论文地址:DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries
1、引言
DETR3D是3D目标检测算法的重要组成之一,是DETR2D在3D空间中进行检测的开创性工作。不同于LSS、BEVDet等一系列自上而下的方法,先进行深度估计,再进行2D-D转换的解决方案。
DETR3D通过先预设一系列预测框的查询向量object querys,利用它们生成3D reference point,将这些3D reference point 利用相机参数转换矩阵,投影回2D图像坐标,并根据他们在图像的位置去找到对应的图像特征,用图像特征和object querys做cross-attention,不断refine object querys。最后利用两个MLP分支分别输出分类预测结果与回归预测结果。正负样本则采用和DETR相同的二分图匹配,即根据最小cost在900个object querys中找到与GT数量最匹配的N个预测框。由于正负样本匹配以及object querys这种查询目标的方式与DETR类似,因此可以看成是DETR在3D的扩展。
注:总体来看,DETR3D也是一个transformer结构的检测框架,但是其没有encoder的结构,使用的是传统的卷积网络的backbone来进行特征的提取工作。
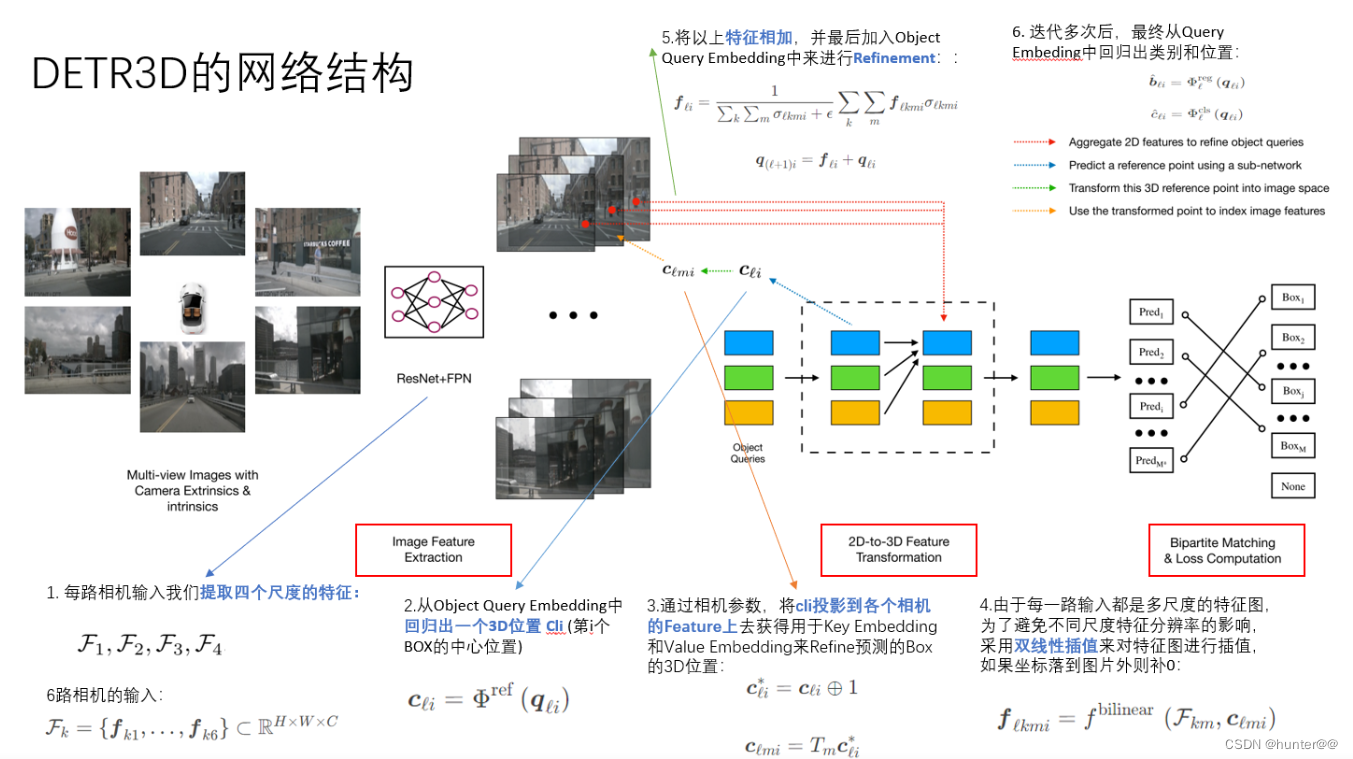
总体步骤:
(1)首先利用图像特征提取网络,例如resnet50等,对不同视角相机拍摄的图像进行特征提取。(这里可以直接认为就是transformer结构中的encoder结构,其实完全不同,可以看出是ViT结构还没有出来之前,早期将transformer和视觉任务结合的尝试)。
(2)使用nn.embeding初始化一个Object Query Embedding,之后利用一个全连接MLP回归出一个3D参考点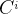
(3)通过相机的内外参数(2)得到的3D参考点ref point(世界坐标系下的点)将其投影到相机平面的特征图上去,下面就是使用2维的DETR来进行2D目标检测的方法了。
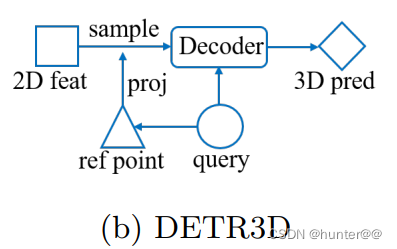
(4)由于每一路输入都是多尺度特征,为了避免不同尺度之间分辨率的影响,使用双线性差值对特征图进行采样,得到不同尺度下的特征差值采样结果{F1,F2,F3,F4}。(这里其实可以理解为不同尺度的特征图和reference_2D之间做一个cross-attention交互)。
(5)将不同尺度特征的采样结果进行合并,再加入原本的Object Query Embedding进行精炼。
(6)多次迭代,最终从最后的Query Embedding回归出类别和位置。
2、pipeline
2.1 img_backbone + grid_mask + img_neck
2.1.1 原理
这里img_backbone使用的resnet50(也是比较常见的图像提取网络了),gird_mask也是比较很常见的数据增强方案,感兴趣的可以参考一下我的bevformer的博客。
最终得到的不同尺度img_feats为一个list,其中包含不同大小的特征图:[1,6,256,116,200],[1,6,256,58,100],[1,6,29,50],[1,6,15,25]。
2.1.2 代码
extract_img_feat函数
def extract_img_feat(self, img, img_metas):
"""Extract features of images."""
B = img.size(0)
if img is not None:
input_shape = img.shape[-2:]
# update real input shape of each single img
for img_meta in img_metas:
img_meta.update(input_shape=input_shape)
if img.dim() == 5 and img.size(0) == 1:
img.squeeze_()
elif img.dim() == 5 and img.size(0) > 1:
B, N, C, H, W = img.size()
img = img.view(B * N, C, H, W)
if self.use_grid_mask:
img = self.grid_mask(img)
img_feats = self.img_backbone(img)
if isinstance(img_feats, dict):
img_feats = list(img_feats.values())
else:
return None
if self.with_img_neck:
img_feats = self.img_neck(img_feats)
img_feats_reshaped = []
for img_feat in img_feats:
BN, C, H, W = img_feat.size()
img_feats_reshaped.append(img_feat.view(B, int(BN / B), C, H, W))
return img_feats_reshaped2.2 Decoder
2.2.1 query初始化 + reference_points初始化
2.2.1.1 原理
这里的query_embeds其实是由nn.Embedding初始化的一组可以学习的特征,shape为[900,512]。通过torch.split函数将其分为query和query_pos,分别表示query和query的位置编码。
通过一个MLP,将shape为[900,256]的query回归到一个3D中心点坐标reference_point(shape为[900,3]),再做了一个sigmoid将其映射到0~1之间。
注:这边的900怎么理解呢,我的个人理解是num_query,对应之后的reference_point的个数,相当于是我预测900个bounding-box,每一个box的编码是256
# self.query_embedding = nn.Embedding(self.num_query,self.embed_dims * 2)
query_embeds = self.query_embedding.weight # [900,512]2.2.1.2 代码
def forward(self,
mlvl_feats, # [1,6,256,116,200]、[1,6,256,58,100]、[16,256,29,50]、[1,6,256,15,25]
query_embed, # [900,512]
reg_branches=None, # 6个全连接层
**kwargs): # []
"""Forward function for `Detr3DTransformer`.
Args:
mlvl_feats (list(Tensor)): Input queries from
different level. Each element has shape
[bs, embed_dims, h, w].
query_embed (Tensor): The query embedding for decoder,
with shape [num_query, c].
mlvl_pos_embeds (list(Tensor)): The positional encoding
of feats from different level, has the shape
[bs, embed_dims, h, w].
reg_branches (obj:`nn.ModuleList`): Regression heads for
feature maps from each decoder layer. Only would
be passed when
`with_box_refine` is True. Default to None.
Returns:
tuple[Tensor]: results of decoder containing the following tensor.
- inter_states: Outputs from decoder. If
return_intermediate_dec is True output has shape \
(num_dec_layers, bs, num_query, embed_dims), else has \
shape (1, bs, num_query, embed_dims).
- init_reference_out: The initial value of reference \
points, has shape (bs, num_queries, 4).
