大数据项目实战
第四章 数据预处理
学习目标
了解数据预处理流程
掌握编写 MapReduce 程序的方法
掌握 HDFS Shell 的基本使用
掌握 MapReduce 程序的两种运行模式
对原始数据进行预处理是大数据分析与应用过程中的重要环节。本篇对上篇第三章采集的数据进行预处理。
一、分析预处理数据
在进行数据预处理之前,先查看要处理数据的数据结构,从而指定可行的数据预处理方案。这里笨猫猫以从第三章爬取文件 page1 为例,在虚拟机上执行以下命令查看数据。
hdfs dfs -cat /JobData/20xxxxxx/page1
这里的路径要根据你爬取数据后所生成的路径,所以这里笨猫猫采用xx代替。
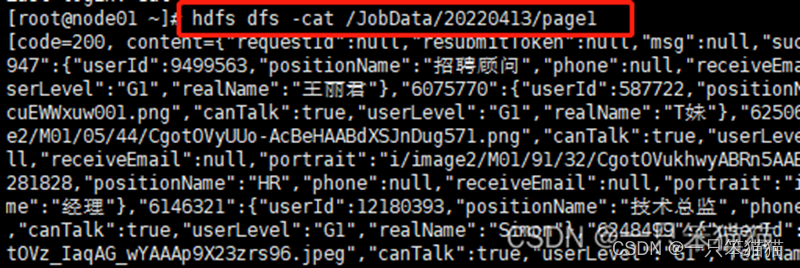
在网上使用 JSON 格式化工具对 page1 文件中的数据进行格式化处理,查看存储了职位信息 result 字段。
打开page1的内容,复制到以下空白处,进行格式化。
点击“格式化“
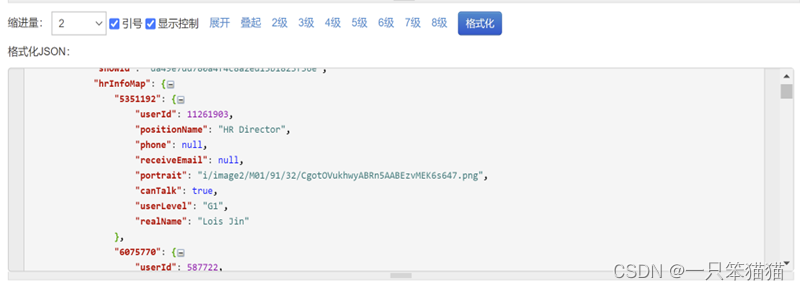
本项目主要分析的内容是薪资、福利、技能要求、职位分布这四方面。所以重点分析薪资(salary)、福利(companyLabelList)、技能要求(skillLables)、职位分布(positionAdvantage)、城市(city)这五个字段。

1)salary
薪资字段数据内容为字符串的形式,例如:“20k~40k” 表示薪资的区间。为方便后续对薪资数据进行数据分析,需要提取出数据进行格式化处理,去除薪资数据中的 “k” 这个字符,将薪资数据保存成为 “20~40” 的数据样式进行存储。
2)city
城市字段的数据内容为字符串形式,例如,“北京” 表示招聘职位的城市,直接提取数据即可,无须处理。
3)skillLabels
技能要求字段的数据内容为数组形式,例如,[“数据仓库”,“数据架构”,“Hadoop”] 表示所要招聘的值为需要掌握多项技能。对该字段的内容需进行格式化处理,提取数组中的每个数据,并将每个技能数据通过 “-” 分隔符重新组合新的字符串数据形式进行存储,便于后续将数据导入数据仓库中。格式化后的结果为 “数据仓库-数据架构-Hadoop”
4)companyLabelList、positionAdvantage
在职位信息数据中有两个字段内容,包括福利标签看数据 companyLabelList 字段和 positionAdvantage字段,前者数据形式为数组,后者数据形式为字符串,数据预处理程序对这两个字段进行格式化处理,这两个字段的每个福利标签进行提取并利用 “-” 作为分隔符合并成新的数据内容。
二、设计数据预处理方案
本篇笨猫猫用数据清洗方法对采集的数据进行数据预处理。通过分布式系统基础架构 Hadoop 提供的 MapReduce 编程思想来编写 MapReduce 程序实现数据清洗。
本篇主要是对数据进行预处理操作,并不需要合并数据处理,所以只需要编写 Mapper 阶段的代码即可。
三、实现数据的预处理
1、创建并配置工程
(参考第三章建立的Maven工程操作,一样的操作)

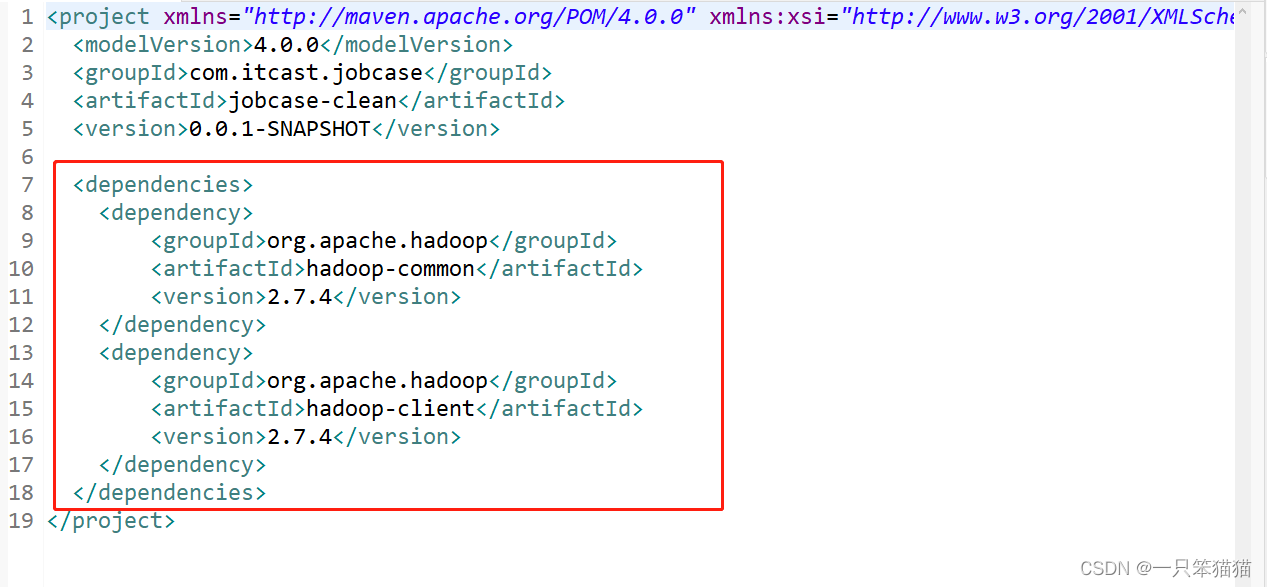
2、配置 pom.xml 文件
添加 Hadoop 相关的依赖。
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies>
配置完成 后,右击项目选择 Maven 选项,单击 Update Project,完成项目工程的搭建。
直接 Ctrl + S 保存也可以,会直接下载依赖。
3、启动 Hadoop 集群
启动 Hadoop001、Hadoop002、Hadoop003,启动后用 Xshell5 远程连接这三台服务器。
然后在主节点上开启 Hadoop 集群中的 hdfs 和 yarn 集群。之前开启了,没有关闭的就不用再开启了。
4、创建数据转换类
1)创建转换类
在 jobcase-clean 工程下的 src/main/java 文件下创建一个名称为 com.position.clean 的 Package包,在包下创建 CleanJob 类,用于实现对职业信息数据进行转换操作,创建好的 CleanJob 类的代码如下。
