嵌入式系统(把软件嵌入到硬件里面)
嵌入式系统是以应用为中心,以计算机技术为基础,并且软硬件可裁剪,适用于对功能、可靠性、成本、体积、功耗有严格要求的专用计算机系统。
Linux起源
UNIX和linux的区别:
1)linux是开发源代码的自由软件,而unix是对源代码实行知识产权保护的传统商业软件
2)UNIX系统大多是与硬件配套的,而Linux则可运行在多种硬件平台上
不同操作系统的内核:
windows - NT
ubuntu - linux
Android - linux
macOs ios - unix
查看系统版本
查看操作系统版本:
lsb_release -a 或者 -r
cat /etc/issue --> 文件中查看
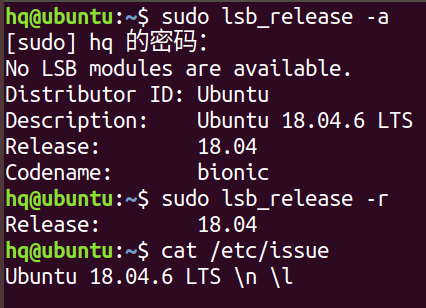
查看内核的版本:
uname -a 或者 -r
cat /proc/version --> 文件中查看

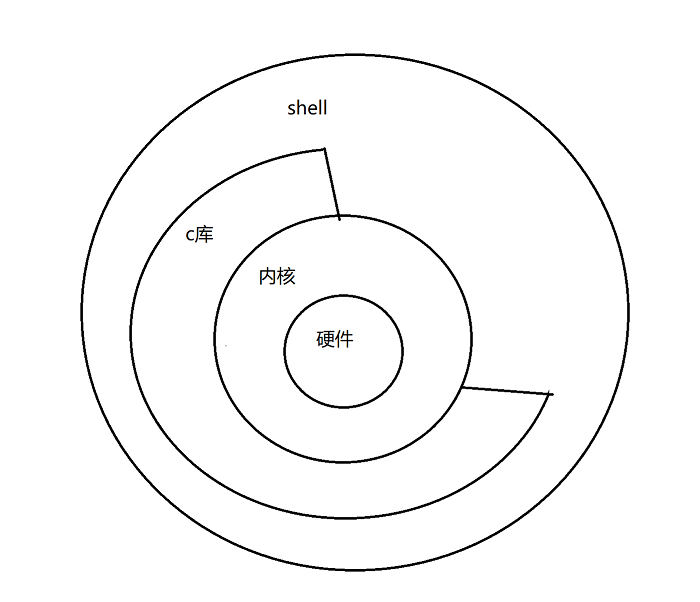
内核系统架构
应用层: app程序 shell命令
内核层:五大功能:内存管理 文件系统管理 设备管理 网络管理 进程管理
驱动层:字符设备驱动、块设备驱动、网络设备驱动
硬件层:鼠标、键盘(字符设备驱动)、硬盘、U盘(块设备驱动)
系统关机重启命令
关机:
sudo shutdown -h now : 立即关机
sudo shutdown -h 时间 "提示语句" :定时关机min为单位
重启:
sudo reboot now :立即重启
sudo shutdown -r now :立即重启
sudo shutdown -r 时间 :定时重启min为单位
shutdown -c:取消定时操作
Linux下的软件安装
两种软件包管理机制
debian linux :deb软件包 - Ubuntu用的是这个
redhat linux :rpm软件包
deb软件包分为两种
二进制软件包(deb):.deb - 安装软件的软件包
源码包(deb-src) :.dsc
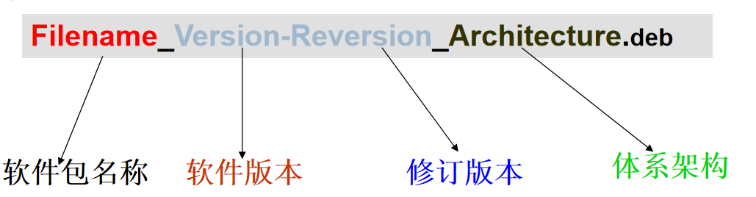
软件包命名
软件包的管理工具:dpkg apt
1) dpkg
特点:安装时需要软件包存在,不需要从镜像站点获取软件包
不需要网络,不能检查软件之间的依赖关系。
dpkg命令:
sudo dpkg -i 软件包的完整名称:安装软件
sudo dpkg -r 软件名:卸载软件
sudo dpkg -s 软件名:查看软件的安装状态
sudo dpkg -P 软件名 :完全卸载
sudo dpkg -L 软件名 :列出软件目录信息
2)apt
特点:安装时不需要软件包存在,需要从镜像站点获取软件包
需要网络,能检查软件之间的依赖关系
apt-get:
sudo apt-get install 软件名:下载并安装软件
/var/cache/apt/archives --》 下载的软件的安装包默认的存放路径
sudo apt-get remove 软件名:卸载软件
sudo apt-get --purge remove 软件名:完全卸载
sudo apt-get clean:清除下载的软件包
sudo apt-get update :下载更新软件包列表信息、
sudo apt-get upgrade :(升级)更新安装软件版本
sudo apt-get download 软件名:下载软件包
sudo apt-get source 软件名:下载源码包
apt-cache:
sudo apt-cache show 软件名:获取二进制包的描述信息
sudo apt-cache policy 软件名:查看软件安装状态
sudo apt-cache depends 软件名:查看依赖的软件
sudo apt-cache rdepends 软件名:查看谁依赖我
练习下载:xcowsay oneko
ping 网址 或 ip地址 ---> 查看虚拟机是否可以上网
shell的基础知识
shell的概念
贝壳 外在保护工具
shell是命令解析器
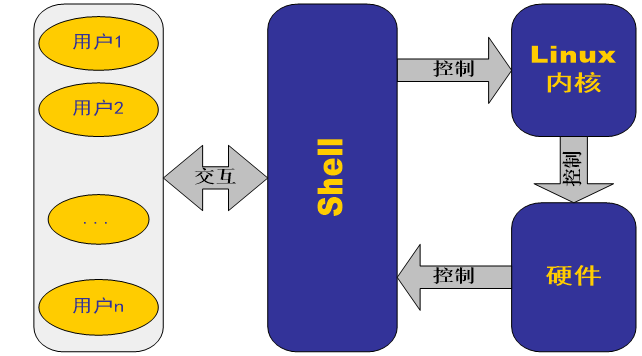
用户、shell、内核、硬件之间的关系
用户在命令行提示符下键入命令文本,开始与Shell进行交互。接着,Shell将用户的命令或按键转化成内核所能够理解的指令。控制操作系统做出响应,直到控制相关硬件设备。然后,Shell将输出结果通过Shell提交给用户。
shell解析器的分类
Bourne Shell(简称sh):Bourne Shell由AT&T贝尔实验室的S.R.Bourne开发,也因开发者的姓名而得名。它是Unix的第一个Shell程序,早已成为工业标准。目前几乎所有的Linux系统都支持它。不过Bourne Shell的作业控制功能薄弱,且不支持别名与历史记录等功能。目前大多操作系统是将其作为应急Shell使用。
C Shell(简称csh):C Shell由加利福尼亚大学伯克利分校开发。最初开发的目的是改进Bourne Shell的一些缺点,并使Shell脚本的编程风格类似于C语言,因而受到广大C程序员的拥护。不过C Shell的健壮性不如Bourne Shell。
Korn Shell(简称ksh):Korn Shell由David Korn开发,解决了Bourne Shell的用户交互问题,并克服了C Shell的脚本编程怪癖的缺点。Korn Shell的缺点是需要许可证,这导致它应用范围不如Bourne Shell广泛。
Bourne Again Shell(简称bash):Bourne Again Shell由AT&T贝尔实验室开发,是Bourne Shell的增强版。随着几年的不断完善,已经成为最流行的Shell。它包括了早期的Bourne Shell和Korn Shell的原始功能,以及某些C Shell脚本语言的特性。此外,它还具有以下特点:能够提供环境变量以配置用户Shell环境,支持历史记录,内置算术功能,支持通配符表达式,将常用命令内置简化。
shell命令格式
通常一条命令包含三个要素:命令名称、选项、参数。其中命令名称是必须的,选项和参数根据实际情况进行填写
Command [-Options] Argument1 Argument1 ……
| Command | shell命令名称,严格区分大小写 |
| Options | shell命令选项,每一个参数都需要添加"-"进行引导 |
| Argument1 | shell命令参数,一条命令的参数大于等于0个,且多个参数的情况需要利用空格进行隔开 |
格式:命令名称 [选项] [参数] ......