- inter_references_out: The internal value of reference \
points in decoder, has shape \
(num_dec_layers, bs,num_query, embed_dims)
- enc_outputs_class: The classification score of \
proposals generated from \
encoder's feature maps, has shape \
(batch, h*w, num_classes). \
Only would be returned when `as_two_stage` is True, \
otherwise None.
- enc_outputs_coord_unact: The regression results \
generated from encoder's feature maps., has shape \
(batch, h*w, 4). Only would \
be returned when `as_two_stage` is True, \
otherwise None.
"""
assert query_embed is not None
bs = mlvl_feats[0].size(0) # 1
query_pos, query = torch.split(query_embed, self.embed_dims , dim=1) # query:[900,256] query_pos:[900,256]
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1) # [1,900,256]
query = query.unsqueeze(0).expand(bs, -1, -1) # [1,900,256]
reference_points = self.reference_points(query_pos) # [1,900,3] Linear(in_features=256, out_features=3, bias=True)
reference_points = reference_points.sigmoid() # 压缩xyz坐标到[0,1]之间
init_reference_out = reference_points # [1,900,3]
# decoder
query = query.permute(1, 0, 2) # [1,900,256]
query_pos = query_pos.permute(1, 0, 2) # [1,900,256]
inter_states, inter_references = self.decoder(
query=query, # [1,900,256]
key=None, # None
value=mlvl_feats, # [1,6,256,115,200]、[1,6,256,58,100]、[1,6,256,29,50]、[1,6,256,15,25]
query_pos=query_pos, # [1,900,256]
reference_points=reference_points, # [1,900,3]
reg_branches=reg_branches, # 6个全连接层
**kwargs)
# inter_states: [6,900,1,256] inter_references:[6,1,900,3]
inter_references_out = inter_references # [6,1,900,3]
return inter_states, init_reference_out, inter_references_out # init_reference_out和inter_references_out的区别,多个decoder的stack的结果
2.2.2 feature_sampling—2D-3D转换模块
2.2.2.1 原理
feature_sampling函数的作用主要是根据从query中回归得到的3D中心点reference_points在不同尺度的mlvl_feats进行采样,得到中心点处的特征值。
(1)首先论文中定义的世界坐标系是激光雷达坐标系(车体坐标系),需要将其转换到相机坐标系下的,再将其转换到像素坐标系上。
具体做法如下:lidar2img就是坐标系转换矩阵(其中包含了R,T),先利用pc_range中保存的上下限对reference_points的xyz坐标进行缩放(因为之前通过sigmoid函数归一化到了0~1之间),再将其变为齐次坐标xyzs,之后乘以坐标系转换矩阵,再将点复制6份,分别对应6个相机。之后又通过一系列的mask、过滤、缩放等操作,将其映射到了像素坐标系上。
(2)得到像素平面的2D中心点reference_points_cams之后(shape为[1,6,900,2]),就需要和之前backbone提取的多尺度图像特征进行采样交互了。这里还是使用F.grid_sample双线性插值函数进行采样的,也就是在不同尺度[6,256,116,200] [6,256,58,100] [6,256,29,50] [6,256,15,25]的特征图上采样900个点,最终每个特征图采样之后的shape都为[6,256,900,1],但是其内容是不一样的,最后在将其在最后一个维度上stack起来,最终sampled_feats的shape变为[1,256,900,6,1,4]。
2.2.2.2 代码
# 十分关键的特征采样函数,2D-to-3D 特征变换
def feature_sampling(mlvl_feats, reference_points, pc_range, img_metas):
lidar2img = []
for img_meta in img_metas:
lidar2img.append(img_meta['lidar2img'])
lidar2img = np.asarray(lidar2img) # [1,6,4,4] 激光坐标系到相机坐标系的变换矩阵
lidar2img = reference_points.new_tensor(lidar2img) # (B, N, 4, 4) [1,6,4,4] 就是将之前的numpy变为的tensor
reference_points = reference_points.clone() # [1,900,3]
reference_points_3d = reference_points.clone() # [1,900,3]
# pc_range 的含义 [x_min, y_min, z_min, x_max, y_max, z_max]
reference_points[..., 0:1] = reference_points[..., 0:1] * (pc_range[3] - pc_range[0]) + pc_range[0] # 对 x 进行缩放
reference_points[..., 1:2] = reference_points[..., 1:2] * (pc_range[4] - pc_range[1]) + pc_range[1] # 对 y 进行缩放
reference_points[..., 2:3] = reference_points[..., 2:3] * (pc_range[5] - pc_range[2]) + pc_range[2] # 对 z 进行缩放
# reference_points (B, num_queries, 4) 将非齐次坐标转换为齐次坐标
reference_points = torch.cat((reference_points, torch.ones_like(reference_points[..., :1])), -1)
