从零开始学Pandas:数据分析必备技能速成
- 1. 创建pandas对象
- 1.1 前言
- 1.2 使用DataFrame类创建pandas对象
- 1.3 对DataFrame对象进行索引
- 1.4 使用Series类创建pandas对象
- 1.5 对DataFrame Series对象使用常见方法
- 2. pandas读取文件
- 2.1 使用pd.read_*方法读取文件
- 2.2 使用to_*保存数据
- 2.3 使用info()方法查看详细信息
- 3. 创建DataFrame子集
- 3.1 导入数据
- 3.2 使用索引DataFrame创建子集
- 3.3 筛选
- 3.4 loc和iloc选择特定行列
- 4. 使用matplotlib画图
- 4.1 导入数据
- 4.2 .plot()使用
- 4.3 subplot子图绘画
- 4.4 保存图片
- 5. 创建新列
- 5.1 导入数据
- 5.2 创建新列
- 5.3 列名重命名
- 6. 汇总统计
- 6.1 导入数据
- 6.2 Series对象数据汇总
- 6.3 DataFrame对象数据汇总
- 6.4 分组
- 6.5 分组索引
- 6.6 统计数据
- 7. 重塑表格布局
- 7.1 导入数据
- 7.2 排序
- 7.3 数据重塑
- 7.4 数据重塑 聚合
- 7.5 添加新索引
- 7.6 将宽表变长表
- 8. 合并多个表
- 8.1 导入数据
- 8.2 拼接
- 9. 处理时间序列数据
- 9.1 导入数据
- 9.2 时间字符串to时间数据
- 9.3 日期时间常用方法
- 9.4 根据日期时间画图
- 9.5 日期时间索引
- 9.6 按照时间频率分组聚合
- 10. 操作文本数据
- 10.1 导入数据
- 10.2 字符串基本操作
)
pandas代码和CSV文件 点击免费下载
1. 创建pandas对象
1.1 前言
在 Pandas 中,Series 和 DataFrame 是核心数据结构。Series 是一维数组,包含数据和索引,适合存储单列数据,如数值或字符串。DataFrame 是二维表格,由多个 Series 组成,每列是一个 Series,具有共享的行索引,适合处理多列数据,如表格或数据库结构。
两者的关系为:DataFrame 是 Series 的集合,每列都是一个 Series 对象。例如,DataFrame 中可以通过列名提取 Series,也可以将多个 Series 合并成一个 DataFrame。因此,Series 是构成 DataFrame 的基础。
1.2 使用DataFrame类创建pandas对象
import pandas as pd
df = pd.DataFrame( #参数为字典,键为标题,值为数据且用列表
{
"Name":[
"Braund, Mr. Owen Harris",
"Allen, Mr. William Henry",
"Bonnell, Miss. Elizabeth",
],
"Age":[22, 35, 58],
"Sex":["male", "male", "female"],
}
)
df #查看对象
| Name | Age | Sex | |
|---|---|---|---|
| 0 | Braund, Mr. Owen Harris | 22 | male |
| 1 | Allen, Mr. William Henry | 35 | male |
| 2 | Bonnell, Miss. Elizabeth | 58 | female |
1.3 对DataFrame对象进行索引
df["Age"] #对Age索引
| 0 | 22 |
|---|---|
| 1 | 35 |
| 2 | 58 |
| Name:Age | dtype:int64 |
1.4 使用Series类创建pandas对象
ages = pd.Series([22, 35, 58], name="Age") #创建Series对象
ages #查看ages
| 0 | 22 |
|---|---|
| 1 | 35 |
| 2 | 58 |
| Name:Age | dtype:int64 |
1.5 对DataFrame Series对象使用常见方法
df["Age"].max()
# np.int64(58)
ages.max()
# np.int64(58)
df.describe() #对DataFrame中数值型的列可以详细描述出来 例如数量 平均值等
| Age | |
|---|---|
| count | 3.000000 |
| mean | 38.333333 |
