一、环境准备⼯作:
确保已经按照以下文档安装完毕:
虚拟机和远程工具的安装(hadoop集群安装01)-CSDN博客
Linux设置以及软件的安装(hadoop集群安装02)-CSDN博客
1、安装了jdk
2、关闭了防⽕墙
3、免密登录
⾃⼰对⾃⼰免密
ssh-copy-id bigdata01 选择yes 输⼊密码
测试免密是否成功: ssh bigdata01
4、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
5、设置host映射
二、本地解压安装
1、上传
2、解压
tar -zxvf hadoop-3.3.1.tar.gz -C /opt/installs/
3、重命名
cd /opt/installs/
mv hadoop-3.3.1 hadoop
4、开始配置环境变量
vi /etc/profile
export JAVA_HOME=/opt/installs/jdk
export HADOOP_HOME=/opt/installs/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
5、刷新配置文件
source /etc/profile
6、验证hadoop命令是否可以识别
hadoop version
三、全分布搭建
全分布模式:必须至少有三台以上的Linux。
前期准备工作:
1、准备三台服务器
目前有两台,克隆第一台(因为第一台上安装了hadoop), 克隆结束后,进行修复操作
1) 修改IP 2) 修改主机名 3)修改映射文件hosts
检查是否满足条件:
环境准备⼯作:
1、安装了jdk
2、设置host映射
192.168.233.128 bigdata01
192.168.233.129 bigdata02
192.168.233.130 bigdata03
远程拷贝:
scp -r /etc/hosts root@bigdata02:/etc/
scp -r /etc/hosts root@bigdata03:/etc/
3、免密登录
bigdata01 免密登录到bigdata01 bigdata02 bigdata03
ssh-copy-id bigdata03
4、第一台安装了hadoop
5、关闭了防⽕墙
systemctl status firewalld
6、修改linux的⼀个安全机制
vi /etc/selinux/config
修改⾥⾯的 SELINUX=disabled
一定要确保三台电脑上的hosts文件都是:
192.168.32.128 bigdata01
192.168.32.129 bigdata02
192.168.32.130 bigdata03修改一台,长拷贝到其他两台:
scp -r /etc/hosts root@bigdata01:/etc
scp -r /etc/hosts root@bigdata02:/etc2、检查各项内容是否到位
1) 防火墙是否都是关闭的
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld
2) jdk是否都安装了
3) 三台电脑是否都安装了hadoop
首先如果你的hadoop已经格式化过namenode ,请删除 /opt/installs/hadoop/tmp文件夹
具体操作就是:确保bigdata01 和 bigdata03 下的 hadoop下的tmp文件夹是删除的状态
cd /opt/installs/hadoop/tmp/
rm -rf ./*
4) Linux的一个安全机制,是否都关闭了
vi /etc/selinux/config
修改此项内容:SELINUX=disabled
5) 三台的免密要做一下
bigdata01 --> bigdata01,bigdata02,bigdata03
ssh-copy-id bigdata02
ssh-copy-id bigdata03
验证一下:
ssh bigdata01 ssh bigdata02 ssh bigdata033、hdfs配置服务的安装
路径:/opt/installs/hadoop/etc/hadoop
<configuration>
<!-- 设置namenode节点 -->
<!-- 注意: hadoop1.x时代默认端⼝9000 hadoop2.x时代默认端⼝8020 hadoop3.x时 代默认端⼝ 9820 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9820</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的⼀个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/installs/hadoop/tmp</value>
</property>
</configuration><configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata02:9868</value>
</property>
