在这个数据驱动的时代,机器学习已经成为创造和预测的强大工具。本文将带你走进循环神经网络(RNN)的世界,教你如何训练一个AI模型来创作歌词。无论你是Python新手还是机器学习爱好者,本文都将为你提供一个实践的平台,让你能够亲手实现一个创作歌词的模型。对于有机器学习基础的读者,本文可作为参考,助力你构建预测歌词的模型,甚至启发你将此方法拓展到其他领域的预测模型开发中
代码和仓库地址:predicteLyrics: 使用rnn模型预测周杰伦的歌词
1. 环境配置
在开始之前,请确保你的开发环境中已安装以下必要的Python库:
-
PyTorch
pip install torch torchvision2. 理解RNN模型
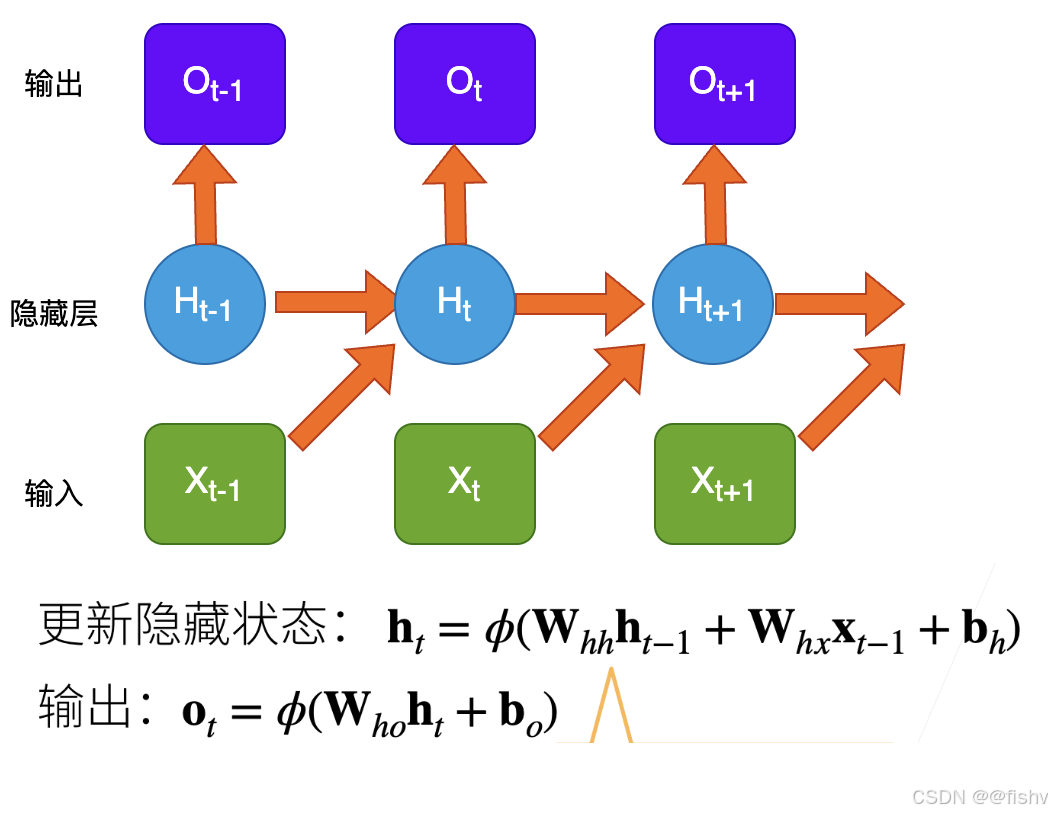
RNN模型特别适合处理序列数据,如时间序列或文本。在RNN中,每个时间点的输出不仅依赖于当前的输入,还依赖于前一个时间点的隐藏状态。这种结构使得RNN能够捕捉到数据的时序特性。
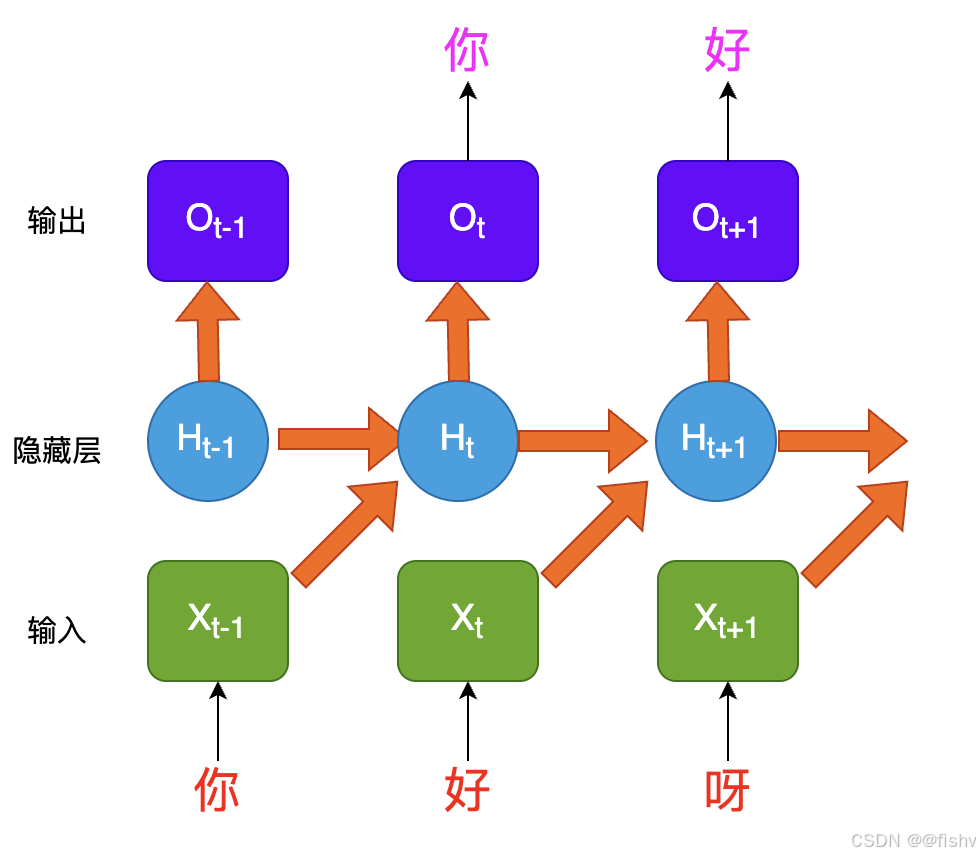
3. 数据处理
我们将使用周杰伦的歌词数据集,从他的第一张专辑《Jay》到第十张专辑《跨时代》。
在获取数据集后,首先进行解压操作,随后从文件中读取数据。读取的数据前 10 行

展示了数据的初始形态。为了便于模型处理,我们需要建立字符索引。通过这种方式,我们可以利用索引在 idx_to_char [] 中准确找到对应字符,反之,通过字符在 char_to_idx 字典中能快速获取其索引。这一过程是数据处理中的关键环节,它建立了字符与索引之间的映射关系,为后续的数据处理和模型训练提供了便利,确保数据在模型中的准确表示和处理。

import zipfile
def data_load(range, file_path):
"""
加载并处理文本数据。
:param range: 要加载的文本长度
:param file_path: 压缩文件路径
:return: 处理后的文本、字符到索引的映射、索引到字符的映射、词汇表大小
"""
# 尝试打开zip文件来读取文本数据
try:
with zipfile.ZipFile(file_path) as zin:
with zin.open("jaychou_lyrics.txt") as f:
texts = f.read().decode('utf-8')
except (zipfile.BadZipFile, FileNotFoundError) as e:
# 如果文件不是zip文件或找不到文件,则打印错误并返回None值
print(f"Error reading file: {e}")
return None, None, None, None
# 如果指定的文本长度超过实际文本长度,则调整为实际文本长度
if range > len(texts):
range = len(texts)
# 将文本中的换行符替换为空格,并截取前range个字符
texts = texts.replace('\n', ' ')
texts = texts[:range]
# 创建字符到索引的映射和索引到字符的映射
idx_to_char = list(set(texts))
char_to_idx = {c: i for i, c in enumerate(idx_to_char)}
# 计算词汇表大小
vocab_size = len(idx_to_char)
# 返回处理后的文本、字符到索引的映射、索引到字符的映射和词汇表大小
return texts, idx_to_char, char_to_idx, vocab_size
4. 数据采样
