文章目录
一、背景
在如今大型互联网公司中,数据其实就是公司的核心。而这个数据的概念中不仅包括了实时数据的查询展示,也包括了离线数据的分析与辅助决策。比如现在的App中流行的推荐功能,其都是依靠海量的数据喂给算法模型训练,然后才能够精准的预测和推荐出用户的喜爱。而海量的数据存储是依靠的数据仓库的搭建与大数据的开发处理,在大数据开发中,Hive是非常重要的数据统计工具。Apache Hive是基于Hadoop的一个数据仓库基础设施,它可以对存储在Hadoop HDFS中的大规模数据进行数据总结、查询和分析。Hive提供了一种类SQL的查询语言——HiveQL(Hive Query Language),使得用户可以方便地对海量数据进行操作。本文将先介绍数据仓库的相关概念,然后再详细介绍Hive的定义、架构、工作原理、应用场景,旨在帮助读者全面了解和掌握Hive的基本原理。
二、数据仓库
2.1 数据仓库概念
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。
数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用,这也是为什么叫“仓库”,而不叫“工厂”的原因。
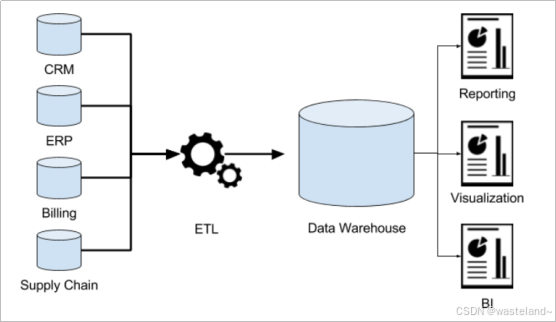
2.2 数据仓库分层架构
2.2.1 数仓分层思想和标准
数据仓库的特点是本身不生产数据,也不最终消费数据。数据分层每个企业根据自己的业务需求可以分成不同的层次,但是最基础的分层思想,理论上数据分为三个层,操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA)。
2.2.2 阿里巴巴数仓3层架构
ODS层(Operation Data Store)
操作型数据层,也称之为源数据层、数据引入层、数据暂存层、临时缓存层。此层存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到数仓的职责,和数据源系统进行解耦合,同时记录基础数据的历史变化。
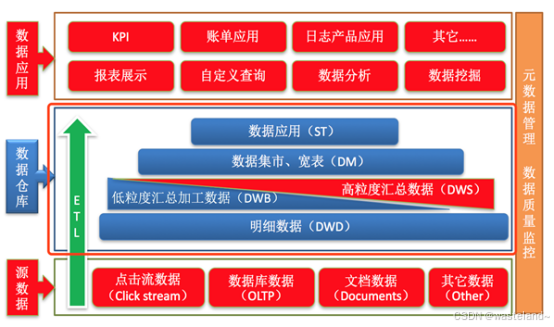
DW层(Data Warehouse)
数据仓库层。此层内部具体包括DIM维度表、DWD和DWS,由ODS层数据加工而成,其主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
数据应用层(DA或ADS)
面向最终用户,面向业务定制提供给产品和数据分析使用的数据。包括前端报表、分析图表、KPI、仪表盘、OLAP专题、数据挖掘等分析。
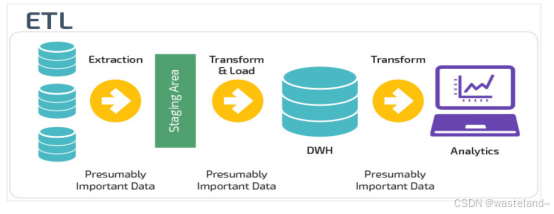
2.2.3 ETL和ELT
ETL: 首先从数据源池中提取数据,这些数据源通常是事务性数据库。提取的数据保存在临时暂存数据库中,然后执行转换操作,将数据结构化并转换为适合目标数据仓库系统的形式以备分析。
