文章目录
1.数据准备
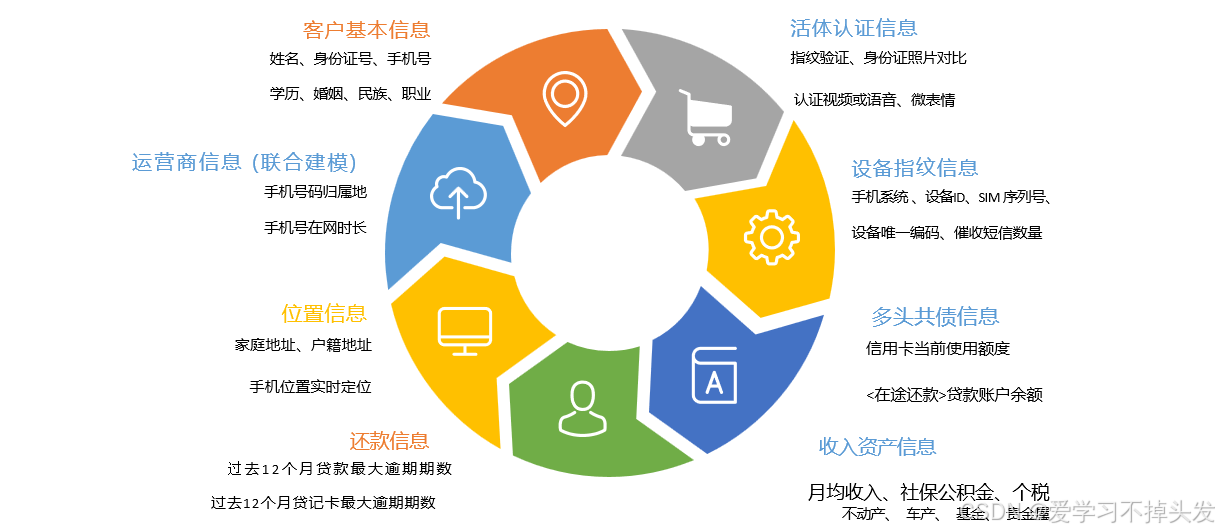
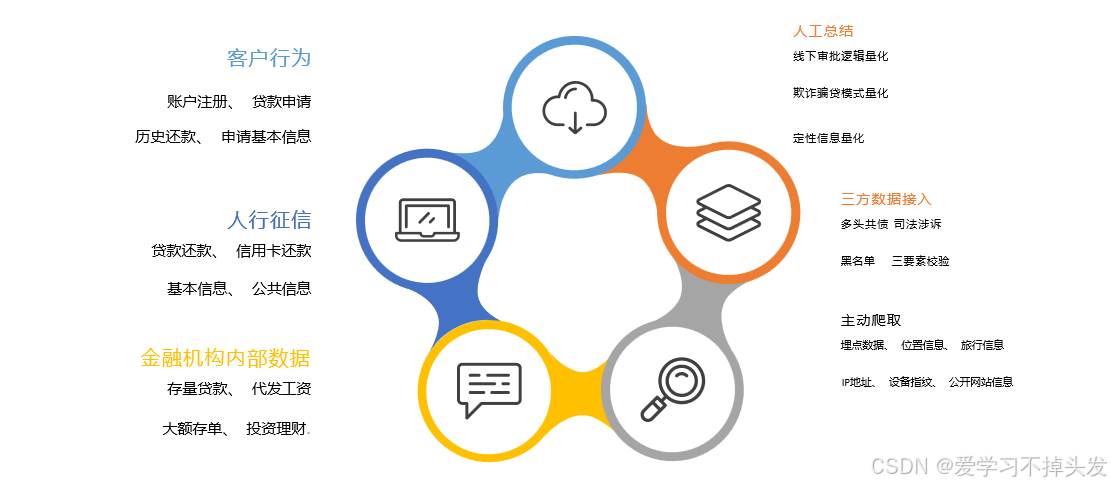
1.1 风控建模特征数据
- 用户信息
- 数据来源
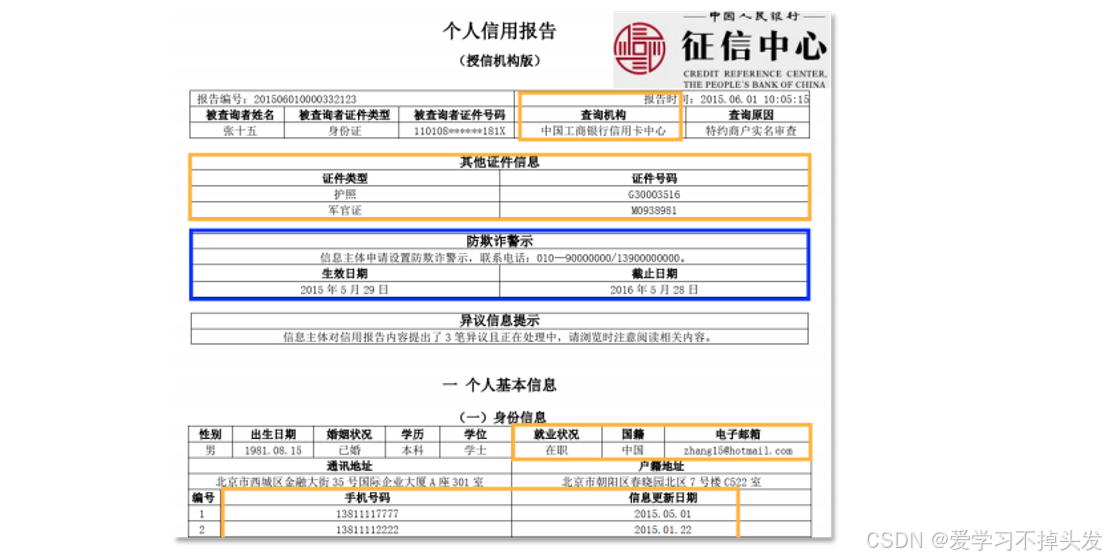
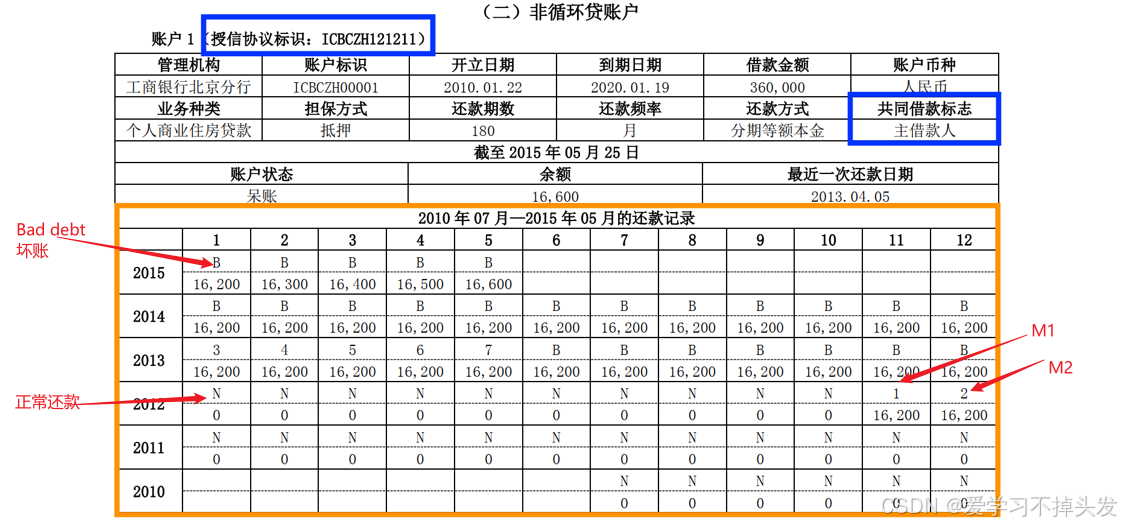
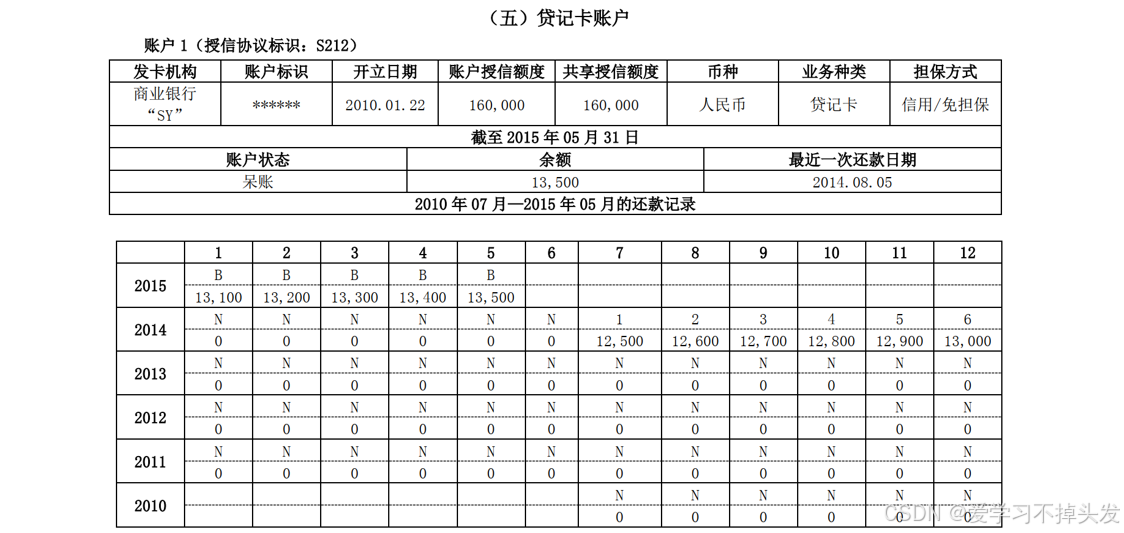
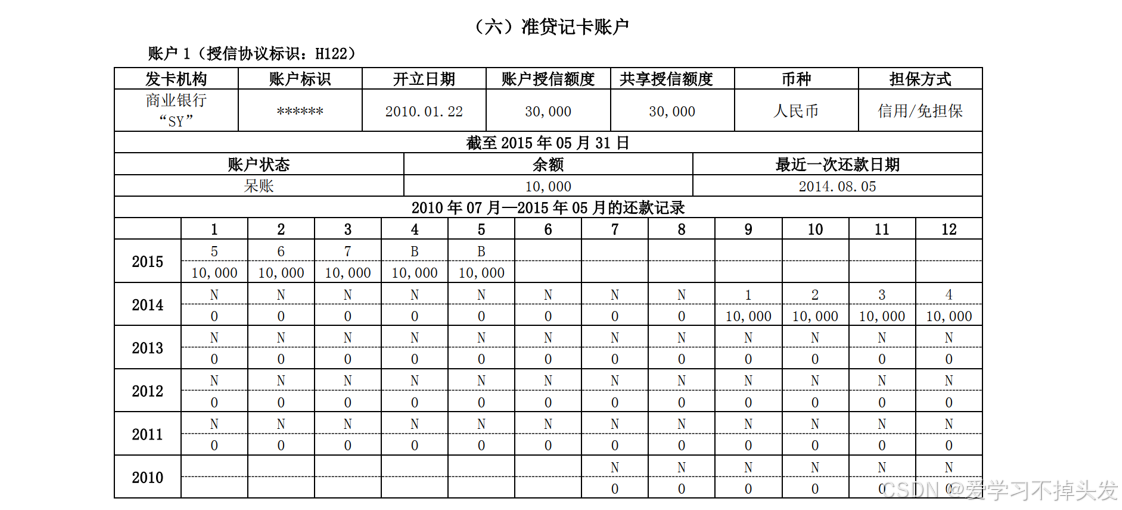
1.2 人行征信数据

1.3 据之间的内在逻辑
- 关系种类
- 一对一:一个用户注册对应有一个注册手机号
- 一对多:一个用户有多笔借款
- 多对多:一个用户可以登录多个设备,一个设备可以有多个用户登录
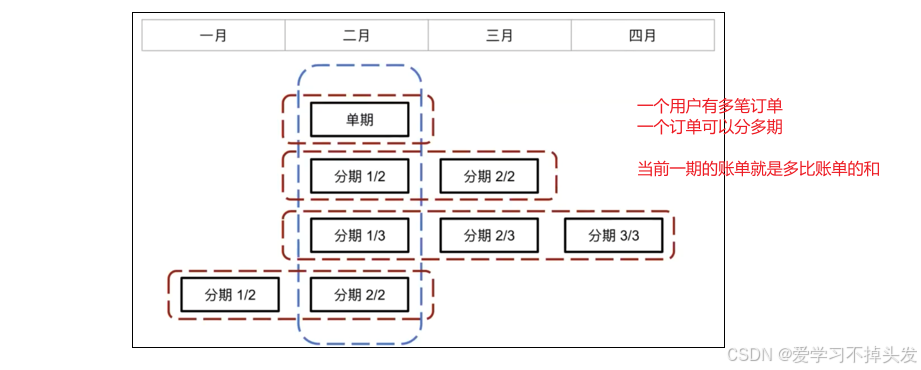
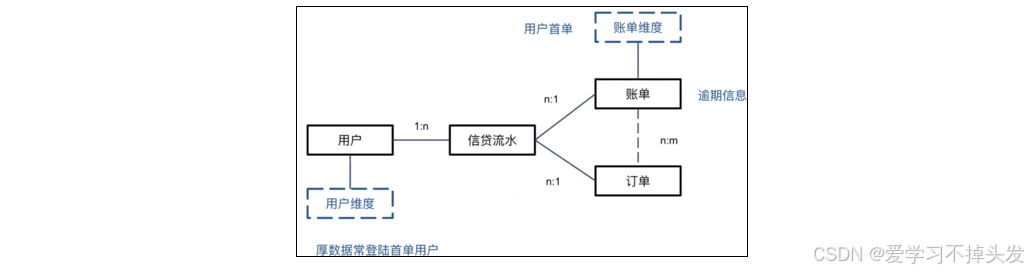
**举例:**下图中,蓝色框为二月当期账单,红色框为订单
- 梳理类ER图
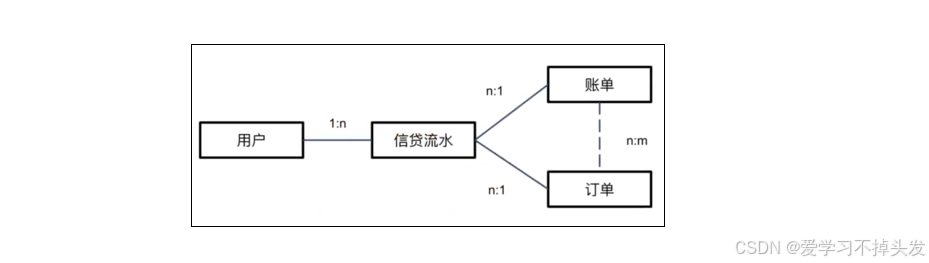
- 任务:分析厚数据(数据量大)常登录首单用户的逾期情况
- 可以将表结构展示到特征文档中,说明取数逻辑

2 样本设计和特征框架
2.1 定义观察期样本
- 确定观察期(定义x时间切面)和表现期(定Y的标签)
- 确认样本数据是否合理
2.2 数据EDA(Explore Data Analysis)
- 查看数据总体分布
data.shape
data.isnull()
data.info()
data.describe()
- 查看好坏样本分布差异
data[data[label] == 0].describe() # 好用户
data[data[label] == 1].describe() # 坏用户
- 查看单个数据
data.sample(n=10,random_state=1)
2.3 梳理特征框架
-
RFM生成新特征
举例:行为评分卡中的用户账单还款特征 -
用户账单关键信息:时间、金额、还款、额度

小结:在构造特征之前,要完成
- 类ER图
- 样本设计表
- 特征框架图
3 特征构造
3.1 静态信息和时间截面特征
-
用户静态信息:用户的基本信息(半年以上不会发生变化)
- 姓名
- 性别
- 年龄
-
用户时间截面:取时间轴上的一个点,作为时间截面
- 截面时间点的购物GVM、银行存款额、逾期最大天数
-
用户时间序列特征:从观察点往前回溯一段时间的数据
- 过去 一个月的GPS数据
- 过去六个月的银行流水
- 过去一年的逾期记录
-
用户时间截面特征相关概念
- 未来信息:当前时间截面之后的数据
- 时间截面数据在取数据的时候,要避免使用未来信息
- 产生未来信息的直接原因:缺少快照表
- 金融相关数据原则上都需要快照表记录所有痕迹(额度变化情况,多次申请的通过和拒绝情况)
- 缺少快照表的原因
* 快照表消耗资源比较大,为了性能不做
* 原有数据表设计人员疏忽,没做
* 借用其他业务数据(如电商)做信贷
- 快照表:每天定时存储一个状态(类似于每天23:00都拍一张照片),每天会把当天的状态进行备份,只存储当天的最终状态。
- 日志表:每一次操作都会记录,不会进行update,只有insert操作,操作一次,插入一条记录。
3.2 未来信息问题
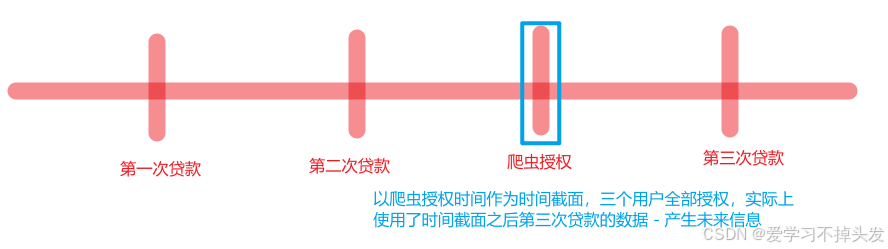
3.2.1 未来信息案例
- 首次借贷 --》二次借贷–》爬虫授权–》三次借贷
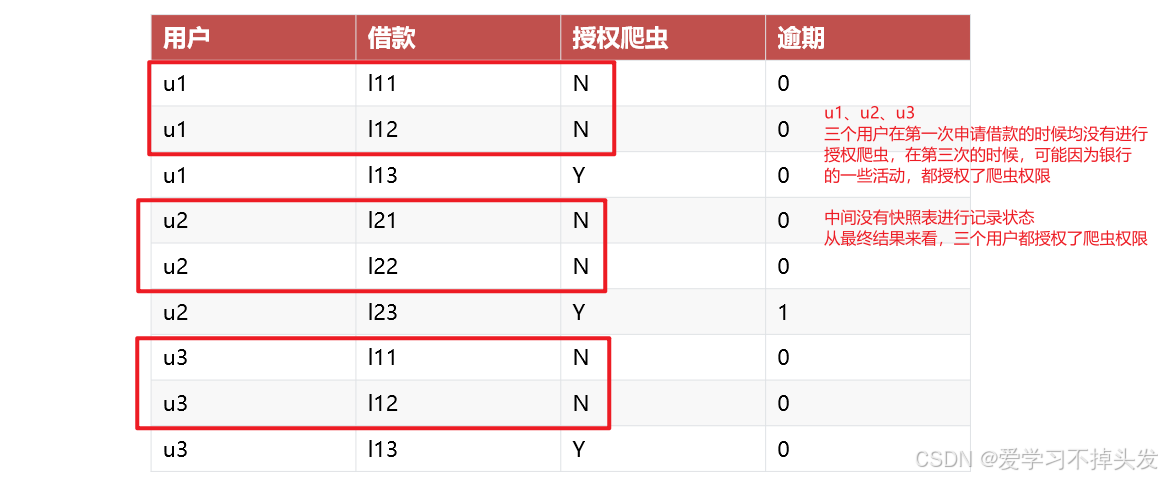
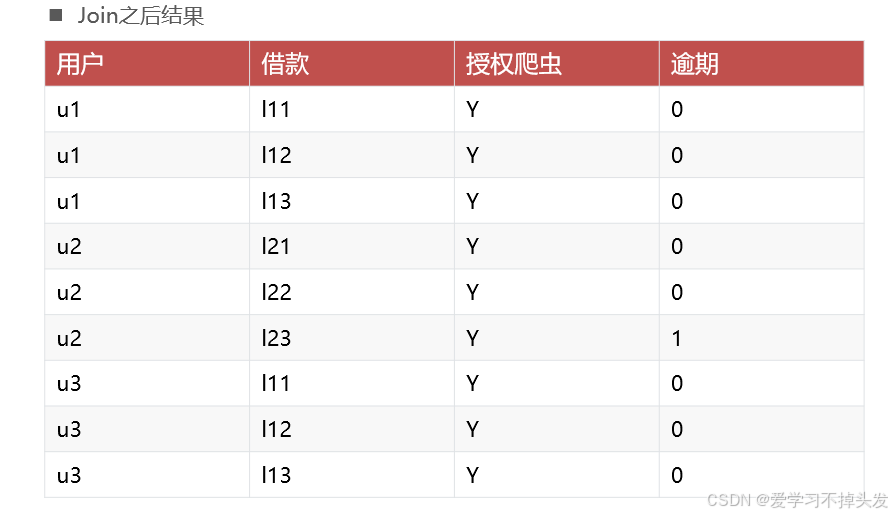
举例:
解决方式:加入快照表存储


3.2.2 时间序列特征的未来信息
时间序列特征:从观察点向前回溯一段时间的数据

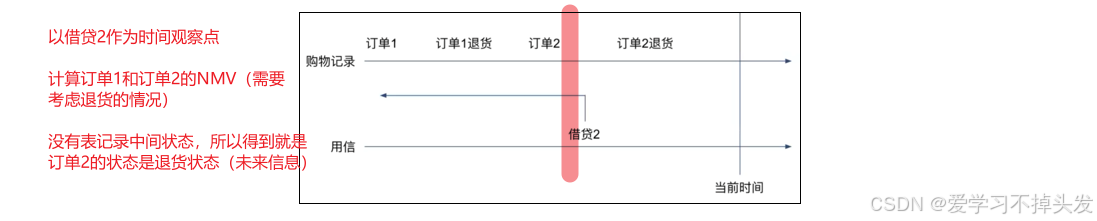
- 以借贷2发生的时间为观测点,下表中的未来信息会将大量退货行为的用户认为是坏客户,但是上下之后效果会变差。
- 特征构建时的补救方法
- 对未来信息窗口外的订单计算有效的特征(NMV)
- 对未来信息窗口内的订单计算一般特征(GMV)
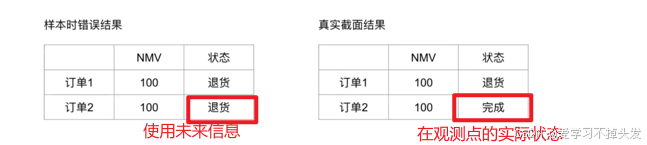
3.2.3 历史信贷特征出现未来信息
- 举例:信用卡每月1日为账单日,每月10日为还款日,次月10日左右为M1(逾期一个月)