public class CleanJob {
}
2)编写实现处理薪资数据的方法
在 CleanJob 类中添加方法 deleteString() ,用于对薪资字符串进行处理,即去除薪资中的 “k” 字符。
文件 CleanJob.java
public class CleanJob {
//处理薪资数据的方法
//deleteString()方法用于对薪资字符串进行处理,即去除薪资中的"k"字符
//"salary": "15k-25k",
public static String deleteString(String str,char delChar) {
StringBuffer stringBuffer = new StringBuffer(""); //创建 StringBuffer 对象,初始化字符串""
for(int i = 0; i < str.length(); ++i) {
if(str.charAt(i) != delChar) { //charAt(i):指定i下标的值,如果不为字符串,添加到新的字符串 ""
stringBuffer.append(str.charAt(i));
}
}
return stringBuffer.toString(); //转换成字符串返回。toString()返回原生数据类型的 String 对象值。
}
}
deleteString() 方法中包括两个参数 str(要处理的字符串) 和 delChar(指定从字符串中剔除的字符),调用该方法时指定这两个参数实现薪资字符串中 “k” 字符的剔除,最终返回符合要求的字符串。
3)编写实现处理福利数据的方法
在 CleanJob 类中添加方法 mergeString(),用于将 companyLabelList 字段中的数据内容和 positionAdvantage 字段中的数据内容进行合并处理,生成新字符串数据(以 “-” 为分隔符)。
文件 CleanJob.java
//处理福利数据的方法
//mergeString()方法用于将companyLabelList字段中的数据内容和positionAdvantage字段中的数据内容进行合并处理,生成新字符串数据(以"-"为分隔符)
//companyLabelList": ["绩效奖金", "带薪年假", "专项奖金", "节日礼物"],
//"positionAdvantage": "朝九晚六 周末双休 弹性工作制",
public static String mergeString(String position,JSONArray company) throws JSONException{
String result = "";
if(company.length() != 0) {
for(int i = 0; i < company.length(); ++i) {
result += company.getString(i) + "-";
}
}
if(position != "") {
String[] positionList = position.split(" |;|,|、|,|;|/");
for(int i = 0; i < positionList.length; ++i) {
result += positionList[i].replaceAll("[\\pP\\p{Punct}]", "") + "-"; //replaceAll()方法把被选元素替换为新的 HTML 元素。
}
}
return result.substring(0,result.length()-1); //substring() 方法返回字符串的子字符串
}
4)编写实现处理技能数据的方法
在 CleanJob 类中添加方法 killResult(),用于将技能数据以 “-” 为分隔符进行分隔,生成新的字符串数据。
文件 CleanJob.java
//处理技能数据的方法
//killResult()方法用于将技能数据以"-"为分隔符进行分隔,生成新的字符串数据
//"skillLables": ["Spark"],
public static String killResult(JSONArray killData) throws JSONException{
String result = "";
