目录
你能学到
- 左值 与 右值
- 左值引用 与 右值引用 基本用法与作用
- 拷贝构造函数 与 移动构造函数
- 移动语义 与 std::move
- 万能引用 与 引用折叠
- 完美转发:std::forward
前言
本文代码片段中变量命名规则如下:
- 小写字母:一般类型的变量(非指针、非引用)
- p:pointer,指针类型的变量(p1、p2…)
- r:reference,引用类型的变量
- lr_*:比如 lr_a,a 的左值引用
- rr*:右值引用(rr1、rr2…)
- 上述均是非 const 变量,如果名称以 c 开头,说明该变量为 const
- fun:function,函数名(fun1、fun2…)
- 大写字母:自定义类名
在说左值引用与右值引用之前,有必要先说说什么是左值,什么是右值:
c++ 中的左值与右值没有标准的定义,没必要死套公式、死扣细节,只需要理解即可。
如果你想要了解更多,可以通过关键字 c++ value categories 搜索相关资料。
1. 左值与右值
- 左值:lvalue
- 右值:rvalue
就它俩的英文缩写以及中文翻译,使得有一部分人将其解释为:
lvalue: left value
rvalue: right value
因此也诞生了对左值与右值的一种解释:
左值:能出现表达式左边
右值:不能出现在表达式左边
这种解释从某方面来说也可以是对的。下面我从另外一方面来解释什么是左值什么是右值:
1.1 左值
lvalue 是
loactor value的缩写
左值指的是 存储在内存中,有明确内存地址的数据。因此在语法层面:
左值包含两部分信息:
- 内存地址:记录对象在内存中的位置
- 数据值:记录对象的值
所以它可以
- 出现在表达式的左边
- 出现在表达式的右边
- 取地址(&)
int a = 0; // a 为左值,值为 1
int b = a; // 正确:a 能出现在右边
a = 1; // 正确:a 能出现在左边
&a; // 正确:a 能取地址
【总结】 左值 可以取地址的、有名字的、非临时的,它是用户创建的,能通过作用域的规则知道它的生存周期。
1.2 右值
lvaue 是
read value的缩写
右值指的是 可以提供数据值的数据。在语法层面:
右值仅包含数据值,因此它
- 只能出现在表达式左边
- 不可以取地址
int a = 0, b = 1;
100; // 100 是一个右值
100 = a; // 错误:右值不能出现在左边
&100; // 错误:右值不能取地址
【总结】 右值 不能取地址、没有名字、临时的,它的创建与销毁实际由编译器在幕后控制,对用户而言有用的信息仅仅是它的数据值。
【扩展】
在 c++ 中,右值实际分为两种:
-
纯右值 (prvalue):
- 返回类型不是引用的一般函数的返回值
int fun() { int a = 1; return a; } fun() = 1; // 错误:fic() 返回值为纯右值- 运算表达式的结果
int a = 0, b = 1; a + b = 1; // 错误:运算表达式 a + b 返回的是纯右值- 原始字面量
- lambda 表达式
- 取地址操作
- … …
-
将亡值 (xvalue,就字面意思:即将死亡的临时对象):
- 返回类型为右值引用的函数的返回值
- std::move 的返回值
- … …
总的来说,最直接地区分左值与右值的方法为:是否可以取地址。
2. 左值引用与右值引用
此部分讲解的主要内容在于:用左值或者右值给左值引用与右值引用进行赋值,不会讲解如果加了 const 修饰需要注意什么问题。如果你对后者感兴趣,看见作者的另外一篇文章:C++ const 关键字详解
无论是左值引用还是右值引用,在语法层面都是 给对象起别名,与被绑定的对象共用同一块内存。在这里先记住一个结论:
左值引用视为左值右值引用
- 有名称的 视为左值
- 否则 视为右值
2.1 左值引用
顾名思义,是对左值的引用,给左值起别名。
语法:
类型 & 名称 = 左值
遵循以下规则:
- 非 const 的左值引用 只能用 左值 来赋值。
- const 的左值引用 可以用 右值 来赋值。
看到这里你可能会疑惑:左值引用不是只针对左值吗,为什么还能用右值来赋值?别急,往后看。
// 以下变量都是左值
int a = 0;
int* p = &a;
int& r = a;
// 以下都是给左值起别名
int& r_a = a;
int*& r_p = p; // 对 int* 的引用,类型解析从右到左
/**
* 直观上 r_r 是 r 的别名,
* 但由于 r 是 a 的别名,
* 因此 r_r 也可以看作 a 的别名
*/
int& r_r = r;
// 特殊
int& r1 = 100; // 错误:非 const 左值引用不能用右值初始化
const int& cr = 100; // 正确:const 左值引用能用右值初始化
对于
const int& cr = 100;
这可能就会让人感到疑惑:
为什么左值引用 (const) 能引用右值?
