一、读流程解析
在 Hadoop 分布式文件系统(HDFS)中,读取数据的过程涉及多个组件的协同工作,包括客户端、NameNode 和 DataNode。为了确保数据的高可用性和容错性,HDFS 采用了分布式存储和副本机制。
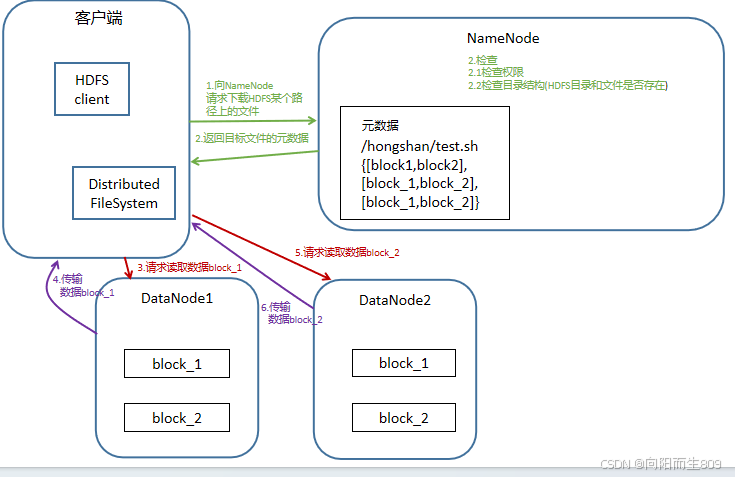
1、客户端发起读请求
客户端向NameData发送请求,告知要读取某个文件。
示例:
客户端调用 hdfs dfs -cat /user/hadoop/example.txt,请求读取 HDFS 中的 example.txt 文件。
客户端向 NameNode 发送读请求,包含文件路径 /user/hadoop/example.txt。
2、NameNode返回文件元数据
NameNode返回文件元数据,并告知客户端从哪些DataNode中读取数据。
示例:
•NameNode 检查文件 example.txt 是否存在,并返回文件的元数据,包括:
•Block 1 (blk_123456789) 存储在:
•DataNode 1 (192.168.1.10)•DataNode 2 (192.168.1.11)•DataNode 3 (192.168.1.12)
•Block 2 (blk_123456790) 存储在:
•DataNode 2 (192.168.1.11)•DataNode 3 (192.168.1.12)•DataNode 4 (192.168.1.13)
3、客户端直接与DataNode通信
客户端根据返回的NameNode返回的DataNode列表,直接和DataNode通信,读取数据块。
示例:
假设客户端在同一机架内的 DataNode 1 (192.168.1.10) 上找到了 Block 1,它会优先选择 DataNode 1 来读取 Block 1。
对于 Block 2,客户端可能会选择 DataNode 2 (192.168.1.11),因为它也是同一机架内的 DataNode
4、DataNode提供数据流
DataNode以流的形式将数据块传输给客户端,客户端可以逐个读取数据块。
示例:
DataNode 1 将 Block 1 以流的形式传输给客户端。
DataNode 2 将 Block 2 以流的形式传输给客户端。
5、客户端处理数据
客户端将读取到的数据块组合成完整的文件内容,并进行进一步的处理。
示例:
客户端将读取到的数据块组合成完整的 example.txt 文件,并将其输出到标准输出(如 hdfs dfs -cat 命令)。
如果文件较大,客户端可以分批次读取数据块,而不需要一次性加载整个文件。
6、容错处理
如果某个DataNode不可用,客户端会自动从其他拥有该数据库副本的DataNode读取数据。
示例:
如果在读取过程中 DataNode 1 出现故障,客户端会自动从其他拥有 Block 1 副本的 DataNode(如 DataNode 2 或 DataNode 3)读取数据。
二、写流程解析
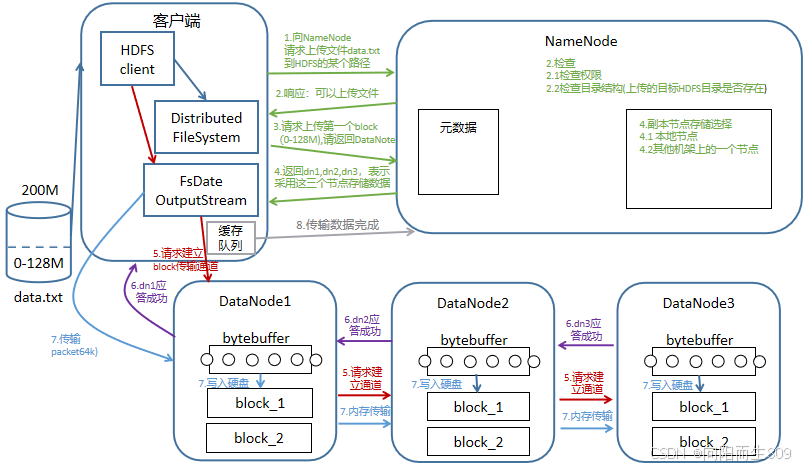
1、客户端发起写请求
客户端向 NameNode 发起写请求,告知要创建或追加到某个文件。
示例:
客户端调用 create() 或 append() 方法,请求创建或追加到 HDFS 中的某个文件。
客户端向 NameNode 发送写请求,包含文件路径、权限、副本数等信息。
2、NameNode 返回文件元数据(即返回响应)
NameNode 检查文件是否存在,并返回文件的元数据。
示例:
NameNode 检查文件是否已经存在:
如果文件不存在,NameNode 会为该文件创建一个新的 inode,并返回文件的元数据(如块大小、副本数等)。
如果文件已存在且允许追加,则 NameNode 返回文件的当前状态。
3、客户端向NameNode请求DateNode
客户端会将传入的文件分割成一个个数据块(机械硬盘单个数据块最大存储128MB,固态硬盘单个数据块最大存储258MB),根据上传文件和数据块的大小决定分割的数据块个数。即客户端和NameNode请求的次数。
4、NameNode返回DataNode 列表
NameNode 返回一个 DataNode 列表,通常包含 3 个 DataNode(默认情况下,HDFS 为每个数据块创建 3 个副本)。
5、 客户端与 DataNode 建立管道,并依次写入到DataNode中
客户端根据 NameNode 返回的 DataNode 列表,依次与这些 DataNode 建立连接,形成一个管道(Pipeline),用于传输数据。
客户端将数据分块并逐个写入 DataNode 管道。每个 DataNode 在接收到数据后,会将其写入本地磁盘,并将数据传递给下一个 DataNode,直到所有副本都写入完成。(存入数据类似于流水线,上个DataNode不需要完全写入完成,在存入过程中下个DataNode就可以开始写入)。
示例:
• 客户端将 example.txt 文件的内容分块(128 MB),并通过管道逐个写入 DataNode。
• 客户端将数据块发送给 DataNode 1。
• DataNode 1 将数据块写入本地磁盘,并将数据传递给 DataNode 2。
• DataNode 2 将数据块写入本地磁盘,并将数据传递给 DataNode 3。
• DataNode 3 将数据块写入本地磁盘。
6、DataNode 向客户端确认写入成功
每个 DataNode 在成功写入数据块后,会向客户端发送确认消息。客户端只有在收到所有 DataNode 的确认后,才会认为写操作成功。
7、NameNode 更新元数据
当客户端完成所有数据块的写入后,它会通知 NameNode,NameNode 会更新文件的元数据,记录新的数据块信息。