B, num_query = reference_points.size()[:2] # B:1 , num_query: 900
num_cam = lidar2img.size(1) # 6
reference_points = reference_points.view(B, 1, num_query, 4).repeat(1, num_cam, 1, 1).unsqueeze(-1) # [1,6,900,4,1] 复制6个相机的情况
lidar2img = lidar2img.view(B, num_cam, 1, 4, 4).repeat(1, 1, num_query, 1, 1) # [1,6,900,4,4] 复制6个相机转换矩阵
reference_points_cam = torch.matmul(lidar2img, reference_points).squeeze(-1) # [1,6,900,4] 乘以坐标转换矩阵
eps = 1e-5 # 阈值
mask = (reference_points_cam[..., 2:3] > eps) # 过滤 [1,6,900,1]
reference_points_cam = reference_points_cam[..., 0:2] / torch.maximum(
reference_points_cam[..., 2:3], torch.ones_like(reference_points_cam[..., 2:3])*eps) # [1,6,900,2] 将3D上的点映射到2d平面上
reference_points_cam[..., 0] /= img_metas[0]['img_shape'][0][1] # 缩放 x
reference_points_cam[..., 1] /= img_metas[0]['img_shape'][0][0] # 缩放 y
reference_points_cam = (reference_points_cam - 0.5) * 2
mask = (mask & (reference_points_cam[..., 0:1] > -1.0)
& (reference_points_cam[..., 0:1] < 1.0)
& (reference_points_cam[..., 1:2] > -1.0)
& (reference_points_cam[..., 1:2] < 1.0))
mask = mask.view(B, num_cam, 1, num_query, 1, 1).permute(0, 2, 3, 1, 4, 5) # [1,1,600,6,1,1]
mask = torch.nan_to_num(mask)
sampled_feats = []
for lvl, feat in enumerate(mlvl_feats): # 对FFN层的不同的多尺度特征进行操作 feat:[1,6,256,116,200]
B, N, C, H, W = feat.size()
feat = feat.view(B*N, C, H, W) # [6,256,116,200]
reference_points_cam_lvl = reference_points_cam.view(B*N, num_query, 1, 2) # [6,900,1,2]
sampled_feat = F.grid_sample(feat, reference_points_cam_lvl) # [6,256,900,1]
sampled_feat = sampled_feat.view(B, N, C, num_query, 1).permute(0, 2, 3, 1, 4) # [1,256,900,6,1]
sampled_feats.append(sampled_feat)
sampled_feats = torch.stack(sampled_feats, -1) # [1,256,900,6,1,4]
sampled_feats = sampled_feats.view(B, C, num_query, num_cam, 1, len(mlvl_feats)) # [1,256,900,6,1,4]
return reference_points_3d, sampled_feats, mask2.2.3 Detr3DCrossAtten模块
2.2.3.1 原理
Detr3DCrossAtten模块的主要作用是将query、value和reference_points之间的特征进行交互。
首先query = query + query_pos,即query + query的位置编码,然后再将其送给一个全连接层得到attention_weights,shape变为[1,900,256] -> [1,900,24] -> [1,1,900,6,1,4]。
之后就是上一小节讲得feature_sample进行特征采样,得到reference_points_3d和output,其中output中保存了不同尺度的图像特征采样后的特征结果。再将attention_weight和output进行注意力权重计算,再sum一下最后3各维度,并进行permute维度交互,最后再连接一个全连接层,进行特征映射得到最终的output结果,shape为[900,1,256]。
最后再使用self.position_encoder函数对3d点的信息reference_points_3d进行编码,使其的shape变为[900,1,256]。最后得到的结果为self.dropout(output) + inp_residual + pos_feat。也就是(dropout后的不同尺度图像采样特征)+(原始的query)+(3D点坐标的编码信息)。
2.2.3.2 代码
def forward(self,
query, # [900,1,256]
key, # None
value, # list [1,6,256,116,200] [1,6,256,58,100] [1,6,256,29,50] [1,6,256,15,25]
residual=None, # None
query_pos=None, # [900,1,256]
key_padding_mask=None, # None
reference_points=None, # [1,900,3]
spatial_shapes=None, # None
level_start_index=None, # None
**kwargs):
"""Forward Function of Detr3DCrossAtten.
Args:
query (Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
key (Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
value (Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`. (B, N, C, H, W)
residual (Tensor): The tensor used for addition, with the
same shape as `x`. Default None. If None, `x` will be used.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, 4),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (Tensor): Spatial shape of features in
different level. With shape (num_levels, 2),
last dimension represent (h, w).
level_start_index (Tensor): The start index of each level.
