4.1模型评估
1.由于像多重回归这样的问题会导致无法在图上展示,所以需要能够够定量地表示机器学习模型的精度。
4.2交叉验证
4.2.1回归问题的验证
1.把获取的全部训练数据分成两份:一份用于测试,一份用于训练。然后用前者来评估模型。
一般来说,比起 5 : 5,大多数情况会采用 3 : 7 或者 2 : 8 这种训练数据更多的比例。不过倒也没有特别规定必须要这样。
2.模型评估就是检查训练好的模型对测试数据的拟合情况。
3.对于回归的情况,只要在训练好的模型上计算测试数据的误差的平方,再取其平均值就可以了。假设测试数据有 n 个,那么可以这样计算。

这个值被称为均方误差或者 MSE,全称 Mean Square Error 。这个误差越小,精度就越高,模型也就越好。
4.2.2分类问题的验证
1.假设分类结果为正的情况是 Positive、为负的情况是 Negative。分类成功为 True、分类失败为 False。

下列表达式表示的是在整个数据集中,被正确分类的数据 TP 和 TN 所占 的比例。

用测试数据来计算这个值,值越高精度越高,也就意味着模型越好。
4.2.3精确率和召回率
1.假设图中的圆点是 Positive 数据、叉号是 Negative 数据,我们来考虑一下数据量极其不平衡的情况。
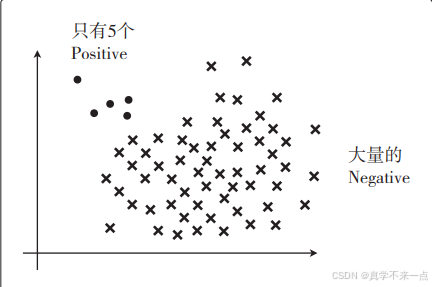
假设有 100 个数据,其中 95 个是 Negative。那么,哪怕出现模型把数据全部分类为 Negative 的极端情况,Accuracy 值也为 0.95, 也就是说模型的精度是 95%。
既然 Positive 相对少很多,那么即使模型把数据全 部分类为 Negative,它的精度也会很高。
2.所以需要引入新的指标,第一个指标——精确率。
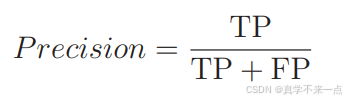

它的含义是在被分类为 Positive 的数据中,实际就是 Positive 的数据所占的比例。
这个值越高,说明分类错误越少。拿这个例子来说,虽然被分类为 Positive 的数据有 3 个,但其中只有 1 个是分类正确的。所以计算得出的精确率很低。
3. 还有一个指标——召回率。


它的含义是在 Positive 数据中,实际被分类为 Positive 的数据所占的比例。
这个值越高,说明被正确分类的数据越多。拿这个例子来说,虽然 Positive 数据共有 5 个,但只有 1 个被分类为 Positive。所以计算得出的召回率也很低。
4. 一般来说,精确率和召回率会一个高一个低,需要我们取舍。
4.2.4F值
1.精确率和召回率只要有一个低,就会拉低 F 值。

Precision 是前面说的精确率,Recall 是召回率。
有时称 F 值为 F1 值会更准确。
F1 值在数学上是精确率和召回率的调和平均值。
2. 除 F1 值之外,还有一个带权重的 F 值指标。
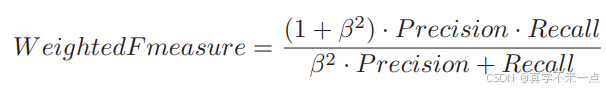
β 指的是权重。可以认为 F 值指的是带权重的 F 值,当权重为 1 时才是刚才介绍的 F1 值
3.当数据不平衡时,使用数量少的那个为主来计算精确率和召回率会更好。例如刚刚是TP比较少,所以以TP为主来计算。
4.把全部训练数据分为测试数据和训练数据的做法称为交叉验证。
5.交叉验证的方法中,尤为有名的是 K 折交叉验证,掌握这种方法很有好处。
把全部训练数据分为 K 份
将K − 1 份数据用作训练数据,剩下的 1 份用作测试数据
每次更换训练数据和测试数据,重复进行 K 次交叉验证
最后计算 K 个精度的平均值,把它作为最终的精度
假设要进行 4 折交叉验证。