<!-- namenode守护进程的http地址:主机名和端⼝号。参考守护进程布局 -->
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata01:9870</value>
</property>
<!--默认是要报错的,因为这是一种安全机制,可以修改一下:
在hdfs-site.xml 中添加如下配置-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>export JAVA_HOME=/opt/installs/jdk
# Hadoop3中,需要添加如下配置,设置启动集群⻆⾊的⽤户是谁
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root修改workers
bigdata01
bigdata02
bigdata03修改完了第一台的配置文件,开始分发到其他两台上去。
scp -r /opt/installs/hadoop root@bigdata02:/opt/installs/
scp -r /opt/installs/hadoop root@bigdata03:/opt/installs/因为第二台什么都没有,所以将整个文件夹都拷贝过去
scp -r /opt/installs/hadoop/ bigdata02:/opt/installs/
第三台: 只需要复制配置文件即可
scp -r /opt/installs/hadoop/etc/hadoop/ bigdata03:/opt/installs/hadoop/etc/
拷贝环境变量:
scp -r /etc/profile root@bigdata02:/etc/
scp -r /etc/profile root@bigdata03:/etc/
在02 和 03 上刷新环境变量 source /etc/profile4、格式化namenode
hdfs namenode -format5、启动hdfs
在第一台电脑上启动
start-dfs.sh启动后jps,看到
| bigdata01 | bigdata02 | bigdata03 |
| namenode | secondaryNameNode | x |
| datanode | datanode | datanode |
web访问:namenode 在哪一台,就访问哪一台。http://192.168.32.128:9870
4、Yarn的配置和搭建
/opt/installs/hadoop/etc/hadoop 文件夹下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
指定mapreduce运行平台为yarn<!--指定resourceManager启动的主机为第一台服务器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
<!--配置yarn的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>检查hadoop-env.sh 中是否配置了权限:
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root继续配置:为了防止报AppMaster的错误,需要如下配置
<property>
<name>yarn.application.classpath</name>
<value>/opt/installs/hadoop/etc/hadoop:/opt/installs/hadoop/share/hadoop/common/lib/*:/opt/installs/hadoop/share/hadoop/common/*:/opt/installs/hadoop/share/hadoop/hdfs:/opt/installs/hadoop/share/hadoop/hdfs/lib/*:/opt/installs/hadoop/share/hadoop/hdfs/*:/opt/installs/hadoop/share/hadoop/mapreduce/*:/opt/installs/hadoop/share/hadoop/yarn:/opt/installs/hadoop/share/hadoop/yarn/lib/*:/opt/installs/hadoop/share/hadoop/yarn/*</value>
</property>获取classpath的值:

分发mapred-site.xml & yarn-site.xml 到另外两台电脑上。
cd /opt/installs/hadoop/etc/hadoop/
xsync.sh mapred-site.xml yarn-site.xml启动和停止yarn平台:
启动: start-yarn.sh
停止: stop-yarn.sh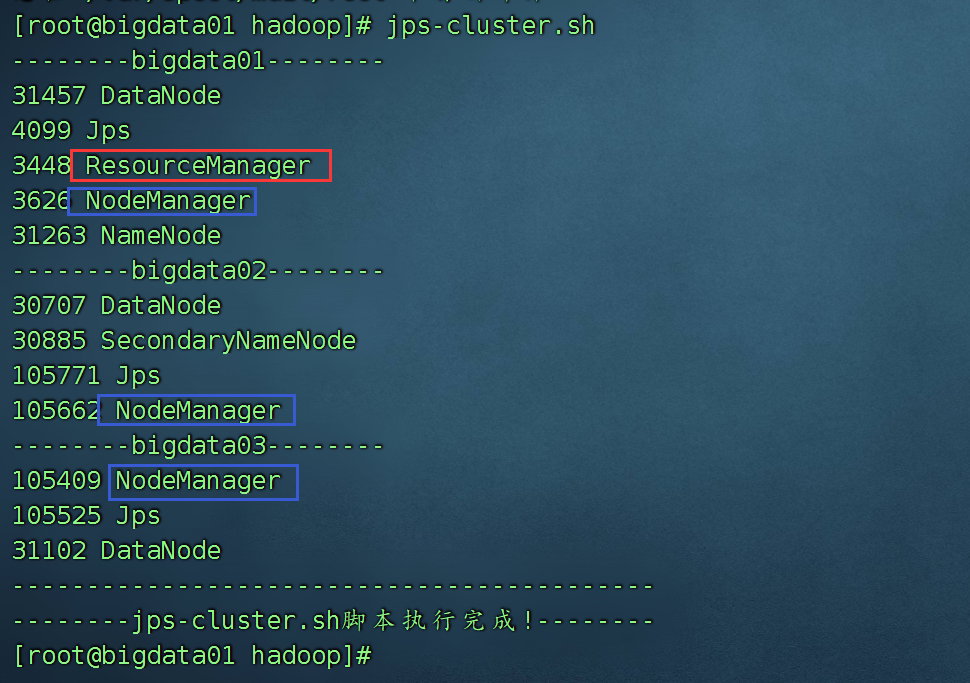
也可以使用web访问一下:
http://192.168.233.128:8088