何谓大语言模型
大语言模型是一种由包含数百亿及以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文本进行训练。ChatGPT、MOSS都属于大语言模型。
为什么要阅读这本书
《大规模语言模型:从理论到实践》对大语言模型感兴趣的读者提供入门指南,也可作为高年级本科生和研究生自然语言处理相关课程的补充教材。
掌握大语言模型相关技术,给自己一个深入研究大语言模型的实践机会。

复旦NLP团队新作
- 构建LLM的每个阶段都有算法、数据来源、代码、难点及实践经验的详细讨论
- 结合作者在NLP领域多年的研究经验、超300篇相关论文深度研读感悟
- 分享作者团队从0开始研发复旦大学MOSS大语言模型过程中的实践经验,为读者展示大语言模型训练的全流程细节
本书架构
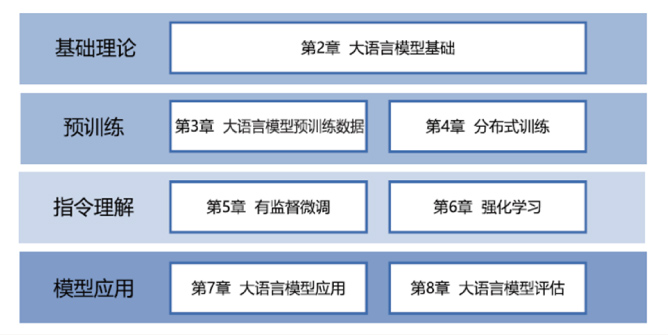
本书结构
基础理论部分:介绍LLM的基础理论知识
- 语言模型的定义
- Transformer结构
- 生成式预训练语言模型GPT
- 大语言模型的结构
- 注意力机制优化
- 实践:基于HuggingFace的预训练语言模型
- 实践:以LLaMA使用的模型结构为例
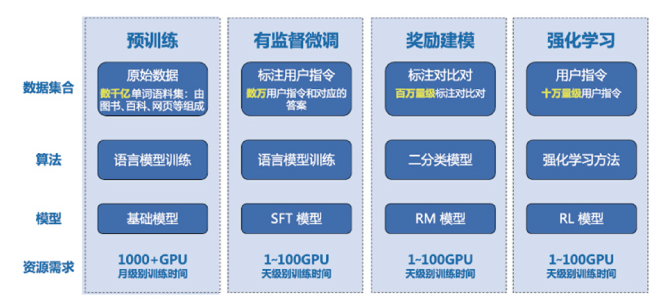
预训练部分:围绕LLM预训练数据和分布式训练展开
- 数据来源
- 数据预处理方法
- 开源数据集
- 模型分布式训练
- 数据并行
- 流水线并行
- 模型并行
- Zero系列优化方法
- 实践:以DeepSpeed为例,进行LLM预训练
- 实践思考分享
- 难点:如何构建训练数据,如何高效地进行分布式训练。
指令理解部分:围绕LLM有监督微调、强化学习展开
- 提示学习
- 语境学习
- 高效模型微调(LORA、Delta Tuning等)
- 有监督微调数据构造方法
- 模型上下文窗口扩展
- 指令数据的构建
- 强化学习基础
- RLHF
- 奖励模型
- 近端策略优化
- 实践:DeepSpeed-Chat SFT
- 训练类ChatGPT系统MOSS-RLHF
- 实践思考分享
- 难点:如何构建训练数据,包括训练数据内部多个任务之间的关系、训练数据与预训练之间的关系及训练数据的规模。如何解决强化学习方法稳定性不高超参数众多及模型收敛困难等问题。
模型应用部分:围绕LLM的应用和评估展开
- 思维链提示
- 由少至多提示
- LangChain技术
- Agent
- 多模态大模型
- LLM评估体系
- LLM评估方法
- LLM评估实践
- LLMEVAL
- 实践思考分享
