简介
这是一个端到端的对抗神经网络,即SegAN。generator是一个全卷积网络,并使用了一种新的激活函数。discriminator使用一个多层 L1 L 1 损失(multi-scale L1 L 1 loss),segmentor通过长或短范围的像素空间关系来学习全局和局部特征。使用的数据是ISIC2017(International Skin Imaging Collaboration),传统的分割方法很难学习像素见的局部和全局上下文关系。
这篇论文的创新点:
1. 提出了一个多层
L1
L
1
损失,critic用来最大化这个损失来区别分割图和ground truth在多层上的差异。
2. 在segmentor S中,我们使用了一个带有残差块/跳跃连接的全卷积神经网络和一个新的激活函数。通过critic的梯度来训练的,目的是最小化critic的相同损失函数。
3. SegAN是在整个图像上的端到端的结构。
方法论
segmentor S生成输入图像的分割mask,critic C有两种输入:一种是有ground truth掩码的原始图,另一种是有由S得到的预测图掩码的原始图。S的训练旨在最小化multi-scale L1 L 1 loss,C的训练旨在最大化这个损失。
1. The multi-scale L1 loss
训练图像为
xn
x
n
对应的ground truth为
yn
y
n
,这个损失可以表示为:
ιmae ι m a e 是 Mean Absolute Error (MAE)或者 L1 L 1 distance, xn∘s(xn) x n ∘ s ( x n ) 是原始输入图和segmentor预测概率图的逐像素乘积, xn∘yn x n ∘ y n 是原始输入图和ground truth逐像素乘积。 fc(x) f c ( x ) 代表了用critic对图像x层级特征的提取。 ιmae ι m a e 定义如下:
L是critic的层数, fic(x) f c i ( x ) 是C的第i层图像x的特征图。
由于区分segmentor分割的概率图和ground truth是很难的,这里将segmentor的最后一层的激活函数sigmod/softmax激活函数换为adaptive logistic激活函数。定义为:
k控制了曲线的陡度。k=1是就变成了sigmod函数,当k变小时,logstic函数变得更陡峭并更接近输出0/1。
2 SegAN结构
segmentor使用了编码器-解码器结构,encoder提取输入图像的特征,decoder扩大接受域并获得更多的信息。像residual blocks 一样在不同水平的encoder和decoder之间建立连接来克服过拟合。
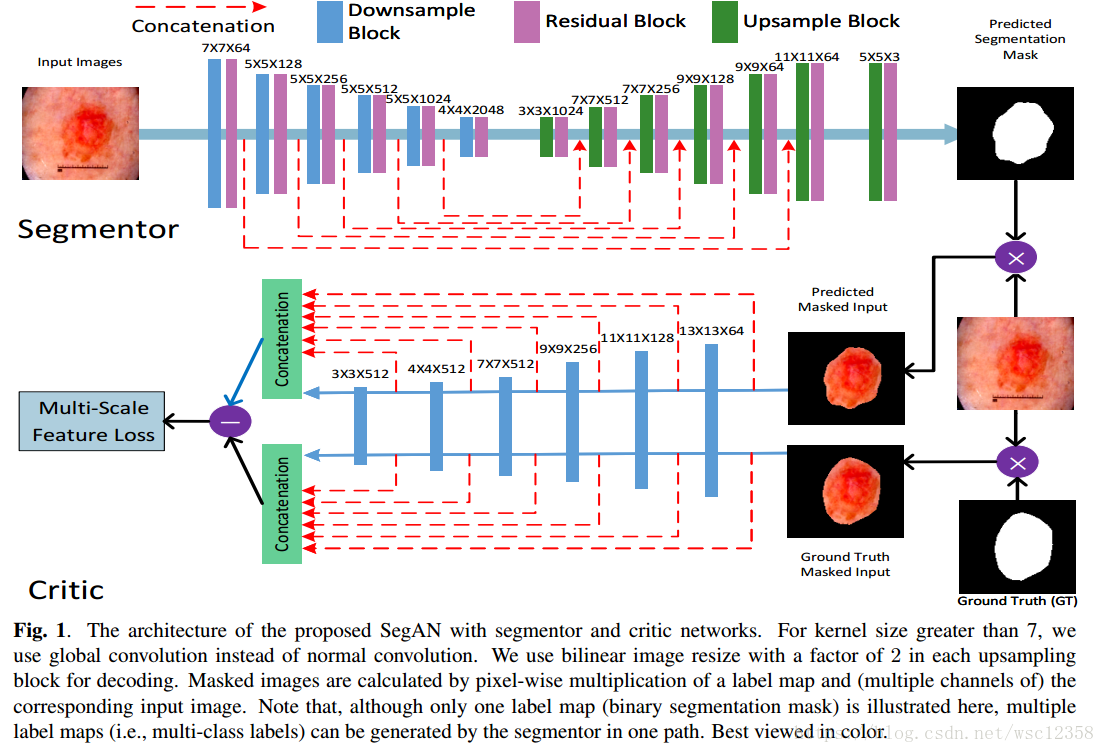
segmentor:在encoder中,卷积层为7,5,4步长为2,在decoder中,卷积核为11,9,7步长为1,在每一个上采样/下采样块后面都有一个残差块,由1*1卷积,3*3卷积和1*1卷积组成,在encoder和decoder的对应层间添加连接,S的最后一层使用了我们提出的adaptive logistic损失函数。
critic:使用了全卷积来获得更大的接受域以及减少参数。方向相反且没有残差块,用C来提取层特征并用the multi-scale
L1
L
1
loss,通过使用这些层特征(如:像素级别特征,低水平特征(superpixels上层像素点),中水平特征(图像块))这个损失可以获取像素间长或短范围的空间关系。
除了S和C的第一个下采样块外,其余的块都用到了正则化,所有的下采样块都用到了Leaky Relu并且所有的批正则化后的上采样块都采用了Relu。