if(killData.length() != 0) {
for(int i = 0 ; i < killData.length(); ++i) {
result += killData.getString(i) + "-";
}
return result.substring(0,result.length()-1);
}
else {
return "null";
}
}
5)编写实现数据清洗的主方法
在 CleanJob 类中添加方法 resultToString() 将数据文件中的每一条职位信息数据进行处理并重新组合成新的字符串形式。
文件 CleanJob.java
//实现数据清洗的主方法
public static String resultToString(JSONArray jobdata) throws JSONException {
String jobResultData = ""; //定义字符串类型的全局变量,用于存储每条职位数据中的薪资、城市、福利标签和技能标签这四个字段合并后的字符串内容,并作为方法的返回值(最终的数据清洗结果)
//for循环遍历JSONArray数组jobdata(每个数据文件包括的15条职位信息数据内容),实现从每一条职位信息数据中提取薪资、城市、福利标签和技能标签数据。
for(int i = 0; i < jobdata.length(); ++i) {
//获取每条职位信息
String everyData = jobdata.get(i).toString(); //通过下标获取到的原生数据转换成字符串
//将String类型的数据转为JSON对象
JSONObject everyDataJson = new JSONObject(everyData);
//获取职位信息中的城市数据
String city = everyDataJson.getString("city");
//获取职位信息中的薪资数据
String salary = everyDataJson.getString("salary");
//获取职位信息中的福利标签数据
String positionAdvantage = everyDataJson.getString("positionAdvantage");
//获取职位信息中的福利标签数据
JSONArray companyLabelList = everyDataJson.getJSONArray("companyLabelList");
//获取职位信息中的技能标签数据
JSONArray skillLables = everyDataJson.getJSONArray("skillLables");
//处理薪资字段数据
//调用处理数据的方法对提取的薪资、福利标签和技能标签数据进行格式化处理
String salaryNew = deleteString(salary,'k');
String welfare = mergeString(positionAdvantage,companyLabelList);
String kill = killResult(skillLables);
//将四个字段的数据按照指定分隔符合并成新的字符串,为了避免每个数据文件中的最后一条职位数据与下一个数据文件中的第一条职位数据间产生空行。
if(i == jobdata.length()-1) {
jobResultData += city + "," + salaryNew + "," + welfare + "," + kill;
}else {
jobResultData += city + "," + salaryNew + "," + welfare + "," + kill + "\n";
}
}
return jobResultData;
}
5、创建实现 Map 任务的 Mapper 类
在 job-clean 工程的 com.position.clean 包下创建一个名为 CleanMapper 类,用于实现 MapReduce 程序的 Map 方法。
(1)Hadoop 提供了一个抽象的 Mapper 基类, Map 程序需要继承这个基类,并实现其中相关的接口函数,因此我们将创建的 CleanMapper 类继承 Mapper 基类,并定义 Map 程序输入和输出的 Key 和 Value。
