声明:笔记是做项目时根据B站博主视频学习时自己编写,请勿随意转载!
一、说在前面的一些话
1、torchvision
需要用到torchvision里的一些模块,之前第一期配置环境的时候已经安装过torchvision!
torchvision是PyTorch生态系统中的一个关键库,专门为计算机视觉任务设计和优化。它提供了丰富的功能和工具:
- 数据集:内置了多种广泛使用的图像和视频数据集,如MNIST、CIFAR10/100、Fashion-MNIST、ImageNet、COCO等,以torch.utils.data.Dataset的形式实现,方便与PyTorch数据加载器(DataLoader)集成。
- 数据预处理工具:通过torchvision.transforms模块提供了丰富的数据增强和预处理操作,包括但不限于裁剪、旋转、翻转、归一化、调整大小、颜色转换等,这些操作对于训练稳健的深度学习模型至关重要。
- 预训练模型:提供了一些常用的预训练模型,如ResNet、VGG、Inception等,这些模型在大型数据集(如ImageNet)上进行过训练,并可以直接使用或进行微调。
- 图像分类、目标检测和语义分割:提供了常用的图像分类、目标检测和语义分割任务的模型和数据集,如CIFAR-10、PASCAL VOC、COCO等。
- 可视化工具:提供了一些可视化工具,如TensorBoard的集成、图像和视频的显示等,方便进行模型调试和结果展示。
2、torchvision.models
torchvision中的models模块是一个非常重要的部分,它包含了大量预先定义好的经典深度学习网络结构,这些网络结构可以直接用于计算机视觉任务,如图像分类、目标检测等。这些网络结构都是经过广泛验证并在各种数据集上表现出色的模型。
具体来说,torchvision.models中包含了如AlexNet、DenseNet、Inception、ResNet、SqueezeNet、VGG等常用的网络结构。这些模型都已经在大型数据集(如ImageNet)上进行了预训练,因此可以直接用于迁移学习或特征提取等任务。
