文章目录
Log
2022.01.20开始新的一章
2022.01.21加油干,提高效率
2022.01.22争取明天拿下
2022.01.23好难,还要一天
2022.01.24今天弄完了
一、代价函数(Cost function)
- 主要内容:介绍一个学习算法,它能在给定训练集时为神经网络拟合参数。和之前学习的的大多数学习算法一样,先从拟合神经网络参数的代价函数开始讲起。
- 重点讲解神经网络在分类问题中的应用。
1. 符号的定义
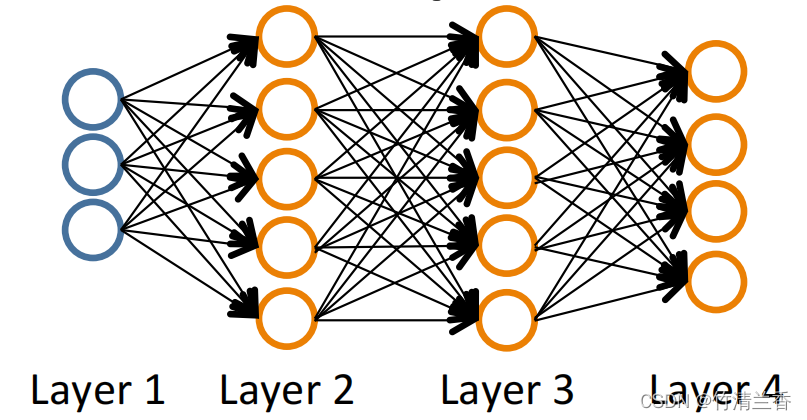
- 有类似上图的神经网络结构,以及如下训练集(有 m 组训练样本):
{ ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } \{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})\} {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))} - 定义如下符号:
L = t o t a l n o . o f l a y e r s i n n e t w o r k ( 总 层 数 ) s l = n o . o f u n i t s ( n o t c o u n t i n g b i a s u n i t ) i n l a y e r ( 一 层 中 不 含 偏 置 单 元 的 神 经 元 个 数 ) \begin{aligned} L = \ &total\ \ no.\ \ of\ \ layers\ \ in\ \ network(总层数)\\ s_l =\ &no.\ \ of\ \ units\ \ (not\ \ counting\ \ bias\ \ unit)\ \ in\ \ layer\ \ \\&(一层中不含偏置单元的神经元个数) \end{aligned} L= sl= total no. of layers in network(总层数)no. of units (not counting bias unit) in layer (一层中不含偏置单元的神经元个数) - 对于上图的例子,L = 4, s1 = 3, s2 = s3 = 5, s4 = 4。
- 考虑两种分类问题:
2. 二元分类(Binary classification)
- y = 0 或 1
- 1 个输出单元。
- hΘ(x) ∈ R (是一个实数)
- sL = 1
- K = 1 (类数,输出层的单元数目)
一般来说,分类个数和神经网络输出单元个数相同,以方便one-hot编码,故在二元分类中的 K 为 1 而不是 2。
3. 多元分类(Multi-class classification [K classes])
- y ∈ RK
- K 个输出单元。
- hΘ(x) ∈ RK(K 维向量)
- sL = K (K ≥ 3)
4. 代价函数
- 神经网络中使用的代价函数是逻辑回归中使用的代价函数的一般形式(如下),由于有不止一个逻辑回归输出单元,所以进一步得到含有 K 个输出单元的代价函数(下2):
L o g i s t i c r e g r e s s i o n : J ( θ ) = − 1 m [ ∑ i = 1 m ( y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 N e u r a l n e t w o r k : J ( Θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 K ( y k ( i ) l o g ( h Θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l o g ( 1 − h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j i ( l ) ) 2 h Θ ( x ) ∈ R K ( h Θ ( x ) ) i = i t h o u t p u t \begin{aligned} &Logistic\ \ regression:\\ &\qquad J(θ)=-\frac{1}{m}[\sum_{i=1}^m(y^{(i)}log(h_θ(x^{(i)}))+(1-y^{(i)})log(1-h_θ(x^{(i)}))]\\&\qquad\qquad\quad+\frac{λ}{2m}{\sum_{j=1}^nθ_j^2}\\ &Neural\ \ network:\\ &\qquad J(\Theta)=-\frac{1}{m}[\sum_{i=1}^m\sum_{k=1}^K(y^{(i)}_klog(h_\Theta(x^{(i)}))_k+(1-y^{(i)}_k)log(1-h_\Theta(x^{(i)}))_k)]\\&\qquad\qquad\quad+\frac{λ}{2m}{\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_l+1}(\Theta^{(l)}_{ji})^2}\\\ \\ &\quad h_\Theta(x)\in\R^K\quad (h_\Theta(x))_i = i^{th}\ output \end{aligned} Logistic regression:J(θ)=−m1[i=1∑m(y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2Neural network:J(Θ)=−m1[i=1∑mk=1∑K(yk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2hΘ(x)∈RK(hΘ(x))i=ith output - 第一处变化的求和项,主要是求 K 个输出单元的和;第二项则类似于逻辑回归中的正则化,不对偏差单元的项进行处理(对应下标为 0 的项)。
二、反向传播算法(Backpropagation algorithm)
1. 前向传播计算激活项
- 主要内容:介绍一个让代价函数最小化的算法。
J ( Θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 K ( y k ( i ) l o g ( h Θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l o g ( 1 − h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j i ( l ) ) 2 min Θ J ( Θ ) N e e d c o d e t o c o m p u t e : − J ( Θ ) − ∂ ∂ Θ i j ( l ) J ( Θ ) \begin{aligned} &J(\Theta)=-\frac{1}{m}[\sum_{i=1}^m\sum_{k=1}^K(y^{(i)}_klog(h_\Theta(x^{(i)}))_k+(1-y^{(i)}_k)log(1-h_\Theta(x^{(i)}))_k)]\\&\qquad\quad+\frac{λ}{2m}{\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_l+1}(\Theta^{(l)}_{ji})^2}\\\ \\ &\large{\min\limits_\Theta J(\Theta)}\\\ \\ &Need\ \ code\ \ to \ \ compute:\\ &\ \ -\ \ J(\Theta)\\ &\ \ -\ \ \frac{\partial}{\partial\Theta^{(l)}_{ij}}J(\Theta) \end{aligned} J(Θ)=−m1[i=1∑mk=1∑K(yk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2ΘminJ(Θ)Need code to compute: − J(Θ) − ∂Θij(l)∂J(Θ) - 重点关注偏导数的计算。