文件 CleanMapper.java
public class CleanMapper extends Mapper<LongWritable, Text, Text,
NullWritable> {
}
定义 Map 程序的输入 <K,V> 分别为 <LongWritable,Text>, 输出的 <K,V> 为 <Text,NullWritable>。
NullWritable 是 Writable 的特殊类,是一个不可变的单实例类型,它不从数据流中读数据,也不写入数据,值充当占位符。在 MapReduce 中,如果不需要使用键或值,就可以将键或值声明为 NullWritable。
(2)在 Mapper 类中实现承担主要的处理工作的 map() 方法,map() 方法对输入的键值对进行处理。
文件 CleanMapper.java
//map()方法对输入的键值对进行处理
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//全局变量jobResultData作为Map程序输出的key值
String jobResultData = ""; //定义全局字符串变量 jobResultData ,该变量作为 Map 程序输出的 key 值。
}
(3)数据文件中包含两个字段 code 和 content,前者代表响应状态码,后者代表响应的内容即爬取的数据内容,在 map() 方法中定义获取 content 字段内容的代码。
文件 CleanMapper.java
String reptileData = value.toString();
//通过截取字符串的方式获取content中的数据
//indexOf() 方法返回动态数组中元素的索引值。substring() 方法返回字符串中的子字符串
//将文件内容赋值给字符串变量 reptileData ,定义字符串 jobData,从字符串 retileData 中截取 content 字段内容,并赋值给该变量
String jobData = reptileData.substring(reptileData.indexOf("=",reptileData.indexOf("=")+1)+1,reptileData.length()-1);
(4)在 content 字段中的 result 部分包括职位信息数据, content 字段的内容可为 JSON 格式,为了便于从 content 字段中获取 result 部分的数据内容,这里通过将 content 字段的字符串形式转为 JSON 对象形式来获取,将获取的 result 内容传入数据转换类进行处理,处理结果作为 Map 输出的 Key 值。
文件 CleanMapper.java
try {
//获取content中的数据内容
JSONObject contentJson = new JSONObject(jobData);
//将字符串 jobData 转为 JSON 对象 contentJson
String contentData = contentJson.getString("content");
//获取content下positionResult中的数据内容
JSONObject positionResultJson = new JSONObject(contentData);
String positionResultData = positionResultJson.getString("positionResult");
//获取最终result中的数据内容
JSONObject resultJson = new JSONObject(positionResultData);
//将 result 转为 JSON 数组对象 resultData
JSONArray resultData = resultJson.getJSONArray("result");
//调用CleanJob类中的清洗类resultToString()进行数据清洗
jobResultData = CleanJob.resultToString(resultData);
context.write(new Text(jobResultData), NullWritable.get());