此外,torchvision.models还提供了预训练的权重,这意味着你可以直接使用这些预训练的模型进行推理,或者在新的数据集上进行微调,从而大大加速模型的训练过程并提高模型的性能。
3、MobileNet
torchvision.models模块中包含了MobileNet。MobileNet是一种轻量级的网络架构,特别适用于移动和嵌入式视觉应用。它使用深度可分离卷积来构建轻量级和高效的模型,同时保持较高的性能。在torchvision中,你可以直接加载预训练的MobileNet模型,也可以根据自己的需求进行微调。这使得MobileNet成为处理各种计算机视觉任务,如图像分类、目标检测等的理想选择。
它实际是一个用于分类的网络结构,我们迁移时实际只用到了它的特征提取(model.features)部分,而未用到的部分。这一段引入介绍的部分详情可看博主原视频:
替换主干网络
import torchvision.models as models
from torchinfo import summary
model = models.mobilenet_v3_small(pretrained=True, progress=True)
summary(model.features, input_size=(1,3,640,640)) #yolo默认的图片输入尺寸
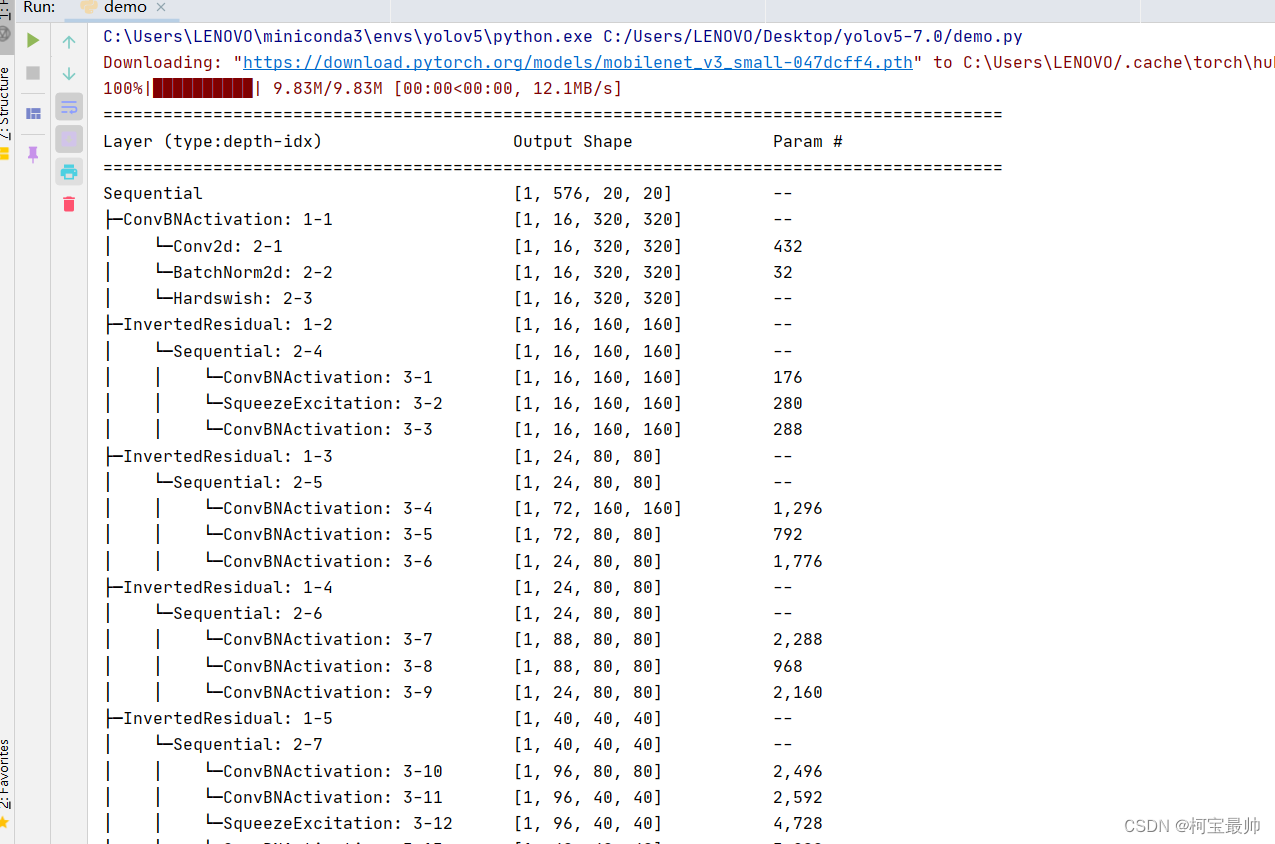
替换主干网络即将yaml文件里的backbone都替换掉,首先需要对网络特征图的尺寸变化有深入理解,了解每步特征图尺寸的变化,哪些层尺寸相同可以合并等(理论重点),如下加特征图尺寸注释的原始yaml配置文件:
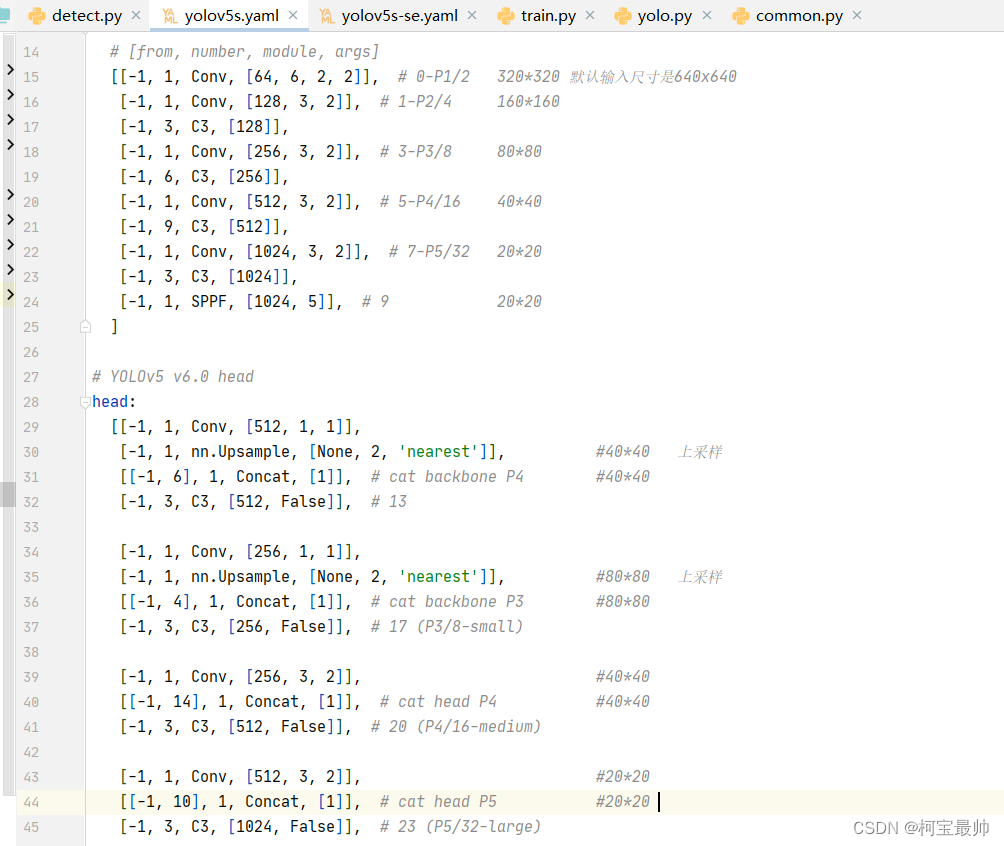
80x80、40x40、20x20的特征图大小需要我们格外关注,即替换时我们需要moblienet的8倍下采样、16倍下采样、32倍下采样的输出。
以上这些都时修改前的必备引入的话,详情可参考原视频链接!