先来看一个例子:
int fun(int& a) { }
如果我们尝试如下调用这个函数
fun(0);
会报错
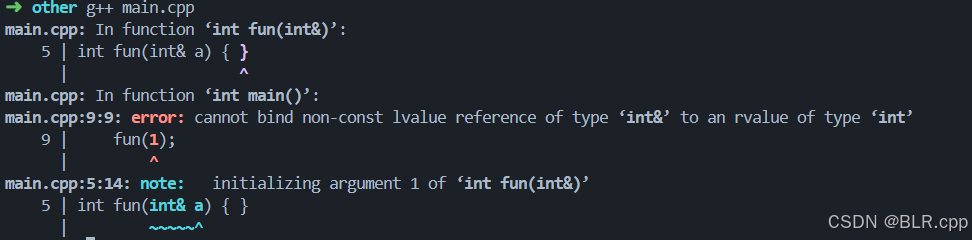
这是因为 1 是一个右值,而 非 const 的左值引用 不能用右值初始化。在 c++11 以前不存在 右值引用的概念,因此为了解决这一问题,引入了规则:
const 的左值引用 既可以用 左值 赋值,也可以用 右值 赋值。
所以当参数类型为左值引用时,更建议使用 const 左值引用,也是出于这个考虑。
比如在老版本的 vector 模板的 push_back() 方法:
void push_back(const value_type& __x);
vector<int> t;
int a = 1;
// 以下均正确
t.push_back(a);
t.push_back(1);
2.2 右值引用
顾名思义,对右值的引用,给右值起别名。
语法:
类型 && 名称 = 右值
遵循以下规则:
- 右值引用 只能用 右值 初始化
int a = 1, b = 1;
int* p = &a;
int& lr = a;
int&& rr = 100;
int&& fun() { return 0 }
// 以下均是右值
100;
a + b;
&a;
// 以下均正确
int&& rr1 = 100;
int&& rr2 = a + b;
int* && rr3 = &a; // 对 int* 指针的右值引用
int&& rr4 = fun(); // fun() 的返回值为 int&&,无名称,视为右值
// 以下均错误
int&& rr5 = a; // a 是左值
int&& rr6 = p; // p 是指针,为左值
int&& rr7 = lr; // lr 为左值引用,视为左值
int&& rr8 = rr; // rr 有名称右值引用,视为左值
从
// 以下均错误
int&& rr6 = lr; // lr 为左值引用,为左值
int&& rr7 = rr; // rr 是右值引用,为左值
也验证了之前所说的
左值引用视为左值右值引用
- 有名称的 视为左值
- 否则 视为右值
既然 有名称的右值引用 是左值,它是用右值初始化的。也就是说
右值引用使得右值 “重获新生”,让此右值的生命周期 与 对应的右值引用的生命周期一样:只要该右值引用还活着,该右值也将一直存活下去。
基本语法搞定之后,那么你会好奇这么一个问题:
既然左值引用已经解决了用右值给左值引用初始化的问题,那为什么还要引入 右值引用 呢?
这是 为了性能考虑。
3. 移动语义 与 std::move
move,可译为移动,但译为 转移 更为合适
3.1 移动语义
移动语义:转移对象的资源控制权
这么直接说定义比较难以理解,下面举个例子:
这例子源于某网站博主的文章(文章结尾有指出本文的所有参考文章)
问题一:如何将大象放入冰箱?
答案是众所周知的。首先你需要有一台特殊的冰箱,这台冰箱是为了装下大象而制造的。你打开冰箱门,将大象放入冰箱,然后关上冰箱门。
问题二:如何将大象从一台冰箱转移到另一台冰箱?