在模型训练过程中,数据采样是一个重要步骤。每次训练需针对一个小批量的样本进行,其中一个样本是由连续的一段字符构成,例如 [' 想 ', ' 要 ', ' 有 ']。我们采用随机取样的方法从数据集中获取小批量数据。在此过程中,有两个关键参数:batch_size 和 num_steps。batch_size 表示每个小批量的样本数量,其大小的选择需要综合考虑模型的训练效率和硬件资源限制。若 batch_size 过大,可能导致内存溢出或模型训练不稳定;若过小,则会降低训练效率。num_steps 指的是一个样本包含的字符数量,它与 RNN 模型的结构密切相关。由于 RNN 模型依赖前一次的隐藏状态(Ht - 1)来初始化下一个时间步的隐藏状态(Ht)和计算输出结果(Ot),而随机取样可能导致相邻批次的样本在原始序列中的位置不相邻,因此每次随机采样前都需要重新初始化隐藏状态,以确保模型训练的准确性。
import random
import torch
def data_iter_random(texts_idx, batch_size, num_steps):
"""
创建一个随机迭代器,用于批量处理文本数据。
参数:
texts_idx (list of int): 文本数据的索引列表。
batch_size (int): 批量大小。
num_steps (int): 每个样本的步数(长度)。
生成器输出:
(torch.tensor, torch.tensor): 输入数据X和目标数据Y的批量,均为张量形式。
"""
# 计算可以生成的样本数量
num_examples = (len(texts_idx) - 1) // num_steps
# 计算每个epoch中包含的批量数量
epoch_size = num_examples // batch_size
# 生成样本索引列表
example_idx = list(range(num_examples))
# 打乱样本索引顺序,以增加数据的随机性
random.shuffle(example_idx)
def _data(pos):
"""
根据位置提取数据。
参数:
pos (int): 起始位置索引。
返回:
list of int: 从起始位置开始,长度为num_steps的数据列表。
"""
return texts_idx[pos: pos + num_steps]
# 遍历每个批量
for i in range(epoch_size):
# 计算当前批量的起始索引
i = i * batch_size
# 提取当前批量的样本索引
batch_idx = example_idx[i: i + batch_size]
# 根据样本索引提取输入数据X
X = [_data(j * num_steps) for j in batch_idx]
# 根据样本索引提取目标数据Y,目标数据是输入数据的下一个字符
Y = [_data(j * num_steps + 1) for j in batch_idx]
# 以张量的形式输出当前批量的输入数据X和目标数据Y
yield torch.tensor(X), torch.tensor(Y)
5. 创建模型
创建一个包含 256 个隐藏单元的单隐藏层循环神经网络。在这个模型中,输出结果会再经过一层全连接层。增加这一层全连接层的目的在于获取每个词的预测概率。在模型构建过程中,需要对输入数据进行热编码(one - hot)。热编码将输入数据转化为一种更适合模型处理的形式,便于模型准确地预测结果。这种编码方式在模型的输入处理环节中具有重要意义,它使得数据的表示更加规范和易于处理,为模型的准确预测提供了有力支持。
import torch
from torch import nn
from torch.nn import functional as F
class RNNModel(nn.Module):
"""
定义一个基于RNN的模型类,用于处理序列数据。
参数:
- input_size: 输入数据的特征维度(词向量长度)
- num_hiddens: 隐藏层单元的数量
- num_layers: RNN层的数量
"""
