文章目录
一、关系数据库和非关系型数据库
1、关系型数据库
关系型数据库是一个结构化的数据库,创建在关系模型(二维表格模型)基础上,一般面向于记录。
SQL语句(标准数据查询语言)就是一种基于关系型数据库的语言,用于执行对关系型数据库中数据的检索和操作。
主流的关系型数据库包括 Oracle、MySQL、SQL Server、Microsoft Access、DB2、PostqreSQL 等。
以上数据库在使用的时候必须先建库建表设计表结构,然后存储数据的时候按表结构去存,如果数据与表结构不匹配就会存储失败。
关系数据库的存储结构是二维表格,关系型数据库大部分将数据存放到硬盘中,可以将有关系的表放在一个库中

在每个二维表格中
每一行称为一条记录,用来描述一个对象的信息
每一列称为一个字段,用来描述对象的一个属性
2、非关系型数据库
NoSQL(NoSQL = Not Only SQL),意思是"不仅仅是 SQL",是非关系型数据库的总称。除了主流的关系型数据库外的数据库,都认为是非关系型。
不需要预先建库建表定义数据存储表结构,每条记录可以有不同的数据类型和字段个数 (比如微信群聊甲的文字、图片、视频、音乐等)
主流的 NoSQL数据库有 Redis、MongBD、Hbase、Memcached 等。

二、关系型数据库和非关系型数据库区别
1、数据存储方式不同
关系型和非关系型数据库的主要差异是数据存储的方式。
1.1 关系型数据
天然就是表格式的,因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也很容易提取数据
1.2 非关系型数据库
与其相反,非关系型数据不适合存储在数据表的行和列中,而是大块组合在一起。非关系型数据通常存储在数据集中,就像文档、键值对或者图结构。数据的及其特性是选择数据存储和提取方式的首要影响因素。
2、扩散方式不同
SQL和NoSQL数据库最大的差别可能是在扩展方式上,要支持日益增长的需求当然要扩展来支持更多的并发量
2.1 SQL数据库
是纵向扩展,扩展CPU性能,磁盘空间,也就是提高处理能力,使用速度更快的计算机,这样处理相同的数据集就更快了。因为数据存储在关系表中,操作的性能瓶颈可能涉及很多个表,这都需要通过提高计算机性能来克服。虽然SOL数据库有很大扩展空间,但最终肯定会达到纵向扩展的上限。
2.2 NoSQL数据库
是横向扩展的。因为非关系型数据存储天然就是分布式的,NoSQL数据库的扩展可以通过给资源池添加更多普通的数据库服务器(节点)来分担负载。
3、对事务性的支持不同
3.1 SQL数据库
如果数据操作需要高事务性或者复杂数据查询需要控制执行计划,那么传统的SQL数据库从性能和稳定性方面考虑是最佳选择。SQL,数据库支持对事务原子性细粒度控制,并且易于回滚事务。
