这个标题是最近看到的一篇文章《What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives》有感而发,也感觉很有意思。在几年前,在项目中还经常会用到Bert。本文主要回顾一下Bert的原理、Bert的继续训练和使用,以及对看到的文章中关于Bert这类以encoder为主的模型逐步淡出舞台做一定的分析总结。
1. Bert原理
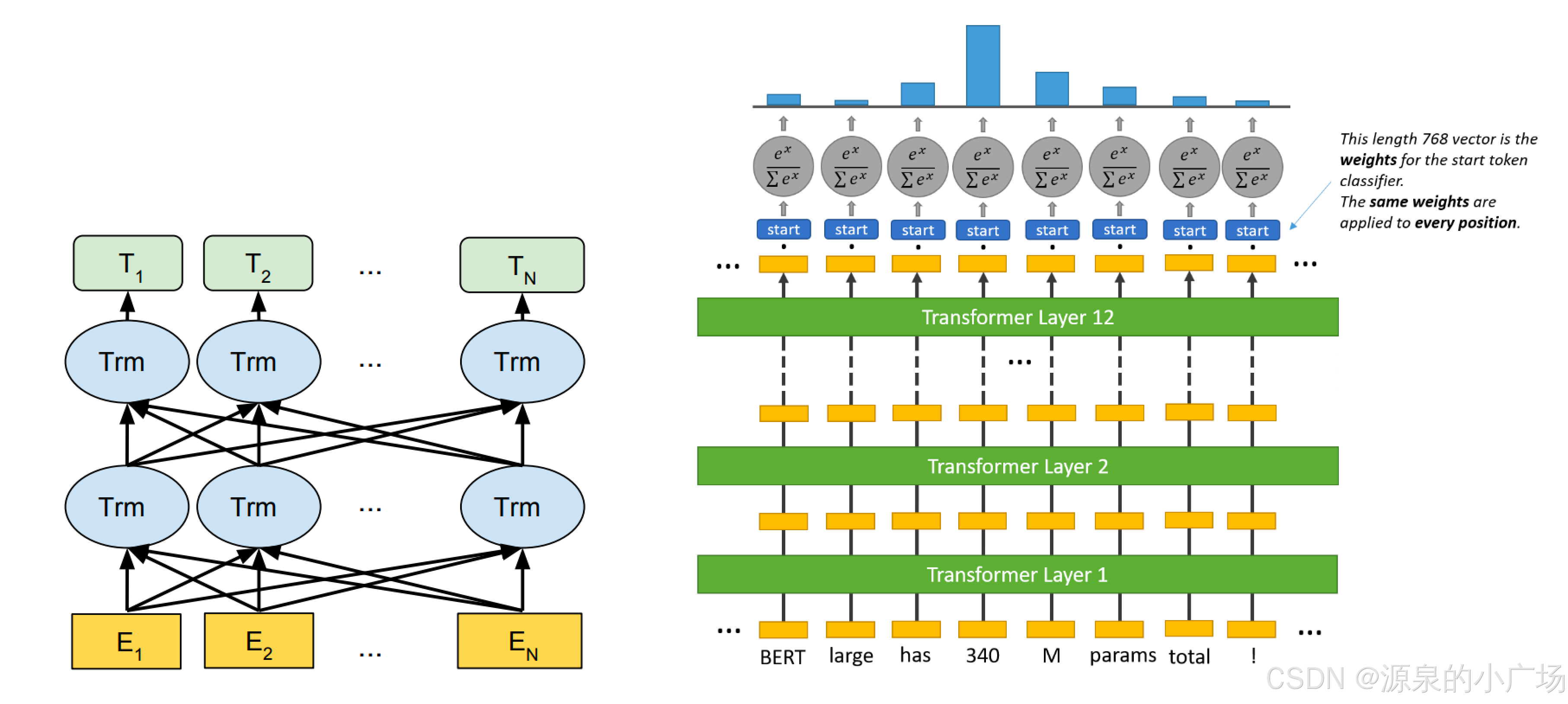
BERT (Bidirectional Encoder Representations from Transformers) 【1】是一种基于Transformer架构的预训练语言模型。BERT的设计使其能够在文本的上下文中理解单词的含义。BERT模型的原理:
-
Transformer架构:BERT基于Transformer的Encoder部分,关于Transformer的原理介绍可以参考《Transformer原理及关键模块深入浅出》。Transformer是由多个层的自注意力机制组成的,能够捕捉序列中各个位置之间的依赖关系。BERT使用的是双向Transformer Encoder,这意味着它能够同时考虑一个单词左边和右边的上下文信息。
-
双向性:BERT是双向的。传统的语言模型通常是单向的,即只能从左到右或从右到左预测单词。而BERT通过双向训练方法,能够在同一时间考虑文本的前后文,从而更好地理解单词在句子中的意义。
-
预训练任务:
- Masked Language Model (MLM):在训练过程中,BERT会随机掩盖输入序列中的一些单词,然后让模型预测这些被掩盖的单词。通过这种方式,模型学会在有缺失信息的情况下推测上下文。
- Next Sentence Prediction (NSP):BERT还通过预测两句话之间的关系进行训练。具体来说,模型会接收一对句子,并判断第二个句子是否紧接第一个句子。这种任务帮助BERT理解句子级别的关系。
关于双向性的思考:
1. 在单向语言模型中,模型生成每个词的表示时,不能利用当前词右侧的上下文信息。因此,对于某些依赖于右侧上下文的信息,模型可能无法准确理解。例如,在句子“他在银行里存钱”中,单向模型只能依赖于左侧的上下文来预测“银行”是金融机构的“银行”,而无法利用“存钱”这一右侧信息。而在BERT中,模型可以同时利用“银行”左右两侧的信息,从而更准确地理解句子的意思。
2. BERT的训练目标是通过掩蔽部分词(即MLM),然后让模型预测这些被掩蔽的词。由于被掩蔽的词可能出现在句子的任意位置(既可能在左边,也可能在右边),BERT必须同时使用来自两边的上下文来预测这些词。
3. 在某些情况下,单向模型可能对多义词或复杂句子的理解存在偏差,因为它只能利用部分上下文信息。BERT通过双向机制,使得模型可以更好地理解这些复杂情况中的词语含义,并生成更为精确的词表示。双向性在处理复杂的句子结构、消歧义、多义词理解等任务中准确性会更高。
2. 业务问题、Bert的继续训练及使用
在大模型盛行之前,其实自己的很多项目还是会引入Bert来支撑,特别是在垂直领域的对话系统项目中。那么Bert能解决哪些问题?在回答这个问题之前,我们需要先分析对话系统需要解决哪些关键问题? 最主要的业务矛盾是什么?