def __init__(self, input_size, num_hiddens, num_layers, **kwargs):
super(RNNModel, self).__init__(**kwargs)
# 初始化RNN层
self.rnn = nn.RNN(input_size, num_hiddens, num_layers)
# 初始化全连接层,用于输出预测结果
self.dense = nn.Linear(num_hiddens, input_size)
# 保存隐藏单元和层数量,供后续使用
self.num_hiddens = num_hiddens
self.num_layers = num_layers
def forward(self, inputs, state):
"""
前向传播函数,处理输入数据并生成输出。
参数:
- inputs: 输入数据序列
- state: RNN的初始隐藏状态
返回:
- output: RNN的输出
- state: RNN的最终隐藏状态
"""
# 调整输入数据的维度顺序,以符合RNN输入要求[时间步长, 批量大小, feature]
inputs = inputs.permute(1, 0)
# 将输入数据进行独热编码,并转换为浮点数类型
inputs = F.one_hot(inputs, num_classes=self.dense.out_features).float()
# 通过RNN层进行数据处理
output, state = self.rnn(inputs, state)
# 调整输出数据的形状,以便进行全连接层处理
output = output.view(-1, self.num_hiddens)
# 通过全连接层生成最终输出
output = self.dense(output)
return output, state
6. 训练并预测
在训练阶段,总共设置 201 个 epoch,一个 epoch 意味着对所有数据进行一次完整的训练。batch_size 设置为 32,即每次训练使用 32 个样本。num_step = 10,表示每个样本的长度为 10 个字符。同时,设置 prefix = ' 爱情 ',num_chars = 32,这意味着模型将以 “晴天” 为起始,创作长度为 32 个字符的歌词。
import torch
from data_loader import data_load
from data_iterator import data_iter_random
from model import RNNModel
from torch import nn
def predict(prefix, num_chars, model, idx_to_char, char_to_idx):
"""
使用训练好的RNN模型进行预测。
参数:
prefix (str): 预测的起始字符串。
num_chars (int): 预测的字符数。
model (RNNModel): 训练好的RNN模型。
idx_to_char (list): 索引到字符的映射。
char_to_idx (dict): 字符到索引的映射。
返回:
str: 预测的字符串。
"""
state = None
output = []
# 预热模型,即输入初始字符串
for char in prefix:
_, state = model(torch.tensor(char_to_idx[char]).unsqueeze(0).unsqueeze(0), state)
output.append(char_to_idx[char])
# 生成预测的字符
for _ in range(num_chars - len(prefix)):
X = torch.tensor(output[-1]).unsqueeze(0).unsqueeze(0)
(Y, state) = model(X, state)
