介绍bert之前我们先来看一下NLP发展的几个阶段。
如果说把人类完全攻克人工智能(AI)比作上天的话,那么现在阶段人类已经爬上天梯的第二个阶梯了。再次之前人类总共进行的三个阶段。
- 第一阶段(地上爬):统计机器学习为代表
- 第二阶段(爬上第一阶梯):word2vec为代表
- 第三阶段(爬上第二阶梯):bert为代表
下面我们简要介绍每个阶段。
一、第一阶段(地上爬)
犹如生命的诞生之初,混沌而原始。在word2vec诞生之前,NLP中并没有一个统一的方法去表示一段文本。
各位前辈和大师们发明了许多的方法:
- one-hot表示一个词
- bag-of-words来表示一段文本
- tf-idf中用频率的手段来表征词语的重要性
- text-rank中借鉴了page-rank的方法来表征词语的权重
- 基于SVD纯数学分解词文档矩阵的LSA
- pLSA中用概率手段来表征文档形成过程
- LDA中引入两个共轭分布从而完美引入先验
1、传统统计语言模型:n-gram
实际上,语言模型的本质是对一段自然语言的文本进行预测概率的大小。
P
(
s
)
=
P
(
w
1
w
2
w
3
.
.
.
w
t
)
=
P
(
w
1
)
P
(
w
2
∣
w
1
)
P
(
w
3
∣
w
1
w
2
)
P
(
w
T
∣
w
1
.
.
.
w
T
−
1
)
P(s)=P(w_1w_2w_3...w_t) =P(w_1)P(w_2|w_1)P(w_3|w_1w_2)P(w_T|w_1...w_{T-1})
P(s)=P(w1w2w3...wt)=P(w1)P(w2∣w1)P(w3∣w1w2)P(wT∣w1...wT−1)
这个公式是怎么来的:
-
(1)联合概率
联合概率指的是包含多个条件且所有条件同时成立的概率,记作P(X=a,Y=b)或P(a,b)或者P(ab)。 -
(2)条件概率
条件概率表示在条件Y=b成立的情况下,X=a的概率,记作P(X=a|Y=b)或P(a|b), -
(3)边缘概率
仅与单个随机变量有关的概率称为边缘概率,边缘概率是与联合概率对应的,P(X=a)或P(Y=b) -
(4)三者关系
P ( a ∣ b ) = P ( a , b ) P ( b ) P(a|b)=\frac {P(a,b)}{P(b)} P(a∣b)=P(b)P(a,b)
所有以上可以得到
P ( a , b ) = P ( a ∣ b ) ∗ P ( b ) P(a,b)=P(a|b)*P(b) P(a,b)=P(a∣b)∗P(b)
- (5) 链式法则
没有找到标准定义?
可以得到以上的公式
然而,这个式子的计算依然过于复杂,我们一般都会引入马尔科夫假设:假定一个句子中的词只与它前面的n个词相关。
N-gram这时候就派上用场了。
对于1-gram,其假设是 P ( w t ∣ w 1 w 2 … w n − 1 ) ≈ P ( w t ∣ w t − 1 ) P(w_t|w_1w_2…w_{n-1})≈P(w_t|w_{t-1}) P(wt∣w1w2…wn−1)≈P(wt∣wt−1)
对于2-gram,其假设是 P ( w t ∣ w 1 w 2 … w t − 1 ) ≈ P ( w t ∣ w t − 1 , w n − 2 ) P(w_t|w_1w_2…w_{t-1})≈P(w_t|w_{t-1},w_{n-2}) P(wt∣w1w2…wt−1)≈P(wt∣wt−1,wn−2)
对于3-gram,其假设是 P ( w t ∣ w 1 w 2 … w n − 1 ) ≈ P ( w t ∣ w t − 1 , w t − 2 , w t − 3 ) P(w_t|w_1w_2…w_{n-1})≈P(w_t|w_{t-1},w_{t-2},w_{t-3}) P(wt∣w1w2…wn−1)≈P(wt∣wt−1,wt−2,wt−3)
依次类推。
那么假如t=3那么3-game怎么算呢?
