1、简单了解了一下GPU和CPU的区别
CPU是Central Process Unit,中央处理器,是个人计算机之中负责处理数据和计算的元件。你在计算机上执行的任何一个操作都需要经过CPU的处理和 计算,才能展示给你结果,所以CPU越好,你的计算机的反应速度就越快。
而GPU是Graphic Process Unit,图形处理器,是专门进行图形数据处理和计算的处理器。在通识中,许多人可能会误解说,GPU是比CPU更“高档”、更“先进“的处理器,但实际上GPU并非CPU的 替代品, GPU也不是”更高层次“的CPU。这两种处理器都执行计算机运行所需的相同的“计算过程”,但不同的是, CPU擅长处理复杂、连续的计算问题,例如操作系统、程序、键盘操作、鼠标操作等,而GPU 擅长处理简单、大量、重复、并行的计算问题,比如游戏中的3D图形渲染,他们之间不能互相代替。一个业内著名的比喻是:CPU是几个博士生,GPU是成千上万个小学生,我把它比喻成CPU是王兴,GPU是美团骑手。对于复杂问题,GPU不如CPU解决得好,甚至不能解决,而对于简单大量问题,CPU再牛,也敌不过GPU并行处理的效率和规模。所以现在的计算机,如果搭配了GPU的,都是CPU+GPU的组合,普通操作和程序运行由CPU执行,当需要GPU时,CPU会指定GPU来进行操作。
深度学习中所涉及到的运算是简单大量、还是复杂连续的呢?答案是简单大量。神经网络涉及的运算过 程其实比很多机器学习算法都要容易(感谢反向传播),神经网络运算的难点主要在于巨量数据需求, 因此GPU在处理深度学习算法时的运算速度有时甚至可以达到CPU的100倍以上。因此在深度学习中,如果有机会,那务必要使用GPU。
2、由下图可见,我的电脑不支持安装GPU(呜呜呜┭┮﹏┭┮),于是接下来TensorFlow选择安装CPU版本即可。
在自己的桌面上点击右键,如果你能够找到NVIDIA控制面板,则说明你这台电脑有适合PyTorch的GPU,你可以安装GPU版本,否则你的电脑就不能安装PyTorch的GPU版本。

3、Anaconda在上学期已经安装过,所以这里直接配置python环境。
Anaconda是一个开源的Python发行版本,用来管理python相关的包,使用anaconda可以很方便的切换不同的环境,使用不同的深度学习框架开发项目。
输入链接“https://www.anaconda.com/”登录Anaconda官网。
鼠标选中“Products”,点击“Indiviaual Edition”选项(Individual Edition是免费版的)。