- 在上图所示的截面时间(如3月5日)是看不到2月账单的逾期DPD30的情况的
- 但如果数据库没有快照表会导致我们可以拿到2月账单的DPD30情况
- 解决方案跟上面例子一样,分区间讨论,可以把账单分成3类
-
当前未出账账单
-
最后一个已出账账单
-
其他已出账账单 (只有这个特征可以构建逾期类特征)
-

小结:处理未来信息问题
- 及时增加快照表
- 没有快照表的情况下,将数据区分为是否有未来信息的区间,分别进行特征构造
3.3 特征构造
3.3.1 时序数据特征衍生
特征聚合:将单个特征的多个时间节点取值进行聚合。特征聚合是传统评分卡建模的主要特征构造方法
-
举例:计算每个用户的额度使用率,记为特征ft,按照时间轴以月份为切片展开
- 申请前30天内的额度使用率ft1
- 申请前30天至60天内的额度使用率ft2
- 申请前60天至90天内的额度使用率ft3
- 申请前330天至360天内的额度使用率ft12
- 得到一个用户的12个特征
import pandas as pd
import numpy as np
data = pd.read_excel('../data/textdata.xlsx')
data.head()

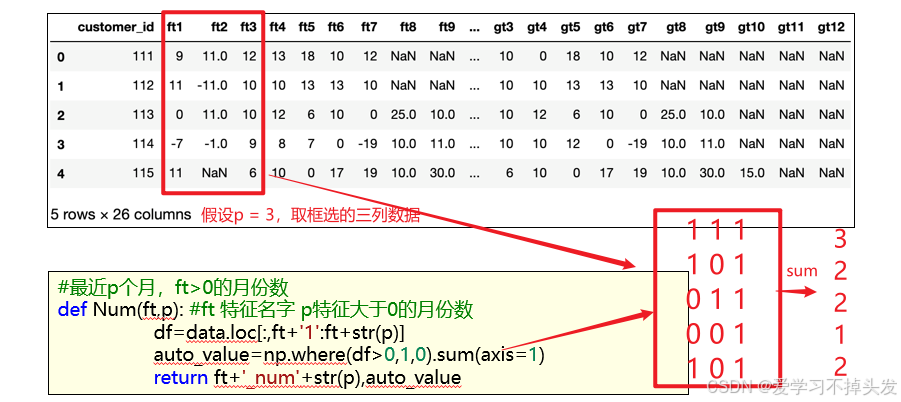
- 可以根据这个时间序列进行基于经验的人工特征衍生,例如计算最近P个月特征大于0的月份数
#最近p个月,ft>0的月份数
def Num(ft,p): #ft 特征名字 p特征大于0的月份数
df=data.loc[:,ft+'1':ft+str(p)] # 选择ft1 - ftp的数据
auto_value=np.where(df>0,1,0).sum(axis=1)
return ft+'_num'+str(p),auto_value
- 计算最近P个月特征ft等于0的月份数
#最近p个月,ft>0的月份数
def Num(ft,p): #ft 特征名字 p特征大于0的月份数
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.where(df>0,1,0).sum(axis=1)
return ft+'_num'+str(p),auto_value
- 计算最近P个月特征ft等于0的月份数
#最近p个月,ft=0的月份数
def zero_cnt(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.where(df==0,1,0).sum(axis=1)
return ft+'_zero_cnt'+str(p),auto_value
- 计算近p个月特征ft大于0的月份数是否大于等于1
#最近p个月,ft>0的月份数是否>=1
def Evr(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
arr=np.where(df>0,1,0).sum(axis=1)
auto_value = np.where(arr,1,0)
return ft+'_evr'+str(p),auto_value
-
- 计算最近p个月特征ft的均值
#最近p个月,ft均值
def Avg(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.nanmean(df,axis = 1 )
return ft+'_avg'+str(p),auto_value
- 计算最近p个月特征ft的和,最大值,最小
#最近p个月,ft和
def Tot(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.nansum(df,axis = 1)
return ft+'_tot'+str(p),auto_value
#最近(2,p+1)个月,ft和
def Tot2T(ft,p):
df=data.loc[:,ft+'2':ft+str(p+1)]
auto_value=df.sum(1)
return ft+'_tot2t'+str(p),auto_value
#最近p个月,ft最大值
def Max(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.nanmax(df,axis = 1)
return ft+'_max'+str(p),auto_value
#最近p个月,ft最小值
