第一部分:解决的问题
- 联邦学习(Federated Learning, FL) 是一种分布式学习方法,允许多个客户端在不共享原始数据的情况下协作训练模型。
- 为保护数据隐私,差分隐私(Differential Privacy, DP)被集成到联邦学习中,形成差分隐私联邦学习(DPFL)。
- 然而,现有DPFL方法(例如DP-FedAvg)由于对模型更新的裁剪和噪声添加操作,在异构数据环境下(如非独立同分布数据,Non-IID)导致模型性能显著下降。
第二部分:解决问题使用到的方法
论文提出的 DP2-FedSAM 方法,通过以下改进在保障隐私的同时显著提升了模型性能:
(1)部分模型个性化(Partial Model Personalization):
将模型划分为共享的表示提取器和个性化的分类器头,只共享表示提取器。这减少了数据异构性带来的偏差并缓解了裁剪误差。
(2)敏锐感知最小化(Sharpness-Aware Minimization, SAM):
使用SAM优化器生成局部平坦的模型,从而降低模型更新的范数,进一步减少裁剪误差,并增强对噪声的鲁棒性。
第三部分:效果优势
数据集:FEMNIST 和 CIFAR-10。
对比方法:DP-FedAvg、DP-FedSAM、CENTAUR等。
结果:
在非IID数据分布下,DP2-FedSAM显著提升了测试精度。例如,在CIFAR-10上,DP2-FedSAM比DP-FedAvg平均提高了12%-30%的精度。
在不同隐私预算(𝜖=1.0和 𝜖=2.0)下,DP2-FedSAM都表现出最佳的隐私-实用性权衡。
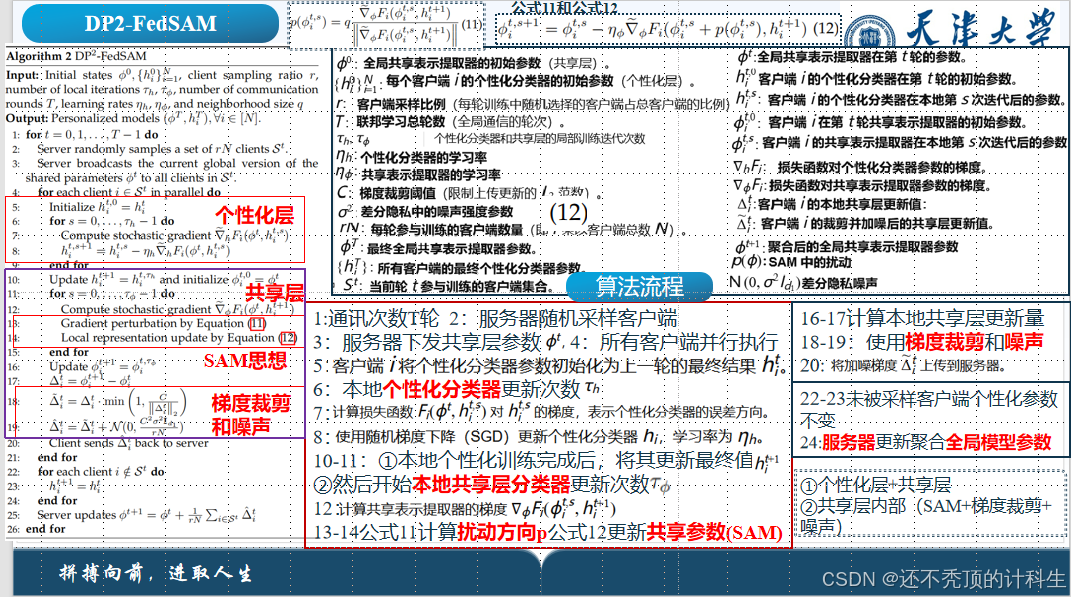
第四部分:算法讲解
(1)联邦学习的目标

(公式1)

