在使用虚拟机时,会有因磁盘空间不足需要外挂存储卷的操作(当然也有反向的操作,即卸载存储卷),本文我们来了解下kubevirt对运行中的虚拟机动态操作存储卷的实现,也就是热插拔存储卷。
hotplug volume
hotplug volume热插拔卷,热插拔在这里指的是虚拟机在不关机断电的情况支持插入或者拔出卷而不影响虚拟机的正常工作。kubevirt封装了virtctl addvolume和virtctl removevolume两个命令来支持热插拔卷,官网有一篇关于hotplug volume的文章,本章节以下内容是对该文章的一些翻译转述。
kubevirt支持运行中的vmi实例使用热插拔卷,但是卷必须是块设备(block volume)或者包含一个磁盘镜像(disk image)。当一个有热插拔卷的vm(注意是vm)实例重启(reboot)后,热插拔卷会attach到该vm中。如果此时卷存在的话,热插拔卷会成为vm spec下的一部分,此时不会被当做热插拔卷。如果此时不存在,这个卷则会作为热插拔卷重新attach。
使能hotplug volume
要使用热插拔卷功能,必须打开相应配置开关,即在kubevirt这个CR中添加HotplugVolume配置项。
virtctl支持
为了热插拔卷功能,首先必须准备好一个卷,这个卷可以是被DataVolume(DV,kubevirt的一个CRD)创建。为了添加额外的存储到一个运行中的vmi实例中,我们在示例中使用一个空的DV。
apiVersion: cdi.kubevirt.io/v1beta1
kind: DataVolume
metadata:
name: example-volume-hotplug
spec:
source:
blank: {}
pvc:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
在这个示例中我们使用ReadWriteOnce访问模式和默认的FileSystem卷模式。只要用户的存储支持组合,热插拔卷就支持所有块设备卷模式和ReadWriteMany/ReadWriteOnce/ReadOnlyMany访问模式的组合。
添加卷(addvolume)
假设当前我们已经启动了一个vmi实例,而且这个vmi实例的名称叫“vmi-fedora”,我们可以通过virtctl addvolume命令添加上述空白卷到这个运行中的虚拟机中。
$ virtctl addvolume vmi-fedora --volume-name=example-volume-hotplug
序列号
也可以使用–serial参数修改磁盘的序列号:
$ virtctl addvolume vmi-fedora --volume-name=example-volume-hotplug --serial=1234567890
这个序列号只在guest(即虚拟机)中使用,在虚拟机中,磁盘by-id会包含这个序列号:
$ virtctl console vmi-fedora
Fedora 32 (Cloud Edition)
Kernel 5.6.6-300.fc32.x86_64 on an x86_64 (ttyS0)
SSH host key: SHA256:c8ik1A9F4E7AxVrd6eE3vMNOcMcp6qBxsf8K30oC/C8 (ECDSA)
SSH host key: SHA256:fOAKptNAH2NWGo2XhkaEtFHvOMfypv2t6KIPANev090 (ED25519)
eth0: 10.244.196.144 fe80::d8b7:51ff:fec4:7099
vmi-fedora login:fedora
Password:fedora
[fedora@vmi-fedora ~]$ ls /dev/disk/by-id
scsi-0QEMU_QEMU_HARDDISK_1234567890
[fedora@vmi-fedora ~]$
可以看到序列号是磁盘名称的一部分,可以利用该序列号来唯一识别。序列号的格式和长度在libvirt文档中有说明:
If present, this specify serial number of virtual hard drive. For example, it may look like <serial>WD-WMAP9A966149</serial>. Not supported for scsi-block devices, that is those using disk type 'block' using device 'lun' on bus 'scsi'. Since 0.7.1
Note that depending on hypervisor and device type the serial number may be truncated silently. IDE/SATA devices are commonly limited to 20 characters. SCSI devices depending on hypervisor version are limited to 20, 36 or 247 characters.
Hypervisors may also start rejecting overly long serials instead of truncating them in the future so it's advised to avoid the implicit truncation by testing the desired serial length range with the desired device and hypervisor combination.
为什么是virtio-scsi?
热插拔磁盘类型被指定为scsi磁盘,为什么不像普通的磁盘一样指定为virtio类型?原因是virtio磁盘的数量限制,因为在虚拟机里,每一个
磁盘都会使用一个PCIe槽,而PCIe槽的数量上限是32,再加上一些其它设备也会使用PCIe槽,因此用户可热插拔磁盘的数量非常有限。另一个问题是这些热插拔槽需要提前预留,因为如果事先不知道热插拔磁盘的数量,则无法正确保留所需的插槽数量。为了解决上述问题,每一个vm都有一个virtio-scsi控制器(controller),它允许热插拔磁盘使用scsi总线。这个控制器允许热插拔超过400W个磁盘,而且virtio-scsi的性能和virtio性能也非常接近。
virtio-blk和virtio-scsi性能对比文章可参考:https://mpolednik.github.io/2017/01/23/virtio-blk-vs-virtio-scsi/
重启之后保留热插拔卷
在许多场景下都期望vm重启后能保留热插拔卷,当然也期望在重启后能支持拔出(unplug)热插拔卷。配置persist参数虚拟机重启后不能卸下之前的热插拔卷,如果没有声明persist参数,默认是在vm重启后会以热插拔卷的形式保留插拔卷。因此大部分时候persist参数都不用配置,除非你想虚拟机重启后把这个卷作为一个持久化的卷。
持久化(persist)
在一些场景下用户希望vm重启后之前的热插拔卷能作为vm的一个标准磁盘,例如你向vm添加了一些永久存储。我们假设正在运行的vmi具有定义其规范匹配的vm对象,你可以使用–persistent标志调用addvolume命令。除了更新vmi domain磁盘外,这将更新vm domain磁盘部分。这意味着当您重新启动vm时,磁盘已经在vm中定义,因此在新的vmi中也会定义。
$ virtctl addvolume vm-fedora --volume-name=example-volume-hotplug --persist
在vm spec字段中会显示成一个新的磁盘:
spec:
domain:
devices:
disks:
- disk:
bus: virtio
name: containerdisk
- disk:
bus: virtio
name: cloudinitdisk
- disk:
bus: scsi
name: example-volume-hotplug
machine:
type: ""
卸载热插拔卷(removevolume)
使用热插拔卷后,可以使用virtctl removevolume命令将热插拔卷拔出:
$ virtctl removevolume vmi-fedora --volume-name=example-volume-hotplug
Note:
只能卸下使用virtctl addvolume命令或者调API接口添加的热插拔卷
卷的状态(volumeStatus)
vmi对象有一个新的status.VolumeStatus字段,这是一个包含每个磁盘的数组(不管磁盘是否是热插拔)。例如,在addvolume示例中热插拔卷后,vmi状态将包含以下内容:
volumeStatus:
- name: cloudinitdisk
target: vdb