| std | 18.230012 |
| min | 22.000000 |
| 25% | 28.500000 |
| 50% | 35.000000 |
| 75% | 46.500000 |
| max | 58.000000 |
2. pandas读取文件
2.1 使用pd.read_*方法读取文件
import pandas as pd #导入pandas包
titanic = pd.read_csv("train.csv") #读取csv文件
titanic #查看文件
titanic.head(8) #查看前8行
titanic.dtypes #查看每一列的数据类型
2.2 使用to_*保存数据
# 将titanic数据保存为excel形式 sheet_name为passengers 不添加索引到表格里
titanic.to_excel("titanic.xlsx", sheet_name="passengers", index=False)
#重新读取保存文件
titanic = pd.read_excel("titanic.xlsx", sheet_name="passengers")
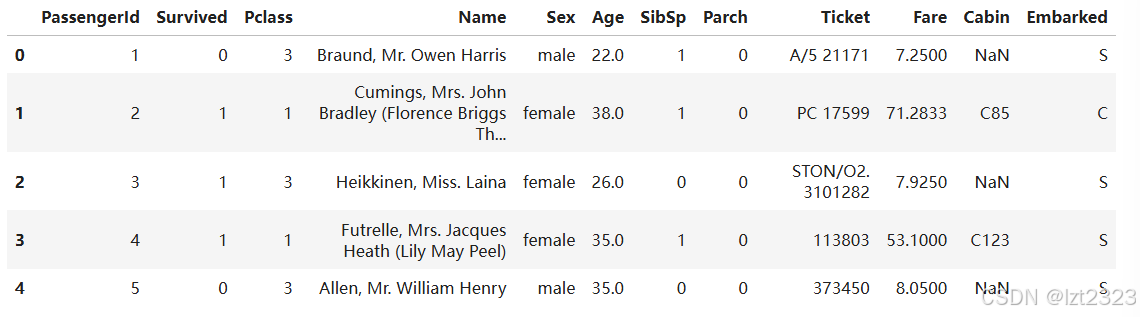
titanic.head() #查看前5行数据
2.3 使用info()方法查看详细信息
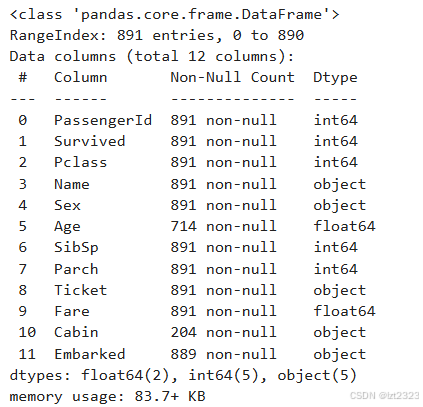
titanic.info() #查看详细信息
DataFrame类
共891行 索引从0到890
数据共12列
每列的索引 Column 每列的名字 Non-Null Count 每列含有数据的数量(有的列为NAN) Dtype 每列数据类型
dtypes 数据类型总结
memory usage 使用内存大小
3. 创建DataFrame子集
3.1 导入数据
import pandas as pd
titanic = pd.read_csv("train.csv")
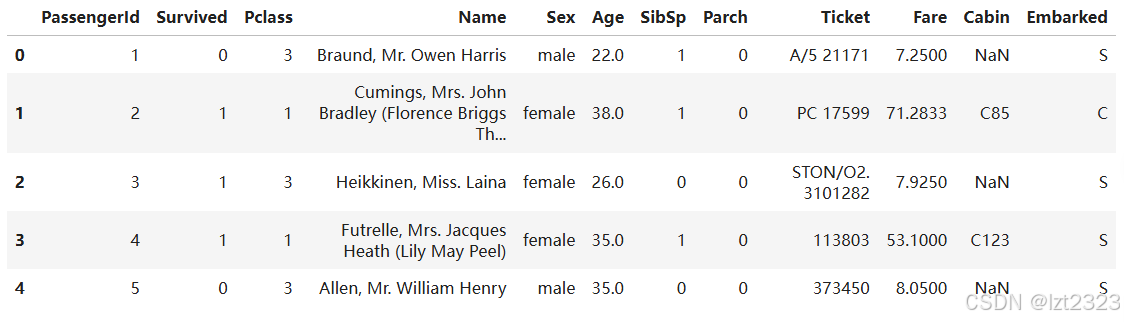
titanic.head() #查看前5行数据
3.2 使用索引DataFrame创建子集
ages = titanic["Age"] #单列创建Series对象
age_sex = titanic[["Age", "Sex"]] #多列创建DataFrame对象
type(titanic["Age"]), type(titanic[["Age", "Sex"]]) #查看对象类型
# (pandas.core.series.Series, pandas.core.frame.DataFrame)
ages.head(), age_sex.head() #查看数据

titanic["Age"].shape, titanic[["Age", "Sex"]].shape #查看数据形状
# ((891,), (891, 2))
3.3 筛选
#筛选条件
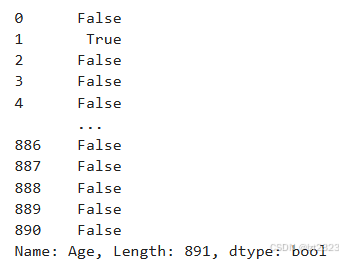
titanic["Age"] > 35
# format: DataFrameobject[筛选条件]
above_35 = titanic[titanic["Age"] > 35] #选择Age大于35的行
above_35.head()
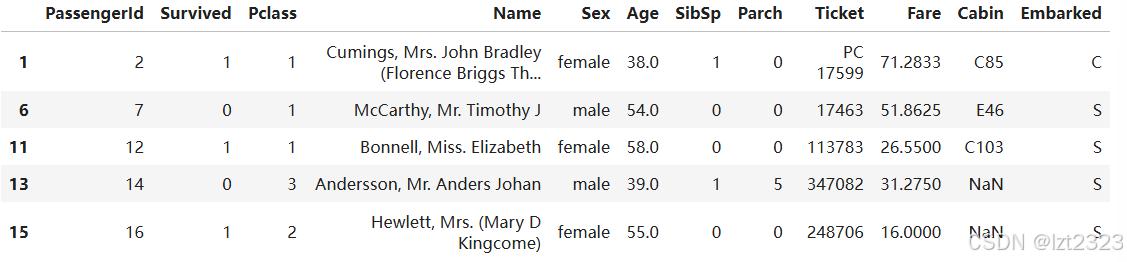
#选择2 3等舱的行 .isin()方法
class_23 = titanic[titanic["Pclass"].isin([2, 3])]
class_23.head()
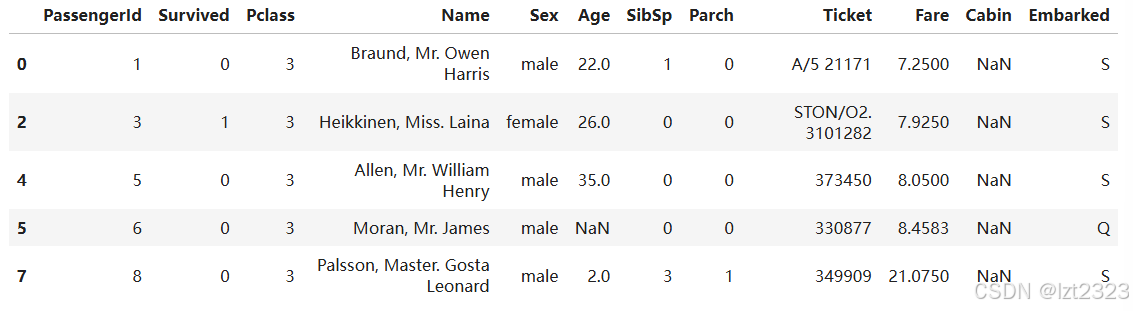
#选择Age列有数值的行 .notna()方法
age_no_na = titanic[titanic["Age"].notna()]
age_no_na.head()
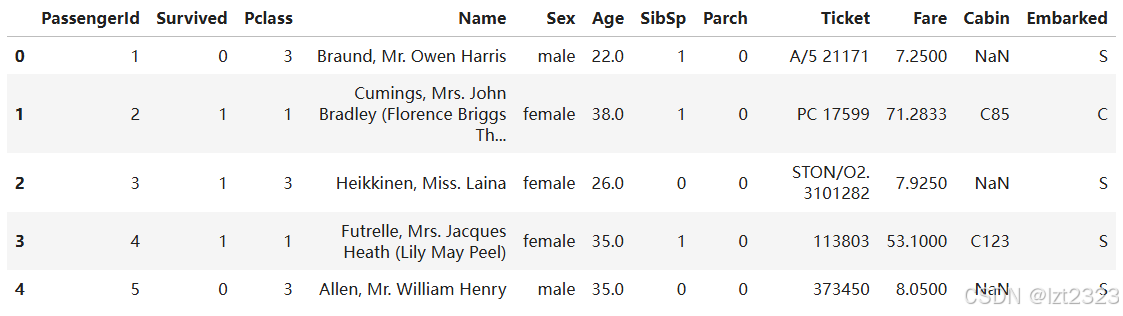
3.4 loc和iloc选择特定行列
# format: DataFrameobject.loc[筛选条件, "列名"]
# 筛选年龄大于35的行,并只显示名字 Series类型
adult_names = titanic.loc[titanic["Age"] > 35, "Name"]
adult_names.head()

#format: DataFrameobject.iloc[行切片, 列切片]
titanic.iloc[9:25, 2:5] #10到25行,3到5列
