目录
一、需求背景
本文要实现类似于知网的检索系统,但是面向的数据是纯英文。在近年的技术中,中文分词已经有了相当成熟的技术,典型代表是ik分词器,这常用于中文分词的场景。然而,对于英文分词的技术被掌握在外国大厂手中。而Elasticsearch中对于英文分词仅仅提供基于滑动窗口的方式,主观上可以看到这种方法会浪费大量的资源并且显得非常僵硬。本文提出一个初始的分词思路以完善该领域的空白。欢迎大家批评指正。
二、预备知识
一、经典分词算法
本文调研了2000年以来所有的英文分词方法——textrank、yake、scake、sgrank等。
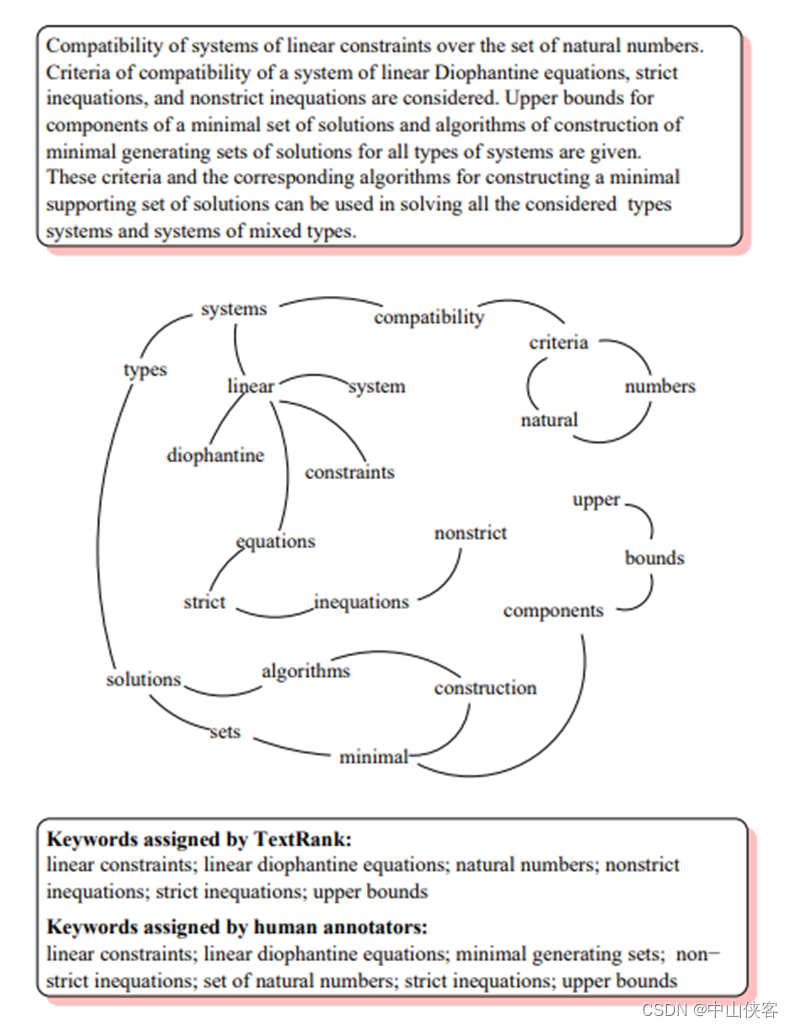
TextRank算法是一种文本排序算法,算法由谷歌的网页重要性排序算法PageRank算法改进而来。TextRank算法能够从一个给定的文本中提取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法提取出该文本的关键句。二者的区别在于:PageRank算法根据网页之间的链接关系构造网络,而TextRank算法根据词之间的共现关系构造网络;PageRank算法构造的网络中的边是有向无权边,而TextRank算法构造的网络中的边是无向有权边。TextRank算法的核心公式如下,其中Wji用于表示两个节点之间
YAKE出自2018年的论文《A Text Feature Based Automatic Keyword Extraction Method for Single Documents》且有开源github。YAKE是一种基于统计的关键词提取方法,分成四个主要的部分:(1) 文本预处理;(2) 特征提取;(3)单词权重计算;(4)候选关键词生成。

scake的思想是将文本数据中的每两连续句组成子文档,然后考察词的共现情况,构造共现矩阵,计算得到得分最高的词组成词组。
sgrank的思想是结合图的方法以及n-grams的方法(依靠提前设置的过滤规则和词组在数据中的位置等信息)。
二、全局等分计算
逆文档频率(Inverted Document Frequency, IDF)是信息检索和自然语言处理中的一个概念,用于评估某个词语对于文档集合的重要程度。它是通过计算一个词在所有文档中出现的频率的倒数来度量的,也就是说,如果一个词在大多数文档中都存在,那么它的IDF值就较低,反之则较高。计算公式如下:
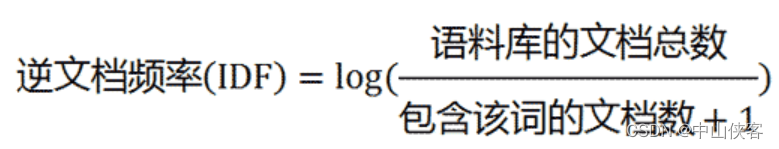
三、分词思路
首先,本文方法面向的是服务器资源紧张,不会考虑从长文档中提取主题词的情况。我们发现除了textrank算法以外,其他算法并不适用于短文档主题词提取。以下这张图展示了一个关键词提取流程。首先,输入原始文档数据,生成n-grams(连续的‘n’个词语序列,移除了一些字符如符号、停用词等)。接着,对生成的n-grams进行标准化处理(例如小写化、词干提取或词形还原)。标准化后的数据通过TextRank算法进行处理,TextRank是一种基于图的排名模型,通过构建词语共现的图并进行排名以识别重要的短语或词语。然后,TextRank算法输出一组候选关键词短语,每个短语带有一个表示其在文档中重要性(考虑到词组在短文档的位置信息)。

一、局部短文档关键词提取算法
import pandas as pd
from tqdm import tqdm
import re
import json
import networkx as nx
from collections import Counter
import textacy
from textacy import *
import os
# 强制 TensorFlow 使用 CPU
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
# 强制 PyTorch 使用 CPU
import torch
torch_device = torch.device("cpu")
en = textacy.load_spacy_lang("en_core_web_trf")
from bs4 import BeautifulSoup
from pyhive import hive
from threading import Lock
import threading
from concurrent.futures import ThreadPoolExecutor
# 判断是不是html格式
def is_html(input_string):
try:
soup = BeautifulSoup(input_string, 'html.parser')
return soup.p.get_text()
except:
return ""
# 去除文本中的<sub></sub> <sup></sup>
def remove_sub_tags(s):
return re.sub(r'<(sub|sup)>.*?</\1>', ' ', s,flags=re.IGNORECASE)
# textrank算法
# 构建共现矩阵
def build_co_occurrence_matrix(sentences_words):
co_occurrence_matrix = {}
# Iterate through each sentence
for sentence in sentences_words:
# Iterate through each word in the sentence
for i, word1 in enumerate(sentence):
# Iterate through the words after the current word
for j in range(i + 1, len(sentence)):
word2 = sentence[j]
# Increment co-occurrence count for word1 and word2
co_occurrence_matrix.setdefault(word1, {}).setdefault(word2, 0)
co_occurrence_matrix[word1][word2] += 1