- name: containerdisk
target: vda
- hotplugVolume:
attachPodName: hp-volume-7fmz4
attachPodUID: 62a7f6bf-474c-4e25-8db5-1db9725f0ed2
message: Successfully attach hotplugged volume volume-hotplug to VM
name: example-volume-hotplug
phase: Ready
reason: VolumeReady
target: sda
vda是包含Fedora OS的容器磁盘,vdb是cloudinit磁盘,正如你所看到的,它们只包含在将它们分配给vm时使用的名称和目标(target)。目标是指定磁盘时传递给qemu的值,该值对于vm是唯一的,不代表guest(虚拟机)内部的命名。例如,对于Windows虚拟机操作系统,target没有意义,热插拔卷也一样。target只是qemu的唯一标识符,在guest中可以为磁盘分配不同的名称。
热插拔卷有一些常规卷状态没有的额外信息。attachPodName是用于将卷attach到vmi运行的节点的pod的名称。如果删除此pod,它也将停止vmi,此时kubevirt无法保证卷将继续attach到节点。其他字段与conditions类似,表示热插拔过程的状态。一旦卷就绪,vm就可以使用它。
热迁移(live migration)
当前kubevirt虚拟机的热迁移支持带有热插拔卷的vm,但是有一个已知问题是,如果热迁移的目标节点使用具有静态策略的CPU管理器和v1.0.0之前版本的runc,则具有热插拔块卷的VMI的迁移可能会失败。
本文以下内容基于[email protected]
virtctl addvolume/removevolume源码分析
通过前文,我们对kubevirt的热插拔卷和virtctl addvolume/removevolume有了一个大致了解,本章节我们从源码层面来看看virtctl addvolume和virtctl removevlume这两个命令的实现。
virtctl addvolume
virtctl
virtctl addvolume命令封装源码如下:
// pkg/virtctl/vm/vm.go
func NewAddVolumeCommand(clientConfig clientcmd.ClientConfig) *cobra.Command {
cmd := &cobra.Command{
Use: "addvolume VMI",
Short: "add a volume to a running VM",
Example: usageAddVolume(),
Args: templates.ExactArgs("addvolume", 1),
RunE: func(cmd *cobra.Command, args []string) error {
c := Command{command: COMMAND_ADDVOLUME, clientConfig: clientConfig}
return c.Run(args)
},
}
cmd.SetUsageTemplate(templates.UsageTemplate())
cmd.Flags().StringVar(&volumeName, volumeNameArg, "", "name used in volumes section of spec")
cmd.MarkFlagRequired(volumeNameArg)
cmd.Flags().StringVar(&serial, serialArg, "", "serial number you want to assign to the disk")
cmd.Flags().StringVar(&cache, cacheArg, "", "caching options attribute control the cache mechanism")
cmd.Flags().BoolVar(&persist, persistArg, false, "if set, the added volume will be persisted in the VM spec (if it exists)")
cmd.Flags().BoolVar(&dryRun, dryRunArg, false, dryRunCommandUsage)
return cmd
}
virtctl addvolume的完整命令示例为:virtctl addvolume -n {namespace} {vmiName} --volume-name={volumeName} --serial={serial} --persist={true|false} --dry-run={true|false},相关参数释义如下:
- namespace:指定命名空间,非必填,不指定则是default命名空间
- vmiName:指定vmi名称,必填,即需要操作的虚拟机名称
- volumeName:热插拔卷的名称,可以是同命名空间下的DataVolume(kubevirt的另一个CRD)或者pvc名称
- serial:指定卷的序列号,非必填
- persist:是否持久化。如果为true,则虚拟机重启后该卷仍存在;false则会在重启后不存在
- dry-run:预检模式运行
再看看virtctl封装实现:
// pkg/virtctl/vm/vm.go
func addVolume(vmiName, volumeName, namespace string, virtClient kubecli.KubevirtClient, dryRunOption *[]string) error {
volumeSource, err := getVolumeSourceFromVolume(volumeName, namespace, virtClient)
if err != nil {
return fmt.Errorf("error adding volume, %v", err)
}
hotplugRequest := &v1.AddVolumeOptions{
Name: volumeName,
Disk: &v1.Disk{
DiskDevice: v1.DiskDevice{
Disk: &v1.DiskTarget{
// 为什么是scsi而不是virtio可参考官网hotplug volume
Bus: "scsi",
},
},
},
VolumeSource: volumeSource,
DryRun: *dryRunOption,
}
if serial != "" {
hotplugRequest.Disk.Serial = serial
} else {
hotplugRequest.Disk.Serial = volumeName
}
if cache != "" {
hotplugRequest.Disk.Cache = v1.DriverCache(cache)
// Verify if cache mode is valid
if hotplugRequest.Disk.Cache != v1.CacheNone &&
hotplugRequest.Disk.Cache != v1.CacheWriteThrough &&
hotplugRequest.Disk.Cache != v1.CacheWriteBack {
return fmt.Errorf("error adding volume, invalid cache value %s", cache)
}
}
if !persist {
err = virtClient.VirtualMachineInstance(namespace).AddVolume(context.Background(), vmiName, hotplugRequest)
} else {
err = virtClient.VirtualMachine(namespace).AddVolume(vmiName, hotplugRequest)
}
if err != nil {
return fmt.Errorf("error adding volume, %v", err)
}
fmt.Printf("Successfully submitted add volume request to VM %s for volume %s\n", vmiName, volumeName)
return nil
}
func getVolumeSourceFromVolume(volumeName, namespace string, virtClient kubecli.KubevirtClient) (*v1.HotplugVolumeSource, error) {
//Check if data volume exists.