}catch(JSONException e){
e.printStackTrace();
}
完整代码如下:
文件CleanJob.java
package com.position.clean;
import org.codehaus.jettison.json.JSONArray;
import org.codehaus.jettison.json.JSONException;
import org.codehaus.jettison.json.JSONObject;
public class CleanJob {
//处理薪资数据的方法
//deleteString()方法用于对薪资字符串进行处理,即去除薪资中的"k"字符
//"salary": "15k-25k",
public static String deleteString(String str,char delChar) {
StringBuffer stringBuffer = new StringBuffer(""); //创建StringBuffer对象,初始化字符串""
for(int i = 0; i < str.length(); ++i) {
if(str.charAt(i) != delChar) { //charAt(i):指定i下标的值,如果不为字符串,添加到新的字符串""
stringBuffer.append(str.charAt(i));
}
}
return stringBuffer.toString(); //转换成字符串返回。toString()返回原生数据类型的 String 对象值。
}
//处理福利数据的方法
//mergeString()方法用于将companyLabelList字段中的数据内容和positionAdvantage字段中的数据内容进行合并处理,生成新字符串数据(以"-"为分隔符)
//companyLabelList": ["绩效奖金", "带薪年假", "专项奖金", "节日礼物"],
//"positionAdvantage": "朝九晚六 周末双休 弹性工作制",
public static String mergeString(String position,JSONArray company) throws JSONException{
String result = "";
if(company.length() != 0) {
for(int i = 0; i < company.length(); ++i) {
result += company.getString(i) + "-";
}
}
if(position != "") {
String[] positionList = position.split(" |;|,|、|,|;|/");
for(int i = 0; i < positionList.length; ++i) {
result += positionList[i].replaceAll("[\\pP\\p{Punct}]", "") + "-"; //replaceAll()方法把被选元素替换为新的 HTML 元素。
}
}
return result.substring(0,result.length()-1); //substring() 方法返回字符串的子字符串
}
//处理技能数据的方法
//killResult()方法用于将技能数据以"-"为分隔符进行分隔,生成新的字符串数据
//"skillLables": ["Spark"],
public static String killResult(JSONArray killData) throws JSONException{
String result = "";
if(killData.length() != 0) {
for(int i = 0 ; i < killData.length(); ++i) {
result += killData.getString(i) + "-";
}
return result.substring(0,result.length()-1);
}
else {
return "null";
}
}
//实现数据清洗的主方法
