文章目录
Log
2022.02.11开始学习第十三章
2022.02.12继续学习
2022.02.14今天继续弄
2022.02.17事情终于忙完了,回来学习
2022.02.18继续弄第十三章
2022.02.21接连不断的事情要做,接着又开学了,又有了更多的事,遥遥无期,抽时间弄吧
2022.02.22弄完十三章
- 本篇文章将要介绍第一个无监督学习算法——聚类算法。
一、无监督学习(Unsupervised learning introduction)
1. 简介
- 虽然之前提到过,但还是有必要将其与监督学习进行比较。
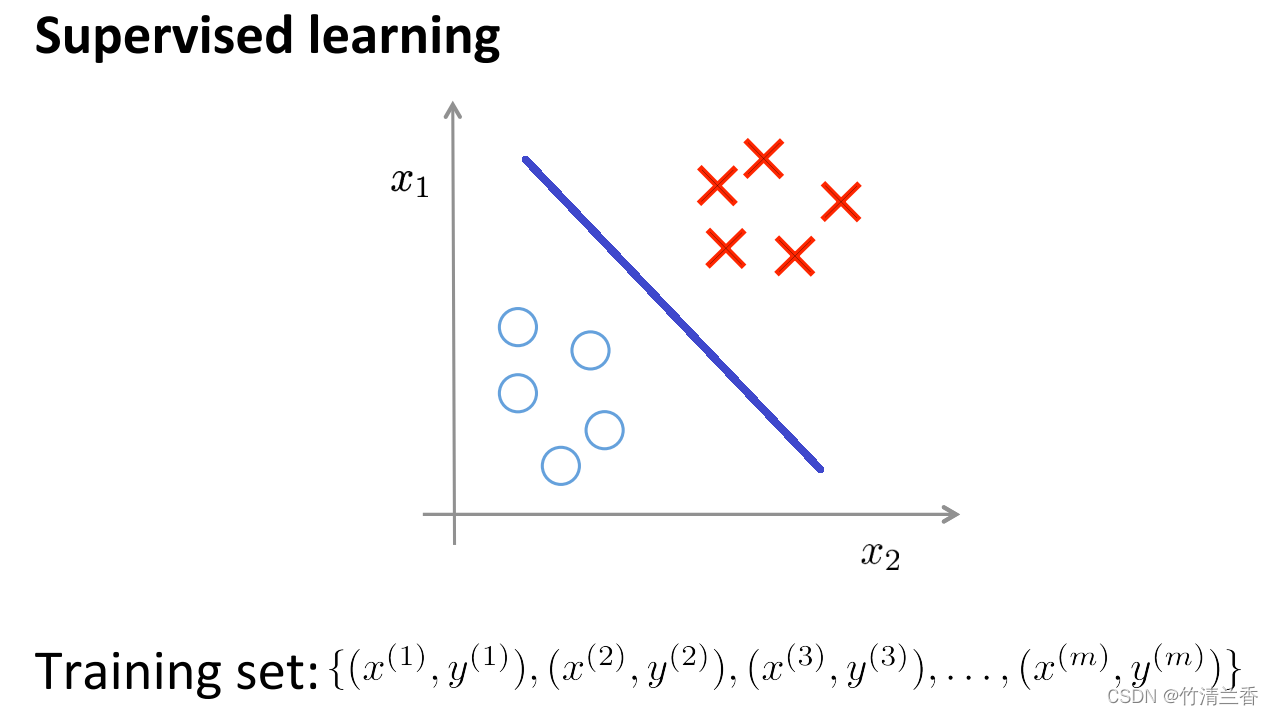
- 上图是一个典型的监督学习问题,给出一个带标签的训练集,目标是找到一条能够区分正负样本的决策边界。在这里,监督学习问题指的是有一系列标签,然后用假设函数去拟合它。
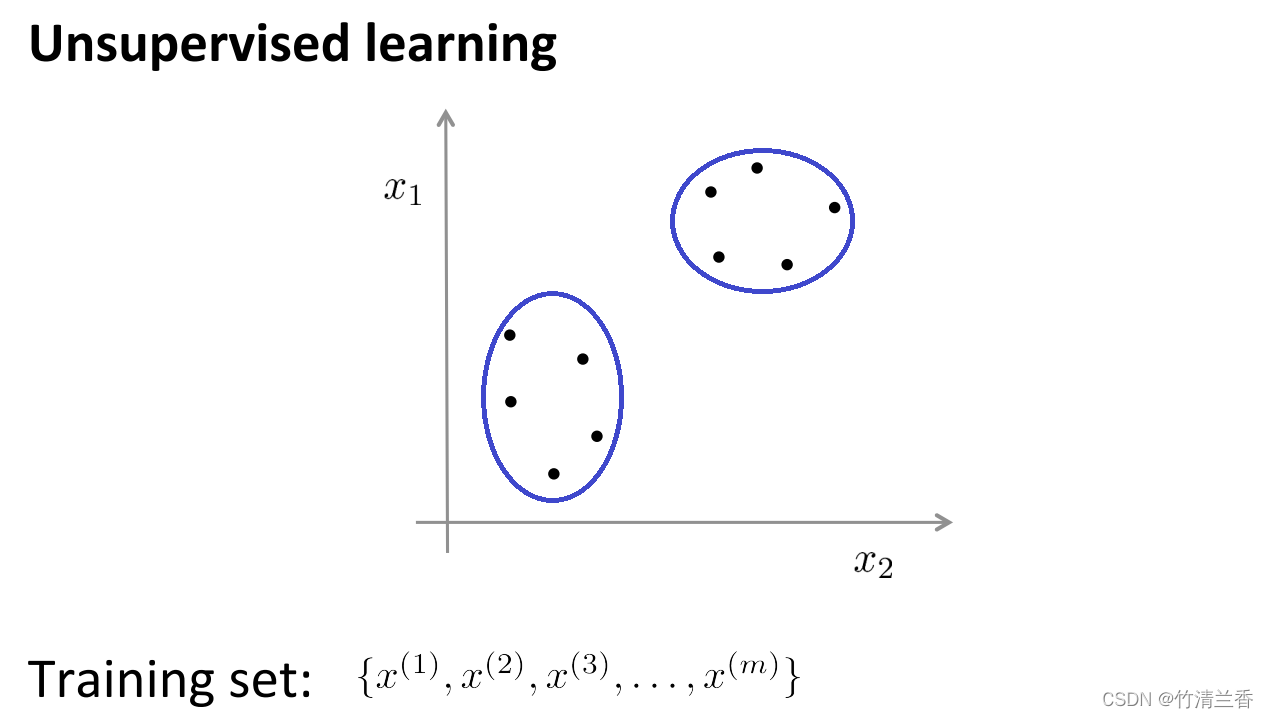
- 相对应的,在无监督学习中,我们的数据并不带有任何标签,因此在无监督学习中要做的就是将这一系列无标签的数据输入到算法中,然后让算法找到一些隐含在数据中的结构,通过下图中的数据,可以找到的一个结构就是数据集中的点可以分成两组分开的点集(簇),能够圈出这些簇(cluster)的算法,就叫做聚类算法(clustering algorithm)。
2. 聚类算法的应用
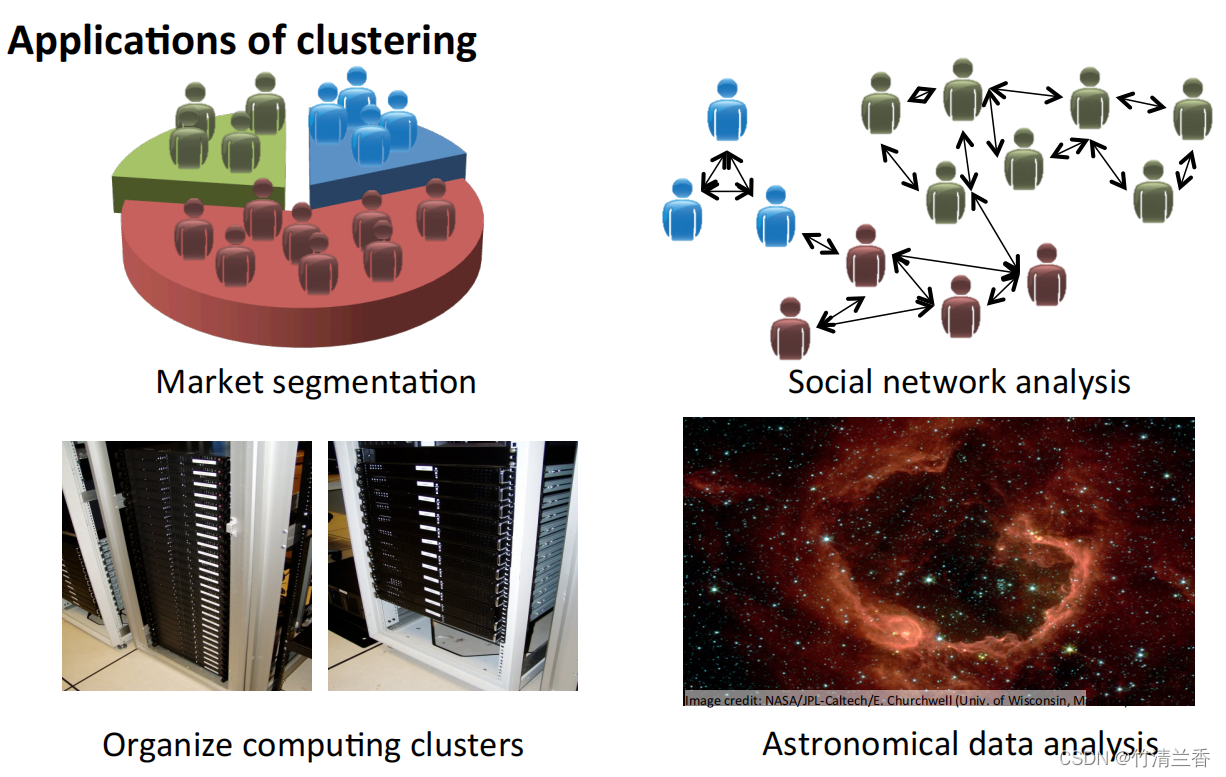
- 市场分割: 将数据库中客户的信息根据市场进行不同的分组,从而实现对其分别销售或者根据不同的市场进行服务改进。
- 社交网络分析: 通过邮件最频繁联系的人及其最频繁联系的人来找到一个关系密切的群体。
- 组织计算机集群: 在数据中心里,计算机集群经常一起协同工作,可以用它来重新组织资源、重新布局网络、优化数据中心以及通信数据。
- 了解银河系的构成: 利用这些信息来了解一些天文学的知识。
二、K-means 算法(K-means algorithm)
- 主要内容: 在聚类问题中,我们会给定一组未加标签的数据集,同时希望有一个算法能够自动地将这些数据分成有紧密关系的的(coherent)子集(subsets) 或是簇(clusters)。K 均值(K-means)算法是现在最热门最为广泛运用的聚类算法,本小节将会介绍 K 均值算法的定义以及原理。
1. 直观理解 K 均值算法
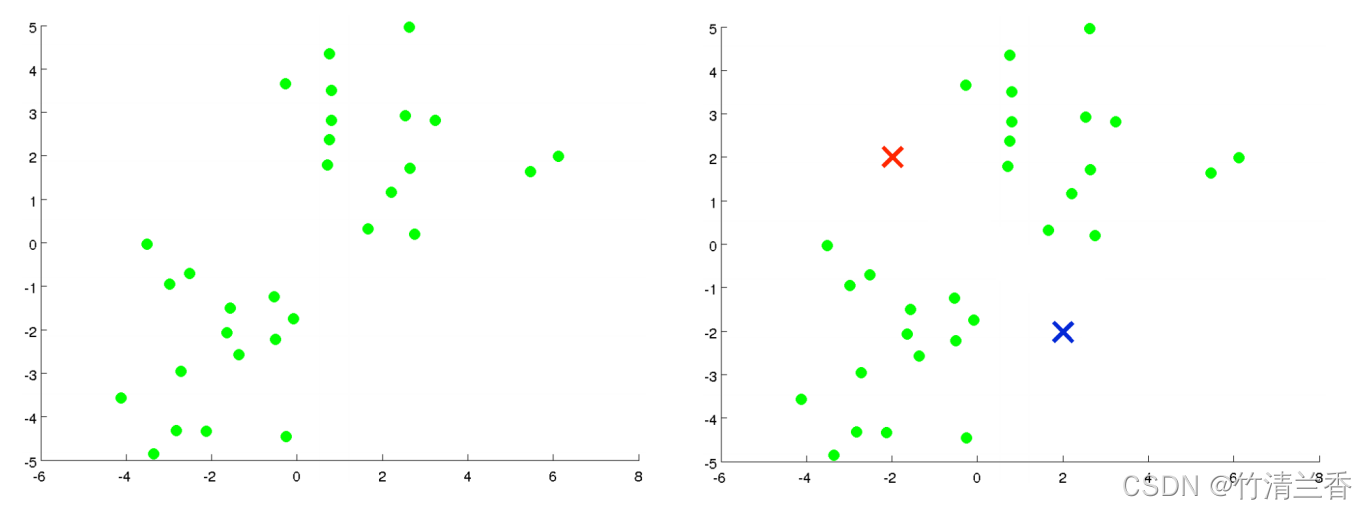
- 假如有一个无标签的数据集(上图左),并且我们想要将其分为两个簇,现在执行 K 均值算法,具体操作如下:
- 第一步,随机生成两个点(因为想要将数据聚成两类)(上图右),这两个点叫做聚类中心(cluster centroids)。
- 第二步,进行 K 均值算法的内循环。K 均值算法是一个迭代算法,它会做两件事情,第一个是簇分配(cluster assignment),第二个是移动聚类中心(move centroid)。
内循环的第一步是要进行簇分配,也就是说,遍历每一个样本,再根据每一个点到聚类中心距离的远近将其分配给不同的聚类中心(离谁近分配给谁),对于本例而言,就是遍历数据集,将每个点染成红色或蓝色。
内循环的第二步是移动聚类中心,将红色和蓝色的聚类中心移动到各自点的均值处(每组点的平均位置)。
接着就是将所有的点根据与新的聚类中心距离的远近进行新的簇分配,如此循环,直至聚类中心的位置不再随着迭代而改变,并且点的颜色也不再发生改变,此时可以说 K 均值已经聚合了。该算法在找出数据中两个簇的方面做的相当好,下面用更规范的格式写出 K 均值算法。

2. K 均值算法的规范表达
I n p u t : − K ( n u m b e r o f c l u s t e r s ) − T r a i n i n g s e t { x ( 1 ) , x ( 2 ) , . . . , x ( m ) } x ( i ) ∈ R n ( d r o p x 0 = 1 c o n v e n t i o n ) \begin{aligned} &Input:\\ &\qquad - K\ \ (number\ \ of\ \ clusters)\\ &\qquad - Training\ \ set\ \ \{x^{(1)},x^{(2)},...\ ,x^{(m)}\}\\\ \\ &\quad x^{(i)}\in\R^n(drop\ \ x_0=1\ \ convention) \end{aligned} Input:−K (number of clusters)−Training set {x(1),x(2),... ,x(m)}x(i)∈Rn(drop x0=1 convention)