以自己的项目经历来说,对话系统中起着至关重要的作用的是两种,NLU (Natural Language Understanding) 和 NLG (Natural Language Generation) ,共同构建了对话系统的核心能力。
2.1 NLU (Natural Language Understanding) - 自然语言理解
NLU的概念: NLU是指计算机从用户输入的自然语言文本中提取出有意义的信息并进行理解的过程。它关注如何让计算机“理解”人类语言,包括语义、意图、情感等方面。NLU是对话系统中理解用户意图的基础。
NLU的主要任务:
意图识别
这是NLU中的核心任务,目的是确定用户输入背后的意图。比如在对话系统中,用户可能会输入“我想订一张飞往纽约的机票”,NLU需要识别用户的意图是“预订航班”。实体识别
实体识别 (Named Entity Recognition, NER) 是从用户输入中提取出特定的实体,如人名、地点、日期等。例如,前述例子中的“纽约”是一个地点实体,“机票”是一个对象实体。语义解析
语义解析将自然语言句子转换为一种可以由机器理解和处理的结构化表示。例如,将句子解析为一棵语法树或一个数据库查询。情感分析
情感分析是确定用户表达的情感倾向,如正面、负面或中性。情感分析可以帮助对话系统调整响应的语气或内容。
在对话系统中,NLU用于分析用户输入,以理解他们的需求。通过意图识别、实体识别和语义解析,系统能够将自然语言转换为结构化的数据,从而使系统能够采取相应的行动,如调用某个API、从数据库中提取信息,或生成合适的响应。
2.2 NLG (Natural Language Generation) - 自然语言生成
NLG的概念: NLG是指计算机自动生成符合人类语言习惯的自然语言文本的过程。它的目标是让计算机能够根据结构化数据或内部表示生成流畅、自然的语言输出。
NLG的主要任务:
内容确定
NLG首先需要决定生成的文本应该包含哪些信息。一般需要基于对话系统的上下文、用户意图以及当前任务。句子规划
句子规划是指决定如何组织和安排文本的结构。包括句子间的逻辑关系和信息的层次结构。文本生成
在文本生成阶段,NLG将内容和句子规划转化为自然语言文本。这一步涉及选择合适的词汇和句式,确保生成的文本符合语法规则并且易于理解。风格和语气控制
根据上下文或用户的偏好,对话系统可能需要生成特定风格或语气的文本。例如,面对生气的用户,系统可能会生成较为礼貌和安抚性的语言。
在对话系统中,NLG用于生成系统的输出文本。当NLU理解了用户的输入并确定了适当的响应行动后,NLG将该响应转化为自然语言。例如,NLU识别用户想要预订航班后,系统通过NLG生成回应:“好的,我可以帮您预订一张飞往纽约的机票。您希望什么时候出发?”
2.3 NLU和NLG在对话系统中的协作
在对话系统中,NLU和NLG是密切相关的:
- NLU负责理解用户的意图,并将用户的自然语言输入转换为机器可处理的结构化信息。
- NLG在NLU分析的基础上,根据对话系统的逻辑或数据库的结果,生成自然、流畅的语言响应。
在我们的对话系统中,工作流程一般包含以下几个关键步骤,这里以比较开放的case来举例,实际业务中都是比较垂直的业务领域:
- 用户输入:用户输入一段自然语言,例如“明天的天气怎么样?”
