python爬虫
所用示例
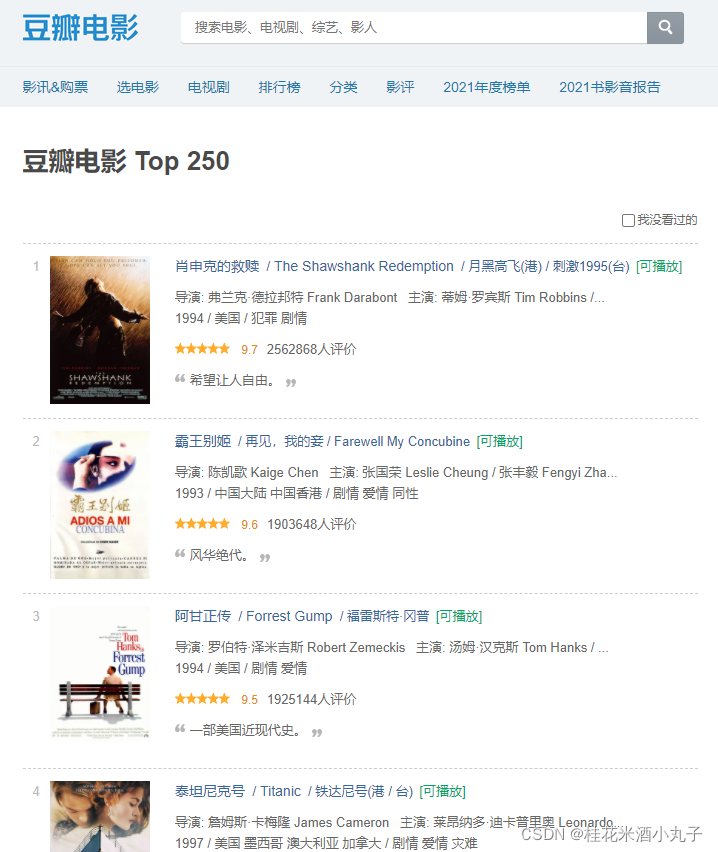
1.任务:爬取豆瓣top250
2.网址:https://movie.douban.com/top250
3.爬取内容:电影名称、豆瓣评分、评价数、电影概况、电影链接
一、准备工作
(一)找网址
https://movie.douban.com/top250
每一页的链接:url = ‘https://movie.douban.com/top250?start=’+ str(page*25)+’&filter=’(page是页数-1)
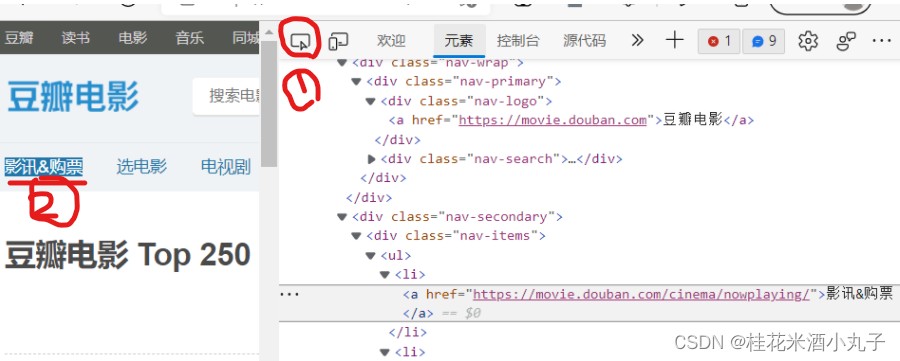
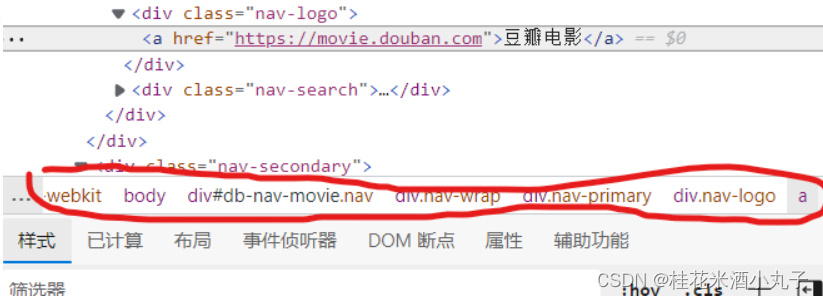
(二)找数据的位置:
方法一:元素(element)
1.Fn+F12
2.点击element
3.点击网页内容:
4.我们根据层级结构确定数据位置:
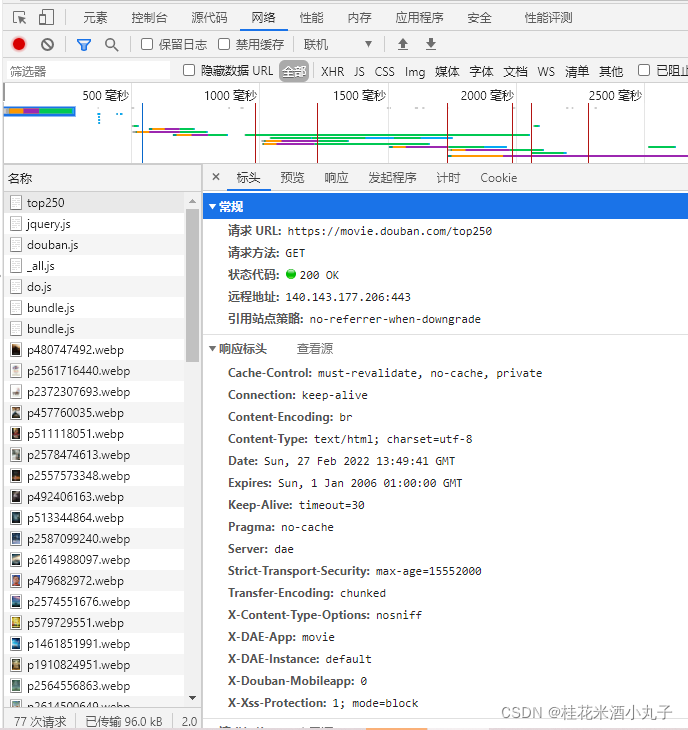
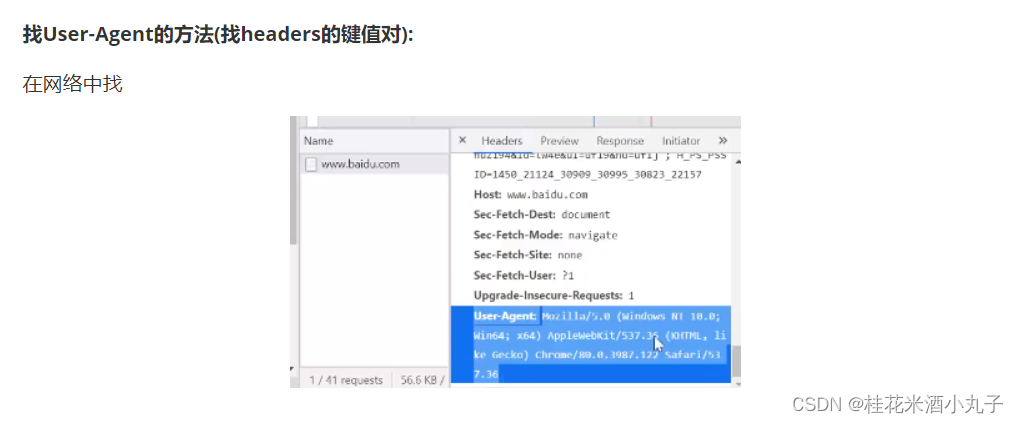
方法二:网络(network)+刷新
headers:我们发送的请求
response:返回的请求
可以看到请求头等信息
(三)编码规范
1.一般python程序第一行要加入(这样可以在代码中包含中文)
#-*-coding:utf-8-*-
或者
#coding=utf-8
2.用于测试程序:(定义程序入口)
def main():
print("hello")
if __name__=="__main__":#下划线有两根,当程序执行时调用函数
main()
(四)引入模块
1.引入自己写的模块:
2.引入系统的模块
(1)安装库:
方法1:点击Terminal——输入pip install 库名
方法2:File->settings->Project douban->Project Intrpreter->±>搜索要安装的包->Install Package
(2)引入库:
from bs4 import BeautifulSoup #网页解析,获取数据beautifulsoup4
import re #正则表达式,文字匹配
import urllib.request,urllib.error #指定URL,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行SQLite数据库操作
二、构建流程
step1 爬取网页
baseurl = 'https://movie.douban.com/top250?start='
datalist = getData(baseurl)
def getData(baseurl):
datalist = 网页中获取的数据
return datalist