ETL:数据在从源数据池中提取后立即加载到单一的集中存储库中,没有临时数据库,然后数据在数据仓库系统中进行转换,以便与商业智能工具和分析一起使用。大数据时代的数仓这个特点很明显。

2.2.4 为什么要分层
分层的主要原因是在管理数据的时候,能对数据有一个更加清晰的掌控,详细来讲,主要有下面几个原因:
清晰数据结构:
每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。
数据血缘追踪:
简单来说,我们最终给业务呈现的是一个能直接使用业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
减少重复开发:
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
把复杂问题简单化:
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
屏蔽原始数据的异常:
屏蔽业务的影响,不必改一次业务就需要重新接入数据。
2.3 数据仓库特征
数据仓库是面向主题性(Subject-Oriented )、集成性(Integrated)、非易失性(Non-Volatile)和时变性(Time-Variant )数据集合,用以支持管理决策 。
2.3.1 面向主题性
数据库中,最大的特点是面向应用进行数据的组织,各个业务系统可能是相互分离的。而数据仓库则是面向主题的,主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。
2.3.2 集成性
确定主题之后,就需要获取和主题相关的数据。当下企业中主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。因此在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库建设中最关键、最复杂的一步,所要完成的工作有:
(1)要统一源数据中所有矛盾之处,如字段的同名异义、异名同义、单位不统一、字长不一致,等等。
(2)进行数据综合和计算。数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
2.3.3 非易失性
数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其中的规律。因此数据进入数据仓库后,它便稳定且不会改变。
操作型数据库主要服务于日常的业务操作,使得数据库需要不断地对数据实时更新,以便迅速获得当前最新数据,不至于影响正常的业务运作。在数据仓库中只要保存过去的业务数据,不需要每一笔业务都实时更新数据仓库,而是根据商业需要每隔一段时间把一批较新的数据导入数据仓库。
数据仓库的数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据。
数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。数据仓库中一般有大量的查询操作,但修改和删除操作很少。