- NLU处理:系统通过NLU识别出用户的意图是“查询天气”,并提取出“明天”作为时间实体。
- 逻辑处理:系统基于意图和实体,通过调用天气API获取明天的天气信息。
- NLG生成:系统通过NLG生成一个自然语言响应,例如“明天的天气预计是晴天,气温在25到30度之间。”
- 系统响应:对话系统将生成的自然语言输出返回给用户。
通过NLU和NLG的合作,对话系统能够从用户输入中提取有用的信息,并生成符合人类语言习惯的响应,从而实现智能、自然的人机交互。
2.4 Bert能做什么?
直接说结论:我们主要将Bert用于NLU模块以及问句与回复内容(主要是问题对之间的匹配)的匹配上。
-
意图识别:
- BERT可以通过预训练模型加微调的方式用于意图识别。因为BERT能够有效捕捉句子中的上下文关系。对话系统可以使用BERT来分类用户的输入,并确定其意图。例如,对于“我想预订一张飞往北京的机票”,BERT可以帮助识别出用户的意图是“预订航班”。
-
实体识别:
- BERT还可以用于命名实体识别 (NER) 任务。通过BERT的双向注意力机制,模型能够更好地识别出文本中的实体,并且能够考虑上下文来进行准确的识别。例如,在句子“帮我订一张明天飞往上海的票”中,BERT可以准确识别出“明天”是时间实体,“上海”是地点实体。
-
情感分析:
- BERT可以用于情感分析任务,帮助对话系统判断用户输入的情感倾向。这对于系统调整响应的语气或策略非常重要。例如,如果用户输入的句子表达了负面情绪,系统可以通过BERT进行情感分析后,选择更为安抚性的回应方式。
-
上下文理解:
- BERT能够在上下文中理解词汇的多义性,这对对话系统处理复杂对话场景尤为重要。它可以通过分析上下文,理解用户输入中含义不明确的词语,并帮助系统做出更准确的反应。
- 问句对匹配
- 在某些场景下,当用户问题被细分为某一个子类问题后,通常可以通过向量化方式,实现用户问题与知识库中的问题-答案实现问句对的匹配任务。我们一般采用Faiss实现基于向量的匹配召回相关知识内容。Bert包括两个版本,12层的transformer与24层的transformer,官方提供了12层的中文模型,每一层transformer的输出值,理论上来说都可以作为句向量,但是到底应该取哪一层,取决于你自身的任务和要求,普遍来说最佳结果是取倒数第二层,最后一层的值太接近于目标,前面几层的值可能语义还未充分的学习到。但层数一多,推理耗时增加,所以也不一定用最后倒数第二层。我们经过实验,可以取第六层,在实际应用中也是可以接受的。关于句向量实现,可以参考pytorch-transformer项目【3】。
2.5 Bert继续训练及使用
2.5.1 使用自身数据继续训练Bert
使用自身数据继续训练,涉及到微调,以transformers为代码示例【4、6】。
以Quora Question pairs数据为自身训练的数据。这里仅给出代码示例帮助理解,如果需要运行测试,还是建议参考原文【6】。
import pandas
from transformers import BertTokenizerFast
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import torch
from torch.utils.data import TensorDataset
import multiprocessing
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from transformers import BertForSequenceClassification
from transformers import AdamW
from transformers import get_linear_schedule_with_warmup
import time
import datetime
from sklearn.metrics import accuracy_score
import random
from matplotlib import pyplot
import numpy
from ds_utils.metrics import plot_confusion_matrix
from pathlib import Path
"""
Quora问题对数据集
Quora是一个问答网站,用户可以在此提出问题、回答问题、关注问题以及编辑内容,内容可以是事实性的,也可以是意见性的。Quora由前Facebook员工Adam D'Angelo和Charlie Cheever于2009年6月共同创立,并于2010年6月21日首次向公众开放。如今,该网站支持多种语言。
每月有超过1亿人访问Quora,因此不难想象,许多人会提出措辞相似的问题。多个具有相同意图的问题可能会导致提问者花费更多时间来找到最优答案,也会让回答者感到需要回答多个版本的同一个问题。
该数据集的目标是预测提供的问题对中哪些包含两个具有相同意义的问题。数据集的标签由人类专家提供,作为真实值。数据集本身可以从Kaggle下载。
数据字段
id - 训练集问题对的唯一标识符
qid1, qid2 - 每个问题的唯一标识符(仅在train.csv中提供)
question1, question2 - 每个问题的全文
is_duplicate - 目标变量,如果question1和question2的含义基本相同,则设为1,否则设为0。
该数据集包含超过40万对问题。
"""
"""
由于性能问题,我将只读取前5000条记录。
请注意:在完整的数据集中存在一些缺失值。因此,在训练模型之前,应该处理这些缺失值。不过在这里,我不会遇到缺失值的问题。
"""
questions_dataset = pandas.read_csv("train.csv", index_col="id", nrows=5000)
print(questions_dataset.head())
print(questions_dataset.info())
"""
为了将文本输入到BERT中,首先必须将其拆分为词元(tokens),然后将这些词元映射到它们在分词器词汇表中的索引。
分词操作必须由BERT自带的分词器执行——下面的代码单元会为我们下载这个分词器。我们将在这里使用“uncased”版本。这个分词器是基于WordPiece分词器构建的。
正在加载BERT分词器
"""
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased', do_lower_case=True)
print(f"Original: {questions_dataset['question1'][0]}")
print(f"Tokenized: {tokenizer.tokenize(questions_dataset['question1'][0])}")
print(f"Token IDs: {tokenizer.convert_tokens_to_ids(tokenizer.tokenize(questions_dataset['question1'][0]))}")
print(f"Original: {questions_dataset['question2'][0]}")
print(f"Tokenized: {tokenizer.encode(questions_dataset['question2'][0])}")
