爬取小说(用xpath方法+一点点正则)
一,准备工作
现在,我们长话短说,首先,我们随便找一个小说
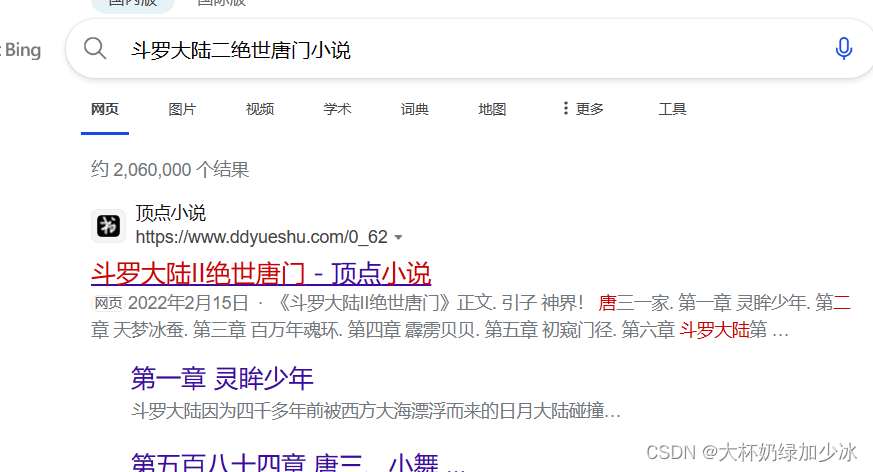
章节显示如下:

在这里我们还是首先导入我们需要的库:
import requests
from lxml import etree
import re
然后对网页进行一个分析,由于刚好这个网页,不需要我们去构建翻页,章节的链接及名称可以直接观察到,非常好查找到。
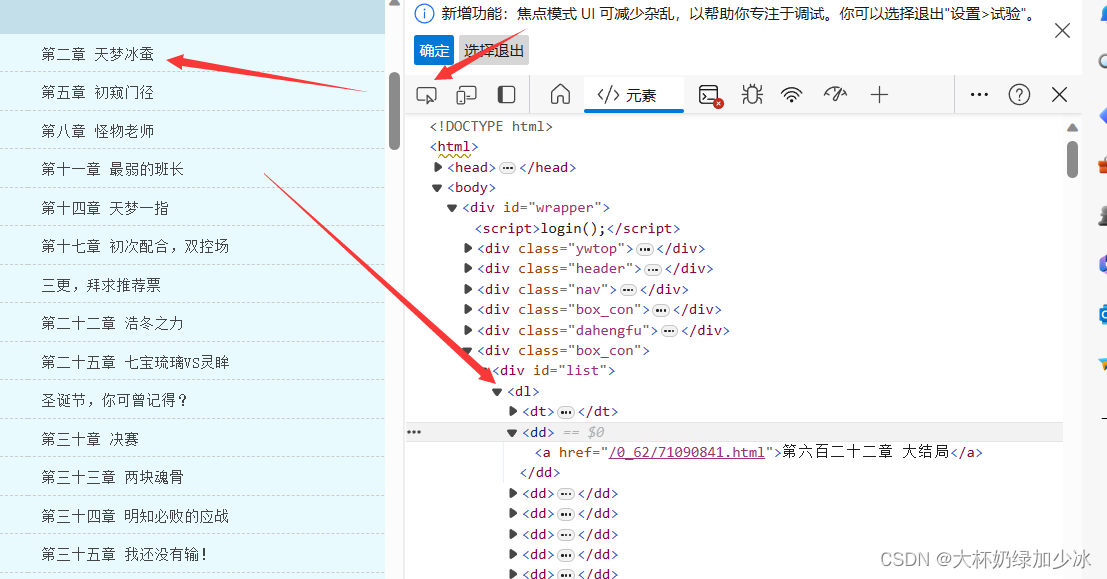
二,代码展示
由于写的非常简单,就不多做解释了,大概大家都能看懂
import requests
from lxml import etree
import re
class novel_data_get(object):
def __init__(self):
self.url = 'https://www.ddyueshu.com/0_62/'
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0'
}
def data_get_index(self):
resp = requests.get(url=self.url, headers=self.headers)
resp.encoding = "gbk"
if resp.status_code == 200:
return resp.text
else:
return None
def parse_data_index(self, response):
html = etree.HTML(response)
data_list = html.xpath('//*[@id="list"]/dl//dd')
for data in data_list:
name = data.xpath('./a/text()')[0]
url = "https://www.ddyueshu.com/" + data.xpath('./a')[0].get('href')
self.parse_content_data(name, url)
def parse_content_data(self, name, url):
new_url = requests.get(url, headers=self.headers)
new_url.encoding = 'gbk'
url_content = new_url.text
content = re.findall(r'<div id="content">(.*?)</div>', url_content)[0]
self.save_novel_data(name, content)
def save_novel_data(self, name, content):
file_name = name
with open('./photo/' + file_name + '.txt', 'w', encoding='utf-8') as f:
f.write(content)
print(f"{file_name}--已经保存完毕!")
