OpenCV官网指导教程第二期,对应官网的 core operation。
主要包括三大类:
1、图像基本操作
2、图像的算术操作
3、(代码)表现的测量和提高
主要使用到的方法如下:
cv2.cvtColor()
cv2.split()
cv2.merge()
cv2.copyMakeBorder()
cv2.add()
cv2.addWeighted()
cv2.threshold()
cv2.bitwise_not()
cv2.bitwise_and()
cv2.getTickCount()
cv2.getTickFrequency()
cv2.setUseOptimized()
cv2.useOptimized()
所有代码(notebook)均上传至
https://github.com/xurongtang/OpenCV-python
1、图像基本操作
图像操作主要包括:
Access pixel values and modify them(对像素的操作)
Access image properties(获得图像属性)
Set a Region of Interest (ROI)(设置感兴趣的区域)
Split and merge images(分割和融合图片)
本节操作可能更加偏向于Numpy而非OpenCV
import numpy as np
import cv2
img_color = cv2.imread("demo.png")
assert img_color is not None, "Image reading failed."
# assert用来确保后面的语句返回True,若不为True则输出后面字符串
img_gray = cv2.imread("demo.png",cv2.IMREAD_GRAYSCALE)
# 索引某个像素,通过xy索引元素
px_1 = img_color[34,21] # 对三通道来说某个坐标的索引结果是array
px_2 = img_gray[34,21] # 对单通道来说某个坐标的索引结构是单个数值
print(px_1,px_2)
# 索引某个具体数值
px_ = img_color[34,21,0]
print(px_)调整某个像素的值
# 调整某个像素的具体数值
print(img_color[34,21])
img_color[34,21] = [255,255,255]
print(img_color[34,21])或者都某个通道进行调整
# 对某个像素的单个通道进行调整
img_color[34,21,0] = 0
print(img_color[34,21])获得图像的属性
# 返回行列和通道,返回元组
print("Color:",img_color.shape)
print("Gray: ",img_gray.shape)
# 返回像素总数
print("Color: ",img_color.size)
print("Gray: ",img_gray.size)
# 返回类型
print("Color: ",img_color.dtype)
print("Gray: ",img_gray.dtype)获得感兴趣的区域(ROI)
Region_1 = img_color[10:60,10:60]
print(Region_1.shape)
img_color[70:120,70:120] = Region_1
cv2.imshow("window",img_color)
cv2.waitKey(0)有时您需要单独处理图像的 B、G、R 通道。在这种情况下,您需要将 BGR 图像分割成单个通道。在其他情况下,您可能需要将这些单独的通道合并以创建 BGR 图像。
需要将三通道分离开。cv2.spilt()
将三通道合并成一个通道。cv2.merge()
# 将各个通道单独出来
b,g,r = cv2.split(img_color) # cv2.split()极耗费时间,如果不是必要不用。
b,g,r = img_color[:,:,0],img_color[:,:,1],img_color[:,:,2]