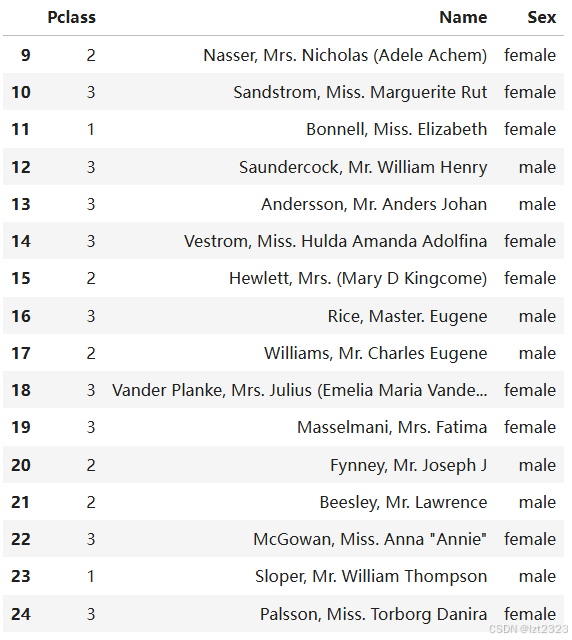
4. 使用matplotlib画图
4.1 导入数据
import pandas as pd
import matplotlib.pyplot as plt
# index_col=0 csv文件第一列将作为DataFrame的索引 parse_dates=True 将被选为索引的列(或自动识别的日期列)转换为日期时间格式,而不是保留为字符串。
air_quality = pd.read_csv("air_quality_no2.csv", index_col=0, parse_dates=True)
# 查看数据
air_quality.head()
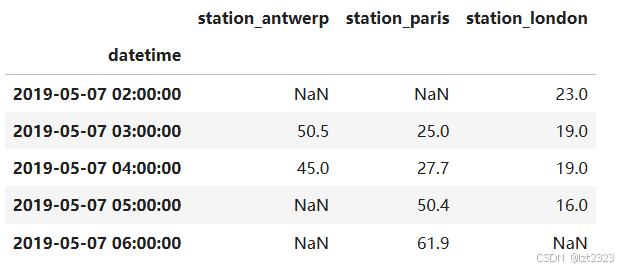
4.2 .plot()使用
air_quality.plot() #直接绘画 第一列索引为x轴 各列为y轴
plt.show()
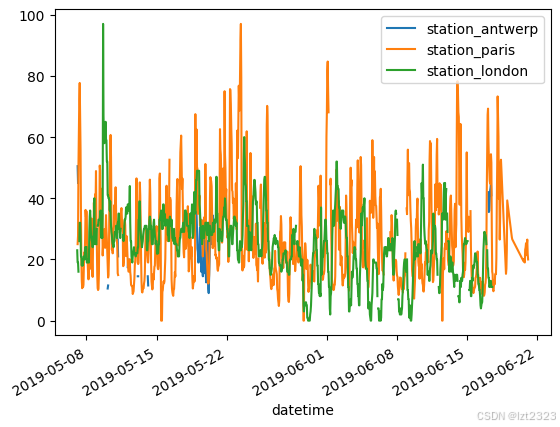
#format: DataFrameObject["列名"].plot()
#只画"station_paris"列
air_quality["station_paris"].plot()
plt.show()
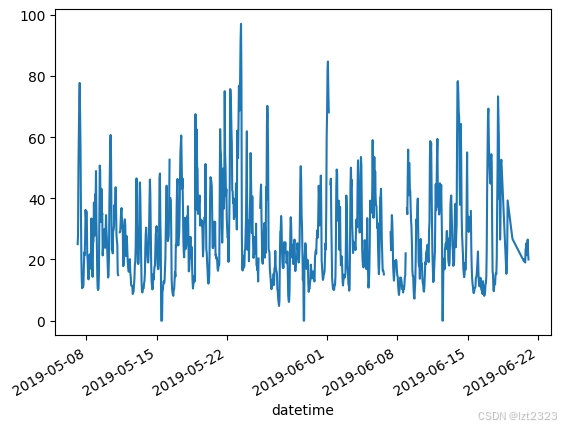
#画其他类型的图
#format: DataFrameObject.plot.other()
#画散点图
air_quality.plot.scatter(x="station_london", y="station_paris", alpha=0.5)
plt.show()
air_quality.plot.box()

[
method_name
for method_name in dir(air_quality.plot)
if not method_name.startswith("_")
] #查看能画哪些图类型
#['area',
#'bar',
#'barh',
#'box',
#'density',
#'hexbin',
#'hist',
#'kde',
#'line',
#'pie',
# 'scatter']
4.3 subplot子图绘画
#format: DataFrame.plot.area(figsize=(x, y), subplot=True)
axs = air_quality.plot.area(figsize=(12, 4), subplot=True)
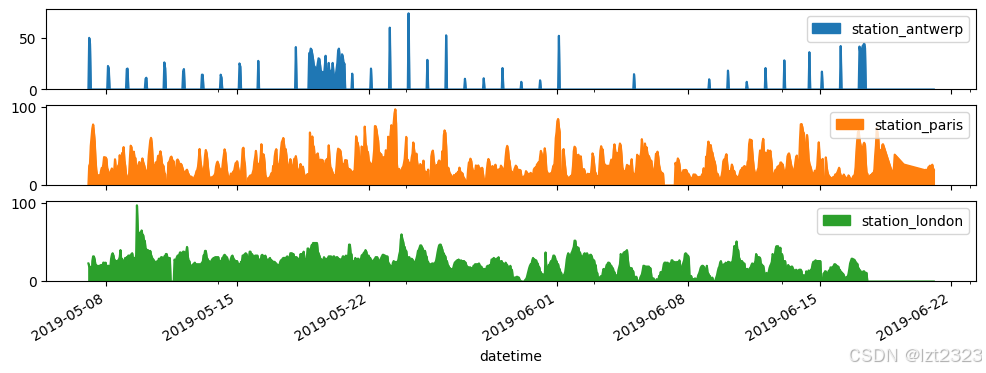
4.4 保存图片
# 使用 Matplotlib 和 Pandas 的绘图功能来创建和保存一张面积图
# 创建一个图表和子图(即坐标轴)
# fig 是图形对象,可以用于控制整体的图表布局和保存
# axs 是坐标轴对象,用于在图中绘制数据
# figsize=(12, 4) 设置图表的宽度为 12 英寸,高度为 4 英寸,控制图表的整体尺寸。
fig, axs = plt.subplots(figsize=(12, 4))
# 调用 Pandas 的 plot.area() 方法在 axs 上绘制面积图
# air_quality 是一个 DataFrame,其中包含需要绘制的 NO₂(氮氧化物)浓度数据
# ax=axs 指定在 axs 这个坐标轴上绘制图形,而不是创建新的坐标轴
air_quality.plot.area(ax=axs)
# 设置y轴标签
axs.set_ylabel("NO$_2$ concentration")
# 将绘制的图保存为一个 PNG 文件
fig.savefig("no2_concentrations.png")
# 显示图片
plt.show()
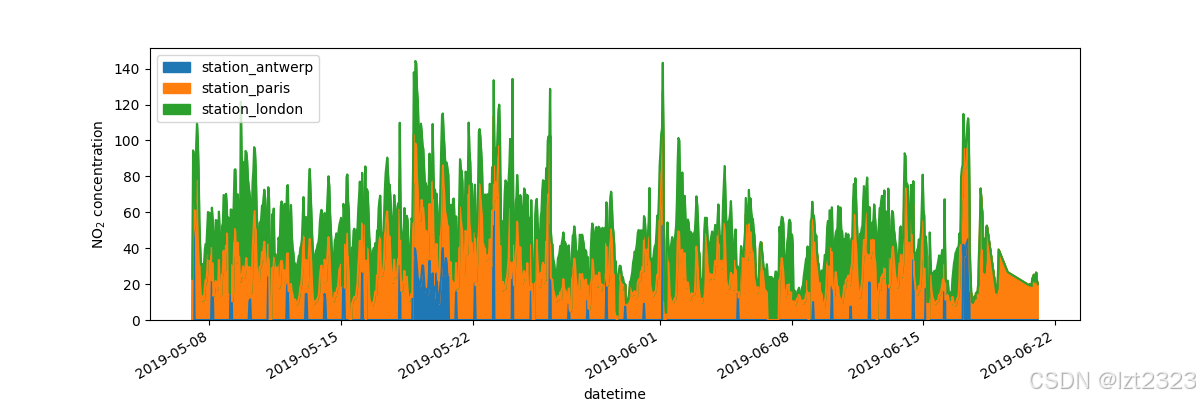
5. 创建新列
5.1 导入数据
import pandas as pd
# index_col=0 csv文件第一列将作为DataFrame的索引 parse_dates=True 将被选为索引的列(或自动识别的日期列)转换为日期时间格式,而不是保留为字符串。
air_quality = pd.read_csv("air_quality_no2.csv", index_col=0, parse_dates=True)
# 查看数据
air_quality.head()
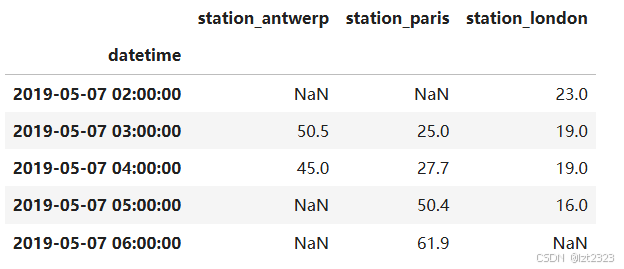
5.2 创建新列