细节:
1. 一条命令的三要素之间用空格隔开
2. 若一行要书写多个命令,需要使用分号(;),进行隔开
3. 如果一条命令不能在一行内写完,需要在行尾使用反斜杠(\) 表明该命令未结束
history - 历史记录查询
history n -> 只显示n条命令 n:数字
直接执行 history 显示HISTSIZE条历史记录
echo $HISTSIZE -> 在终端显示环境变量HISTSIZE的值
家目录下隐藏文件.bash_history,保存历史记录。
终端关闭,终端上执行的命令刷新到文件中
更改环境变量的值:
export HISTSIZE=20 临时修改,只有在本次打开的终端有效
家目录文件 .bashrc 中修改就是永久修改,修改完成生效,从新打开的终端开始生效(vi .bashrc)
alias起别名命令
alias:查看系统中起别名的命令
alias 新名='原来的命令':起别名
unalias 新名:取消别名
shell中的特殊字符
通配符
当用户需要用命令处理一组文件,例如 file1.txt、file2.txt、file3.txt、file4.txt ……,用户不必输入所有文件名。可以使用shell通配符。
| 通配符 | 含义 |
| * | 匹配所有长度的字符 |
| ? | 匹配一个长度的字符 |
| [] | 匹配其中指定的一个字符 |
| [-] | 匹配指定的字符范围 |
| [^] | 匹配指定字符以外的所有字符 |
实例:
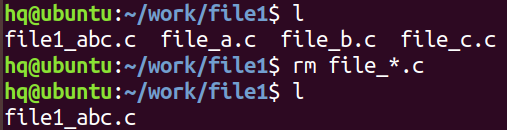
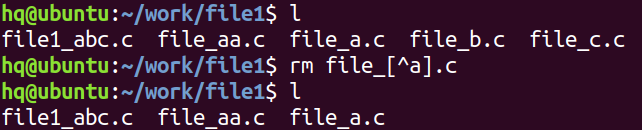
- 用 file_*.c,匹配到file_a.c、file_b.c、file_c.c 能匹配到的,file1_abc.c则匹配不到(命令后面单独使用 * 表示全部,如:rm *:表示删除全部文件)
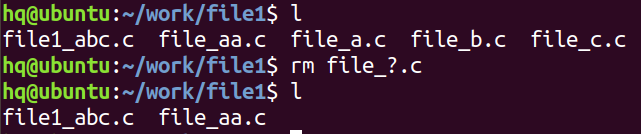
- 使用file_?.c,匹配file_a.c、file_b.c、file_c.c是可以匹配到的,file_aa.c则匹配不到
- 使用file_[ab].c 只能匹配file_a.c、file_b.c

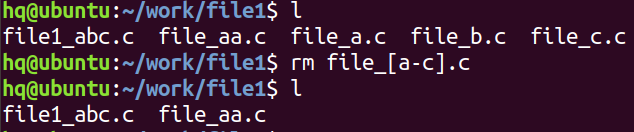
- 使用 file_[a-c].c 能匹配到file_a.c、file_b.c 直到 file_c.c
- 使用 file_[^a].c 除了file_a.c、file_b.c、file_c.c的其他文件
管道 |
格式:命令1 | 命令2
作用:前一个命令的输出作为后一个命令的输入
例:cat xxx.c | wc -l --> 将cat输出到终端的内容作为wc -l的输入,计算行数
补充:
wc -l 文件名:文件行数
wc -c 文件夹名:文件字符个数
wc -m 文件名:计算文件字节大小
wc -w 文件名:文件单词个数

输入输出重定向
输出重定向
命令 > file:将file作为输出源,file文件不存在创建
命令 >> file:如果文件不存在则创建 ,如果文件中存在内容则会追加
命令 &> file 或者 命令 2> file:将由命令产生的错误输出到file
输入重定向
命令 < file
命令置换符 ` `
在英文状态下,esc键下的 ~ 按键
将一个命令的输出作为另一个命令参数
系统维护命令
1. man man:查看man手册
第一个章节:shell命令
第二个章节:系统调用
第三个章节:C库
2. sudo passwd 用户名:修改用户密码
3. su:切换用户
su:默认切换到root
sudo su 用户名:切换到指定的用户
exit:退出切换的用户
4. echo "输出内容":向我们终端输出内容,默认是换行
echo -n "输出内容" ---> 输出不换行
5. date:查看当前系统的日期
date -s 年/月/日
date -s 时:分:秒
6. clear:清屏
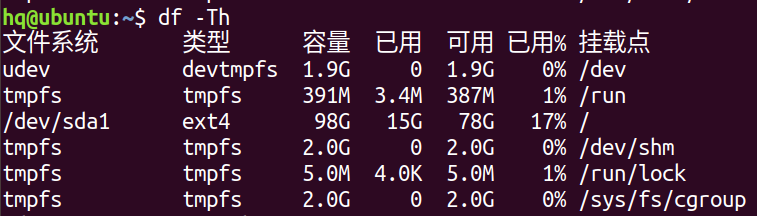
7. df -Th 或者 df -h:查看磁盘空间
8. mount:文件系统的挂载
sudo mount -t 设备类型 设备名称 挂载点:挂载设备
sudo umount 挂载点:卸载设备
注意:卸载时不要在挂载点卸载
用户管理命令
sudo adduser 用户名:添加用户
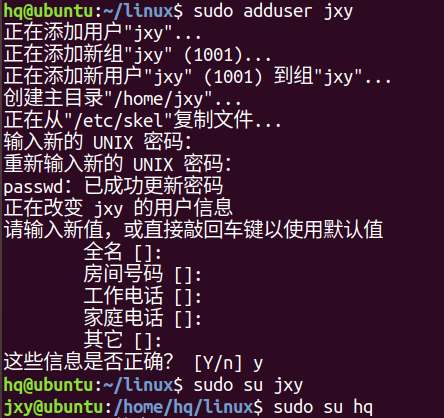
给用户添加sudo权限
切换到超级管理员身份:sudo su
给用户添加sudo权限:sudo vi /etc/sudoers
添加:用户名 ALL=(ALL:ALL) ALL
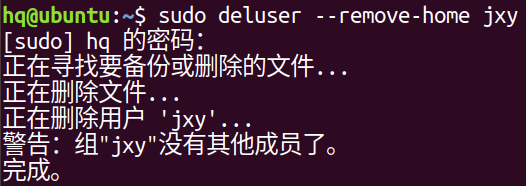
sudo deluser --remove-home 用户名:删除用户
sudo userdel -f 用户名:强制删除用户
进程管理命令
进程:是程序的一次运行过程,是动态的
程序:存放在磁盘空间上的可执行文件,是静态
1. ps 查看进程的状态
ps -aux
PID:是唯一标识进程的id
ps -ef:查看父进程(PPID)
ps -ajx:PPID PID PGID(组id) SID(会话id)
可以通过man ps查看关于进程状态的信息
| 表头 | 含义 |
| USER | 该进程是由哪个用户产生的。 |
| PID | 进程的 ID。 |
| %CPU | 该进程占用 CPU 资源的百分比,占用的百分比越高,进程越耗费资源。 |
| %MEM | 该进程占用物理内存的百分比,占用的百分比越高,进程越耗费资源。 |
| VSZ | 该进程占用虚拟内存的大小,单位为 KB。 |
| RSS | 该进程占用实际物理内存的大小,单位为 KB。 |
| TTY | 该进程是在哪个终端运行的。其中,tty1 ~ tty7 代表本地控制台终端(可以通过 Alt+F1 ~ F7 快捷键切换不同的终端),tty1~tty6 是本地的字符界面终端,tty7 是图形终端。pts/0 ~ 255 代表虚拟终端,一般是远程连接的终端,第一个远程连接占用 pts/0,第二个远程连接占用 pts/1,依次増长。?是守护进程,也就是一开始启动时系统在后台运行的进程。(后面IO会讲) |
| STAT | 1. D uninterruptible sleep (usually IO) 不可中断的睡眠态 2. R running or runnable (on run queue) 运行态 3. S interruptible sleep (waiting for an event to complete) 可中断的睡眠态 4. T stopped by job control signal 暂停态 5. t stopped by debugger during the tracing 因为调试而暂停 6. X dead (should never be seen) 死亡态 7. Z defunct ("zombie") process, terminated but not reaped by its parent 僵尸态 8. < high-priority (not nice to other users) 高优先级 9. N low-priority (nice to other users) 低优先级 10. L has pages locked into memory (for real-time and custom IO) 锁在内存中 11. s is a session leader 会话组组长 12. l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)多线程 13. + is in the foreground process group 前台进程 14. 没有+时,默认是后台进程 15. I 空闲状态进程 |