_, err := virtClient.CdiClient().CdiV1beta1().DataVolumes(namespace).Get(context.TODO(), volumeName, metav1.GetOptions{})
if err == nil {
return &v1.HotplugVolumeSource{
DataVolume: &v1.DataVolumeSource{
Name: volumeName,
Hotpluggable: true,
},
}, nil
}
// DataVolume not found, try PVC
_, err = virtClient.CoreV1().PersistentVolumeClaims(namespace).Get(context.TODO(), volumeName, metav1.GetOptions{})
if err == nil {
return &v1.HotplugVolumeSource{
PersistentVolumeClaim: &v1.PersistentVolumeClaimVolumeSource{
PersistentVolumeClaimVolumeSource: k8sv1.PersistentVolumeClaimVolumeSource{
ClaimName: volumeName,
},
Hotpluggable: true,
},
}, nil
}
// Neither return error
return nil, fmt.Errorf("Volume %s is not a DataVolume or PersistentVolumeClaim", volumeName)
}
virtcl客户端这里的封装主要是针对不同参数做不同处理,主要有以下的注意点:
- disk bus配置的是
scsi而不是virtio,原因可参考hotplug volume - virtctl会从DataVolume和pvc中查找volumeName,二者任意一个匹配都满足
- 如果persist为false,调用的是
vmi的AddVolume方法;如果persist为true,调用的则是vm的AddVolume方法。
virt-api
virtctl调用vmi/vm的AddVolume方法后,请求都会被k8s的apiServer转到virt-api,我们来看看virt-api如何处理这两个请求:
func (app *virtAPIApp) composeSubresources() {
/*...*/
subws.Route(subws.PUT(definitions.NamespacedResourcePath(subresourcesvmiGVR)+definitions.SubResourcePath("addvolume")).
To(subresourceApp.VMIAddVolumeRequestHandler).
Reads(v1.AddVolumeOptions{}).
Param(definitions.NamespaceParam(subws)).Param(definitions.NameParam(subws)).
Operation(version.Version+"vmi-addvolume").
Doc("Add a volume and disk to a running Virtual Machine Instance").
Returns(http.StatusOK, "OK", "").
Returns(http.StatusBadRequest, httpStatusBadRequestMessage, ""))
subws.Route(subws.PUT(definitions.NamespacedResourcePath(subresourcesvmGVR)+definitions.SubResourcePath("addvolume")).
To(subresourceApp.VMAddVolumeRequestHandler).
Reads(v1.AddVolumeOptions{}).
Param(definitions.NamespaceParam(subws)).Param(definitions.NameParam(subws)).
Operation(version.Version+"vm-addvolume").
Doc("Add a volume and disk to a running Virtual Machine.").
Returns(http.StatusOK, "OK", "").
Returns(http.StatusBadRequest, httpStatusBadRequestMessage, ""))
/*...*/
}
// pkg/virt-api/rest/subresource.go
// VMIAddVolumeRequestHandler handles the subresource for hot plugging a volume and disk.
func (app *SubresourceAPIApp) VMIAddVolumeRequestHandler(request *restful.Request, response *restful.Response) {
app.addVolumeRequestHandler(request, response, true)
}
// VMAddVolumeRequestHandler handles the subresource for hot plugging a volume and disk.
func (app *SubresourceAPIApp) VMAddVolumeRequestHandler(request *restful.Request, response *restful.Response) {
app.addVolumeRequestHandler(request, response, false)
}
可以看到,不管是vmi还是vm的addVolume操作,最终都是走到addVolumeRequestHandler函数:
// pkg/virt-api/rest/subresource.go
func (app *SubresourceAPIApp) addVolumeRequestHandler(request *restful.Request, response *restful.Response, ephemeral bool) {
/*...*/
// 这里的ephemeral实际上是前文的persist参数
// inject into VMI if ephemeral, else set as a request on the VM to both make permanent and hotplug.