3.2 NoSQL数据库
虽然NoSQL数据库也可以使用事务操作, 但稳定性方面没法和关系型数据库比较,所以它们真正闪亮的价值是在操作的扩展性和大数据量处理方面。
• 关系型: 特别适合高事务性要求和需要控制执行计划的任务
• 非关系型: 此处会稍显弱势,其价值点在于高扩展性和大数据量处理方面
4、非关系型数据库产生背景
可用于应对 Web2.0 纯动态网站类型的三高问题。
(1)Highperformance——对数据库高并发读写需求
(2)Huge Storage——对海量数据高效存储与访问需求
(3)High Scalability && High Availability——对数据库高可扩展性与高可用性需求
关系型数据库和非关系型数据库都有各自的特点与应用场景,两者的紧密结合将会给web2.0的数据库发展带来新的思略。让关系数据库关注在关系上,非关系型数据库关注在存储上。
例如,在读写分离的MySQL数据库环境中,可以把经常访问的数据存储在非关系型数据库中,提升访问速度。
5、SQL和NoSQL数据的存储过程
5.1 关系型数据库
实例–>数据库–>表(table)–>记录行(row)、数据字段(column)
5.2 非关系型数据库
实例–>数据库–>集合(collection)–>键值对(key-value)、文档、图结构
非关系型数据库不需要手动建数据库和集合 (表)。
三、Redis数据库
1. Redis数据库的概述
Redis(远程字典服务器)是一个开源的、使用C语言编写的NoSQL数据库
Redis 基于内存运行并支持持久化,采用key-value(键值对)的存储形式,是目前分布式架构中不可或缺的一环。
Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。
若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降; 若在同一台服务器上开启多个Redis进程,Redis在提高并发处理能力的同时会给服务器的CPU造成很大压力。
在实际生产环境中,需要根据实际的需求来决定开启多少个Redis进程。若对高并发要求更高一些,可能会考虑在同一台服务器上开启多个进程。若CPU资源比较紧张,采用单进程即可。
*Redis6.0之前都是单线程,6.0版本之后支持多线程,但一般只针对网络,读写方面还是使用单线程
2、Redis的特点
(1)具有极高的数据读写速度∶数据读取的速度最高可达到 110000 次/s,数据写入速度最高可达到 81000 次/s。
(2)支持丰富的数据类型∶使用key-value存储模式,Strings、Lists、Hashes、Sets 及 Sorted Sets 等数据类型操作。
