前言
之前在针对实习面试的博文中讲到Redis在实际开发中的生产问题,其中缓存穿透、击穿、雪崩在面试中问的最频繁,本文加了图解,希望帮助你更直观的了解缓存穿透😀
(放出之前写的针对实习面试的关于Redis生产问题的博文链接)
Redis生产问题(缓存穿透、击穿、雪崩)——针对实习面试
什么是缓存穿透?
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查询数据库
下面是一个正常的数据查询流程:

而上图是一般缓存穿透发生的场景:

当某些请求时不合理的(缓存中不存在,数据库中也不存在)且请求数量巨大时,导致大量请求直接作用在数据库上,一般来说数据库无法承接短时巨量查询,会直接导致宕机(此手段黑客常用)
如上图,数据库承接巨量压力,如不解决缓存穿透问题,极易导致宕机崩溃,数据丢失

怎么解决缓存穿透?
缓存穿透是指查询一个不存在的数据,缓存和数据库都没有命中,导致每次请求都直接访问数据库,从而可能压垮数据库。以下是几种解决缓存穿透问题的有效方法:
一、缓存空值法
- 原理
- 当从数据库查询不到数据时,将空值(如
null)缓存起来。下次再查询相同的数据时,缓存直接返回空值,避免了再次访问数据库。不过需要设置一个较短的缓存过期时间,因为数据可能后续会被添加到数据库中。
- 当从数据库查询不到数据时,将空值(如
- 示例
-
假设使用Redis作为缓存,查询用户信息的场景。当查询一个不存在的用户ID(如
user - 123)时,数据库返回为空。此时,在Redis中设置一个键值对,键为user - 123,值为null,并设置过期时间为60秒(可根据实际情况调整)。后续再查询user - 123时,Redis直接返回null,而不会穿透到数据库。 -
代码示例(使用Python的
redis - py库):
import redis r = redis.Redis(host='localhost', port=6379, db=0) user_id = "user - 123" result = r.get(user_id) if result is None: # 从数据库查询 from_database = query_database(user_id) if from_database is None: # 数据库也为空,缓存空值 r.set(user_id, None, ex = 60) else: # 缓存数据库查询到的值 r.set(user_id, from_database) else: # 直接使用缓存的值 print(result) -
二、布隆过滤器法
- 原理
- 布隆过滤器是一种基于概率的数据结构,它可以快速判断一个元素是否可能存在于集合中。它通过多个哈希函数将元素映射到一个位数组中的多个位置。如果这些位置都为