def run(self):
response = self.data_get_index()
self.parse_data_index(response)
# print(response)
if __name__ == '__main__':
Novel = novel_data_get()
Novel.run()
三,结果展示
这里我们爬取太多,简单爬取一点点就暂停了
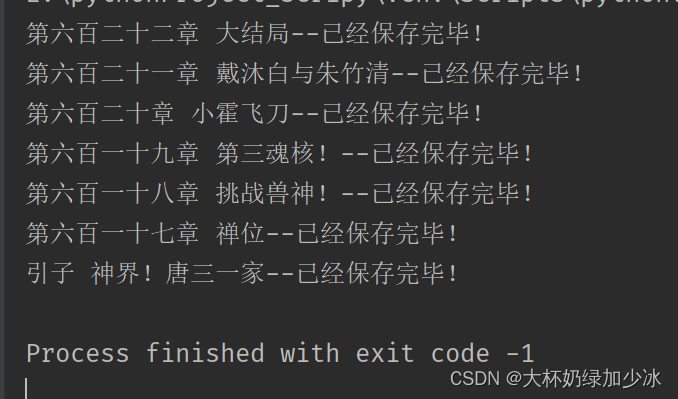
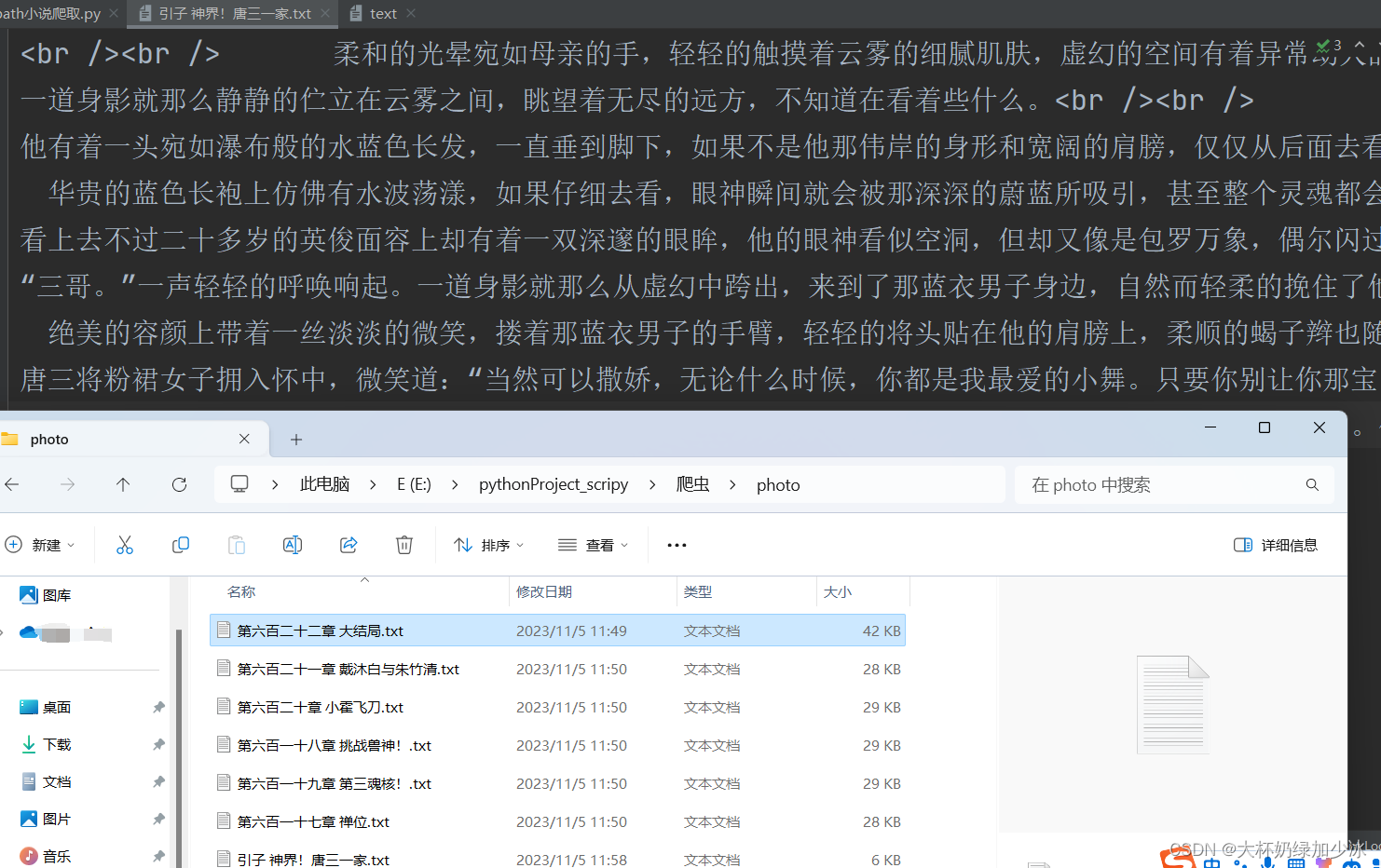
最后发现可以正常获取到小说的所有内容。