(3)支持数据的持久化∶可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
(4)原子性∶Redis所有操作都是原子性的。
(5)支持数据备份∶即 master-salve 模式的数据备份。
Redis作为基于内存运行的数据库,缓存是其最常应用的场景之一。
除此之外, Redis常见应用场景还包括获取最新N个数据的操作、排行榜类应用、计数器应用、存储关系、实时分析系统、日志记录(根据不同的数据类型实现不同场景的支持)。
3、Redis五种数据类型
3.1 String数据类型
概述:String是redis最基本的类型,最大能存储512MB的数据,String类型是二进制安全的,即可以存储任何数据、比如数字、图片、序列化对象等
3.2 List数据类型
概述:列表的元素类型为string,按照插入顺序排序,在列表的头部或尾部添加元素
3.3 Hash数据类型(散列类型)
概述:hash用于存储对象。可以采用这样的命名方式:对象类别和ID构成键名,使用字段表示对象的属性,而字段值则存储属性值。如:存储ID为2的汽车对象。
如果Hash中包含很少的字段,那么该类型的数据也将仅占用很少的磁盘空间。每一个Hash可以存储4294967295个键值对。
3.4 Set数据类型(无序集合)
概述:无序集合,元素类型为String类型,元素具有唯一性,不允许存在重复的成员。多个集合类型之间可以进行并集、交集和差集运算。
应用范围:
1.可以使用Redis的Set数据类型跟踪一些唯一性数据,比如访问某一博客的唯一IP地址信息。对于此场景,我们仅需在每次访问该博客时将访问者的IP存入Redis中,Set数据类型会自动保证IP地址的唯一性。
2.充分利用Set类型的服务端聚合操作方便、高效的特性,可以用于维护数据对象之间的关联关系。比如所有购买某一电子设备的客户ID被存储在一个指定的Set中,而购买另外一种电子产品的客户ID被存储在另外一个Set中,如果此时我们想获取有哪些客户同时购买了这两种商品时,Set的intersections命令就可以充分发挥它的方便和效率的优势了。
3.5 Sorted Set数据类型(zset、有序集合)
概述:有序集合,元素类型为Sting,元素具有唯一性,不能重复。
每个元素都会关联一个double类型的分数score(表示权重),可以通过权重的大小排序,元素的score可以相同。
应用范围:
1)可以用于一个大型在线游戏的积分排行榜。每当玩家的分数发生变化时,可以执行ZADD命令更新玩家的分数,此后再通过ZRANGE命令获取积分TOP10的用户信息。当然我们也可以利用ZRANK命令通过username来获取玩家的排行信息。最后我们将组合使用ZRANGE和ZRANK命令快速的获取和某个玩家积分相近的其他用户的信息。