def Min(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.nanmin(df,axis = 1)
return ft+'_min'+str(p),auto_value
- 其他衍生方法
#最近p个月,最近一次ft>0到现在的月份数
def Msg(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
df_value=np.where(df>0,1,0)
auto_value=[]
for i in range(len(df_value)):
row_value=df_value[i,:]
if row_value.max()<=0:
indexs='0'
auto_value.append(indexs)
else:
indexs=1
for j in row_value:
if j>0:
break
indexs+=1
auto_value.append(indexs)
return ft+'_msg'+str(p),auto_value
#最近p个月,最近一次ft=0到现在的月份数
def Msz(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
df_value=np.where(df==0,1,0)
auto_value=[]
for i in range(len(df_value)):
row_value=df_value[i,:]
if row_value.max()<=0:
indexs='0'
auto_value.append(indexs)
else:
indexs=1
for j in row_value:
if j>0:
break
indexs+=1
auto_value.append(indexs)
return ft+'_msz'+str(p),auto_value
#当月ft/(最近p个月ft的均值)
def Cav(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = df[ft+'1']/np.nanmean(df,axis = 1 )
return ft+'_cav'+str(p),auto_value
#当月ft/(最近p个月ft的最小值)
def Cmn(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = df[ft+'1']/np.nanmin(df,axis = 1 )
return ft+'_cmn'+str(p),auto_value
#最近p个月,每两个月间的ft的增长量的最大值
def Mai(ft,p):
arr=np.array(data.loc[:,ft+'1':ft+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
auto_value.append(np.nanmax(value_lst))
return ft+'_mai'+str(p),auto_value
#最近p个月,每两个月间的ft的减少量的最大值
def Mad(ft,p):
arr=np.array(data.loc[:,ft+'1':ft+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k+1] - df_value[k]
value_lst.append(minus)
auto_value.append(np.nanmax(value_lst))
return ft+'_mad'+str(p),auto_value
#最近p个月,ft的标准差
def Std(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.nanvar(df,axis = 1)
return ft+'_std'+str(p),auto_value
#最近p个月,ft的变异系数
def Cva(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value=np.nanvar(df,axis = 1)/(np.nanmean(df,axis = 1 )+1e-10)
return ft+'_cva'+str(p),auto_value
#(当月ft) - (最近p个月ft的均值)
def Cmm(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = df[ft+'1'] - np.nanmean(df,axis = 1 )