| START | 该进程的启动时间。 |
| TIME | 该进程占用 CPU 的运算时间,注意不是系统时间。 |
| COMMAND | 产生此进程的命令名。 |
2. top 动态显示进程状态
在进程管理中,NI通常表示进程的Nice值(Nice Value)。Nice值是用来调整进程优先级的参数,它可以影响进程在系统中的调度顺序
Nice值通常是一个整数,在大多数操作系统中,它的范围通常是-20到+19。较小的Nice值表示进程的优先级较高,而较大的Nice值表示进程的优先级较低
NI:优先级 +19 ~ -20 值越小,优先级越高
PR:20 + NI
在进程管理中,PR通常表示进程的优先级(Priority)。进程优先级是操作系统用来管理和调度进程的一种机制。每个进程都有一个与之相关联的优先级,用于确定进程在系统中的调度顺序。
3. renice 修改正在运行的进程的优先级
sudo renice -n NI值 PID
NI: 要修改的优先级的值
PID:要修改进程优先级的PID
1. 在xxx.c 写一个死循环 并执行
2. top 看一下当前的执行的文件的进程优先级是多少以及该进程的PID
3. sudo renice -n 优先级值 PID
4. top 看一下当前的优先级是否更改
4. nice 定制运行的进程优先级
sudo nice -n NI值 ./可执行文件
5. kill 发送一个信号
kill -l:查看Linux下的信号
2) SIGINT 结束进程 ctrl+c
3) SIGQUIT 程序正常退出 ctrl+\
4) SIGILL 结束进程
9) SIGKILL 强制杀死进程 不可忽略信号无条件终止指定进程
13) SIGPIPE 管道破裂信号
14) SIGALRM 时钟信号
15) SIGTERM 默认kill信号
17) SIGCHLD 子进程状态发生改变会给父进程发送
19) SIGSTOP 停止 不可忽略信号
20) SIGTSTP 暂停信号 ctrl+z
kill -num PID:给指定的进程发送num号信号
killall 文件名:杀死所有为该文件的进程
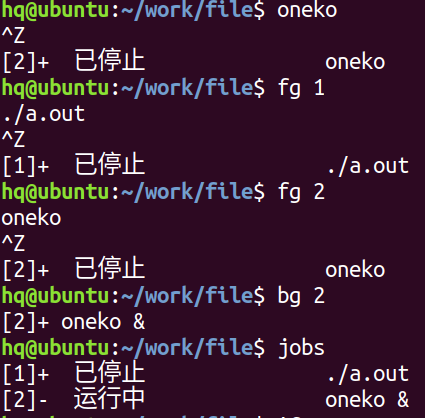
6. 前后台进程切换
先运行进程
ctrl z:将前台运行的进程暂停同时放到后台
bg 数字:将后台暂停的进程在后台运行起来
jobs:在当前终端查看后台进程
fg 数字:将后台运行的进程拉到前台运行
文件系统命令
磁盘文件系统:指本地主机中实际可以访问到的文件系统,包括硬盘、CD-ROM、DVD、USB存储器、磁盘阵列等。常见文件系统格式有:autofs、coda、Ext(Extended File sytem,扩展文件系统)、Ext2、Ext3、VFAT、ISO9660(通常是CD-ROM)、UFS(Unix File System,Unix文件系统)、ReiserFS、XFS、JFS、FAT(File Allocation Table,文件分配表)、FAT16、FAT32、NTFS(New Technology File System)等;
网络文件系统:是可以远程访问的文件系统,这种文件系统在服务器端仍是本地的磁盘文件系统,客户机通过网络远程访问数据。常见文件系统格式有:NFS(Network File System,网络文件系统)、Samba(SMB/CIFS)、AFP(Apple Filling Protocol,Apple文件归档协议)和WebDAV等;
专有/虚拟文件系统:不驻留在磁盘上的文件系统。常见格式有:TMPFS(临时文件系统)、PROCFS(Process File System,进程文件系统)和LOOPBACKFS(Loopback File)
根文件系统结构
需要了解常见的目录含义:
/bin:存放系统中最常用的可执行文件(二进制)
/sbin : 存放更多的可执行文件(二进制),包括系统管理、目录查询等关键命令文件
/boot:存放Linux内核和系统启动文件,包括Grub、lilo启动器程序
/opt: 与系统无关的安装程序
/etc: 放的一些配置文件。Linux开机自启动脚本存放在/etc/rc.d或/etc/init.d目录下。这些目录是Linux系统中用于存放启动脚本的标准目录
/dev : 存放所有设备文件,包括硬盘、分区、键盘、鼠标、USB、tty等
/lib : 存放共享的库文件,包含许多被/bin和/sbin中程序使用的库文件
/mnt : 该目录通常用于作为被挂载的文件系统的挂载点
/proc : 存放所有标志为文件的进程,它们是通过进程号或其他的系统动态信息进行标识,例如cpuinfo文件存放CPU当前工作状态的数据
/usr : 用于存放与系统用户直接有关的文件和目录,例如应用程序及支持它们的库文件。以下罗列了/usr中部分重要的目录。
/usr/lib: 库文件,系统默认搜索的库路径
/usr/include: 头文件,系统默认搜索的头文件路径
Linux开机自启动脚本存放在/etc/rc.d或/etc/init.d目录下。这些目录是Linux系统中用于存放启动脚本的标准目录
文件操作相关命令
1. file 文件名:查找文件属性信息
2. rm -f 文件名:强制删除、文件存不存在都会删除
rm -rf 文件夹名:强制删除文件夹存不存在都会删除
3. cat 文件名:将文件内容输出到终端
cat -n 文件名:将文件的内容以及行号输出到终端
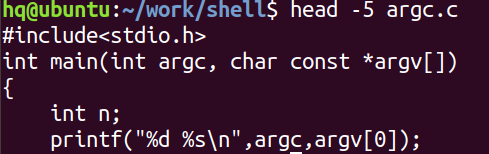
4. head 文件名:默认输出文件内容的前10行
head -num 文件名:输出文件内容的前num行输出到终端
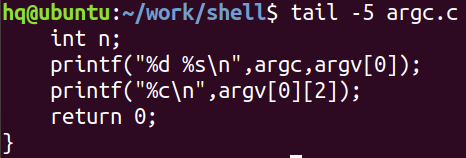
5. tail 文件名:默认输出文件内容的后10行
tail -num 文件名:输出文件内容的后num行输出到终端
6. find 查找文件
格式:find 路径 -name "文件名":在指定路径下查找文件
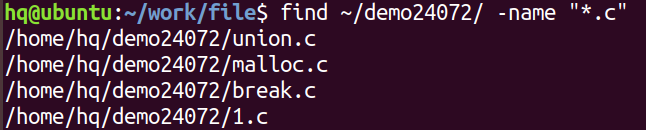
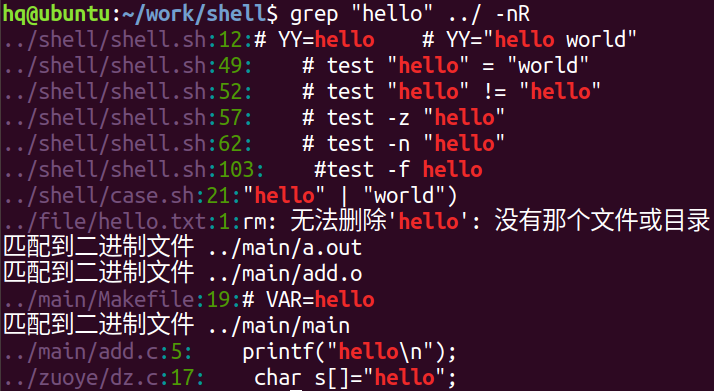
7. grep 查找指定的字符串
grep "字符串" 文件名:在一个文件中查找
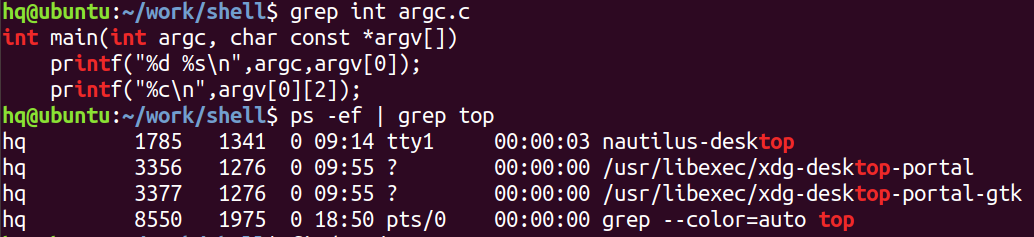
grep "字符串" 路径 -nR:从这个路径开始往后查找,找到所有用到了这个字符串的文件
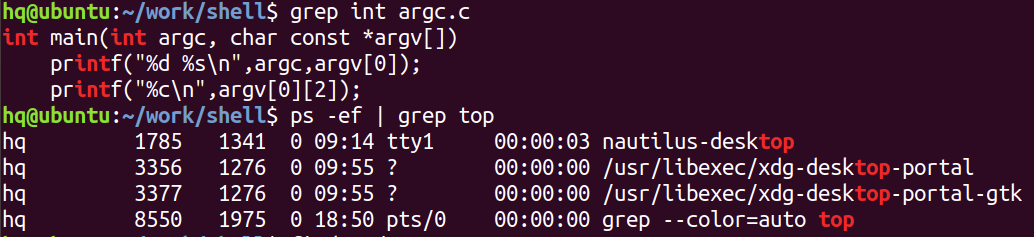
grep "\<字符串\>" 文件名:在文件中精确查找

结合ps以及管道:
ps -ef | grep a.out:从进程信息中查找带a.out的字符串
硬链接和软连接(符号链接)
硬链接
ln根据Linux系统分配给文件 inode(ls -i)号 进行建立链接,没办法跨越文件系统
格式:ln 被链接的文件(源文件) 生成的链接文件(目标文件)