# format: DataFrameObject["新列名"] = DataFrameObject["原列名"] + - * / value
air_quality["london_mg_per_cubic"] = air_quality["station_london"] * 1.882
air_quality.head()
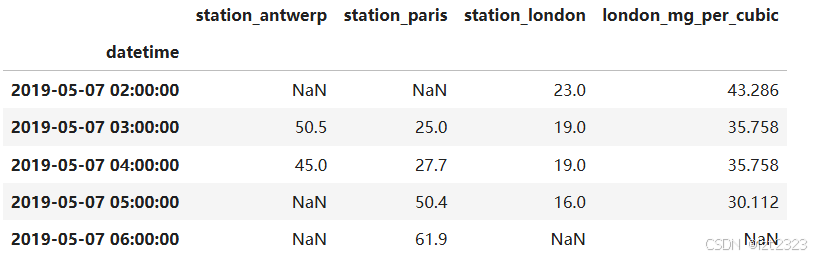
air_quality["ratio_paris_antwerp"] = (
air_quality["station_paris"] / air_quality["station_antwerp"]
)
air_quality.head()
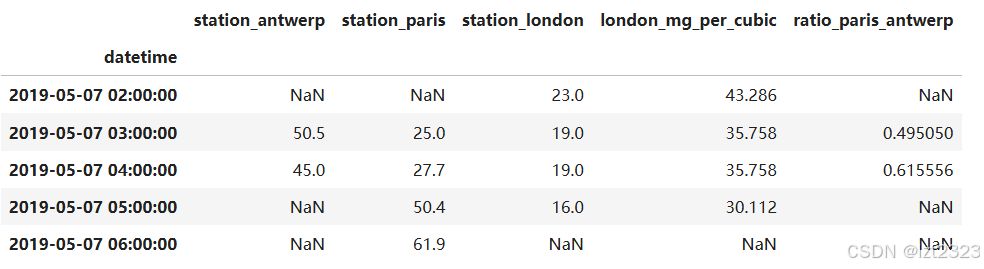
5.3 列名重命名
#使用 .rename(columns=)方法
#formated: DataFrameObject.rename(columns={字典}) 字典的键为原列名 值为新列名
air_quality_renamed = air_quality.rename(
columns={
"station_antwerp": "BETR801",
"station_paris": "FR04014",
"station_london": "London Westminster",
}
)
air_quality_renamed.head()
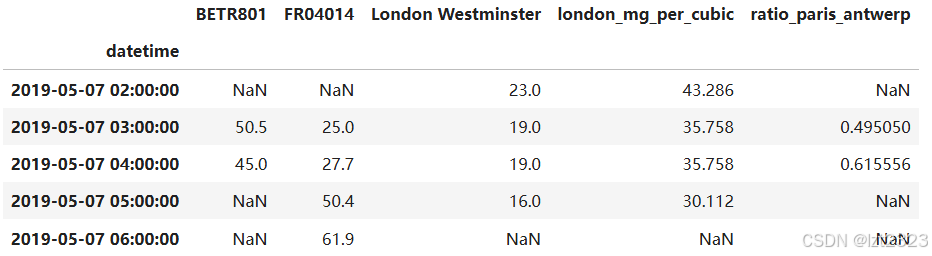
6. 汇总统计
6.1 导入数据
import pandas as pd
titanic = pd.read_csv("titanic.csv")
titanic.head()
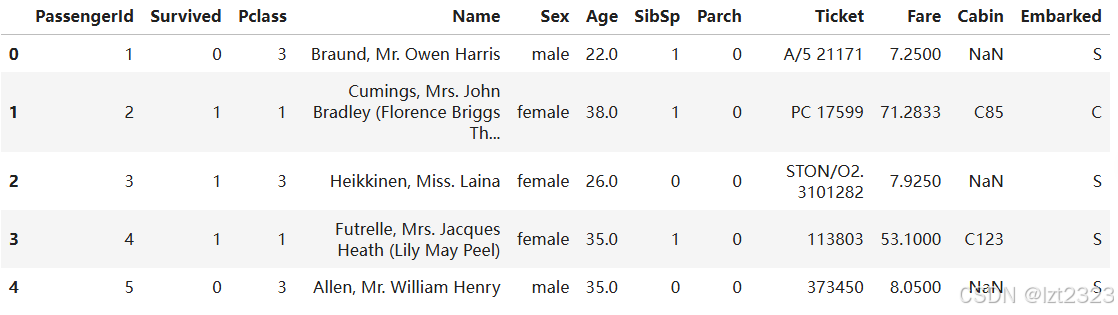
6.2 Series对象数据汇总
# 方法:.mean() .max() .min() .median() .count()
titanic["Age"].mean()
# np.float64(29.69911764705882)
6.3 DataFrame对象数据汇总
# 方法:.mean() .max() .min() .median() .count()
titanic[["Age", "Fare"]].median()
#Age 28.0000
#Fare 14.4542
#dtype: float64
titanic[["Age", "Fare"]].describe()
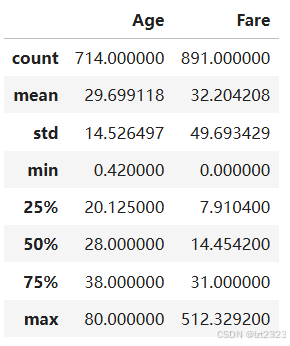
# 使用agg指定汇总参数
# format: DataFrame.agg(字典)
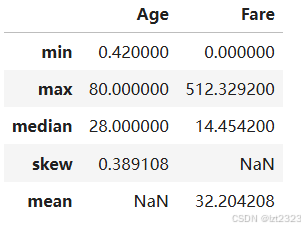
titanic.agg(
{
"Age": ["min", "max", "median", "skew"],
"Fare": ["min", "max", "median", "mean"]
}
)
6.4 分组
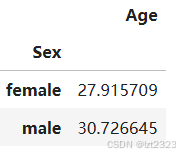
# 按照Sex的不同类别分组 并且取Age列的平均值
# format: DataFrame.groupby("列名").mean()
titanic[["Sex", "Age"]].groupby("Sex").mean()
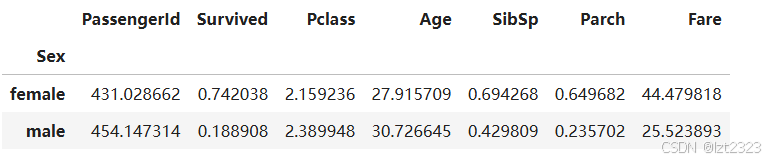
# 按照Sex的不同类别分组 并且取数值列的平均值 numeric_only=True 只计算数值类型的列
titanic.groupby("Sex").mean(numeric_only=True)
6.5 分组索引
#索引分组后Age列的平均值
titanic.groupby("Sex")["Age"].mean()
#Sex
#female 27.915709
#male 30.726645
#Name: Age, dtype: float64
#按照"Sex" "Pclass"列分组后 取"Fare"的平均值
titanic.groupby(["Sex", "Pclass"])["Fare"].mean()
#Sex Pclass
#female 1 106.125798
# 2 21.970121
# 3 16.118810
#male 1 67.226127
# 2 19.741782
# 3 12.661633
#Name: Fare, dtype: float64
6.6 统计数据
#使用.value_counts() 统计每个类别的数量