print(tokenizer.decode([101, 2054, 2003, 1996, 3357, 2011, 3357, 5009, 2000, 15697, 1999, 3745, 3006, 1029, 102]))
"""
特殊标记
[SEP] - 在每个句子的末尾,我们需要添加特殊的 [SEP] 标记。
这个标记是用于双句子任务的,其中BERT会接收两个独立的句子,并要求判断某些内容(记住,BERT最初是为预测问答任务而训练的)。
[CLS] - 对于分类任务,我们必须在每个句子的开头添加特殊的 [CLS] 标记。
这个标记具有特殊的意义。BERT由12层Transformer组成。每个Transformer接收一系列词元嵌入,并在输出时生成相同数量的嵌入。
现在让我们看看如何将两个问题编码在一起:
"""
encoded_pair = tokenizer.encode(questions_dataset['question1'][0], questions_dataset['question2'][0])
print(tokenizer.decode(encoded_pair))
"""
句子长度
我们的数据集中句子的长度显然是不同的,那么BERT是如何处理这种情况的呢?
BERT有两个限制条件:
所有句子必须填充或截断为一个固定长度。
最大句子长度为512个词元。填充使用的是特殊的 [PAD] 标记,该标记在BERT词汇表中的索引为0。
最大长度会影响训练和评估的速度。
不过,在准备编码文本之前,我们需要决定用于填充/截断的最大句子长度。
找出问题对的最大长度
"""
tqdm.pandas()
questions_dataset["question1_length"] = questions_dataset["question1"].progress_apply(lambda question:
len(tokenizer.tokenize(question)))
questions_dataset["question2_length"] = questions_dataset["question2"].progress_apply(lambda question:
len(tokenizer.tokenize(question)))
questions_dataset["joint_length"] = questions_dataset["question1_length"] + questions_dataset["question2_length"]
questions_dataset["joint_length"].max()
"""
训练与验证集的划分
我将把数据集分为3200条记录用于训练(64%),800条记录用于验证(16%),以及1000条记录用于测试(20%)。
创建训练集、验证集和测试集
"""
X_train, X_test, y_train, y_test = train_test_split(questions_dataset[["question1", "question2"]],
questions_dataset["is_duplicate"], test_size=0.2, random_state=42)
X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
print(X_train.head())
print(y_train.head())
"""
对数据集进行分词并创建数据加载器
现在我们准备进行真正的分词操作。
tokenizer.encode_plus 函数为我们组合了多个步骤:
将句子拆分为词元。
添加特殊的 [CLS] 和 [SEP] 标记。
将词元映射到它们的ID。
对所有句子进行填充或截断,使它们具有相同的长度。
创建注意力掩码,用于明确区分真实词元和 [PAD] 标记。
"""
"""
我们得到了什么:
input_ids - 词元ID,在末尾用0进行填充。
token_type_ids - 这个数组告诉BERT哪部分是第一个句子,哪部分是第二个句子。如果只对一个句子进行分类,这个数组是多余的。
attention_mask - “注意力掩码”是一个由1和0组成的数组,指示哪些词元是填充的,哪些不是。这个掩码告诉BERT中的“自注意力”机制不要将这些 [PAD] 标记纳入句子的理解中。
所有数组的大小都是 max_length。
"""
max_length = 310
tokenizer.encode_plus(X_train.iloc[0]["question1"], X_train.iloc[0]["question2"], max_length=max_length,
pad_to_max_length=True, return_attention_mask=True, return_tensors='pt', truncation=True)
def convert_to_dataset_torch(data: pandas.DataFrame, labels: pandas.Series) -> TensorDataset:
input_ids = []
attention_masks = []
token_type_ids = []
for _, row in tqdm(data.iterrows(), total=data.shape[0]):
encoded_dict = tokenizer.encode_plus(row["question1"], row["question2"], max_length=max_length,
pad_to_max_length=True,
return_attention_mask=True, return_tensors='pt', truncation=True)
# Add the encoded sentences to the list.
input_ids.append(encoded_dict['input_ids'])
token_type_ids.append(encoded_dict["token_type_ids"])
# And its attention mask (simply differentiates padding from non-padding).
attention_masks.append(encoded_dict['attention_mask'])
# Convert the lists into tensors.
input_ids = torch.cat(input_ids, dim=0)
token_type_ids = torch.cat(token_type_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels.values)
return TensorDataset(input_ids, attention_masks, token_type_ids, labels)
"""
使用 torch 的 DataLoader 类为我们的数据集创建一个迭代器。这在训练过程中有助于节省内存,
因为与 for 循环不同,使用迭代器时整个数据集不需要全部加载到内存中
"""
train = convert_to_dataset_torch(X_train, y_train)
validation = convert_to_dataset_torch(X_validation, y_validation)