A tensor has shape (num_levels) and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
"""
if key is None:
key = query
if value is None:
value = key
if residual is None:
inp_residual = query # [900,1,256] 用于残差连接
if query_pos is not None:
query = query + query_pos # [900,1,256] query + query的位置编码
# change to (bs, num_query, embed_dims)
query = query.permute(1, 0, 2) # [1,900,256]
bs, num_query, _ = query.size() # bs:1, num_query:900, _:256
# [1,900,256] -> [1,900,24] -> [1,1,900,6,1,4]
attention_weights = self.attention_weights(query).view(bs, 1, num_query, self.num_cams, self.num_points, self.num_levels)
# reference_points_3d:[1,900,3]
# output:[1,256,900,6,1,4]
# mask:[1,1,900,6,1,1]
reference_points_3d, output, mask = feature_sampling(value, reference_points, self.pc_range, kwargs['img_metas'])
output = torch.nan_to_num(output) # torch.nan_to_num,用于将张量中的非数字(NaN, 正无穷inf, 负无穷-inf)替换为数值
mask = torch.nan_to_num(mask) # torch.nan_to_num,用于将张量中的非数字(NaN, 正无穷inf, 负无穷-inf)替换为数值
attention_weights = attention_weights.sigmoid() * mask # [1,1,900,6,1,4]
output = output * attention_weights # [1,256,900,6,1,4]
output = output.sum(-1).sum(-1).sum(-1) # [1,256,900] 合并6、1、4维度
output = output.permute(2, 0, 1) # [900,1,256]
output = self.output_proj(output) # [900,1,256]
# (num_query, bs, embed_dims) 还把3d点的信息进行编码 与 采样之后的图像特征 相加
pos_feat = self.position_encoder(inverse_sigmoid(reference_points_3d)).permute(1, 0, 2) # [1,900,3] -> [1,900,256] -> [900,1,256]
return self.dropout(output) + inp_residual + pos_feat2.2.4 其他结构
2.2.4.1 原理
Detr3DHead函数的forward函数。
首先通过transformer类得到6个decoder输出的采样特征图hs,shape为[6,1,900,256]。之后分别用两个全连接层对每一个decoder输出的特征图hs[lvl],shape为[1,900,256]进行全连接映射到[1,900,10],得到outputs_class和tmp,分别用来预测类别和box大小,又结合reference和pc_range也就是3D中心点位置xyz和[x_min,y_min,z_min,x_max,y_max,z_max]坐标上下限对tmp的结果进行平移缩放。最后再将不同decoder层的预测结果stack起来进行loss计算。
2.2.4.2 代码
def forward(self, mlvl_feats, img_metas):
"""Forward function.
Args:
mlvl_feats (tuple[Tensor]): Features from the upstream
network, each is a 5D-tensor with shape
(B, N, C, H, W).
Returns:
all_cls_scores (Tensor): Outputs from the classification head, \
shape [nb_dec, bs, num_query, cls_out_channels]. Note \
cls_out_channels should includes background.
all_bbox_preds (Tensor): Sigmoid outputs from the regression \
head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \
Shape [nb_dec, bs, num_query, 9].
"""
query_embeds = self.query_embedding.weight # [900,512]
hs, init_reference, inter_references = self.transformer(
mlvl_feats, # [1,6,256,116,200]、[1,6,256,58,100]、[1,6,256,29,50]、[1,6,256,15,25]
query_embeds, # [900,512]
reg_branches=self.reg_branches if self.with_box_refine else None, # 6个全连接层
img_metas=img_metas,) # 一堆list
hs = hs.permute(0, 2, 1, 3) # hs: [6,900,1,256]->[6,1,900,256] init_reference:[1,900,3] inter_references:[6,1,900,3]
outputs_classes = []
outputs_coords = []
for lvl in range(hs.shape[0]): # 遍历每一个decoder输出的特征图,多尺度预测
if lvl == 0:
reference = init_reference
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference) # 反sigmoid函数
outputs_class = self.cls_branches[lvl](hs[lvl]) # 对每一个decoder输出的特征图[1,900,256]进行全连接映射 [1,900,10]
tmp = self.reg_branches[lvl](hs[lvl]) # [1,900,10]
# TODO: check the shape of reference
assert reference.shape[-1] == 3
tmp[..., 0:2] += reference[..., 0:2]
tmp[..., 0:2] = tmp[..., 0:2].sigmoid()
tmp[..., 4:5] += reference[..., 2:3]
tmp[..., 4:5] = tmp[..., 4:5].sigmoid()
tmp[..., 0:1] = (tmp[..., 0:1] * (self.pc_range[3] - self.pc_range[0]) + self.pc_range[0])
tmp[..., 1:2] = (tmp[..., 1:2] * (self.pc_range[4] - self.pc_range[1]) + self.pc_range[1])
tmp[..., 4:5] = (tmp[..., 4:5] * (self.pc_range[5] - self.pc_range[2]) + self.pc_range[2])
# TODO: check if using sigmoid
outputs_coord = tmp # 坐标预测结果
outputs_classes.append(outputs_class) # 类别预测结果
outputs_coords.append(outputs_coord) # 坐标预测结果
outputs_classes = torch.stack(outputs_classes)
outputs_coords = torch.stack(outputs_coords)
outs = {
'all_cls_scores': outputs_classes,
'all_bbox_preds': outputs_coords,
'enc_cls_scores': None,
'enc_bbox_preds': None,
}
return outs2.3 Loss
2.3.1 原理
这边Loss也是比较传统的目标检测loss,由分类损失和回归损失组成,唯一需要注意的是_get_target_single函数,它的主要作用是填充(这边建议仔细食用一下代码)。
2.3.2 代码
loss函数
def loss(self,
gt_bboxes_list, # 18个物体的 box 信息
gt_labels_list, # 18个物体的 label
preds_dicts, # [[6,1,900,10],[6,1,900,10],[None],[None]]
gt_bboxes_ignore=None): # None
""""Loss function.