#format: SeriesObject.value_count()
titanic["Pclass"].value_counts()
#Pclass
#3 491
#1 216
#2 184
#Name: count, dtype: int64
#分组后统计
titanic.groupby("Pclass")["Pclass"].count()
#Pclass
#1 216
#2 184
#3 491
#Name: Pclass, dtype: int64
7. 重塑表格布局
7.1 导入数据
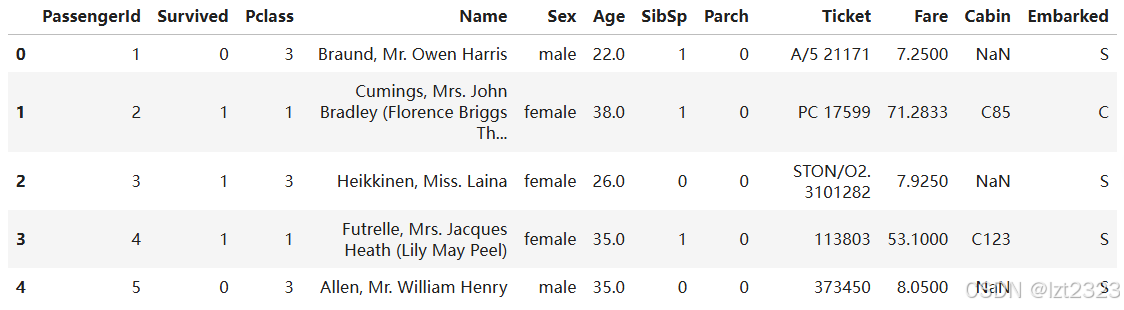
import pandas as pd
titanic = pd.read_csv("titanic.csv")
titanic.head()
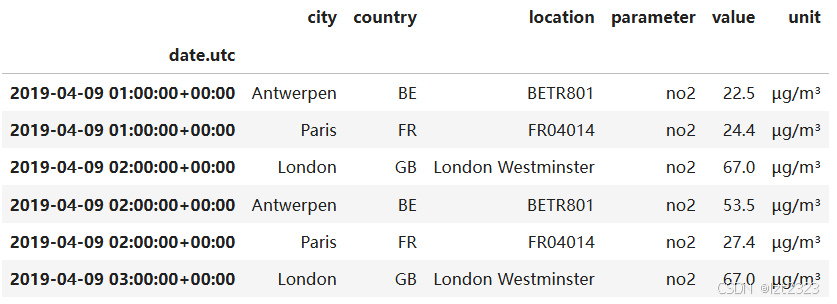
air_quality = pd.read_csv(
"air_quality_long.csv", index_col="date.utc", parse_dates=True
)
air_quality.head()
7.2 排序
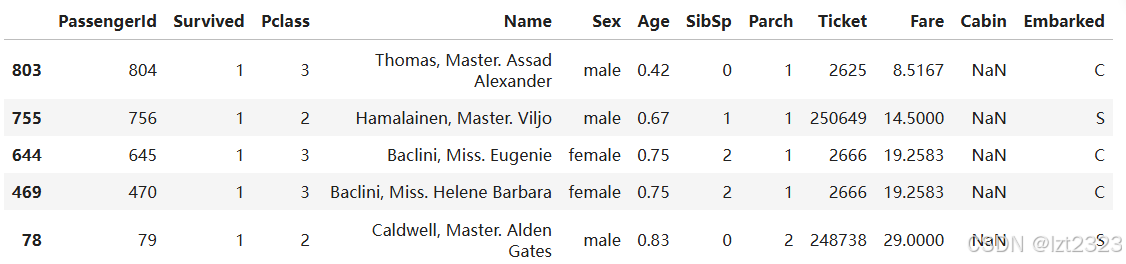
# 方法.sort_values(by="列名") 按照"Age"升序排列
titanic.sort_values(by="Age").head()
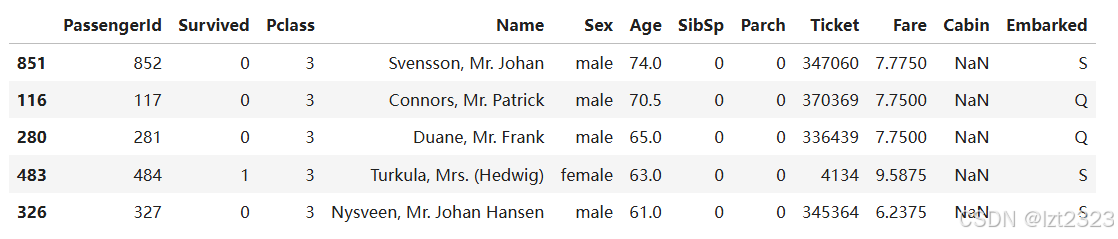
# 按照"Pclass" "Age"降序排列
titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head()
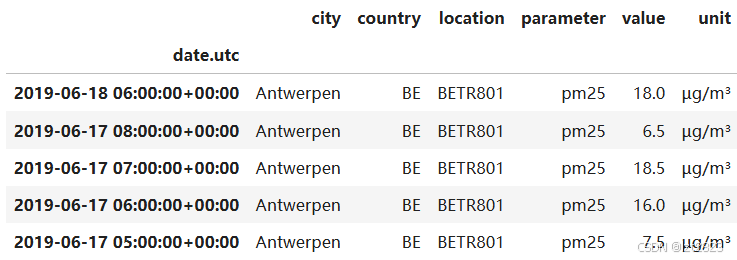
# 筛选"parameter"=="no2"的行
no2 = air_quality[air_quality["parameter"] == "no2"]
# 按照索引排序 并且按照location分组 每组取前面两行
no2_subset = no2.sort_index().groupby(["location"]).head(2)
# 展示数据
no2_subset
7.3 数据重塑
# 重新构造 标题为"location"列各个类别 值为"value"对应的数值
no2_subset.pivot(columns="location", values="value")
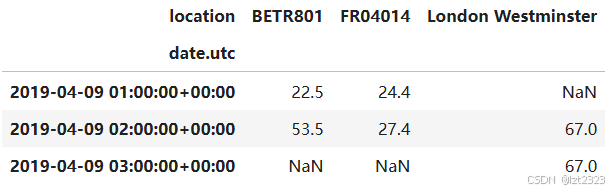
no2.head()
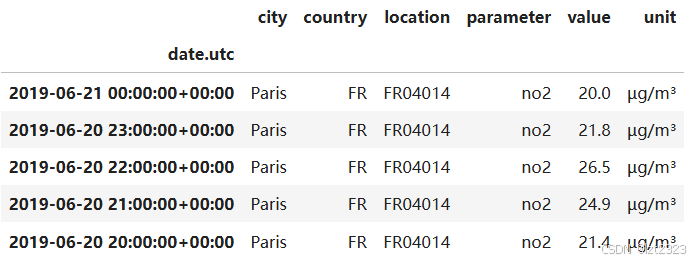
# 重新构造一个DataFrame 重新构造 标题为"location"列各个类别 值为"value"对应的数值
# 使用.plot()方法画图 x为时间轴索引 y为各列
no2.pivot(columns="location", values="value").plot()
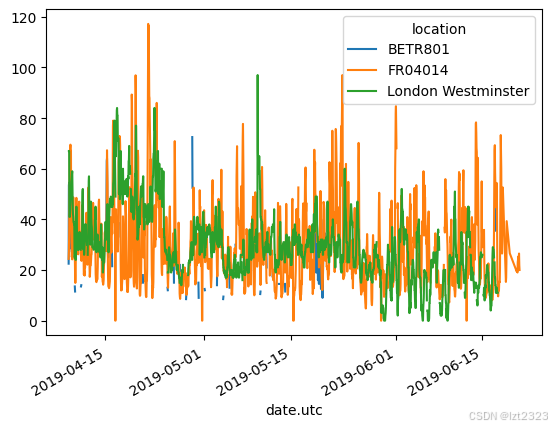
7.4 数据重塑 聚合
# .pivot_table()方法对重新塑造的数据聚合
# 索引列"location" 标题行"parameter" 值"value"列 聚合方法"mean"求平均
air_quality.pivot_table(
values="value", index="location", columns="parameter", aggfunc="mean"
)
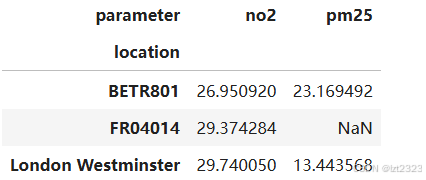
air_quality.pivot_table(
values="value",
index="location",
columns="parameter",
aggfunc="mean",
margins=True,
)
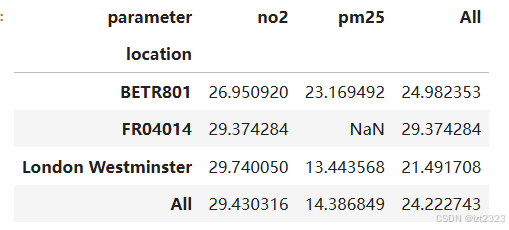
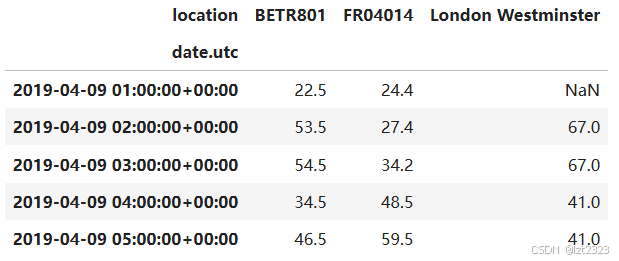
7.5 添加新索引
no2_pivoted = no2.pivot(columns="location", values="value")
no2_pivoted.head()
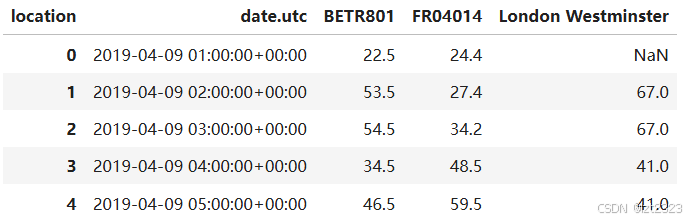
# 使用.reset_index() 添加新索引
no2_pivoted = no2.pivot(columns="location", values="value").reset_index()