b.shape,g.shape,r.shape融合操作
# 融合
merge_img = cv2.merge((b,g,r))
merge_img.shape如果您想在图像周围创建边框,类似于相框,可以使用 cv.copyMakeBorder()。但它在卷积操作、零填充等方面有更多应用。参数如下:
src - 输入图像
top, bottom, left, right - 对应方向上需要扩充的像素的个数
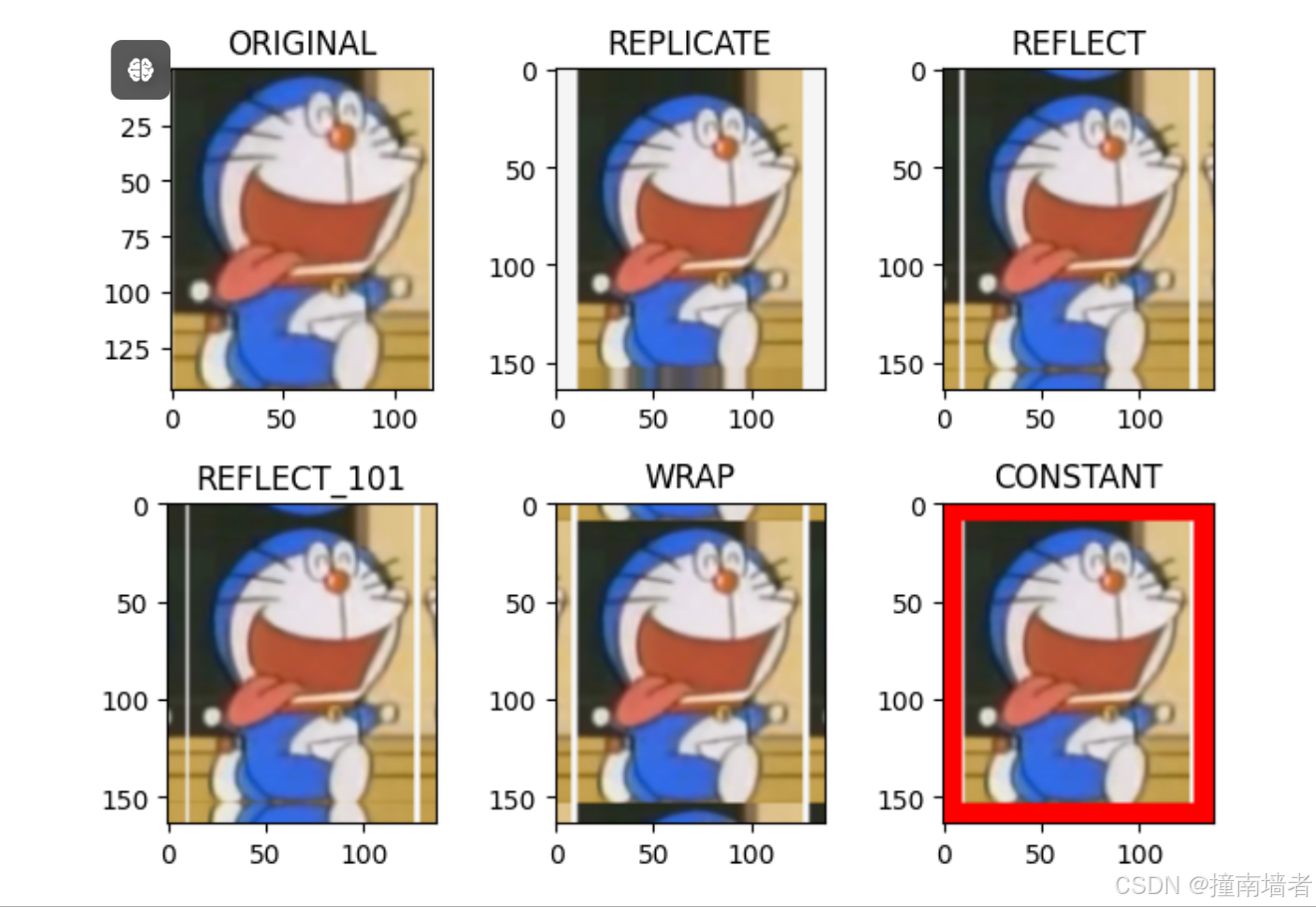
borderType - 填充的类型,有以下类型: cv.BORDER_CONSTANT - 使用常量值,用此方法需要在下一个参数中传入值. cv.BORDER_REFLECT - 镜像反射方法。fedcba|abcdefgh|hgfedcb cv.BORDER_REFLECT_101 or cv.BORDER_DEFAULT - 另一种类型的镜像关系。gfedcb|abcdefgh|gfedcba cv.BORDER_REPLICATE - 用最边缘元素进行复制。aaaaaa|abcdefgh|hhhhhhh cv.BORDER_WRAP - 形如: cdefgh|abcdefgh|abcdefg
value - 如果类型是 cv.BORDER_CONSTANT 设置的颜色值。
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
BLUE = [255,0,0]
img1 = cv.imread('demo2.png')
img1 = cv.cvtColor(img1,cv.COLOR_BGR2RGB) # 默认通道时bgr,转化为rgb
assert img1 is not None, "file could not be read, check with os.path.exists()"
replicate = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REPLICATE)
reflect = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REFLECT)
reflect101 = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REFLECT_101)
wrap = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_WRAP)
constant= cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_CONSTANT,value=BLUE)
plt.subplot(231),plt.imshow(img1,'gray'),plt.title('ORIGINAL')
plt.subplot(232),plt.imshow(replicate,'gray'),plt.title('REPLICATE')
plt.subplot(233),plt.imshow(reflect,'gray'),plt.title('REFLECT')
plt.subplot(234),plt.imshow(reflect101,'gray'),plt.title('REFLECT_101')
plt.subplot(235),plt.imshow(wrap,'gray'),plt.title('WRAP')
plt.subplot(236),plt.imshow(constant,'gray'),plt.title('CONSTANT')
plt.tight_layout()
plt.show()结果:
2、图像算术操作
图像相加:
import cv2
import numpy as np
img1 = cv2.imread("demo.png",cv2.IMREAD_COLOR)