(2)sam算法

(3)差分隐私
基于高斯机制和子抽样放大效应,证明DP2-FedSAM满足严格的差分隐私保证((𝜖,𝛿)-DP)。
查看下面论文第六部分讲解:【数据隐私关注的联邦学习算法优化研究(张一衡学长研究生毕设论文)(差分隐私)(联邦学习) - CSDN App】https://blog.csdn.net/weixin_74009895/article/details/143810936?sharetype=blog&shareId=143810936&sharerefer=APP&sharesource=weixin_74009895&sharefrom=link
(4)攻击模型与隐私目标
①攻击模型定义(Honest-but-Curious)
“诚实但好奇”模型: 服务端被假设为遵守联邦学习协议,也就是说它不会主动篡改或破坏训练过程。
好奇的部分: 服务端对客户端的本地数据集感兴趣,并试图通过共享的消息推断客户端的数据内容。
②可能的第三方攻击
除了服务端可能会好奇客户端数据外,系统还需防范第三方攻击,例如:
外部监听者: 未授权访问者可能拦截通信信息。
服务端数据广播时的分析: 第三方可能分析每轮联邦学习中的全局模型更新,从中推断出客户端的敏感信息。
③隐私目标
确保服务端和可能的第三方攻击者无法通过分析全局模型更新来推断出客户端的本地数据具体信息。
④具体例子
场景:
假设有一个联邦学习系统,目标是训练一个模型来识别手写数字。每个客户端(比如你的手机)都有自己私有的手写数字图片数据,服务器不能直接访问这些数据。
诚实但好奇的服务器:
诚实:
服务器按照规则执行联邦学习,比如:
收集客户端上传的模型更新。
结合所有客户端的更新,生成一个全局模型。
再把这个全局模型发回给客户端。
好奇:
虽然服务器遵守规则,但它试图从客户端上传的模型更新中推测你的数据。
比如,如果你的更新特别强调“数字7”,服务器可能猜测你本地的数据有很多“7”的图片。
隐私目标:
确保服务器:
不能从模型更新中推断你的具体数据,比如服务器(或者第三方攻击者)无法知道你有多少张“7”的图片,甚至不知道你是否有“7”这个数字的数据。
(5)dp-fedavg在联邦学习中实现客户端级差分隐私


 (6)裁剪的影响(能减少隐私泄露和过大梯度的影响,但会引起误差,降低准确性)
(6)裁剪的影响(能减少隐私泄露和过大梯度的影响,但会引起误差,降低准确性)
①裁剪的基本定义


②裁剪引起的误差
裁剪会引入一定的误差:
裁剪后的更新与原始更新的差值可以表示为:
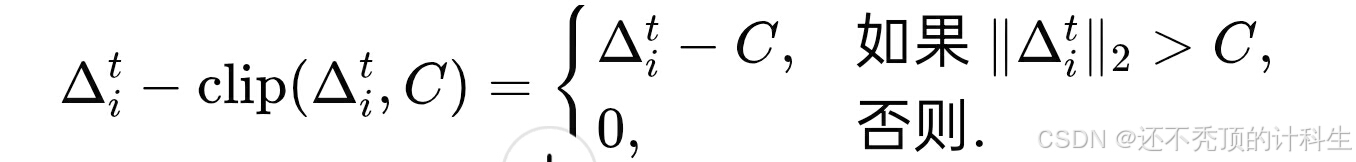
(公式8)

影响与问题:
裁剪操作的好处: 裁剪限制了更新的大小,可以有效减少异常更新(例如,某些客户端的数据分布不同导致的极端更新)对全局模型的影响。
问题:
在非独立同分布(Non-IID)数据场景下,各客户端的数据分布差异较大。
这可能导致某些客户端的更新范数较大,从而触发裁剪操作,导致误差积累。
长期来看,这种裁剪误差会对全局模型的训练效果产生负面影响。
③解决方法
1:使用部分模型共享
将模型分为“共享部分”和“个性化部分”,只共享对所有客户端一致的部分,减少因数据分布不同引起的裁剪误差。


2:敏锐感知最小化(SAM)
通过优化平坦的损失区域(减少尖锐的梯度变化),进一步减小本地更新的范数,从根本上降低触发裁剪的概率,从而减少裁剪误差。

代表的含义就是这个sam用的位置是“共享层”位置。
 ④补充:(范数的计算例子)
④补充:(范数的计算例子)


