列表list
1、一个排列整齐的队伍,Python采用顺序表实现
2、列表内的个体称作元素,由若干元素组成列表
3、元素可以是任意对象(数字、字符串、对象、列表等)
4、列表内元素有顺序,可以使用索引
5、线性的数据结构
6、使用 [ ] 表示
7、列表是可变的
列表是非常重要的数据结构,对其内存结构和操作方法必须烂熟于心。
初始化
1、list() -> new empty list
2、list(iterable) -> new list initialized from iterable's items
3、[]
4、列表不能一开始就定义大小
ls1 = []
ls2 = list()
ls3 = [2, 'ab', [3, 'abc'], (5, 30, 50)] # 列表是一个容器,元素可以是其它类型
ls4 = list(range(5)) # 非常常用的构造方式,将一个可迭代对象转换为一个列表
索引
1、索引,也叫下标
2、正索引:从左至右,从0开始,为列表中每一个元素编号
如果列表有元素,索引范围[0, 长度-1] [0,len()-1]
3、负索引:从右至左,从-1开始
如果列表有元素,索引范围[-长度, -1] [-len().-1]
正、负索引不可以超界,否则引发异常IndexError
为了理解方便,可以认为列表是从左至右排列的,左边是头部,右边是尾部,左边是下界,右边是上界
列表通过索引访问,list[index] ,index就是索引,使用中括号访问
使用索引定位访问元素的时间复杂度为0(1),这是最快的方式,是列表最好的使用方式。
x = [1,'abc',None,True,1.2,[1]]
输入:x
输出:[1, 'abc', None, True, 1.2, [1]]
输入:x,len(x)
输出:([1, 'abc', None, True, 1.2, [1]], 6)
输入:x[-1],x[0],x[5],x[-len(x)]
输出:([1], 1, [1], 1)
二维数组
输入:x[5][-1]
输出:1
查询
ndex(value,[start,[stop]])
通过值value,从指定区间查找列表内的元素是否匹配
匹配第一个就立即返回索引
匹配不到,抛出异常ValueError
count(value)
返回列表中匹配value的次数
时间复杂度
index和count方法都是0(n)
随着列表数据规模的增大,而效率下降
耗时长,能不用就不用
如何返回列表元素的个数?如何遍历?如何设计高效?
len()
x = [1,2,3,1,2,3]
输入:x.index(3) #3是元素
输出:2 #2是索引
输入:x.count(4),x.count(3)
输出:(0, 2)
修改
索引定位元素,然后修改。注意索引不能超界
x = [1,2,3,1,2,3]
输入:x[0]=100
x
输出:[100,2,3,1,2,3]
增加单个元素
append(object) -> None
列表尾部追加元素,返回None
返回None就意味着没有新的列表产生,就地修改
定位时间复杂度是O(1)
insert(index, object) -> None
在指定的索引index处插入元素object
返回None就意味着没有新的列表产生,就地修改
定位时间复杂度是O(1)
索引能超上下界吗?
超越上界,尾部追加
超越下界,头部追加
x = [100,2,3,1,2,3]
输入:x.append(4) #方法method,无返回值,就地修改
x
输出:[100, 2, 3, 1, 2, 3, 4]
输入:x.insert(0,0) #就地修改
x
输出:[0, 100, 2, 3, 1, 2, 3, 4]
输入:x.insert(-1,200)
x
输出:[0, 100, 2, 3, 1, 2, 3, 200, 4]
输入:x.insert(2000,300)
x
输出:[0, 100, 2, 3, 1, 2, 3, 200, 4, 300]
输入:x.insert(-2000,400)
x
输出:[400, 0, 100, 2, 3, 1, 2, 3, 200, 4, 300]增加多个元素
extend(iteratable) -> None
将可迭代对象的元素追加进来,返回None
就地修改,本列表自身扩展
+-> list
连接操作,将两个列表连接起来,产生新的列表,原列表不变
本质上调用的是魔术方法__add__()方法
-> list
重复操作,将本列表元素重复n次,返回新的列表
x = [400, 0, 100, 2, 3, 1, 2, 3, 200, 4, 300]
输入:x.extend(range(5))
x
输出:[400, 0, 100, 2, 3, 1, 2, 3, 200, 4, 300, 0, 1, 2, 3, 4]
输入:x = list(range(5))
y = [1,2,3]
x + y # + 运算符重载 + 拼接生成全新列表
输出:[0, 1, 2, 3, 4, 1, 2, 3]
输入: x,y
输出:([0, 1, 2, 3, 4], [1, 2, 3])
输入:x * 3 #生成全新列表,用x的元素
输出:[0, 1, 2, 3, 4, 0, 1, 2, 3, 4, 0, 1, 2, 3, 4]
输入:x = [1] * 3
print(1,x) #[1,1,1]
x[1] = 200
print(2,x) #[1,200,1]
输出:1 [1, 1, 1]
2 [1, 200, 1]
输入:z = [[1]] * 3
print(z) #[[1],[1],[1]]
z[1] = 300 #[[1], 300, [1]]
print(z)
输出:[[1], [1], [1]]
[[1], 300, [1]]
在Python中,当你使用[[1]] * 3这样的表达式来创建一个列表时,实际上是创建了一个包含三个引用的列表,这三个引用指向的是同一个列表对象[1]。这意味着,如果你修改了这个列表对象的任何一个引用,所有其他引用也会反映出这个修改,因为它们实际上指向的是同一个对象。
在你的代码中,a = [[1]] * 3创建了一个列表a,其中包含三个指向同一个列表[1]的引用。然后,你修改了a[1][0]的值为500。由于这三个列表引用指向的是同一个列表对象,所以当你修改这个列表对象的第一个元素时,所有三个引用都会显示这个修改。
因此,当你打印a时,你会看到[[500], [500], [500]],因为你修改了原始列表[1]的第一个元素,而这个列表被a中的所有三个引用共享。
输入:a = [[1]] * 3 #[[1],[1],[1]]
a[1][0] = 500
print(a)
输出:[[500], [500], [500]] 删除
remove(value) -> None
从左至右查找第一个匹配value的值,找到就移除该元素,并返回None,否则ValueError
就地修改
效率?
pop([index]) -> item
不指定索引index,就从列表尾部弹出一个元素
指定索引index,就从索引处弹出一个元素,索引超界抛出IndexError错误
效率?指定索引的的时间复杂度?不指定索引呢?
pop()默认pop(-1) 建议从最后弹
clear() -> None
清除列表所有元素,剩下一个空列表
x = [1,200,1]
输入:x.remove(1)
x
输出:[200, 1]
输入:t = x.pop(-1)
t,x
输出:(1, [200])
输入:x.clear()
x
输出:[]反转
reverse() -> None
将列表元素反转,返回None
就地修改
这个方法最好不用,可以倒着读取,都不要反转。
x = [0,1,2,3,4]
输入:x.reverse()
x
输出:[4,3,2,1,0]
输入:for i in range(1,len(x)+1):
print(i,x[-i])
输出:1 0
2 1
3 2
4 3
5 4
输入:for i in reversed(x):
print(i)
输出:0
1
2
3
4
排序
sort(key=None, reverse=False) -> None
对列表元素进行排序,就地修改,默认升序
reverse为True,反转,降序
key一个函数,指定key如何排序,lst.sort(key=function)
如果排序是必须的,那么排序。排序效率高吗?
x = [4,3,2,1,0]
输入:x.sort() #升序 会改变原有的列表
x
输出:[4,3,2,1,0]
输入:x.insert(2,5)
x
输出:[4, 3, 5, 2, 1, 0]
输入:sorted(x) #升序 不会改变原有的列表
输出:[0, 1, 2, 3, 4, 5]
输入:x
输出:[4, 3, 5, 2, 1, 0]
输入:sorted(x,reverse=True)
输出:[5, 4, 3, 2, 1, 0]
in成员操作
输入:1 in [1,2,3]
输出:True
输入:'abc' in [1,2,'abc']
输出:True
输入:3 in [3,[1,2]]
输出:True
输入:2 in [3,[1,2]]
输出:False
输入:[2,1] in [3,[1,2]]
输出:False
输入:[1,2] in [3,[1,2]]
输出:True列表复制
a = list(range(4))
b = list(range(4))
print(1,a==b,a,b)
a[2] = 200
print(2,a==b,a,b)
1 True [0, 1, 2, 3] [0, 1, 2, 3]
2 False [0, 1, 200, 3] [0, 1, 2, 3]
输入:a =list(range(4))
b = a.copy()
print(1,a==b,a,b)
a[2] = 200
print(2,a==b,a,b)
输出:1 True [0, 1, 2, 3] [0, 1, 2, 3]
2 False [0, 1, 200, 3] [0, 1, 2, 3]

输入:a = [0,1,[2,3,4],5]
b = a.copy()
print(1,a==b,a,b)
c = a
c[2] = 200
print(2,a==c,a,c)
输出:1 True [0, 1, [2, 3, 4], 5] [0, 1, [2, 3, 4], 5]
2 True [0, 1, 200, 5] [0, 1, 200, 5]
列表的内存模型和深浅拷贝
shadow copy
影子拷贝,也叫浅拷贝。遇到引用类型数据,仅仅复制一个引用而已
deep copy
深拷贝,往往会递归复制一定深度
浅拷贝
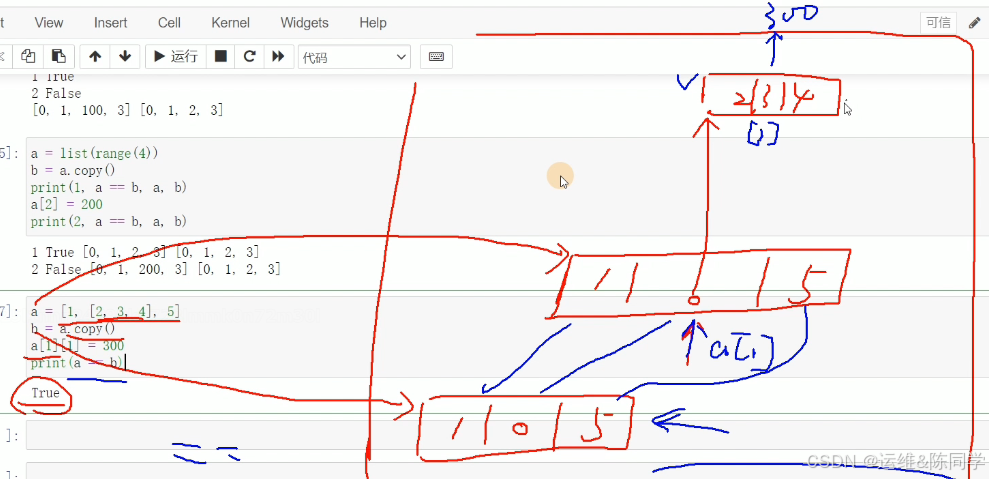
输入:a = [0,1,[2,3,4],5]
b = a.copy()
a[1][1] = 300
print(a==b,a,b)
输出:True [0, 1, [2, 300, 4], 5] [0, 1, [2, 300, 4], 5]
深拷贝
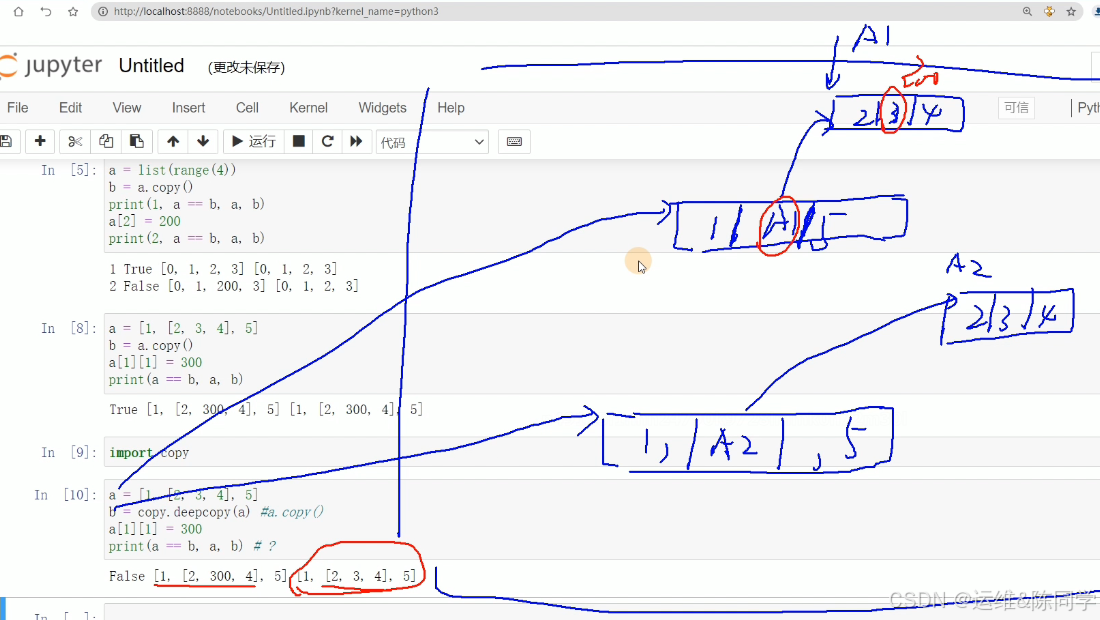
import copy
输入:a = [1,[2,3,4],5]
b = copy.deepcopy(a)
a[1][1] = 300
print(a == b,a,b)
输出:False [1, [2, 300, 4], 5] [1, [2, 3, 4], 5]随机数
random模块
1、randint(a, b) 返回[a, b]之间的整数
2、randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数缺省值为1。 random.randrange(1,7,2)
3、choice(seq) 从非空序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 random.choice([1,3,5,7])
4、3.6开始提供choices,一次从样本中随机选择几个,可重复选择,可以指定权重
5、random.shuffle(list) ->None 就地打乱列表元素
6、sample(population, k) 从样本空间或总体(序列或者集合类型)中随机取出k个不同的元素,返回一个新的列表
random.sample(['a', 'b', 'c', 'd'], 2)
random.sample(['a', 'a'], 2) 会返回什么结果
每次从样本空间采样,在这一次中不可以重复抽取同一个元素
import random
#0到4取取随机数,循环10次
for i in range(10):
print(random.randint(0,4))
3
1
4
2
0
2
4
4
0
0
#0到10取偶数,循环10次
for i in range(10):
print(random.randrange(0,10,2))
6
6
8
8
2
0
0
8
6
4
#x取值,循环5次
x = [1,0,4,3,2]
for i in range(5):
print(random.choice(x))
3
2
3
2
1
#x取值,一次取3个,循环5次
for i in range(5):
print(random.choices(x,k=3))
[3, 3, 4]
[3, 0, 4]
[4, 3, 3]
[2, 4, 2]
[1, 3, 4]
#0,2,1 分别按7:3:5的权重 随机取4个值.循环5次
for i in range(5):
print(random.choices([0,2,1],[7,3,5],k=2))
[1, 0, 0, 0]
[1, 1, 0, 1]
[2, 0, 0, 0]
[0, 0, 2, 1]
[1, 0, 2, 0]random.sample
import random
#抽取值没有重复
random.sample(x,k=5)
[4, 3, 1, 2, 0]
#抽取值没有重复。循环5次
for i in range(5):
print(random.sample(x,k=5))
[1, 4, 3, 2, 0]
[4, 2, 3, 0, 1]
[4, 2, 1, 3, 0]
[2, 3, 1, 4, 0]
[0, 4, 3, 1, 2]