# The DataLoader needs to know our batch size for training, so we specify it
# here.
batch_size = 32
core_number = multiprocessing.cpu_count()//2
# Create the DataLoaders for our training and validation sets.
# We'll take training samples in random order.
train_dataloader = DataLoader(
train, # The training samples.
sampler = RandomSampler(train), # Select batches randomly
batch_size = batch_size, # Trains with this batch size.
num_workers = core_number
)
# For validation the order doesn't matter, so we'll just read them sequentially.
validation_dataloader = DataLoader(
validation, # The validation samples.
sampler = SequentialSampler(validation), # Pull out batches sequentially.
batch_size = batch_size, # Evaluate with this batch size.
num_workers = core_number
)
"""
训练分类模型
现在我们的输入数据已经正确格式化,是时候对BERT模型进行微调了。
BertForSequenceClassification
对于这个任务,我们首先要修改预训练的BERT模型,使其能够输出分类结果,然后继续在我们的数据集上训练模型,直到整个模型(端到端)都适合我们的任务。
幸运的是,Hugging Face的PyTorch实现包含了一组为各种自然语言处理任务设计的接口。虽然这些接口都是建立在经过训练的BERT模型之上的,但每个接口都有不同的顶部层和输出类型,旨在适应其特定的NLP任务。
我们将使用 BertForSequenceClassification。这是一个标准的BERT模型,在顶部添加了一个用于分类的线性层,我们将其用作句子分类器。当我们输入数据时,整个预训练的BERT模型和额外的未训练的分类层将在我们的特定任务上进行训练。
好的,让我们加载BERT吧!有几个不同的预训练BERT模型可供选择。bert-base-uncased 意味着这个版本仅包含小写字母(“uncased”),并且是两种版本中较小的一种(“base”与“large”)。
"""
# Load BertForSequenceClassification, the pretrained BERT model with a single
# linear classification layer on top.
bert_model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased", # Use the 12-layer BERT model, with an uncased vocab.
num_labels=2, # The number of output labels--2 for binary classification.
# You can increase this for multi-class tasks.
output_attentions=False, # Whether the model returns attentions weights.
output_hidden_states=False, # Whether the model returns all hidden-states.
)
"""
优化器与学习率调度器
现在我们已经加载了模型,需要从存储的模型中获取训练超参数。
为了微调模型,作者建议从以下值中进行选择(来自BERT论文的附录A.3):
批量大小:16, 32
学习率(Adam):5e-5, 3e-5, 2e-5
训练轮数:2, 3, 4
我选择了:
批量大小:32
学习率:2e-5
训练轮数:2
这些选择都是由于硬件性能问题。
创建优化器
"""
# Note: AdamW is a class from the huggingface library (as opposed to pytorch)
adamw_optimizer = AdamW(bert_model.parameters(),
lr = 2e-5, # args.learning_rate - default is 5e-5, our notebook had 2e-5
eps = 1e-8 # args.adam_epsilon - default is 1e-8.The epsilon parameter eps = 1e-8 is “a very small number to prevent any division by zero in the implementation”.
)
# Number of training epochs. The BERT authors recommend between 2 and 4.
epochs = 2
# Total number of training steps is [number of batches] x [number of epochs].
# (Note that this is not the same as the number of training samples).
total_steps = len(train_dataloader) * epochs
# Create the learning rate scheduler.
scheduler = get_linear_schedule_with_warmup(adamw_optimizer,
num_warmup_steps = 0,
num_training_steps = total_steps)
def format_time(elapsed):
'''
Takes a time in seconds and returns a string hh:mm:ss
'''
# Round to the nearest second.
elapsed_rounded = int(round((elapsed)))
# Format as hh:mm:ss
return str(datetime.timedelta(seconds=elapsed_rounded))
def fit_batch(dataloader, model, optimizer, epoch):
total_train_loss = 0
for batch in tqdm(dataloader, desc=f"Training epoch:{epoch}", unit="batch"):
# Unpack batch from dataloader.
input_ids, attention_masks, token_type_ids, labels = batch
# clear any previously calculated gradients before performing a backward pass.
model.zero_grad()
# Perform a forward pass (evaluate the model on this training batch).
loss, _ = model(input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_masks,
labels=labels)
total_train_loss += loss.item()
# Perform a backward pass to calculate the gradients.
loss.backward()
# Clip the norm of the gradients to 1.0.
# This is to help prevent the "exploding gradients" problem.
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# Update parameters and take a step using the computed gradient.