- K 均值算法接受两个输入,一个是参数 K , 表示你想从数据中聚类出的簇的个数,另一个是一系列无标签的只用 x 来表示的数据集(因为这是无监督学习,所以不需要标签 y)。
- 同时在非监督学习的 K 均值算法里,我们约定 x(i) 为 n 维实数向量(因为去掉了 x0 所以不是 n + 1 维向量)。
R a n d o m l y i n i t i a l i z e K c l u s t e r c e n t r o i d s μ 1 , μ 2 , . . . , μ K ∈ R n R p e a t { C l u s t e r a s s i g n m e n t s t e p { f o r i = 1 t o m : c ( i ) : = i n d e x ( f r o m 1 t o K ) o f c l u s t e r c e n t r o i d c l o s e s t t o x ( i ) c ( i ) = k o f min k ∣ ∣ x ( i ) − μ k ∣ ∣ c ( i ) = k o f min k ∣ ∣ x ( i ) − μ k ∣ ∣ 2 M o v e c e n t r o i d s t e p { f o r k = 1 t o K μ k : = a v e r a g e ( m e a n ) o f p o i n t s a s s i g n e d t o c l u s t e r k e . g . x ( 1 ) , x ( 5 ) , x ( 6 ) , x ( 10 ) → c ( 1 ) = 2 , c ( 2 ) = 2 , c ( 5 ) = 2 , c ( 10 ) = 2 μ 2 = 1 4 [ x ( 1 ) + x ( 5 ) + x ( 6 ) + x ( 10 ) ] ∈ R n } \begin{aligned} &Randomly\ \ initialize\ \ K\ \ cluster\ \ centroids\ \ \mu_1,\mu_2,...\ ,\mu_K\in\R^n\\ &Rpeat\ \ \{\\ &{{Cluster\atop assignment}\atop step}\begin{cases} &for\ \ i=1\ \ to\ \ m:\\ &\qquad c^{(i)}:=index\ \ (from\ \ 1\ \ to\ \ K)\ \ of\ \ cluster\ \ centroid\\ &\qquad\quad\qquad closest\ \ to\ \ x^{(i)}\\ &\qquad c^{(i)}=k\ \ of\ \ \min\limits_k||x^{(i)}-\mu_k||\\ &\qquad c^{(i)}=k\ \ of\ \ \min\limits_k||x^{(i)}-\mu_k||^2\\ \end{cases}\\ &{{Move\atop centroid}\atop step}\begin{cases} &for\ \ k=1\ \ to\ \ K \\ &\qquad \mu_k:=average(mean)\ \ of\ \ points\ \ assigned\ \ to\ \ cluster\ \ k\\ &e.g.