1) 硬链接的属性 - 相当于生成一个副本 起别名
2) 修改内容都变化
3) 源文件删除链接文件依然存在
4) 不能链接目录
软连接
ln -s 利用文件的路径名来创建,最好从绝对路径开始
格式:ln -s 被链接的文件(源文件) 生成的链接文件(目标文件)
1) 软连接的文件属性 l 相当于快捷方式
2) 源文件删除,链接断开,建立源文件之后重新链接
3) 软连接可以链接目录
4) 修改内容都变化
硬链接和软连接的区别
首先,从使用的角度讲,两者没有任何区别,都与正常文件访问方式一样,支持读写,如果是可执行文件的话也可以直接执行
区别在底层原理上
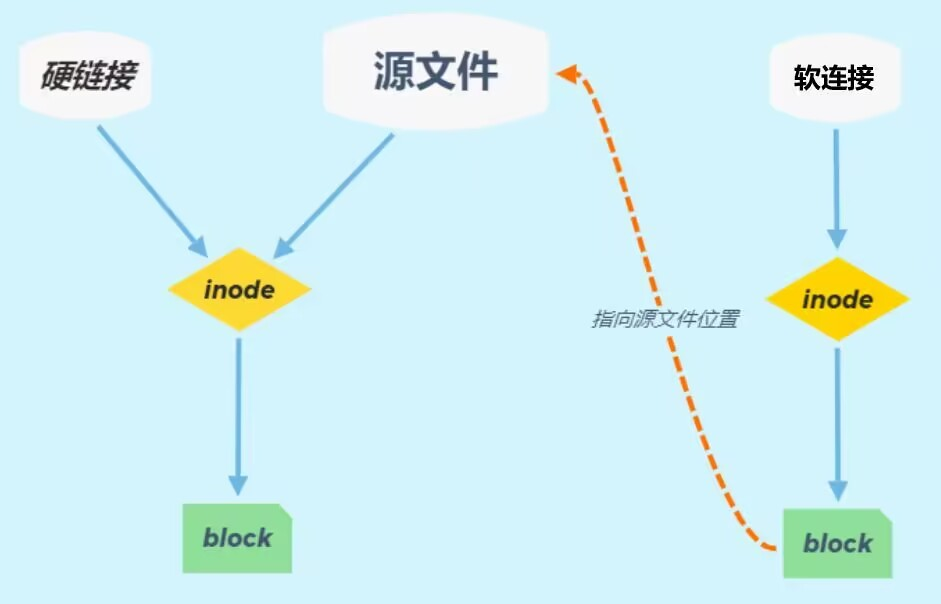
本质区别:
硬链接:本质上是同一个文件
软连接:本质上不是同一个文件
跨设备区别:
硬链接:不支持
软连接:支持
inode区别:
硬链接:相同
软连接:不同
连接数:
硬链接:创建新的硬链接,连接数会增加,删除硬链接,链接数减少
软连接:创建或删除,链接数不会变化
文件夹:
硬链接:不支持
软连接:支持
解压和压缩
gzip 和 gunzip
特点:只能对单个的普通文件进行压缩
不能进行归档,压缩或解压后的源文件都不存在
压缩后所生成的压缩格式是 .gz 格式
压缩:gzip 文件名 ---> 默认生成:文件名.gz的压缩文件
解压:gunzip 压缩文件名.gz -> 默认解压为:文件名
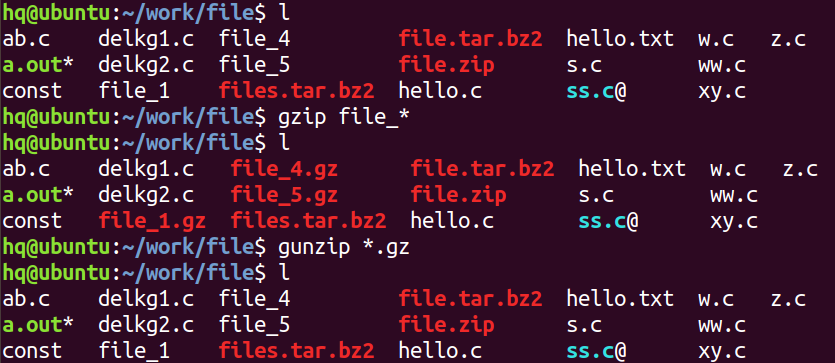
bzip2 和 bunzip2 (特点和gzip相似)
压缩后生成压缩格式:.bz2格式
压缩:bzip2 文件名 ---> 默认生成:文件名.bz2 的压缩文件
解压:bunzip2 压缩文件名.bz2 ---> 默认解压为:文件名
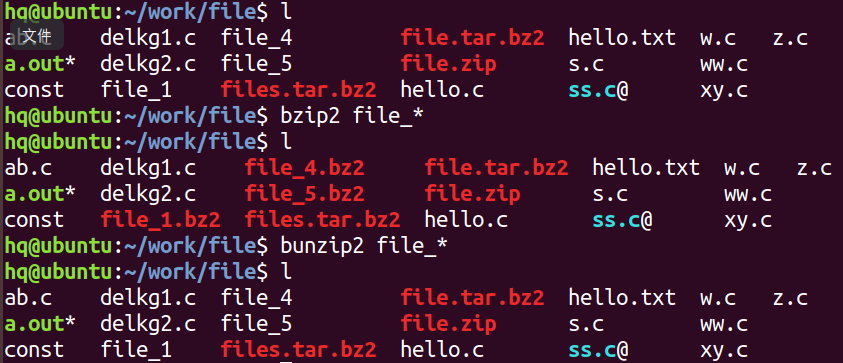
xz 和 unxz (特点和gzip相似)
压缩后生成压缩格式是:.xz 格式
压缩:xz 文件名 ----> 默认生成:文件名.xz 的压缩文件
解压:unxz 压缩文件名.xz ----> 默认解压为:文件名
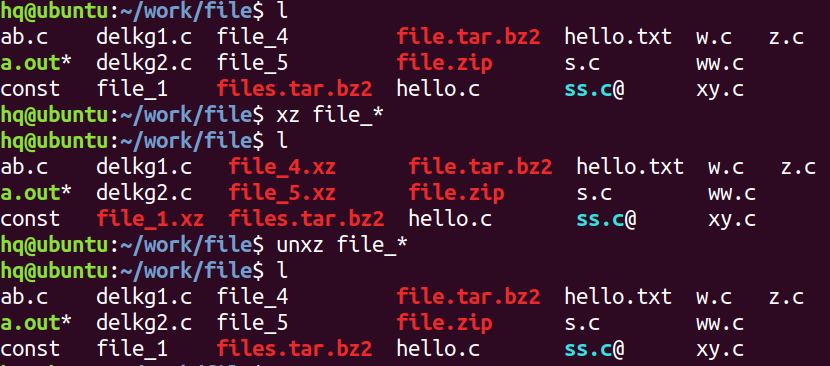
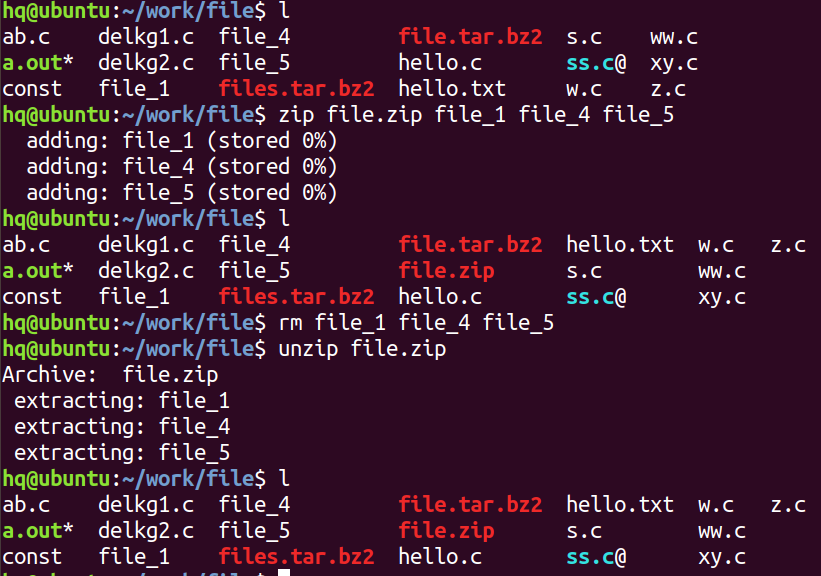
zip 和 unzip
zip 命令用于将一个文件或者多个文件压缩成单一的文件 .zip
注意:
1. 具有归档功能,并进行压缩
2. 可以压缩文件夹,后缀 .zip ,压缩文件夹时需要加 -r 选项
3. 压缩或解压后源文件依然存在
压缩:zip 压缩文件名 要压缩的文件列表
解压:unzip 要解压的压缩文件
tar
选项:
-x:释放归档文件
-c:创建一个新的归档文件
-v:显示归档和释放的过程信息
-f:用户指定归档文件的文件名,否则使用默认名称 后跟文件名
-t:查看使用tar命令进行归档的文件
-j:由 tar 生成归档,然后由 bzip2 压缩 .tar.bz2
-z:由 tar 生成归档,然后由 gzip 压缩 .tar.gz
-J:由 tar 生成归档,然后由 xz 压缩 .xz
注意:
1) 具有归档功能,并通过参数可以进行压缩或解压
2) 压缩或解压后源文件存在
3) 需要写全压缩或解压的文件名格式
组合:
-cvjf:以 bz2 的格式压缩文件
-cvzf:以 gz 的格式压缩文件
-cvJf:以 xz 的格式压缩文件
-xvf:解压一个压缩包,解压后压缩包依然存在
压缩:
tar -cvjf file.tar.bz2 要压缩的文件列表
tar -cvzf file.tar.gz 要压缩的文件列表
tar -cvJf file.tar.xz 要压缩的文件列表
注意:tar -cvf file.tar 要压缩的文件列表 --> 只归档不压缩
解压:
tar -xvf xxx.tar.压缩格式
shell脚本编程
概念
shell脚本的本质:shell命令的有序集合
shell既是应用程序又是脚本语言,并且是解释型语言,不需要编译,解释一条执行一条。
shell脚本编程:将shell命令结合一些按照一定逻辑集合到一起,写一个.sh文件,实现一个或多个功能,这个脚本不用编译直接执行
shell创建执行
创建shell脚本文件的步骤:
1. 创建一个脚本文件
touch xxx.sh
2. 将脚本权限修改为可执行
chmod 777 xxx.sh
3. 编辑内容
vi xxx.sh (可以在vscode中编辑脚本内容)
4. 执行脚本
./xxx.sh 或者 bash xxx.sh
练习:
1)在当前路径下创建file_1到file_5, 5个普通文件
2)删除 file_2和file_3文件(使用通配符)
3)将剩下的file文件用tar压缩成bz2的格式
4)将压缩文件复制到家目录下
5)进入到家目录解压压缩文件
6)删除压缩包
#!/bin/bash
touch file_1 file_2 file_3 file_4 file_5
rm file_[23]
tar -cvjf file.tar.bz2 file_*
cp file.tar.bz2 /home/hq/
cd ~
tar -xvf file.tar.bz2
rm file.tar.bz2shell变量
shell中允许建立变量存储数据,但是不支持数据类型
(如:整型、字符、浮点类型),所有赋值给变量的值都解释为一串字符
变量的定义格式
变量名=值
注意:等号两边不能有空格
取shell变量的值:$变量名
变量的分类
自定义变量
YY=hello # YY="hello"
echo $YY
XX=$YY # 将 YY 的值复制给XX
echo $XX
unset YY # 取消该变量的值 unset 变量名
echo $YY
环境变量
系统配置好的、内置变量
环境变量一般是指操作系统中用来指定操作系统运行环境的一些参数,如:临时文件夹位置和系统文件夹位置等
使用命令查看系统环境变量:printenv 或者 env
HOME:/etc/passwd 文件中列出的用户主目录
PATH:shell 搜索路径,就是一系列目录,当执行命令时,linux就在这些命令中查找
export 变量名=值 临时终端有效
永久生效只需要将这个命令放到家目录下 .bashrc 文件中,当前用户永久有效
若放到/etc/bash.bashrc 这个中间中就是所有用户永久有效
命令变量与命令行参数
$0 执行的脚本名(不包括第一个命令行参数)
$1-$9、${10}-${n} 命令行传的参数 n:第几个命令参数
$# 所有命令行参数个数不包含$0
$@ $* 遍历输出命令行参数内容(不包括第一个命令行参数)
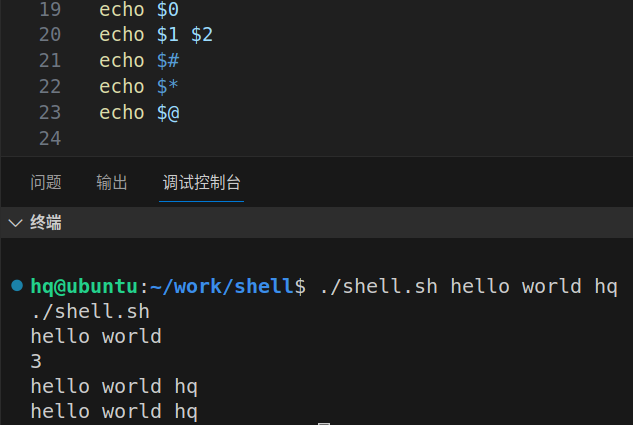
预定义变量
$? 获取的上一个命令是否是正确的执行结果
0:真 非0:假
$$ 获取当前shell的进程PID
shell中的语句
1. 说明性语句
以 # 开始到该行结束,起解释说明作用
#!/bin/bash 告诉操作系统使用哪种类型的shell执行此脚本文件
2. 功能性语句
任意的shell命令、用户程序或其他的shell程序
3. 结构性语句
条件测试语句、多路分支语句、循环语句、循环控制语句
功能性语句
read (类似C当中scanf)
从终端获取值赋值给变量
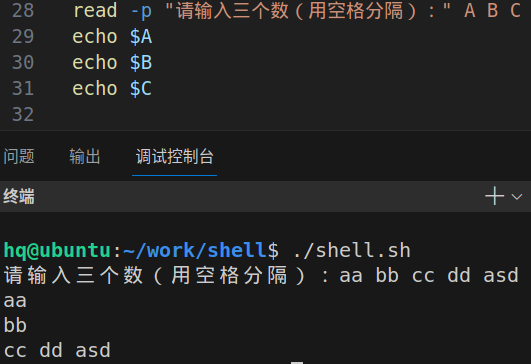
格式:read 变量名1 变量名2...