step2 解析数据
边爬边解析,逐一解析
step3 保存数据
savepath = '.\\豆瓣电影Top'
def saveData(savepath):
……
三、urllib
(一)把网页中的源代码封装到一个对象中
import urllib.request
#获取一个get请求
response = urllib.request.urlopen("http://www.baidu.com") #封装在response中
print(response.read().decode('utf-8')) #decode('utf-8')对获取到的网页代码解码,防止出现中文乱码,打出网页源码
#获取一个post请求(用于模拟登录(密码,用户))
用httpbin.org
import urllib.parse #解析器,解析键值对
data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding = "utf-8")#表单,将键值对信息封装为二进制的包,encoding = "utf-8"封装方式
response = urllib.request.urlopen("http://httpbin.org/post",data = data)
print(response.read().decode('utf-8'))
(二)超时问题
try:
response = urllib.request.urlopen("http://httpbin.org/post",timeout=0.01)#时间超过0.01秒
print(response.read().decode('utf-8'))
except urllib.error.URLError as e:
print("time out!")
(三)响应头的问题(伪装成浏览器)
url = "https://httpbin.org/post"
headers = {"User-Agent":"……"}
data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding = "utf-8")
req = urllib.request.Request(url=url,data=data,headers=headers,method='post')#封装,模拟成真的浏览器
response = urllib.request.urlopen(req)#封装
print(response.read().decode("utf-8"))
(四)获取数据
#爬取网页
def getData(baseurl):
dataist = []
for i in range(0,10):#调用获取页面信息的函数,10次
url = baseurl + str(i*25)
html = askURL(url)#保存获取到的网页源码