output.append(int(Y.argmax(dim=1).item()))
return ''.join([idx_to_char[i] for i in output])
def train_and_predict_rnn(model, texts_idx, num_epochs, batch_size, num_steps, lr, idx_to_char, char_to_idx, prefix,
num_chars):
"""
训练RNN模型并进行预测。
参数:
model (RNNModel): RNN模型。
texts_idx (list): 文本数据的索引表示。
num_epochs (int): 训练的轮数。
batch_size (int): 批次大小。
num_steps (int): 时间步的长度。
lr (float): 学习率。
idx_to_char (list): 索引到字符的映射。
char_to_idx (dict): 字符到索引的映射。
prefix (str): 预测的起始字符串。
num_chars (int): 预测的字符数。
"""
trainer = torch.optim.Adam(model.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
loss_sum = 0
# 使用随机采样的数据迭代器进行训练
for X, Y in data_iter_random(texts_idx, batch_size, num_steps):
state = None
output, state = model(X, state)
Y = Y.transpose(0, 1).reshape(-1)
l = loss(output, Y.long())
trainer.zero_grad()
l.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
trainer.step()
loss_sum += l.item() * Y.shape[0]
print(f"epoch: {epoch}, loss: {loss_sum / len(texts_idx)}")
if epoch % 10 == 0:
print(predict(prefix, num_chars, model, idx_to_char, char_to_idx))
if __name__ == "__main__":
file_path = "./data/jaychou_lyrics.txt.zip"
texts, idx_to_char, char_to_idx, vocab_size = data_load(20000, file_path)
texts_idx = [char_to_idx[c] for c in texts]
model = RNNModel(input_size=vocab_size, num_hiddens=256, num_layers=1)
train_and_predict_rnn(model, texts_idx, 201, 32, 10, 0.01, idx_to_char, char_to_idx, "晴天", 32)
在实际训练过程中,模型运行速度较快,在不到 1 分钟内即可完成训练。从训练结果来看,虽然生成的歌词中存在部分句子不够通顺的情况,但其中不少词语组合是合理且符合语言逻辑的。若进一步增大数据集,或者增加模型的复杂度,有望获得更优的歌词创作结果,使生成的歌词在语法和语义上更加完善。
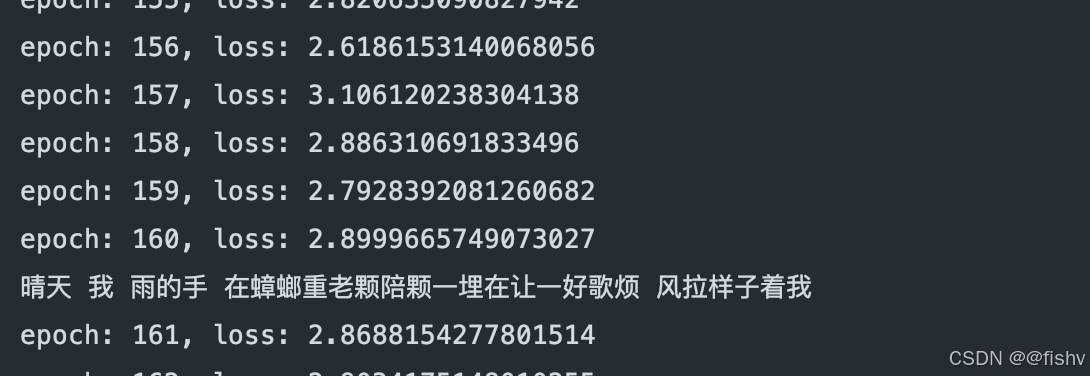
7.项目目录
结语
感谢您阅读本文,希望文中所阐述的内容能为您在循环神经网络的应用以及歌词创作模型的开发方面提供有益的参考和启发。如果你有任何问题或想要进一步探讨,欢迎在评论区留言。