public static String resultToString(JSONArray jobdata) throws JSONException {
String jobResultData = "";
for(int i = 0; i < jobdata.length(); ++i) {
//获取每条职位信息
String everyData = jobdata.get(i).toString(); //通过下标获取到的原生数据转换成字符串
//将String类型的数据转为JSON对象
JSONObject everyDataJson = new JSONObject(everyData);
//获取职位信息中的城市数据
String city = everyDataJson.getString("city");
//获取职位信息中的薪资数据
String salary = everyDataJson.getString("salary");
//获取职位信息中的福利标签数据
String positionAdvantage = everyDataJson.getString("positionAdvantage");
//获取职位信息中的福利标签数据
JSONArray companyLabelList = everyDataJson.getJSONArray("companyLabelList");
//获取职位信息中的技能标签数据
JSONArray skillLables = everyDataJson.getJSONArray("skillLables");
//处理薪资字段数据
String salaryNew = deleteString(salary,'k');
String welfare = mergeString(positionAdvantage,companyLabelList);
String kill = killResult(skillLables);
if(i == jobdata.length()-1) {
jobResultData += city + "," + salaryNew + "," + welfare + "," + kill;
}else {
jobResultData += city + "," + salaryNew + "," + welfare + "," + kill + "\n";
}
}
return jobResultData;
}
}
文件 CleanMapper.java
package com.position.clean;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.codehaus.jettison.json.JSONArray;
import org.codehaus.jettison.json.JSONException;
import org.codehaus.jettison.json.JSONObject;
//输入的<K,V>:<LongWritable,Text> 输出的<K,V>:<Text,NullWritable>
//NullWritable是Writable的特殊类,是一个不可变的单实例变量,他不从数据流中读数据,也不写数据,只充当占位符
public class CleanMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
//map()方法对输入的键值对进行处理
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{
//全局变量jobResultData作为Map程序输出的key值
String jobResultData = "";
//将每个数据文件的内容转为String类型
String reptileData = value.toString();
//通过截取字符串的方式获取content中的数据
//indexOf() 方法返回动态数组中元素的索引值。substring() 方法返回字符串中的子字符串
String jobData = reptileData.substring(reptileData.indexOf("=",reptileData.indexOf("=")+1)+1,reptileData.length()-1);