return ft+'_cmm'+str(p),auto_value
#(当月ft) - (最近p个月ft的最小值)
def Cnm(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = df[ft+'1'] - np.nanmin(df,axis = 1 )
return ft+'_cnm'+str(p),auto_value
#(当月ft) - (最近p个月ft的最大值)
def Cxm(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = df[ft+'1'] - np.nanmax(df,axis = 1 )
return ft+'_cxm'+str(p),auto_value
#( (当月ft) - (最近p个月ft的最大值) ) / (最近p个月ft的最大值) )
def Cxp(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
temp = np.nanmax(df,axis = 1 )
auto_value = (df[ft+'1'] - temp )/ temp
return ft+'_cxp'+str(p),auto_value
#最近p个月,ft的极差
def Ran(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = np.nanmax(df,axis = 1 ) - np.nanmin(df,axis = 1 )
return ft+'_ran'+str(p),auto_value
#最近p个月中,特征ft的值,后一个月相比于前一个月增长了的月份数
def Nci(ft,p):
arr=np.array(data.loc[:,ft+'1':ft+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
value_ng = np.where(np.array(value_lst)>0,1,0).sum()
auto_value.append(np.nanmax(value_ng))
return ft+'_nci'+str(p),auto_value
#最近p个月中,特征ft的值,后一个月相比于前一个月减少了的月份数
def Ncd(ft,p):
arr=np.array(data.loc[:,ft+'1':ft+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
value_ng = np.where(np.array(value_lst)<0,1,0).sum()
auto_value.append(np.nanmax(value_ng))
return ft+'_ncd'+str(p),auto_value
#最近p个月中,相邻月份ft 相等的月份数
def Ncn(ft,p):
arr=np.array(data.loc[:,ft+'1':ft+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
for k in range(len(df_value)-1):
minus = df_value[k] - df_value[k+1]
value_lst.append(minus)
value_ng = np.where(np.array(value_lst)==0,1,0).sum()
auto_value.append(np.nanmax(value_ng))
return ft+'_ncn'+str(p),auto_value
#最近P个月中,特征ft的值是否按月份严格递增,是返回1,否返回0
def Bup(ft,p):
arr=np.array(data.loc[:,ft+'1':ft+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
index = 0
for k in range(len(df_value)-1):
if df_value[k] > df_value[k+1]:
break
index =+ 1
if index == p:
value= 1
else:
value = 0
auto_value.append(value)
return ft+'_bup'+str(p),auto_value
#最近P个月中,特征ft的值是否按月份严格递减,是返回1,否返回0