Args:
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
preds_dicts:
all_cls_scores (Tensor): Classification score of all
decoder layers, has shape
[nb_dec, bs, num_query, cls_out_channels].
all_bbox_preds (Tensor): Sigmoid regression
outputs of all decode layers. Each is a 4D-tensor with
normalized coordinate format (cx, cy, w, h) and shape
[nb_dec, bs, num_query, 4].
enc_cls_scores (Tensor): Classification scores of
points on encode feature map , has shape
(N, h*w, num_classes). Only be passed when as_two_stage is
True, otherwise is None.
enc_bbox_preds (Tensor): Regression results of each points
on the encode feature map, has shape (N, h*w, 4). Only be
passed when as_two_stage is True, otherwise is None.
gt_bboxes_ignore (list[Tensor], optional): Bounding boxes
which can be ignored for each image. Default None.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
assert gt_bboxes_ignore is None, \
f'{self.__class__.__name__} only supports ' \
f'for gt_bboxes_ignore setting to None.'
all_cls_scores = preds_dicts['all_cls_scores'] # [6,1,900,10]
all_bbox_preds = preds_dicts['all_bbox_preds'] # [6,1,900,10]
enc_cls_scores = preds_dicts['enc_cls_scores'] # None
enc_bbox_preds = preds_dicts['enc_bbox_preds'] # None
num_dec_layers = len(all_cls_scores) # decoder的层数:6个
device = gt_labels_list[0].device
# gt_bboxes.gravity_center: 这是gt_bboxes对象的一个属性,代表边界框的重心或质心坐标。
# 它是一个形状为(N, 3)的Tensor,其中N是边界框的数量,3是二维坐标(x,y,z)
# gt_bboxes.tensor[:, 3:]: 这部分从gt_bboxes.tensor这个Tensor中选取了所有行(由:指定)但仅从第4列开始到最后的列。
# 这表示边界框的宽度、高度和其他可能的属性(例如旋转角度等)。假设gt_bboxes.tensor的形状为(N, M),其中M大于或等于4,那么这部分将返回一个形状为(N, M-3)的Tensor。
gt_bboxes_list = [torch.cat((gt_bboxes.gravity_center, gt_bboxes.tensor[:, 3:]),dim=1).to(device) for gt_bboxes in gt_bboxes_list]
all_gt_bboxes_list = [gt_bboxes_list for _ in range(num_dec_layers)] # 复制6份,每个decoder复制一份
all_gt_labels_list = [gt_labels_list for _ in range(num_dec_layers)] # 复制6份,每个decoder复制一份
all_gt_bboxes_ignore_list = [gt_bboxes_ignore for _ in range(num_dec_layers)] # 复制6份,每个decoder复制一份
losses_cls, losses_bbox = multi_apply(self.loss_single,
all_cls_scores, all_bbox_preds,
all_gt_bboxes_list,
all_gt_labels_list,
all_gt_bboxes_ignore_list)
loss_dict = dict()
# loss of proposal generated from encode feature map.
if enc_cls_scores is not None:
binary_labels_list = [torch.zeros_like(gt_labels_list[i])for i in range(len(all_gt_labels_list))]
enc_loss_cls, enc_losses_bbox = self.loss_single(enc_cls_scores, enc_bbox_preds,gt_bboxes_list, binary_labels_list, gt_bboxes_ignore)
loss_dict['enc_loss_cls'] = enc_loss_cls
loss_dict['enc_loss_bbox'] = enc_losses_bbox
# loss from the last decoder layer
loss_dict['loss_cls'] = losses_cls[-1]
loss_dict['loss_bbox'] = losses_bbox[-1]
# loss from other decoder layers
num_dec_layer = 0
for loss_cls_i, loss_bbox_i in zip(losses_cls[:-1],losses_bbox[:-1]):
loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i
num_dec_layer += 1
return loss_dict_get_target_single函数
def _get_target_single(self,
cls_score, # [900,10]
bbox_pred, # [900,10]
gt_labels, # [18]
gt_bboxes, # [18,9]
gt_bboxes_ignore=None): # None
""""Compute regression and classification targets for one image.