- 从只有一个训练样本的情况开始说起:
- 该样本记为 (x,y) ,计算的过程如下
G i v e n o n e t r a i n i n g e x a m p l e ( x , y ) : F o r w a r d p r o p a g a t i o n : a ( 1 ) = x z ( 2 ) = Θ ( 1 ) a ( 1 ) a ( 2 ) = g ( z ( 2 ) ) ( a d d a 0 ( 2 ) ) z ( 3 ) = Θ ( 2 ) a ( 2 ) a ( 3 ) = g ( z ( 3 ) ) ( a d d a 0 ( 3 ) ) z ( 4 ) = Θ ( 3 ) a ( 3 ) a ( 4 ) = h Θ ( x ) = g ( z ( 4 ) ) \begin{aligned} &Given\ \ one\ \ training\ \ example\ \ (x,y):\\\ \\ &Forward\ \ propagation:\\ &\qquad a^{(1)}=x\\ &\qquad z^{(2)}=\Theta^{(1)}a^{(1)}\\ &\qquad a^{(2)}=g(z^{(2)})\ \ (add\ a^{(2)}_0)\\ &\qquad z^{(3)}=\Theta^{(2)}a^{(2)}\\ &\qquad a^{(3)}=g(z^{(3)})\ \ (add\ a^{(3)}_0)\\ &\qquad z^{(4)}=\Theta^{(3)}a^{(3)}\\ &\qquad a^{(4)}=h_\Theta(x)=g(z^{(4)})\\ \end{aligned} Given one training example (x,y):Forward propagation:a(1)=xz(2)=Θ(1)a(1)a(2)=g(z(2)) (add a0(2))z(3)=Θ(2)a(2)a(3)=g(z(3)) (add a0(3))z(4)=Θ(3)a(3)a(4)=hΘ(x)=g(z(4))
- 这里用了三次前向传播,实现了了把前向传播向量化,使得可以计算神经网络结构里的每一个神经元的激活值。
- 接下来,将采用反向传播(Backpropagation ) 的算法来计算导数项。
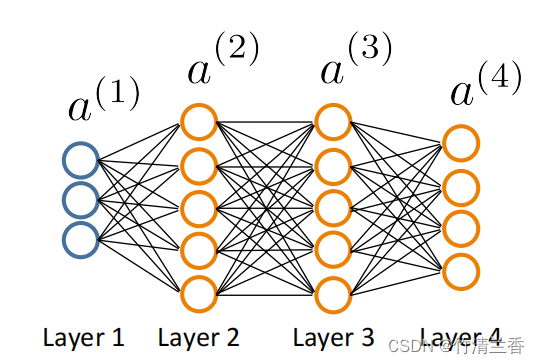
2. 反向传播计算导数项
①只有一个训练样本时
- 反向传播算法从直观上来说就是对每一个结点计算下面这一项:
δ j ( l ) = “ e r r o r ” o f n o d e j i n l a y e r l δ^{(l)}_j=“error”\ \ of\ \ node\ \ j\ \ in\ \ layer\ \ l δj(l)=“error” of node j in layer l - δ j l 代表了第 l 层第 j 个结点的误差。
δ j ( 4 ) = a j ( 4 ) − y j = ( h Θ ( x ) ) j − y j 看 成 向 量 可 以 写 成 如 下 形 式 δ ( 4 ) = a ( 4 ) − y δ ( 3 ) = ( Θ ( 3 ) ) T δ ( 4 ) . ∗ g ′ ( z ( 3 ) ) δ ( 2 ) = ( Θ ( 2 ) ) T δ ( 3 ) . ∗ g ′ ( z ( 2 ) ) . ∗ : 点 乘 , 向 量 元 素 之 间 对 于 乘 法 的 操 作 g ′ ( z ( 3 ) ) : 在 输 入 为 z ( 3 ) 时 对 激 活 函 数 g 求 的 导 数 计 算 后 得 到 : a ( 3 ) . ∗ ( 1 − a ( 3 ) ) a ( 3 ) 为 激 活 向 量 、 1 是 以 1 为 元 素 的 向 量 δ ( 1 ) : 不 存 在 该 项 , 因 为 第 一 次 对 应 输 入 层 , 表 示 在 训 练 集 中 观 察 到 的 , 不 存 在 误 差 。 \begin{aligned} &δ^{(4)}_j=a^{(4)}_j-y_j=(h_\Theta(x))_j-y_j\\ &看成向量可以写成如下形式\\ &δ^{(4)}=a^{(4)}-y\\\ \\ &δ^{(3)}=(\Theta^{(3)})^Tδ^{(4)}.*g'(z^{(3)})\\ &δ^{(2)}=(\Theta^{(2)})^Tδ^{(3)}.*g'(z^{(2)})\\\ \\ &.*:点乘,向量元素之间对于乘法的操作\\ &g'(z^{(3)}):在输入为\ z^{(3)}\ 时对激活函数\ g\ 求的导数\\ &\qquad\qquad 计算后得到:a^{(3)}.*(1-a^{(3)})\\ &\qquad\qquad a^{(3)}为激活向量、1\ 是以\ 1\ 为元素的向量\\ &δ^{(1)}:不存在该项,因为第一次对应输入层,表示在训练集中观察到的,不存在误差。 \end{aligned} δj(4)=aj(4)−yj=(hΘ(x))j−yj看成向量可以写成如下形式δ(4)=a(4)−yδ(3)=(Θ(3))Tδ(4).∗g′(z(3))δ(2)=(Θ(2))Tδ(3).∗g′(z(2)).∗:点乘,向量元素之间对于乘法的操作g′(z(3)):在输入为 z(3) 时对激活函数 g 求的导数计算后得到:a(3).∗(1−a(3))a(3)为激活向量、1 是以 1 为元素的向量δ(1):不存在该项,因为第一次对应输入层,表示在训练集中观察到的,不存在误差。 - 反向传播法这个名字源于我们从输出层开始计算 δ 项,然后返回到上一层计算第三隐藏层的 δ 项,再往前一步来计算 δ(2)。类似于把输出层的误差反向传播给了第三层,然后再传到第二层。
- 该过程的推导十分麻烦,如果不是特别严谨的情况下,可以得到以下式子(其中忽略了正则化):
∂ ∂ Θ i j ( l ) J ( Θ ) = a j ( l ) δ i ( l + 1 ) ( i g n o r i n g λ ; i f λ = 0 ) \frac{\partial}{\partial\Theta^{(l)}_{ij}}J(\Theta)=a^{(l)}_jδ^{(l+1)}_i\qquad(ignoring\ \ \lambda;if\ \ \lambda=0) ∂Θij(l)∂J(Θ)=aj(l)δi(l+1)(ignoring λ;if λ=0) - 下面把所有的内容整合在一起,介绍当有一个非常大的样本时,如何实现反向传播算法来计算这些参数的偏导数。
②当有多个训练样本时
- 假设有 m 个样本的训练集,同时设定Δ:
T r a n i n g s e t : { ( x ( 1 ) , y ( 1 ) ) , . . . , ( x ( m ) , y ( m ) ) } S e t Δ i j ( l ) = 0 ( f o r a l l l , i , j ) . ( 用 于 计 算 偏 导 项 ∂ ∂ Θ i j ( l ) J ( Θ ) ) ( d e l t a 大 写 : Δ 小 写 δ ) \begin{aligned} &Traning\ \ set:\{(x^{(1)},y^{(1)}),...,(x^{(m)},y^{(m)})\}\\ &Set\ \ \Delta^{(l)}_{ij}=0\ \ (for\ \ all\ \ l,\ i,\ j).\qquad(用于计算偏导项\frac{\partial}{\partial\Theta^{(l)}_{ij}}J(\Theta))\\ &(delta\ 大写:\Delta\ 小写\delta) \end{aligned} Traning set:{(x(1),y(1)),...,(x(m),y(m))}Set Δij(l)=0 (for all l, i, j).(用于计算偏导项∂Θij(l)∂J(Θ))(delta 大写:Δ 小写δ) - 接下来将遍历训练集