def Pdn(ft,p):
arr=np.array(data.loc[:,ft+'1':ft+str(p)])
auto_value = []
for i in range(len(arr)):
df_value = arr[i,:]
value_lst = []
index = 0
for k in range(len(df_value)-1):
if df_value[k+1] > df_value[k]:
break
index =+ 1
if index == p:
value= 1
else:
value = 0
auto_value.append(value)
return ft+'_pdn'+str(p),auto_value
#最近P个月中,ft的切尾均值,这里去掉了数据中的最大值和最小值
def Trm(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = []
for i in range(len(df)):
trm_mean = list(df.loc[i,:])
trm_mean.remove(np.nanmax(trm_mean))
trm_mean.remove(np.nanmin(trm_mean))
temp=np.nanmean(trm_mean)
auto_value.append(temp)
return ft+'_trm'+str(p),auto_value
#当月ft / 最近p个月的ft中的最大值
def Cmx(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = (df[ft+'1'] - np.nanmax(df,axis = 1 )) /np.nanmax(df,axis = 1 )
return ft+'_cmx'+str(p),auto_value
#( 当月ft - 最近p个月的ft均值 ) / ft均值
def Cmp(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = (df[ft+'1'] - np.nanmean(df,axis = 1 )) /np.nanmean(df,axis = 1 )
return ft+'_cmp'+str(p),auto_value
#( 当月ft - 最近p个月的ft最小值 ) /ft最小值
def Cnp(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
auto_value = (df[ft+'1'] - np.nanmin(df,axis = 1 )) /np.nanmin(df,axis = 1 )
return ft+'_cnp'+str(p),auto_value
#最近p个月取最大值的月份距现在的月份数
def Msx(ft,p):
df=data.loc[:,ft+'1':ft+str(p)]
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxdf['_max'] = np.nanmax(df,axis = 1)
for i in range(1,p+1):
df[ft+str(i)] = list(df[ft+str(i)] == df['_max'])
del df['_max']
df_value = np.where(df==True,1,0)
auto_value=[]
for i in range(len(df_value)):
row_value=df_value[i,:]
indexs=1
for j in row_value:
if j == 1:
break
indexs+=1
auto_value.append(indexs)
return ft+'_msx'+str(p),auto_value
#最近p个月的均值/((p,2p)个月的ft均值)
def Rpp(ft,p):
df1=data.loc[:,ft+'1':ft+str(p)]
value1=np.nanmean(df1,axis = 1 )
df2=data.loc[:,ft+str(p):ft+str(2*p)]
value2=np.nanmean(df2,axis = 1 )
auto_value = value1/value2
return ft+'_rpp'+str(p),auto_value
#最近p个月的均值 - ((p,2p)个月的ft均值)
def Dpp(ft,p):