optimizer.step()
# Update the learning rate.
scheduler.step()
return total_train_loss
def eval_batch(dataloader, model, metric=accuracy_score):
total_eval_accuracy = 0
total_eval_loss = 0
predictions, predicted_labels = [], []
for batch in tqdm(dataloader, desc="Evaluating", unit="batch"):
# Unpack batch from dataloader.
input_ids, attention_masks, token_type_ids, labels = batch
# Tell pytorch not to bother with constructing the compute graph during
# the forward pass, since this is only needed for backprop (training).
with torch.no_grad():
# Forward pass, calculate logit predictions.
loss, logits = model(input_ids,
token_type_ids=token_type_ids,
attention_mask=attention_masks,
labels=labels)
total_eval_loss += loss.item()
# Calculate the accuracy for this batch of validation sentences, and
# accumulate it over all batches.
y_pred = numpy.argmax(logits.detach().numpy(), axis=1).flatten()
total_eval_accuracy += metric(labels, y_pred)
predictions.extend(logits.detach().numpy().tolist())
predicted_labels.extend(y_pred.tolist())
return total_eval_accuracy, total_eval_loss, predictions, predicted_labels
# Set the seed value all over the place to make this reproducible.
seed_val = 42
random.seed(seed_val)
numpy.random.seed(seed_val)
torch.manual_seed(seed_val)
def train(train_dataloader, validation_dataloader, model, optimizer, epochs):
# We'll store a number of quantities such as training and validation loss,
# validation accuracy, and timings.
training_stats = []
# Measure the total training time for the whole run.
total_t0 = time.time()
for epoch in range(0, epochs):
# Measure how long the training epoch takes.
t0 = time.time()
# Reset the total loss for this epoch.
total_train_loss = 0
# Put the model into training mode.
model.train()
total_train_loss = fit_batch(train_dataloader, model, optimizer, epoch)
# Calculate the average loss over all of the batches.
avg_train_loss = total_train_loss / len(train_dataloader)
# Measure how long this epoch took.
training_time = format_time(time.time() - t0)
t0 = time.time()
# Put the model in evaluation mode--the dropout layers behave differently
# during evaluation.
model.eval()
total_eval_accuracy, total_eval_loss, _, _ = eval_batch(validation_dataloader, model)
# Report the final accuracy for this validation run.
avg_val_accuracy = total_eval_accuracy / len(validation_dataloader)
print(f"Accuracy: {avg_val_accuracy}")
# Calculate the average loss over all of the batches.
avg_val_loss = total_eval_loss / len(validation_dataloader)
# Measure how long the validation run took.
validation_time = format_time(time.time() - t0)
print(f" Validation Loss: {avg_val_loss}")
# Record all statistics from this epoch.
training_stats.append(
{
'epoch': epoch,
'Training Loss': avg_train_loss,
'Valid. Loss': avg_val_loss,
'Valid. Accur.': avg_val_accuracy,
'Training Time': training_time,
'Validation Time': validation_time
}
)
print("")
print("Training complete!")
print(f"Total training took {format_time(time.time() - total_t0)}")
return training_stats
training_stats = train(train_dataloader, validation_dataloader, bert_model, adamw_optimizer, epochs)
df_stats = pandas.DataFrame(training_stats).set_index('epoch')
print(df_stats)
pyplot.plot(df_stats['Training Loss'], 'b-o', label="Training")
pyplot.plot(df_stats['Valid. Loss'], 'g-o', label="Validation")
pyplot.title("Training & Validation Loss")
pyplot.xlabel("Epoch")
pyplot.ylabel("Loss")
pyplot.legend()
pyplot.xticks(df_stats.index.values.tolist())
pyplot.show()
test = convert_to_dataset_torch(X_test, y_test)
test_dataloader = DataLoader(test, sampler=SequentialSampler(test), batch_size=batch_size)
bert_model.eval()
_, _,_ ,predicted_labels = eval_batch(test_dataloader, bert_model)
plot_confusion_matrix(y_test, predicted_labels, [1, 0])
pyplot.show()
output_dir = Path("__file__").parents[0].absolute().joinpath("model_save")