# Since the co-occurrence matrix is symmetric,
# we also need to increment the count for word2 and word1
co_occurrence_matrix.setdefault(word2, {}).setdefault(word1, 0)
co_occurrence_matrix[word2][word1] += 1
return co_occurrence_matrix
# 构建图结构
def build_graph(co_occurrence_matrix):
G = nx.Graph()
# Add nodes (words) to the graph
for word1 in co_occurrence_matrix:
for word2 in co_occurrence_matrix[word1]:
G.add_edge(word1, word2, weight=co_occurrence_matrix[word1][word2])
return G
# 计算每个单词得分
def calculate_textrank_scores(graph):
textrank_scores = nx.pagerank(graph)
return textrank_scores
# 对结果再次进行
# n-grams提取候选词 textrank打分
def extract_keyphrases(textrank_scores,sentences_words, filter_words,filter_words_pos,file,aid):
phrases = []
for i, filtered_sentence in enumerate(filter_words):
stack = []
stack_pos = []
original_sentence = sentences_words[i]
sum = 0
for j,word in enumerate(filtered_sentence):
if not stack:
if word in textrank_scores.keys() and word != ' ':
stack.append(word)
stack_pos.append(filter_words_pos[i][j])
sum = textrank_scores[word]
else:
continue
else:
top_word = stack[-1]
if original_sentence.index(top_word) + 1 == original_sentence.index(word):
stack.append(word)
stack_pos.append(filter_words_pos[i][j])
sum = sum+textrank_scores[word]
else:
if len(stack) > 2:
phrase = ' '.join(stack)
phrases.append(dict({phrase:sum}))
elif len(stack) == 2:
if stack_pos in [['NUM','NOUN'],['NUM','NUM']]:
stack = [word]
stack_pos = [filter_words_pos[i][j]]
sum = textrank_scores[word]
else:
phrase = ' '.join(stack)
phrases.append(dict({phrase:sum}))
else:
stack = [word]
stack_pos = [filter_words_pos[i][j]]
sum = textrank_scores[word]
if len(stack) > 2:
phrase = ' '.join(stack)
phrases.append(dict({phrase:sum}))
elif len(stack) == 2:
if stack_pos in [['NUM','NOUN'],['NUM','NUM']]:
stack = [word]
stack_pos = [filter_words_pos[i][j]]
sum = textrank_scores[word]
else:
phrase = ' '.join(stack)
phrases.append(dict({phrase:sum}))
# 使用 Counter 统计每个短语的出现次数
phrase_counter = Counter()
for item in phrases:
phrase = list(item.keys())[0]
value = item[phrase]
phrase_counter[phrase] = max(phrase_counter[phrase], value)
# 将 Counter 转换为字典列表形式
phrases = [{"aid":aid,'keyphrase': phrase.strip(), 'weight': round(value/(i+1),5)} for i, (phrase, value) in enumerate(phrase_counter.items())]
# values = [item['weight'] for item in phrases]
# min_value = min(values)
# max_value = max(values)
# # 对 value 进行归一化
# phrases = [{'keyphrase': item['keyphrase'], 'weight': (item['weight'] - min_value) / (max_value - min_value)} for item in phrases]
# 对 normalized_phrases 按照 value 进行排序
phrases = sorted(phrases, key=lambda x: x['weight'], reverse=True)
# 取前五项
phrases = phrases[:5]