6. 不切实际地增加 K 值会非常耗费时间,所以我们必须要确定一个合适的 K 值。
4.3正则化
4.3.1过拟合
1.模型只能拟合训练数据的状态被称为过拟合。在回归时,过度增加函数 fθ(x)的次数会导 致过拟合。
2.有几种方法可以避免过拟合。
增加全部训练数据的数量
使用简单的模型
正则化
4.3.2正则化的方法
1.我们要向目标函数增加下面这样的正则化项。
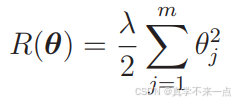

我们要对这个新的目标函数进行最小化,这种方法就称为正则化。
m 是参数的个数。
2.θ0 这种只有参数的项称为偏置项,一般不对它进行正则化。
3.λ 是决定正则化项影响程度的正的常数。
4.3.3正则化的效果
1.首先把目标函数分成两个部分。

C(θ) 是本来就有的目标函数项,R(θ) 是正则化项。
2.假设C(θ)和R(θ)的图像如下:
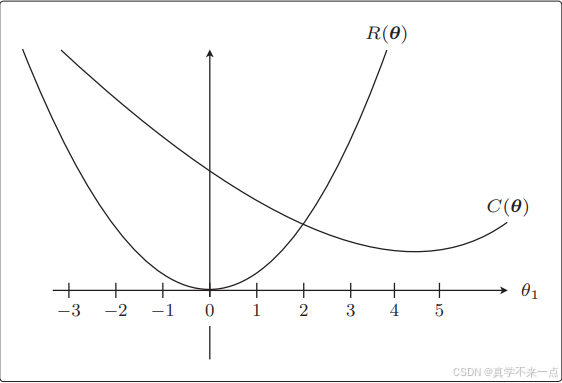

与加正则化项之前相比,θ1 更接近 0 了。这就是正则化的效果。它可以防止参数变得过大,有助于参数接近较小的值。虽然我们只考虑了 θ1,但其他 θj 参数的情况也是类似的。
参数的值变小,意味着该参数的影响也会相应地变小。
正是通过减小不需要的参数的影响,将复杂模型替换为简单模型来防止过拟合的方式。
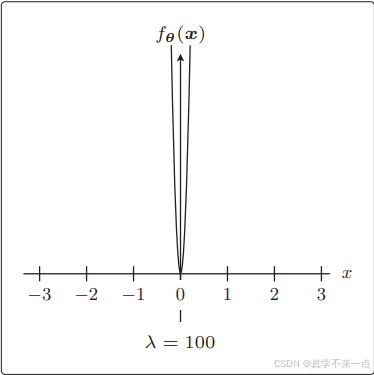
3.λ是可以控制正则化惩罚的强度。
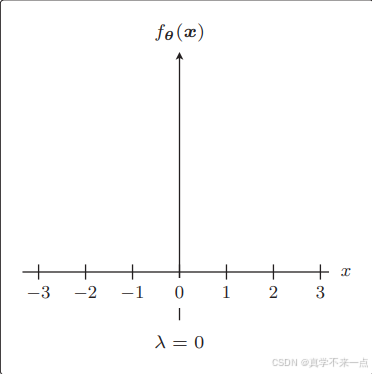
反过来 λ 越大,正则化的惩罚也就越严厉。
4.3.4分类的正则化
1.分类也可以应用正则化。

对数似然函数本来以最大化为目标。但是,这次我想让它变成和回归的目标函数一样的最小化问题,所以在原来的目标函数上加了负号。
反转了符号之后,在更新参数时就要像回归一样,与微分的函数的符号反方向移动才行。
4.3.5包含正则化项的表达式的微分
1.新的目标函数的形式:




最终的微分结果:

参数更新表达式:

2.之 前说过一般不对 θ0 应用正则化。R(θ) 对 θ0 微分的结果为 0,所以 j = 0 时表达式 4.3.14 中的 λθj 就消失了。因此,实际上需要像这样区分两种情况。

3.对于逻辑回归的流程也是一样的:

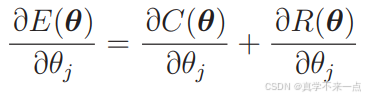
参数更新表达式:

这种方法被称为L2正则化。
4.除 L2 正则化方法之外,还有 L1 正则化方法。它的正则化项 R 是这样的。
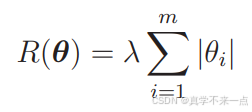
5.L1 正则化的特征是被判定为不需要的参数会变为 0,从而减少变量个数。而 L2 正则化不会把参数变为 0。
6.L2 正则化会抑制参数,使变量的影响不会过大,而 L1 会直接去除不要的变量。
4.4学习曲线
4.4.1欠拟合
1.欠拟合是与过拟合相反的状态,所以它是没有拟合训练数据的状态。
比如用直线对图中这种拥有复杂边界线的数据进行分类的情况,无论怎样做都不能很好地分类,最终的精度会很差。

4.4.2区分过拟合和欠拟合
1.如果模型过于简单,那么随着数据量的增加,误差也会一点点变大。换句话说就是精度会一点点下降。
2.训练数据较少时训练好的模型难以预测未知的数据,所以精度很低;反过来说,训练数据变多时,预测精度就会一点点地变高。
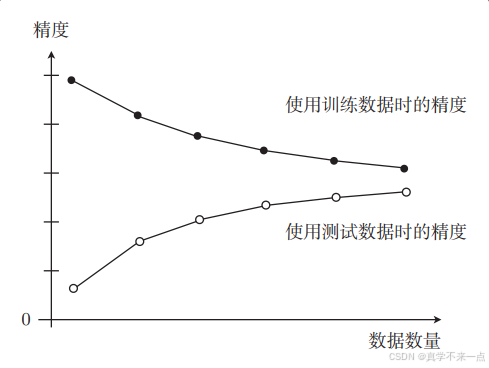
3.将两份数据的精度用图来展示后,如果是这种形状,就说明出现了欠拟合的状态。也有一种说法叫作高偏差。
这是一种即使增加数据的数量,无论是使用训练数据还是测试数据,精度也都会很差的状态
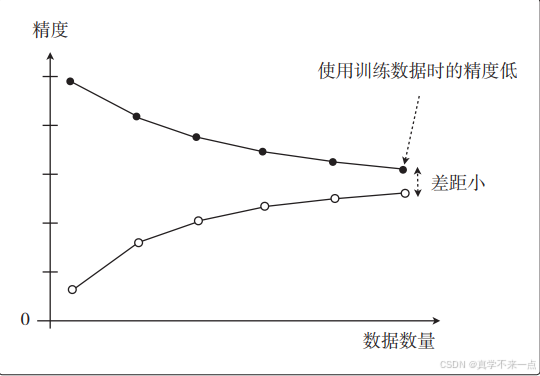
4.而在过拟合的情况下,图是这样的。这也叫作高方差。
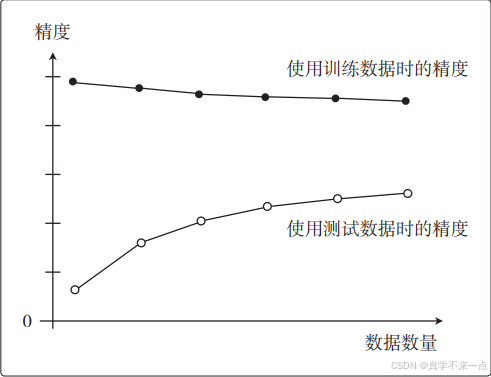
随着数据量的增加,使用训练数据时的精度一直很高,而使用测试数据时的精度一直没有上升到它的水准。
5.展示了数据数量和精度的图称为学习曲线。
通过学习曲线判断出是过拟合还是欠拟合之后,就可以采取相应的对策以便改进模型了。