\quad x^{(1)},x^{(5)},x^{(6)},x^{(10)}\rightarrow c^{(1)}=2,c^{(2)}=2,c^{(5)}=2,c^{(10)}=2\\ &\qquad \mu_2=\frac{1}{4}\left[x^{(1)}+x^{(5)}+x^{(6)}+x^{(10)}\right]\in\R^n \end{cases}\\ &\} \end{aligned} Randomly initialize K cluster centroids μ1,μ2,... ,μK∈RnRpeat {stepassignmentCluster⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧for i=1 to m:c(i):=index (from 1 to K) of cluster centroidclosest to x(i)c(i)=k of kmin∣∣x(i)−μk∣∣c(i)=k of kmin∣∣x(i)−μk∣∣2stepcentroidMove⎩⎪⎪⎪⎨⎪⎪⎪⎧for k=1 to Kμk:=average(mean) of points assigned to cluster ke.g.x(1),x(5),x(6),x(10)→c(1)=2,c(2)=2,c(5)=2,c(10)=2μ2=41[x(1)+x(5)+x(6)+x(10)]∈Rn} - K 均值算法做的第一步是随机初始化。K 个聚类中心记作 μ1,μ2 一直到 μk,通常情况下聚类中心不止两个。
- 随后会重复下面的事情,首先,进行簇分配步骤:
- 对每一个聚类样本,用 c(i) 来表示第 1 到第 K 个最接近 x(i) 的聚类中心,将每个样本根据它离哪个聚类中心更近一些将其染成对应的颜色, c(i) 的数值范围是从 1 到 K。
- 另一种表达方式是计算第 i 个样本距离每个聚类中心 μk 的距离(大写的 K 表示聚类中心的个数,小写的 k 表示不同中心的下标) ,然后对其进行最小化,找出某个 k 值能够最小化 x(i) 与聚类中心的距离,然后将最小化这项的 k 值赋值给 c(i) 。
- 除此之外,还有一种 c(i) 的表示方式,在上一种的基础上平方,最后得到的 c(i) 是一样的(使得表达式最小的 k)。通常来说,人们约定俗成地在 K 均值算法里使用平方项这一种表示方式。
- 随后进行移动聚类中心:
- 对于每一个聚类中心,也就是 k 从 1 到 K, μk 等于这个簇中所有点的均值,例如上面公式下方举出的例子。值得注意的是,如果一个聚类中心没有被分配到点,常见的做法是直接移除那个没有点的聚类中心,对应的最终分配得到的簇的数量会减少(如 K 个变成 K-1 个),有时确实需要 K 个簇时,那么就应该重新随机初始化这个聚类中心。
3. K 均值算法的应用:分离不佳的簇的问题(non-separated clusters)
-
目前为止,K 均值算法都基于图中的数据集(下图左),明显可以分为三个簇,然后用算法实现它。
-
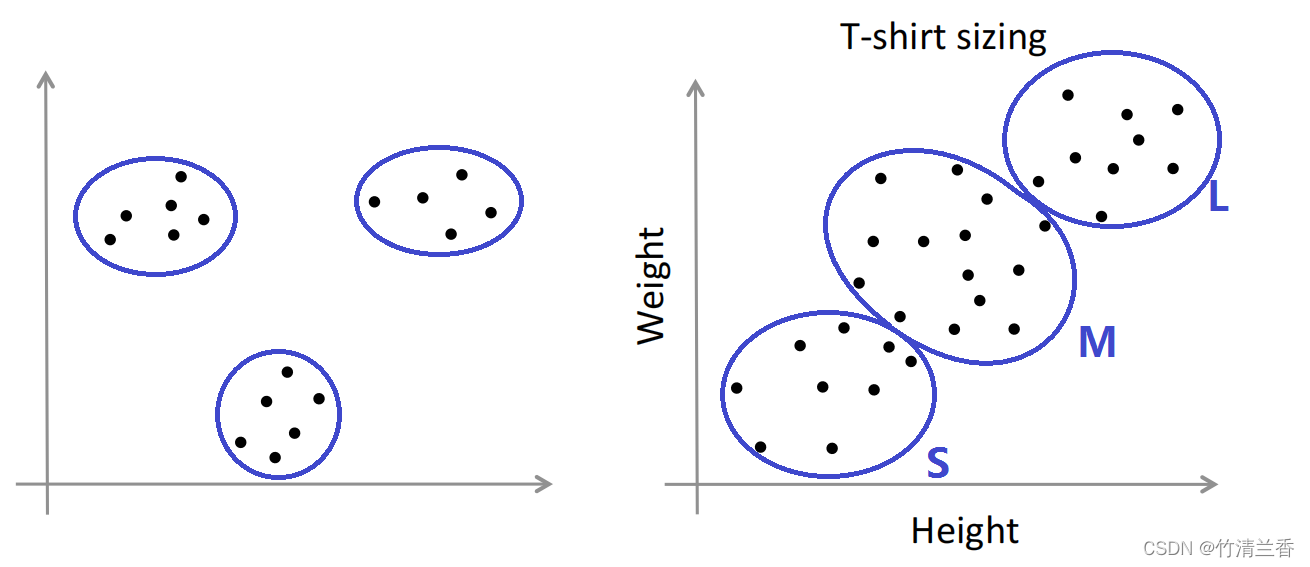
但在实际中,K 均值算法也会基于这样的数据集(上图右),看起来不能很好地分为几个簇。举个例子,关于 T 恤尺寸的例子,假如 T 恤制造商已经找到了一些顾客,想把 T 恤卖给他们,现在已经收集到了一些这些人身高体重的样本数据,假设身高和体重高度相关,现在想确定 T 恤的尺寸,设计三种不同大小的 T 恤(小中大),可以执行 K 均值聚类算法,可能会将数据分为图示的三个簇,之后可以观察第一类人群的身高体重数据,然后设计出小号 T 恤,中号大号以此类推。
-
这有点类似于市场划分的例子,用 K 均值算法将市场划分为 3 个不同的部分,这样就可以分别设计产品(小号中号大号),分别去贴近这三个人群的需求。
三、优化目标(Optimization objective)
- 主要内容: K 均值算法的优化目标。
- 目的: ①了解 K 均值的优化目标函数能帮助我们对学习算法进行调试确保 K 均值算法运行正确 ②更好地使用它帮助 K 均值算法找到更好的簇,并且避免局部最优解。
1. 失真代价函数(the distortion cost function)
- 当运行 K 均值算法时会对两组变量进行跟踪:
c ( i ) : = i n d e x o f c l u s t e r ( f r o m 1 t o K ) t o w h i c h e x a m p l e x ( i ) i s c u r r e n t l y a s s i g n e d μ k : = c l u s t e r c e n t r o i d k ( μ k ∈ R n ) k ∈ { 1 , 2 , . . . , K } \begin{aligned} &c^{(i)}:=index\ \ of\ \ cluster\ \ (from\ \ 1\ \ to\ \ K)\ \ to\ \ which\ \ example\\ &\qquad\quad x^{(i)}\ \ is\ \ currently\ \ assigned\\ &\mu_k:=cluster\ \ centroid\ \ k\ (\mu_k\in\R^n)\qquad k\in\{1,2,...\ ,K\}\\ \end{aligned} c(i):=index of cluster (from 1 to K) to which examplex(i) is currently assignedμk:=cluster centroid k (μk∈Rn)k∈{1,2,... ,K} - 首先是 c(i) ,表示的是当前样本 x(i) 所属的那个簇的索引或者序号;
- 另外一组变量 μk 用来表示第 k 个聚类中心的位置,k 的取值范围为 1 到 K。
- 除此之外还有一个符号 μc(i) 用来表示 x(i) 所属的那个簇的聚类中心:
μ c ( i ) : = c l u s t e r c e n t r o i d o f c l u s t e r t o w h i c h e x a m p l e x ( i ) h a s b e e n a s s i g n e d x ( i ) → 5 c ( i ) = 5 μ c ( i ) = μ 5 \begin{aligned} &{\Large\mu_{c^{(i)}}}:=cluster\ \ centroid\ \ of\ \ cluster\ \ to\ \ which\ \ example\ \ x^{(i)}\\ &\qquad \qquad has\ \ been\ \ assigned\\ &x^{(i)}\rightarrow5\qquad c^{(i)}=5\qquad \mu_{c^{(i)}}=\mu_5 \end{aligned} μc(i):=cluster centroid of cluster to which example x(i)has been assignedx(i)→5c(i)=5μc(i)=μ5 - 假设 x(i) 被划分为第 5 个簇,也就是说 c(i) ( x(i) 的索引)等于 5,这意味着 x(i) 这个样本被划分到了第 5 个簇,因此 μc(i) 就等于 μ5,通过这样的表示方法,我们就能写出 K 均值聚类算法的优化目标了:
Optimization objective: J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) = 1 m ∑ i = 1 m ∣ ∣ x ( i ) − μ c ( i ) ∣ ∣ 2 min c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) \begin{aligned} &\textbf{Optimization\ \ objective:}\\ &\qquad {\large J(c^{(1)},...\ ,c^{(m)},\mu_1,...\ ,\mu_K)=\frac{1}{m}\sum^m_{i=1}||x^{(i)}-\mu_{c^{(i)}}||^2}\\ &\qquad{\large {\min \atop{c^{(1)},...\ ,c^{(m)},\atop \mu_1,...\ ,\mu_K}}J(c^{(1)},...\ ,c^{(m)},\mu_1,...\ ,\mu_K)} \end{aligned} Optimization objective:J(c(1),... ,c(m),μ1,... ,μK)=m1i=1∑m∣∣x(i)−μc(i)∣∣2μ1,... ,μKc(1),... ,c(m),minJ(c(1),... ,c(m),μ1,... ,μK) - K 均值算法最小化的代价函数就是函数 J ,参数为 c(1) 到 c(m) 以及 μ1 到 μK ,这些参数会随着算法的运行不断变化。上式右侧是优化目标,求和项为后面的式子表示的是每个样本 x(i) 到 x(i) 所属的聚类中心的距离的平方值。那么 K 均值算法要做的事情就是要找到参数 c(i) 和 μi,也就是能够最小化代价函数 J 的 c 和 μ,上面式子中的代价函数有时也叫做失真代价函数(the distortion cost function),或者K-means算法的失真(the distortion of the K -means algorithm)。