F o r i = 1 t o m S e t a ( 1 ) = x ( i ) P e r f o r m f o r w a r d p r o p a g a t i o n t o c o m p u t e a ( 1 ) f o r l = 2 , 3 , . . . , L U s i n g y ( i ) , c o m p u t e δ ( L ) = a ( L ) − y ( i ) C o m p u t e δ ( L − 1 ) , δ ( L − 2 ) , . . . , δ ( 2 ) Δ i j ( l ) : = Δ i j ( l ) + a j ( l ) δ i ( l + 1 ) 向 量 化 形 式 : Δ ( l ) : = Δ ( l ) + δ ( l + 1 ) ( a ( l ) ) T \begin{aligned} &For\ \ i=1\ \ to\ \ m\\ &\qquad Set\ \ a^{(1)}=x^{(i)}\\ &\qquad Perform\ \ forward\ \ propagation\ \ to\ \ compute\ \ a^{(1)}\ \ for\ \ l =2,3,...,L\\ &\qquad Using\ \ y^{(i)},\ compute\ \ \delta^{(L)}=a^{(L)}-y^{(i)}\\ &\qquad Compute\ \ \delta^{(L-1)},\delta^{(L-2)},...,\delta^{(2)}\\ &\qquad \Delta^{(l)}_{ij}:=\Delta^{(l)}_{ij}+a^{(l)}_jδ^{(l+1)}_i\\ &\qquad 向量化形式:\Delta^{(l)}:=\Delta^{(l)}+δ^{(l+1)}(a^{(l)})^T\\ \end{aligned} For i=1 to mSet a(1)=x(i)Perform forward propagation to compute a(1) for l=2,3,...,LUsing y(i), compute δ(L)=a(L)−y(i)Compute δ(L−1),δ(L−2),...,δ(2)Δij(l):=Δij(l)+aj(l)δi(l+1)向量化形式:Δ(l):=Δ(l)+δ(l+1)(a(l))T - 对于 i 的每一次遍历,取训练样本 (x(i),y(i))
- 首先设定输入层的激活函数 a(i),就是第 i 个训练样本的输入值 x(i)。
- 接下来,运用正向传播来计算第二层的激活值,然后是第三层,第四层,直到最后一层 L 层。
- 接下来用样本的输出值来计算输出值所对应的误差 δ(L),就是假设的输出值减去目标输出。
- 接下来,运用反向传播算法来计算 δ(L-1) , δ(L-2) 一直到 δ(2)(再次强调没有 δ(1) 这一项,因为不需要对输入层考虑误差项)。
- 最后用 Δ 来积累在前面写好的偏导数项。
- 最后,跳出循环计算下面的式子:
D i j ( l ) : = 1 m Δ i j ( l ) + λ Θ i j ( l ) i f j ≠ 0 D i j ( l ) : = 1 m Δ i j ( l ) i f j = 0 ( 对 应 偏 差 项 ) \begin{aligned} &D^{(l)}_{ij}:=\frac{1}{m}\Delta^{(l)}_{ij}+\lambda\Theta^{(l)}_{ij}\qquad if\ \ j\ne0\\ &D^{(l)}_{ij}:=\frac{1}{m}\Delta^{(l)}_{ij}\qquad\qquad\ \quad if\ \ j=0(对应偏差项)\\ \end{aligned} Dij(l):=m1Δij(l)+λΘij(l)if j=0Dij(l):=m1Δij(l) if j=0(对应偏差项) - 计算出了所有的 D 项之后,可以发现它正好就是代价函数关于每个参数的偏导数,可以使用梯度下降或者其他高级优化算法。
∂ ∂ Θ i j ( l ) J ( Θ ) = D i j ( l ) \frac{\partial}{\partial\Theta^{(l)}_{ij}}J(\Theta)=D^{(l)}_{ij} ∂Θij(l)∂J(Θ)=Dij(l)
三、反向传播示例(Backpropagation intuition)
- 主要内容:重点介绍一下反向传播的一些固定步骤,更直观地展示这些固定的步骤在做什么以及算法的合理性。
1. 前向传播的过程
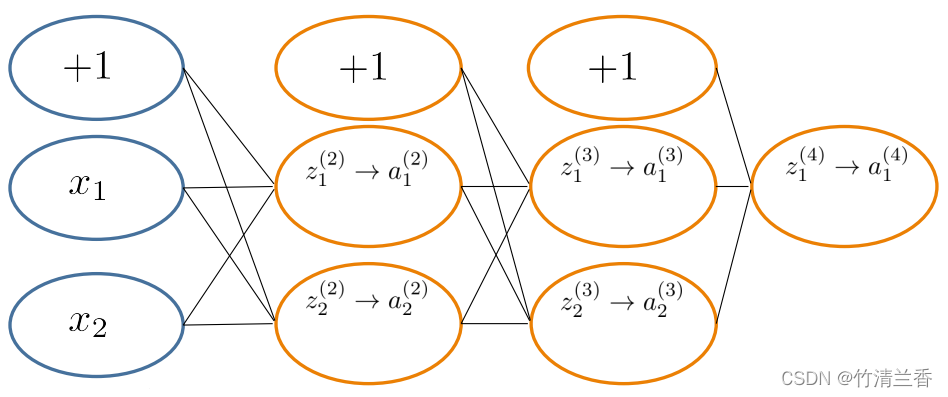
-
以 z1(3) 的计算为例:
z 1 ( 3 ) = Θ 10 ( 2 ) × 1 + Θ 11 ( 2 ) × a 1 ( 2 ) + Θ 12 ( 2 ) × a 2 ( 2 ) z^{(3)}_1=\Theta^{(2)}_{10}\times 1+\Theta^{(2)}_{11}\times a_1^{(2)}+\Theta^{(2)}_{12}\times a_2^{(2)} z1(3)=Θ10(2)×1+Θ11(2)×a1(2)+Θ12(2)×a2(2) -
反向传播的过程实际上和前向传播相似,只是方向不同。
-
对于只有一个输出单元的情况,对应的代价函数如下:
J ( Θ ) = − 1 m [ ∑ i = 1 m ( y ( i ) l o g ( h Θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h Θ ( x ( i ) ) ) ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j i ( l ) ) 2 \begin{aligned} &J(\Theta)=-\frac{1}{m}[\sum_{i=1}^m(y^{(i)}log(h_\Theta(x^{(i)}))+(1-y^{(i)})log(1-h_\Theta(x^{(i)})))]\\&\qquad\quad+\frac{λ}{2m}{\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_l+1}(\Theta^{(l)}_{ji})^2} \end{aligned} J(Θ)=−m1[i=1∑m(y(i)log(hΘ(x(i)))+(1−y(i))log(1−hΘ(x(i))))]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2 -
同一组样本中,同时使用了前向传播和反向传播算法。关注只有一个输出单元的情况((x(i),y(i)),其中 x(i) 为实数),同时忽略正则化(λ = 0),此时以上代价函数表达式中的最后一项就没有了。
-
观察括号中的求和项,发现代价函数对应第 i 个训练样本,即代价函数对应的训练样本 (x(i),y(i)),是由下面的表达式给出的:
c o s t ( i ) = y ( i ) l o g h Θ ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h Θ ( x ( i ) ) ) \begin{aligned} cost(i)=y^{(i)}log\ h_\Theta(x^{(i)})+(1-y^{(i)})log(1-h_\Theta(x^{(i)})) \end{aligned} cost(i)=y(i)log hΘ(x(i))+(1−y(i))log(1−hΘ(x(i))) -
这个代价函数起到了一个类似方差的作用,也可以把这个表达式近似地当成是神经网络输出值与实际值的方差:
c o s t ( i ) ≈ ( h Θ ( x ( i ) ) − y ( i ) ) 2 \begin{aligned} cost(i)\approx(h_\Theta(x^{(i)})-y^{(i)})^2 \end{aligned} cost(i)≈(hΘ(x(i))−y(i))2 -
就像逻辑回归中,实际中会偏向于选择比较复杂的带对数形式的代价函数,但是为了方便理解,可以把这个代价函数看做是某种方差函数,因此 cost(i) 表示了神经网络预测样本值的准确程度,也就是网络的输出值和实际观测值 y(i) 的接近程度。
2. 反向传播的过程
-