2)Sorted-Set类型还可用于构建索引数据。
4、Redis效率快的原因
(1)Redis 是一款纯内存结构,避免了磁盘I/O等耗时操作。
(2)Redis 命令处理的核心模块为单线程,减少了锁竞争,以及频繁创建线程和销毁线程的代价,减少了线程上下文切换的消耗。
(3)采用了 I/O 多路复用机制,大大提升了并发效率。
I/O多路复用程序虽然会同时监听多个 Socket 连接,但是其会将监听的 Socket 都放到一个队列里面,然后通过这个队列有序的,同步的将每个 Socket 对应的事件传送给文件事件分派器,再由文件事件分派器分派给对应的事件处理器进行处理,只有当一个 Socket 所对应的事件被处理完毕之后,I/O多路复用程序才会继续向文件事件分派器传送下一个 Socket所对应的事件,这也可以验证上面的结论,处理客户端的命令请求是单线程的方式逐个处理,但是事件处理器内并不是只有一个线程。
四、Redis 部署以及相关命令
1、Redis安装部署的操作步骤
1.1 关闭防火墙和SElinux
systemctl stop firewalld
setenforce 0
1.2 安装gcc gcc-c++ 编译器
yum install -y gcc gcc-c++ make
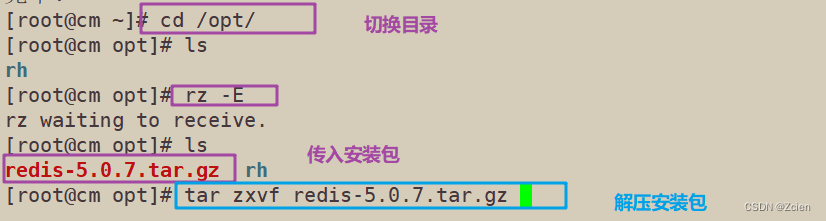
1.3 将redis-5.0.7.tar.gz压缩包上传到/opt目录中,解压,并编译安装
tar zxvf redis-5.0.7.tar.gz -C /opt/
cd /opt/redis-5.0.7/
make
make PREFIX=/usr/local/redis install
由于Redis源码包中直接提供了Makefile文件,所以在解压完软件包后,不用先执行./configure进行配置,可直接执行make与make install命令进行安装
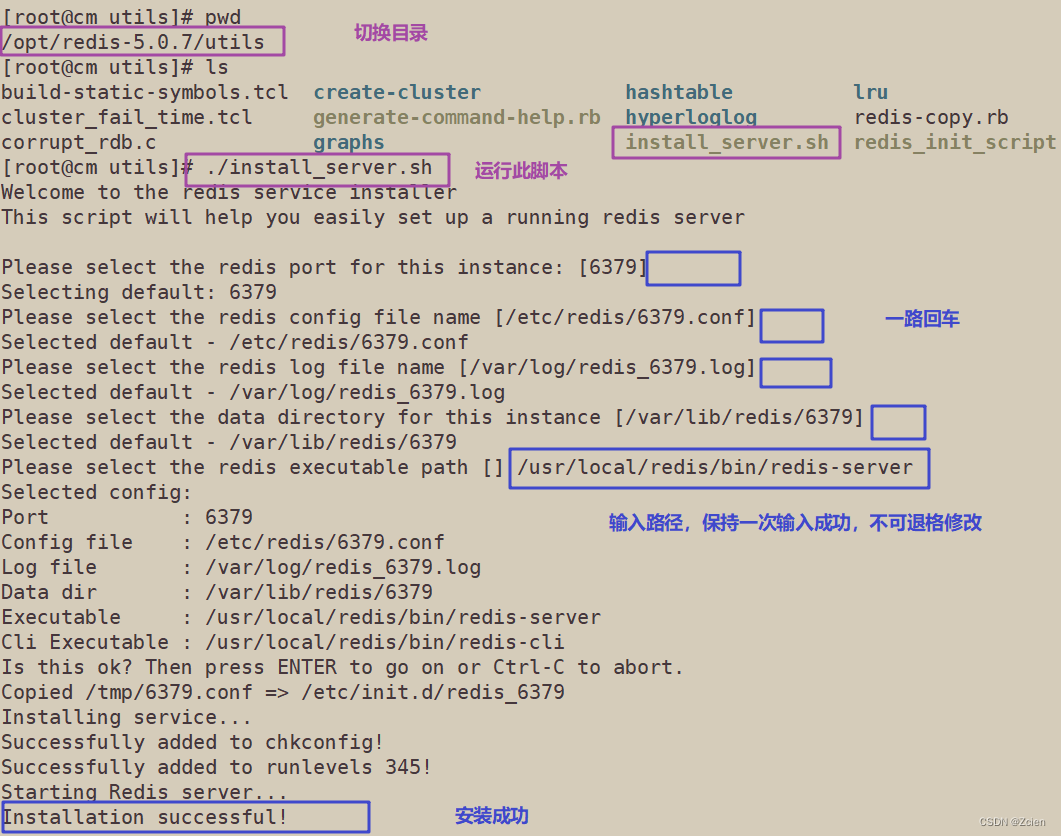
1.4 执行软件包提供的installserver.sh脚本文件设置Redis服务所需要的相关配置文件
cd /opt/redis-5.0.7/utils
./install_server.sh
......
#一直回车.
Please select the redis executable path [/usr/local/bin/redis-server]
/usr/local/redis/bin/redis-server
#需要手动修改为/usr/local/redis/bin/redis-server 注意要一次性正确输入
Selected config:
Port : 6379 #默认侦听端口为6379
Config file : /etc/redis/6379.conf #配置文件路径