加提示语句:read -p "提示字符串" 变量名1 变量名2...
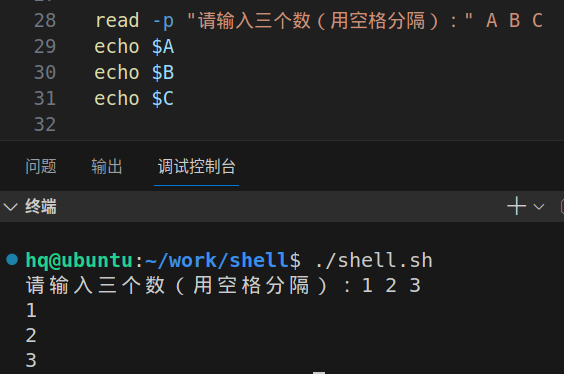
注:把终端读入空格隔开的第一个单词赋值给第一个变量,第二个单词赋值给第二个变量,依次类推赋值,剩余所有单词赋值给最后一个变量。
expr
算术运算命令expr 主要用于进行简单的整数运算,包括 +、-、*、/、% 等操作
注意:
1) 运算符左右两侧必须有空格
2) *和()必须加转义字符,\*、\( 、\)
3) expr语句可以直接输出运算结果
例:
NUM=`expr \( 15 + 8 \) \* 2`
echo $NUM
补充:也可以用双园括号(( ))进行运算,表达式和C语言写法一样
练习:
计算表达式值a*b+c-d/b; (使用shell脚本)
要求:
1)从终端读入4个数a,b,c,d;a=2,b=3,c=15,d=18
2)进行运算
3)打印结果输出到终端
read -p "请输入四个数(用空格分隔):" A B C D
NUM=`expr $A \* $B + $C - $D / $B`
((NUM=A*B+C-D/B))
echo "NUM="$NUMlet
注意:
1) 在运算中不能有空格
2) 运算结果需要赋值给一个变量
3) 变量参与运算的过程不用加 $ 取值
例:
read -p "请输入三个数:" VAL1 VAL2 VAL3
let NUM=\(VAL1+VAL2\)\*VAL3
let NUM++
echo $NUM
test
test语句可以测试三种对象
字符串 整数 文件属性
字符串测试
s1 = s2 测试两字符串的内容是否一样
test "hello" = "world"
echo $? # 1 相等为真,不相等为假
s1 != s2 测试字符串的内容是否有差异
test "hello" != "hello"
echo $? # 1 相等为假,不相等为真
-z s1 测试s1字符串长度是否为0
test -z ""
echo $? # 0 字符串的长度为0,则为真
test -z "hello"
echo $? # 1 字符串有长度,则为假
-n s1 测试s1字符串的长度是否不为空 (空的时候为假,反之为真)
test -n ""
echo $? # 1 字符串长度为空,则为假
test -n "hello"
echo $? # 0 字符串有长度,则为真
整数测试
a -eq b 测试a和b是否相等的 # equal
read A B
test $A -eq $B
echo $? # 如果两个数相等则为真,反之为假
a -ne b 测试a和b是否不相等 # no equal
read A B
test $A -ne $B
echo $? # 如果两个数不相等则为真,反之为假
a -gt b 测试a是否大于b # greater than
read A B
test $A -gt $B
echo $? # 如果a大于b则为真,反之为假
a -ge b 测试a是否大于等于b # greater equal than
read A B
test $A -ge $B
echo $? # 如果a大于等于b则为真,反之为假
a -lt b 测试a是否小于b # less then
read A B
test $A -lt $B
echo $? # 如果a小于b则为真,反之为假
a -le b 测试a是否小于等于b # less equal then
read A B
test $A -le $B
echo $? # 如果a小于等于b则为真,反之为假
文件属性测试
-d name 测试name是否是一个目录
test -d 路径
echo $? # 如果name是目录则为真,反之为假
-f name 测试name是否是一个普通文件
test -f 路径
echo $? # 如果name是普通文件则为真,反之为假
-e name 测试文件是否存在
test -e 路径
echo $? # 如果文件或者目录存在则为真,反之为假
结构性语句
条件测试语句
if...then...fi
基本结构
if 表达式
then
命令表
fi
分层结构
if 表达式
then
命令表1
else
命令表2
fi
嵌套结构
if 表达式1
then
if 表达式2
then
命令表2
else
命令表3
fi
else
命令表
fi
多路分支语句
elif
if 表达式1
then
命令表1
elif 表达式2
then
命令表2
elif 表达式3
then
命令表3
...
else
表达式n
fi
注意:
如果表达式为真, 则执行命令表中的命令; 否则退出if语句, 即执行fi后面的语句
if和fi是条件语句的语句括号, 必须成对使用
命令表中的命令可以是一条, 也可以是若干条
补充操作符:
-o 或运算 例如[$a -lt 20 -o $b -gt 100] 返回 true
-a 与运算 例如[$a -lt 20 -a $b -gt 100] 返回 false
!非运算 例如[ ! false ] 返回 true
&& 逻辑与 例如[[ $a -lt 100 && $b -gt 100 ]] 返回 false
|| 逻辑或 例如[[ $a -lt 100 || $b -gt 100 ]] 返回 true
| 位或 例如echo $[[2|2]]
& 位与 例如echo &[2&1]
练习:从终端输入3个整数,输出三个数中的最小值,使用shell脚本实现
#!/bin/bash
read -p "input 3 num:" val1 val2 val3
if [[ $val1 -gt $val3 && $val2 -gt $val3 ]]
then
echo $val3
elif [[ $val1 -lt $val2 && $val1 -lt $val3 ]]
then
echo $val1
else
echo $val2
ficase语句
case 变量 in
模式1)
命令表1
;;
模式2)
命令表2
;;
...
*)
表达式n
;;
esac
工作方式:
取值后面必须为关键字 in ,每一个模式必须以右括号结束
取值可以为变量或者常量,取值检测到匹配的每一个模式
一旦模式匹配,期间所有命令开始执行直至 ;;
执行完匹配模式相应的命令不会继续匹配其他的模式
如果无一匹配模式,使用 * 号捕获该值
练习:
学生成绩管理系统,用shell中的case实现
90-100:A
80-89:B
70-79:C
60-69:D
<60:不及格
#!/bin/bash
read -p "input student score:" n
case $n in
100|9[0-9])
echo "A"
;;
8[0-9])
echo "B"
;;
7[0-9])
echo "C"
;;
6[0-9])
echo "D"
;;
[1-5][0-9]|[0-9])
echo "不及格"
;;
*)
echo "error"
;;
esac循环语句
for循环
格式:
for 变量名 in 单词表
do
命令表
done
执行顺序:
变量依次取单词表中的各个单词,每次只取一个单词,就执行一次循环体中的命令,循环次数是由单词表中的单词数量决定,命令表中命令可以是一条,也可以是由分号或者换行符分开的多条
for语句的几种书写格式
1. 变量num从单词表中取值
for num in 1 2 3 4 5 6 7 8 9 10 do ... done
2. 变量num从 1-10个数取值
for num in {1..10} do ... done
3. 变量num从命令行中取值,省略in、单词表
for num do ... done
4. 书写格式类似C语言
for (( i = 0; i < 10; i++ )) do ... done
while循环
格式:
while 命令或者表达式
do
命令表
done
执行顺序:
while语句首先测试命令或者表达式的值,如果为真,就执行一次循环体中的命令,然后再测试该命令或者表达式的值,执行循环体,直到该命令或表达式为假时退出循环
循环控制语句
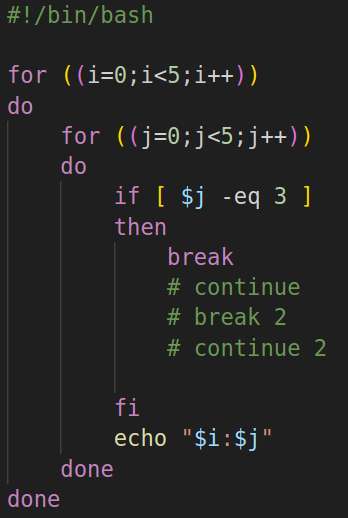
break n:结束n层循环
continue n:跳过n层 本次循环,继续下一次循环
shell中的数组
数组的赋值
1、arr=(1 2 3 4 5)
2、arr=($1 $2 $3...)