其实就是
P
(
w
t
∣
w
1
w
2
…
w
n
−
1
)
≈
P
(
w
t
∣
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
P(w_t|w_1w_2…w_{n-1})≈P(w_t|w_{t-1},w_{t-2},w_{t-3})
P(wt∣w1w2…wn−1)≈P(wt∣wt−1,wt−2,wt−3)怎么计算的问题,根据条件概率公式可得:
P
(
w
t
∣
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
=
P
(
w
t
,
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
P
(
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
)
P(w_t|w_{t-1},w_{t-2},w_{t-3})=\frac {P(w_t,w_{t-1},w_{t-2},w_{t-3})}{P(w_{t-1},w_{t-2},w_{t-3}))}
P(wt∣wt−1,wt−2,wt−3)=P(wt−1,wt−2,wt−3))P(wt,wt−1,wt−2,wt−3)
根据极大似然估计(Maximum Likelihood Estimation,MLE)**,说人话就是数频数:
P
(
w
t
∣
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
=
P
(
w
t
,
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
P
(
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
)
=
C
(
w
t
,
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
C
(
w
t
−
1
,
w
t
−
2
,
w
t
−
3
)
)
P(w_t|w_{t-1},w_{t-2},w_{t-3})=\frac {P(w_t,w_{t-1},w_{t-2},w_{t-3})}{P(w_{t-1},w_{t-2},w_{t-3}))}=\frac {C(w_t,w_{t-1},w_{t-2},w_{t-3})}{C(w_{t-1},w_{t-2},w_{t-3}))}
P(wt∣wt−1,wt−2,wt−3)=P(wt−1,wt−2,wt−3))P(wt,wt−1,wt−2,wt−3)=C(wt−1,wt−2,wt−3))C(wt,wt−1,wt−2,wt−3)
这样一来,语言模型的计算终于变得可行。
2、 n-gram 存在的三个缺点
然而,这种基于统计的语言模型却存在很多问题:
-
第一,很多情况下 [公式] 的计算会遇到特别多零值,尤其是在n取值比较大的情况下,这种数据稀疏导致的计算为0的现象变得特别严重。所以统计语言模型中一个很重要的方向便是设计各种平滑方法来处理这种情况。
-
第二, 另一个更为严重的问题是,基于统计的语言模型无法把n取得很大,一般来说在3-gram比较常见,再大的话,计算复杂度会指数上升。这个问题的存在导致统计语言模型无法建模语言中上下文较长的依赖关系。
-
第三,统计语言模型无法表征词语之间的相似性。
二、第二阶段(爬上第一阶梯)
1.NNLM(Neural Net Language Model)–铺垫
这些缺点的存在,迫使2003年Bengio在他的经典论文《A Neural Probabilistic Language Model》中,首次将深度学习的思想融入到语言模型中,并发现将训练得到的NNLM(Neural Net Language Model。
NNLM的最主要贡献是非常有创见性的将模型的第一层特征映射矩阵当做词的分布式表示,从而可以将一个词表征为一个向量形式,这直接启发了后来的word2vec的工作。
NNLM虽然将N-Gram的阶n提高到了5,相比原来的统计语言模型是一个很大的进步,但是为了获取更好的长程依赖关系,5显然是不够的。再者,因为NNLM只对词的左侧文本进行建模,所以得到的词向量并不是语境的充分表征。还有一个问题就更严重了,NNLM的训练依然还是太慢,在论文中,Bengio说他们用了40块CPU,在含有1400万个词,只保留词频相对较高的词之后词典大小为17964个词,只训练了5个epoch,但是耗时超过3周。按这么来算,如果只用一块CPU,可能需要2年多,这还是在仅有1400万个词的语料上。如此耗时的训练过程,显然严重限制了NNLM的应用。
2.NNLM优化----铺垫
自NNLM于2003年被提出后,后面又出现了很多类似和改进的工作,诸如LBL, C&W和RNNLM模型等等,这些方法主要从两个方面去优化NNLM的思想。
- (1)其一是NNLM只用了左边的n-1个词,如何利用更多的上下文信息便成为了很重要的一个优化思路(如Mikolov等人提出的RNNLM);
- (2)其二是NNLM的一个非常大的缺点是输出层计算量太大,如何减小计算量使得大规模语料上的训练变得可行,这也是工程应用上至关重要的优化方向(如Mnih和Hinton提出的LBL以及后续的一系列模型)。