df1=data.loc[:,ft+'1':ft+str(p)]
value1=np.nanmean(df1,axis = 1 )
df2=data.loc[:,ft+str(p):ft+str(2*p)]
value2=np.nanmean(df2,axis = 1 )
auto_value = value1 - value2
return ft+'_dpp'+str(p),auto_value
#(最近p个月的ft最大值)/ (最近(p,2p)个月的ft最大值)
def Mpp(ft,p):
df1=data.loc[:,ft+'1':ft+str(p)]
value1=np.nanmax(df1,axis = 1 )
df2=data.loc[:,ft+str(p):ft+str(2*p)]
value2=np.nanmax(df2,axis = 1 )
auto_value = value1/value2
return ft+'_mpp'+str(p),auto_value
#(最近p个月的ft最小值)/ (最近(p,2p)个月的ft最小值)
def Npp(ft,p):
df1=data.loc[:,ft+'1':ft+str(p)]
value1=np.nanmin(df1,axis = 1 )
df2=data.loc[:,ft+str(p):ft+str(2*p)]
value2=np.nanmin(df2,axis = 1 )
auto_value = value1/value2
return ft+'_npp'+str(p),auto_value
- 将上面的衍生方法定义为函数
#定义批量调用双参数的函数
def auto_var2(feature,p):
#global data_new
try:
columns_name,values=Num(feature,p)
data_new[columns_name]=values
except:
print("Num PARSE ERROR",feature,p)
try:
columns_name,values=Nmz(feature,p)
data_new[columns_name]=values
except:
print("Nmz PARSE ERROR",feature,p)
try:
columns_name,values=Evr(feature,p)
data_new[columns_name]=values
except:
print("Evr PARSE ERROR",feature,p)
try:
columns_name,values=Avg(feature,p)
data_new[columns_name]=values
except:
print("Avg PARSE ERROR",feature,p)
try:
columns_name,values=Tot(feature,p)
data_new[columns_name]=values
except:
print("Tot PARSE ERROR",feature,p)
try:
columns_name,values=Tot2T(feature,p)
data_new[columns_name]=values
except:
print("Tot2T PARSE ERROR",feature,p)
try:
columns_name,values=Max(feature,p)
data_new[columns_name]=values
except:
print("Tot PARSE ERROR",feature,p)
try:
columns_name,values=Max(feature,p)
data_new[columns_name]=values
except:
print("Max PARSE ERROR",feature,p)
try:
columns_name,values=Min(feature,p)
data_new[columns_name]=values
except:
print("Min PARSE ERROR",feature,p)
try:
columns_name,values=Msg(feature,p)
data_new[columns_name]=values
except:
print("Msg PARSE ERROR",feature,p)
try:
columns_name,values=Msz(feature,p)
data_new[columns_name]=values
except:
print("Msz PARSE ERROR",feature,p)
try:
columns_name,values=Cav(feature,p)
data_new[columns_name]=values
except:
print("Cav PARSE ERROR",feature,p)
try:
columns_name,values=Cmn(feature,p)
data_new[columns_name]=values
except:
print("Cmn PARSE ERROR",feature,p)
try:
columns_name,values=Std(feature,p)
data_new[columns_name]=values
except:
print("Std PARSE ERROR",feature,p)
try:
columns_name,values=Cva(feature,p)
data_new[columns_name]=values
except:
print("Cva PARSE ERROR",feature,p)
try:
columns_name,values=Cmm(feature,p)
data_new[columns_name]=values
except:
print("Cmm PARSE ERROR",feature,p)
try:
columns_name,values=Cnm(feature,p)
data_new[columns_name]=values
except:
print("Cnm PARSE ERROR",feature,p)
try:
columns_name,values=Cxm(feature,p)
data_new[columns_name]=values
except:
print("Cxm PARSE ERROR",feature,p)
try:
columns_name,values=Cxp(feature,p)
data_new[columns_name]=values
except:
print("Cxp PARSE ERROR",feature,p)
try:
columns_name,values=Ran(feature,p)
data_new[columns_name]=values
except:
print("Ran PARSE ERROR",feature,p)
try:
columns_name,values=Nci(feature,p)
data_new[columns_name]=values
except:
print("Nci PARSE ERROR",feature,p)
try:
columns_name,values=Ncd(feature,p)
data_new[columns_name]=values
except:
print("Ncd PARSE ERROR",feature,p)
try:
columns_name,values=Ncn(feature,p)
data_new[columns_name]=values
except:
print("Ncn PARSE ERROR",feature,p)
try:
columns_name,values=Pdn(feature,p)
data_new[columns_name]=values
except:
print("Pdn PARSE ERROR",feature,p)
try:
columns_name,values=Cmx(feature,p)
data_new[columns_name]=values
except:
print("Cmx PARSE ERROR",feature,p)
try:
columns_name,values=Cmp(feature,p)
data_new[columns_name]=values
except:
print("Cmp PARSE ERROR",feature,p)
try:
columns_name,values=Cnp(feature,p)
data_new[columns_name]=values
except:
print("Cnp PARSE ERROR",feature,p)
try:
columns_name,values=Msx(feature,p)
data_new[columns_name]=values
except:
print("Msx PARSE ERROR",feature,p)
try:
columns_name,values=Nci(feature,p)