一种直观的理解是:反向传播算法就是在计算这些 δ 项,可以把它看做是在第 l 层中,第 j 个单元中得到的激活项的“误差”。
-
δ 项实际上是代价函数 cost(i) 关于 zj(l) 的偏导数,也就是计算出的 z 项的加权和,或者说代价函数关于 z 项的偏导数。具体来说,这个代价函数是一个关于标签 y 和神经网络中 h(x) 的输出值的函数。
-
如果在神经网络的内部稍微把 zj(l) 改一下,就会影响到神经网络中 y(i)、hΘ(x(i)) 的值,最终将改变代价函数的值。
δ j ( l ) = “error” of cost for a j ( l ) (unit j in layer l ). Formally, δ j ( l ) = ∂ ∂ z j ( l ) c o s t ( i ) (for j ≥ 0 ) , where c o s t ( i ) = y ( i ) l o g h Θ ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h Θ ( x ( i ) ) ) \begin{aligned} &\delta^{(l)}_j=\textbf{“error”\ \ of\ \ cost\ \ for\ \ }a^{(l)}_j\ \ \textbf{(unit\ \ }j\ \ \textbf{in\ \ layer}\ \ l\textbf{).}\\ &\textbf{Formally,}\ \ \delta^{(l)}_j=\frac{\partial}{\partial z^{(l)}_j}cost(i)\quad \textbf{(for\ \ }j\ge0),\textbf{where}\\ &cost(i)=y^{(i)}log\ h_\Theta(x^{(i)})+(1-y^{(i)})log(1-h_\Theta(x^{(i)})) \end{aligned} δj(l)=“error” of cost for aj(l) (unit j in layer l).Formally, δj(l)=∂zj(l)∂cost(i)(for j≥0),wherecost(i)=y(i)log hΘ(x(i))+(1−y(i))log(1−hΘ(x(i))) -
这些 δ 项实际上是代价函数关于这些所计算出的中间项的偏导数,他们衡量的是为了影响这些中间值,想要改变神经网络中的权重的程度,进而影响整个神经网络的输出 h(x),并影响所有的代价函数。
-
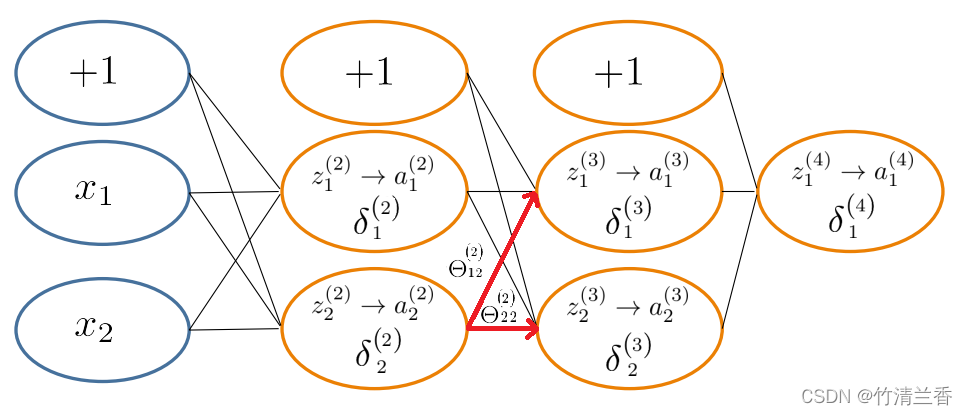
以上图中 a2(2)、a1(4) 神经元计算的 δ 项为例:
δ 1 ( 4 ) = y ( i ) − a 1 ( 4 ) δ 2 ( 2 ) = Θ 12 ( 2 ) δ 1 ( 3 ) + Θ 22 ( 2 ) δ 2 ( 3 ) \begin{aligned} &\delta^{(4)}_1=y^{(i)}-a^{(4)}_1\\ &\delta^{(2)}_2=\Theta^{(2)}_{12}\delta^{(3)}_1+\Theta^{(2)}_{22}\delta^{(3)}_2 \end{aligned} δ1(4)=y(i)−a1(4)δ2(2)=Θ12(2)δ1(3)+Θ22(2)δ2(3) -
注意:最终计算 δ 项的隐藏单元中不包含偏置单元。
四、使用注意:展开参数(Implementation note:Unrolling parameters)
- 主要介绍一个细节实现过程,把参数从矩阵展开成向量,以便在高级最优化步骤中的使用需要。
function [jVal, gradient] = costFunction(theta)
...
optTheta = fminunc(@costFunction, initialTheta, options)
- 执行了代价函数,输入参数是 theta ,函数返回代价值以及导数值,再将返回值传递给高级最优化算法 fminunc。也可以使用其他的优化算法,但它们的功能都是取出这些输入值 @costFunction 以及 theta 值的一些初始值),并且这些程序都假定 theta 和 theta 的初始值都是参数向量;同时,假定代价函数第二个返回值也就是梯度值,也是一个向量。
- 在逻辑回归中,这样做没有问题,但是在神经网络中,需要把参数从向量转变为矩阵。
N e u r a l N e t w o r k ( L = 4 ) : Θ ( 1 ) , Θ ( 2 ) , Θ ( 3 ) − m a t r i c e s ( T h e t a 1 , T h e t a 2 , T h e t a 3 ) ( 参 数 矩 阵 ) D ( 1 ) , D ( 2 ) , D ( 3 ) − m a t r i c e s ( D 1 , D 2 , D 3 ) ( 梯 度 矩 阵 ) \begin{aligned} &Neural\ \ Network\ \ (L=4):\\ &\qquad \Theta^{(1)},\Theta^{(2)},\Theta^{(3)}-matrices\blue{(Theta1, Theta2, Theta3)}(参数矩阵 )\\ &\qquad D^{(1)},D^{(2)},D^{(3)}-matrices\blue{(D1, D2, D3)}(梯度矩阵) \end{aligned} Neural Network (L=4):Θ(1),Θ(2),Θ(3)−matrices(Theta1,Theta2,Theta3)(参数矩阵)D(1),D(2),D(3)−matrices(D1,D2,D3)(梯度矩阵) - 下面将介绍如何取出这些矩阵,并且将它们展开成向量(“Unroll” in to vectors),以便他们最终成为恰当的格式,能够传入代价函数中对应 theta 的位置,并且得到梯度返回值。
1. 将参数从矩阵展开成向量
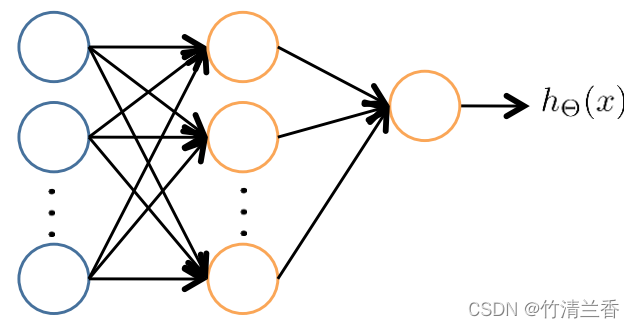
- 假设有一个这样的神经网络(如下图),输入层有 10 个输入单元,隐藏层有 10 个单元,最后的输出层只有一个输出单元。
s 1 = 10 , s 2 = 10 , s 3 = 1 Θ ( 1 ) ∈ R 10 × 11 , Θ ( 2 ) ∈ R 10 × 11 , Θ ( 3 ) ∈ R 1 × 11 D ( 1 ) ∈ R 10 × 11 , D ( 2 ) ∈ R 10 × 11 , D ( 3 ) ∈ R 1 × 11 \begin{aligned} &s_1 = 10,\ s_2 = 10,\ s_3 = 1\\ &\Theta^{(1)}\in\R^{10\times11},\ \ \Theta^{(2)}\in\R^{10\times11},\ \Theta^{(3)}\in\R^{1\times11}\\ &D^{(1)}\in\R^{10\times11},\ D^{(2)}\in\R^{10\times11},\ D^{(3)}\in\R^{1\times11} \end{aligned} s1=10, s2=10, s3=1Θ(1)∈R10×11, Θ(2)∈R10×11, Θ(3)∈R1×11D(1)∈R10×11, D(2)∈R10×11, D(3)∈R1×11 - 在 Octave 中实现在矩阵和向量之间来回转化:
% 矩阵展开成为长向量
thetaVec = [ Theta1(:); Theta2(:); Theta3(:)];
DVec = [D1(:); D2(:); D3(:)];
% 从向量表达式返回到矩阵表达式
% reshape 用于改变矩阵大小
Theta1 = reshape(thetaVec(1:110),10,11);
Theta2 = reshape(thetaVec(111:220),10,11);
Theta3 = reshape(thetaVec(221:231),1,11);
2. 将该方法应用于学习算法
- 先把初始的参数展开成一个长向量 initialTheta,然后传递给 fminunc 函数:
H a v e i n i t i a l p a r a m e t e r s Θ ( 1 ) , Θ ( 2 ) , Θ ( 3 ) . U n r o l l t o g e t i n i t i a l T h e t a t o p a s s t o f m i n u n c ( @ c o s t F u n c t i o n , i n i t i a l T h e t a , o p t i o n s ) \begin{aligned} &Have\ \ initial\ \ parameters\ \ \Theta^{(1)},\Theta^{(2)},\Theta^{(3)}.\\ &Unroll\ \ to \ \ get\ \ \blue{initialTheta}\ \ to\ \ pass\ \ to\\ &\blue{fminunc(@costFunction, initialTheta, options)} \end{aligned} Have initial parameters Θ(1),Θ(2),Θ(3).Unroll to get initialTheta to pass tofminunc(@costFunction,initialTheta,options) - 下一步就是实现代价函数,对应的算法如下:
f u n c t i o n [ j v a l , g r a d i e n t V e c ] = c o s t F u n c t i o n ( t h e t a V e c ) F r o m t h e t a V e c , g e t Θ ( 1 ) , Θ ( 2 ) , Θ ( 3 ) . U s e f o r w a r d p r o p / b a c k p r o p t o c o m p u t e D ( 1 ) , D ( 2 ) , D ( 3 ) a n d J ( Θ ) . U n r o l l D ( 1 ) , D ( 2 ) , D ( 3 ) t o g e t g r a d i e n t V e c . \begin{aligned} &\blue{function [jval, gradientVec] = costFunction(thetaVec)}\\ &\qquad From\ \ \blue{thetaVec}, \ get\ \ \Theta^{(1)},\Theta^{(2)},\Theta^{(3)}.\\ &\qquad Use\ \ forward\ \ prop/back\ \ prop\ \ to\ \ compute\ \ D^{(1)},D^{(2)},D^{(3)}\ \ and\ \ J(\Theta).\\ &\qquad Unroll\ \ D^{(1)},D^{(2)},D^{(3)}\ \ to\ \ get\ \ \blue{gradientVec}. \end{aligned} function[jval,gradientVec]=costFunction(thetaVec)From thetaVec, get Θ(1),Θ(2),Θ(3).Use forward prop/back prop to compute D(1),D(2),D(3) and J(Θ).Unroll D(1),D(2),D(3) to get gradientVec. - 代价函数会得到输入参数 thetaVec,包含了所有的参数向量,所有的参数都展开成一个向量的形式。
- 首先要使用 thetaVec 和重组函数 reshape,重组得到初始参数矩阵。
- 有了更方便的形式,就能执行前向传播和反向传播来计算出导数以及代价函数 J(Θ)。
- 最后可以取出这些导数值,然后展开他们,保持和展开的 Θ 值同样的顺序,可以以一个向量的形式(gradientVec)由代价函数返回这些导数值。
- 使用矩阵表达式的好处: 当参数以矩阵的形式存储时,在进行正向传播和反向传播时会更加方便,当将参数储存为矩阵时,也更容易充分利用向量化实现。
- 向量表达式的优点: 如果有像 thetaVec 或者 DVec 这样的矩阵,在使用一些高级优化算法时,通常要求把所有的参数展开成一个长向量的形式。
五、梯度检测(Gradient checking)
- 前面讨论了如何在神经网络中使用前向传播和反向传播来计算导数,但是反向传播算法还有许多细节,因此实现起来比较困难,并且他有一个不好的特性,很容易产生一些微妙的 bug(这些问题的产生,大多都和反向传播的错误实现有关)。当它与梯度下降或是其他算法一同工作时,看起来它确实能正常运行,并用且代价函数 J(θ) 在每次梯度下降的迭代中也在不断减小。
- 虽然在反向传播的实现中存在一些 bug,但运行情况看起来确实不错,虽然 J(θ) 在不断减小,但是到了最后得到的神经网络,其误差将会比无 bug 的情况下高出一个量级,并且你很可能不知道你得到的结果是由 bug 所导致的。
- 为了解决这一问题,我们将使用梯度检验(Gradient checking) 的思想来确保前向传播和反向传播得到正确的结果。
1. 示例
①当 θ 为实数时
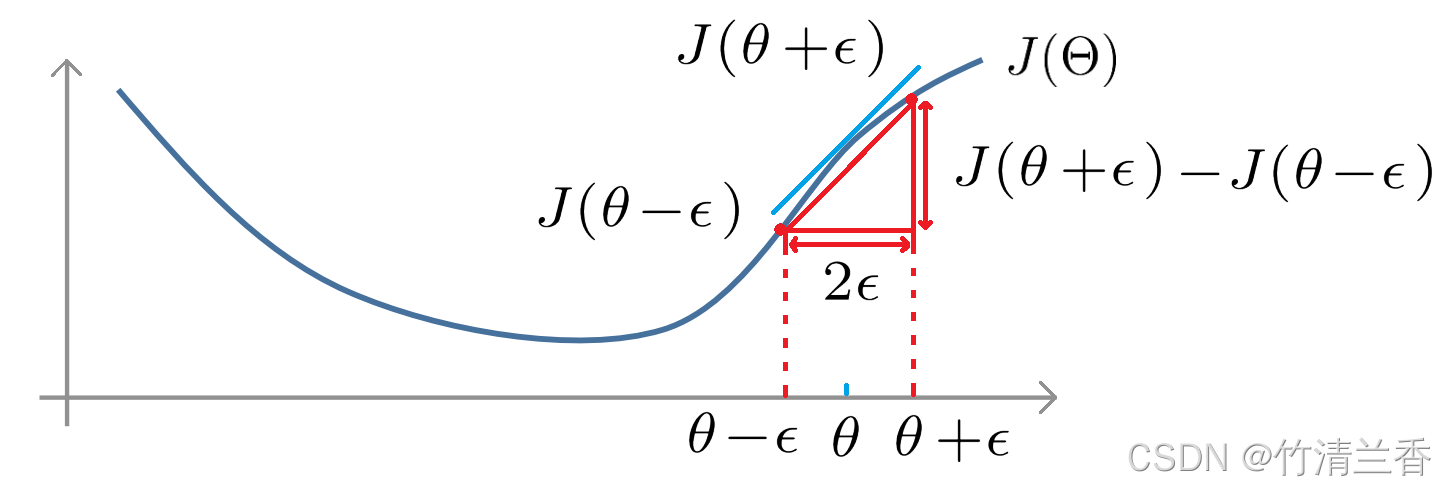
- 图中浅蓝色的线为函数 J(θ) 在 θ 点的切线,该点的导数就是切线的斜率,红线则为数值上逼近该值的过程:
- J(θ) 关于 θ 的偏导数为:
∂ ∂ θ J ( θ ) ≈ J ( θ + ε ) − J ( θ − ε ) 2 ε \begin{aligned} \frac{\partial}{\partial \theta}J(θ)\approx\frac{J(θ+\varepsilon)-J(θ-\varepsilon)}{2\varepsilon} \end{aligned} ∂θ∂J(θ)≈2εJ(θ+ε)−J(θ−ε) - ε 通常是一个很小的值,比如 10-4,当其足够小时,上式就变成了函数在 θ 点的导数值。
- 上面用于求导数的公式叫做双侧差分(two-sided difference)
, 下面的公式叫做单侧差分(one-sided difference),双侧差分能得到更加准确的结果。
J ( θ + ε ) − J ( θ − ε ) ε \begin{aligned} \frac{J(θ+\varepsilon)-J(θ-\varepsilon)}{\varepsilon} \end{aligned} εJ(θ+ε)−J(θ−ε) - 需要在 Octave 中执行下面的计算,计算出 gradApprox ,也就是该点导数的近似值:
gradApprox = (J(theta + EPSILON) – J(theta – EPSILON)) /(2*EPSILON)
②当 θ 为向量时
- 下面考虑更普遍的情况,即 θ 为向量参数的时候,可以用类似的思想估计所有的偏导数项:
P a r a m e t e r v e c t o r θ θ ∈ R n ( E . g . θ i s “ u n r o l l e d ” v e r s i o n o f Θ ( 1 ) , Θ ( 2 ) , Θ ( 3 ) ) θ = [ θ 1 , θ 2 , θ 3 , . . . , θ n ] ∂ ∂ θ 1 J ( θ ) ≈ J ( θ 1 + ε , θ 2 , θ 3 , . . . , θ n ) − J ( θ 1 − ε , θ 2 , θ 3 , . . . , θ n ) 2 ε ∂ ∂ θ 2 J ( θ ) ≈ J ( θ 1 , θ 2 + ε , θ 3 , . . . , θ n ) − J ( θ 1 , θ 2 − ε , θ 3 , . . . , θ n ) 2 ε . . . ∂ ∂ θ n J ( θ ) ≈ J ( θ 1 , θ 2 , θ 3 , . . . , θ n + ε ) − J ( θ 1 , θ 2 , θ 3 , . . . , θ n − ε ) 2 ε \begin{aligned} &Parameter\ \ vector\ \ \theta\\ &\qquad \theta\in\R^n\ \ (E.g.