if ephemeral {
if err := app.vmiVolumePatch(name, namespace, &volumeRequest); err != nil {
writeError(err, response)
return
}
} else {
if err := app.vmVolumePatchStatus(name, namespace, &volumeRequest); err != nil {
writeError(err, response)
return
}
}
/*...*/
}
func (app *SubresourceAPIApp) vmiVolumePatch(name, namespace string, volumeRequest *v1.VirtualMachineVolumeRequest) *errors.StatusError {
vmi, statErr := app.FetchVirtualMachineInstance(namespace, name)
if statErr != nil {
return statErr
}
if !vmi.IsRunning() {
return errors.NewConflict(v1.Resource("virtualmachineinstance"), name, fmt.Errorf(vmiNotRunning))
}
patch, err := generateVMIVolumeRequestPatch(vmi, volumeRequest)
if err != nil {
return errors.NewConflict(v1.Resource("virtualmachineinstance"), name, err)
}
dryRunOption := app.getDryRunOption(volumeRequest)
log.Log.Object(vmi).V(4).Infof("Patching VMI: %s", patch)
if _, err := app.virtCli.VirtualMachineInstance(vmi.Namespace).Patch(context.Background(), vmi.Name, types.JSONPatchType, []byte(patch), &k8smetav1.PatchOptions{DryRun: dryRunOption}); err != nil {
log.Log.Object(vmi).V(1).Errorf("unable to patch vmi: %v", err)
if errors.IsInvalid(err) {
if statErr, ok := err.(*errors.StatusError); ok {
return statErr
}
}
return errors.NewInternalError(fmt.Errorf("unable to patch vmi: %v", err))
}
return nil
}
func (app *SubresourceAPIApp) vmVolumePatchStatus(name, namespace string, volumeRequest *v1.VirtualMachineVolumeRequest) *errors.StatusError {
vm, statErr := app.fetchVirtualMachine(name, namespace)
if statErr != nil {
return statErr
}
patch, err := generateVMVolumeRequestPatch(vm, volumeRequest)
if err != nil {
return errors.NewConflict(v1.Resource("virtualmachine"), name, err)
}
dryRunOption := app.getDryRunOption(volumeRequest)
log.Log.Object(vm).V(4).Infof(patchingVMFmt, patch)
if err := app.statusUpdater.PatchStatus(vm, types.JSONPatchType, []byte(patch), &k8smetav1.PatchOptions{DryRun: dryRunOption}); err != nil {
log.Log.Object(vm).V(1).Errorf("unable to patch vm status: %v", err)
if errors.IsInvalid(err) {
if statErr, ok := err.(*errors.StatusError); ok {
return statErr
}
}
return errors.NewInternalError(fmt.Errorf("unable to patch vm status: %v", err))
}
return nil
}
通过上面代码可以看出,不管是vmiVolumePatch还是vmVolumePatchStatus,原理都差不多,即都是对比当前vmi/vm中的卷信息与请求中的卷信息差异,然后更新到对应的vmi/vm对象中。
virt-controller
通过前面的代码发现virt-api更新完vmi/vm对象信息后没有后续的逻辑了,而vmi/vm的更新会被virt-controller监听到,于是流程来到了virt-controller。我们直接从virt-controller中处理vmi的关键代码看起(vm相关代码流程留给读者自行研读):
// pkg/virt-controller/watch/vmi.go
func (c *VMIController) sync(vmi *virtv1.VirtualMachineInstance, pod *k8sv1.Pod, dataVolume []*cdiv1.DataVolume) syncError {
/*...*/
if !isTempPod(pod) && isPodReady(pod) {
hotplugVolumes := getHotplugVolumes(vmi, pod)
hotplugAttachmentPods, err := controller.AttachmemtPods(pod, c.podInformer)
if err != nil {
return &syncErrorImpl{fmt.Errorf("failed to get attachment pods: %v", err), FailedHotplugSyncReason}
}
if pod.DeletionTimestamp == nil && c.needsHandleHotplug(hotplugVolumes, hotplugAttachmentPods) {
var hotplugSyncErr syncError = nil
hotplugSyncErr = c.handleHotplugVolumes(hotplugVolumes, hotplugAttachmentPods, vmi, pod, dataVolumes)
if hotplugSyncErr != nil {
if hotplugSyncErr.Reason() == MissingAttachmentPodReason {
// We are missing an essential hotplug pod. Delete all pods associated with the VMI.
c.deleteAllMatchingPods(vmi)
} else {
return hotplugSyncErr
}
}
}
}
return nil
}
// pkg/virt-controller/watch/vmi.go
func (c *VMIController) handleHotplugVolumes(hotplugVolumes []*virtv1.Volume, hotplugAttachmentPods []*k8sv1.Pod, vmi *virtv1.VirtualMachineInstance, virtLauncherPod *k8sv1.Pod, dataVolumes []*cdiv1.DataVolume) syncError {
logger := log.Log.Object(vmi)
readyHotplugVolumes := make([]*virtv1.Volume, 0)
// Find all ready volumes
for _, volume := range hotplugVolumes {
var err error
ready, wffc, err := c.volumeReadyToAttachToNode(vmi.Namespace, *volume, dataVolumes)
if err != nil {
return &syncErrorImpl{fmt.Errorf("Error determining volume status %v", err), PVCNotReadyReason}
}
if wffc {
// Volume in WaitForFirstConsumer, it has not been populated by CDI yet. create a dummy pod
logger.V(1).Infof("Volume %s/%s is in WaitForFistConsumer, triggering population", vmi.Namespace, volume.Name)
syncError := c.triggerHotplugPopulation(volume, vmi, virtLauncherPod)
if syncError != nil {
return syncError
}
continue
}
if !ready {
// Volume not ready, skip until it is.