data_new[columns_name]=values
except:
print("Nci PARSE ERROR",feature,p)
try:
columns_name,values=Trm(feature,p)
data_new[columns_name]=values
except:
print("Trm PARSE ERROR",feature,p)
try:
columns_name,values=Bup(feature,p)
data_new[columns_name]=values
except:
print("Bup PARSE ERROR",feature,p)
try:
columns_name,values=Mai(feature,p)
data_new[columns_name]=values
except:
print("Mai PARSE ERROR",feature,p)
try:
columns_name,values=Mad(feature,p)
data_new[columns_name]=values
except:
print("Mad PARSE ERROR",feature,p)
try:
columns_name,values=Rpp(feature,p)
data_new[columns_name]=values
except:
print("Rpp PARSE ERROR",feature,p)
try:
columns_name,values=Dpp(feature,p)
data_new[columns_name]=values
except:
print("Dpp PARSE ERROR",feature,p)
try:
columns_name,values=Mpp(feature,p)
data_new[columns_name]=values
except:
print("Mpp PARSE ERROR",feature,p)
try:
columns_name,values=Npp(feature,p)
data_new[columns_name]=values
except:
print("Npp PARSE ERROR",feature,p)
return data_new.columns.size
- 对之前数据应用封装的函数
# 创建空的df
data_new = pd.DataFrame()
# 遍历12个月
for p in range(1, 12):
# 对所有ft-i和gt-i的列进行特征衍生
for inv in ['ft', 'gt']:
auto_var2(inv, p)
-
上面这种无差别聚合方法进行聚合得到的结果常具有较高的共线性,但信息量并无明显增加,影响模型的鲁棒性和稳定性
-
评分卡模型对模型的稳定性要求远高于其性能
-
在时间窗口为1年的场景下,p值会通过先验知识,人为选择3、6、12等,而不是遍历全部取值1~12
-
在后续特征筛选时,会根据变量的显著性、共线性等指标进行进一步筛选
-
最近一次(current) 和历史 (history)做对比
- current/history
- current-history
-
3.3.2 用户关联特征
如何评价一个没有内部数据的新客?
- 使用第三方数据
- 把新用户关联到内部用户,使用关联到的老客信息评估
用户特征关联,可以考虑用倒排表做关联
- 用户→[特征1,特征2,特征3…]
- 特征→[用户1,用户2,用户3…]
举例:用户所在地区的统计特征
- 将用户申请时的GPS转化为geohash位置块
- geohash:基本原理是将地球理解为一个二维平面,将平面递归分解成更小的子块,每个子块在一定经纬度范围内拥有相同的编码
- 对每个大小合适的位置块,统计申请时点GPS在该位置块的人的信用分
- 当新申请的人,查询其所在的位置块的平均信用分作为GPS倒排表特征
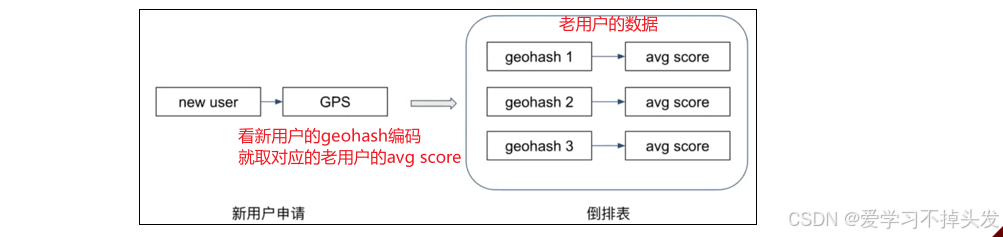
- 倒排表的组成:关键主键+统计指标
关键主键:新用户通过什么数据和平台存量用户发生关联
统计指标:使用存量用户的什么特征去评估这个新客户
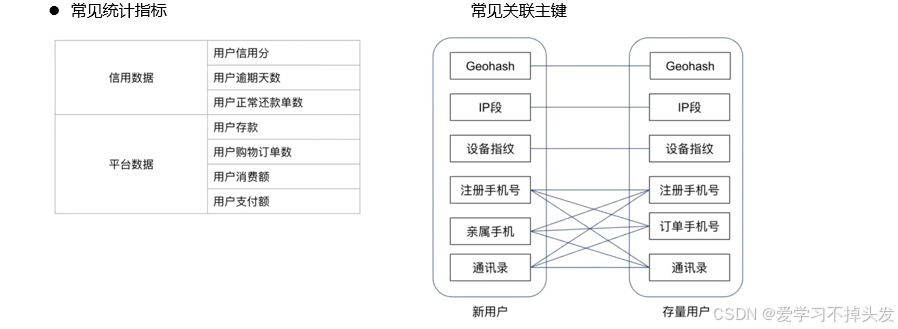
-
信贷业务的特征要求:
- 逻辑简单
- 容易构造
- 容易排查错误
- 有强业务解释性
-
构造特征要从两个维度看数据:归纳+演绎
- 归纳:从大量数据的结果总结出规律(相关关系),从数据中只能得到相关性
- 演绎:从假设推导出必然的结果(因果关系)