2. K 均值算法的细节
- 下面是之前提到过的 K 均值算法:
R a n d o m l y i n i t i a l i z e K c l u s t e r c e n t r o i d s μ 1 , μ 2 , . . . , μ K ∈ R n R p e a t { f o r i = 1 t o m c ( i ) : = i n d e x ( f r o m 1 t o K ) o f c l u s t e r c e n t r o i d c l o s e s t t o x ( i ) f o r k = 1 t o K μ k : = a v e r a g e ( m e a n ) o f p o i n t s a s s i g n e d t o c l u s t e r k } \begin{aligned} &Randomly\ \ initialize\ \ K\ \ cluster\ \ centroids\ \ \mu_1,\mu_2,...\ ,\mu_K\in\R^n\\ &Rpeat\ \ \{\\ &\qquad \qquad for\ \ i=1\ \ to\ \ m\\ &\qquad \qquad \qquad c^{(i)}:=index\ \ (from\ \ 1\ \ to\ \ K)\ \ of\ \ cluster\ \ centroid\\ &\qquad \qquad \qquad\quad\qquad closest\ \ to\ \ x^{(i)}\\ &\qquad \qquad for\ \ k=1\ \ to\ \ K \\ &\qquad \qquad \qquad \mu_k:=average(mean)\ \ of\ \ points\ \ assigned\ \ to\ \ cluster\ \ k\\ &\quad \qquad \} \end{aligned} Randomly initialize K cluster centroids μ1,μ2,... ,μK∈RnRpeat {for i=1 to mc(i):=index (from 1 to K) of cluster centroidclosest to x(i)for k=1 to Kμk:=average(mean) of points assigned to cluster k} - 这个算法的第一步就是簇分配,把每一个点划分给各自所属的聚类中心,可以用数学证明这个簇分配的步骤实际上就是在最小化代价函数 J,它的参数就是这些 c(1),c(2),… ,c(m)。要保持最近的聚类中心,也就是 μ1 到 μk 的位置固定不变。
cluster assignment step: m i n i m i z e J w . r . t . c ( 1 ) , c ( 2 ) , . . . , c ( m ) ( h o l d i n g μ 1 , . . . , μ K f i x e d ) move centroid step: m i n i m i z e J w . r . t . μ 1 , . . . , μ K \begin{aligned} &\textbf{cluster\ \ assignment\ \ step:}\\ &\qquad minimize\ \ J\ \ w.r.t.\ \ c^{(1)},c^{(2)},...\ ,c^{(m)}\\ &\qquad \qquad (holding\ \ \mu_1,...\ ,\mu_K\ \ fixed)\\ &\textbf{move\ \ centroid\ \ step:}\\ &\qquad minimize\ \ J\ \ w.r.t.\ \ \mu_1,...\ ,\mu_K\\ \end{aligned} cluster assignment step:minimize J w.r.t. c(1),c(2),... ,c(m)(holding μ1,... ,μK fixed)move centroid step:minimize J w.r.t. μ1,... ,μK
