见仓库:
https://github.com/MaybeBio/video2ppt
以下是修改后的代码,并附有每一行的详细解释。修改的主要部分包括:
- 使用绝对路径:确保输出目录使用绝对路径,避免相对路径引起的问题。
- 增加调试信息:在保存图像前后添加更多的打印语句,以便更好地了解程序运行状态。
- 检查输出目录权限:确保程序有权限在指定目录下创建和写入文件。
- 优化错误处理:提供更详细的错误信息,帮助定位问题。
import os
from datetime import datetime
import cv2
from fpdf import FPDF
# 指定视频文件所在的目录路径 (绝对路径)
directory_path = r'D:\download\gene\动植物基因表达调控(研)_于明\ppt_real'
# 指定输出图像和PDF的目录 (绝对路径)
output_directory = os.path.join(directory_path, 'output_directory')
os.makedirs(output_directory, exist_ok=True) # 如果目录不存在,则创建
# 获取目录下所有文件的列表
file_list = os.listdir(directory_path)
# 按照文件的修改时间进行排序
file_list.sort(key=lambda x: os.path.getmtime(os.path.join(directory_path, x)))
# 遍历排序后的文件列表
for file_name in file_list:
file_path = os.path.join(directory_path, file_name)
# 检查是否为文件而非子目录
if not os.path.isfile(file_path):
continue # 跳过非文件项
# 获取文件的修改时间
modified_time = datetime.fromtimestamp(os.path.getmtime(file_path))
print(f"正在处理文件: {file_path}")
print(f"文件名:{file_name},修改时间:{modified_time}")
# 打开视频文件
cap = cv2.VideoCapture(file_path)
# 检查视频是否成功打开
if not cap.isOpened():
print(f"无法打开视频文件: {file_path}")
continue # 跳过无法打开的视频文件
# 初始化变量
prev_frame_gray_1 = None
prev_frame_gray_2 = None
page_images = []
i = 0
while True:
ret, frame = cap.read()
if not ret:
break # 读取完毕或发生错误
# 检查帧是否为空
if frame is None:
continue
# 确保感兴趣区域的坐标在帧的边界内
if frame.shape[0] < 720 or frame.shape[1] < 1280:
print(f"帧尺寸不足,跳过该帧,帧尺寸:{frame.shape}")
continue
# 调整感兴趣区域的坐标以适应帧的实际尺寸
roi_1 = frame[660:720, 1180:1280] # 感兴趣区域1
roi_2 = frame[300:460, 360:500] # 感兴趣区域2
# 将感兴趣区域转换为灰度图像
roi_gray_1 = cv2.cvtColor(roi_1, cv2.COLOR_BGR2GRAY)
roi_gray_2 = cv2.cvtColor(roi_2, cv2.COLOR_BGR2GRAY)
# 初始化前一帧灰度图像
if prev_frame_gray_1 is None:
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
continue # 跳过第一帧的差分检测
# 计算当前帧和前一帧的差分图像
frame_diff_1 = cv2.absdiff(roi_gray_1, prev_frame_gray_1)
frame_diff_2 = cv2.absdiff(roi_gray_2, prev_frame_gray_2)
# 对差分图像进行阈值处理
_, threshold_1 = cv2.threshold(frame_diff_1, 30, 255, cv2.THRESH_BINARY)
_, threshold_2 = cv2.threshold(frame_diff_2, 30, 255, cv2.THRESH_BINARY)
# 统计阈值图像中非零像素的数量
diff_pixels_1 = cv2.countNonZero(threshold_1)
diff_pixels_2 = cv2.countNonZero(threshold_2)
# 如果两个区域的差分像素数量都超过阈值,则认为帧发生了变化
if (diff_pixels_1 > 100 and diff_pixels_2 > 300) or diff_pixels_1 > 150 or diff_pixels_2 > 1000:
print(f"帧发生变化: {i + 1}, 差分像素1: {diff_pixels_1}, 差分像素2: {diff_pixels_2}")
# 生成安全的文件名,移除特殊字符
safe_file_name = ''.join(c for c in file_name if c.isalnum() or c in (' ', '_')).rstrip()
page_path = os.path.join(output_directory, f"{safe_file_name}_page_{i + 1}.jpg")
# 尝试保存图像
try:
# 检查输出目录是否存在
if not os.path.exists(output_directory):
os.makedirs(output_directory, exist_ok=True)
print(f"创建输出目录: {output_directory}")
# 保存图像
success = cv2.imwrite(page_path, frame)
if success:
print(f"图像已保存: {page_path}")
page_images.append(page_path)
else:
print(f"图像保存失败: {page_path}")
except Exception as e:
print(f"保存图像时发生错误: {str(e)}")
i += 1
# 更新前一帧
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
# 显示当前帧 (可选,运行时可关闭窗口加快速度)
# cv2.imshow("Frame", frame)
# 跳过一定数量的帧以加快处理速度
current_frame = cap.get(cv2.CAP_PROP_POS_FRAMES)
max_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 计算目标帧的索引(例如跳500帧)
target_frame = current_frame + 500
if target_frame >= max_frames:
break # 超过总帧数,结束处理
cap.set(cv2.CAP_PROP_POS_FRAMES, target_frame)
# 按下 'q' 键退出循环 (可选,已注释)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
cap.release()
cv2.destroyAllWindows()
# 创建PDF文件
pdf = FPDF()
pdf.set_auto_page_break(auto=True, margin=15)
for image_path in page_images:
if os.path.exists(image_path):
pdf.add_page()
# 计算图片的宽度和高度,以适应PDF页面
pdf_width = pdf.w - 20 # 左右各10的边距
pdf.image(image_path, x=10, y=10, w=pdf_width)
else:
print(f"图像文件不存在: {image_path}")
# 保存PDF
pdf_file_name = os.path.splitext(file_name)[0] + '.pdf'
pdf_path = os.path.join(output_directory, pdf_file_name)
try:
pdf.output(pdf_path)
print(f"已保存PDF: {pdf_path}")
except Exception as e:
print(f"保存PDF时发生错误: {str(e)}")
代码详解
- 导入所需模块
import os
from datetime import datetime
import cv2
from fpdf import FPDF
- `os`:用于处理文件和目录路径。
- `datetime`:用于获取文件的修改时间。
- `cv2`:OpenCV库,用于视频处理和图像保存。
- `fpdf`:用于生成PDF文件。
- 指定视频文件所在的目录路径
directory_path = r'D:\download\gene\动植物基因表达调控(研)_于明\ppt_real'
- `directory_path`:视频文件存放的绝对路径。
- 指定输出图像和PDF的目录
output_directory = os.path.join(directory_path, 'output_directory')
os.makedirs(output_directory, exist_ok=True)
- `output_directory`:生成的图像和PDF将保存到该目录下。
- `os.makedirs`:创建输出目录,如果目录已存在则不会报错。
- 获取目录下所有文件的列表并按修改时间排序
file_list = os.listdir(directory_path)
file_list.sort(key=lambda x: os.path.getmtime(os.path.join(directory_path, x)))
- 获取目录中所有文件,并按文件的修改时间进行排序,确保按时间顺序处理视频文件。
- 遍历排序后的文件列表
for file_name in file_list:
file_path = os.path.join(directory_path, file_name)
- 遍历每个文件,构建文件的绝对路径。
- 检查是否为文件
if not os.path.isfile(file_path):
continue
- 跳过子目录或非文件项,确保只处理文件。
- 获取文件的修改时间并打印信息
modified_time = datetime.fromtimestamp(os.path.getmtime(file_path))
print(f"正在处理文件: {file_path}")
print(f"文件名:{file_name},修改时间:{modified_time}")
- 获取并打印当前处理文件的名称和修改时间。
- 打开视频文件并检查是否成功
cap = cv2.VideoCapture(file_path)
if not cap.isOpened():
print(f"无法打开视频文件: {file_path}")
continue
- 使用OpenCV打开视频文件,如果无法打开,则跳过该文件。
- 初始化变量
prev_frame_gray_1 = None
prev_frame_gray_2 = None
page_images = []
i = 0
- `prev_frame_gray_1` 和 `prev_frame_gray_2` 用于存储前一帧的灰度图像。
- `page_images` 用于存储检测到变化的帧的图像路径。
- `i` 用于计数保存的图像数量。
- 读取视频帧并处理
while True:
ret, frame = cap.read()
if not ret:
break
if frame is None:
continue
if frame.shape[0] < 720 or frame.shape[1] < 1280:
print(f"帧尺寸不足,跳过该帧,帧尺寸:{frame.shape}")
continue
roi_1 = frame[660:720, 1180:1280]
roi_2 = frame[300:460, 360:500]
roi_gray_1 = cv2.cvtColor(roi_1, cv2.COLOR_BGR2GRAY)
roi_gray_2 = cv2.cvtColor(roi_2, cv2.COLOR_BGR2GRAY)
if prev_frame_gray_1 is None:
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
continue
frame_diff_1 = cv2.absdiff(roi_gray_1, prev_frame_gray_1)
frame_diff_2 = cv2.absdiff(roi_gray_2, prev_frame_gray_2)
_, threshold_1 = cv2.threshold(frame_diff_1, 30, 255, cv2.THRESH_BINARY)
_, threshold_2 = cv2.threshold(frame_diff_2, 30, 255, cv2.THRESH_BINARY)
diff_pixels_1 = cv2.countNonZero(threshold_1)
diff_pixels_2 = cv2.countNonZero(threshold_2)
if (diff_pixels_1 > 100 and diff_pixels_2 > 300) or diff_pixels_1 > 150 or diff_pixels_2 > 1000:
print(f"帧发生变化: {i + 1}, 差分像素1: {diff_pixels_1}, 差分像素2: {diff_pixels_2}")
safe_file_name = ''.join(c for c in file_name if c.isalnum() or c in (' ', '_')).rstrip()
page_path = os.path.join(output_directory, f"{safe_file_name}_page_{i + 1}.jpg")
try:
if not os.path.exists(output_directory):
os.makedirs(output_directory, exist_ok=True)
print(f"创建输出目录: {output_directory}")
success = cv2.imwrite(page_path, frame)
if success:
print(f"图像已保存: {page_path}")
page_images.append(page_path)
else:
print(f"图像保存失败: {page_path}")
except Exception as e:
print(f"保存图像时发生错误: {str(e)}")
i += 1
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
current_frame = cap.get(cv2.CAP_PROP_POS_FRAMES)
max_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
target_frame = current_frame + 500
if target_frame >= max_frames:
break
cap.set(cv2.CAP_PROP_POS_FRAMES, target_frame)
- **读取帧**:使用 `cap.read()` 读取视频的每一帧。
- **检查帧有效性**:确保帧不为空且尺寸符合要求。
- **定义感兴趣区域(ROI)**:选取视频帧中需要监测变化的区域。
- **转换为灰度图像**:便于进行差分计算。
- **初始化前一帧**:为第一帧设置前一帧的灰度图像。
- **计算帧差分**:通过 `cv2.absdiff` 计算当前帧与前一帧的差异。
- **阈值处理**:将差分图像进行二值化,突出变化区域。
- **统计变化像素**:计算二值化图像中非零像素的数量,作为变化的指标。
- **变化检测**:根据阈值判断是否发生了显著变化。
- **保存变化帧**:如果检测到变化,尝试保存当前帧为图像文件。
- **跳帧处理**:每检测到一次变化后,跳过500帧以加快处理速度。
- 释放资源并关闭窗口
cap.release()
cv2.destroyAllWindows()
- 释放视频捕捉对象并关闭所有OpenCV窗口。
- 创建PDF文件
pdf = FPDF()
pdf.set_auto_page_break(auto=True, margin=15)
for image_path in page_images:
if os.path.exists(image_path):
pdf.add_page()
pdf_width = pdf.w - 20 # 左右各10的边距
pdf.image(image_path, x=10, y=10, w=pdf_width)
else:
print(f"图像文件不存在: {image_path}")
- 初始化 `FPDF` 对象,并设置自动分页。
- 遍历保存的图像,将每张图像添加到PDF中,调整图片宽度以适应页面。
- 保存PDF文件
pdf_file_name = os.path.splitext(file_name)[0] + '.pdf'
pdf_path = os.path.join(output_directory, pdf_file_name)
try:
pdf.output(pdf_path)
print(f"已保存PDF: {pdf_path}")
except Exception as e:
print(f"保存PDF时发生错误: {str(e)}")
- 生成PDF文件的名称,并保存到输出目录中。
- 捕捉保存过程中的异常,打印错误信息。
可能的修复点
- 使用绝对路径:确保输出目录使用绝对路径,避免因为当前工作目录不同导致的路径错误。
- 权限问题:确保程序有权限在指定的输出目录下创建和写入文件,特别是在Windows系统中。
- 文件名安全性:通过移除文件名中的特殊字符,避免因非法字符导致保存失败。
- 检查帧数据:确保
frame数据在保存前是有效的,可以通过打印frame.shape或其他方式进行验证。 - OpenCV 编码器支持:确保OpenCV支持保存JPEG格式,必要时可以尝试保存为其他格式(如PNG)以测试。
调试建议
- 打印更多信息:在
cv2.imwrite之前后打印frame的相关信息,如数据类型、尺寸等。 - 尝试不同的图像格式:将保存格式从
.jpg改为.png以测试是否为编码器问题。
page_path = os.path.join(output_directory, f"{safe_file_name}_page_{i + 1}.png")
- 检查磁盘空间:确保目标磁盘有足够的空间来保存图像文件。
- 手动测试保存图像:在脚本外部,手动使用OpenCV保存一张图像,确保环境配置正确。
sample_image_path = os.path.join(output_directory, "test_image.jpg")
cv2.imwrite(sample_image_path, frame)
如果这一步失败,说明问题可能出在环境配置或路径权限上。
通过以上修改和调试,应该能够定位并解决“图像保存失败”的问题。如果问题依然存在,可以提供更多的错误日志或环境信息,以便进一步分析。
修改之后:
```plain
import os
from datetime import datetime
import cv2
from fpdf import FPDF
import re
# 指定视频文件所在的目录路径 (绝对路径)
directory_path = r'D:\download\gene\ppt_real'
# 指定输出图像和PDF的目录 (绝对路径)
output_directory = os.path.join(directory_path, 'ppt_directory')
os.makedirs(output_directory, exist_ok=True) # 如果目录不存在,则创建
# 获取目录下所有文件的列表
file_list = os.listdir(directory_path)
# 按照文件的修改时间进行排序
file_list.sort(key=lambda x: os.path.getmtime(os.path.join(directory_path, x)))
# 遍历排序后的文件列表
for file_name in file_list:
file_path = os.path.join(directory_path, file_name)
# 检查是否为文件而非子目录
if not os.path.isfile(file_path):
continue # 跳过非文件项
# 获取文件的修改时间
modified_time = datetime.fromtimestamp(os.path.getmtime(file_path))
print(f"正在处理文件: {file_path}")
print(f"文件名:{file_name},修改时间:{modified_time}")
# 打开视频文件
cap = cv2.VideoCapture(file_path)
# 检查视频是否成功打开
if not cap.isOpened():
print(f"无法打开视频文件: {file_path}")
continue # 跳过无法打开的视频文件
# 初始化变量
prev_frame_gray_1 = None
prev_frame_gray_2 = None
page_images = []
i = 0
while True:
ret, frame = cap.read()
if not ret:
break # 读取完毕或发生错误
# 检查帧是否为空
if frame is None:
continue
# 确保感兴趣区域的坐标在帧的边界内
if frame.shape[0] < 720 or frame.shape[1] < 1280:
print(f"帧尺寸不足,跳过该帧,帧尺寸:{frame.shape}")
continue
# 调整感兴趣区域的坐标以适应帧的实际尺寸
roi_1 = frame[660:720, 1180:1280] # 感兴趣区域1
roi_2 = frame[300:460, 360:500] # 感兴趣区域2
# 在帧上绘制感兴趣区域的矩形框
cv2.rectangle(frame, (1180, 660), (1280, 720), (0, 255, 0), 2) # 绘制感兴趣区域1
cv2.rectangle(frame, (360, 300), (500, 460), (0, 255, 0), 2) # 绘制感兴趣区域2
# 将感兴趣区域转换为灰度图像
roi_gray_1 = cv2.cvtColor(roi_1, cv2.COLOR_BGR2GRAY)
roi_gray_2 = cv2.cvtColor(roi_2, cv2.COLOR_BGR2GRAY)
# 初始化前一帧灰度图像
if prev_frame_gray_1 is None:
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
continue # 跳过第一帧的差分检测
# 计算当前帧和前一帧的差分图像
frame_diff_1 = cv2.absdiff(roi_gray_1, prev_frame_gray_1)
frame_diff_2 = cv2.absdiff(roi_gray_2, prev_frame_gray_2)
# 对差分图像进行阈值处理
_, threshold_1 = cv2.threshold(frame_diff_1, 30, 255, cv2.THRESH_BINARY)
_, threshold_2 = cv2.threshold(frame_diff_2, 30, 255, cv2.THRESH_BINARY)
# 统计阈值图像中非零像素的数量
diff_pixels_1 = cv2.countNonZero(threshold_1)
diff_pixels_2 = cv2.countNonZero(threshold_2)
# 如果两个区域的差分像素数量都超过阈值,则认为帧发生了变化
if (diff_pixels_1 > 100 and diff_pixels_2 > 300) or diff_pixels_1 > 150 or diff_pixels_2 > 1000:
print(f"帧发生变化: {i + 1}, 差分像素1: {diff_pixels_1}, 差分像素2: {diff_pixels_2}")
# 提取文件名中的编号部分
match = re.search(r'第(\d+)讲', file_name)
if match:
lecture_number = match.group(1)
else:
lecture_number = 'unknown'
# 生成简化的文件名
simplified_file_name = f"{lecture_number}_{i + 1}.jpg"
page_path = os.path.join(output_directory, simplified_file_name)
# 尝试保存图像
try:
# 检查输出目录是否存在
if not os.path.exists(output_directory):
os.makedirs(output_directory, exist_ok=True)
print(f"创建输出目录: {output_directory}")
# 保存图像
success = cv2.imwrite(page_path, frame)
if success:
print(f"图像已保存: {page_path}")
page_images.append(page_path)
else:
print(f"图像保存失败: {page_path}")
except Exception as e:
print(f"保存图像时发生错误: {str(e)}")
i += 1
# 更新前一帧
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
# 显示当前帧 (可选,运行时可关闭窗口加快速度)
cv2.imshow("Frame", frame)
# 跳过一定数量的帧以加快处理速度
current_frame = cap.get(cv2.CAP_PROP_POS_FRAMES)
max_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 计算目标帧的索引(例如跳500帧)
target_frame = current_frame + 500
if target_frame >= max_frames:
break # 超过总帧数,结束处理
cap.set(cv2.CAP_PROP_POS_FRAMES, target_frame)
# 按下 'q' 键退出循环 (可选,已注释)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 创建PDF文件
pdf = FPDF()
pdf.set_auto_page_break(auto=True, margin=15)
for image_path in page_images:
if os.path.exists(image_path):
pdf.add_page()
# 计算图片的宽度和高度,以适应PDF页面
pdf_width = pdf.w - 20 # 左右各10的边距
pdf.image(image_path, x=10, y=10, w=pdf_width)
else:
print(f"图像文件不存在: {image_path}")
# 保存PDF
pdf_file_name = os.path.splitext(file_name)[0] + '.pdf'
pdf_path = os.path.join(output_directory, pdf_file_name)
try:
pdf.output(pdf_path)
print(f"已保存PDF: {pdf_path}")
except Exception as e:
print(f"保存PDF时发生错误: {str(e)}")
中间那个区域方框还可以,但是右下角那个就有点不起作用了;
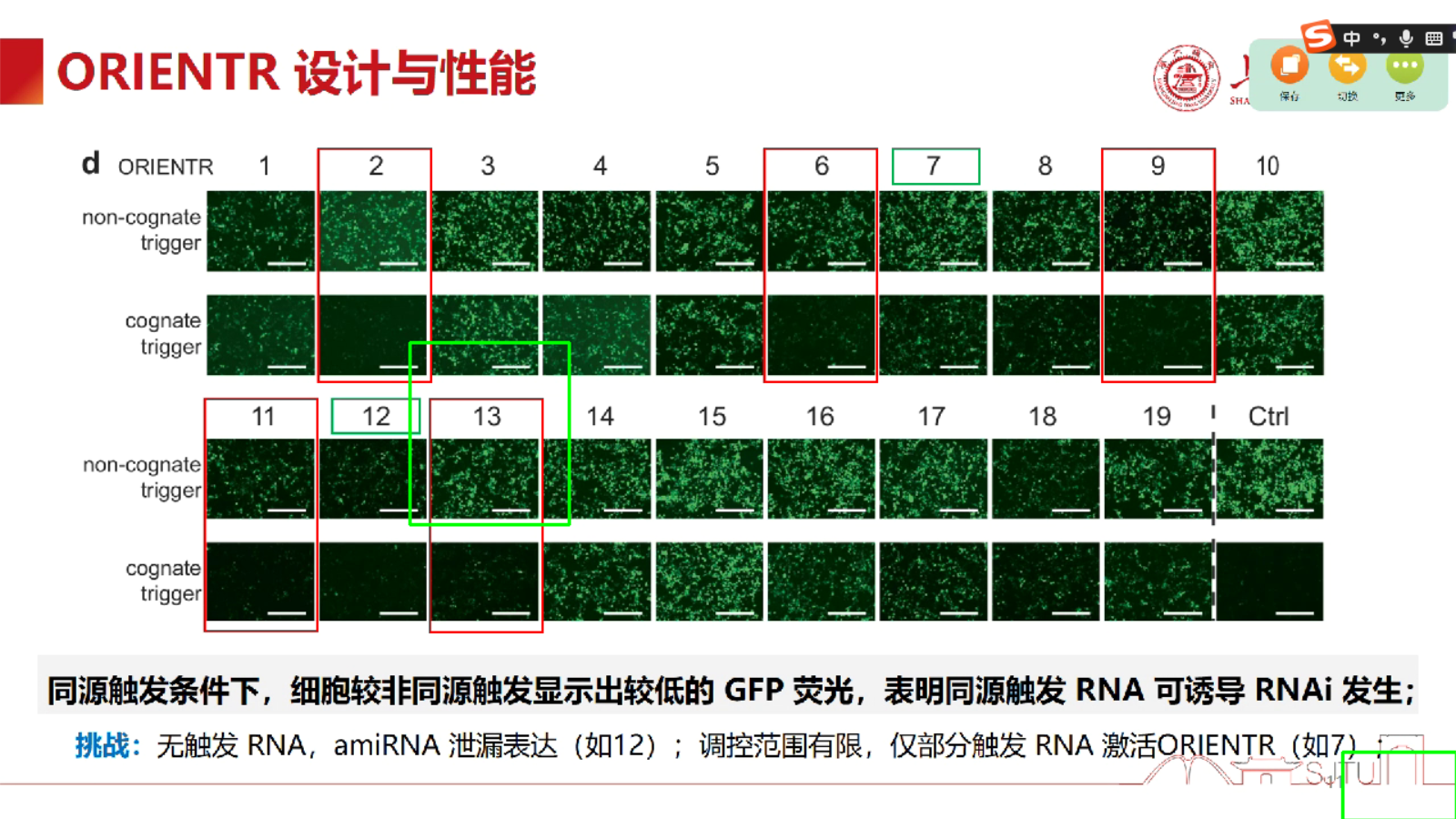
中间那个可以放大一下,右边那个可以左上角移动一下:
import os
from datetime import datetime
import cv2
from fpdf import FPDF
import re
# 指定视频文件所在的目录路径 (绝对路径)
directory_path = r'D:\download\gene\ppt_real'
# 指定输出图像和PDF的目录 (绝对路径)
output_directory = os.path.join(directory_path, 'output_directory')
os.makedirs(output_directory, exist_ok=True) # 如果目录不存在,则创建
# 获取目录下所有文件的列表
file_list = os.listdir(directory_path)
# 按照文件的修改时间进行排序
file_list.sort(key=lambda x: os.path.getmtime(os.path.join(directory_path, x)))
# 遍历排序后的文件列表
for file_name in file_list:
file_path = os.path.join(directory_path, file_name)
# 检查是否为文件而非子目录
if not os.path.isfile(file_path):
continue # 跳过非文件项
# 获取文件的修改时间
modified_time = datetime.fromtimestamp(os.path.getmtime(file_path))
print(f"正在处理文件: {file_path}")
print(f"文件名:{file_name},修改时间:{modified_time}")
# 打开视频文件
cap = cv2.VideoCapture(file_path)
# 检查视频是否成功打开
if not cap.isOpened():
print(f"无法打开视频文件: {file_path}")
continue # 跳过无法打开的视频文件
# 初始化变量
prev_frame_gray_1 = None
prev_frame_gray_2 = None
page_images = []
i = 0
while True:
ret, frame = cap.read()
if not ret:
break # 读取完毕或发生错误
# 检查帧是否为空
if frame is None:
continue
# 确保感兴趣区域的坐标在帧的边界内
if frame.shape[0] < 720 or frame.shape[1] < 1280:
print(f"帧尺寸不足,跳过该帧,帧尺寸:{frame.shape}")
continue
# 调整感兴趣区域的坐标以适应帧的实际尺寸
roi_1 = frame[620:680, 1140:1240] # 感兴趣区域1,左上移动一些
roi_2 = frame[280:500, 340:540] # 感兴趣区域2,扩大一些
# 在帧上绘制感兴趣区域的矩形框
cv2.rectangle(frame, (1140, 620), (1240, 680), (0, 255, 0), 2) # 绘制感兴趣区域1
cv2.rectangle(frame, (340, 280), (540, 500), (0, 255, 0), 2) # 绘制感兴趣区域2
# 将感兴趣区域转换为灰度图像
roi_gray_1 = cv2.cvtColor(roi_1, cv2.COLOR_BGR2GRAY)
roi_gray_2 = cv2.cvtColor(roi_2, cv2.COLOR_BGR2GRAY)
# 初始化前一帧灰度图像
if prev_frame_gray_1 is None:
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
continue # 跳过第一帧的差分检测
# 计算当前帧和前一帧的差分图像
frame_diff_1 = cv2.absdiff(roi_gray_1, prev_frame_gray_1)
frame_diff_2 = cv2.absdiff(roi_gray_2, prev_frame_gray_2)
# 对差分图像进行阈值处理
_, threshold_1 = cv2.threshold(frame_diff_1, 30, 255, cv2.THRESH_BINARY)
_, threshold_2 = cv2.threshold(frame_diff_2, 30, 255, cv2.THRESH_BINARY)
# 统计阈值图像中非零像素的数量
diff_pixels_1 = cv2.countNonZero(threshold_1)
diff_pixels_2 = cv2.countNonZero(threshold_2)
# 如果两个区域的差分像素数量都超过阈值,则认为帧发生了变化
if (diff_pixels_1 > 100 and diff_pixels_2 > 300) or diff_pixels_1 > 150 or diff_pixels_2 > 1000:
print(f"帧发生变化: {i + 1}, 差分像素1: {diff_pixels_1}, 差分像素2: {diff_pixels_2}")
# 提取文件名中的编号部分
match = re.search(r'第(\d+)讲', file_name)
if match:
lecture_number = match.group(1)
else:
lecture_number = 'unknown'
# 生成简化的文件名
simplified_file_name = f"{lecture_number}_{i + 1}.jpg"
page_path = os.path.join(output_directory, simplified_file_name)
# 尝试保存图像
try:
# 检查输出目录是否存在
if not os.path.exists(output_directory):
os.makedirs(output_directory, exist_ok=True)
print(f"创建输出目录: {output_directory}")
# 保存图像
success = cv2.imwrite(page_path, frame)
if success:
print(f"图像已保存: {page_path}")
page_images.append(page_path)
else:
print(f"图像保存失败: {page_path}")
except Exception as e:
print(f"保存图像时发生错误: {str(e)}")
i += 1
# 更新前一帧
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
# 显示当前帧 (可选,运行时可关闭窗口加快速度)
cv2.imshow("Frame", frame)
# 跳过一定数量的帧以加快处理速度
current_frame = cap.get(cv2.CAP_PROP_POS_FRAMES)
max_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 计算目标帧的索引(例如跳500帧)
target_frame = current_frame + 500
if target_frame >= max_frames:
break # 超过总帧数,结束处理
cap.set(cv2.CAP_PROP_POS_FRAMES, target_frame)
# 按下 'q' 键退出循环 (可选,已注释)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# 创建PDF文件
pdf = FPDF()
pdf.set_auto_page_break(auto=True, margin=15)
for image_path in page_images:
if os.path.exists(image_path):
pdf.add_page()
# 计算图片的宽度和高度,以适应PDF页面
pdf_width = pdf.w - 20 # 左右各10的边距
pdf.image(image_path, x=10, y=10, w=pdf_width)
else:
print(f"图像文件不存在: {image_path}")
# 保存PDF
pdf_file_name = os.path.splitext(file_name)[0] + '.pdf'
pdf_path = os.path.join(output_directory, pdf_file_name)
try:
pdf.output(pdf_path)
print(f"已保存PDF: {pdf_path}")
except Exception as e:
print(f"保存PDF时发生错误: {str(e)}")
最后还要考虑视频中截取的每一帧的图片的尺寸与最后pdf的尺寸之间的区别
import os
from datetime import datetime
import cv2
from fpdf import FPDF
import re
# 指定视频文件所在的目录路径 (绝对路径)
directory_path = r'D:\download\gene\ppt_real'
# 指定输出图像和PDF的目录 (绝对路径)
output_directory = os.path.join(directory_path, 'ppt')
os.makedirs(output_directory, exist_ok=True) # 如果目录不存在,则创建
# 获取目录下所有文件的列表
file_list = os.listdir(directory_path)
# 按照文件的修改时间进行排序
file_list.sort(key=lambda x: os.path.getmtime(os.path.join(directory_path, x)))
# 遍历排序后的文件列表
for file_name in file_list:
file_path = os.path.join(directory_path, file_name)
# 检查是否为文件而非子目录
if not os.path.isfile(file_path):
continue # 跳过非文件项
# 获取文件的修改时间
modified_time = datetime.fromtimestamp(os.path.getmtime(file_path))
print(f"正在处理文件: {file_path}")
print(f"文件名:{file_name},修改时间:{modified_time}")
# 打开视频文件
cap = cv2.VideoCapture(file_path)
# 检查视频是否成功打开
if not cap.isOpened():
print(f"无法打开视频文件: {file_path}")
continue # 跳过无法打开的视频文件
# 初始化变量
prev_frame_gray_1 = None
prev_frame_gray_2 = None
page_images = []
i = 0
while True:
ret, frame = cap.read()
if not ret:
break # 读取完毕或发生错误
# 检查帧是否为空
if frame is None:
continue
# 确保感兴趣区域的坐标在帧的边界内
if frame.shape[0] < 720 or frame.shape[1] < 1280:
print(f"帧尺寸不足,跳过该帧,帧尺寸:{frame.shape}")
continue
# 调整感兴趣区域的坐标以适应帧的实际尺寸
roi_1 = frame[480:660, 1060:1200] # 感兴趣区域1,往上移动100像素
roi_2 = frame[280:500, 340:540] # 感兴趣区域2,扩大一些
# 将感兴趣区域转换为灰度图像
roi_gray_1 = cv2.cvtColor(roi_1, cv2.COLOR_BGR2GRAY)