1,则元素可能存在;如果有一个位置为0,则元素一定不存在。(以下是布隆过滤器的简单原理示意图)
- 布隆过滤器是一种基于概率的数据结构,它可以快速判断一个元素是否可能存在于集合中。它通过多个哈希函数将元素映射到一个位数组中的多个位置。如果这些位置都为
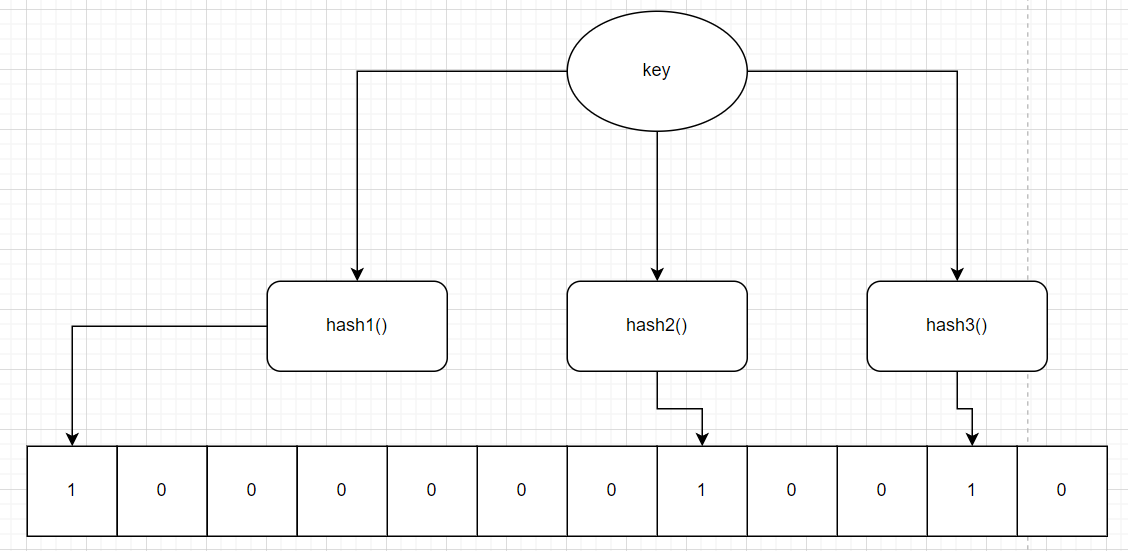
- 在缓存场景中,将数据库中所有可能存在的键(如用户ID)经过布隆过滤器处理。当有查询请求时,先通过布隆过滤器判断键是否可能存在。如果布隆过滤器判断一定不存在,就直接返回数据不存在,不再访问缓存和数据库。
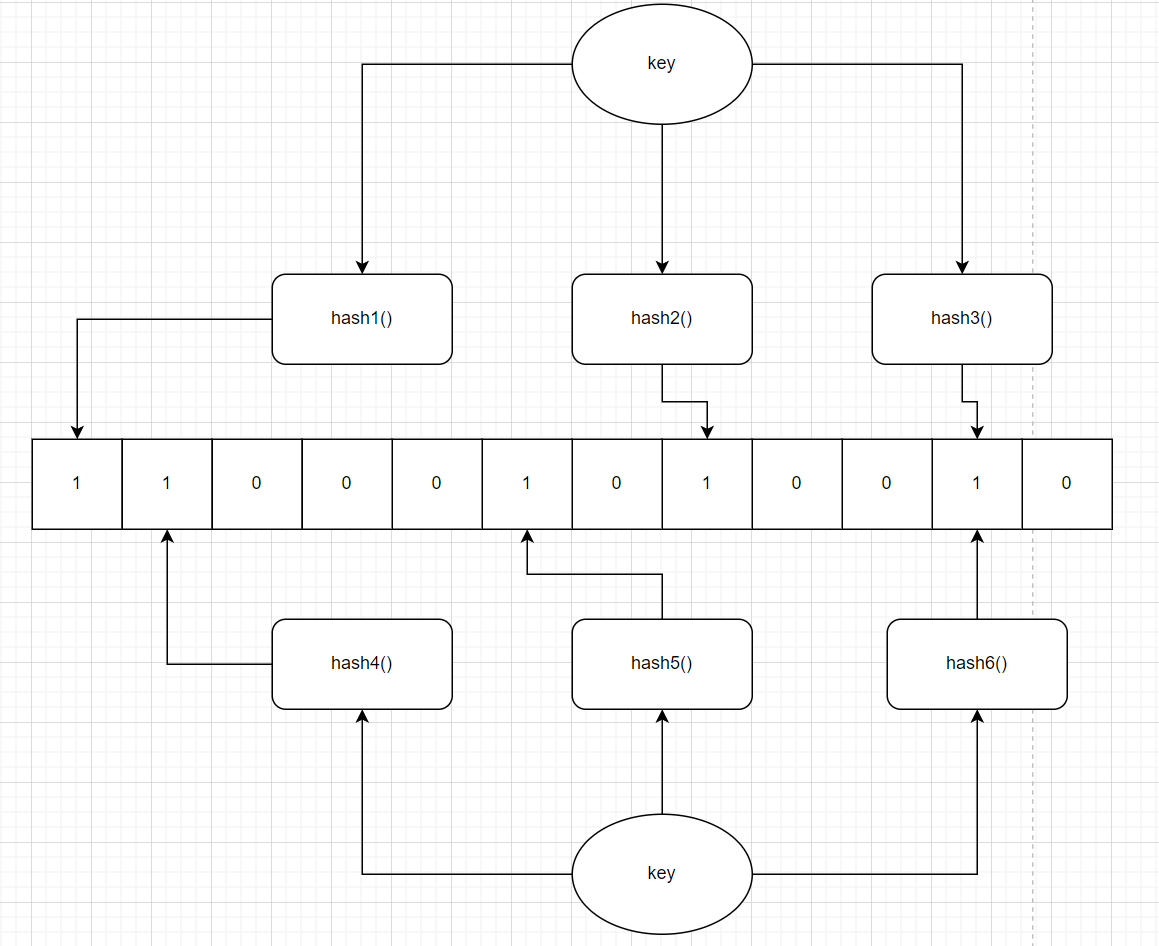
- 但布隆过滤器也存在一定的缺点,它的实现较为复杂,且存在误判(当数据越多越容易产生误判,因为布隆过滤器是通过哈希函数判断的,当数据量大时,一定会产生哈希冲突,下图中hash3()和hash6()发生了冲突)
- 示例
- 以Java为例,使用Google Guava库中的布隆过滤器。首先,在系统初始化时,将数据库中现有的所有用户ID添加到布隆过滤器中。
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; import java.nio.charset.Charset; import java.util.ArrayList; import java.util.List; public class BloomFilterExample { private static final int expectedInsertions = 1000; private static final double fpp = 0.01; private static BloomFilter<String> bloomFilter; static { // 初始化布隆过滤器,假设存储用户ID为字符串类型 bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF - 8")), expectedInsertions, fpp); List<String> existingUserIds = queryAllUserIdsFromDatabase(); for (String userId : existingUserIds) { bloomFilter.put(userId); } } public static boolean mightContain(String userId) { return bloomFilter.mightContain(userId); } }- 当有查询请求时,先调用
mightContain方法判断用户ID是否可能存在。如果返回false,则直接返回数据不存在。