-
普通解答:打开冰箱门,取出大象,关上冰箱门,打开另一台冰箱门,放进大象,关上冰箱门。
-
2B解答:在第二个冰箱中启动量子复制系统,克隆一只完全相同的大象,然后启动高能激光将第一个冰箱内的大象气化消失。
这里的 问题二 就比较好的说明了什么是移动语义。分析一下这个例子:
假设现在我们已经有了一个实体:大象A,需要通过 A 创建另外一个大象B,那么我们两套方案:
- 普通解答:将 A “移动” 到 B,即将 A 的资源 转移给 B
- 2B解答:拷贝一份 A 的资源给 B,然后再将 A 的资源回收(即析构大象A)
即便你没有对底层有多了解,听了这个例子你也能得出:普通解答显然效率更高。
这两个解答就很好地对应了 c++ 的 2B解答——拷贝构造函数 与 普通解答——移动构造函数。
本文只讲解 拷贝/移动 构造函数,不讲解 拷贝/移动 赋值函数
不考虑其他的,移动构造函数 的效率比 拷贝构造函数 要高。
因为 拷贝构造函数 会拷贝一份 对象A 的资源,需要向操作系统申请资源(系统资源是十分昂贵的),再将资源赋给 对象B,这就降低了性能;而 移动构造函数 则是直接将 对象A 的资源转移给 对象B,不存在申请资源操作。
既然 移动构造函数 的效率更高,那么为什么还保留 拷贝构造函数?
需要注意,当调用了移动构造函数后,A 资源被转移了,那么 A 此时相当于是个 “废物” 了,如果你在之后仍然使用 A 对象,那么会导致未定义行为。
换句话说,移动构造函数 相当于进行了 废物利用:当明确 对象A 在后续一定不会被使用时,那么它的资源可以转给其他需要此类型资源的对象,不需要重新申请资源,也不用释放资源。
废物也不是完全无用,因为它可以
回收利用😐
但是如果 对象A 你在后续仍然会使用,并且需要创建 对象B,那么就应该调用 拷贝构造函数。
从形式上看:
- 拷贝构造函数:参数为 const 的左值引用
- 移动构造函数:参数为 右值引用
上面说了一堆理论,下面用代码来实现:
A 类如下
class A
{
public:
A(int v)
:_val{ new int(v) }
{ }
// * 拷贝构造函数
A(const A& a) // 使用 const,保证了原对象不会改变
:_val{ new int(*(a._val)) } // new: 向操作系统申请了资源
{ cout << "调用了拷贝构造函数" << endl; }
// * 移动构造函数
A(A&& a) // 采用引用的方式,因为需要转移资源
:_val{ a._val } // 转移资源
{
/**
* 由于 a 的资源被转移了,
* 因此将 a 的资源 _val 指针指向 nullptr,
* 避免之后误用 a
*/
a._val = nullptr;
cout << "调用了移动移动函数" << endl;
}
~A()
{
delete _val;
}
private:
int* _val;
};
现在我们来使用 A 类
int main()
{
A a(10);
A b(a);
A c(std::move(a)); // move: 将 a 转为右值引用
return 0;
}
执行输入为:

A 类的构造函数由多个(重载函数),但是编译器会利用指定的规则取匹配最合适的函数。
比如上述代码中:
- A b(a);
a 的类型为 A,此时最合适的函数是 A(const A& a); - A c(std::move(a));
std::move(a) 的返回值为 A&&,即便 A(const A& a); 也能匹配,但是最合适的是 A(A&& a);
看完上面代码,相信让你比较疑惑的一点是 std::move:
3.2 std::move
源码如下:
template<typename _Tp>
constexpr typename std::remove_reference<_Tp>::type&&
move(_Tp&& __t) noexcept
{
return static_cast<typename std::remove_reference<_Tp>::type&&>(__t);
}
可能有的地方你看不懂,但是不要紧,重点在 static_cast 关键字,它用于强制类型转换。
如果你对它的源码剖析感兴趣,可以见文章: C++11的右值引用、移动语义(std::move)和完美转发(std::forward)详解
也就是说,std::move 的作用 仅仅 是 将一个传入的参数类型强制转换为右值引用,(而其返回值为右值引用,没有名称,因此被视为右值) ,我们可以用此函数来 辅助 实现移动语义。
比如上面代码中的 A c(std::move(c));
当我们确定 a 对象不在使用时,同时需要创建 c 对象,那么可以 废物利用,将 c 转为右值,因此调用了 移动构造函数 将 a 的资源转移给 c。
【易错】
-
std::move 仅仅是做强制类型转换,
没有实现资源转移的功能。如果将 A 类的移动构造函数删除,那么执行 A c(std::move(a));,此时调用的是 拷贝构造函数。
-
移动构造函数的 资源转移 功能依赖于它自己的内部实现,并不是说你调用了 移动构造函数 就实现了 资源转移 。
如果将 A 类的移动构造函数改为:
A(A&& a) { }此时执行 A c(a);,即便调用的是拷贝构造函数,但是你并没有在内部实现如何转移资源。
-
资源转移 并不包含 析构对象
在执行完 A c(std::move(a)); 后,除非调用析构函数,否则 a 对象仍然存在,只不过它的资源 (_val) 被转移给 c 对象了(由移动构造函数实现)。
4. 完美转发:std::forward
4.1 引入
在 模板 以及 自动推导类型 中,并不是说你指定了 && 它的类型就是 右值引用:
- 模板:T&&
- auto:auto&&