3、read a b c
arr=($a $b $c)
4、read -a arr
数组的调用
${arr[i]} 引用数组元素,数组下标从0开始到n-1结束(用循环语句)
arr[i]=10 对数组元素重新赋值
${arr[@]} 遍历数组
${#arr[@]} 数组元素的个数
#!/bin/bash
arr=(1 2 3 4) #数组元素赋值
n=${#arr[@]} #数组元素的个数
echo $n
echo ${arr[@]} #遍历数组元素
arr[1]=22 #将第二个元素重新赋值为22
for((i=0;i<n;i++)) #用for语句遍历数组
do
echo -n ${arr[i]}
done
echo练习:从终端输入3个整数,输出三个数中的最小值,使用数组实现
#!/bin/bash
read -a arr
n=${#arr[@]}
echo $n
min=${arr[0]}
i=1
while [ $i -lt $n ]
do
if [ ${arr[i]} -lt $min ]
then
min=${arr[i]}
fi
((i++))
done
echo $min冒泡排序:
#!/bin/bash
read -a arr
n=${#arr[@]}
echo $n
j=0
while [ $j -lt $((n-1)) ]
do
for((i=0;i<n-1-j;i++))
do
if [ ${arr[i]} -gt ${arr[i+1]} ]
then
t=${arr[i]}
arr[i]=${arr[((i+1))]}
arr[i+1]=$t
fi
done
((j++))
done
echo ${arr[@]}shell中的函数
函数定义
1、函数名( )
{
命令表
}
2、function 函数名( )
{
命令表
}
函数调用
函数名 参数列表
#!/bin/bash
fun ()
{
echo $0 $1 $2
}
fun hello world
function funs()
{
if [ $1 -eq 10 ]
then
echo "我是卧底"
else
echo "我不是卧底"
fi
}
funs 10函数体内$1 $2 表示的是传递给函数的参数
make工具
1. 工程管理器:管理较多的文件
Make工程管理也就是个 "自动编译管理器",这里的 "自动"是指它能够根据文件的时间戳,发现更新过的文件而减少编译的工作量同时它通过读入Makefile文件的内容来执行大量的编译工作
2. make工具的作用
当项目中包含了多个.c文件,但只对其中一个文件进行了修改,那用 gcc 编译会将所有的文件从头到尾编译一遍,这样的效率非常低
所以通过 make 工具,可以查找到修改过的文件(根据时间戳),只需要对修改过的文件进行编译,这样大大的减少了编译时间,提高编译效率
3. Makefile是make读入的唯一的配置文件
Makefile工程文本文件
4. Makefile的编写格式:
格式:
目标:依赖
<tab>命令
Makefile根据以下步骤编写:
gcc xxx.o -o xxx
gcc -c xxx.c -o xxx.o
例子:写一个Makefile文件
目标: 伪命令
<tab> 命令
伪命令它的目的不是创建目标文件,而是执行下面的命令
#第一版本
main:main.o add.o
gcc main.o add.o -o main
main.o:main.c
gcc -c main.c -o main.o
add.o:add.c
gcc -c add.c -o add.o
.PHONY:clean
clean:
rm main *.o执行Makefile:make
执行删除命令:make clean
规则中 rm 命令不是为了创建 clean 这个文件而是执行删除命令。当工作目录中不存在clean命名文件时,执行 make clean 命令 rm -rf *.o main总会被执行。
如果避免同名文件加 .PHONY:clean 不然当前目录下有有名字叫clean的文件会报:make:"clean"已是最新
Makefile变量
自定义变量
自己定义的变量:一般用大写表示变量名,取变量值用 $(变量名)
= 递归方式展开
:= 直接赋值(当前的值是什么就立即赋值)
+= 追加新的值
?= 判断之前是否定义,如果定义,不重新赋值,否则赋值
# 自定义变量
VAR=hello
SUM=$(VAR) world # 递归展开,VAR改变SUM随之改变
SUM:=$(VAR) world # 直接赋值,VAR改变SUM不随之改变
VAR=new
SUM+=where #在SUM后面追加新的值
SUM?=from #进行判断,判断之前是否定义,如果定义不能重新赋值,否则赋值
all:
echo $(VAR)
echo $(SUM)预定义变量
系统预先定义好的一些变量,可能有默认值可能没有
RM 文件删除程序的名称,默认值为 rm -f
CC C编译器的名称,默认值是cc
CPP C预编译的名称,默认值:$(CC) -E
CFLAGS C编译器的选项,无默认值
OBJS 生成的二进制文件或者目标文件,自己定义的
# 第二版本
CC=gcc
CFLAGS=-c -g -Wall #-c编译 -g调试 -Wall显示警告
OBJS=main.o add.o
main: $(OBJS)
$(CC) $(OBJS) -o main
main.o: main.c
$(CC) $(CFLAGS) main.c -o main.o
add.o: add.c
$(CC) $(CFLAGS) add.c -o add.o
.PHONY: clean
clean:
$(RM) *.o main自动变量
$< 第一个依赖文件
$@ 目标文件的完整名称
$^ 所有不重复的依赖文件,以空格分开