Log file : /var/log/redis_6379.log #日志文件路径
Data dir : /var/lib/redis/6379 #数据文件路径
Executable : /usr/local/redis/bin/redis-server #可执行文件路径
Cli Executable : /usr/local/bin/redis-cli #客户端命令工具
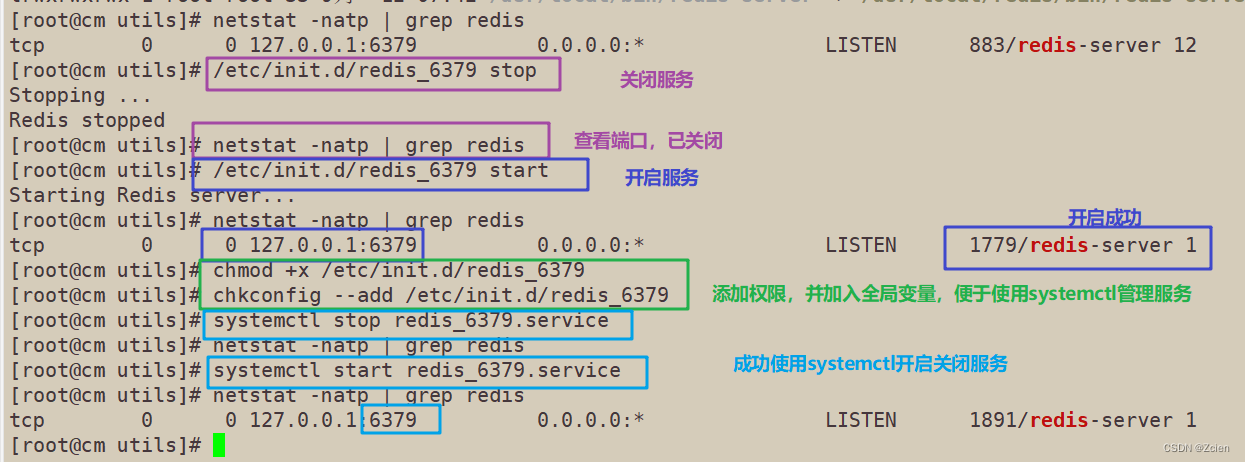
1.5 把redis的可执行程序文件放入路径环境变量的目录中便于系统识别
ln -s /usr/local/redis/bin/* /usr/local/bin/
#当install_server.sh 脚本运行完毕,Redis 服务就已经启动,默认侦听端口为6379
netstat -natp | grep redis
1.6 Redis服务控制
/etc/init.d/redis_6379 stop
#停止
/etc/init.d/redis_6379 start
#启动
/etc/init.d/redis_6379 restart
#重启
hmod +x /etc/init.d/redis_6379 #加入全局系统环境,使用systemctl命令管理
chkconfig --add /etc/init.d/redis_6379
systemctl start redis_6379.service
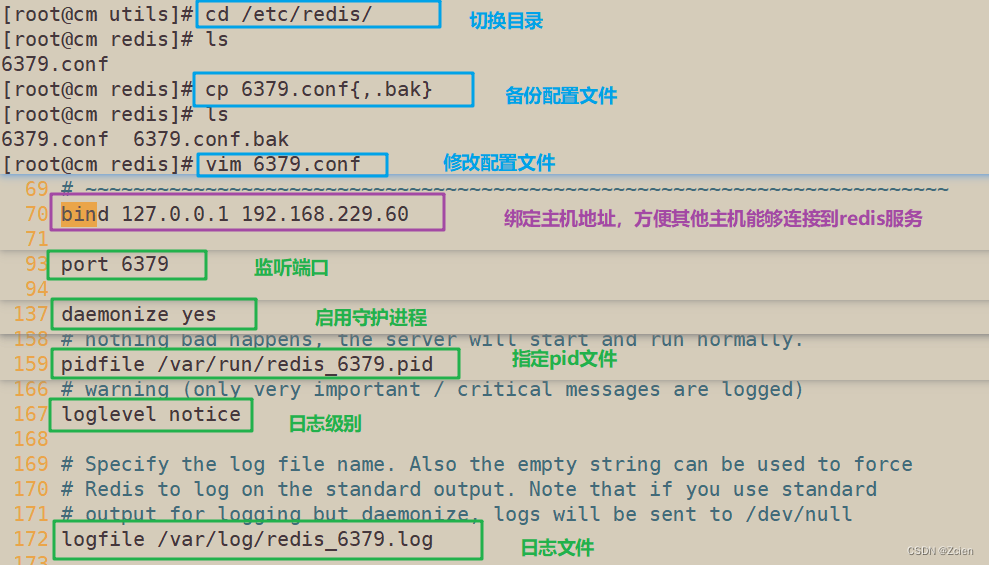
1.7 修改配置/etc/redis/6379.conf参数
vim /etc/redis/6379.conf
bind 127.0.0.1 192.168.226.129
#70行,添加监听的主机地址
port 6379
#93行,Redis默认的监听端口
daemonize yes
#137行,启用守护进程
pidfile /var/run/redis_6379.pid
#159行,指定PID文件
loglevel notice
#167行,日志级别
logfile /var/log/redis_6379.log
#172行,指定日志文件
/etc/init.d/redis_6379 restart
2、实例操作:Redis安装部署
2.1 关闭防火墙和SElinux
2.2 安装gcc gcc-c++ 编译器

2.3 将redis-5.0.7.tar.gz压缩包上传到/opt目录中,解压,并编译安装
2.4 执行软件包提供的installserver.sh脚本文件设置Redis服务所需要的相关配置文件


2.5 把redis的可执行程序文件放入路径环境变量的目录中便于系统识别
2.6 Redis服务控制