2.3.4 时变性
数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关。虽然数据仓库的用户不能修改数据,但并不是说数据仓库的数据是永远不变的。分析的结果只能反映过去的情况,当业务变化后,挖掘出的模式会失去时效性。因此数据仓库的数据需要随着时间更新,以适应决策的需要。
数据仓库的数据随时间的变化表现在以下几个方面。
(1)数据仓库的数据时限一般要远远长于操作型数据的数据时限。
(2)操作型系统存储的是当前数据,而数据仓库中的数据是历史数据。
(3)数据仓库中的数据是按照时间顺序追加的,它们都带有时间属性。
三、hive库
3.1 hive概述
Apache Hive是由 Facebook 开源用于解决海量结构化日志的数据统计工具,其是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。而HQL其实就是Hive缩写为H,Query缩写为Q,Language缩写为L。
3.2 hive架构
3.2.1 hive架构图
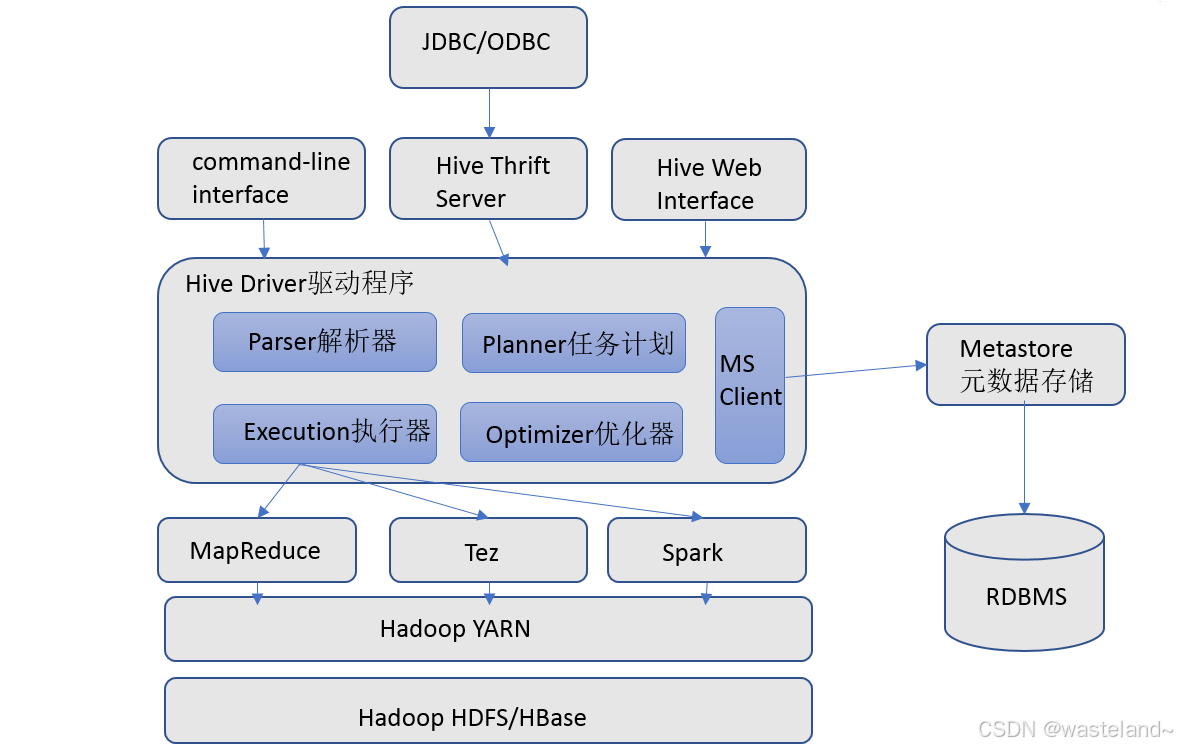
3.2.2 hive组件
用户接口:包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
元数据存储:通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。
执行引擎:Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
启动命令:
hive --service metastore
hive --service hiveserver2
//杀掉端口占用了10000的yunDetectService服务,占用端口
3.3 hive工作原理
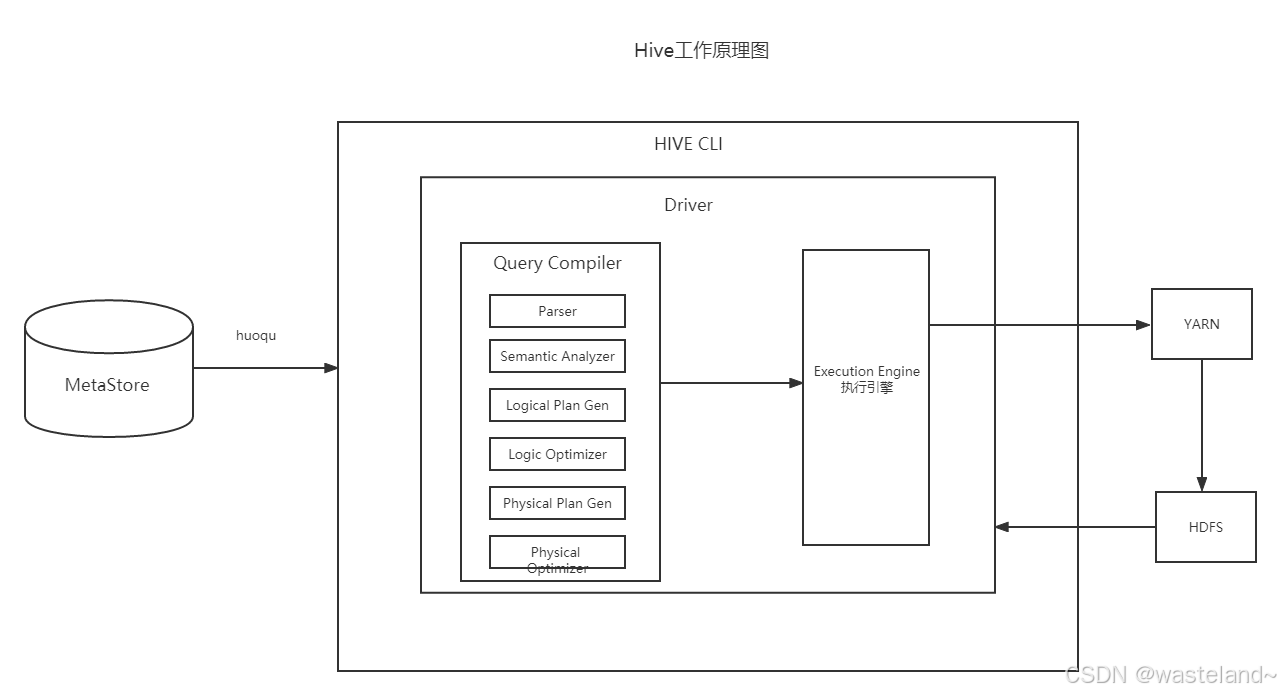
由于Hive是一个数据仓库工具,没有数据存储功能,它的数据是从HDFS来获得的,但是它又不能直接从HDFS进行数据访问,它是通过MapReduce来实现的,本质上也就是将HQL语句转换为MapReduce的任务,然后来进行数据访问。
将HQL语句转换为MapReduce任务进行运行的流程如下:
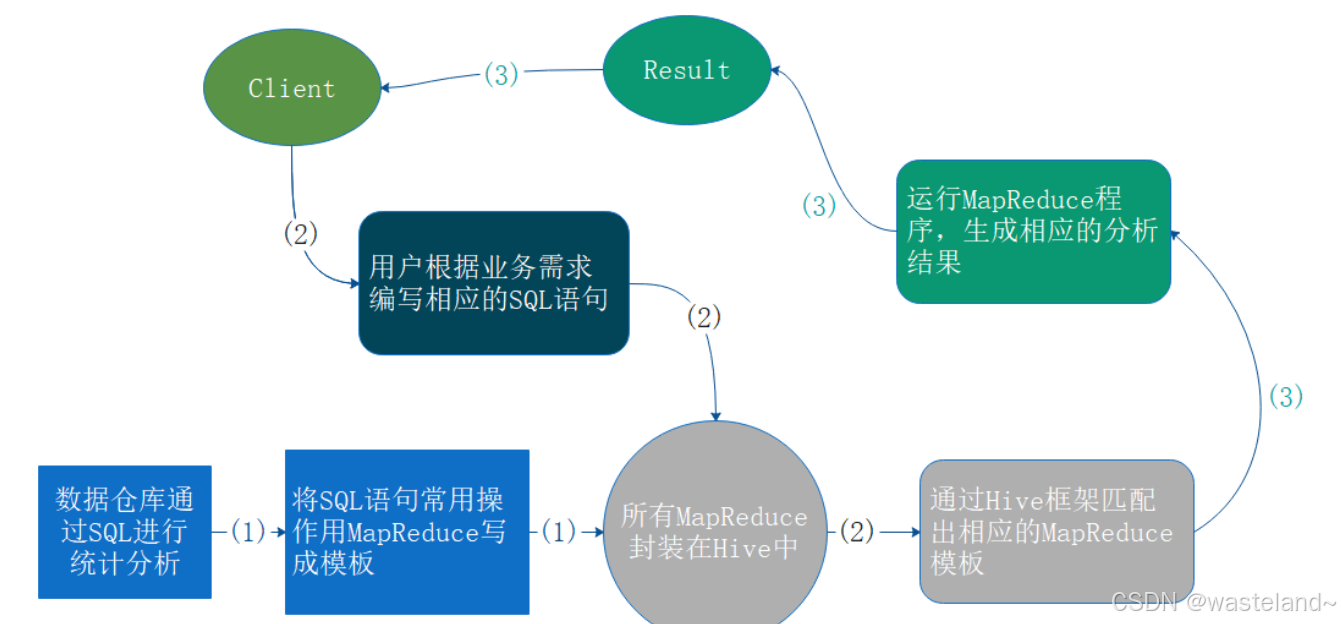
在搭建Hive数据仓库时,将相关语句常用的指令操作,比如SELECT、FROM、WHERE以及函数用MapReduce写成模板,并且将这些所有的MapReduce的模板封装到Hive中。这是我们在搭建Hive数据仓库的时候就形成的。那我们所要做的,如果我们是开发,根据业务需求编写相应的SQL语句,它会自动地到Hive封装的这些MapReduce中去匹配。匹配完之后就运行MapReduce程序,生成相应的分析结果,然后反馈给我们。
