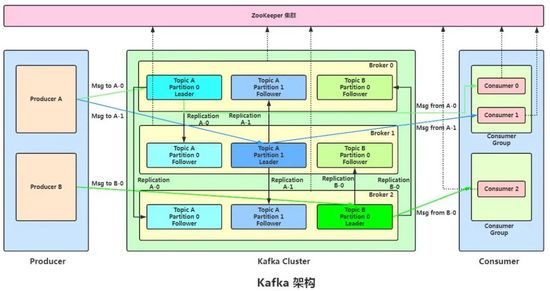
Broker:消息中间件处理节点(服务器),一个节点就是一个broker,一个Kafka集群由一个或多个broker组成。
Topic:Kafka对消息进行归类,发送到集群的每一条消息都要指定一个topic。
Partition:物理上的概念,每个topic包含一个或多个partition,一个partition对应一个文件夹,这个文件夹下存储partition的数据和索引文件,每个partition内部是有序的。
Producer:生产者,负责发布消息到broker。
Consumer:消费者,从broker读取消息。
ConsumerGroup:每个consumer属于一个特定的consumer group,可为每个consumer指定group name,若不指定,则属于默认的group,一条消息可以发送到不同的consumer group,但一个consumer group中只能有一个consumer能消费这条消息。
kafka存储机制
我们的生产者会决定发送到哪个 Partition,如果没有 Key 值则进行轮询发送。
如果有 Key 值,对 Key 值进行 Hash,然后对分区数量取余,保证了同一个 Key 值的会被路由到同一个分区。(所有系统的partition都是同一个路数)。
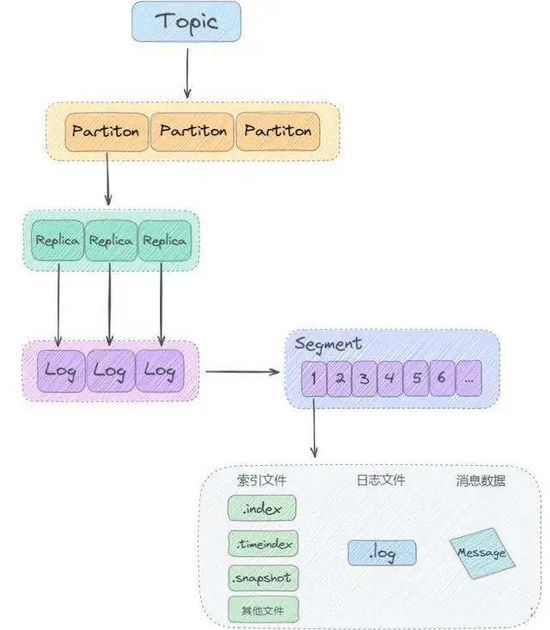
总所周知,topic在物理层面以partition为分组,一个topic可以分成若干个partition,那么topic以及partition又是怎么存储的呢?
其实partition还可以细分为logSegment,一个partition物理上由多个logSegment组成,那么这些segment又是什么呢?
LogSegment 文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为 Segment 索引文件和数据文件。
这两个文件的命令规则为:partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值,数值大小为64位,20位数字字符长度,没有数字用0填充,如下:
第一个segment 00000000000000000000.index 00000000000000000000.log 第二个segment,文件命名以第一个segment的最后一条消息的offset组成 00000000000000170410.index 00000000000000170410.log 第三个segment,文件命名以上一个segment的最后一条消息的offset组成 00000000000000239430.index 00000000000000239430.log
“.index”索引文件存储大量的元数据,“.log”数据文件存储大量的消息,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
kafka和rocketmq的比较
RocketMQ和Kafka的存储核心设计有很大的不同,所以其在写入性能方面也有很大的差别,这是16年阿里中间件团队对RocketMQ和Kafka不同Topic下做的性能测试:
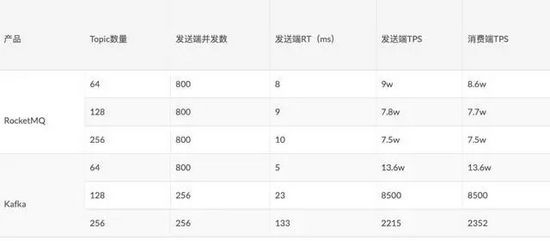
从图上可以看出:
Kafka在Topic数量由64增长到256时,吞吐量下降了98.37%。
RocketMQ在Topic数量由64增长到256时,吞吐量只下降了16%。
这是为什么呢?

kafka一个topic下面的所有消息都是以partition的方式分布式的存储在多个节点上。同时在kafka的机器上,每个Partition其实都会对应一个日志目录,在目录下面会对应多个日志分段。
所以如果Topic很多的时候Kafka虽然写文件是顺序写,但实际上文件过多,会造成磁盘IO竞争非常激烈。
那RocketMQ为什么在多Topic的情况下,依然还能很好的保持较多的吞吐量呢?我们首先来看一下RocketMQ中比较关键的文件:
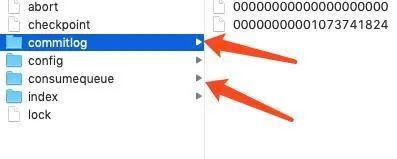
rocketmq中的消息主体数据并没有像Kafka一样写入多个文件,而是写入一个文件,这样我们的写入IO竞争就非常小,可以在很多Topic的时候依然保持很高的吞吐量。
有人可能说这里的ConsumeQueue写是在不停的写入呢,并且ConsumeQueue是以Queue维度来创建文件,那么文件数量依然很多,在这里ConsumeQueue的写入的数据量很小,每条消息只有20个字节,30W条数据也才6M左右,所以其实对我们的影响相对Kafka的Topic之间影响是要小很多的。
再顺便提一嘴,一个topic分了一万个partition和一万个topic每个topic都是单partition对于kafka的负载是一样的。
如果感觉本文对你有帮助,点击下方小卡片【灌注】支持下