它们既可能是左值引用,也可能是右值引用,这种引用也被称为 万能引用,T 的实际类型需要编译器进行推导。
【注意】
-
const auto &&或者const T &&就是右值引用,不需要推导 -
只有 T 或者 auto 后紧跟 && 才可能是 万能引用。
template <typename T> fun(std::vector<T>>&& arg);arg 不是万能引用,这是一个 vector<T> 类型的右值引用。
-
在上述提到的情况下,只有当 类型需要推导时才是万能引用
对于下面的模板:
template <typename T> fun(T&& arg);-
对于函数调用 fun<int>(100); 来说 arg 不是 万能引用
因为此时已经明确指出 <int>,即明确告诉编译器 T 就是 int,所以不存在类型推导,所以 arg 不是万能引用
-
对于函数调用 fun(100); 来说,arg 是 万能引用。
因为没有指出 T 的类型,所以需要编译器自行推导,因此 arg 是万能引用。
-
-
当 arg 是 万能引用 时,那么 T 的类型是不确定的,需要编译器进行推导;
-
当 T 的类型被推导出来时,此时它的后面还有 &&,需要进行 引用折叠,最终得到参数 arg 的实际类型。
万能引用推导规则 (以 T&& 为例,T 换为 auto 也是一样的):
如果传入的参数是左值,那么 T 被推导为 左值引用如果传入的参数是右值,那么 T 被推导为 非引用类型
引用折叠规则:
T& &、T&& &、T& &&被折叠为T&T&& &&被折叠为T&&
下面看几个例子:
- 模板中的 const T&&
template <typename T>
void fun(const T&& t) { } // t 就是 const 右值引用,不需要推导
fun(100); // 正确
int&& rr = 100;
fun(rr); // 错误:rr 视为左值,不能给 右值引用初始化
- 模板中的 T&&
template <typename T>
void fun2(T&& t> { }
int a = 0;
int& lr = a;
int&& rr = 0;
// - 以下明确指出了 T 的类型,t 不是万能引用
// 但是存在 *引用折叠*
fun<int> (10); // t: int&&
fun<int&> (lr); // t: int& && -> int&
fun<int&&>(10); // t: int&& && -> int&&
// - 以下需要推导类型,t 是万能引用
fun(0); // 0 为右值,所以 T = int -> t: int&&
fun(a); // a 为左值,所以 T = int& -> t: int& && -> int&
fun(rr); // rr 为左值,所以 T = int& -> t: int& && -> int&
// std::move返回值为右值,所以 T = int -> t: int&&
fun(std::move(rr));
- auto 自动推导类型
int a = 1;
int& lr = a;
int&& rr = 100;
int&& fun() { return 0; }
const auto&& rr1 = rr; // 正确:rr1为右值引用
const auto&& rr2 = lr; // 错误:rr2 是右值引用,不能用左值初始化
// 以下变量类型均为右值引用
auto&& rr3 = 100; // 100 为右值,所以 auto = int -> rr3: int&&
auto&& rr4 = fun(); // 同上
// 以下变量类型均为左值引用
auto&& lr1 = lr; // lr 为左值,所以 auyo = int& -> lr1: int& && -> int&
auto&& lr2 = rr; // 同上
4.2 std::forward
std::forward 主要功能是:实现参数转递时,既能保留右值属性,也能保留左值属性。
这句话可能也很抽象,下面来分析一个例子:
#include <iostream>
using namespace std;
void print(int&) { cout << "int&" << endl; }
void print(int&&) { cout << "int&&" << endl; }
template <typename T>
void fun(T&& t)
{
print(t);
}
int main()
{
int a = 0;
int& lr = a;
int&& rr = 0;
fun(a);
fun(0);
fun(lr);
fun(rr);
return 0;
}
程序如上,在模板函数 fun 中调用了 print 函数,并且 传递了参数 t。
下面分析程序的执行结果:
-
fun(a)
a 为左值,所以 T&& 被推导为 int&,那么 print 应输出 int& -
fun(0)
0 为右值,所以 T&& 被推导为 int&&,此时你以为 print 应输出 int&&,然而结果并不是。前面我们提到过有名称的右值引用 被视为 左值,因此虽然 fun 函数的参数 t 为 int&&,但是它被视为 左值,所以 print 仍然输出 int&
说到这里就不在分析之后两个函数调用结果了,留给读者自行分析。
最后程序运行结果为:
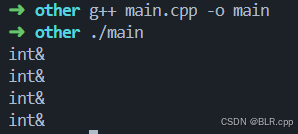
分析完之后,我们发现了关键的问题所在:有名称的右值引用 被视为 左值。
如果我们想保留参数 t 的右值属性,也就是说如果传递给 fun 函数的参数 t 是右值,那么 fun内部调用其他函数时,所传递的参数 t 也要保留右值属性,即调用 print(int&&) 函数。
那么怎么实现呢?