简单来说Hive就是一个查询引擎,当Hive接受到一条SQL语句会执行如下操作:
1.词法分析和语法分析。使用antlr将SQL语句解析成抽象语法树。
2.语义分析。从MetaStore中获取元数据信息,解释SQL语句中的表名、列名、数据类型。
3.逻辑计划生成。生成逻辑计划得到算子树。
4.逻辑计划优化。对算子树进行优化。
5.物理计划生成。将逻辑计划生成出的MapReduce任务组成的DAG的物理计划。
6.物理计划执行。将DAG发送到Hadoop集群进行执行。
7.返回查询结果。
3.5 hive数据模型
数据模型:用来描述数据、组织数据和对数据进行操作,是对现实世界数据特征的描述。Hive的数据模型类似于RDBMS库表结构,此外还有自己特有模型。Hive数据在种类上可区分为元数据和表数据二种,表数据我们都知道是表中的数据,而元数据是用来存储表的名字、列、表分区以及属性。
3.5.1 元数据
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
3.5.1.1 Metadata
元数据(Metadata),主要记录数据仓库中模型的定义、各层级间的映射关系、监控数据仓库的数据状态及 ETL 的任务运行状态。一般会通过元数据资料库(Metadata Repository)来统一地存储和管理元数据,其主要目的是使数据仓库的设计、部署、操作和管理能达成协同和一致。元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
3.5.1.2 Metastore
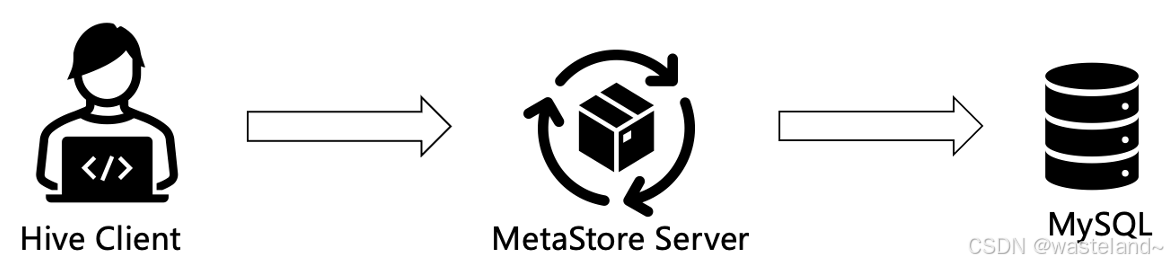
Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。
3.5.1.3 元数据存储模式
内嵌模式: 这种模式连接到一个本地内嵌的数据库Derby,通常用于单元测试。内嵌的Derby数据库每次只能访问一个数据文件,这意味着它不支持多会话连接。这种配置适用于轻量级的测试场景,其中每个测试可以在相对独立的数据库环境中运行,确保测试之间的隔离性和可重复性。
多用户模式: 这种模式本质上将Hive默认的元数据存储介质从内置的Derby数据库切换至MySQL数据库。通过这种配置,不论以何种方式或在何处启动Hive,只要连接到同一台Hive服务,所有节点都能访问一致的元数据信息,实现元数据的共享。
远程服务器模式: 在远程模式下,MetaStore服务在其自己的独立JVM上运行,而不是在HiveServer的JVM中。其他进程若要与MetaStore服务器通信,则可以使用Thrift协议连接至MetaStore服务进行元数据库访问。在生产环境中,强烈建议配置Hive MetaStore为远程模式。在这种配置下,其他依赖于Hive的软件能够通过MetaStore访问Hive。由于这种模式下还可以完全屏蔽数据库层,因此带来更好的可管理性和安全性。
3.5.2 表数据