选择Windows版本“64-Bit Graphical Installer双击“Anaconda3-2021.11-Windows-x86_64.exe”,进行安装。(510 MB)”进行安装。
接下来一路next并选择下载路径。
配置环境变量
在系统变量(一定要看清,是系统变量,不是用户变量)一栏中,找到“Path”(这个Path不同电脑的书写可能不一样,所以根据自己电脑上的来,我这里是Path,但其它的电脑可能在大小写上有区别)。
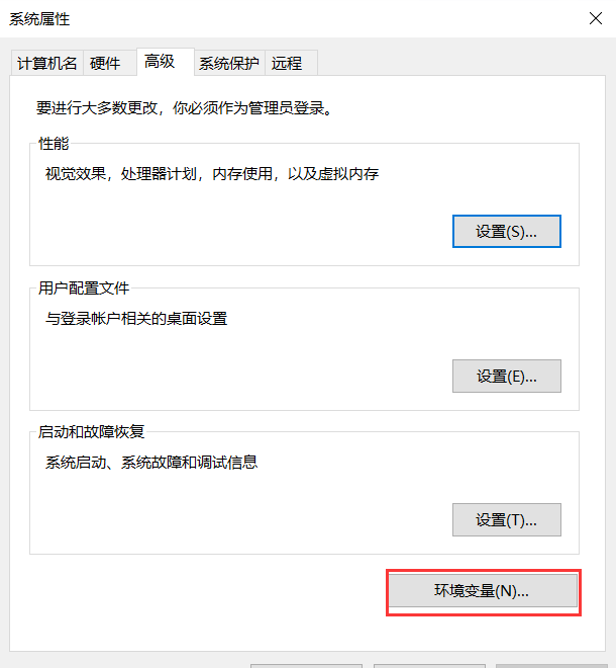
输入以下信息(Anaconda安装路径要根据自己当时安装Anaconda的路径来):
Anaconda安装路径
Anaconda安装路径\Scripts
Anaconda安装路径\Library\bin
检验是否成功:
(1)打开cmd。
(2)输入“conda --version”。
(3)输入“conda info”。
输入“activate”,回车,之后再输入“python”。显示版本即安装成功。

4、在anaconda Prompt中创建python环境并激活
5、升级pip

6、下载TensorFlow2.10版本
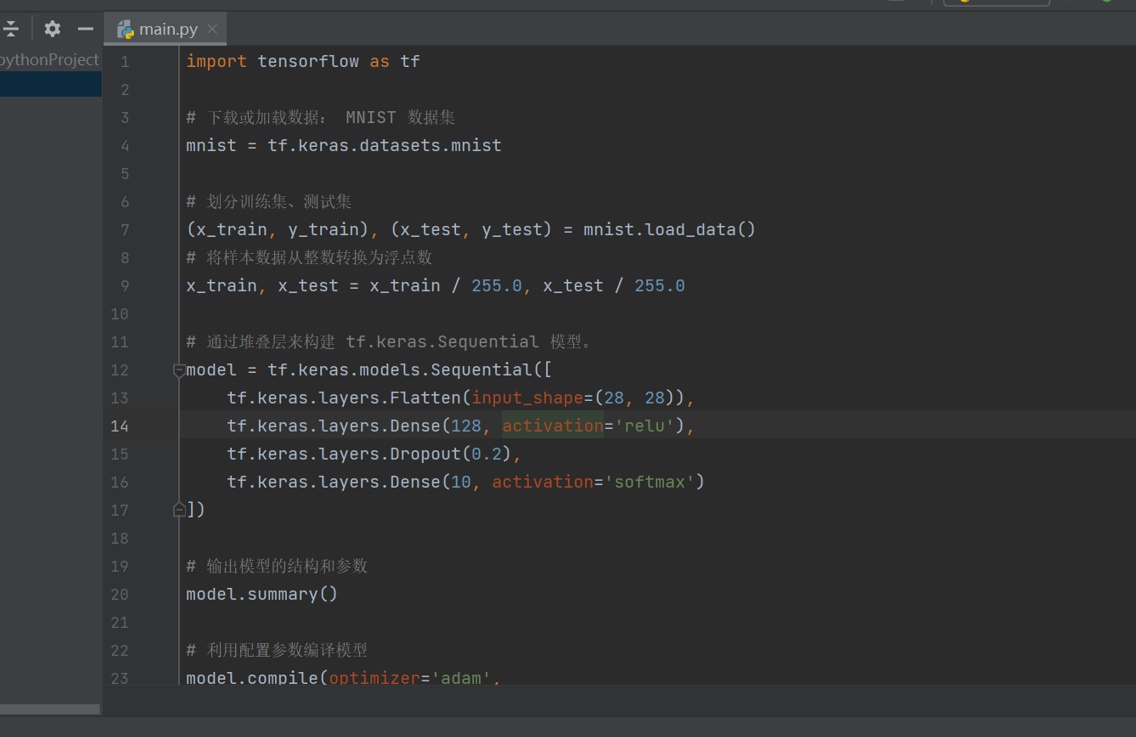
7、测试一个代码
import tensorflow as tf
# 下载或加载数据: MNIST 数据集
mnist = tf.keras.datasets.mnist
# 划分训练集、测试集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 将样本数据从整数转换为浮点数
x_train, x_test = x_train / 255.0, x_test / 255.0
# 通过堆叠层来构建 tf.keras.Sequential 模型。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
# 输出模型的结构和参数
model.summary()
# 利用配置参数编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 评估模型
model.evaluate(x_test, y_test)
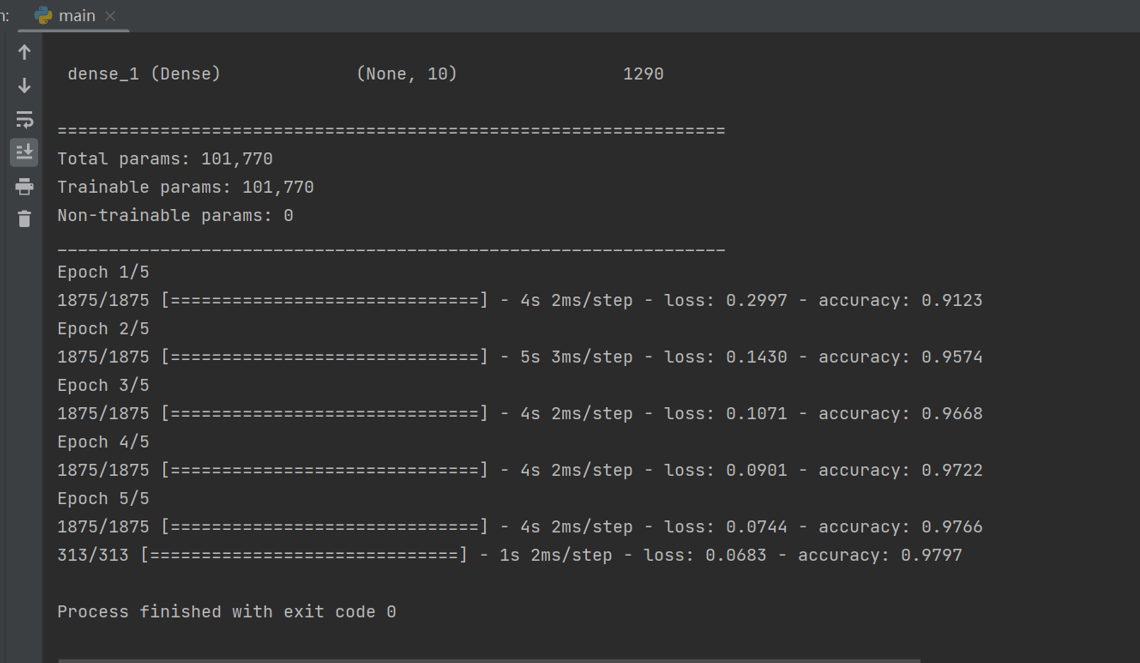
8、运行结果如下所示,可见安装成功,小功告成!