Outputs from a single decoder layer of a single feature level are used.
Args:
cls_score (Tensor): Box score logits from a single decoder layer
for one image. Shape [num_query, cls_out_channels].
bbox_pred (Tensor): Sigmoid outputs from a single decoder layer
for one image, with normalized coordinate (cx, cy, w, h) and
shape [num_query, 4].
gt_bboxes (Tensor): Ground truth bboxes for one image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (Tensor): Ground truth class indices for one image
with shape (num_gts, ).
gt_bboxes_ignore (Tensor, optional): Bounding boxes
which can be ignored. Default None.
Returns:
tuple[Tensor]: a tuple containing the following for one image.
- labels (Tensor): Labels of each image.
- label_weights (Tensor]): Label weights of each image.
- bbox_targets (Tensor): BBox targets of each image.
- bbox_weights (Tensor): BBox weights of each image.
- pos_inds (Tensor): Sampled positive indices for each image.
- neg_inds (Tensor): Sampled negative indices for each image.
"""
num_bboxes = bbox_pred.size(0) # 900
# assigner and sampler 正负样本的分配与采样
# assigner将预测的边界框与真实的边界框进行匹配,并确定哪些预测框是正样本,哪些是负样本。然后,sampler根据这些匹配结果进行采样,以确保正负样本的平衡。
assign_result = self.assigner.assign(bbox_pred, cls_score, gt_bboxes, gt_labels, gt_bboxes_ignore)
sampling_result = self.sampler.sample(assign_result, bbox_pred,gt_bboxes)
pos_inds = sampling_result.pos_inds # [18] # 获取正样本的索引
neg_inds = sampling_result.neg_inds # [882] # 获取负样本的索引
# label targets
# 初始化一个形状为[900]的Tensor,其中所有元素都是类别的数量(这里作为背景类别的索引)。然后,将正样本的索引对应的标签设置为真实的类别标签。
labels = gt_bboxes.new_full((num_bboxes, ),self.num_classes,dtype=torch.long) # [900]
labels[pos_inds] = gt_labels[sampling_result.pos_assigned_gt_inds]
# 为所有预测框(包括正样本和负样本)生成标签权重,这里都设为1。但在某些情况下,你可能希望为负样本赋予不同的权重。
label_weights = gt_bboxes.new_ones(num_bboxes) # [900]
# bbox targets
# 初始化一个与bbox_pred形状相同的Tensor,但只保留前9个通道(假设边界框的坐标和尺寸有9个参数)。
# 然后,初始化一个与bbox_pred形状相同的Tensor,但所有元素都是0。接着,将正样本的索引对应的权重设为1.0
bbox_targets = torch.zeros_like(bbox_pred)[..., :9] # [900,9]
bbox_weights = torch.zeros_like(bbox_pred) # [900,10]
bbox_weights[pos_inds] = 1.0
# DETR
# 将正样本的索引对应的边界框目标设置为真实的边界框坐标和尺寸。
bbox_targets[pos_inds] = sampling_result.pos_gt_bboxes
# 注意:变量包含了真实值(特别是对于正样本)和一些初始化的值(特别是对于负样本)。
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds, neg_inds)get_targets函数
def get_targets(self,
cls_scores_list, # [900,10]
bbox_preds_list, # [900,10]
gt_bboxes_list, # [18,9] 9个label信息,3个xyz,3个长宽高,3个旋转角
gt_labels_list, # 18个label
gt_bboxes_ignore_list=None):
""""Compute regression and classification targets for a batch image.
Outputs from a single decoder layer of a single feature level are used.
Args:
cls_scores_list (list[Tensor]): Box score logits from a single
decoder layer for each image with shape [num_query,
cls_out_channels].
bbox_preds_list (list[Tensor]): Sigmoid outputs from a single
decoder layer for each image, with normalized coordinate
(cx, cy, w, h) and shape [num_query, 4].
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
gt_bboxes_ignore_list (list[Tensor], optional): Bounding
boxes which can be ignored for each image. Default None.
Returns:
tuple: a tuple containing the following targets.
- labels_list (list[Tensor]): Labels for all images.
- label_weights_list (list[Tensor]): Label weights for all \
images.
- bbox_targets_list (list[Tensor]): BBox targets for all \
images.
- bbox_weights_list (list[Tensor]): BBox weights for all \
images.
- num_total_pos (int): Number of positive samples in all \
images.