(7)噪声的影响

①仅使用共享模型无法解决噪声的影响
部分模型共享虽然可以减少裁剪误差,但它无法解决由于噪声添加(如隐私保护中的高斯噪声)引入的误差问题。
因此,仅使用部分模型共享还不够,需要结合其他方法(如SAM)来提升模型的整体性能和鲁棒性。

例子:联邦学习中的手写数字识别
假设你在用联邦学习训练一个手写数字识别模型,每个客户端的数据集如下:
客户端 A:包含数字 0~4 的图片。
客户端 B:包含数字 5~9 的图片。
共享层的作用:
共享层需要提取所有客户端的通用特征(如笔画的粗细、数字的形状等),但由于各客户端的数据分布不同,提取通用特征已经是一个挑战。
加入噪声后会发生什么?
为了保护隐私,差分隐私机制在客户端上传的模型更新中加入随机噪声:
客户端 A 的更新中加入噪声,例如:
[0.1,−0.2,0.05]。
客户端 B 的更新中加入噪声,例如:
[−0.3,0.2,0.1]。
结果:
共享层在合并客户端 A 和 B 的更新时,会同时受到数据分布差异和噪声的影响。
由于噪声是随机的,可能导致共享层提取的特征偏离真实的数据分布。例如,数字 0~4 的特征可能被噪声干扰得无法准确识别,最终影响全局模型的性能。
②仅使用sam不足以缓解添加噪声的影响
SAM 无法完全解决噪声影响的原因:
SAM 只优化本地模型的平坦性,但本地平坦性未必能累积到全局模型的平坦性。
数据的异质性导致不同客户端的平坦区域存在差异,这种差异会在模型聚合时引入偏差。
加入噪声后,这些差异放大会削弱模型的鲁棒性。
示例说明: 假设两个客户端 A 和 B 的数据分布差异较大:
客户端 A 的本地平坦区域可能适用于数字 0~4。
客户端 B 的本地平坦区域可能适用于数字 5~9。
当这两个客户端的模型更新聚合时,由于各自的平坦区域不同,无法形成一个全局平坦模型。
如果此时再加入噪声,模型对噪声的敏感性可能进一步增加。

举例: 假设在客户端 A 的数据分布下,某个参数 𝜙的平坦区域是 [1.0,1.2],但在客户端 B 的数据分布下,这个参数区域可能是尖锐的。因此:
A 的本地模型虽然对自己的数据分布来说是平坦的,但在 B 的数据分布中可能是“尖锐区域”。
当两个客户端的模型聚合时,最终的参数可能位于一个对任何客户端都不平坦的区域。

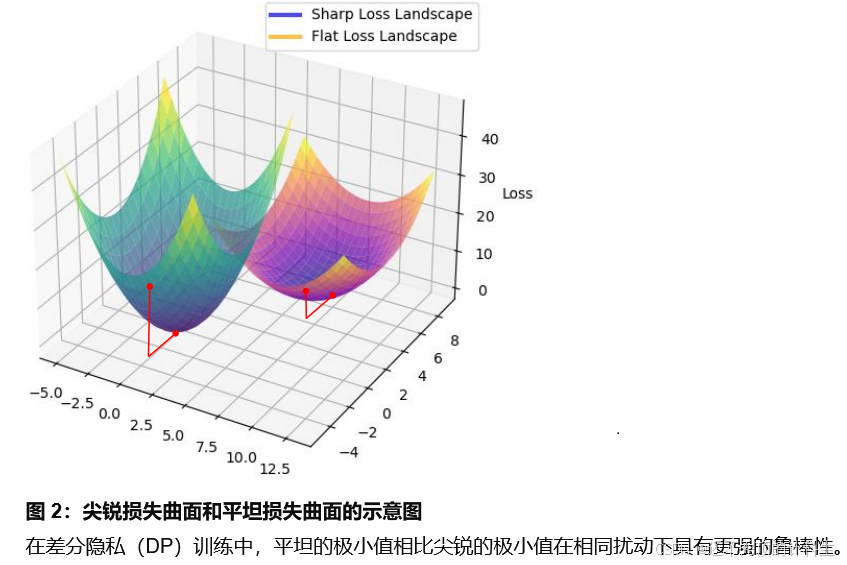
③共享模型+sam
刚刚说sam无法得到“全局平坦极小值”,但是当我们加入“共享表示提取器”,就可以实现“全局平坦最小值了”。

