
文章目录
1. pandas简介
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
Pandas 提供了丰富的功能,包括:
- 数据清洗:处理缺失数据、重复数据等。
- 数据转换:改变数据的形状、结构或格式。
- 数据分析:进行统计分析、聚合、分组等。
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
2. pandas 安装
安装 pandas 需要基础环境是 Python,Pandas 是一个基于 Python 的库,因此你需要先安装 Python,然后再通过 Python 的包管理工具 pip 安装 Pandas。
使用 pip 安装 pandas:
pip install pandas
安装完成可以查看版本
import pandas
pandas.__version__ # 查看版本
3. pandas 的数据结构
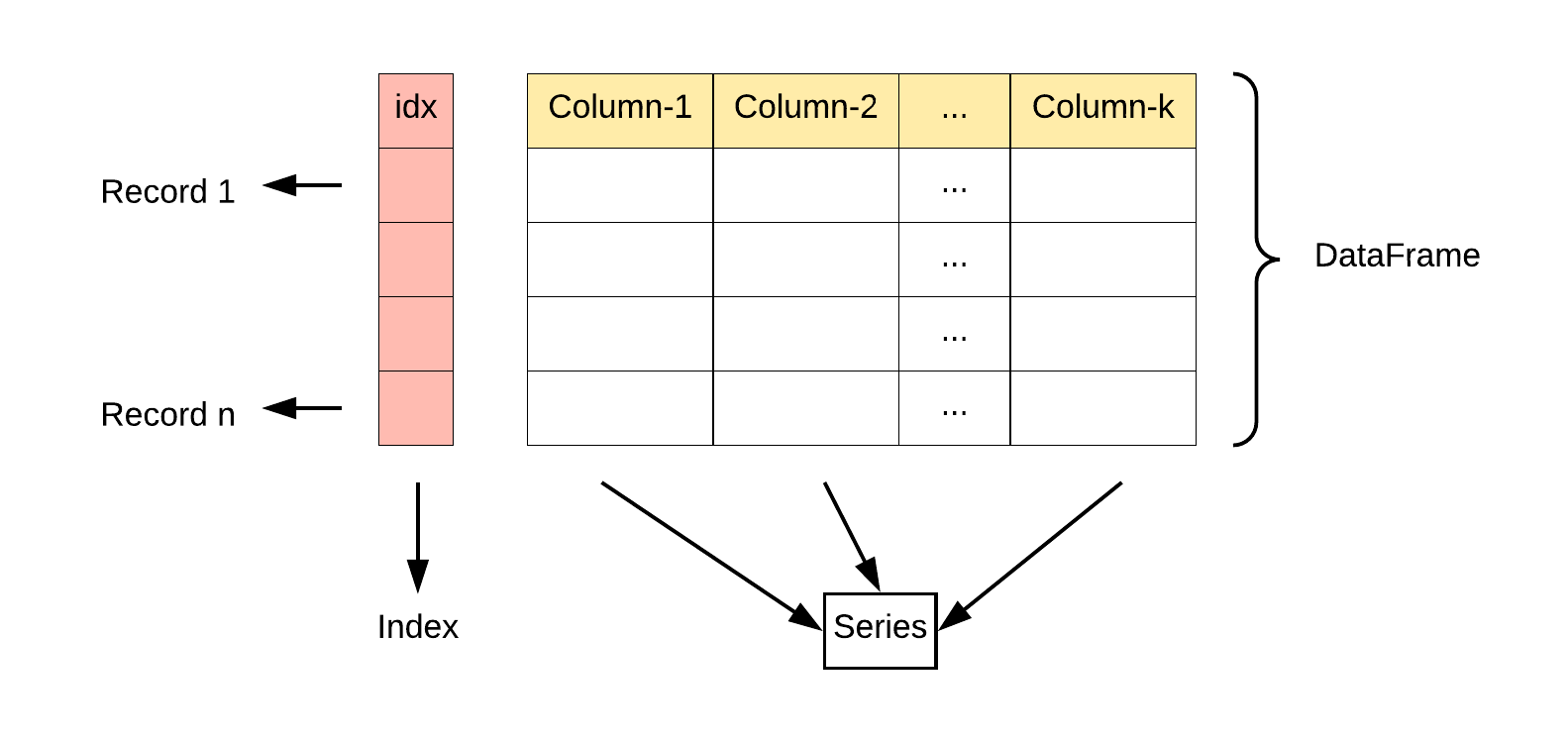
Pandas 主要引入了两种新的数据结构:DataFrame 和 Series。
-
Series: 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。
-
DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。

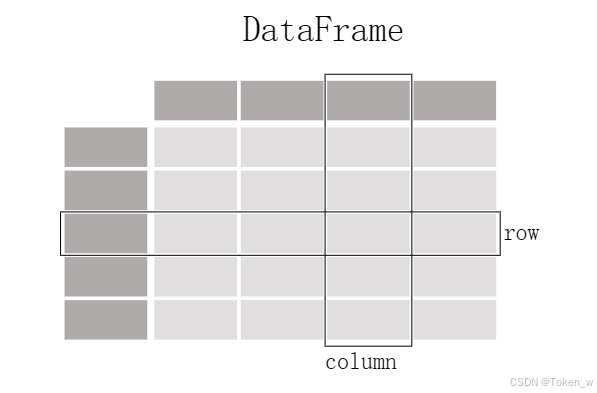
DataFrame 可视为由多个 Series 组成的数据结构:
4. pandas 数据处理
4.1 读取excel数据
1.读取.xlsx文件
import pandas as pd
import os
dir=os.path.abspath(os.path.join(os.path.dirname("__file__"),os.path.pardir))
os.chdir(dir)
#转移到上一级目录
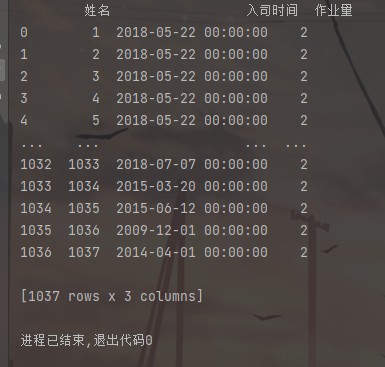
df=pd.read_excel("5.xlsx",sheet_name="材料2",skiprows=6,usecols="b:d")
print(df)
2.读取.csv文件
import pandas as pd
df = pd.read_csv('nba.csv')
print(df)
4.2 切片
对 pandas 中的数据按照行、列或者快进行抓取处理
import pandas as pd
import numpy as np
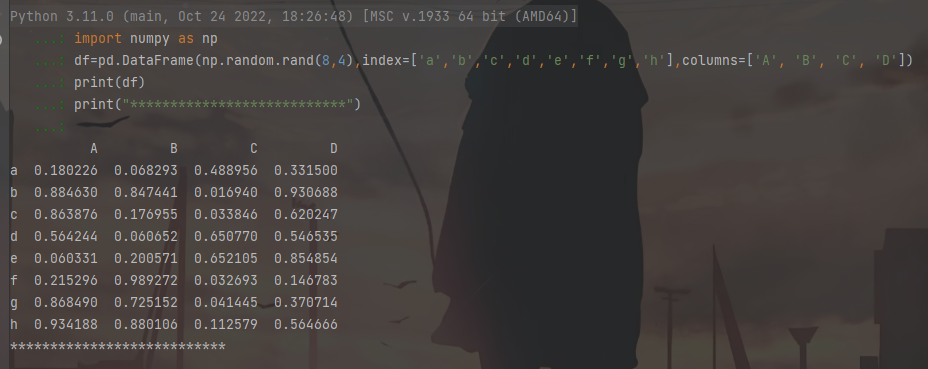
df=pd.DataFrame(np.random.rand(8,4),index=['a','b','c','d','e','f','g','h'],columns=['A', 'B', 'C', 'D'])
print(df)
print("***************************")
print(df.loc[:,'A'])
print("***************************")
print(df.loc[:,['A','C']])
print("***************************")