return datalist
#得到指定的一个URL的网页内容
def askURL(url):
head = {
"User-Agent":"……"
}#用来伪装,模拟浏览器头部信息
request = urllib.request.Request(url,headers=head)#携带headers去访问url
try:
response = urllib.request.urlopen(request)#获取整个网页的信息
html = response.read().decode("utf-8")#读取信息(网页源码)
except urllib.error.URLError as e:#捕获错误
if hasattr(e,"code"):
print(e.code)#打印code,看编码有什么问题
if hasattr(e,"reason"):
print(e.reason)#打印出没有成功的原因
return html
四、BeautifulSoup(获取网页指定内容)
(一)概述
1.作用:获取网页指定内容
2.引用
from bs4 import BeautifulSoup
(二)操作
1.
from bs4 import BeautifulSoup
file = open("./baidu.html","rb")#baidu.html是存有已经爬取并存下来的网页源代码的文件
html = file.read()#网页源代码
bs = BeautifulSoup(html,"html.parser")#解析html,解析器为html.parser,解析为树形结构
print(bs.a)
print(bs.title)#tag打印出标签tag及其内容:只能拿出找到的第一条
print(bs.title.string)
print(type(bs.title.string))#NavigableString 打印出标签里的内容(字符串)
print(bs.a.attrs)#拿到标签里的所有属性
print(bs)#整个文档的内容
print(bs.a.string)#Comment 是一个特殊的NavigableString,输出的内容不包含注释符号
2.文档的遍历:
print(bs.head.contents)#将tag(此处的tag是head)的子节点以列表的方式输出
print(bs.head.contents[1])#用列表所用来获取它的第1个元素
注:详情可搜索:遍历文件树
3.文档的搜索:
#字符串遍历
t_list = bs.find_all("a")#查找所有a标签的超链接
print(t_list)
#正则表达式
t_list=bs.find_all(re.compile("a"))#找出含有a字母的标签下的所有链接
print(t_list)
#传入一个函数,根据函数要求来搜索
def name_is_exists(tag)