logger.V(3).Infof("Skipping hotplugged volume: %s, not ready", volume.Name)
continue
}
readyHotplugVolumes = append(readyHotplugVolumes, volume)
}
// Determine if the ready volumes have changed compared to the current pod
currentPod := make([]*k8sv1.Pod, 0)
oldPods := make([]*k8sv1.Pod, 0)
for _, attachmentPod := range hotplugAttachmentPods {
if !c.podVolumesMatchesReadyVolumes(attachmentPod, readyHotplugVolumes) {
oldPods = append(oldPods, attachmentPod)
} else {
currentPod = append(currentPod, attachmentPod)
}
}
if len(currentPod) == 0 && len(readyHotplugVolumes) > 0 {
// ready volumes have changed
// Create new attachment pod that holds all the ready volumes
if err := c.createAttachmentPod(vmi, virtLauncherPod, readyHotplugVolumes); err != nil {
return err
}
}
// Delete old attachment pod
for _, attachmentPod := range oldPods {
if err := c.deleteAttachmentPodForVolume(vmi, attachmentPod); err != nil {
return &syncErrorImpl{fmt.Errorf("Error deleting attachment pod %v", err), FailedDeletePodReason}
}
}
return nil
}
一个远端存储设备要在容器/虚拟机中使用,一般会有attach、格式化、mount等操作,这里的attachmentPod的作用就是将存储设备attach到节点上。
可以看到virt-controller在处理热插拔卷时两个关键动作createAttachmentPod和deleteAttachmentPodForVolume,其中createAttachmentPod对应的是addvolume,deleteAttachmentPodForVolume对应的是removevolume,逻辑很简单,就是把attachmentPod删除。本章节主要看看createAttachmentPod。
我们从createAttachmentPod往下继续看具体代码实现:
// pkg/virt-controller/watch/vmi.go
func (c *MigrationController) createAttachmentPod(migration *virtv1.VirtualMachineInstanceMigration, vmi *virtv1.VirtualMachineInstance, virtLauncherPod *k8sv1.Pod) error {
/*...*/
attachmentPodTemplate, err := c.templateService.RenderHotplugAttachmentPodTemplate(volumes, virtLauncherPod, vmiCopy, volumeNamesPVCMap, false)
if err != nil {
return fmt.Errorf("failed to render attachment pod template: %v", err)
}
/*...*/
attachmentPod, err := c.clientset.CoreV1().Pods(vmi.GetNamespace()).Create(context.Background(), attachmentPodTemplate, v1.CreateOptions{})
/*...*/
}
// pkg/virt-controller/services/template.go
func (t *templateService) RenderHotplugAttachmentPodTemplate(volumes []*v1.Volume, ownerPod *k8sv1.Pod, vmi *v1.VirtualMachineInstance, claimMap map[string]*k8sv1.PersistentVolumeClaim, tempPod bool) (*k8sv1.Pod, error) {
zero := int64(0)
sharedMount := k8sv1.MountPropagationHostToContainer
command := []string{"/bin/sh", "-c", "/usr/bin/container-disk --copy-path /path/hp"}
pod := &k8sv1.Pod{
ObjectMeta: metav1.ObjectMeta{
GenerateName: "hp-volume-",
OwnerReferences: []metav1.OwnerReference{
*metav1.NewControllerRef(ownerPod, schema.GroupVersionKind{
Group: k8sv1.SchemeGroupVersion.Group,
Version: k8sv1.SchemeGroupVersion.Version,
Kind: "Pod",
}),
},
Labels: map[string]string{
v1.AppLabel: hotplugDisk,
},
},
Spec: k8sv1.PodSpec{
Containers: []k8sv1.Container{
{
Name: hotplugDisk,
Image: t.launcherImage,
Command: command,
Resources: k8sv1.ResourceRequirements{ //Took the request and limits from containerDisk init container.
Limits: map[k8sv1.ResourceName]resource.Quantity{
k8sv1.ResourceCPU: resource.MustParse("100m"),
k8sv1.ResourceMemory: resource.MustParse("80M"),
},
Requests: map[k8sv1.ResourceName]resource.Quantity{
k8sv1.ResourceCPU: resource.MustParse("10m"),
k8sv1.ResourceMemory: resource.MustParse("2M"),
},
},
SecurityContext: &k8sv1.SecurityContext{
SELinuxOptions: &k8sv1.SELinuxOptions{
Level: "s0",
Type: t.clusterConfig.GetSELinuxLauncherType(),
},
},
VolumeMounts: []k8sv1.VolumeMount{
{
Name: hotplugDisks,
MountPath: "/path",
MountPropagation: &sharedMount,
},
},
},
},
Affinity: &k8sv1.Affinity{
NodeAffinity: &k8sv1.NodeAffinity{
RequiredDuringSchedulingIgnoredDuringExecution: &k8sv1.NodeSelector{
NodeSelectorTerms: []k8sv1.NodeSelectorTerm{
{
MatchExpressions: []k8sv1.NodeSelectorRequirement{
{
Key: "kubernetes.io/hostname",
Operator: k8sv1.NodeSelectorOpIn,
Values: []string{ownerPod.Spec.NodeName},
},
},
},
},
},
},
},
Volumes: []k8sv1.Volume{
{
Name: hotplugDisks,
VolumeSource: k8sv1.VolumeSource{
EmptyDir: &k8sv1.EmptyDirVolumeSource{},
},
},
},
TerminationGracePeriodSeconds: &zero,
},
}
hotplugVolumeStatusMap := make(map[string]v1.VolumePhase)
for _, status := range vmi.Status.VolumeStatus {
if status.HotplugVolume != nil {
hotplugVolumeStatusMap[status.Name] = status.Phase
}
}
for _, volume := range volumes {
claimName := types.PVCNameFromVirtVolume(volume)
if claimName == "" {
continue
}
skipMount := false
if hotplugVolumeStatusMap[volume.Name] == v1.VolumeReady || hotplugVolumeStatusMap[volume.Name] == v1.HotplugVolumeMounted {
skipMount = true
}
pod.Spec.Volumes = append(pod.Spec.Volumes, k8sv1.Volume{
Name: volume.Name,
VolumeSource: k8sv1.VolumeSource{
PersistentVolumeClaim: &k8sv1.PersistentVolumeClaimVolumeSource{
ClaimName: claimName,
},
},
})
if !skipMount {
pvc := claimMap[volume.Name]
if pvc != nil {
if pvc.Spec.VolumeMode != nil && *pvc.Spec.VolumeMode == k8sv1.PersistentVolumeBlock {