因为“全局共享提取器”共享部分的模型参数相似度比较高,在相似“样本标签”下的平坦区域的客户端A迁移到客户端B中的时候也是平坦的。
(8)DP2FedSam算法流程图
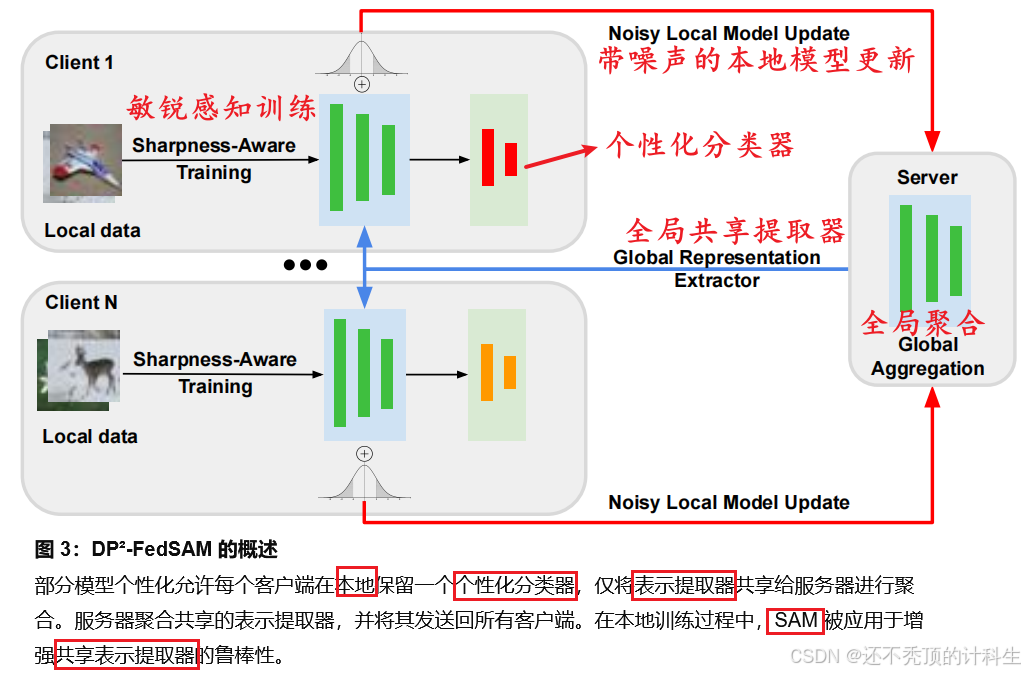
第五部分:总结
(1)存在的问题
①问题1:差分隐私(裁剪+添加噪声)导致模型性能下降
②问题2:客户端漂移(数据的统计异质性)导致的模型性能下降
(2)解决办法
使用:“共享模型”(实现个性化和全局聚合)+“sam”(增强鲁棒性)
①针对裁剪
共享模型:减少因数据分布不同引起的裁剪误差,进而减少裁剪模型参数的L2范数,(作用在共享层)
sam:平坦区域的模型更新范数更小,从而减少裁剪误差
②针对噪声
共享模型:提供共享表示提取器,提取各个客户端共享的参数部分
sam:在“共享层”的基础上,“客户端的平坦最小值”在聚合之后,也能够实现“全局的平坦最小值”,进而能够缓解早入噪声后的影响
③针对客户端漂移与本地模型个性化
共享模型:
实现本地客户端与全局模型的对齐(共享表示提取器(𝜙)用于捕获通用特征),同时能够实现本地模型的个性化(个性化分类器头(ℎ𝑖)),以适应各自的数据分布。