output_dir.mkdir(exist_ok=True)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = bert_model.module if hasattr(bert_model, 'module') else bert_model # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(str(output_dir.absolute()))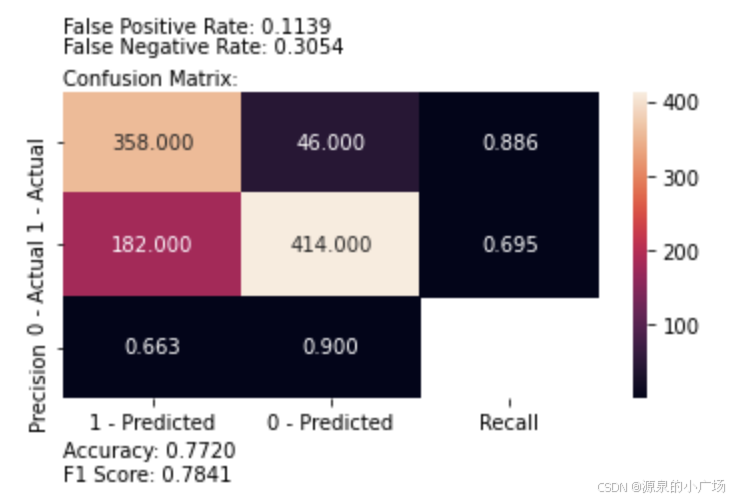
2.5.2 用于句子向量化
句子向量化,是可以直接使用预训练模型,不需要微调。根据实际场景可以配置你所需的模型版本,以pytorch_transformers为代码示例。
import torch
import logging
from pytorch_transformers import BertModel, BertTokenizer
from typing import List
CLS_TOKEN = "[CLS]"
SEP_TOKEN = "[SEP]"
logger = logging.getLogger(__name__)
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self, input_ids, input_mask, segment_ids):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
def convert_examples_to_features(examples, tokenizer, max_seq_length,
cls_token_at_end=False, pad_on_left=False,
cls_token='[CLS]', sep_token='[SEP]', pad_token=0,
sequence_a_segment_id=0, sequence_b_segment_id=1,
cls_token_segment_id=1, pad_token_segment_id=0,
mask_padding_with_zero=True):
""" Loads a data file into a list of `InputBatch`s
`cls_token_at_end` define the location of the CLS token:
- False (Default, BERT/XLM pattern): [CLS] + A + [SEP] + B + [SEP]
- True (XLNet/GPT pattern): A + [SEP] + B + [SEP] + [CLS]
`cls_token_segment_id` define the segment id associated to the CLS token (0 for BERT, 2 for XLNet)
"""
features = []
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
logger.info("Writing example %d of %d" % (ex_index, len(examples)))
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
# Modifies `tokens_a` and `tokens_b` in place so that the total
# length is less than the specified length.
# Account for [CLS], [SEP], [SEP] with "- 3"
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[:(max_seq_length - 2)]
# The convention in BERT is:
# (a) For sequence pairs:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) For single sequences:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# Where "type_ids" are used to indicate whether this is the first
# sequence or the second sequence. The embedding vectors for `type=0` and
# `type=1` were learned during pre-training and are added to the wordpiece
# embedding vector (and position vector). This is not *strictly* necessary
# since the [SEP] token unambiguously separates the sequences, but it makes
# it easier for the model to learn the concept of sequences.
#
# For classification tasks, the first vector (corresponding to [CLS]) is
# used as as the "sentence vector". Note that this only makes sense because
# the entire model is fine-tuned.
tokens = tokens_a + [sep_token]
segment_ids = [sequence_a_segment_id] * len(tokens)
if tokens_b:
tokens += tokens_b + [sep_token]
segment_ids += [sequence_b_segment_id] * (len(tokens_b) + 1)
if cls_token_at_end:
tokens = tokens + [cls_token]
segment_ids = segment_ids + [cls_token_segment_id]
else:
tokens = [cls_token] + tokens
segment_ids = [cls_token_segment_id] + segment_ids
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = max_seq_length - len(input_ids)
if pad_on_left:
input_ids = ([pad_token] * padding_length) + input_ids
input_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + input_mask
segment_ids = ([pad_token_segment_id] * padding_length) + segment_ids
else:
input_ids = input_ids + ([pad_token] * padding_length)
input_mask = input_mask + ([0 if mask_padding_with_zero else 1] * padding_length)
segment_ids = segment_ids + ([pad_token_segment_id] * padding_length)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
if ex_index < 5:
logger.info("*** Example ***")
logger.info("guid: %s" % (example.guid))
logger.info("tokens: %s" % " ".join(
[str(x) for x in tokens]))
logger.info("input_ids: %s" % " ".join([str(x) for x in input_ids]))
logger.info("input_mask: %s" % " ".join([str(x) for x in input_mask]))
logger.info("segment_ids: %s" % " ".join([str(x) for x in segment_ids]))
features.append(
InputFeatures(input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids))
return features
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
"""Truncates a sequence pair in place to the maximum length."""