2.7 修改配置/etc/redis/6379.conf参数


3、Redis命令工具
redis-server 用于启动 Redis 的工具
redis-benchmark 用于检测 Redis 在本机的运行效率
redis-check-aof 修复 AOF 持久化文件
redis-check-rdb 修复 RDB 持久化文件
redis-cli Redis命令行工具
rdb和aof是redis服务中持久化功能的两种形式RDB AOF
redis-cli 常用于登陆至redis数据库
4、redis-cli命令行工具(远程登录)
语法: redis-cli -h host -p port -a password
选项:
-h :指定远程主机
-p :指定Redis 服务的端口号
-a :指定密码,未设置数据库密码可以省略-a选项
若不添加任何选项表示,则使用127.0.0.1:6379 连接本机上的 Redis 数据库,
redis-cli -h 192.168.229.60 -p 6379

5、redis-benchmark 测试工具
redis-benchmark 是官方自带的 Redis 性能测试工具,可以有效的测试 Redis 服务的性能。
-h:指定服务器主机名
-p:指定服务器端口
-s:指定服务器 socket
-c:指定并发连接数
-n:指定请求数
-d:以字节的形式指定 SET/GET 值的数据大小
-k:1=keep alive 0=reconnect
-r: SET/GET/INCR 使用随机 key, SADD 使用随机值
-P:通过管道传输<numred>请求
-q:强制退出 redis。仅显示 query/sec 值
–csv:以 CSV 格式输出
-l:生成循环,永久执行测试
-t:仅运行以逗号分隔的测试命令列表
-I:Idle 模式。仅打开 N 个 idle 连接并等待
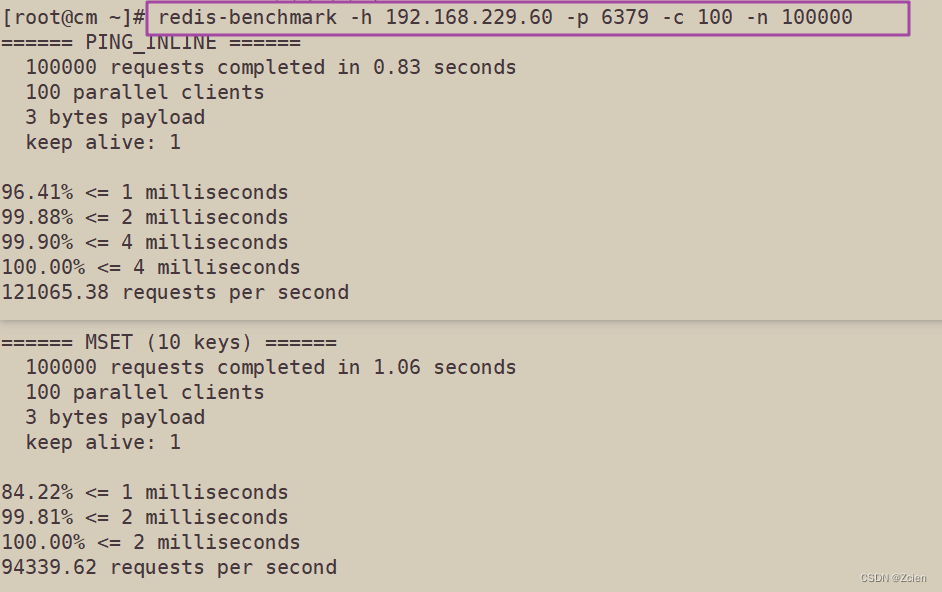
#向 IP 地址为 192.168.229.60、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
redis-benchmark -h 192.168.229.60 -p 6379 -c 100 -n 100000
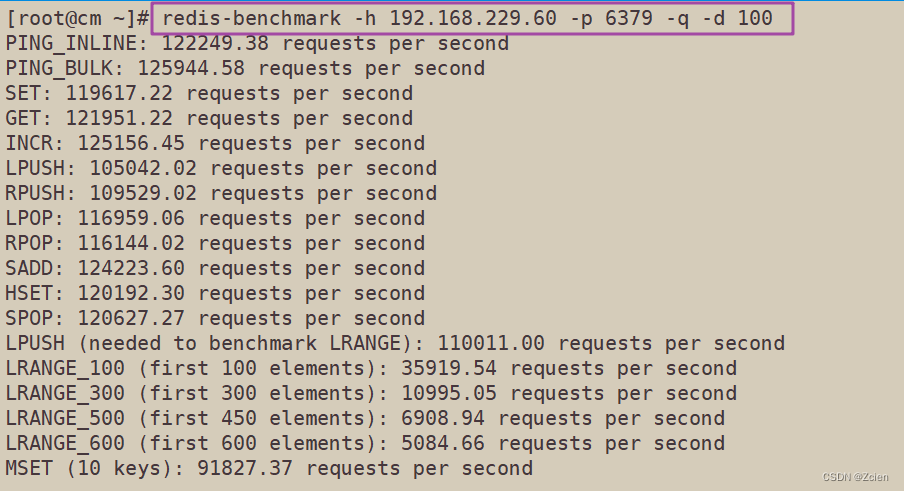
#测试存取大小为 100 字节的数据包的性能
redis-benchmark -h 192.168.229.60 -p 6379 -q -d 100
#测试本机上 Redis 服务在进行 set 与 lpush 操作时的性能
redis-benchmark -t set,lpush -n 100000 -q