return tag.has_attr("name")
t_list = bs.find_all(name_is_exists)
print(t_list)
#指定参数经行搜索kwargs
t_list=bs.find_all(id="head")
t_list=bs.find_all(class_=True)
t_list=bs.find_all(href="http://……")
#找出含有响应内容的文本
t_list=bs.find_all(text = "地图")#找出含有“地图”的文本
t_list=bs.find_all(text = ["地图","贴吧"])
t_list=bs.find_all(text=re.compile("\d"))#用正则表达式查出所有含数字的文本内容(标签里的字符串
#limit参数
t_list = bs.find_all("a",limit=3)#获取三条标签为a的文档
#css选择器
t_list = bs.select("title")#通过标签查找
t_list = bs.select(".mnav")#通过类名查找(class="mnav")
t_list = bs.select("#u1")#按照id来查找(id="u1")
t_list = bs.select("a[class='bri']")#通过属性来查找(<a class="bri" href="……"……)
t_list = bs.select("head>title")#通过子标签查找(<head>……<title>……)
t_list = bs.select(".mnav ~ .bri")#兄弟节点
print(t_list[0].get.text())#拿第一个文本元素
五、正则表达式(字符串的格式要求)
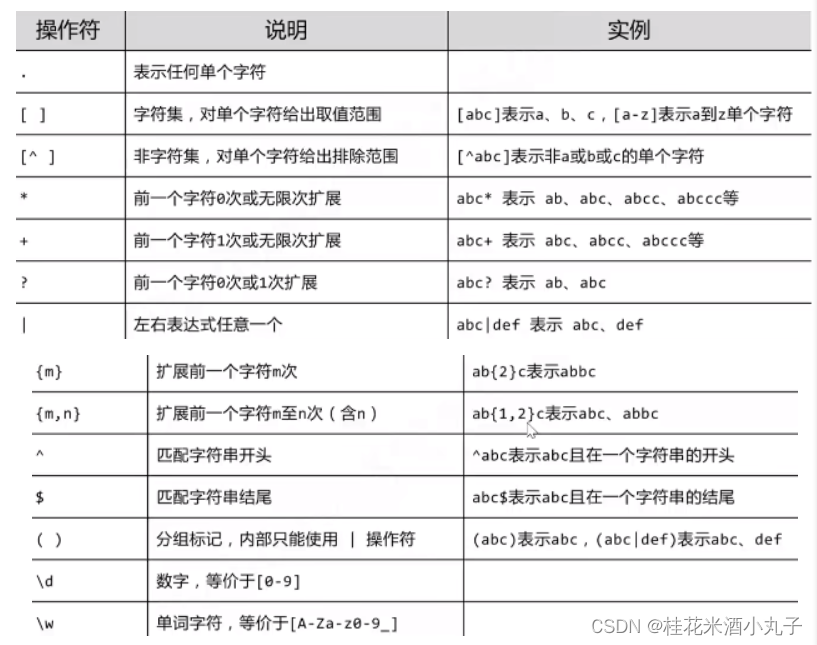
(一)正则表达式的常用操作符
注意:可以网上搜索“史上最全正则表达式大全”
(二)re库(解决正则表达式匹配问题)
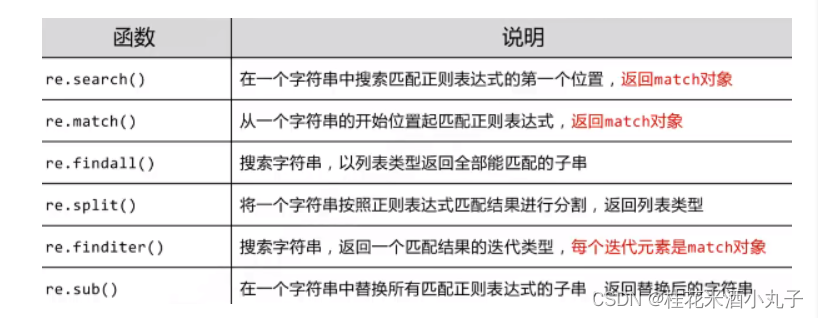
1.作用
2.模式限制
①re.l 忽略大小写

②re.S 扩大字符的判断范围
3.代码
import re
#创建模式对象
pat = re.compile("AA")#此处的AA是正则表达式,用来验证其他的字符串
#校验
#写法1
m1 = pat.search("CBA")#""中放被校验的内容
print(m1)
m2 = pat.search("CBAA")
print(m2)
m3 = pat.search("AACBAA")
print(m3)
#写法2
m = re.search("asd","Aasd")
print(m)
#找到所有匹配的内容
print(re.findall("a","ASDaBDDa"))#第一个""中放规则,后面的""放字符串