\ \ \theta\ \ is\ \ “unrolled”\ \ version\ \ of\ \ \Theta^{(1)},\Theta^{(2)},\Theta^{(3)})\\ &\qquad \theta=[\theta_1,\ \ \theta_2,\ \ \theta_3,...,\ \ \theta_n]\\ &\qquad \frac{\partial}{\partial \theta_1}J(\theta)\approx\frac{J(θ_1+\varepsilon,\ \theta_2,\ \theta_3,\ ...,\ \theta_n)-J(θ_1-\varepsilon,\ \theta_2,\ \theta_3,\ ...,\ \theta_n)}{2\varepsilon}\\ &\qquad \frac{\partial}{\partial \theta_2}J(\theta)\approx\frac{J(\theta_1,\ θ_2+\varepsilon,\ \theta_3,\ ...,\ \theta_n)-J(\theta_1,\ θ_2-\varepsilon,\ \theta_3,\ ...,\ \theta_n)}{2\varepsilon}\\ &\qquad ...\\ &\qquad \frac{\partial}{\partial \theta_n}J(\theta)\approx\frac{J(θ_1,\ \theta_2,\ \theta_3,\ ...,\ \theta_n+\varepsilon)-J(θ_1,\ \theta_2,\ \theta_3,\ ...,\ \theta_n-\varepsilon)}{2\varepsilon}\\ \end{aligned} Parameter vector θθ∈Rn (E.g. θ is “unrolled” version of Θ(1),Θ(2),Θ(3))θ=[θ1, θ2, θ3,..., θn]∂θ1∂J(θ)≈2εJ(θ1+ε, θ2, θ3, ..., θn)−J(θ1−ε, θ2, θ3, ..., θn)∂θ2∂J(θ)≈2εJ(θ1, θ2+ε, θ3, ..., θn)−J(θ1, θ2−ε, θ3, ..., θn)...∂θn∂J(θ)≈2εJ(θ1, θ2, θ3, ..., θn+ε)−J(θ1, θ2, θ3, ..., θn−ε) - 为了估算导数需要在 Octave 中实现下面这些语句:
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) = thetaPlus(i) + EPSILON;
thetaMinus = theta;
thetaMinus(i) = thetaMinus(i) – EPSILON;
gradApprox(i) = (J(thetaPlus) – J(thetaMinus))
/(2*EPSILON);
end;
% Check that gradApprox ≈ DVec
- 在神经网络中使用上面这种方法·来完成对神经网络中代价函数的所有参数的偏导数的计算,然后与再反向传播中得到的梯度进行比较,DVec 是从反向传播中得到的导数。
- 接下来通常要做的就是验证这个计算出的导数,也就是刚才计算的结果 gradApprox ,验证它是否相等于(或者数值上非常接近)用反向传播所计算出的导数 DVec。如果这两种方法计算出的结果相等(或者数值上非常接近,只差几位小数)就证明反向传播的实现是正确的。
2. 小结
I m p l e m e n t a t i o n N o t e : − I m p l e m e n t b a c k p r o p t o c o m p u t e D V e c ( u n r o l l e d D ( 1 ) , D ( 2 ) , D ( 3 ) ) . − I m p l e m e n t n u m e r i c a l g r a d i e n t c h e c k t o c o m p u t e g r a d A p p r o x . − M a k e s u r e t h e y g i v e s i m i l a r v a l u e s . − T u r n o f f g r a d i e n t c h e c k i n g . U s i n g b a c k p r o p c o d e f o r l e a r n i n g . I m p o r t a n t : − B e s u r e t o d i s a b l e y o u r g r a d i e n t c h e c k i n g c o d e b e f o r e t r a i n i n g y o u r c l a s s i f i e r . I f y o u r u n n u m e r i c a l g r a d i e n t c o m p u t a 5 o n o n e v e r y i t e r a 5 o n o f g r a d i e n t d e s c e n t ( o r i n t h e i n n e r l o o p o f c o s t F u n c t i o n ( … ) ) y o u r c o d e w i l l b e v e r y ‾ s l o w . \begin{aligned} &Implementation\ \ Note\ \ :\\ &\qquad - Implement\ \ backprop\ \ to\ \ compute\ \ \blue{DVec}\ \ (unrolled\ \ D^{(1)},D^{(2)},D^{(3)}).\\ &\qquad - Implement\ \ numerical\ \ gradient\ \ check\ \ to\ \ compute\ \ \blue{gradApprox}.\\ &\qquad - Make\ \ sure\ \ they\ \ give\ \ similar\ \ values.\\ &\qquad - Turn\ \ off\ \ gradient\ \ checking.\ \ Using\ \ backprop\ \ code\ \ for\ \ learning.\\ &Important:\\ &\qquad - Be\ \ sure\ \ to\ \ disable\ \ your\ \ gradient\ \ checking\ \ code\ \ before\ \ training\\ &\qquad \quad your\ \ classifier.\ \ If\ \ you\ \ run\ \ numerical\ \ gradient\ \ computa5on\ \ on\\ &\qquad \quad every\ \ itera5on\ \ of\ \ gradient\ \ descent\ \ (or\ \ in\ \ the\ \ inner\ \ loop\ \ of\\ &\qquad \quad \blue{costFunction(…)})your\ \ code\ \ will\ \ be\ \ \underline{very}\ \ slow.\\ \end{aligned} Implementation Note :−Implement backprop to compute DVec (unrolled D(1),D(2),D(3)).−Implement numerical gradient check to compute gradApprox.−Make sure they give similar values.−Turn off gradient checking. Using backprop code for learning.Important:−Be sure to disable your gradient checking code before trainingyour classifier. If you run numerical gradient computa5on onevery itera5on of gradient descent (or in the inner loop ofcostFunction(…))your code will be very slow.