Hive中的数据可以在粒度级别上分为三类:Table 表、Partition分区、Bucket 分桶。
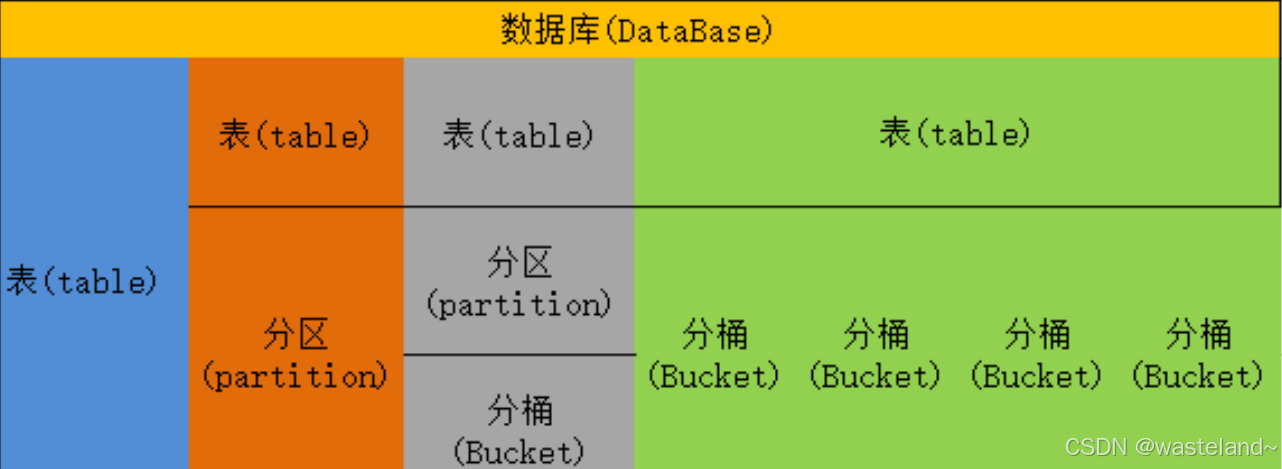
3.5.2.1 Table表
Table表:表是由存储的数据以及描述表的一些元数据组成。hive表分四种:内部表(MANGED_TABLE)、外部表(EXTERNAL_TABLE)、索引表(INDEX_TABLE)、视图表(VIRTUAL_VIEW)
3.5.2.1.1 内部表
Hive的数据都是存储在HDFS上的,存储路径为:${hive.metastore.warehouse.dir}/databasename.db/tablename,默认有一个根目录,在hive-site.xml中,由参数hive.metastore.warehouse.dir指定,其默认值为/user/hive/warehouse。
# 例如:
CREATE TABLE managed_table (dummy STRING);
LOAD DATA INPATH '/user/tom/data.txt' INTO table managed_table;
# 描述:根据上面的代码,hive 会把文件 data.txt 文件存储在 warehouse 目录下的managed_table 表 ,即 hdfs://user/hive/warehouse/databasename.db/managed_table 。
3.5.2.1.2 外部表
外部表与内部表的行为上有些差别。我们能够控制数据的创建和删除。删除外部表的时候,hive只会删除表的元数据,不会删除表数据(数据路径是在创建表的时候指定的):
# 例如:
CREATE EXTERNAL TABLE external_table (dummy STRING)
LOCATION '/user/tom/external_table';
LOAD DATA INPATH '/user/tom/data.txt' INTO TABLE external_table;
# 描述:利用EXTERNAL关键字创建外部表,Hive不会去管理表数据,所以它不会把数据移到/user/hive/warehouse目录下。
3.5.2.2 Partition分区
Partition分区是hive的一种优化手段表。Partition分区:hive的分区是根据某列的值(例如“日期day”)进行粗略的划分,每个分区对应HDFS上的一个目录。分区在存储层面上的表现是:table表目录下以子文件夹形式存在,一个文件夹表示一个分区,子文件命名标准:分区列=分区值。分区表基于分区键把具有相同分区键的数据存储在一个目录下,在查询某一个分区的数据的时候,只需要查询相对应目录下的数据,而不会执行全表扫描,提高查询数据的效率。也就是说,hive 在查询的时候会进行分区剪裁 ,每个表可以有一个或多个分区键。
3.5.2.2.1 静态分区
- 把输入数据文件单独插入分区表的叫静态分区;