print(re.findall("[A-Z]+","ASDaBDDa"))
#风格替换
print(re.sub("a","A","abcdef")#找到a用A替换,在第三个字符串中查找
注意:建议在被比较的字符串前面加上一个r,防止转义字符问题,eg:
a = "\aabs-\'"
print(a)
(三)应用
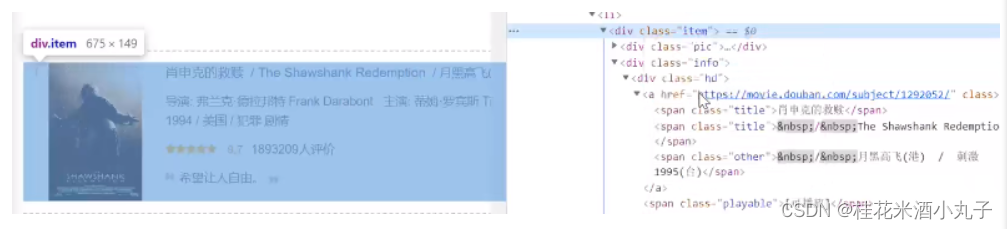
找要爬取的内容的源代码:
①影片内容信息
②影片链接
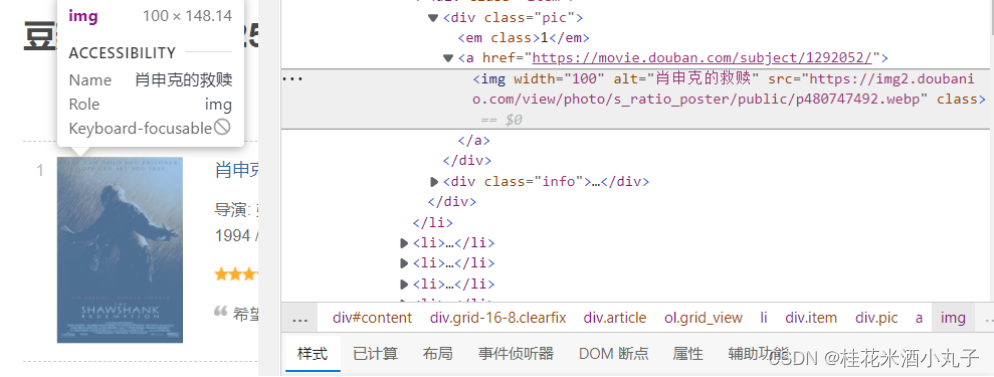
③影片图片
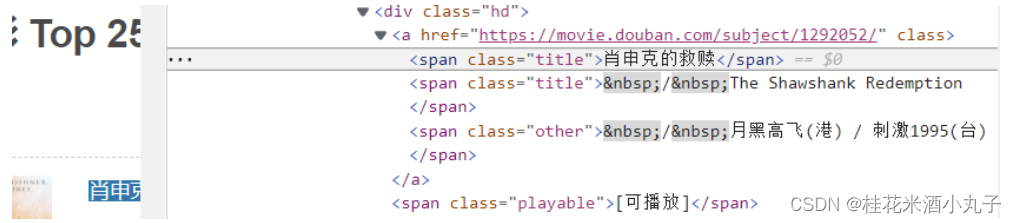
④影片名字
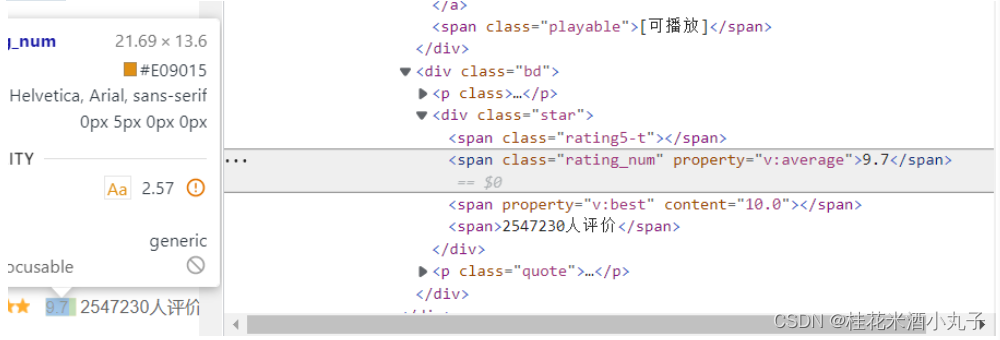
⑤评分
⑥评价人数
⑦一句话的评价
⑧电影信息
注意:复制源代码:右键->edit as HTML

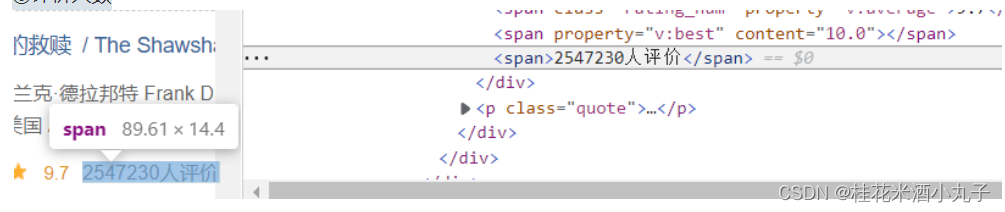

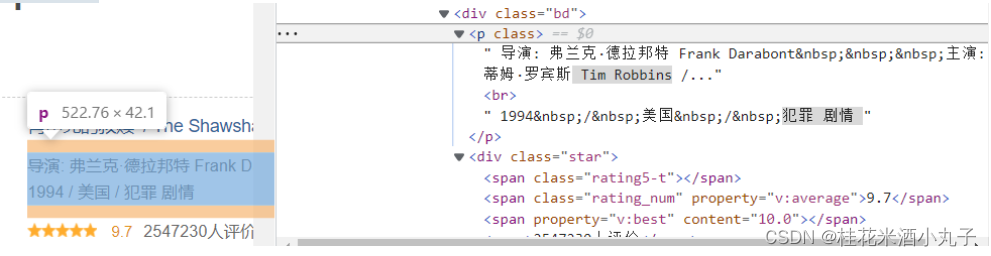
代码:
def main():
baseurl = "http://movie.douban.com/top250?start="
datalist = getData(baseurl)
#影片详情信息的规则
findLink = re.compile(r'<a href="(.*?)">')#创建正则表达式对象,表示规则(字符串模式)②
findImgSrc = re.compile(r'<img.*src="(.*?)"',re.S)#找图片的内容,re.S让换行符包含在字符中,忽略换行符号③
findTitle = re.compile(r'<span class="title">(.*)</span>')#影片片名
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')#影片评分
findJudge = re.compile(r'<span>(\d*)人评价</span>')#评价人数
findInq = re.compile(r'<span class="inq">(.*)</span>')#一句话的评价
findBd = re.compile(r'<p class="">(.*?)</p>',re.S)#电影信息
#爬取网页
def getData(baseurl):
datalist = []
for i in range(0,10): #调用获取页面信息10次
url = baseurl = str(i*25)
html = askURL(url) #保存获取到的网页源码
#逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.findall('div',class_="item"): #查找符合要求(<div class="item">……)的字符串,形成列表(内容含有源代码)①