- 首先,通过反向传播来计算 DVec
- 接着实现数值上的梯度检查,计算出 gradApprox
- 确保 gradApprox 和 DVec 都能得出相似的值,确保只有几位小数的差距
- 最后先关掉梯度检验,再使用代码进行学习(或训练网络),这里就不需要用前面讲到的方法来计算 gradApprox
- 这是因为这段之前所说的梯度检验的代码是一个计算量非常大的,也是非常慢的计算导数的程序
- 相对而言,之前所讲的反向传播算法,也就是之前说的计算 DVec 的方法,是一个高性能的计算导数的方法
- 因此,一旦通过检验确定反向传播的实现是正确的,就应该关掉梯度检验,不再去使用它
六、随机初始化(Random initialization)
- 前面的内容总结了神经网络中所有需要实现和训练的内容,本小节将要介绍最后一个思想——随机初始化。
1. 问题的产生
- 当我们执行一个算法,例如梯度下降或者高级优化算法时,我们需要为变量 Θ 选取一些初始值,对于高级优化算法,它默认会为 Θ 提供一些初始值。
optTheta = fminunc(@costFunction, initialTheta, options)
- 对于梯度下降算法,同样的我们也需要对 Θ 进行初始化,初始化完毕以后,就可以一步一步通过梯度下降来最小化代价函数 J(Θ)
- 一种方法是将初始值全部设为 0:
initialTheta = zeros(n,1)
-
虽然在逻辑回归中这样做是没有问题的,但实际上在训练网络时,将所有的参数都初始化为 0 起不到任何作用,以下面的神经网络训练为例:
-
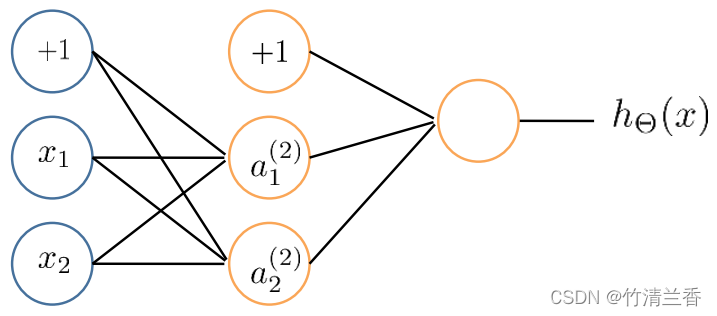
假如将神经网络中所有参数都初始化为 0,这就意味着从输入层到第一个隐藏层中的每一条边的权值均为 0,对于训练集中的每一个样本,最后都能得到:
a 1 ( 2 ) = a 2 ( 2 ) δ 1 ( 2 ) = δ 2 ( 2 ) \begin{aligned} a_1^{(2)}&=a_2^{(2)}\\ \delta_1^{(2)}&=\delta_2^{(2)}\\ \end{aligned} a1(2)δ1(2)=a2(2)=δ2(2) -
这就意味着,在梯度下降的更新过程中,虽然数值会发生变化不为 0,但最后二者仍然会是相等的:
∂ ∂ Θ 01 ( 1 ) J ( Θ ) = ∂ ∂ Θ 02 ( 1 ) J ( Θ ) Θ 01 ( 1 ) = Θ 02 ( 1 ) \begin{aligned} \frac{\partial}{\partial\Theta_{01}^{(1)}}J(\Theta)&=\frac{\partial}{\partial\Theta_{02}^{(1)}}J(\Theta)\\\ \\ \Theta_{01}^{(1)}&=\Theta_{02}^{(1)}\\ \end{aligned} ∂Θ01(1)∂J(Θ) Θ01(1)=∂Θ02(1)∂J(Θ)=Θ02(1) -
也就是说,所有的隐藏单元都在计算同一个特征。这是一种高度冗余的现象,这就意味着,最后的逻辑回归单元只能得到一个特征,因为所有的单元都一样,神经网络也就学习不到任何有趣的东西。
-
为了解决这一问题,在神经网络中对参数进行初始化时,要使用随机初始化的思想。
2. 解决方案
- 刚才出现的问题,有时也被称作对称权重问题(problem of symmetric weights),也就是所有的权重是一样的。所以,随机初始化就是解决这种对称问题的方法。
- 将参数初始化,在一定的范围之间:
I n i t i a l i z e e a c h Θ i j ( l ) t o a r a n d o m v a l u e i n [ − ε , ε ] ( i . e . − ε ≤ Θ i j ( l ) ≤ ε ) ( 此 处 的 ε 与 梯 度 检 测 中 的 ε 无 关 ) \begin{aligned} &Initialize\ \ each\ \ \Theta^{(l)}_{ij}\ \ to\ \ a\ \ random\ \ value\ \ in\ \ [-\varepsilon,\ \varepsilon ]\\ &(i.e.\ \ -\varepsilon\le\Theta^{(l)}_{ij}\le\varepsilon)\\ &(此处的\ \ \varepsilon\ \ 与梯度检测中的\ \ \varepsilon\ \ 无关) \end{aligned} Initialize each Θij(l) to a random value in [−ε, ε](i.e. −ε≤Θij(l)≤ε)(此处的 ε 与梯度检测中的 ε 无关) - Octave 中的代码实现:
Theta1 = rand(10,11)*(2*INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand( 1,11)*(2*INIT_EPSILON) - INIT_EPSILON;
- 总结: 为了训练神经网络,首先要将权重随机初始化为一个接近零范围在 ±ε 之间的数,然后进行反向传播,再进行梯度检测,最后,使用梯度下降或者其他高级优化算法,来最小化代价函数 J。
- 整个过程从为参数选取一个随机初始化的值开始,这是一种打破对称性的流程,随后通过梯度下降或者高级优化算法,就能计算出 Θ 的最优值。
七、组合到一起(Putting it together)
- 本节将把所有学过的内容做一个总体的回顾,弄清楚相互之间有怎样的联系,以及神经网络学习算法的总体实现过程。
1. 确定选择
- 在训练一个神经网络时,首先要做的是选择一种网络架构(神经元之间的连接模式),一般从以下三中架构中进行选择:
- 第一种包含三个输入单元,五个隐藏单元和四个输出单元
- 第二种结构是三个输入单元,两组五个隐藏单元,四个输出单元
- 最后一种是三个输入单元,每个隐藏层包含五个单元,然后是四个输出单元

- 如何做出选择?
- 输入单元的个数: 特征的维数
- 输出单元的个数: 分类问题中类别的个数(输出时要用向量表示,而不是用数值)
- 隐藏层单元的个数以及隐藏层的层数: 默认只用一个隐藏层,例如第一个神经架构,如果大于一层的话,通常每层的单元个数应该相等,例如第二个和第三个神经架构。
- 通常隐藏层单元的个数越多越好,但是需要注意,如果个数过多,会导致计算量过大。
- 同时,每个隐藏层所包含的单元数量还应和输入 x 的维度相匹配,即和特征的数目匹配,隐藏单元的数目可以和数特征的数量相同,或者是它的倍数(实现了匹配),这样都是有效的。
2. 实现步骤
- 下面介绍神经网络需要实现的步骤:
- 构建一个神经网络,然后随机初始化权重
- 执行前向传播算法
- 通过代码计算代价函数 J(Θ)
- 执行反向传播算法算出偏导数项(J(Θ) 关于 Θ 的偏导)
(第一次使用反向传播时最好用 for 循环,通过执行前向传播和反向传播来获得神经网络每一层每一个单元的激励值 a 和 δ 项) - 使用梯度检查来比较已经计算得到的偏导数项。把用反向传播算法得到的偏导数值与用数值方法得到的估值进行比较,确保反向传播算法得到的结果是正确的,随后,要停用梯度检查,因为梯度检查的计算速度非常慢。
- 使用一个最优化算法,比如说梯度下降算法或者高级优化算法,和反向传播算法相结合来最小化代价函数。