w.r.t.:with respect to —— 关于 - 因此,第一步要做的不是改变聚类中心的位置,而是要选出 c(1),c(2),… ,c(m) 来最小化这个代价函数(失真函数)(簇分配)。直观地来说,就是把每个点分配给它们最靠近的聚类中心,这样就可以使得这些点到对应的聚类中心的平方最小化。
- 第二步就是移动聚类中心,它所做的就是选择 μ 值来最小化代价函数 J ,最小化聚类中心的位置 μ1,… ,μK。K 均值算法实际做的就是把这两个系列的变量分成两半,一组是变量 c,另一组是变量 μ,随后最小化 J 关于变量 c,接着最小化 J 关于变量 μ,然后保持迭代。
- 除此之外,K 均值算法来最小化代价函数J 这一方法还可以被用来调试学习算法,确保实现的 K 均值算法是收敛的并且能够正确运行。
四、随机初始化(Random initialization)
- 主要内容: 初始化 K 均值聚类算法以及如何使算法避开局部最优。
1. 随机初始化(具体做法)
-
有几种不同的方法可以用来随机初始化聚类中心。但是事实证明,通常下面的一种方法效果最好:
S h o u l d h a v e K < m R a n d o m l y p i c k K t r a i n i n g e x a m p l e s . S e t μ 1 , . . . , μ K e q u a l t o t h e s e K e x a m p l e s . \begin{aligned} &Should\ \ have\ \ K<m\\\ \\ &Randomly\ \ pick\ \ K\ \ training\ \ examples.\\\ \\ &Set\ \ \mu_1,...\ ,\mu_K\ \ equal\ \ to \ \ these\ \ K\ \ examples. \end{aligned} Should have K<mRandomly pick K training examples.Set μ1,... ,μK equal to these K examples. -
当运行 K 均值算法时,应该把聚类中心数值 K 设置为比训练样本数量 m 小的值,通常用来初始化 K 均值聚类的方法是随机挑选 K 个训练样本,然后设定 μ1 到 μK,让它们等于这K个样本,下面是一个具体的例子:
-
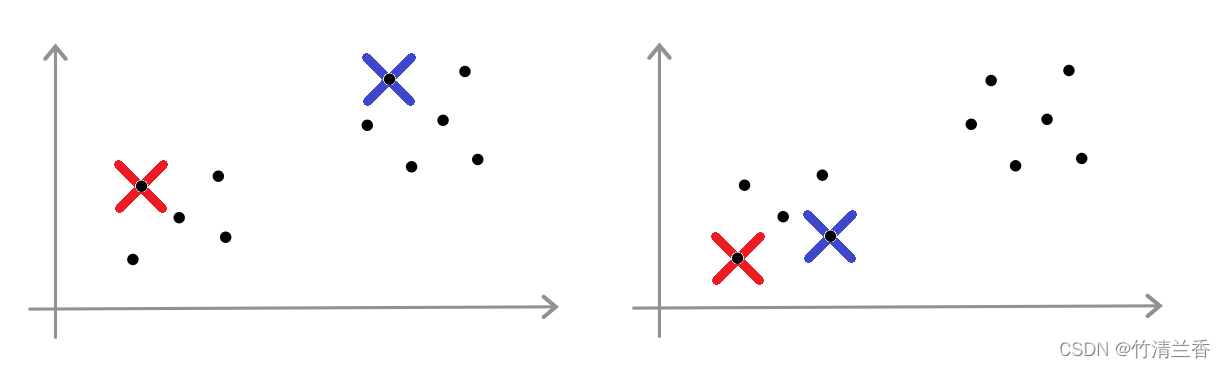
假设 K 等于 2,并且想找到两个聚类,为了初始化聚类中心,随机挑选 2 个样本,理想情况下为上图左,但是有时也会是是上图右。
-
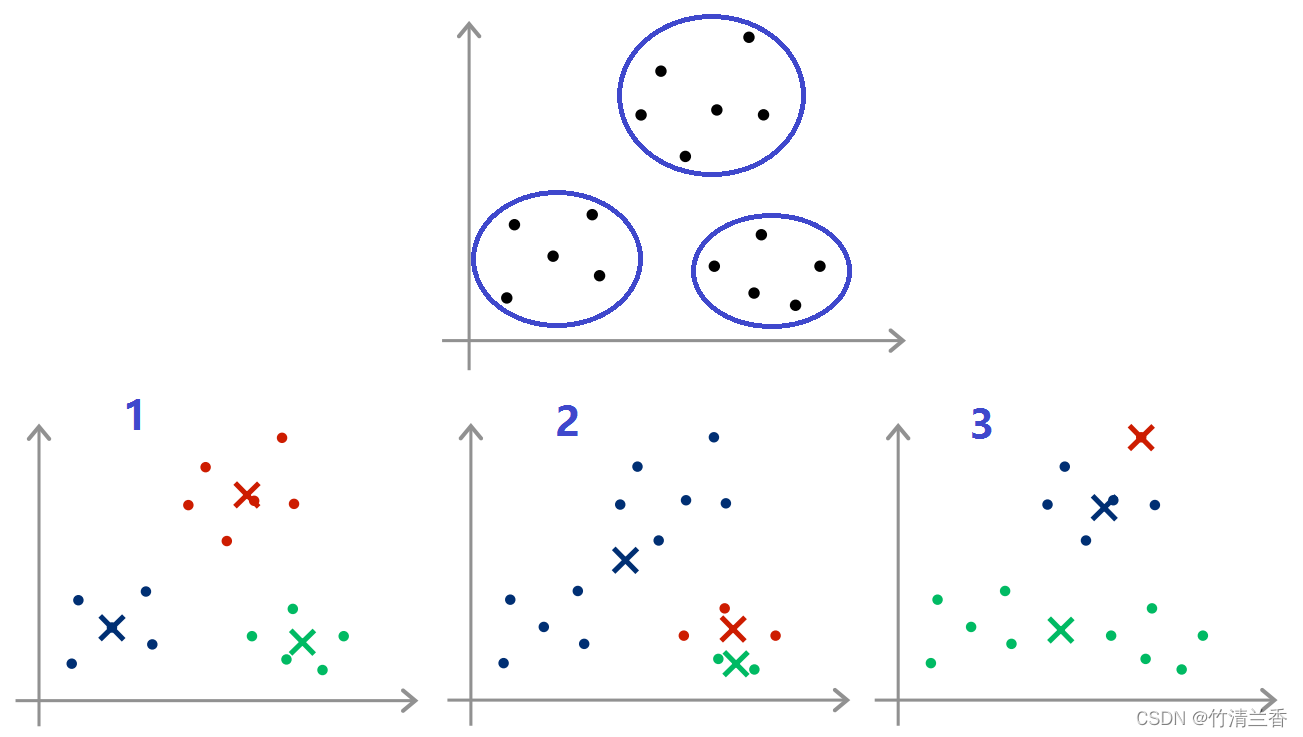
不同的聚类初始化状态决定了最终收敛于不同的结果,随机初始化状态不同 K 均值最后可能会得到不同的结果。具体而言,K 均值算法可能会落在局部最优。下图的数据看起来好像有 3 个聚类,如果运行 K 均值算法,假设最后得到一个比较好的局部最优,但事实上这应该是全局最优(下图 1),可能会得到这样的聚类结果,但是如果随机初始化得到的结果不好,就可能得到下面这些不同的局部最优值(下图 2、3):
-
例如上图 2,看上去蓝色的聚类捕捉到了左边的很多点,而红色和绿色的聚类则捕捉到了相对较少的点,这就是不好的局部最优,因为它将上面的两个聚类当做一个聚类,进一步将下面的聚类分割成了两个小的聚类,图 3 存在着同样的问题。
2. 多次随机初始化(解决局部最优解问题)
- 上面两个例子(图 2、图 3 )对应着 K 均值算法的不同的局部最优,实际上图 3 中的红色的聚类只捕捉到了一个无标签样本,而局部最优这个术语,指的是这个畸变函数(distortion function) J 的局部最优解。这些局部最优所对应的情况其实是 K 均值算法落在了局部最优,因而不能很好地最小化畸变函数 J。
- 因此,如果担心 K 均值算法落到局部最优,如果想让 K 均值算法找到最有可能的聚类,可以尝试多次随机初始化,并运行 K 均值算法很多次,以此来保证最终能得到一个足够好的结果,一个尽可能好的局部或全局最优值,以下是具体做法:
Random initialization: f o r i = 1 t o 100 { R a n d o m l y i n i t i a l i z e K – m e a n s . R u n K – m e a n s . G e t c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K . C o m p u t e c o s t f u n c t i o n ( d i s t o r t i o n ) J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) } P i c k c l u s t e r i n g t h a t g a v e l o w e s t c o s t J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) \begin{aligned} &\textbf{Random\ \ initialization:}\\ &for\ \ i=1\ \ to\ \ 100\{\\ &\qquad\qquad Randomly\ \ initialize\ \ K\text{\textendash}means.\\ &\qquad\qquad Run\ \ K\text{\textendash}means.Get\ \ c^{(1)},...\ ,c^{(m)},\mu_1,...\ ,\mu_K.\\ &\qquad\qquad Compute\ \ cost\ \ function(distortion)\\ &\qquad\qquad\qquad J(c^{(1)},...\ ,c^{(m)},\mu_1,...\ ,\mu_K)\\ &\qquad\qquad\}\\\ \\ &Pick\ \ clustering\ \ that\ \ gave\ \ lowest\ \ cost\ \ J(c^{(1)},...\ ,c^{(m)},\mu_1,...\ ,\mu_K) \end{aligned} Random initialization:for i=1 to 100{Randomly initialize K–means.Run K–means.Get c(1),... ,c(m),μ1,... ,μK.Compute cost function(distortion)J(c(1),... ,c(m),μ1,... ,μK)}Pick clustering that gave lowest cost J(c(1),... ,c(m),μ1,... ,μK)
- 假如决定运行 K 均值算法 100 次,那么需要执行这个循环 100 次,典型的运行次数一般在 50 到 1,000 之间。假设决定运行 100 次,这意味着要随机初始化 K 均值算法,对于这 100 次中每一次随机初始化都运行 K 均值算法,会得到一系列聚类结果和一系列聚类中心,然后可以计算畸变函数 J,用得到的聚类分配和聚类中心来计算这个代价函数。最后,完成整个过程 100 次之后会得到 100 种分类这些数据的方法。
- 最后要做的就是在所有这 100 种分类数据的方法中选取代价(畸变值)最小的一个。
- 事实证明,如果运行 K 均值算法时,所用的聚类数相当小(如果聚类数在2到10之间),那么多次随机初始化通常能够保证能得到较好的局部最优解、更好的聚类。
- 但是如果 K 非常大的话(如果 K 比 10 大很多),如果想要找到成百上千个聚类,那么多次随机初始化就不会有太大改善,更有可能第一次随机初始化就会得到相当好的结果,多次随机初始化可能会得到稍微好一点的结果,但是不会好太多。但是在聚类数相对较小的情况下,特别是如果有 2、3 或 4 个聚类的话,随机初始化会有较大的影响,可以保证很好地最小化畸变函数,并且能得到一个很好的聚类结果。
五、选取聚类数量(Choosing the number of clusters)
- 主要内容: 如何去选择聚类数量(参数 K 的值),最常用的方法是观察可视化的图或者观察聚类的输出等等。
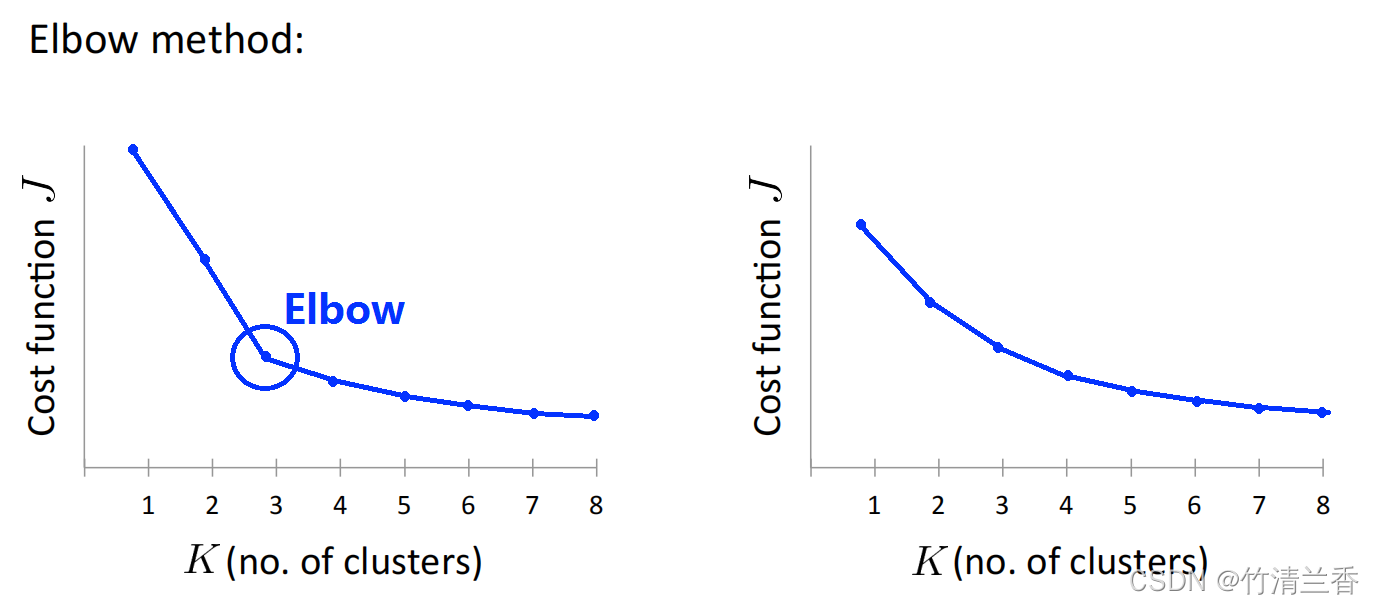
1. 肘部法则(the Elbow Method)
-