try {
//获取content中的数据内容
JSONObject contentJson = new JSONObject(jobData);
String contentData = contentJson.getString("content");
//获取content下positionResult中的数据内容
JSONObject positionResultJson = new JSONObject(contentData);
String positionResultData = positionResultJson.getString("positionResult");
//获取最终result中的数据内容
JSONObject resultJson = new JSONObject(positionResultData);
JSONArray resultData = resultJson.getJSONArray("result");
//调用CleanJob类中的清洗类resultToString()进行数据清洗
jobResultData = CleanJob.resultToString(resultData);
context.write(new Text(jobResultData), NullWritable.get());
}catch(JSONException e){
e.printStackTrace();
}
}
}
文件 CleanMain.java
package com.position.clean;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.log4j.BasicConfigurator;
public class CleanMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
//控制台输出日志
BasicConfigurator.configure();
//初始化Hadoop配置
Configuration conf = new Configuration();
//从hadoop命令行读取参数
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
//判断从命令行读取的参数正常是两个,分别是输入文件和输出文件的目录
if(otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
//定义一个新的Job,第一个参数是Hadoop配置信息,第二个参数是Job的名字
Job job = new Job(conf, "job");
//设置主类
job.setJarByClass(CleanMain.class);
//设置Mapper类
job.setMapperClass(CleanMapper.class);
//处理小文件,默认是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//n个小文件之和不能大于2MB
CombineTextInputFormat.setMinInputSplitSize(job,2097152); //2MB
//在n个小文件之和大于2MB情况下,徐满足n+1个小文件之和不能大于4MB;
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); //4MB
//设置job输出数据的key类
job.setOutputKeyClass(Text.class);
//设置job输出数据的value类
job.setOutputValueClass(NullWritable.class);
//设置输入文件
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
//设置输出文件
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
四、将数据预处理程序提交到集群中运行
在 jobcase-clean 工程 com.position.clean 包下创建一个名为 CleanMain 的类,用于实现 MapReduce 程序配置。