- num_total_neg (int): Number of negative samples in all \
images.
"""
assert gt_bboxes_ignore_list is None, \
'Only supports for gt_bboxes_ignore setting to None.'
num_imgs = len(cls_scores_list) # 1
gt_bboxes_ignore_list = [gt_bboxes_ignore_list for _ in range(num_imgs)] # None
(labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, pos_inds_list, neg_inds_list) = multi_apply(
self._get_target_single, cls_scores_list, bbox_preds_list,
gt_labels_list, gt_bboxes_list, gt_bboxes_ignore_list)
num_total_pos = sum((inds.numel() for inds in pos_inds_list)) # 18
num_total_neg = sum((inds.numel() for inds in neg_inds_list)) # 882
return (labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, num_total_pos, num_total_neg)
loss_single函数
def loss_single(self,
cls_scores, # [1,900,10]
bbox_preds, # [1,900,10]
gt_bboxes_list, # list[[18,9] 9表示3个xyz,3个长宽高,3个旋转角]
gt_labels_list, # list[18个label]
gt_bboxes_ignore_list=None):# None
""""Loss function for outputs from a single decoder layer of a single
feature level.
Args:
cls_scores (Tensor): Box score logits from a single decoder layer
for all images. Shape [bs, num_query, cls_out_channels].
bbox_preds (Tensor): Sigmoid outputs from a single decoder layer
for all images, with normalized coordinate (cx, cy, w, h) and
shape [bs, num_query, 4].
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
gt_bboxes_ignore_list (list[Tensor], optional): Bounding
boxes which can be ignored for each image. Default None.
Returns:
dict[str, Tensor]: A dictionary of loss components for outputs from
a single decoder layer.
"""
num_imgs = cls_scores.size(0) # 1
cls_scores_list = [cls_scores[i] for i in range(num_imgs)] # [900,10]
bbox_preds_list = [bbox_preds[i] for i in range(num_imgs)] # [900,10]
cls_reg_targets = self.get_targets(cls_scores_list, bbox_preds_list,gt_bboxes_list, gt_labels_list, gt_bboxes_ignore_list)
# cls——reg_targets为一个list,里面有6个值,这是真实值
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,num_total_pos, num_total_neg) = cls_reg_targets
# 真实的label值
labels = torch.cat(labels_list, 0) # [900]
# 真实的label_weight
label_weights = torch.cat(label_weights_list, 0) # [900]
# 真实的bbox
bbox_targets = torch.cat(bbox_targets_list, 0) # [900,9]
# 真实bbox_weight
bbox_weights = torch.cat(bbox_weights_list, 0) # [900,10]
# 预测的类别分数
cls_scores = cls_scores.reshape(-1, self.cls_out_channels) # [900,10]
# construct weighted avg_factor to match with the official DETR repo
cls_avg_factor = num_total_pos * 1.0 + num_total_neg * self.bg_cls_weight # 18
if self.sync_cls_avg_factor:
cls_avg_factor = reduce_mean(cls_scores.new_tensor([cls_avg_factor])) # 1
# 类别损失
cls_avg_factor = max(cls_avg_factor, 1) # [18]
loss_cls = self.loss_cls(cls_scores, labels, label_weights, avg_factor=cls_avg_factor) # 类别损失 2.2571
# Compute the average number of gt boxes accross all gpus, for
# normalization purposes
num_total_pos = loss_cls.new_tensor([num_total_pos])
num_total_pos = torch.clamp(reduce_mean(num_total_pos), min=1).item()
# regression L1 loss
bbox_preds = bbox_preds.reshape(-1, bbox_preds.size(-1)) # 18.0
normalized_bbox_targets = normalize_bbox(bbox_targets, self.pc_range) # [900,10]
isnotnan = torch.isfinite(normalized_bbox_targets).all(dim=-1) # 布尔值
bbox_weights = bbox_weights * self.code_weights # [900,10]
loss_bbox = self.loss_bbox(bbox_preds[isnotnan, :10], normalized_bbox_targets[isnotnan, :10], bbox_weights[isnotnan, :10], avg_factor=num_total_pos)
loss_cls = torch.nan_to_num(loss_cls)
loss_bbox = torch.nan_to_num(loss_bbox)
return loss_cls, loss_bbox总结
(1)DETR3D是DETR2D的一个改进版,主要通过初始化一个3D的object query,将其投影到2D像素平面上和不同视角图像特征进行交互,来预测3D物体的位置。
(2)和LSS、BEVdet等一系列基于深度估计的BEV方案完全不同。
(3)BEVformer可以看成DETR3D的改进版,是DETR3D和BEV方案的结合产物,个人感觉是介于DETR3D和自上而下的BEV方案的中间产物。
参考
论文精读:《DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries》-CSDN博客