# This is a simple heuristic which will always truncate the longer sequence
# one token at a time. This makes more sense than truncating an equal percent
# of tokens from each, since if one sequence is very short then each token
# that's truncated likely contains more information than a longer sequence.
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
def select_field(features, field):
"""As the output is dic, return relevant field"""
return [[choice[field] for choice in feature.choices_features] for feature in features]
def create_examples(_list, set_type="train"):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(_list):
guid = "%s-%s" % (set_type, i)
text_a = line
# text_b = line[1]
examples.append(
InputExample(guid=guid, text_a=text_a))
return examples
class BertEmbedder:
def __init__(self,
pretrained_weights='bert-base-uncased',
tokenizer_class=BertTokenizer,
model_class=BertModel,
max_seq_len=20):
super().__init__()
self.pretrained_weights = pretrained_weights
self.tokenizer_class = tokenizer_class
self.model_class = model_class
self.tokenizer = self.tokenizer_class.from_pretrained(pretrained_weights)
self.model = self.model_class.from_pretrained(pretrained_weights)
self.max_seq_len = max_seq_len
# tokenizer = BertTokenizer.from_pretrained(pretrained_weights)
# model = BertModel.from_pretrained(pretrained_weights)
def get_bert_embeddings(self,
raw_text: List[str]) -> torch.tensor:
examples = create_examples(raw_text)
features = convert_examples_to_features(
examples, self.tokenizer, self.max_seq_len, True)
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_input_mask = torch.tensor([f.input_mask for f in features], dtype=torch.long)
all_segment_ids = torch.tensor([f.segment_ids for f in features], dtype=torch.long)
last_hidden_states = self.model(all_input_ids)[0] # Models outputs are now tuples
print(last_hidden_states.size())
return last_hidden_states
if __name__=="__main__":
embedder = BertEmbedder()
raw_text = ["[CLS] This is first element [SEP] continuing statement",
"[CLS] 最快的出行方式是飞机."]
bert_embedding = embedder.get_bert_embeddings(raw_text)
print("bert_embedding:", bert_embedding)
3. Bert消声的分析
参考材料【5】,在过去几年中,模型架构主要有三种大体范式:仅编码器模型(例如BERT)、编码器-解码器模型(例如T5)和仅解码器模型(例如GPT系列)。编码器-解码器模型实际上仍然是自回归模型。编码器-解码器模型中的解码器在本质上仍然是因果解码器。一种变体是前缀语言模型或前缀LM架构,它基本上做了与编码器-解码器相同的事情,除了没有交叉注意力(以及一些其他小细节,如共享编码器/解码器的权重以及没有编码器瓶颈)。前缀LM有时也被称为非因果解码器。
与此同时,仅编码器模型(如原始的BERT)以不同的方式进行去噪,并在某种程度上依赖于分类“任务”头,在预训练后做一些有用的事情。去噪目标后来被T5模型以“适应方式”采用,使用序列到序列格式。T5中的去噪实际上并不是一个全新的目标函数,而是一种输入数据的转换。
预训练的主要目标是构建一个有用的内部表示,以最有效和高效的方式与下游任务对齐。内部表示越好,后续使用这些表示进行有用任务的难度就越低。简单的下一个词预测“因果语言建模”目标被认为非常擅长此任务,并且已经成为LLM革命的基础。现在的问题是去噪目标是否同样有效。从公开信息来看,我们知道T5-11B表现得相当不错,即使在对齐或SFT之后(Flan-T5 XXL的MMLU得分超过55,对于这种规模和当时来说已经相当不错)。因此,我们可以得出结论,去噪目标的转移过程(预训练 -> 对齐)在这种规模上表现得相对不错。
BERT类模型的逐步淘汰,主要原因是统一和任务/建模范式的转变。BERT类模型比较笨重,但BERT模型真正被弃用的原因是人们希望一次完成所有任务,这导致了使用自回归模型进行更好去噪的方法。在2018-2021年期间,任务特定微调逐渐转变为大规模多任务模型。用BERT实现这一目标非常困难。这与“去噪”无关。人们只是找到了重新表达去噪预训练任务的方法(即T5),这使得BERT类模型在这一点上被弃用,因为有了更好的替代方案。具体来说,编码器-解码器和仅解码器模型能够同时表示多个任务,而不需要特定任务的分类头。对于编码器-解码器模型,如果去掉编码器,仅使用解码器也能与BERT编码器一样具有竞争力。
在大模型时代,GPT类型模型(即解码器-only模型)被认为更适合的原因个人认为主要有以下几点:
-
自回归生成:GPT类型模型使用自回归(autoregressive)生成方式,即基于前面的文本生成后续的文本。这种生成方式在大规模语言模型中表现出色,尤其是在需要生成长文本、对话、翻译、代码生成等任务时效果很好。
-
单一架构的通用性:GPT类型模型能够通过单一的解码器架构处理多种任务,无需像BERT那样针对每个任务设计不同的微调模型。这种通用性使得GPT在大规模预训练后可以更方便地应用于广泛的下游任务。
-
顺序处理的效率:在大模型的训练过程中,GPT模型由于其顺序生成的特性,能够更有效地利用硬件资源。这在训练大规模模型时非常重要,因为它有助于提高计算效率和缩短训练时间。
-
任务统一化:随着大模型的规模和能力的增加,研究者更倾向于使用统一的模型架构来处理多种任务,而不是为每个任务定制不同的模型。GPT类型的模型由于其自回归的生成方式,可以更自然地适应这一趋势,减少了任务特定的调整需求。
-
少样本学习和零样本学习:GPT类型的大模型在少样本学习(few-shot learning)和零样本学习(zero-shot learning)方面表现优异。这意味着它们可以在不经过专门微调的情况下,通过简单地提示(prompt)生成合理的输出,这使得它们在各种应用场景中非常灵活。
4. 参考材料
【1】Devlin, Jacob. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
【2】Sentence-BERT: 如何通过对比学习得到更好的句子向量表示
【3】PyTorch-Transformers | PyTorch
【4】Question-Answering with Bert
【5】What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives