一、哈希表

哈希表(Hash table)是一种常用、重要、高效的数据结构。
哈希表通过哈希函数,可以快速地将键(Key)映射到值(Value)。从而允许在近常数时间内对键关联的值进行插入、删除和查找操作。
哈希表的主要思想是通过哈希函数将键转换为索引,将索引映射到数组中的存储位置
通俗的例子是,为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表,在首字母为L的表中查找“雷”姓的电话号码,显然比直接查找就要快得多。
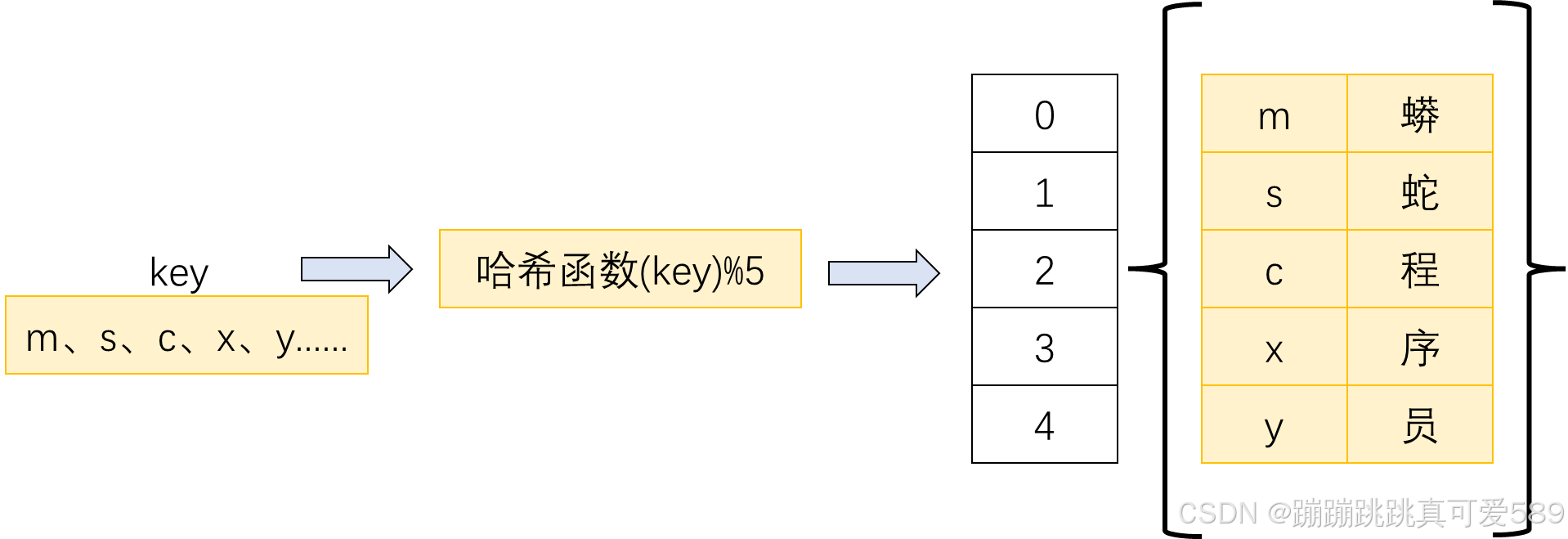
二、代码展示
2.1、键值对
class Pair:
"""键值对的类,包含一个键和一个值"""
def __init__(self, key: int, val: str):
"""初始化键值对"""
self.key = key # 键,整数类型
self.val = val # 值,字符串类型
def __repr__(self):
"""返回键值对的字符串表示"""
return f"{self.key} -> {self.val}" 2.2、初始化
def __init__(self):
"""构造方法,初始化哈希表"""
# 创建一个包含 100 个桶的数组
self.buckets: list[Pair | None] = [None] * 100 2.3、哈希函数
def hash_func(self, key: int) -> int:
"""哈希函数,将键映射到索引"""
index = hash(key) % 100 # 使用内置哈希函数计算键的哈希值,并对桶的数量取模
return index 2.4、添加键值对
def put(self, key: int, val: str):
"""添加键值对到哈希表"""
pair = Pair(key, val) # 创建新的键值对
index: int = self.hash_func(key) # 计算键的哈希索引
self.buckets[index] = pair # 将键值对放入相应的桶中 2.5、查询值
def get(self, key: int) -> str:
"""根据给定的键查询值"""
index: int = self.hash_func(key) # 计算键的哈希索引
pair: Pair = self.buckets[index] # 获取对应的键值对
if pair is None:
return None # 如果未找到,返回 None
return pair.val # 返回找到的值 2.6、删除键值对
def remove(self, key: int):
"""根据给定的键删除键值对"""
index: int = self.hash_func(key) # 计算键的哈希索引
self.buckets[index] = None # 将桶置为 None,表示删除 2.7、返回所有键值对
def entry_set(self) -> list[Pair]:
"""返回哈希表中所有的键值对"""
result: list[Pair] = []
for pair in self.buckets:
if pair is not None:
result.append(pair) # 将非空桶的键值对添加到结果列表中
return result 2.8、返回键
def key_set(self) -> list[int]:
"""返回哈希表中所有的键"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.key) # 将非空桶的键添加到结果列表中
return result 2.9、返回值
def value_set(self) -> list[str]:
"""返回哈希表中所有的值"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.val) # 将非空桶的值添加到结果列表中
return result 2.10、输出
def print(self):
"""打印哈希表中的所有键值对"""
for pair in self.buckets:
if pair is not None:
print(pair.key, "->", pair.val) # 打印每个键值对 2.11、完整代码
class Pair:
"""键值对的类,包含一个键和一个值"""
def __init__(self, key: int, val: str):
"""初始化键值对"""
self.key = key # 键,整数类型
self.val = val # 值,字符串类型
def __repr__(self):
"""返回键值对的字符串表示"""
return f"{self.key} -> {self.val}"
class ArrayHashMap:
"""基于数组实现的哈希表"""
def __init__(self):
"""构造方法,初始化哈希表"""
# 创建一个包含 100 个桶的数组
self.buckets: list[Pair | None] = [None] * 100
def hash_func(self, key: int) -> int:
"""哈希函数,将键映射到索引"""
index = hash(key) % 100 # 使用内置哈希函数计算键的哈希值,并对桶的数量取模
return index
def put(self, key: int, val: str):
"""添加键值对到哈希表"""
pair = Pair(key, val) # 创建新的键值对
index: int = self.hash_func(key) # 计算键的哈希索引
self.buckets[index] = pair # 将键值对放入相应的桶中
def get(self, key: int) -> str:
"""根据给定的键查询值"""
index: int = self.hash_func(key) # 计算键的哈希索引
pair: Pair = self.buckets[index] # 获取对应的键值对
if pair is None:
return None # 如果未找到,返回 None
return pair.val # 返回找到的值
def remove(self, key: int):
"""根据给定的键删除键值对"""
index: int = self.hash_func(key) # 计算键的哈希索引
self.buckets[index] = None # 将桶置为 None,表示删除
def entry_set(self) -> list[Pair]:
"""返回哈希表中所有的键值对"""
result: list[Pair] = []
for pair in self.buckets:
if pair is not None:
result.append(pair) # 将非空桶的键值对添加到结果列表中
return result
def key_set(self) -> list[int]:
"""返回哈希表中所有的键"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.key) # 将非空桶的键添加到结果列表中
return result
def value_set(self) -> list[str]:
"""返回哈希表中所有的值"""
result = []
for pair in self.buckets:
if pair is not None:
result.append(pair.val) # 将非空桶的值添加到结果列表中
return result
def print(self):
"""打印哈希表中的所有键值对"""
for pair in self.buckets:
if pair is not None:
print(pair.key, "->", pair.val) # 打印每个键值对
if __name__ == '__main__':
map = ArrayHashMap() # 创建一个新的哈希表实例
map.put('m', '蟒') # 添加键值对
map.put('s', '蛇')
map.put('c', '程')
map.put('x', '序')
map.put('y', '员')
# 查询并打印值
print(map.get('m')) # 输出:蟒
print(map.get('s')) # 输出:蛇
print(map.get('c')) # 输出:程
print(map.get('x')) # 输出:序
print(map.get('y')) # 输出:员
# 打印哈希表的内容
map.print()
print(map.entry_set()) # 输出所有的键值对三、 哈希冲突
若key(关键字)为n,则其值存放在 f(n) = n % size 的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f函数为哈希(散列)函数,按这个思想建立的表为哈希(散列)表
但对不同的关键字可能得到同一散列地址,即n1 ≠ n2,而f(n1)==f(n2),这种现象称为冲突
3.1、散列函数
哈希表中元素的位置是由哈希函数确定的。将数据n作为自变量,通过一定的函数关系计算出的值,即为该元素的存储地址。
3.1.1、直接定址法
直接使用key的某些部分作为存储地址,适用于关键字的取值范围不大的情况
假设我们有一组学生ID,并决定使用学生ID本身作为哈希地址
公式:哈希地址 = 学生ID
3.1.2、数字分析法
针对key的数位进行分析,选择具有代表性的数位作为哈希地址。
适用于关键字具有一定规律的情况假设我们有一组社交安全号码,我们选择使用最后两位数字作为哈希地址
对于123-45-6789,我们取最后两位89作为哈希地址
3.1.3、平方取中法
将关键字的平方值的中间一部分作为哈希地址。
适用于关键字分布较均匀的情况假设我们有一组三位数,我们将每个数字平方,然后取中间的数字作为哈希地址
对于数字456,平方得到207936。取中间两位数字
哈希地址为79公式:哈希地址 = 取中位数字(平方(关键字))
3.1.4、折叠法
将关键字分割成固定长度的片段,然后将这些片段相加,再取余数作为哈希地址。
适用于关键字长度较长的情况。考虑一组电话号码(例如,123-456-7890)。
我们可以将数字分成两位一组,求和,然后取模得到哈希地址对于电话号码123-456-7890,哈希地址将是(12 + 34 + 56 + 78 + 90) % 表大小
公式:哈希地址 = 组的数字之和(关键字) % 表大小
3.1.5、随机数法
用一个随机数生成器产生哈希地址。适用于关键字分布随机的情况
3.1.6、除留余数数法(常用)
将关键字除以某个不大于哈希表大小的数,取余数作为哈希地址
公式:哈希地址 = 关键字 % 表大小
3.2、 哈希冲突处理的办法
1、单独链表法(常用)
每个桶(数组元素)存储一个链表或其他数据结构(如列表)。所有哈希到同一索引的元素都放在这个链表中。
2、开放定址法
当发生哈希冲突时,试探性地寻找下一个空桶以存储新的键值对。可以使用线性探测、二次探测或者双重散列来确定下一个桶的位置。
3、双散列
是开放定址法的一种变体,使用两个不同的哈希函数。当发生冲突时,第二个哈希函数决定下一步的探测位置,从而实现更均匀的分布。
4、再散列
当哈希表达到一定的负载因子时,扩展表的大小并重新计算所有元素的位置,分散冲突。一般会将哈希表的容量加倍,并使用新的哈希函数或改变现有的哈希函数。
5、建立一个公共溢出区
设计一个额外的数组(溢出区)用于存储溢出(冲突)的元素。每当一个桶中溢出时,它就会将该元素放入溢出区。