(1)2007年Mnih和Hinton提出的LBL以及后续的一系列相关模型,省去了NNLM中的激活函数,直接把模型变成了一个线性变换,尤其是后来将Hierarchical Softmax引入到LBL后,训练效率进一步增强,但是表达能力不如NNLM这种神经网络的结构;
(2)2008年Collobert和Weston 提出的C&W模型不再利用语言模型的结构,而是将目标文本片段整体当做输入,然后预测这个片段是真实文本的概率,所以它的工作主要是改变了目标输出,由于输出只是一个概率大小,不再是词典大小,因此训练效率大大提升,但由于使用了这种比较“别致”的目标输出,使得它的词向量表征能力有限;
(3)2010年Mikolov(对,还是同一个Mikolov)提出的RNNLM主要是为了解决长程依赖关系,时间复杂度问题依然存在。
3.word2vec—突破
- (1)CBOW和Skip-gram模型
2013年,Tomas Mikolov连放几篇划时代的论文,其中最为重要的是两篇,《Efficient estimation of word representations in vector space》首次提出了CBOW和Skip-gram模型。
- (2)优化方法:Hierarchical Softmax和 Negative Sampling
进一步的在《Distributed Representations of Words and Phrases and their Compositionality》中,又介绍了几种优化训练的方法,包括Hierarchical Softmax(当然,这个方法早在2003年,Bengio就在他提出NNLM论文中的Future Work部分提到了这种方法,并于2005年把它系统化发表了一篇论文), Negative Sampling和Subsampling技术。放出两篇论文后,当时仍在谷歌工作的Mikolov又马不停蹄的放出了大杀器——word2vec工具,并在其中开源了他的方法。顺便提一下的是,很多人以为word2vec是一种模型和方法,其实word2vec只是一个工具,背后的模型是CBOW或者Skip-gram,并且使用了Hierarchical Softmax或者Negative Sampling这些训练的优化方法。所以准确说来,word2vec并不是一个模型或算法,只不过Mikolov恰好在当时把他开源的工具包起名叫做word2vec而已。
- (3)里程碑革命意义
word2vec的出现,极大的促进了NLP的发展,尤其是促进了深度学习在NLP中的应用(不过有意思的是,word2vec算法本身其实并不是一个深度模型,它只有两层全连接),利用预训练好的词向量来初始化网络结构的第一层几乎已经成了标配,尤其是在只有少量监督数据的情况下,如果不拿预训练的embedding初始化第一层,几乎可以被认为是在蛮干。
虽然咿咿呀呀囫囵吞枣似的刚开始能够说得三两个词,然而这是“NLP的一小步,人类AI的一大步”。正如人类语言产生之初,一旦某个原始人类的喉部发出的某个音节,经无比智慧和刨根问底考证的史学家研究证实了它具有某个明确的指代意义(无论它指代什么,即便是人类的排泄物),这便无比庄严的宣示着一个全新物种的诞生。
4.word2vec—发展
在此之后,一大批word embedding方法大量涌现,比较知名的有GloVe和fastText等等,它们各自侧重不同的角度,并且从不同的方向都得到了还不错的embedding表征。
二、第三阶段(爬上第二阶梯)
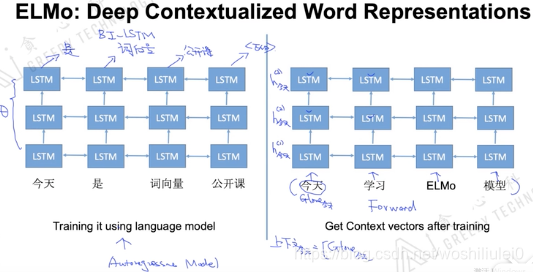
1.ELMo–铺垫
2018年的早些时候,AllenNLP的Matthew E. Peters等人在论文《Deep contextualized word representations》(该论文同时被ICLR和NAACL接受,并且还获得了NAACL最佳论文奖,可见这篇论文的含金量)中首次提出了ELMo,它的全称是Embeddings from Language Models,从名称上可以看出,ELMo为了利用无标记数据,使用了语言模型。
- 1.1特征提取
使用的时双向LSTM来抽取特征,还是使用语言模型的方式来定义loss。
- 1.2特征提取-存在的缺点
(1).梯度消失和梯度爆炸问题、即便使用了attention,也无法解决长文本的long-term dependency,长文本依赖问题
(2).因为使用的是标准的语言模型(sequential model),所以无法并行计算
2.GPT–曙光
大规模语料集上的预训练语言模型这把火被点燃后,整个业界都在惊呼,原来预训练的语言模型远不止十年前Bengio和五年前Mikolov只为了得到一个词向量的威力。然而,当大家还在惊呼,没过几个月,很快在2018年6月的时候,不再属于“钢铁侠”马斯克的OpenAI,发了一个大新闻(相关论文是《Improving Language Understanding by Generative Pre-Training》),往这把火势正猛的烈焰上加了一剂猛料,从而将这把火推向了一个新的高潮。
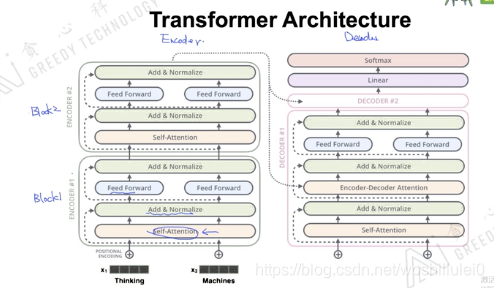
OpenAI的猛料配方里,第一剂主料便是谷歌于2017年年中的时候提出的Transformer框架(《Attention Is All You Need》)。Transformer是谷歌在17年做机器翻译任务的“Attention is all you need”的论文中提出的,引起了相当大的反响。