Training a neural network 1. R a n d o m l y i n i t i a l i z e w e i g h t s 2. I m p l e m e n t f o r w a r d p r o p a g a t i o n t o g e t h Θ ( x ( i ) ) f o r a n y x ( i ) 3. I m p l e m e n t c o d e t o c o m p u t e c o s t f u n c t i o n J ( Θ ) 4. I m p l e m e n t b a c k p r o p t o c o m p u t e p a r t i a l d e r i v a t i v e s ∂ ∂ Θ j k ( l ) J ( Θ ) f o r i = 1 : m P e r f o r m f o r w a r d p r o p a g a t i o n a n d b a c k p r o p a g a t i o n u s i n g e x a m p l e ( x ( i ) , y ( i ) ) ( G e t a c t i v a t i o n s a ( l ) a n d d e l t a t e r m s δ ( l ) f o r l = 2 , . . . , L ) . 5. U s e g r a d i e n t c h e c k i n g t o c o m p a r e ∂ ∂ Θ j k ( l ) J ( Θ ) c o m p u t e d u s i n g b a c k p r o p a g a t i o n v s . u s i n g n u m e r i c a l e s t i m a t e o f g r a d i e n t o f J ( Θ ) . T h e n d i s a b l e g r a d i e n t c h e c k i n g c o d e . 6. U s e g r a d i e n t d e s c e n t o r a d v a n c e d o p t i m i z a t i o n m e t h o d w i t h b a c k p r o p a g a t i o n t o t r y t o m i n i m i z e J ( Θ ) a s a f u n c t i o n o f p a r a m e t e r s \begin{aligned} &\textbf{Training \ \ a\ \ neural\ \ network}\\ &1. Randomly\ \ initialize\ \ weights\\ &2. Implement\ \ forward\ \ propagation\ \ to\ \ get\ \ h_\Theta(x^{(i)})\ \ for\ \ any\ \ x^{(i)}\\ &3. Implement\ \ code\ \ to\ \ compute\ \ cost\ \ function\ \ J(\Theta)\\ &4. Implement\ \ backprop\ \ to\ \ compute\ \ partial\ \ derivatives\ \ \ \ \frac{\partial}{\partial\Theta_{jk}^{(l)}}J(\Theta)\\ &\quad for \ \ i = 1:m \\ &\quad\qquad Perform\ \ forward\ \ propagation\ \ and\ \ backpropagation\ \ using\\ &\quad\qquad example\ \ (x^{(i)},y^{(i)})\\ &\quad\qquad(Get\ \ activations\ \ a^{(l)}and\ \ delta\ \ terms\ \ \delta^{(l)}\ \ for \ \ l=2,...,L).\\ &5. Use\ \ gradient\ \ checking\ \ to\ \ compare\ \ \frac{\partial}{\partial\Theta_{jk}^{(l)}}J(\Theta)\ \ computed\ \ using\\ &\quad\qquad backpropagation\ \ vs.\ \ using\ \ \ \ numerical\ \ estimate\ \ of\ \ gradient\ \ of\ \ J(\Theta).\\ &\quad\qquad Then\ \ disable\ \ gradient\ \ checking\ \ code.\\ &6. Use\ \ gradient\ \ descent\ \ or\ \ advanced\ \ optimization\ \ method\ \ with\\ &\quad\qquad backpropagation\ \ to\ \ try\ \ to\ \ \ \ minimize\ \ J(\Theta)\ \ as\ \ a\ \ function\ \ of\\ &\quad\qquad parameters\\ \end{aligned} Training a neural network1.Randomly initialize weights2.Implement forward propagation to get hΘ(x(i)) for any x(i)3.Implement code to compute cost function J(Θ)4.Implement backprop to compute partial derivatives ∂Θjk(l)∂J(Θ)for i=1:mPerform forward propagation and backpropagation usingexample (x(i),y(i))(Get activations a(l)and delta terms δ(l) for l=2,...,L).5.Use gradient checking to compare ∂Θjk(l)∂J(Θ) computed usingbackpropagation vs. using numerical estimate of gradient of J(Θ).Then disable gradient checking code.6.Use gradient descent or advanced optimization method withbackpropagation to try to minimize J(Θ) as a function ofparameters
- 对于神经网络代价函数 J(Θ) 是一个非凸函数,因此理论上梯度下降等算法最终可能停留在局部最小值的位置(虽然不是全局最小值,但是结果还是不错的)。
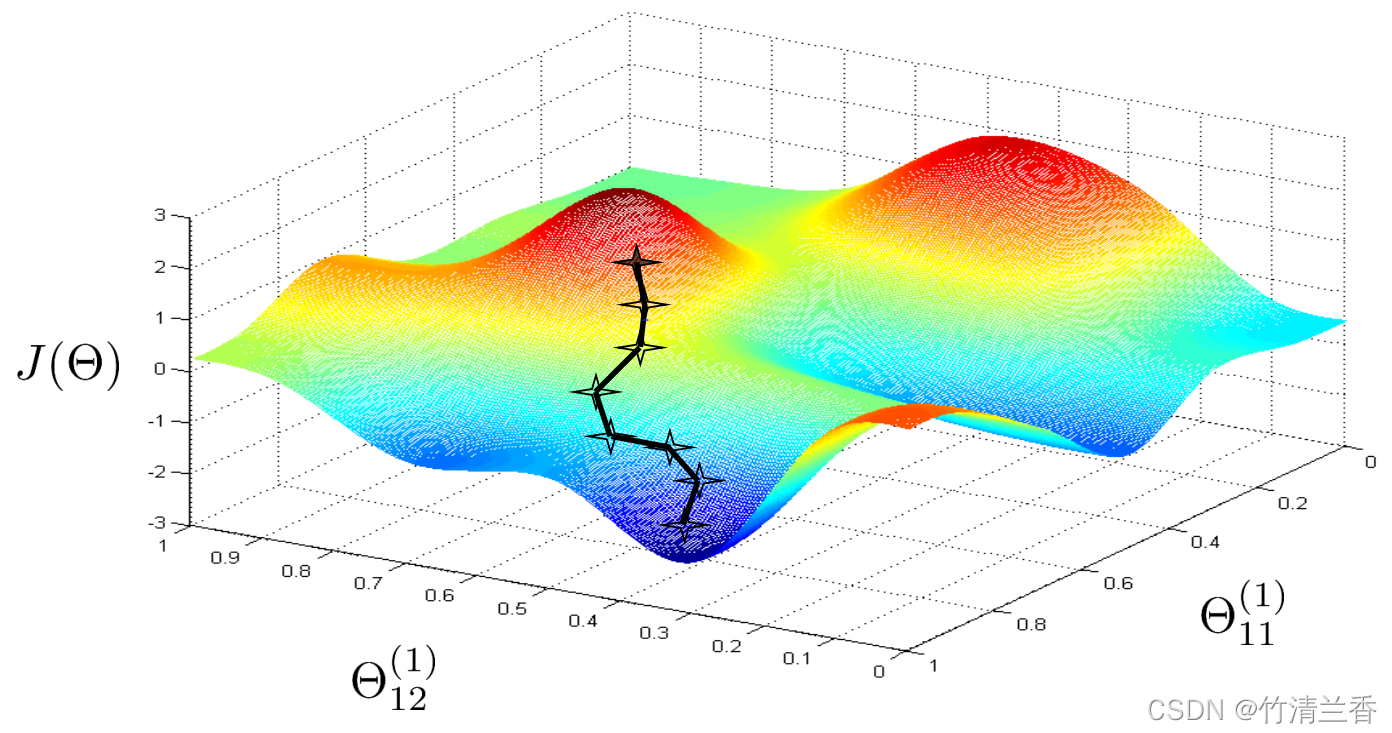
3. 直观理解
- 取两个参数为例:
- 代价函数 J(Θ) 度量的就是神经网络对训练数据的拟合情况。
- 如果假设函数得到的值近似相等于样本值,那么对应的代价函数的值就会很小(对应上图中低处的深蓝色区域)。
- 梯度下降算法的原理是从某个随机的初始点开始,他将会不停的往下下降,反向传播的目的就是算出梯度下降的方向,而梯度下降的作用就是沿着这个方向一点点的下降,一直都希望得到的点(上面这个例子中对应的是局部最优点)。
- 基本的原理就是试图找到某个最优的参数值,使得神经网络的输出值与训练集中观测到的实际值尽可能的接近。
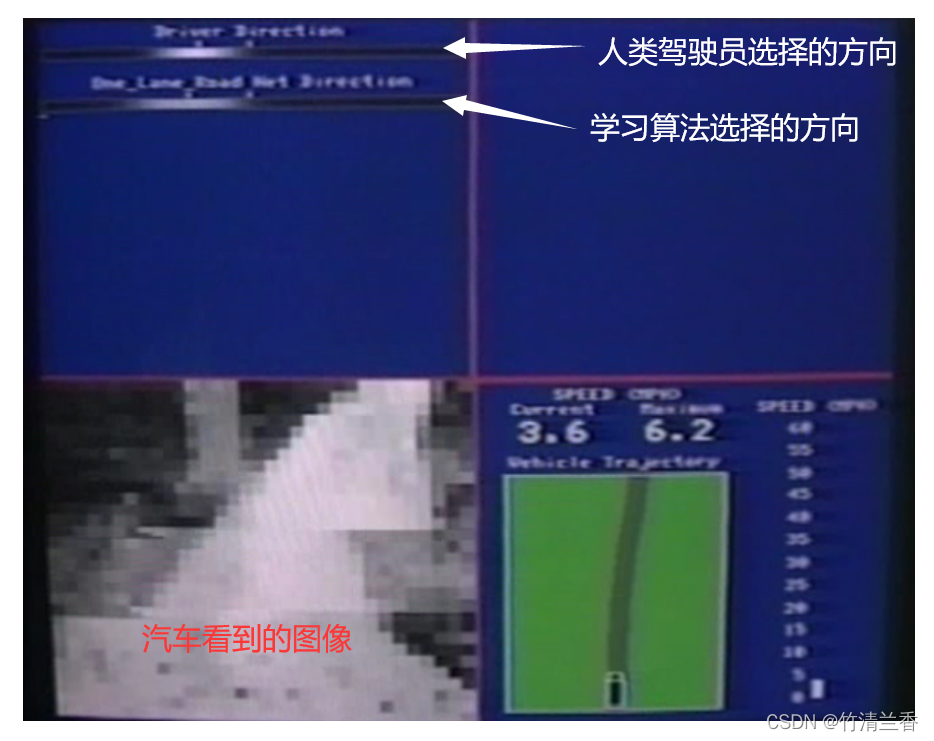
八、无人驾驶(Autonomous driving example)
-
本节将介绍一个神经网络学习的例子,就是通过神经网络来实现自动驾驶(汽车通过学习来自己驾驶)。
-
起初初始化后算法对应的横线是一段比较均匀的白线,随着学习的进行,白色部分逐渐集中在一小部分区域。

总结
- 本文主要介绍了神经网络中的代价函数、具体实现的反向传播算法、计算过程中的技巧(展开参数)、梯度检测、随机初始化以及神经网络的应用。
- 反向传播算法主要用于计算偏导项,其过程与前向传播法大致相同只是方向不同。
- 展开参数就是通过矩阵和向量的互相转换来实现高级最优化步骤中的使用需要。
- 梯度检测主要讲了从数值上计算梯度的方法,去验证反向传播算法的实现是正确的。
- 随机初始化则是为了解决对称权重问题,避免最后的逻辑回归单元只能得到一个特征。