- 通常在加载文件(大文件)到 Hive 表的时候,首先选择静态分区;
- 在加载数据时,静态分区比动态分区更节省时间;
- 可以通过
alter table add partition语句在表中添加一个分区,并将文件移动到表的分区中; - 静态分区中的分区可以修改;
- 可以从文件名、日期等获取分区列值,而无需读取整个大文件;
- 如果要在 Hive 使用静态分区,需要把
hive.mapred.mode设置为strict,set hive.mapred.mode=strict; - 可以在 Hive的内部表和外部表使用静态分区。
3.5.2.2.2 动态分区
- 对分区表的一次性插入称为动态分区;
- 通常动态分区表从非分区表加载数据;
- 在加载数据的时候,动态分区比静态分区会消耗更多时间;
- 如果需要存储到表的数据量比较大,那么适合用动态分区;
- 假如要对多个列做分区,但又不知道有多少个列,那么适合使用动态分区;
- 动态分区不需要
where子句使用limit; - 不能对动态分区执行修改;
- 可以对内部表和外部表使用动态分区;
- 使用动态分区之前,需要把模式修改为非严格模式。
set hive.mapred.mode=nostrict。
3.5.2.3 Bucket 分桶
Bucket分桶表是hive的一种优化手段表。hive 是针对表的某一列进行分桶,采用对表的列值进行哈希计算,然后除以桶的个数求余的方式决定该条记录存放在哪个桶中(分桶的好处是可以获得更高的查询处理效率,使取样更高效)。
要使用hive的分桶功能,首先需要打开hive对桶的控制:
set hive.enforce.bucketing=true;
分桶表创建命令:
CREATE TABLE table_name
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
CLUSTERED BY (column_name1, column_name2, …)
SORTED BY (column_name [ASC|DESC], …)]
INTO num_buckets BUCKETS;
每个桶只是表目录或者分区目录下的一个文件,如果表不是分区表,那么桶文件会存储在表目录下,如果表是分区表,那么桶文件会存储在分区目录下。所以你可以选择把分区分成 n 个桶,那么每个分区目录下就会有 n 个文件。
3.5.2.3.1 Bucket 分桶特性
数据分桶原理是基于对分桶列做哈希计算,然后对哈希的结果和分桶数取模。分桶特性如下:
- 哈希函数取决于分桶列的类型;
- 具有相同分桶列的记录将始终存储在同一个桶中;
- 使用
clustered by将表分成桶; - 通常,在表目录中,每个桶只是一个文件,并且桶的编号是从 1 开始的;
- 分桶表创建的数据文件大小几乎是一样的。
3.5.2.3.2 Bucket 分桶好处
- 与非分桶表相比,分桶表提供了高效采样。通过采样,我们可以尝试对一小部分数据进行查询,以便在原始数据集非常庞大时进行测试和调试;