Transformer作为机器翻译模型注定了这个模型有两个过程:Encoder->Decoder。
Transformer的核心技术是self-attention
-
1.1特征提取
使用了Transformer的decoder过程做特征抽取,还是使用语言模型的方式来定义loss。 -
1.2特征提取-存在的缺点
(1)使用了语言模型的从左边到右的方式,没有考虑右边文本意思,是单向
3.bert–突破
Bidirectional Encoder Representations from Transformers(BERT)
如果要用一句时下正流行的话来形容BERT的出现,这句话大概再恰当不过:
一切过往, 皆为序章。
2018年的10月11日,这似乎是个绝对平凡的日子(OpenAI在其博客中放出GPT工作的时间恰好不多不少是4个整月前,即2018年6月11日),然而Google AI的Jacob Devlin和他的合作者们悄悄地在arxiv上放上了他们的最新文章,名为《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,随后先是在Twitter上引发了一波浪潮,同样是Google AI团队的Thang Luong在其Twitter上直言这项工作是一个划时代的工作(原话“A new era of NLP has just begun a few days ago.”)
-
1.1特征提取
使用了Transformer的Encoder过程做特征抽取,考虑了文本的上下文。 -
1.2特征提取-存在的缺点

4.bert–发展
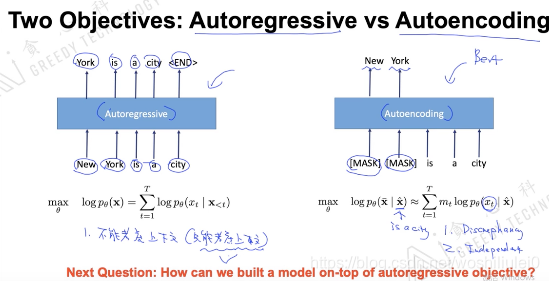
(1).XLNET
自回归自编码的区别

- 1.1特征提取
不能直接适用transformer,需要做调整。

- 1.2特征提取-存在的缺点
???
(2).Roberta
优化bert的一些地方
1).Training the model longer, with bigger batches, over more data
2).Removing the next sentence prediction objective
3).Training on longer sequences
4).Dynamically changing the masking patten applied to the training data.
(3).ALbert
模型压缩
目前可用的号称比bert更好的有中文预训练的模型有
- (1)XLNET-google出品
2019年6月CMU与谷歌大脑提出英文语言模型。
官方地址:https://github.com/zihangdai/xlnet
2019年9月哈工大讯飞联合实验室实现中文XLNet-base语言模型。
https://github.com/ymcui/Chinese-XLNet - (2)ERNIE-百度出品
2019.3 ERNIE1.0
2019.7 ERNIE2.0
官方地址:https://github.com/PaddlePaddle/ERNIE
ERNIE 2.0 模型在英语任务上很多都优于 BERT 和 XLNet,在 7 个 GLUE 任务上取得了最好的结果;中文任务上,ERNIE 2.0 模型在所有 9 个中文 NLP 任务上全面优于 BERT。
缺点:ERNIE2.0预训练模型不开源,无法离线使用,必须在百度平台paddlepaddle上使用。
目前来说百度的ERNIE2.0应该是最好的中文预训练模型,但是必须基于百度的生态才能使用。
DNN->CNN->RNN->LSTM->Attention->Transformer->Bert->XLNet->ERNIE2.0
其他:
ERT优点
-
Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能
-
因为双向功能以及多层Self-attention机制的影响,使得BERT必须使用Cloze版的语言模型Masked-LM来完成token级别的预训练
-
为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练
-
为了适配多任务下的迁移学习,BERT设计了更通用的输入层和输出层
-
微调成本小
BERT缺点
-
task1的随机遮挡策略略显粗犷,推荐阅读《Data Nosing As Smoothing In Neural Network Language Models》
-
[MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现;
-
每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
-
BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
关于BERT最新的各领域应用推荐张俊林的Bert时代的创新(应用篇)
参考文献:
1.https://zhuanlan.zhihu.com/p/50443871
2.https://www.bilibili.com/video/BV1XK4y1t7N5
3.https://www.bilibili.com/video/BV1XK4y1t7N5