data = []#保存一部电影的所有信息
item = str(item)
link = re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串,[0]表示只要符合条件的第一个,link=一页中所有电影的超链接
data.append(link)#把找到的链接加进去
ImgSrc = re.findall(findImgSrc,item)[0] #图片信息
data.append(ImgSrc)#把找到的图片加进去
titles = re.findall(findTitle,item) #片名可能只有一个中文名没有外文名,也可能都有
if(len(titles)==2):
ctitle = titles[0]
data.append(ctitle)#添加中国名
otitle = titles[1].replace("/","")#去掉无关的符号
data.append(ctitle)#添加外文名
else:
data.append(titles[0])
data.append(' ')#外国名留空
rating = re.findall(findRating,item)[0] #打分
data.append(rating)#把找到的分数加进去
judgeNum = re.findall(findJudge,item)[0] #评价人数
data.append(judgeNum)#添加评价人数
inq = re.findall(findInq,item) #添加概述
if len(inq)!=0:
inq = inq[0].replace("。","")#去掉句号
data.append(inq)#概述
else
data.append(" ")#留空
bd = re.findall(findBd,item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?'," ",bd)#去掉<br/>
bd = re.sub('/'," ",bd)#替换\
data.append(bd.strip())#bd.strip()去掉前后的空格
datalist.append(data)#处理好一部电影的信息就存入datalist
return datalist
六、保存数据
1.txt保存
(1)打开
打开方式:open(文件名,访问模式)
访问模式:
例:

f = open('text.txt','w')#w模式(写模式),文件不存在就打开
注意:不存在text的open后新建在当前工程下
(2)关闭
关闭方式:close()
f.close()
(3)写入
写入方式:write
f.write("hello,world!")