二、开始替换主干网络
1、common.py(定义模块)
在conmmon.py里面添加如下代码:
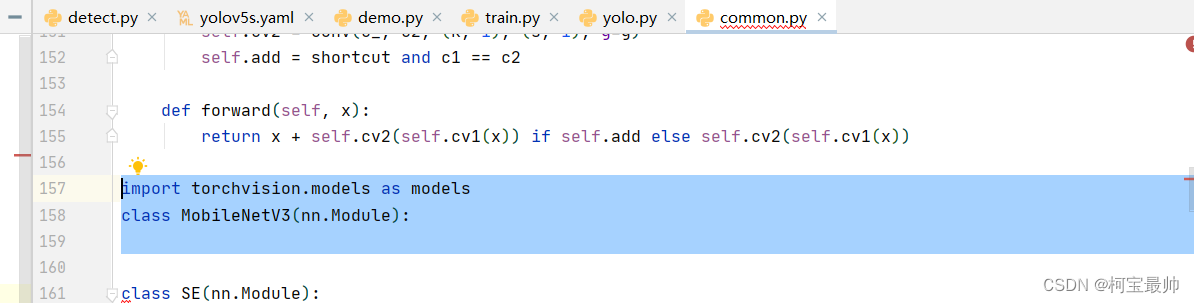
MobileNetV3类的完整定义如下:
class MobileNetV3(nn.Module):
def __init__(self, slice):
super(MobileNetV3, self).__init__()
self.model = None
if slice == 1:
self.model = models.mobilenet_v3_small(pretrained=True).features[:4] #mobilenet特征提取部分的前4层
elif slice == 2:
self.model = models.mobilenet_v3_small(pretrained=True).features[4:9] #mobilenet特征提取部分的5-9层
else:
self.model = models.mobilenet_v3_small(pretrained=True).features[9:] #mobilenet特征提取部分的第10层及以后几层
def forward(self, x):
return self.model(x)2、yolov5s.yaml(结构配置)
老样子,新复制一份命名为yolov5s-mobilenet.yaml,里面的backbone和head修改后如下:(主要是backbone里原来的10层变成了3层,而head里面只是把from参数拼接处对应改动)
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
# [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 320*320 默认输入尺寸是640x640
# [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 160*160
# [-1, 3, C3, [128]],
# [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 80*80
# [-1, 6, C3, [256]],
# [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 40*40
# [-1, 9, C3, [512]],
# [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 20*20
# [-1, 3, C3, [1024]],
# [-1, 1, SPPF, [1024, 5]], # 9 20*20
[[-1, 1, MobileNetV3, [24, 1]], #0-P3/8 80*80
[-1, 1, MobileNetV3, [48, 2]], #1-P4/16 40*40
[-1, 1, MobileNetV3, [576, 3]], #2-P5/32 20*20
]
# YOLOv5 v6.0 head
head:
# [[-1, 1, Conv, [512, 1, 1]], #10
# [-1, 1, nn.Upsample, [None, 2, 'nearest']], #40*40 上采样
# [[-1, 6], 1, Concat, [1]], # cat backbone P4 #40*40
# [-1, 3, C3, [512, False]], # 13
#
# [-1, 1, Conv, [256, 1, 1]],
# [-1, 1, nn.Upsample, [None, 2, 'nearest']], #80*80 上采样
# [[-1, 4], 