print(df.loc['a':'e',['A','C']])
print('开始输出iloc')
print (df.iloc[:4])
print("***************************")
print(df.iloc[:,:2])
print("***************************")
print(df.iloc[:,[0,2]])
切片方法有 loc 和 iloc 两种,前者按照字母方式进行切片,后者按照数字方式进行切片。
注:1. pandas的切片操作中,逗号表示不连续选择,冒号表示连续选择。
- python的“左闭右开”原则,[0:5]表示从0到4
4.3 排序、筛选与分类汇总
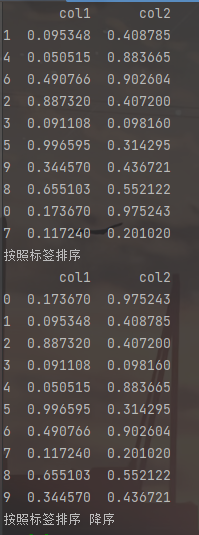
1.排序
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.rand(10,2),index=[1,4,6,2,3,5,9,8,0,7],columns=['col1','col2'])
print(df)
sorted=df.sort_index()#按照标签排序
print('按照标签排序')
print(sorted)
print('按照标签排序 降序')
sorted=df.sort_index(ascending=False)#按照标签排序
print(sorted)
print('按照col1进行排序')
sorted=df.sort_values(by='col1')
print(sorted)
print('按照col2进行排序 降序')
sorted=df.sort_values(by='col2',ascending=False)
print(sorted)
2.筛选
import pandas as pd
import numpy as np
df=pd.read_excel('筛选 数据源.xlsx')
print(df)
#多条件查询
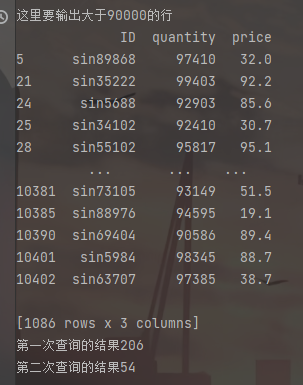
df1=df[df['quantity']>=90000]
print('这里要输出大于90000的行')
print(df1)
df1=df[(df['quantity']>=90000) & (df['quantity']<=92000)]
print('第一次查询的结果' + str(len(df1)))
df1.to_excel('查询结果.xlsx')
df1=df[(df['quantity']>=90000) & (df['quantity']<=92000) & (df['price']>=80)]
print('第二次查询的结果' + str(len(df1)))
df1.to_excel('查询结果1.xlsx')
df1.to_excel('查询结果2.xlsx',sheet_name='哈哈啊',startrow=10,startcol=10)
3.分类汇总
import pandas as pd
import numpy as np
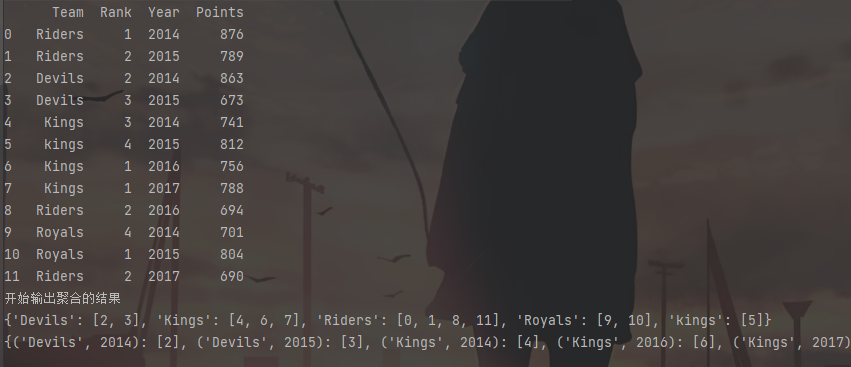