(4)读取
操作1:按字符读(read())
f.read(5)#读取5个字符
注:read并不是每次都从开头读取,执行一次就往后移
例子:
f = open("text.txt",'r')
content = f.read(5)
print(content)#打出hello
content = f.read(5)
print(content)#打出,worl
f.close()
操作2:读取整个文档(列表)(readlines())
f = open("text.txt",'r')
content = f.readlines()
print(content)#打出整个文档
i=1
for temp in content:
print("%d:%s"%(i,temp))
i+=1
#一行一行读取
f.close()
操作3:按行读取(readline())
f = open("text.txt",'r')
content = f.readline()
print(content,end='')#打出第一行,end=''相当于不换行
content = f.readline()
print(content)#打出第二行
f.close()
注意:其他操作import os可以自行查找补充
2.Excel保存
(1)库
xlwt
(2)基本思路
以utf-8编码创建一个Excel对象
创建一个sheet表
往单元格写入内容
保存表格
(3)代码
表格的坐标位置
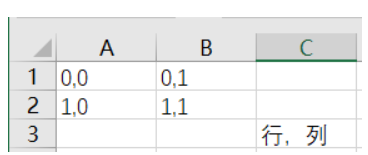
import xlwt
workbook = xlwt.Workbook(encoding="utf-8") #创建workbook对象
worksheet = workbook.add_sheet("sheet1")#创建名为sheet1的工作表
worksheet.write(0,0,'hello') #写入数据.write(行,列,参数内容)
workbook.save("student.xls") #保存数据表
九九乘法表写入

(4)应用
savepath = "豆瓣电影Top250.xls"
def saveData(datalist,savepath):
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet("豆瓣电影Top250",cell_overwrite_ok=True)#创建名工作表
col = ("电影详情链接","图片链接","影片中文名","影片外文名","评分","评价书","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i])#列名
for i in range(0,250):
data = datalist[i]
for j in range(0,8)
sheet.write(i+1,j,data[j])
workbook.save(savepath) #保存数据表
3.Pymysql保存
(1)下载
pip install pymysql
(2)链接数据库
import pymysql
conn = pymysql.connect( # 创建数据库连接
host='10.10.11.131', # 要连接的数据库所在主机ip
user='chb', # 数据库登录用户名
password='123456!', # 登录用户密码
database='base1' # 数据库的名称
)
(3)创建游标
cursor = conn.cursor()#游标
cursor.execute(操作)#可以用游标进行各种操作
(4)创建数据库、表
①创建数据库
# -*- coding: utf-8 -*-
import pymysql
conn = pymysql.connect( # 创建数据库连接
host='10.10.11.131', # 要连接的数据库所在主机ip
user='chb', # 数据库登录用户名
password='123456!', # 登录用户密码
charset='utf8' # 编码,注意不能写成utf-8
)
cursor = conn.cursor()
cursor .execute("create database test_db character set utf8;")
# 执行完之后别忘了关闭游标和数据库连接
cursor.close()
conn.close()
②创建数据表
# -*- coding: utf-8 -*-
import pymysql
conn = pymysql.connect( # 创建数据库连接
host='10.10.11.131', # 要连接的数据库所在主机ip
user='chb', # 数据库登录用户名
password='123456!', # 登录用户密码
database='test_db', # 连接的数据库名,也可以后续通过cursor.execture('user test_db')指定
charset='utf8' # 编码,注意不能写成utf-8
)
cursor = conn.cursor() # 创建一个游标
# 需要执行的创建表的sql语句
sql = """
create table book(
bookid int auto_increment primary key ,
bookname VARCHAR(255) not null ,
authors VARCHAR(255) not null ,
year_publication YEAR not null
);
"""
cursor.execute(sql) # 使用游标执行sql
# 执行完之后别忘了关闭游标和数据库连接
cursor.close()
conn.close()
(5)增、删、改、查
①插入
(1.一次插入一条记录execute()