img2 = cv2.imread("demo2.png",cv2.IMREAD_COLOR)
print(img1.shape,img2.shape)
img2 = cv2.resize(img2,(img1.shape[1],img1.shape[0]))
print(img1.shape,img2.shape)
# 两种加法都是对应元素相加,但是计算逻辑有所不同
add_1 = cv2.add(img1,img2) # cv2.add()方法对元素进行对应相加,对超过255的值一律取255
add_2 = img1 + img2 # 直接相加(若超过上限,np.unint8的上限为255,则重新计数,如260->4)
np.all(add_1 == add_2)
# 理论上add_1中的255要多于add_2
print(np.count_nonzero(add_1 == 255))
print(np.count_nonzero(add_2 == 255))带权重相加:
理论如下:

# 学习使用 cv.addWeighted()
# 参数:图像一、图像一的权重、图像二、图像二的权重,加上的残差。
blend_img = cv2.addWeighted(img1,0.8,img2,0.2,0)
# 匿名函数(转换通道)
cvt_img = lambda img : cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
# map映射
blend_img,img1,img2 = map(cvt_img,[blend_img,img1,img2])
import matplotlib.pyplot as plt
plt.subplot(131),plt.imshow(img1),plt.title("image1")
plt.subplot(132),plt.imshow(img2),plt.title("image2")
plt.subplot(133),plt.imshow(blend_img),plt.title("blend(0.8+0.2)")
plt.tight_layout()
plt.show()元素端的操作(涉及阈值处理和元素端逻辑运算):
示例:目标是将一些不规则的目标(如一个logo)放入另一张图像当中。如果采用上述方法,可能会导致图像颜色改变或者有透明效果。如果目标是规则的矩形,则可以使用上节的ROI进行添加,但是多数不是规则图形则不可行。
第一步:读入
img3 = cv2.imread("demo3.jpg",cv2.IMREAD_COLOR)
img4 = cv2.imread("demo4.jpg",cv2.IMREAD_COLOR)
img3,img4 = map(cvt_img,[img3,img4])
plt.subplot(121),plt.imshow(img3),plt.title("image3")
plt.subplot(122),plt.imshow(img4),plt.title("image4")
plt.tight_layout()
plt.show()
第二步:创建掩码
# 为了方便,调整一下image3的尺寸
img3 = cv2.resize(img3,(100,50))
# 我想把表情放在图4的中下部分,获得ROI
row,col,channels = img3.shape
roi = img4[-20-row:-20,100:100+col]
# 创建掩码,并创建它的反掩码
img3_gray = cv2.cvtColor(img3,cv2.COLOR_RGB2GRAY) # 此处的图片已经是转换过颜色通道的,为RGB通道顺序
ret,mask = cv2.threshold(img3_gray,250,255,cv2.THRESH_BINARY)