有一个方案是 std::move,假设我们将 fun 函数修改为
template <typename T>
void fun(T&& t)
{
print(std::move(t));
}
显然可以保留 t 的右值属性,但是这出现了一个问题:如果 t 是左值引用,那么 t 也被转为了右值。这不是我们想要的,我们更期望 它既能保留右值参数的右值属性,也能左值参数的保留左值属性,这就是 std::forward 函数的功能:
template<typename _Tp>
constexpr _Tp&&
forward(typename std::remove_reference<_Tp>::type& __t) noexcept
{
return static_cast<_Tp&&>(__t);
}
template<typename _Tp>
constexpr _Tp&&
forward(typename std::remove_reference<_Tp>::type&& __t) noexcept
{
static_assert(!std::is_lvalue_reference<_Tp>::value,
"std::forward must not be used to convert an rvalue to an lvalue");
return static_cast<_Tp&&>(__t);
}
看源码可能比较费劲,下面我直接说结论:
如果你对其源码剖析感兴趣,见 C++11的右值引用、移动语义(std::move)和完美转发(std::forward)详解
-
第一个函数:
参数为左值引用(即 _Tp 为左值引用类型),返回类型通过 引用折叠 为 左值引用。
-
第二个函数:
参数为右值引用(即 _Tp 为右值引用类型),返回类型通过 引用折叠 为 右值引用。
因此,正确的做法是将 fun 函数改写为
template <typename T>
void fun(T&& t)
{
print(std::forward<T>(t));
}
下面来分析结果应该是什么。
源程序的函数调用顺序如下:
fun(a);
fun(0);
fun(lr);
fun(rr);
-
fun(a)
a 是左值,所以 T 为 int&,参数 t 为 int&,此时调用 第一个 forward 函数,返回 左值引用,所以 print 输出 int&
-
fun(0)
0 为右值,所以 T 为 int,参数 t 为 int&&,此时调用第二个 forward 函数,返回 右值引用,所以 print 输出 int&&
其余留给读者去验证,尤其是最后一个
最终程序的执行结果为:
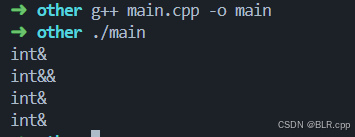
最后针对最终结果来总结以下:
- fun(a)、fun(lr)、fun(rr) 的参数都是
左值,由于 fun 函数内部 std::forward 函数实现了完美转发:传递给 fun 函数的参数为左值,那么 std::forward 保留了它的左值属性,使得 fun 内部传递给 print 的参数仍然均有 左值属性 - fun(0) 的参数为 右值,由于 fun 函数内部的 std::forward 函数实现了完美转发:传递给 fun 函数的参数为右值,那么 std::forward 保留了它的右值属性,使得 fun 内部传递给 print 的参数仍然具有 右值属性。
本文参考
- <<C++ Primer 第五版>>
- C++11的右值引用、移动语义(std::move)和完美转发(std::forward)详解
- 详解 C++ 左值、右值、左值引用以及右值引用
- c++ 左值引用与右值引用
- 右值引用(大象装冰箱的例子)
- C++ 新特性 | C++ 11 | std::forward、万能引用与完美转发
本文如有错误,欢迎指正。