no2_pivoted.head()
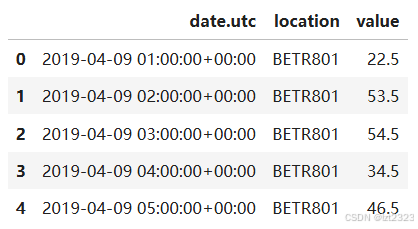
7.6 将宽表变长表
# 使用.melt()方法 该方法会将 id_vars 中未提及的所有列一起熔化为两列:一列包含列标题名称,一列包含值本身。默认情况下,后一列取"value"名
no_2 = no2_pivoted.melt(id_vars="date.utc")
no_2.head()
# 指定 date.utc 列作为标识变量。这意味着在转换过程中,date.utc 列的值将保留,不会被改变
# value_vars=["BETR801", "FR04014", "London Westminster"]:指定需要变形的值变量。这些列(BETR801、FR04014 和 London Westminster)的值将被收集到新列中
# value_name="NO_2":指定新列的名称为 NO_2,该列将包含从 value_vars 列中收集到的所有数值
# var_name="id_location":指定新列的名称为 id_location,该列将包含原来被变形的列名(即 BETR801、FR04014 和 London Westminster)的名称
no_2 = no2_pivoted.melt(
id_vars="date.utc",
value_vars=["BETR801", "FR04014", "London Westminster"],
value_name="NO_2",
var_name="id_location"
)
no_2.head()
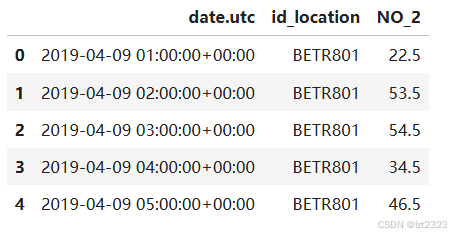
8. 合并多个表
8.1 导入数据
import pandas as pd
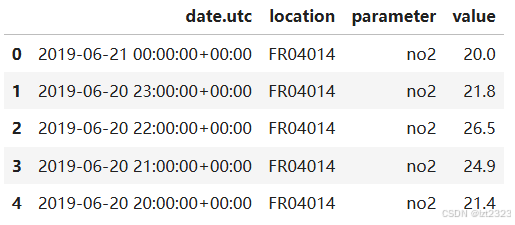
air_quality_no2 = pd.read_csv("air_quality_no2_long.csv",
parse_dates=True)
air_quality_no2 = air_quality_no2[["date.utc", "location",
"parameter", "value"]
air_quality_no2.head()
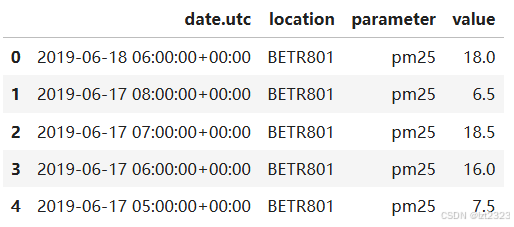
air_quality_pm25 = pd.read_csv("air_quality_pm25_long.csv",
parse_dates=True)
air_quality_pm25 = air_quality_pm25[["date.utc", "location",
"parameter", "value"]]
air_quality_pm25.head()
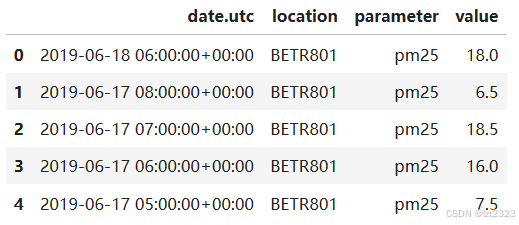
8.2 拼接
# 使用pd.concat()方法拼接两个表
# 参数1 拼接列表 参数2 沿哪个轴
air_quality = pd.concat([air_quality_pm25, air_quality_no2], axis=0)
air_quality.head()
# 通过 keys 参数提供了一个方便的解决方案,添加了一个额外的(分层的)行索引
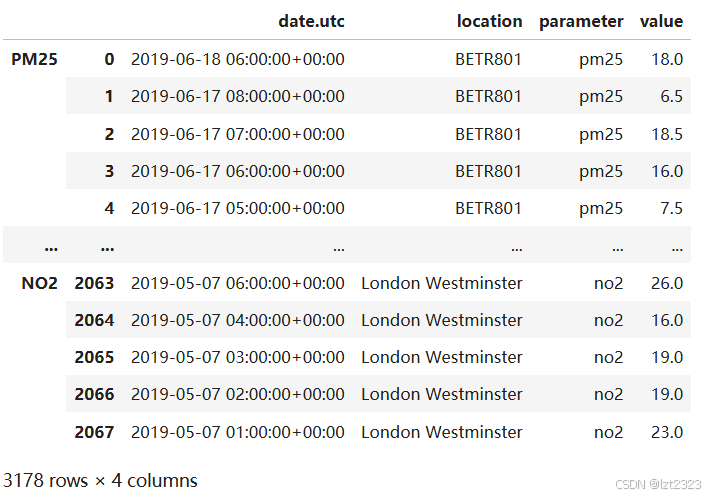
air_quality_ = pd.concat([air_quality_pm25, air_quality_no2], keys=["PM25", "NO2"])
air_quality_
9. 处理时间序列数据
9.1 导入数据
import pandas as pd
import matplotlib.pyplot as plt
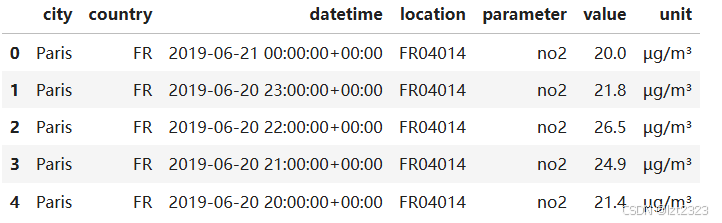
air_quality = pd.read_csv("air_quality_no2_long.csv")
air_quality = air_quality.rename(columns={"date.utc": "datetime"})
air_quality.head()
# air_quality.city:通过 属性 的方式访问列。这种方式更简洁,但仅适用于列名符合变量命名规则的情况(例如,列名不能包含空格、特殊字符,且不能以数字开头)
# air_quality["city"]:通过 索引 的方式访问列。该方法通用且更可靠,适用于所有列名
air_quality.city.unique()