- 由于数据文件的大小是几乎一样的,
map端的join在分桶表上执行的速度会比分区表快很多。在做map端join时,处理左侧表的 map知道要匹配的右表的行在相关的桶中,因此只需要检索该桶即可; - 分桶表查询速度快于非分桶表;
- 分桶的还提供了灵活性,可以使每个桶中的记录按一列或多列进行排序。 这使得 map 端 join 更加高效,因为每个桶之间的 join变为更加高效的合并排序(
merge-sort)。
3.5.2.4 分区与分桶的区别
- 分区和分桶最大的区别就是分桶随机分割数据库,分区是非随机分割数据库;
分区是水平划分,表的部分列的集合,可以为频繁使用的数据建立分区,这样查找分区中的数据时就不需要扫描全表,这对于提高查找效率很有帮助;分桶是垂直划分,桶是通过对指定列进行哈希计算来实现的,通过哈希值将一个列名下的数据切分为一组桶,并使每个桶对应于该列名下的一个存储文件;- 分桶是存储在
文件中,分区是存放在文件夹中,分桶要比分区查询效率高。
3.6 hive数据类型
Hive支持两种数据类型,一种原子数据类型、还有一种叫复杂数据类型。
原子数据类型
| 类型 | 描述 |
|---|---|
| TINYINT | 1字节有符合整数 |
| SMALLINT | 2字节有符号整数 |
| INT | 4字节有符号整数 |
| BIGINT | 8字节有符号整数 |
| FLOAT | 4字节单精度浮点数 |
| DOUBLE | 8字节双精度浮点数 |
| BOOLEAN | true/false |
| STRING | 字符串 |
复杂数据类型
| 类型 | 描述 |
|---|---|
| ARRAY | 有序的字段,字符类型必须相同 |
| MAP | 无序的键值对,建的类型必须是原子的,值可以是任何类型 |
| STRUCT | 一组命名的字段,字段类型可以不同 |
Hive类型中的String数据类型类似于MySQL中的VARCHAR,该类型是一个可变的字符串。
Hive支持数据类型转换,Hive是用Java编写的,所以数据类型转换规则遵循Java :
隐式转换 --> 小转大
强制转换 --> 大传小
3.7 hive文件格式
- TextFile
- 这是默认的文件格式,数据不会压缩处理,磁盘开销大,数据解析开销也大
- SequenceFile
- 这是Hadoop API提供的一种二进制文件支持,以二进制的形式序列化到文件中
- RCFile
- 这种格式是行列存储结构的存储方式
- ORC
- Optimized Row Columnar ORC文件格式是一种Hadoop生态圈中的列式存储格式
3.8 hive本质
将HQL转换成MapReduce程序。
- Hive处理的数据存储在HDFS上
- Hive分析数据底层的实现是MapReduce
- 执行程序运行在Yarn上
3.9 hive优缺点
优点:
- 类似于SQL语句,简单学习易上手,避免了去写 MapReduce,减少开发人员的学习成本