pod.Spec.Containers[0].VolumeDevices = append(pod.Spec.Containers[0].VolumeDevices, k8sv1.VolumeDevice{
Name: volume.Name,
DevicePath: fmt.Sprintf("/path/%s/%s", volume.Name, pvc.GetUID()),
})
pod.Spec.SecurityContext = &k8sv1.PodSecurityContext{
RunAsUser: &[]int64{0}[0],
}
} else {
pod.Spec.Containers[0].VolumeMounts = append(pod.Spec.Containers[0].VolumeMounts, k8sv1.VolumeMount{
Name: volume.Name,
MountPath: fmt.Sprintf("/%s", volume.Name),
})
}
}
}
}
return pod, nil
}
通过上面的代码可以看出,在执行virtctl addvolume后,virtcontroller会创建一个attachmentPod来plug卷,这个pod有几个注意点:
- 使用的镜像是virt-launcher的镜像,但是执行的命令是/bin/sh -c /user/bin/container-disk --copy-path /path/hp,
该命令的作用是拷贝attachmentPod的vmi镜像到宿主机上的一个共享目录/path/hp,当virt-handler发现vmi有一个这种镜像文件后,会把必要的配置更新到对应的domain xml中 - 该pod的ownerReference是虚拟机对应的pod
- 配置了SElinux参数level和type
- 如果pvc是块设备,则把pvc信息填充到pod.spec.volumeDevices下,路径为/path/{pvc名称}/{pvcID};其它类型的存储则挂到/{pvc名称}下。并设置运行用户为0,也就是root用户
当创建完这个attachmentPod后,会重新触发virt-controller中的vmi controller流程,源码如下。本次virt-controller逻辑主要是在vmi.spec.volumeStatus中更新热插拔卷的状态为AttachedToNode(即借助k8s原生功能把pvc attach到宿主机上了),并且设置该status的hotplugVolume.attachPodUID为attachmentPod(后面virt-handler在宿主机上找相关资源时需要用到该id)。
// pkg/virt-controller/watch/vmi.go
func (c *VMIController) updateStatus(vmi *virtv1.VirtualMachineInstance, pod *k8sv1.Pod, dataVolumes []*cdiv1.DataVolume, syncErr syncError) error {
/*...*/
case vmi.IsRunning():
// 运行中的虚拟机
/*...*/
c.updateVolumeStatus(vmiCopy, pod)
/*...*/
}
func (c *VMIController) updateVolumeStatus(vmi *virtv1.VirtualMachineInstance, virtlauncherPod *k8sv1.Pod) error {
/*...*/
for i, volume := range vmi.Spec.Volumes {
/*...*/
if _, ok := hotplugVolumesMap[volume.Name]; ok {
/*...*/
attachmentPod := c.findAttachmentPodByVolumeName(volume.Name, attachmentPods)
if attachmentPod == nil {
/*...*/
} else {
status.HotplugVolume.AttachPodName = attachmentPod.Name
if len(attachmentPod.Status.ContainerStatuses) == 1 && attachmentPod.Status.ContainerStatuses[0].Ready {
status.HotplugVolume.AttachPodUID = attachmentPod.UID
}
if c.canMoveToAttachedPhase(status.Phase) {
// 在vmi.status.volumeStatus下增加一个状态变化记录,记录卷的状态为attachedToNode
status.Phase = virtv1.HotplugVolumeAttachedToNode
status.Message = fmt.Sprintf("Created hotplug attachment pod %s, for volume %s", attachmentPod.Name, volume.Name)
status.Reason = SuccessfulCreatePodReason
c.recorder.Eventf(vmi, k8sv1.EventTypeNormal, status.Reason, status.Message)
}
}
}
}
}
当virt-controller执行完上述步骤后,就轮到virt-handler,virt-handler中的vmController监听到上述变动后,会走到如下代码中:
// pkg/virt-handler/vm.go
func (d *VirtualMachineController) vmUpdateHelperDefault(origVMI *v1.VirtualMachineInstance, domainExists bool) error {
if !vmi.IsRunning() && !vmi.IsFinal() {
/*...*/
} else if vmi.IsRunning() {
if err := d.hotplugVolumeMounter.Mount(vmi); err != nil {
return err
}
}
/*...*/
// 调virt-launcher grpc接口同步修改到libvirt xml和domain中
err = client.SyncVirtualMachine(vmi, options)
if err != nil {
isSecbootError := strings.Contains(err.Error(), "EFI OVMF rom missing")
if isSecbootError {
return &virtLauncherCriticalSecurebootError{fmt.Sprintf("mismatch of Secure Boot setting and bootloaders: %v", err)}
}
return err
}
if !domainExists {
d.recorder.Event(vmi, k8sv1.EventTypeNormal, v1.Created.String(), VMIDefined)
}
if vmi.IsRunning() {
// Umount any disks no longer mounted
if err := d.hotplugVolumeMounter.Unmount(vmi); err != nil {
return err
}
}
return nil
}
// pkg/virt-handler/hotplug-disk/mount.go
func (m *volumeMounter) Mount(vmi *v1.VirtualMachineInstance) error {
record, err := m.getMountTargetRecord(vmi)
if err != nil {
return err
}
for _, volumeStatus := range vmi.Status.VolumeStatus {
if volumeStatus.HotplugVolume == nil {
// Skip non hotplug volumes
continue
}
sourceUID := volumeStatus.HotplugVolume.AttachPodUID
if err := m.mountHotplugVolume(vmi, volumeStatus.Name, sourceUID, record); err != nil {
return err
}
}
return nil
}
func (m *volumeMounter) mountHotplugVolume(vmi *v1.VirtualMachineInstance, volumeName string, sourceUID types.UID, record *vmiMountTargetRecord) error {
logger := log.DefaultLogger()
logger.V(4).Infof("Hotplug check volume name: %s", volumeName)
if sourceUID != types.UID("") {
if m.isBlockVolume(&vmi.Status, volumeName) {
logger.V(4).Infof("Mounting block volume: %s", volumeName)
if err := m.mountBlockHotplugVolume(vmi, volumeName, sourceUID, record); err != nil {
return err
}
} else {
logger.V(4).Infof("Mounting file system volume: %s", volumeName)
if err := m.mountFileSystemHotplugVolume(vmi, volumeName, sourceUID, record); err != nil {
return err
}
}
}
return nil
}
func (m *volumeMounter) mountBlockHotplugVolume(vmi *v1.VirtualMachineInstance, volume string, sourceUID types.UID, record *vmiMountTargetRecord) error {
virtlauncherUID := m.findVirtlauncherUID(vmi)
if virtlauncherUID == "" {
// This is not the node the pod is running on.