# 第三版本
CC=gcc
CFLAGS=-c -g -Wall
OBJS=main.o add.o
main: $(OBJS)
$(CC) $^ -o $@
%.o: %.c
$(CC) $(CFLAGS) $^ -o $@
.PHONY: clean
clean:
$(RM) *.o main可以用 %.c和 %.o去替换所有的.c和.o文件:相当于让每个.c生成各自的.o
# 终极版本
CC=gcc
CFLAGS=-c -g -Wall
OBJS=main.o add.o
main: $(OBJS)
$(CC) $^ -o $@
%.o: %.c
$(CC) $(CFLAGS) $^ -o $@
.PHONY: clean
clean:
$(RM) *.o mainmake指令
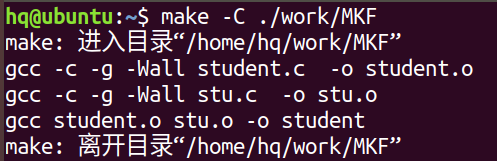
make -s:隐藏执行的指令
make -C 路径:进入指定路径去执行make指令

C高级部分
gcc 编译步骤
预处理:处理以#开头的内容,展开头文件、替换宏定义、删除注释,但是不会进行语法检查
gcc -E xxx.c -o xxx.i
编译:进行语法检查,将 .i文件转化成 .s汇编文件
gcc -S xxx.i -o xxx.s
汇编:将汇编文件转化成不可执行的二进制文件
gcc -c xxx.s -o xxx.o
链接:链接库文件,将不可执行的二进制文件转化成可执行的二进制文件
gcc xxx.o -o xxx
gdb调试工具
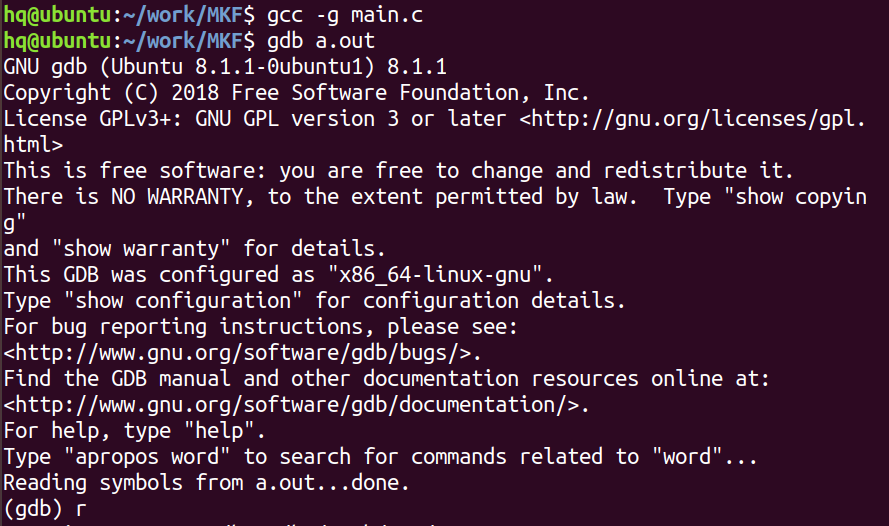
gcc -g xxx.c --->生成a.out
gdb a.out
r/run:运行代码
l/list:显示当前行下面的10行代码
b/break 函数名或者行号:添加断点
info b:查看断点信息
d/delete num:删除断点
p/print 变量名:查看变量的值
s/step:单步执行程序,如果是函数会进入
n/next:单步执行程序,如果是函数整体执行,不会进入
help:帮助
q:退出
gdb调试
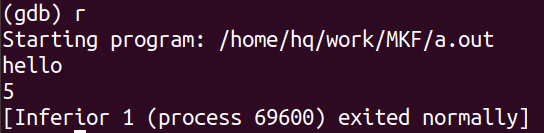
调试:
运行:
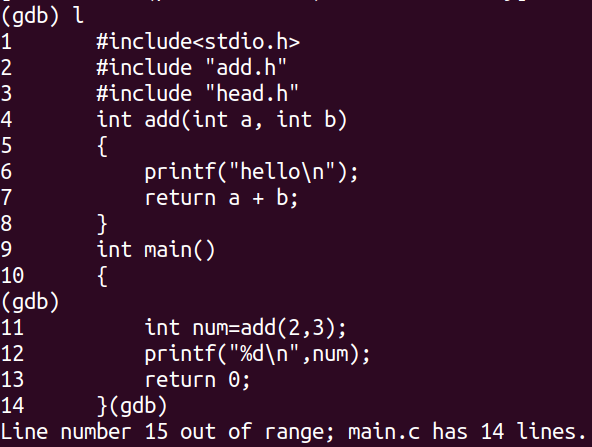
查看代码:
设置断点:
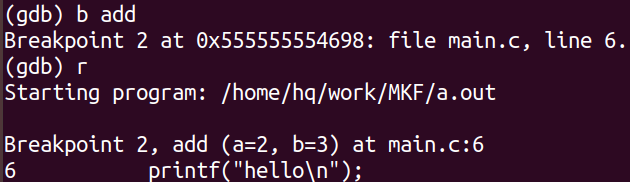
- 现在add函数处添加了断点,然后直接运行程序
- 然后就停在了6行(实际上是从第11行调用的),也就是在add函数中第一条语句的位置
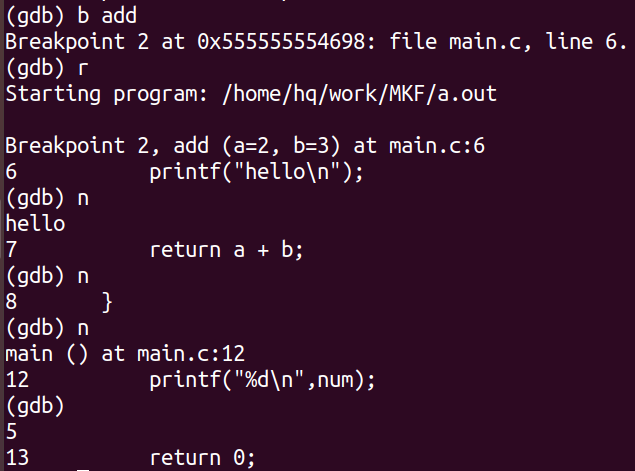
- 执行n指令,继续走一步,来到第7行
- 再次指令n指令,来到第8行
- 按下回车,执行上一次指令,也就是n,num赋值完成来到12行
- 再次重复上次操作,执行printf语句打印信息,显示下一行语句:return 0;
打印变量的值:

断点情况:
- 查看断点

- 删除断点
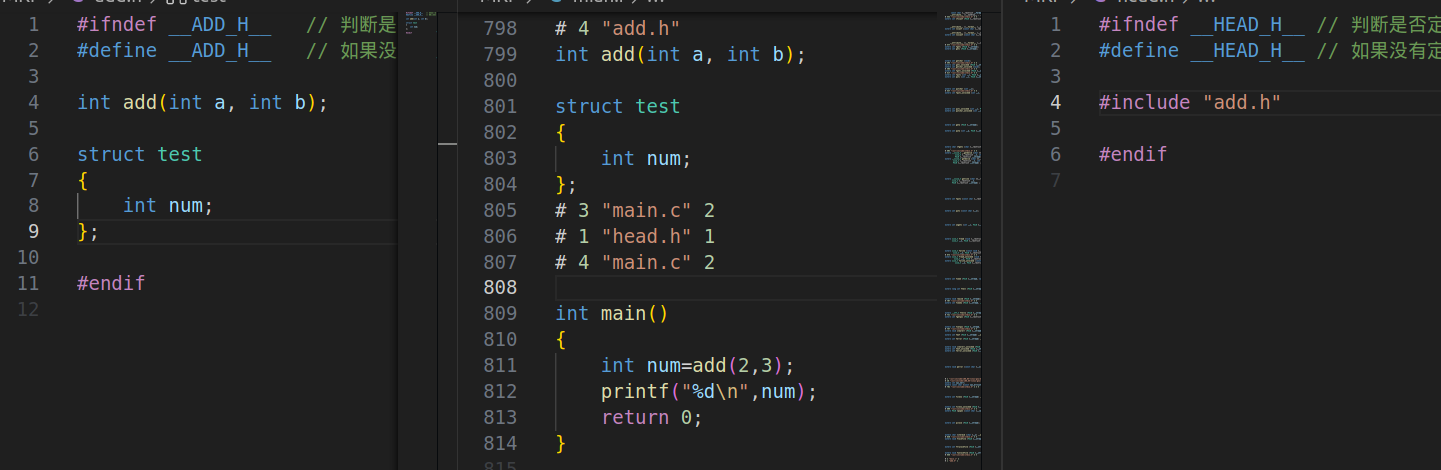
分文件编程
整个工程包含:多个.c文件和多个 .h文件
.c源文件:
1.main.c ----> main() // 这些文件统一由main函数调用
2.xxx.c ----> 多个.c //不同功能的函数接口
.h头文件:
1. 其他头文件
2. 函数的声明
3. 构造数据类型
4. 宏定义(define)
5. 重定义类型(typedef)
6. 外部引用(extern)
7. 全局变量
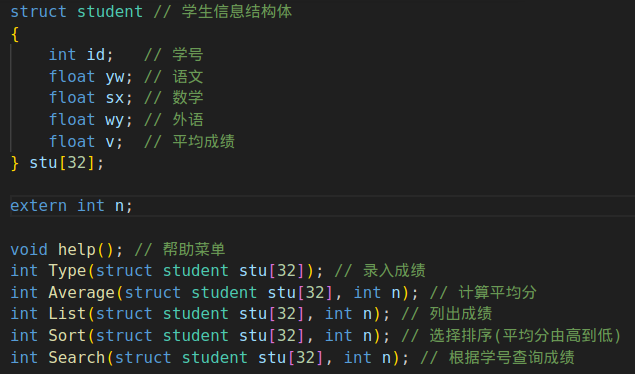
编译:gcc 所有.c文件
include 引用时 " " 和 <> 的区别
#include <stdio.h>
系统定义的头文件:去系统目录下查找头文件
#inlcude "add.h"
自定义的头文件:先去当前目录下查找,如果没有再去系统目录下查找头文件
编译器根据条件的真假决定是否编译相关的代码
条件编译
根据宏是否定义
#define 宏名
#ifdef 宏名
代码块1;
#else
代码块2;
#endif
#include <stdio.h>
#define DEF
int main(int argc, char const *argv[])
{
// 如果有DEF宏定义则下面的代码编译,否则else后面的代码编译
#ifdef DEF
printf("yes\n");
#else
printf("no\n");
#endif
return 0;
}
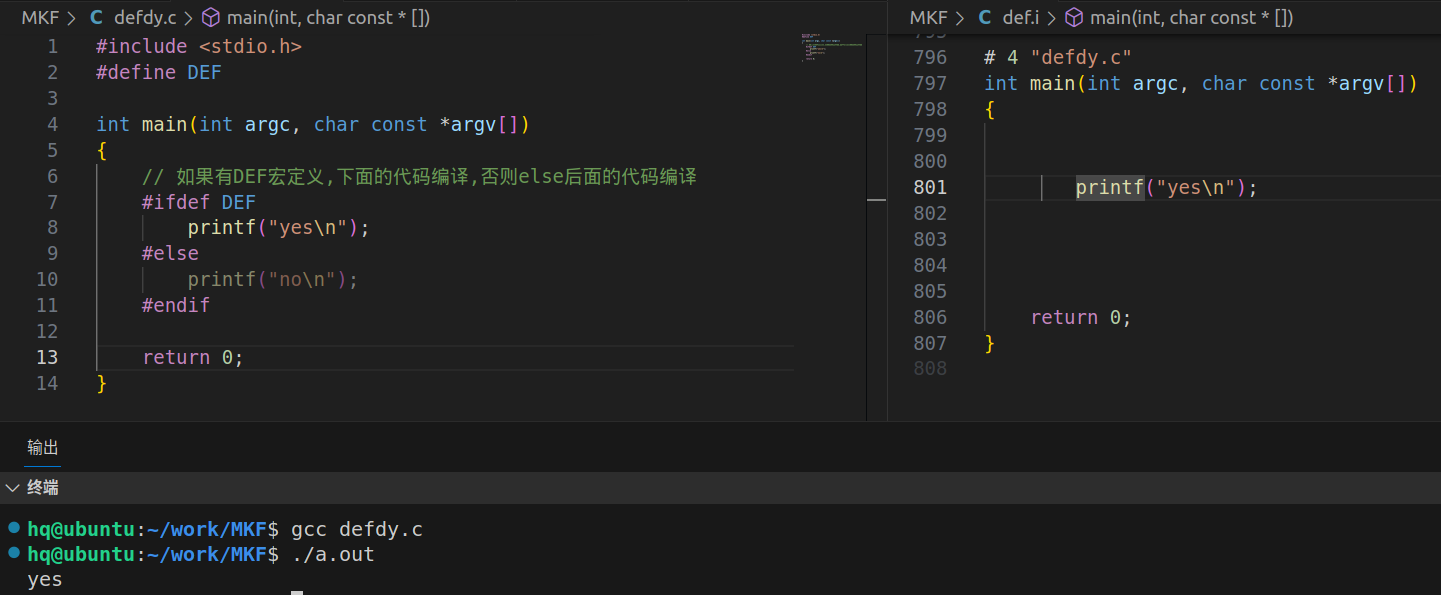
根据宏值是否为真
#define 宏名 值
#if 宏名
代码块1;
#else
代码块2;
#endif
#include <stdio.h>
#define DEF 1
int main(int argc, char const *argv[])
{
#if DEF
printf("yes\n");
#else
printf("no\n");
#endif
return 0;
}
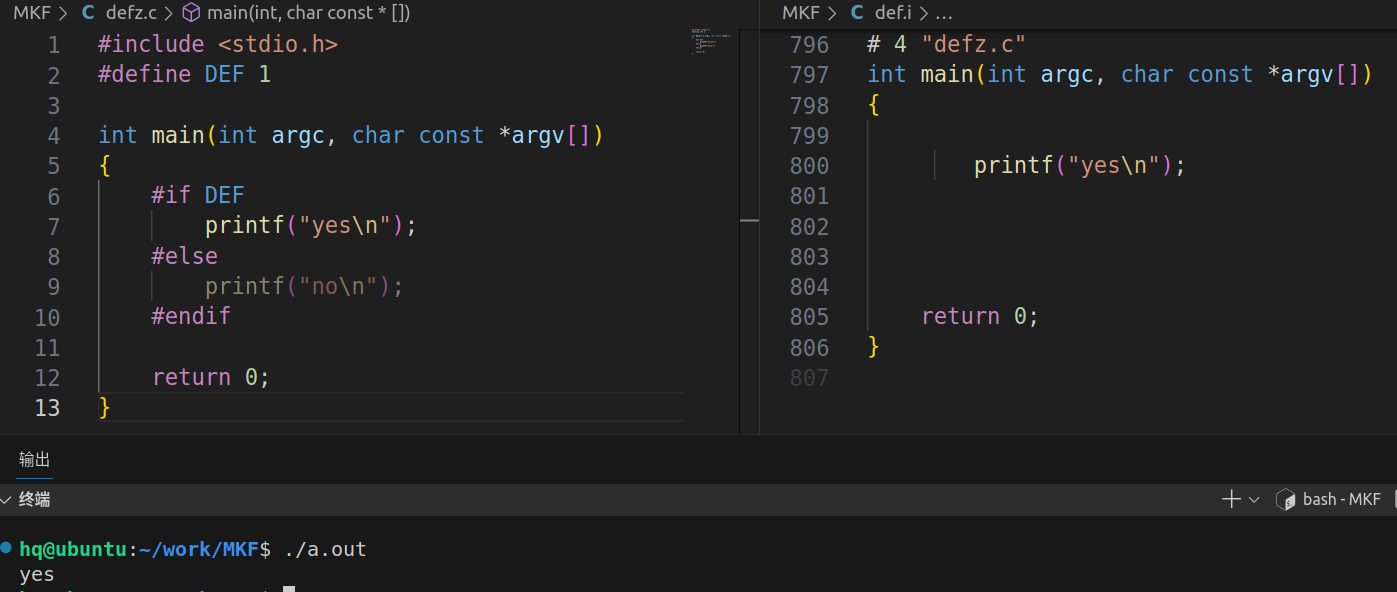
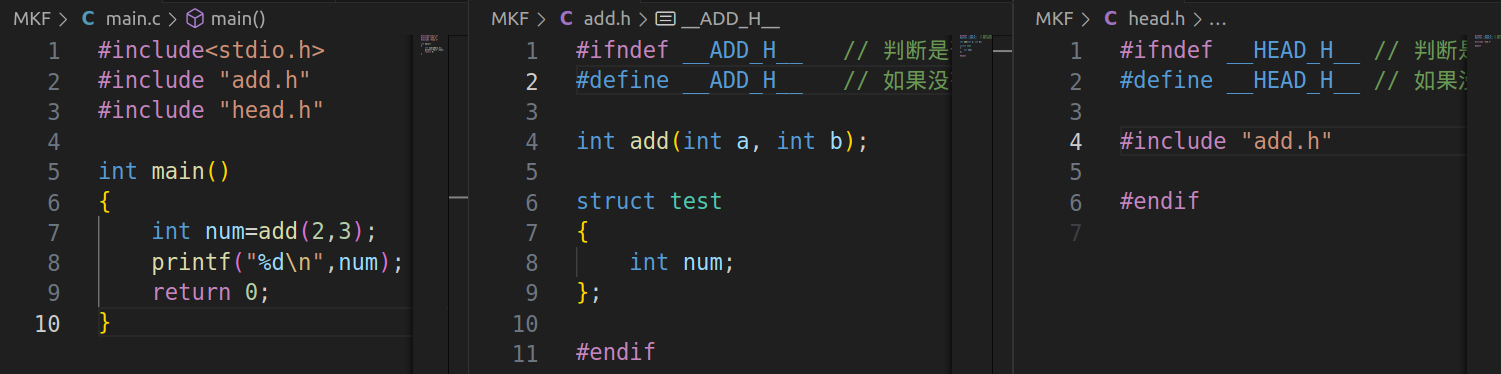
根据宏是否定义,作用:防止头文件重复包含
#ifndef 宏名 // 如果没有定义这个宏
#define 宏名 // 那么我就去定义这个宏,然后去使用
...
#endif
指针函数
本质上是函数,函数的返回值是地址
定义格式
存储类型 数据类型 *函数名(形参)
{
函数体;
return 地址; //失败一般返回NULL
}
函数内开辟空间
错误案例一:
#include<stdio.h>
char *fun()
{