cursor.execute('insert into 数据表名(键值对) values(数据类型);',(插入的数据内容))
cursor.execute('insert into book(bookname, authors, year_publication) values("%s", "%s", %s);' % ('Python从入门到放弃', '乔布斯', 2019))
conn.commit()
import pymysql
user = '小黑'
pwd = '06161086'
sql = "insert into userinfo(user,password) values(%s,%s)"#增
cursor.execute(sql,user,pwd)#返回值r为受影响的行数
conn.commit()
(2.一次插入多条记录executemany()
data = [
('21天完全入门Java', '扎克伯格', 2018),
('Linux学习手册', '李纳斯', 2017),
('MySQL从删库到跑路', '比尔盖茨', 2018),
]
cursor.executemany('insert into book(bookname, authors, year_publication) values("%s", "%s", %s);', data)
conn.commit()
②更新
cursor.execute('update book set authors=%s where bookname=%s;', ["马云", "Python从入门到放弃"])
conn.commit()
③查询
(1.fetch操作
Ⅰ查询所有记录:fetchall()
cursor.execute('select * from 表名;')
books = cursor.fetchall()
cursor.execute('select * from book where bookid < %s;', [4])
books = cursor.fetchall()
print(books)#输出结果以元组形式保存,每条记录也是一个元素输出内容为(1, 'Python从入门到放弃', '马云', 2019), (2, 'Python从入门到放弃', '马云', 2019), (3, '21天完全入门Java', '扎克伯格', 2018))
Ⅱ查询指定数量的记录:fetchmany(要记录的条数)
cursor.execute('select * from book where bookid < %s;', [4])
books = cursor.fetchmany(2)
print(books)#输出结果为((1, 'Python从入门到放弃', '马云', 2019), (2, 'Python从入门到放弃', '马云', 2019))
Ⅲ取第一条记录:fetchone()
cursor.execute('select * from book where bookid < %s;', [4])
books = cursor.fetchone()
print(books)#输出结果(1, 'Python从入门到放弃', '马云', 2019)
(2.游标(pymysql还提供了DictCursor、SSCursor、SSDictCursor这几类游标。)
ⅠDicCursor(返回的数据以字典形式保存)
cursor = conn.cursor(pymysql.cursors.DictCursor) # 创建一个字典游标
cursor.execute('select * from book where bookid < %s;', [3])
books = cursor.fetchall()
print(books)
cursor.execute('select * from book where bookid < %s;', [3])
book_one = cursor.fetchone()
print(book_one)
输出结果:
[{‘bookid’: 1, ‘bookname’: ‘Python从入门到放弃’, ‘authors’: ‘马云’, ‘year_publication’: 2019},
{‘bookid’: 2, ‘bookname’: ‘Python从入门到放弃’, ‘authors’: ‘马云’, ‘year_publication’: 2019}]
{‘bookid’: 1, ‘bookname’: ‘Python从入门到放弃’, ‘authors’: ‘马云’, ‘year_publication’: 2019}
ⅡSSCursor和SSDictCursor(流式游标,陆陆续续一条一条得返回查询数据,用于内存低、网络带宽小、数据量大的应用场景中。)
cursor = conn.cursor(pymysql.cursors.SSCursor) # 创建一个流式游标
cursor.execute('select * from book;')
book = cursor.fetchone()
while book:
print(book)
book = cursor.fetchone()
输出结果:
(1, ‘Python从入门到放弃’, ‘马云’, 2019)
(2, ‘Python从入门到放弃’, ‘马云’, 2019)
(3, ‘21天完全入门Java’, ‘扎克伯格’, 2018)
(4, ‘Linux学习手册’, ‘李纳斯’, 2017)
(5, ‘MySQL从删库到跑路’, ‘比尔盖茨’, 2018)
④删除
(1.删除一条记录
cursor.execute('delete from book where bookid=%s;', [1])
(2.删除多条记录
cursor.executemany('delete from book where bookid=%s;', [[2], [4]])
conn.commit()#bookid为2和4的记录已经被删除