return nil
}
targetPath, err := m.hotplugDiskManager.GetHotplugTargetPodPathOnHost(virtlauncherUID)
if err != nil {
return err
}
deviceName := filepath.Join(targetPath, volume)
isMigrationInProgress := vmi.Status.MigrationState != nil && !vmi.Status.MigrationState.Completed
if isBlockExists, _ := isBlockDevice(deviceName); !isBlockExists {
computeCGroupPath, err := m.getTargetCgroupPath(vmi)
if err != nil {
return err
}
sourceMajor, sourceMinor, permissions, err := m.getSourceMajorMinor(sourceUID, volume)
if err != nil {
return err
}
if err := m.writePathToMountRecord(deviceName, vmi, record); err != nil {
return err
}
// allow block devices
if err := m.allowBlockMajorMinor(sourceMajor, sourceMinor, computeCGroupPath); err != nil {
return err
}
if _, err = m.createBlockDeviceFile(deviceName, sourceMajor, sourceMinor, permissions); err != nil {
return err
}
} else if isBlockExists && (!m.volumeStatusReady(volume, vmi) || isMigrationInProgress) {
// Block device exists already, but the volume is not ready yet, ensure that the device is allowed.
computeCGroupPath, err := m.getTargetCgroupPath(vmi)
if err != nil {
return err
}
sourceMajor, sourceMinor, _, err := m.getSourceMajorMinor(sourceUID, volume)
if err != nil {
return err
}
if err := m.allowBlockMajorMinor(sourceMajor, sourceMinor, computeCGroupPath); err != nil {
return err
}
}
return nil
}
func (m *volumeMounter) mountFileSystemHotplugVolume(vmi *v1.VirtualMachineInstance, volume string, sourceUID types.UID, record *vmiMountTargetRecord) error {
virtlauncherUID := m.findVirtlauncherUID(vmi)
if virtlauncherUID == "" {
// This is not the node the pod is running on.
return nil
}
targetDisk, err := m.hotplugDiskManager.GetFileSystemDiskTargetPathFromHostView(virtlauncherUID, volume, false)
if err != nil {
return err
}
if isMounted, err := isMounted(targetDisk); err != nil {
return fmt.Errorf("failed to determine if %s is already mounted: %v", targetDisk, err)
} else if !isMounted {
sourcePath, err := m.getSourcePodFilePath(sourceUID, vmi, volume)
if err != nil {
log.DefaultLogger().V(3).Infof("Error getting source path: %v", err)
// We are eating the error to avoid spamming the log with errors, it might take a while for the volume
// to get mounted on the node, and this will error until the volume is mounted.
return nil
}
if err := m.writePathToMountRecord(targetDisk, vmi, record); err != nil {
return err
}
targetDisk, err := m.hotplugDiskManager.GetFileSystemDiskTargetPathFromHostView(virtlauncherUID, volume, true)
if err != nil {
return err
}
if out, err := mountCommand(filepath.Join(sourcePath, "disk.img"), targetDisk); err != nil {
return fmt.Errorf("failed to bindmount hotplug-disk %v: %v : %v", volume, string(out), err)
}
} else {
return nil
}
return nil
}
上面的代码就是virt-handler把pvc挂到虚拟机里的逻辑:如果pvc是块设备,会通过cgroup+mknod等步骤把块设备从attachment pod“放入”kvm pod中;如果是fs,则通过virt-chroot等步骤把attachment pod磁盘挂到kvm pod中。之后virt-handler会调用kvm pod中virt-launcher的grpc接口SyncVirtualMachine把数据同步到libvirt的domain和xml中。
virt-launcher
virt-launcher中的SyncVirtualMachine方法如下,通过vmi对象中的信息和pod中的信息更新libvirt domain和xml从而完成完成最终的pvc挂到虚拟机中:
// pkg/virt-launcher/virtwrap/cmd-server/server.go
func (l *Launcher) SyncVirtualMachine(_ context.Context, request *cmdv1.VMIRequest) (*cmdv1.Response, error) {
vmi, response := getVMIFromRequest(request.Vmi)
if !response.Success {
return response, nil
}
if _, err := l.domainManager.SyncVMI(vmi, l.allowEmulation, request.Options); err != nil {
log.Log.Object(vmi).Reason(err).Errorf("Failed to sync vmi")
response.Success = false
response.Message = getErrorMessage(err)
return response, nil
}
log.Log.Object(vmi).Info("Synced vmi")
return response, nil
}
// pkg/virt-launcher/virtwrap/cmd-server/manager.go
func (l *LibvirtDomainManager) SyncVMI(vmi *v1.VirtualMachineInstance, allowEmulation bool, options *cmdv1.VirtualMachineOptions) (*api.DomainSpec, error) {
/*...*/
domain := &api.Domain{}
c, err := l.generateConverterContext(vmi, allowEmulation, options, false)
if err != nil {
logger.Reason(err).Error("failed to generate libvirt domain from VMI spec")
return nil, err
}
if err := converter.Convert_v1_VirtualMachineInstance_To_api_Domain(vmi, domain, c); err != nil {
logger.Error("Conversion failed.")
return nil, err
}
/*...*/
xmlstr, err := dom.GetXMLDesc(0)
if err != nil {
return nil, err
}
var oldSpec api.DomainSpec
err = xml.Unmarshal([]byte(xmlstr), &oldSpec)
if err != nil {
logger.Reason(err).Error("Parsing domain XML failed.")