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
print (df)
print('开始输出聚合的结果')
print(df.groupby('Team').groups)
print(df.groupby(['Team','Year']).groups)
4.数据合并
import pandas as pd
import numpy as np
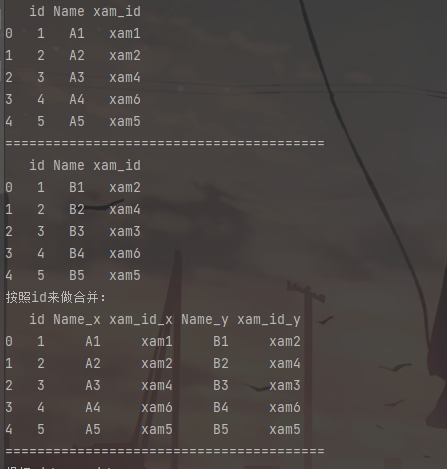
left = pd.DataFrame({
'id':[1,2,3,4,5],
'Name': ['A1', 'A2', 'A3', 'A4', 'A5'],
'xam_id':['xam1','xam2','xam4','xam6','xam5']})
right = pd.DataFrame(
{'id':[1,2,3,4,5],
'Name': ['B1', 'B2', 'B3', 'B4', 'B5'],
'xam_id':['xam2','xam4','xam3','xam6','xam5']})
print (left)
print("========================================")
print (right)
print('按照id来做合并:')
rs=pd.merge(left,right,on='id')
print(rs)
5. pandas 统计分析
统计分析指标:
平均值、中位数、频数、标准差、方差、变异系数、二八系数、峰度、极值、偏度
| 函数 | 说明 |
|---|---|
| df.describe() | 计算基本统计信息,如均值、标准差、最小值、最大值等。 |
| df.mean() | 计算每列的平均值。 |
| df.median() | 计算每列的中位数。 |
| df.mode() | 计算每列的众数。 |
| df.count() | 计算每列非缺失值的数量。 |
import pandas as pd
# 读取 JSON 数据
df = pd.read_json('data.json')
# 删除缺失值
df = df.dropna()
# 用指定的值填充缺失值
df = df.fillna({'age': 0, 'score': 0})
# 重命名列名
df = df.rename(columns={'name': '姓名', 'age': '年龄', 'gender': '性别', 'score': '成绩'})
# 按成绩排序
df = df.sort_values(by='成绩', ascending=False)
# 按性别分组并计算平均年龄和成绩
grouped = df.groupby('性别').agg({'年龄': 'mean', '成绩': 'mean'})
# 选择成绩大于等于90的行,并只保留姓名和成绩两列
df = df.loc[df['成绩'] >= 90, ['姓名', '成绩']]
# 计算每列的基本统计信息
stats = df.describe()
# 计算每列的平均值
mean = df.mean()
# 计算每列的中位数
median = df.median()
# 计算每列的众数
mode = df.mode()
# 计算每列非缺失值的数量
count = df.count()