roi_gray_2 = cv2.cvtColor(roi_2, cv2.COLOR_BGR2GRAY)
# 初始化前一帧灰度图像
if prev_frame_gray_1 is None:
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
continue # 跳过第一帧的差分检测
# 计算当前帧和前一帧的差分图像
frame_diff_1 = cv2.absdiff(roi_gray_1, prev_frame_gray_1)
frame_diff_2 = cv2.absdiff(roi_gray_2, prev_frame_gray_2)
# 对差分图像进行阈值处理
_, threshold_1 = cv2.threshold(frame_diff_1, 30, 255, cv2.THRESH_BINARY)
_, threshold_2 = cv2.threshold(frame_diff_2, 30, 255, cv2.THRESH_BINARY)
# 统计阈值图像中非零像素的数量
diff_pixels_1 = cv2.countNonZero(threshold_1)
diff_pixels_2 = cv2.countNonZero(threshold_2)
# 如果两个区域的差分像素数量都超过阈值,则认为帧发生了变化
if (diff_pixels_1 > 100 and diff_pixels_2 > 300) or diff_pixels_1 > 150 or diff_pixels_2 > 1000:
print(f"帧发生变化: {i + 1}, 差分像素1: {diff_pixels_1}, 差分像素2: {diff_pixels_2}")
# 提取文件名中的编号部分
match = re.search(r'第(\d+)讲', file_name)
if match:
lecture_number = match.group(1)
else:
lecture_number = 'unknown'
# 生成简化的文件名
simplified_file_name = f"{lecture_number}_{i + 1}.jpg"
page_path = os.path.join(output_directory, simplified_file_name)
# 尝试保存图像
try:
# 检查输出目录是否存在
if not os.path.exists(output_directory):
os.makedirs(output_directory, exist_ok=True)
print(f"创建输出目录: {output_directory}")
# 保存图像
success = cv2.imwrite(page_path, frame)
if success:
print(f"图像已保存: {page_path}")
page_images.append(page_path)
else:
print(f"图像保存失败: {page_path}")
except Exception as e:
print(f"保存图像时发生错误: {str(e)}")
i += 1
# 更新前一帧
prev_frame_gray_1 = roi_gray_1.copy()
prev_frame_gray_2 = roi_gray_2.copy()
# 显示当前帧 (可选,运行时可关闭窗口加快速度)
cv2.imshow("Frame", frame)
# 跳过一定数量的帧以加快处理速度
current_frame = cap.get(cv2.CAP_PROP_POS_FRAMES)
max_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
# 计算目标帧的索引(例如跳500帧)
target_frame = current_frame + 100
if target_frame >= max_frames:
break # 超过总帧数,结束处理
cap.set(cv2.CAP_PROP_POS_FRAMES, target_frame)
# 按下 'q' 键退出循环 (可选,已注释)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
cap.release()
cv2.destroyAllWindows()
# 创建PDF文件
pdf = FPDF(orientation='L', unit='mm', format='A4') # 使用横向A4纸
pdf.set_auto_page_break(auto=True, margin=15)
for image_path in page_images:
if os.path.exists(image_path):
pdf.add_page()
# 计算图片的宽度和高度,以适应PDF页面
pdf_width = pdf.w # 左右各5的边距
pdf_height = pdf.h - 20 # 上下各10的边距
pdf.image(image_path, x=5, y=10, w=pdf_width, h=pdf_height)
else:
print(f"图像文件不存在: {image_path}")
# 保存PDF
pdf_file_name = os.path.splitext(file_name)[0] + '.pdf'
pdf_path = os.path.join(output_directory, pdf_file_name)
try:
pdf.output(pdf_path)
print(f"已保存PDF: {pdf_path}")
except Exception as e:
print(f"保存PDF时发生错误: {str(e)}")
跳的帧数需要经验参考,此处使用100帧,当然有些ppt跳的快,可能需要50帧以内等,有些需要更多;
总之设置一个尽可能小的rough的数目,然后再去调整哪些ppt是没有用的。