return nil, err
}
//Look up all the disks to detach
for _, detachDisk := range getDetachedDisks(oldSpec.Devices.Disks, domain.Spec.Devices.Disks) {
logger.V(1).Infof("Detaching disk %s, target %s", detachDisk.Alias.GetName(), detachDisk.Target.Device)
detachBytes, err := xml.Marshal(detachDisk)
if err != nil {
logger.Reason(err).Error("marshalling detached disk failed")
return nil, err
}
err = dom.DetachDevice(strings.ToLower(string(detachBytes)))
if err != nil {
logger.Reason(err).Error("detaching device")
return nil, err
}
}
//Look up all the disks to attach
for _, attachDisk := range getAttachedDisks(oldSpec.Devices.Disks, domain.Spec.Devices.Disks) {
allowAttach, err := checkIfDiskReadyToUse(getSourceFile(attachDisk))
if err != nil {
return nil, err
}
if !allowAttach {
continue
}
logger.V(1).Infof("Attaching disk %s, target %s", attachDisk.Alias.GetName(), attachDisk.Target.Device)
attachBytes, err := xml.Marshal(attachDisk)
if err != nil {
logger.Reason(err).Error("marshalling attached disk failed")
return nil, err
}
err = dom.AttachDevice(strings.ToLower(string(attachBytes)))
if err != nil {
logger.Reason(err).Error("attaching device")
return nil, err
}
}
// Resize and notify the VM about changed disks
for _, disk := range domain.Spec.Devices.Disks {
if shouldExpandOnline(dom, disk) {
possibleGuestSize, ok := possibleGuestSize(disk)
if !ok {
logger.Reason(err).Warningf("Failed to get possible guest size from disk %v", disk)
break
}
err := dom.BlockResize(getSourceFile(disk), uint64(possibleGuestSize), libvirt.DOMAIN_BLOCK_RESIZE_BYTES)
if err != nil {
logger.Reason(err).Errorf("libvirt failed to expand disk image %v", disk)
}
}
}
// TODO: check if VirtualMachineInstance Spec and Domain Spec are equal or if we have to sync
return &oldSpec, nil
当pvc挂到虚拟机中之后,virt-handler会更新vmi中volumeStatus字段,virt-controller中的逻辑也会删除attachmemt pod。
virtctl removevolume
virtctl removevolume其实整体逻辑和virtctl addvolume差不多,都是virtctl封装请求发送给virt-api,virt-api对比差异更新vmi/vm,之后virt-controller监听到vmi/vm的变化,执行deleteAttachmentPodForVolume,unplug卷。整体逻辑分析可参考上述virtctl addvolume,此处不再赘述。
整体逻辑
通过前面的分析,我们对kubevirt热插拔卷支持的实现原理有了更深层次的理解,我们假设当前有一个正在运行的kvm(一个vmi对象+一个vmi pod)以及一个块设备pvc,结合图示整理下virtctl addvolume的整体流程(virtctl removevolume流程类似,读者可自行分析)。
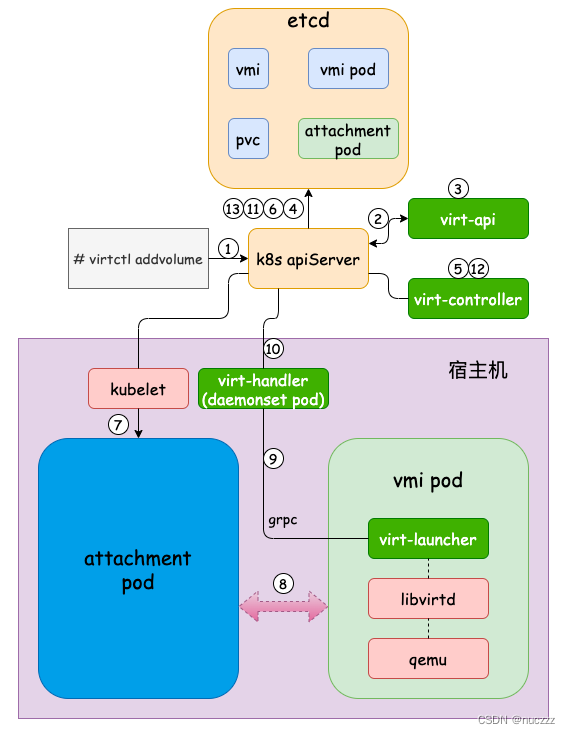
- 用户执行virtctl addvolume命令,请求到达k8s apiserver;
- k8s apiserver把该请求转发给virt-api;
- virt-api收到请求,调k8s apiserver接口更新vmi对象的spec.volumes和spec.domain.devices.disks等字段;
- k8s apiserver收到请求更新etcd中vmi对象;
- virt-controller监听到vmi对象的更新事件,发现有hotplug volume需要处理,调k8s apiserver接口创建一个attachment pod,该pod配置需要挂载的pvc;
- k8s apiserver在etcd中创建attachment pod对象;
- 经过k8s scheduler调度后(图示中省略了这个过程),对应宿主机上的kubelet创建attachment pod,这里借助了k8s原生功能,完成pvc块设备到宿主机的attach过程。
- 节点上的virt-handler发现有attachment pod创建且需要处理hotplug volume后,通过操作cgroup、chroot、mknod等动作把pvc块设备挂到vmi pod中;
- virt-handler通过grpc接口调virt-launcher的SyncVirtualMachine方法,使得pod中的设备数据更新到libvirt的xml和domain中;
- virt-hanlder调k8s apiserver更新vmi的volumeStatus等字段;
- k8s apiserver更新etcd中的vmi对象;
- virt-controller监听到vmi更新,此时会调k8s apiserver删除前面创建的attachment pod;
- k8s apiserver删除etcd中的attachment pod。
微信公众号卡巴斯同步发布,欢迎大家关注。