# array(['Paris', 'Antwerpen', 'London'], dtype=object)
9.2 时间字符串to时间数据
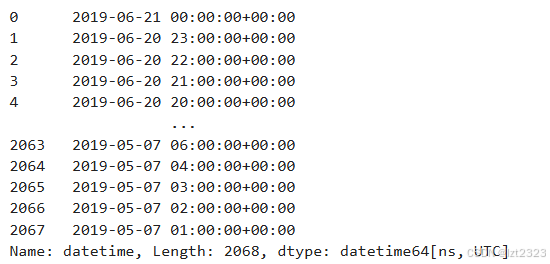
# 通过应用 to_datetime 函数,pandas 会解释字符串并将其转换为日期时间(即 datetime64[ns, UTC])对象
air_quality["datetime"] = pd.to_datetime(air_quality["datetime"])
air_quality["datetime"]air_quality["datetime"]
9.3 日期时间常用方法
air_quality["datetime"].min(), air_quality["datetime"].max()
#(Timestamp('2019-05-07 01:00:00+0000', tz='UTC'),
# Timestamp('2019-06-21 00:00:00+0000', tz='UTC'))
air_quality["datetime"].max() - air_quality["datetime"].min()
# Timedelta('44 days 23:00:00')
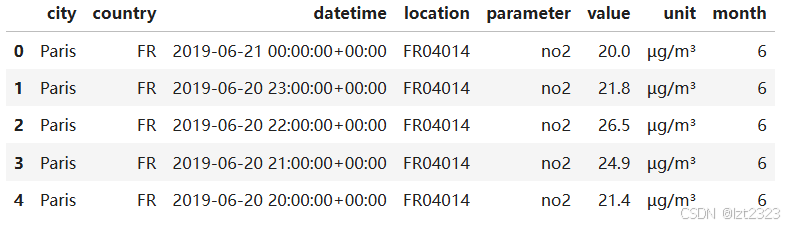
# 通过使用 Timestamp 对象进行日期,pandas 提供了许多与时间相关的属性。例如,月份,但也包括年份、季度,...所有这些属性都可以由 dt 访问器访问。
air_quality["month"] = air_quality["datetime"].dt.month
air_quality.head()
# 按照星期日 "location"分组 求"value"列平均值
air_quality.groupby(
[air_quality["datetime"].dt.weekday, "location"])["value"].mean()
9.4 根据日期时间画图
# plt.subplots():创建一个图形(figure)和一个或多个子图(axes)。在这里,它创建了一个包含一个子图的图形
# figsize=(12, 4):设置图形的大小,宽度为 12 英寸,高度为 4 英寸。这个参数控制了图表的显示尺寸
fig, axs = plt.subplots(figsize=(12, 4))
# air_quality["datetime"].dt.hour:从 datetime 列中提取小时信息(.dt.hour),按小时对数据进行分组
# ["value"]:指定要对其计算均值的列为 value 列
# .mean():计算每小时的 value 列的平均值
# .plot(kind='bar', rot=0, ax=axs)
# kind='bar':指定图表类型为柱状图(bar chart)
# rot=0:设置 x 轴标签的旋转角度为 0,即标签保持水平显示
# ax=axs:指定绘图的轴(axes)对象为 axs,即将图表绘制在之前创建的 axs 子图中
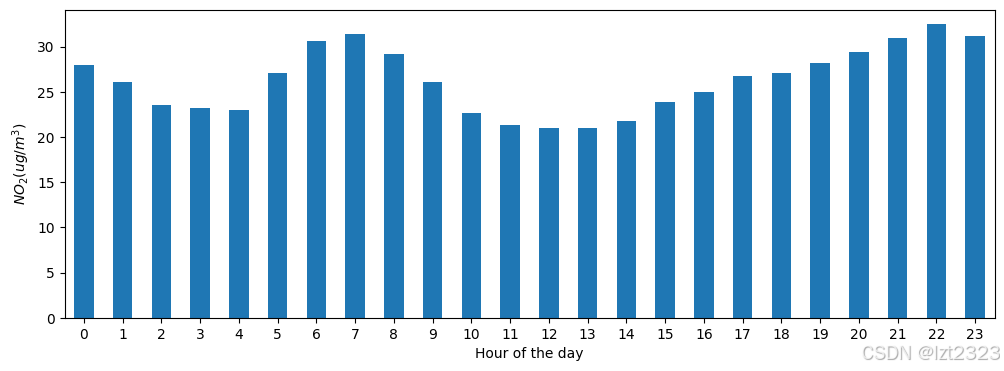
air_quality.groupby(air_quality["datetime"].dt.hour)["value"].mean().plot(
kind='bar', rot=0, ax=axs
)
# 设置 x 轴的标签
plt.xlabel("Hour of the day")
# 设置 y 轴的标签
plt.ylabel("$NO_2 (ug/m^3)$")
# 展示
plt.show()
9.5 日期时间索引
# 通过.pivot方法重塑 设置索引为datetime
no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
no_2.head()
# 索引年 索引周
no_2.index.year, no_2.index.weekday
#(Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
# ...
# 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
# dtype='int32', name='datetime', length=1033),
#Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# ...