9、TensorFlow学习
TensorFlow™是一个基于数据流编程(dataflow programming)的符号数学系统,被广泛应用于各类机器学习(machine learning)算法的编程实现,其前身是谷歌的神经网络算法库DistBelief。
Tensorflow拥有多层级结构,可部署于各类服务器、PC终端和网页并支持GPU和TPU高性能数值计算,被广泛应用于谷歌内部的产品开发和各领域的科学研究。
TensorFlow由谷歌人工智能团队谷歌大脑(Google Brain)开发和维护,拥有包括TensorFlow Hub、TensorFlow Lite、TensorFlow Research Cloud在内的多个项目以及各类应用程序接口(ApplicationProgramming Interface, API)。自2015年11月9日起,TensorFlow依据阿帕奇授权协议(Apache 2.0 open source license)开放源代码。
分布式TensorFlow的核心组件(core runtime)包括:分发中心(distributed master)、执行器(dataflowexecutor/worker service)、内核应用(kernel implementation)和最底端的设备层(device layer)/网络层(networkinglayer)。
分发中心从输入的数据流图中剪取子图(subgraph),将其划分为操作片段并启动执行器。分发中心处理数据流图时会进行预设定的操作优化,包括公共子表达式消去(common subexpression elimination)、常量折叠(constantfolding)等。
执行器负责图操作(graph operation)在进程和设备中的运行、收发其它执行器的结果。分布式TensorFlow拥有参数器(parameter server)以汇总和更新其它执行器返回的模型参数。执行器在调度本地设备时会选择进行并行计算和GPU加速。
内核应用负责单一的图操作,包括数学计算、数组操作(array manipulation)、控制流(control flow)和状态管理操作(state management operations)。内核应用使用Eigen执行张量的并行计算、cuDNN库等执行GPU加速、gemmlowp执行低数值精度计算,此外用户可以在内核应用中注册注册额外的内核(fused kernels)以提升基础操作,例如激励函数和其梯度计算的运行效率。
单进程版本的TensorFlow没有分发中心和执行器,而是使用特殊的会话应用(Sessionimplementation)联系本地设备。TensorFlow的C语言API是核心组件和用户代码的分界,其它组件/API均通过C语言API与核心组件进行交互。
10、安装中遇到的问题
我在下了半天才发现自己的电脑装不了GPU,也算是给自己长了一个教训,在下次配置环境的时候你要做的是先了解你的电脑和配置情况!因为整个安装过程唯一问题是所有的东西的版本是否全都统一。
显卡部分:了解你的驱动版本、支持的CUDA版本(为统一版本做准备)
方法:鼠标右键—>NVIDIA控制面板—>组件
(查看的是支持的版本,不是已安装的版本)
说明:支持的CUDA版本是最高版本,可向下兼容(不是上来看到这里是什么版本就直接下载)
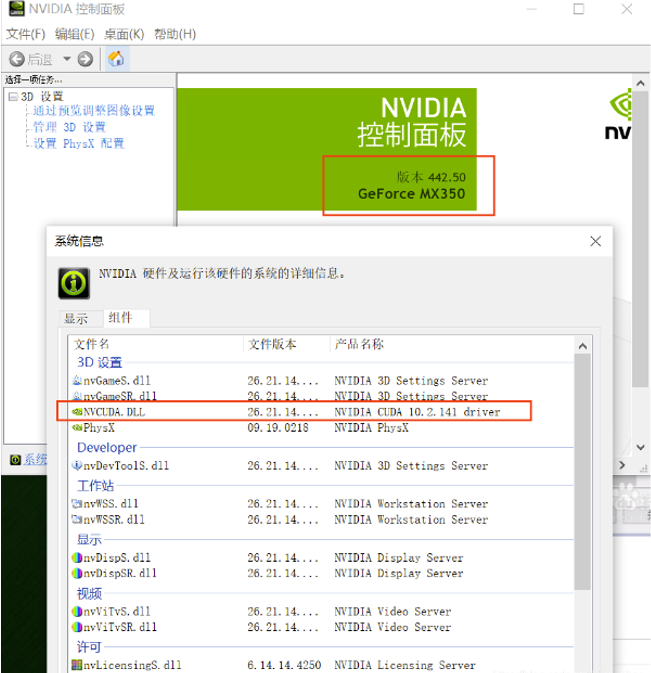
下次注意!!