(1)MapReduce 程序主类
文件 CleanMain.java
public class CleanMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
//控制台输出日志
BasicConfigurator.configure();
//初始化Hadoop配置
Configuration conf = new Configuration();
//从hadoop命令行读取参数
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
//判断从命令行读取的参数正常是两个,分别是输入文件和输出文件的目录
if(otherArgs.length != 2) {
System.err.println("Usage: wordcount <in><out>");
System.exit(2);
}
//定义一个新的Job,第一个参数是Hadoop配置信息,第二个参数是Job的名字
Job job = new Job(conf, "job");
//设置主类
job.setJarByClass(CleanMain.class);
//设置Mapper类
job.setMapperClass(CleanMapper.class);
//处理小文件,默认是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//n个小文件之和不能大于2MB
CombineTextInputFormat.setMinInputSplitSize(job,2097152); //2MB
//在n个小文件之和大于2MB情况下,徐满足n+1个小文件之和不能大于4MB;
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); //4MB
//设置job输出数据的key类
job.setOutputKeyClass(Text.class);
//设置job输出数据的value类
job.setOutputValueClass(NullWritable.class);
//设置输入文件
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
//设置输出文件
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
(2)创建 jar 包
先进入 Eclipse 本地存放项目的目录,输入 PowerShell,回车出现下面第二张图
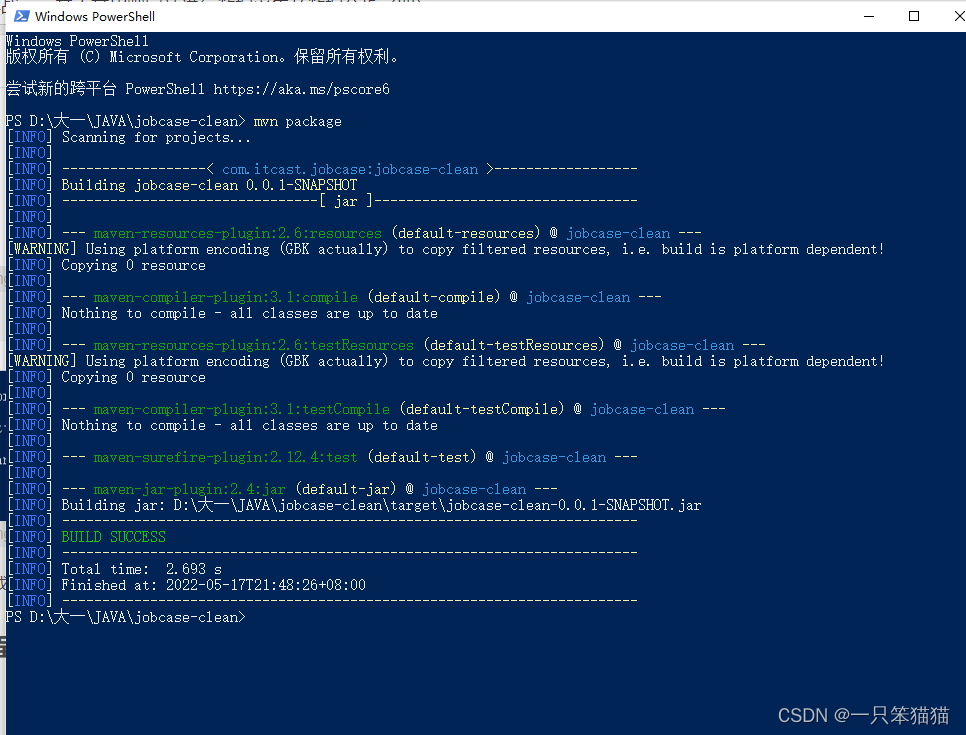
输入:mvn package ,将其打包成 jar 包
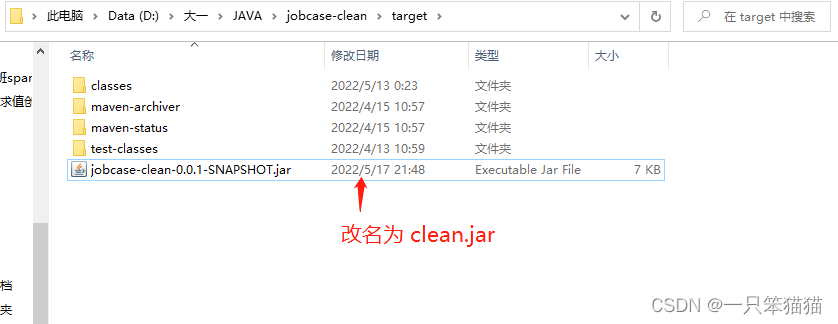
将所指 jar 包改名为 clean.jar

(3)上传 jar 包
上传到 Hadoop001 服务器的 /export/software,用 WinSCP 上传 jar 包到指定路径即可,上传后查看有没有 clean.,jar 这个 jar 包。

(4)在集群中运行 jar 包
在 Haoop001 中运行 hadoop jar 命令执行数据预处理程序的 jar 包,在命令中指定数据输入和结果输出的目录,命令如下。
hadoop jar clean.jar com.position.clean.CleanMain /JobData/20xxxxxx/ /JobData/output
由于每个人的 output 路径不一样,所以笨猫猫用xxxxxx代替之
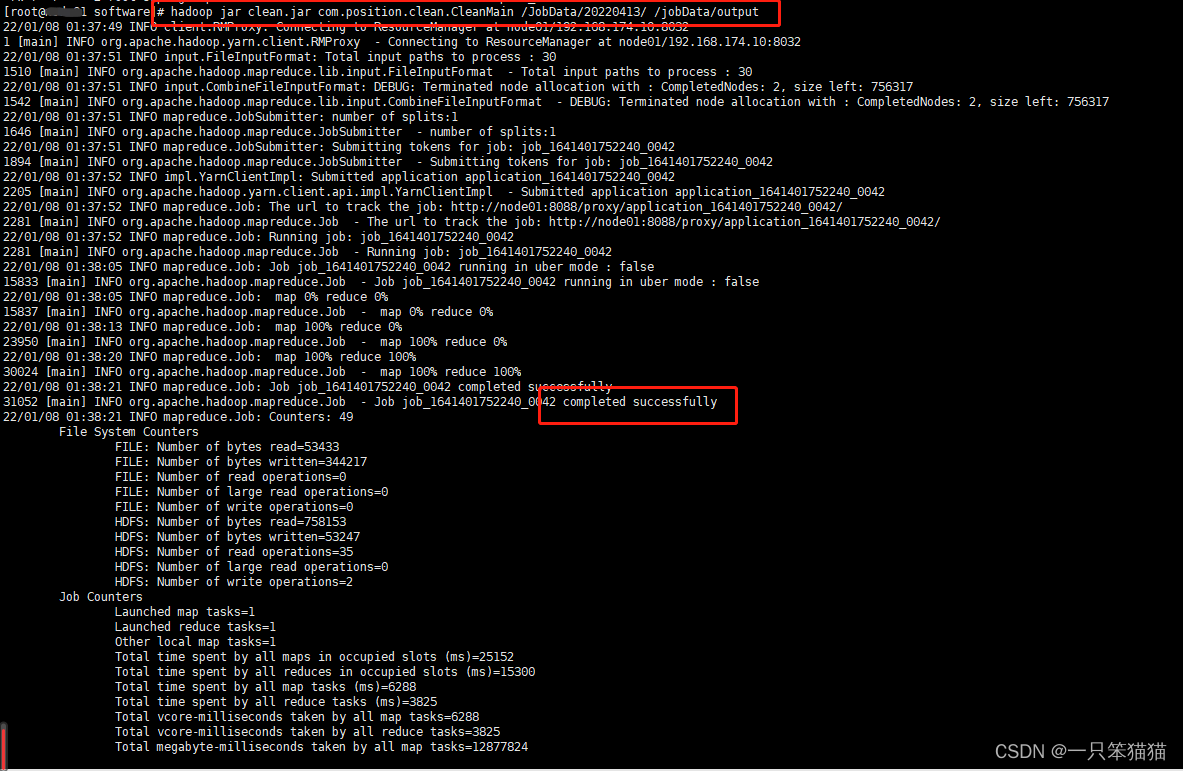
(5)查看结果
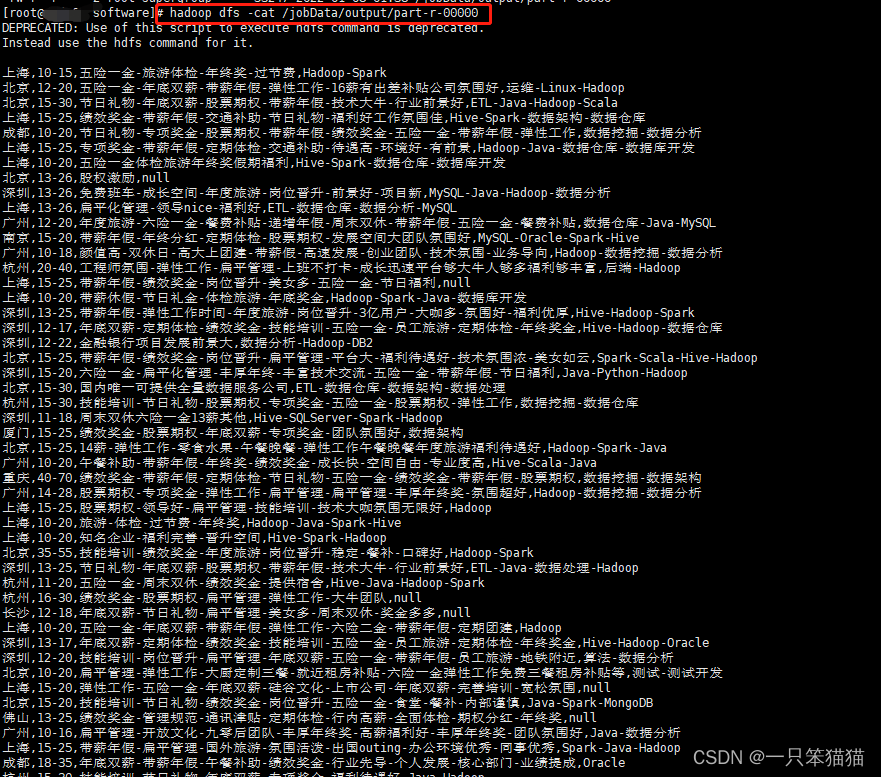
查看结果命令
hadoop dfs -cat /JobData/output/part-r-00000
出现如下图结果即为数据预处理完成。
总结
本篇主要讲解数据预处理程序的编写,通过分析预处理数据和设计数据预处理方案实现数据预处理程序。通过本篇的学习,读者可以掌握利用 MapReduce 分布式处理框架进行数据预处理的技巧,熟悉数据预处理的流程。