# print(file)
with open( '//test/dataprocessed/'+file,'+a',encoding='utf-8') as f:
for phrase in phrases:
f.write(json.dumps(phrase, ensure_ascii=False)+','+'\n')
# print(phrase)
f.close()
# 构建匹配无效字符的正则表达式
invalid_chars_pattern = re.compile(r'[0-9${}\[\]|=><^+~{}\\\\@#$/]')
# 读取自定义停用词文件
with open('stopwords.txt', 'r', encoding='utf-8') as f:
stop_words = set(line.strip() for line in f)
f.close()
# 从hive数据库读取数据时所用的格式
def text_rank(text,aid,file):
text = text.replace(',', ' i ').replace('(','').replace(')','').replace('\\"','').replace('\'','').replace(' ',' ').replace('\"','').replace('%','').replace(')','').replace('(','').replace('#','').replace('\\','').replace('$','')
doc = en(text)
sentences_nlp_words = []
sentences_nlp_words_pos = []
for token in doc:
tmp = token.lemma_
tmp1 = token.pos_
sentences_nlp_words.append(tmp)
sentences_nlp_words_pos.append(tmp1)
processed_tokens = []
processed_tokens_pos = []
sentences_words = []
sentences_words_pos = []
i = 0
while i < len(sentences_nlp_words):
token = sentences_nlp_words[i]
if token.startswith('-') or token.startswith('–') or token.startswith('‐') or token.startswith('—'):
if len(processed_tokens)>0 and i+1<len(sentences_nlp_words):
# 检查是否已经处理过连字符两边的词
processed_tokens[-1] = "".join([processed_tokens[-1],token,sentences_nlp_words[i+1]])
processed_tokens_pos[-1] = 'NOUN'
i = i + 1
elif token == '.':
sentences_words.append(processed_tokens)
sentences_words_pos.append(processed_tokens_pos)
processed_tokens = []
processed_tokens_pos = []
elif sentences_nlp_words_pos[i] == 'PUNCT':
i = i+1
continue
else:
processed_tokens.append(token)
processed_tokens_pos.append(sentences_nlp_words_pos[i])
i += 1
filter_words = []
filter_words_pos = []
for index,sentence in enumerate(sentences_words):
# 将句子分割成单词列表,并移除停用词
words = []
words_pos = []
for index1, (word, pos) in enumerate(zip(sentence, sentences_words_pos)):
if word.lower() not in stop_words and not invalid_chars_pattern.search(word) and sentences_words_pos[index][index1] not in ['VERB','ADV','PUNCT','X','SPACE','SYM','CCONJ']:
words.append(word)
words_pos.append(pos)
filter_words.append(words)
filter_words_pos.append(words_pos)
# Example usage
co_occurrence_matrix = build_co_occurrence_matrix(filter_words)
# print(co_occurrence_matrix)
# Example usage
G = build_graph(co_occurrence_matrix)
# Example usage
textrank_scores = calculate_textrank_scores(G)
# print(textrank_scores)
# Example usage
extract_keyphrases(textrank_scores,sentences_words, filter_words,filter_words_pos,file,aid)二、全局主题词组得分计算
一般情况下,我们可以直接利用logstash将结果导入elasticsearch中(如果有朋友有兴趣的话,请回馈,我会考虑做些logstash教程),但是为了极大节省资源,我们使用hadoop的MapReduce编程将所有主题词去重并得到在文档集中的全局得分。以下是代码(以及将敏感信息删除)。
driver:
public class KeyphraseDriver {
public static void main(String[] args) throws Exception {
if (args.length != 3) {
System.err.println("Usage: KeyphraseDriver <input path> <output path> <total documents>");
System.exit(-1);
}
Configuration conf = new Configuration();
try {
// 将第三个参数转换为 long 并设置到配置中
Integer totalDocuments = Integer.parseInt(args[2]);
conf.setInt("total_documents", totalDocuments);
} catch (NumberFormatException e) {
System.err.println("Error: <total documents> must be a valid number.");
System.exit(-1);
}
conf.set("mapreduce.output.textoutputformat.separator", ";");
Job job = Job.getInstance(conf, "Keyphrase Count");
job.setJarByClass(KeyphraseDriver.class);
job.setMapperClass(KeyphraseMapper.class);
job.setReducerClass(KeyphraseReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(KeyphraseWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
mapper:
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class KeyphraseMapper extends Mapper<LongWritable, Text, Text, KeyphraseWritable> {
private Text keyphraseText = new Text();
private KeyphraseWritable keyphraseWritable = new KeyphraseWritable();
Keyphrase keyphrase1;
Double weight;
String keyphrase;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
try {
keyphrase1 = JSONObject.parseObject(line.substring(0,line.length() - 1),Keyphrase.class);
// parse JSON String
// System.out.println(getJsonValue(line, "aid"));
keyphrase = keyphrase1.getKeyphrase();
weight = keyphrase1.getWeight();
keyphraseText.set(keyphrase);
keyphraseWritable.setWeight(weight);
context.write(keyphraseText, keyphraseWritable);
} catch (Exception e) {
System.out.println(line);
e.printStackTrace();
// System.exit(-1);
}
}
}reducer:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class KeyphraseReducer extends Reducer<Text, KeyphraseWritable, Text, Text> {
private Integer TOTAL_DOCUMENTS; // 总文档数,假设为4
private Text keyphraseText = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 获取总文档数
TOTAL_DOCUMENTS = context.getConfiguration().getInt("total_documents", 1); // 默认值为1,以防出现除零错误
}
@Override
protected void reduce(Text key, Iterable<KeyphraseWritable> values, Context context) throws IOException, InterruptedException {
List<Long> aids = new ArrayList<>();
double weightSum = 0;
int count = 0;
for (KeyphraseWritable value : values) {
weightSum += value.getWeight();
count++;
}
double idf = Math.log((double) TOTAL_DOCUMENTS / (count + 1));
double finalWeight = weightSum * idf;
finalWeight = Math.round(finalWeight * 100000.0) / 100000.0;
String outputValue = ""+finalWeight;
keyphraseText.set(outputValue);
// Write the key and the formatted value
context.write(key, keyphraseText);
}
}
关于之后如何对elasticsearch索引进行更新的,请关注我。随后发文给出详解。