# cv2.threshold(),参数如下:
# img2gray:输入的灰度图像。
# 10:设置的阈值,所有像素值小于这个值的像素将被设为 0。
# 255:对于所有像素值大于或等于阈值的像素,将被设为 255。(也即小于10为0也就是黑色,大于10为255也就是白色)
# cv.THRESH_BINARY:指定使用的阈值类型,这里表示使用二值化处理。
# 提升对cv2.threshold的理解,现在图像中只有0或255,所以0和255的个数加起来应该等于总个数
black_count = np.count_nonzero(mask == 0)
white_count = np.count_nonzero(mask == 255)
print(black_count,white_count,black_count+white_count,img3_gray.size)
# 返回值ret为阈值,mask为返回的二值图像(阈值选择依据情况而定)
print(ret)
# 对一个mask图像进行反位操作
mask_inv = cv2.bitwise_not(mask)
plt.subplot(121),plt.imshow(mask,'gray'),plt.title("mask")
plt.subplot(122),plt.imshow(mask_inv,'gray'),plt.title("inv_mask")
plt.show()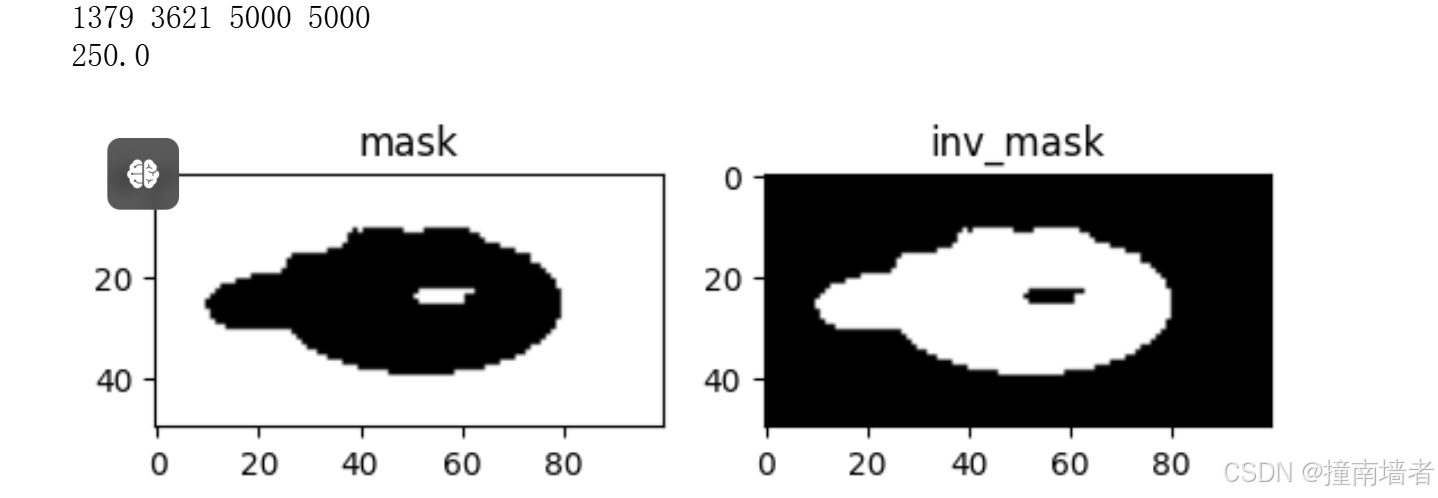
第三步:抠图
# 抠图,在roi上扣除对应位置的图像
img4_background = cv2.bitwise_and(roi,roi,mask=mask) # 对原图像,保留白色(255)区域,提出黑色(0)的区域。
# 取图
fg = cv2.bitwise_and(img3,img3,mask=mask_inv)
# 合并
dst = cv2.add(img4_background,fg)
print(img4_background.shape,fg.shape)
plt.subplot(131),plt.imshow(img4_background)
plt.subplot(132),plt.imshow(fg)
plt.subplot(133),plt.imshow(dst)
plt.show()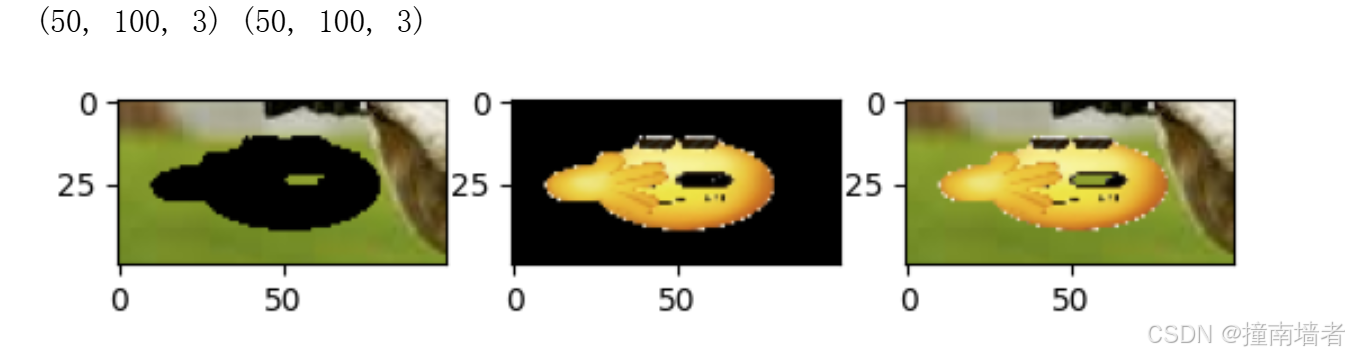
第四步:合并
# 合并
img4_res = img4[:,:,:]
img4_res[-20-row:-20,100:100+col] = dst
img4_res = cv2.cvtColor(img4_res,cv2.COLOR_BGR2RGB)
cv2.imshow("res",img4_res)
cv2.waitKey(0)
3、(代码)表现的测量与提升
代码计时
e1 = cv2.getTickCount() # 获得当前的钟刻数
e2 = cv2.getTickCount() # 获得当前的钟刻数
# cv2.getTickFrequency() 是OpenCV 中的一个函数,用于返回系统中时钟的频率(即每秒钟的时钟刻度数)
# cv2.getTickFrequency() 返回一秒的钟刻数
time = (e2 - e1) / cv2.getTickFrequency()
# time: 刻钟之间差值 除以 一秒钟的钟刻数 等于 过程的秒数
print(e1)
print(e2)
print(cv2.getTickFrequency())运行过程优化
许多OpenCV函数使用SSE2、AVX等进行了优化。它也包含未优化的代码。因此,如果我们的系统支持这些功能,我们应该利用它们(几乎所有现代处理器都支持它们)。在编译时默认启用。因此,如果启用,OpenCV将运行优化的代码,否则将运行未优化的代码。您可以使用cv2.useOptimized()来检查它是否启用/禁用,并使用cv2.setUseOptimized()来启用/禁用它。
cv2.setUseOptimized(False) # 关闭
cv2.useOptimized() # 返回bool类型以上,欢迎批评指正。