5.1 向 IP 地址为 192.168.229.60、端口为 6379 的 Redis 服务器发送 100 个并发连接与 100000 个请求测试性能
5.2 测试存取大小为 100 字节的数据包的性能
5.3 测试本机上 Redis 服务在进行 set 与 lpush 操作时的性能

五、redis总结
1)数据库
关系型数据库:实例–>数据库–>表(table)–>记录行(row)、数据字段(column)
非关系型数据库:实例–>数据库–>集合(collection) -->键值对(key-value)
非关系型数据库不需要手动建数据库和集合(表)
2)redis测试工具
Redis命令工具中的 rdb 和 aof 是redis服务中持久化功能的两种形式!
redis-cli命令行工具(远程登录);
redis-benchmark 测试工具(有效的测试 Redis 服务的性能)
3)redis数据库命令
set 、get和del :存放、获取和删除数据
keys:获取key,可以结合通配符 * 和 ?
exists和type:判断key是否存在和判断类型
rename和renamenx:重命名的两种,后者会进行判断,存在则不改
dbsize:查看当前数据库中key的数目
4)Redis多数据库常用命令
select 序号 :切换库名(16个数据库,数据库名称是用数字0-15)
move 键值 序号:多数据库间移动数据
FLUSHDB :清空当前数据库数据
FLUSHALL :清空所有数据库的数据,慎用!
5)Redis 高可用
含义:高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常服务。
组成:实现高可用的技术主要包括持久化、主从复制、哨兵和集群。
6 ) 高可用中的持久化:RDB与AOF
(1) 持久化方式:
①RDB:周期性的快照
②AOF:接近实时的持久化(以everysec方式)
(2)redis启用的优先级
AOF > RDB 同时仅当AOF功能关闭的情况下,redis才会再重新启动时使用RDB的方式进行恢复
(3)RDB和AOF中的持久化模式
①RDB:由redis主进程(周期性)fork派生出子进程对redis内存中的数据进行持久化,生成到.rdb文件中.
②AOF:根据持久化策略(alawys、no、everysec(默认)),先将redis中的语句保存在缓存区中,再从缓冲区同步到.aof文件中.
7 ) redis的恢复策略/优势
redis与其他常用非关数据库类似,都是将数据保存在内存中
而保存在内存中时,当redis重启,内存数据丢失,但redis通过RDB或AOF的持久化功能可以在redis进行重启之后,优先读取AOF文件,基于AOF文件进行数据恢复这种方式来“持久化保存”数据。