1, Concat, [1]], # cat backbone P3 #80*80
# [-1, 3, C3, [256, False]], # 17 (P3/8-small)
#
# [-1, 1, Conv, [256, 3, 2]], #40*40
# [[-1, 14], 1, Concat, [1]], # cat head P4 #40*40
# [-1, 3, C3, [512, False]], # 20 (P4/16-medium)
#
# [-1, 1, Conv, [512, 3, 2]], #20*20
# [[-1, 10], 1, Concat, [1]], # cat head P5 #20*20
# [-1, 3, C3, [1024, False]], # 23 (P5/32-large)
#
# [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
[[-1, 1, Conv, [512, 1, 1]], #3
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #4 #40*40 上采样
[[-1, 1], 1, Concat, [1]], # 5-cat backbone P4 #40*40
[-1, 3, C3, [512, False]], # 6
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #80*80 上采样
[[-1, 0], 1, Concat, [1]], # cat backbone P3 #80*80
[-1, 3, C3, [256, False]], # 10 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], #40*40
[[-1, 7], 1, Concat, [1]], # cat head P4 #40*40
[-1, 3, C3, [512, False]], # 13 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], #20*20
[[-1, 3], 1, Concat, [1]], # cat head P5 #20*20
[-1, 3, C3, [1024, False]], # 16 (P5/32-large)
[[10, 13, 16], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]3、yolo.py(注册模块)
与上节的注意力机制SE模块一样,还是在parse_model函数中以elif形式注册MobleNetV3模块:
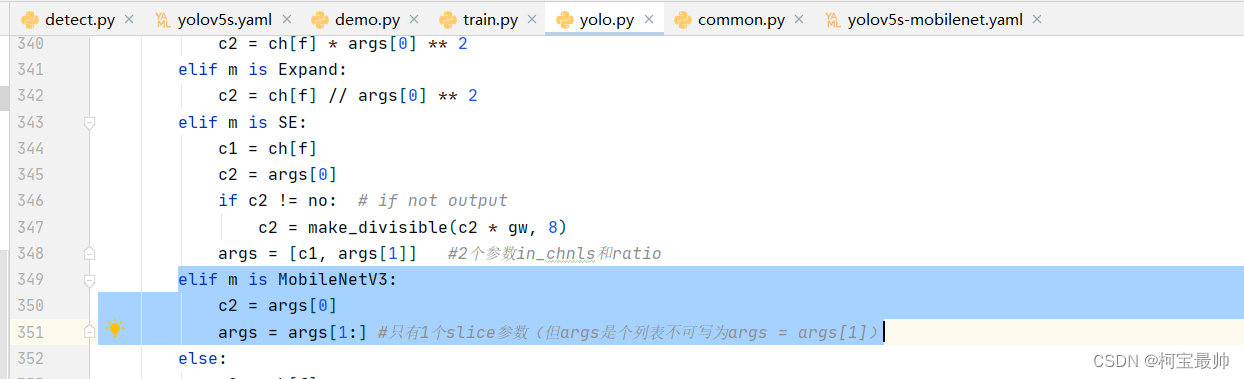
elif m is MobileNetV3:
c2 = args[0]
args = args[1:] #只有1个slice参数(但args是个列表不可写为args = args[1])其中c2参数记录了当前模块的输出,下一个模块输入等于该参数,不记录会导致下一个模块无法链接成功!!
三、train.py训练
对比下参数量:
首先使用默认配置文件yolov5s.yaml
层数和参数量如下:

替换为刚才我们忙了半天的轻量化模型MobileNet,即配置文件yolov5s-mobilenet.yaml:

层数和参数量如下:

可见层数略微增加点,但是参数量却减少了几乎一半!

训练速度也提高了不少,时间从原来的0.4hours降低到0.2hours左右!

效果这里不太佳,这随着不同的训练对象可能有不同的效果!结果保存在exp16文件夹!
往期精彩
STM32专栏(9.9)
OpenCV-Python专栏(9.9)
AI底层逻辑专栏(9.9)
机器学习专栏(免费)