# 3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
# dtype='int32', name='datetime', length=1033))
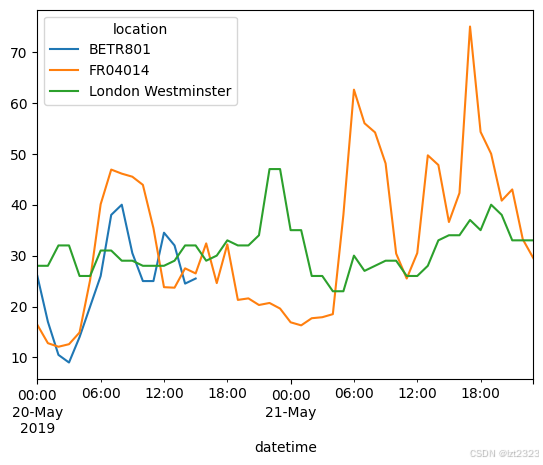
# 索引切片绘图
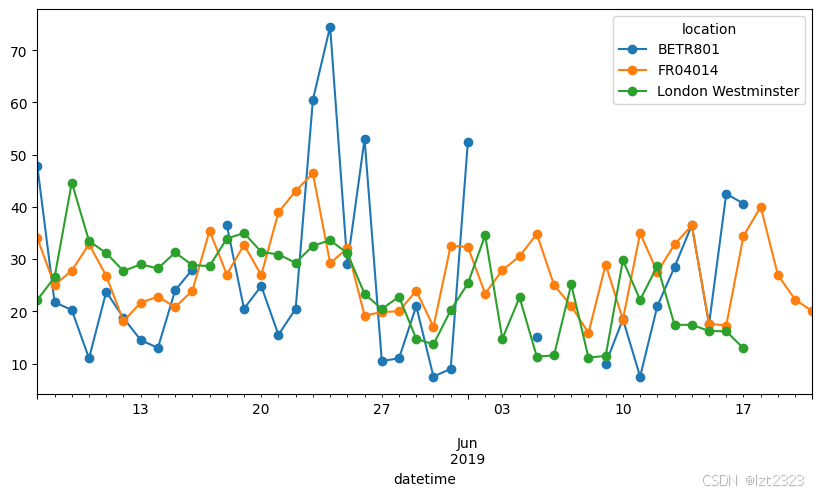
no_2["2019-05-20": "2019-05-21"].plot()
9.6 按照时间频率分组聚合
# resample 是 Pandas 中用于重采样时间序列数据的方法
# "ME" 表示重采样的频率。"ME" 代表 月末(Month End),即按每个月的最后一天作为时间间隔
# 这一步将 no_2 中的数据重新按月进行分组,每个组包含该月内的数据
# 在分组完成后,.max() 会对每组数据(即每个月的数据)取最大值
# monthly_max 是结果保存的变量名称。它存储的是 no_2 DataFrame 按月重采样后的最大值
monthly_max = no_2.resample("ME").max()
monthly_max

# monthly_max.index.freq 用于查看 monthly_max DataFrame 索引的频率属性
monthly_max.index.freq
# <MonthEnd>
# no_2.resample("D").mean().plot(style="-o", figsize=(10, 5)) 这段代码用于对 no_2 数据按天进行重采样,计算每天的均值,并以折线图的方式绘制结果
# style="-o":指定绘图的样式 figsize=(10, 5):设置图表的大小,宽度为 10 英寸,高度为 5 英寸
no_2.resample("D").mean().plot(style="-o", figsize=(10, 5))
10. 操作文本数据
10.1 导入数据
import pandas as pd
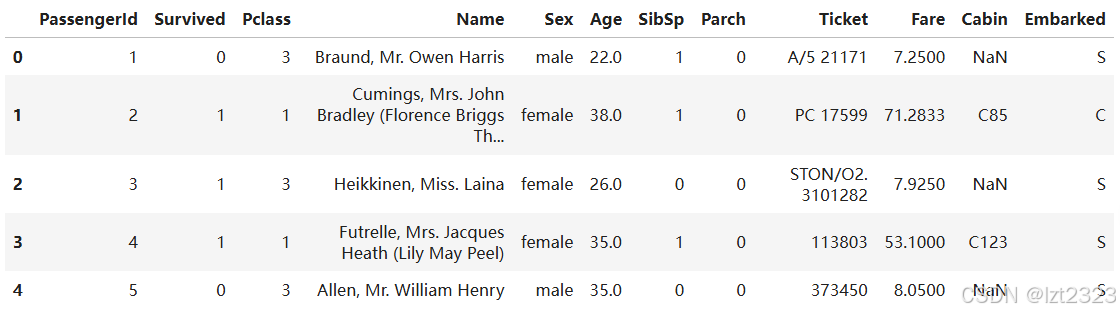
titanic = pd.read_csv("titanic.csv")
titanic.head()
10.2 字符串基本操作
# 要将 Name 列中的每个字符串设置为小写,请选择 Name 列,添加 str 访问器并应用 lower 方法
titanic["Name"].str.lower()
#0 braund, mr. owen harris
#1 cumings, mrs. john bradley (florence briggs th...
#2 heikkinen, miss. laina
#3 futrelle, mrs. jacques heath (lily may peel)
#4 allen, mr. william henry
# ...
#886 montvila, rev. juozas
#887 graham, miss. margaret edith
#888 johnston, miss. catherine helen "carrie"
#889 behr, mr. karl howell
#890 dooley, mr. patrick
#Name: Name, Length: 891, dtype: object
# "Name"列 在 , 分离
titanic["Name"].str.split(",")
#0 [Braund, Mr. Owen Harris]
#1 [Cumings, Mrs. John Bradley (Florence Briggs ...
#2 [Heikkinen, Miss. Laina]
#3 [Futrelle, Mrs. Jacques Heath (Lily May Peel)]
#4 [Allen, Mr. William Henry]
# ...
#886 [Montvila, Rev. Juozas]
#887 [Graham, Miss. Margaret Edith]
#888 [Johnston, Miss. Catherine Helen "Carrie"]
#889 [Behr, Mr. Karl Howell]
#890 [Dooley, Mr. Patrick]
#Name: Name, Length: 891, dtype: object
# 取分类后列表的第一位元素
titanic["Surname"] = titanic["Name"].str.split(",").str.get(0)
#0 Braund
#1 Cumings
#2 Heikkinen
#3 Futrelle
#4 Allen
# ...
#886 Montvila
#887 Graham
#888 Johnston
#889 Behr
#890 Dooley
#Name: Surname, Length: 891, dtype: object
#筛选"Name"列中字符串里面有没有"Countess"字符串
titanic["Name"].str.contains("Countess")
#0 False
#1 False
#2 False
#3 False
#4 False
# ...
#886 False
#887 False
#888 False
#889 False
#890 False
#Name: Name, Length: 891, dtype: bool
#查看筛选出来的行
titanic[titanic["Name"].str.contains("Countess")]

# 查看字符串长度
titanic["Name"].str.len()
#0 23
#1 51
#2 22
#3 44
#4 24
# ..
#886 21
#887 28
#888 40
#889 21
#890 19
#Name: Name, Length: 891, dtype: int64
# 找到 titanic DataFrame 中 Name 列中名字字符数最长的那一行的索引
titanic["Name"].str.len().idxmax()
# 307
# 找出那行名字
titanic.loc[titanic["Name"].str.len().idxmax(), "Name"]
# 字符串名称替换
titanic["Sex_short"] = titanic["Sex"].replace({"male": "M", "female": "F"})
titanic["Sex_short"]
#0 M
#1 F
#2 F
#3 F
#4 M
# ..
#886 M
#887 F
#888 F
#889 M
#890 M
#Name: Sex_short, Length: 891, dtype: object