char *buf[32]="hello";
return buf;
}
int main(int argc, char const *argv[])
{
char *p=NULL;
p=fun();
printf("%s\n",p);
return 0;
}结果未知,因为返回局部变量地址,函数调用结束后没有权限使用栈区空间了所以结果是不可控的。如果被其他进程占用,可能会报段错误或打印奇怪的东西。
修改:可以返回堆区的地址
#include<stdio.h>
#includ<stdlib.h>
#include<string.h>
char *fun() //p=&q
{
char *p=(char *)malloc(32); //*p=*&q=q
if(NULL==*P)
{
printf("error");
return NULL;
}
strcpy(*p,"hello");
return p;
}
int main(int argc, char const *argv[])
{
char *q=fun();
printf("%s\n",q);
return 0;
}错误案例二:
#include<stdio.h>
#includ<stdlib.h>
#include<string.h>
char fun(char *p) //p=NULL
{
p=(char *)malloc(32); //改变p的指向,让p指向开辟的堆区空间
if(NULL==P)
printf("error");
strcpy(p,"hello");
}
int main(int argc, char const *argv[])
{
char *q=NULL;
fun(q); //函数调用后,q依然指向NULL
//p在堆区空间,而q在堆区空间,改变函数内的p不会影响函数外的q
printf("%s\n",q);
return 0;
}
//段错误段错误:p在堆区空间,而q在堆区空间,改变函数内的p不会影响函数外的q,q还是指向NULL
修改:传递二级指针
#include<stdio.h>
#includ<stdlib.h>
#include<string.h>
char fun(char **p) //p=&q
{
*p=(char *)malloc(32); //*p=*&q=q
if(NULL==*P)
printf("error");
strcpy(*p,"hello");
}
int main(int argc, char const *argv[])
{
char *q=NULL;
fun(&q); //把q的地址传递给p,让二级指针p指向一级指针q
//p在堆区空间,而q在堆区空间,改变函数内的p不会影响函数外的q
printf("%s\n",q);
return 0;
}函数指针
本质上是指针,指向函数的指针
函数名:就是函数的首地址
定义格式
存储类型 数据类型 (*函数指针变量名)(形参列表)
数据类型:指向函数的返回值类型一致
形参列表:指向函数的参数列表一致
函数名:函数首地址
通过函数指针调用函数
函数指针变量名(实参) ---> 指针代替函数名去调用函数
(*函数指针变量名)(实参) ---> 不常用
#include<stdio.h>
int add(int a,int b)
{
return a+b;
}
int sub(int a,int b)
{
return a-b;
}
int test(int (*p)(int,int),int a,int b)//把函数指针当成参数传递给函数
{
return p(a,b); //add(a,b) sub(a,b)
}
int main(int argc, char const *argv[])
{
int (*p)(int,int); //定义函数指针
p=add; //函数指针p指向函数add
p=sub; //函数指针p指向函数sub
printf("%d %d\n",p(2,2),p(2,2);//用指针代替函数名调用函数
printf("%d %d\n",test(add,2,2),test(sub,2,2));
return 0;
}使用:
当一个函数指针指向了一个函数,就可以通过这个指针来调用该函数
什么情况下使用函数指针:
有机会看到 Linux 内核原码的时候,很多函数的参数用的是函数指针
这样写有什么意义?
方便、扩展性强,只需要一个 test 函数,可以实现不同的功能,这就是"多态"的特性,
面向对象三大特性:封装、继承、多态,我只需要一个接口,实现不同功能,就可以简化代码
结构体内成员是函数指针
#include<stdio.h>
struct pp
{
int (*p)(int,int); //函数指针
}t;
int add(int a,int b)
{
return a+b;
}
int main(int argc, char const *argv[])
{
t.p=add; //通过.访问函数指针p指向函数add
printf("%d\n",t.p(2,2));
return 0;
}函数指针数组
本质是数组,数组中元素是函数指针
定义格式
数据类型 (*数组名[元素个数])(参数列表);
数据类型:和函数指针指向的函数的返回值一致
参数列表:和函数指针指向的函数参数一致
赋值
#include<stdio.h>
int add(int a,int b)
{
return a+b;
}
int sub(int a,int b)
{
return a-b;
}
int main(int argc, char const *argv[])
{
int (*arr[3])(int,int)={add,sub}; //函数指针数组
printf("%d %d\n",arr[0](2,2),arr[1](2,2));
return 0;
}