- 在数据存储方面,它能够存储很大的数据集(实际上它是不存储数据的,这里的“很大的数据集”实际上指的是HDFS),并且它对数据完整性和格式要求不严格(只要是结构化的就可以了)
- Hive 的执行延迟比较高,因此 Hive 常用于数据分析,处理大数据,对于处理小数据没有优势,适用于对实时性要求不高的场合
- Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
- Hive 的 HQL 表达能力有限
- Hive 的效率比较低
- Hive本质是一个MR
四、hive与Hadoop的关系
从功能来说,数据仓库软件,至少需要具备下述两种能力:
- 存储数据的能力
- 分析数据的能力
Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于用户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
五、Hive是要取代Mysql吗?
Hive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都十分相似,但应用场景却完全不同。Hive只适合用来做海量数据的离线分析。Hive的定位是数据仓库,面向分析的OLAP系统。因此,Hive不是大型数据库,也不是要取代Mysql承担业务数据处理。更直观的对比如下表所示:
| hive | mysql | |
|---|---|---|
| 定位 | 数据仓库 | 数据库 |
| 使用场景 | 离线数据分析 | 业务数据事务处理 |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Local FS |
| 执行引擎 | MR、Tez、Spark | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 常见操作 | 导入数据、查询 | 增删查改 |
六、hive应用场景
数据仓库
Hive常用于数据仓库场景,帮助企业将大规模数据进行存储、管理和查询。通过Hive,企业可以构建一个统一的数据仓库,将各类数据集中存储,并利用HiveQL进行数据分析和报表生成。
数据分析
Hive在大数据分析中扮演重要角色,适用于各种数据分析任务。利用Hive,数据分析师可以通过类SQL语言对海量数据进行复杂查询和统计分析,支持业务决策。
日志处理
Hive在日志处理方面有广泛应用,许多公司利用Hive来存储和分析日志数据。通过将日志数据导入Hive表,用户可以方便地对日志进行查询和分析,获取有价值的信息。
七、总结
Hive作为一个强大的数据仓库工具,凭借其类SQL的查询语言、与Hadoop生态系统的无缝集成以及强大的扩展性,广泛应用于各种数据仓库、数据分析和日志处理场景。通过本文的介绍,相信读者已经对数仓的基本概念、Hive的定义、架构、工作原理、应用场景有了全面的了解。在实际应用中,结合具体需求合理使用Hive,将能够充分发挥其优势,解决大规模数据处理和存储的挑战。