现在人们的主要想法是手动选择聚类数目。选择聚类数量并不容易,很大程度上是因为通常在数据集中有多少个聚类是不清楚的。看这样一个数据集:
-
有些人可能会觉得上面的数据中有 4 个聚类(蓝色),而另一些人可能觉得是 2 个(红色)。观察类似这样的数据集,真实的聚类数相当地模棱两可,并非只有一个正确的答案。这就是无监督学习的一部分,数据没有标签,因此并不总是有一个明确的答案,也因为这个原因,用一个自动化的算法来选择聚类数量是很困难的。
-
当人们在讨论选择聚类数量的方法时,可能会谈到一个方法,叫做 “肘部法则(the Elbow Method)” ,其要做的是改变K,也就是聚类总数,先用一个类来聚类,这就意味着所有的数据都会分到一个类里,然后计算代价函数,即畸变函数 J,对应着下图(左)中曲线的起点。
-
随着聚类数量的增多,畸变值下降,可能会得到一条类似于下图(左)中的曲线。如果观察这条曲线,“肘部法则”所做的就是观察这个图,可以看到这条曲线有一个“肘部”,可以发现这种模式从 1 到 2,从 2 到 3,畸变值迅速下降,到了肘部(K=3),在此之后,畸变值就下降的非常慢,看上去,也许使用3个类来进行聚类是正确的,这时因为这个点是曲线的拐点(the elbow),一开始畸变值下降地很快直到 K 等于 3,再之后就下降得很慢,那么就选 K 等于 3。当应用“肘部法则”的时候,如果得到了一个像下图(左)这样的图,那么这将是一种用来选择聚类个数的合理方法。
-
事实证明,“肘部法则”并不那么常用,原因之一是在实际运用到聚类问题上时,往往最后会得到一条看上去相当模糊的曲线(上图右),如果观察上面这个图,也许没有一个清晰的拐点,看上去畸变值是连续下降的,可能是3、4、5。
-
在实际操作中,图像如果看起来像之前那个带拐点的非常好了,它会给一个清晰的答案,但是也有很多时候,最终得到的图像是上面那个没有清晰拐点的,这种情况下,用这个方法来选择聚类数目是很困难的。
-
小结:“肘部法则”是一个值得尝试的方法,但是不能期望它能够解决任何问题。
2. 以后续目的为聚类数量的取值依据
-
最后还有另外一种选择 K 值的思路。通常人们使用 K 均值聚类是为了得到一些聚类用于后面的目的,或者说下游目的(downstream purpose)。也许想用 K 均值聚类来做市场分割(就像之前说的 T 恤尺寸的例子),或者来更好地组织计算机集群,或者为了别的目的。如果后续目的,如市场分割,能给我们一个评估标准,那么决定聚类的数量更好的方式是看哪个聚类数量能更高地应用于后续目的。
-
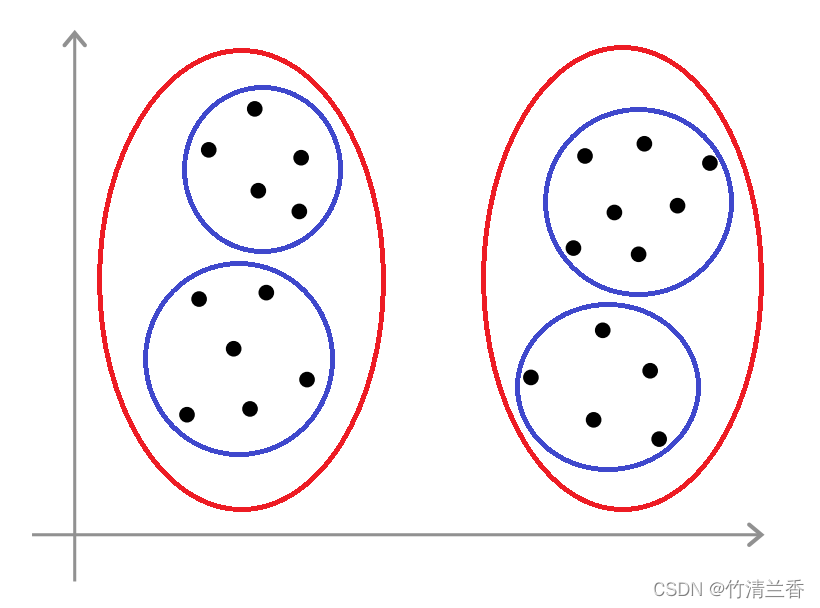
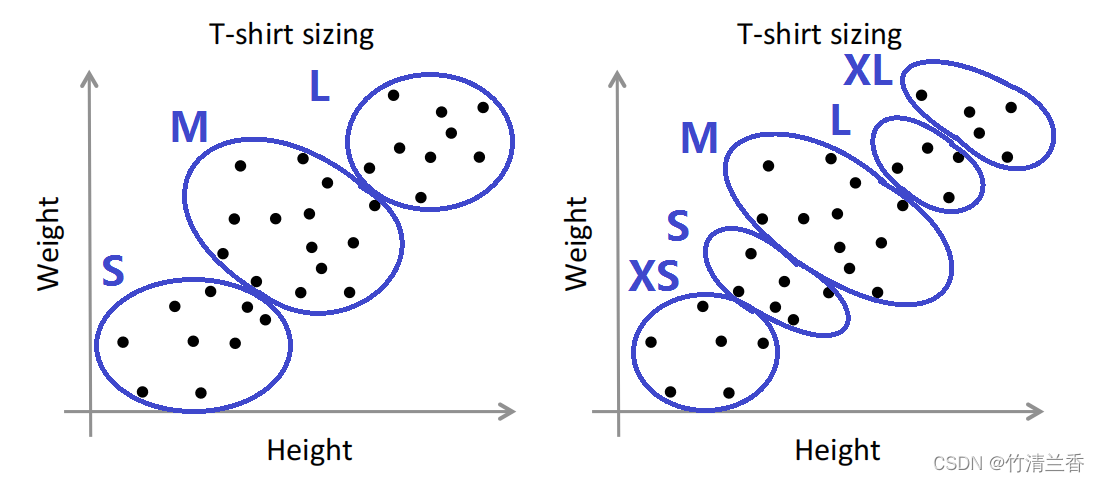
用一个具体的例子来解释。还是来看T恤尺寸的例子,要决定是否需要 3 种 T 恤尺寸,因此选择 K 等于 3(小号、中号、大号),或者可以选择 K 等于 5(特小号、小号、中号、大号、特大号),所以可以有3种T恤尺寸或者5种,当然也可以有4种尺寸(这里为了简洁只展示 3 和 5 两种情况)。
-
分别用 K 等于 3 和 5 来跑 K 均值得到如下结果:
-
这个例子的一个好处就是,它给了我们另一种方法来选择我们想要的聚类数量究竟是 3、4 还是 5。具体而言,我们可以从 T 恤商业的角度来思考,并且问自己“如果我有 5 个分类,我的 T 恤能否很好地满足顾客的需求?我可以卖出多少 T 恤?客户是否会感到满意?”,其中真正有意义的是从 T 恤商业的角度去考虑。这个例子说明怎样用后续的下游目的,比如决定生产什么样的 T 恤作为评价标准来选择聚类数量。
总结
- 本文主要介绍了聚类算法的相关内容。首先复习了无监督学习的内容以及聚类算法的应用。其次从直观上介绍了 K 均值算法,以及该算法的规范表达和具体的应用(分离不佳的簇)。
- 在优化目标的部分提到了失真代价函数,同时也对 K 均值算法进行了补充。
- 随机初始化 K 均值算法适用于聚类数目相对较小的聚类方法,有时可以帮助我们找到对数据进行聚类的更好的方法,即便是聚类数目较大,该方法也可以 K 均值算法一个合理的起始点来找到一个好的聚类结果。
- 聚类数量 K 仍然是通过手动、人工输入或者用经验来决定。一种可以尝试的方法是使用“肘部原则”,但不会期望它每次都有效果。选择聚类的更好的思路是去问自己,运行 K 均值聚类的目的是什么,然后想一想聚类数量 K 取哪一个值能更好地服务于后续的目的。