4、部署模式
flink部署模式:
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
区别在于集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行。
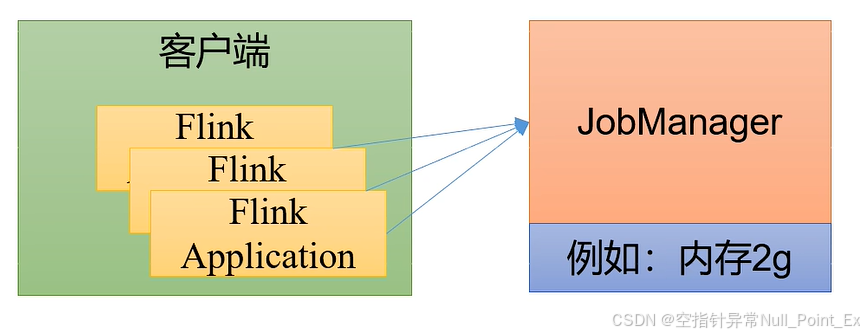
4.1、会话模式
先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时资源已经确定,所有提交的作业会晶振集群中的资源。适合规模小、执行时间短的大量作业。
4.2、单作业模式
资源共享会导致问题,为了隔离资源要为每个提交的作业启动一个集群,即单作业模式。
作业完成后集群关闭,资源释放,一般借助yarn、K8s资源管理框架启动集群。实际应用首选模式

4.3、应用模式
前面两种模式,代码都在客户端上执行,由客户端提交给JobManager,导致客户端需要占用大量网络带宽,加重客户端所在节点的资源消耗。应用模式把应用提交到JobManager运行,每个提交的应用单独启动一个JobManager,执行结束后JobManager关闭。
总结:

- 应有模式与单作业模式是提交作业后才创建集群
- 单作业模式是通过客户端来提交,客户端解析出的每一个作业对应一个集群
- 应用模式直接由JobManager执行应用程序
5、YARN运行模式
5.1、会话模式部署
yarn部署过程:
- 客户端把Flink应用提交给yarn的ResourceManager,yarn的ResourceManager向yarn的NodeManager申请容器
- Flink部署JobManager和TaskManager到容器上,在启动集群
- Flink根据运行在JobManager上的作业所需要的Slot数量动态分配TaskManager资源
配置准备
-
修改配置文件
vim /etc/profile -
添加环境变量
export HADOOP_CLASSPATH=`hadoop classpath` -
环境变量生效
source /etc/profile
- 会话模式部署
启动测试
提交jar任务
运行状态


5.2、应用模式部署(生产环境推荐)
与但作业模式类似,直接执行flink run-application命令即可,先将jar拷贝到flink根文件夹下
使用命令提交作业
bin/flink run-application -t yarn-application -c FlinkDemo.StreamWordCount ./flinkDemo-1.0-SNAPSHOT-jar-with-dependencies.jar
使用HDFS提交(生产环境推荐)
1、上传flink依赖到HDFS的flink-dist文件夹
hadoop fs -put lib/ /flink-dist
hadoop fs -put lib/ /flink-dist
hadoop fs -put plugins/ /flink-dist
2、上传jar包到HDFS到flink-jars文件夹
hadoop fs -mkdir /flink-jars
hadoop fs -put flinkDemo-1.0-SNAPSHOT-jar-with-dependencies.jar/ /flink-jars
3、运行jar包
bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop100:8020/flink-dist" -c FlinkDemo.StreamWordCount hdfs://hadoop100:8020/flink-jars/flinkDemo-1.0-SNAPSHOT-jar-with-dependencies.jar
历史服务器:查看停止的job的统计信息
6、flink运行时架构
以Standalone会话模式为例

-
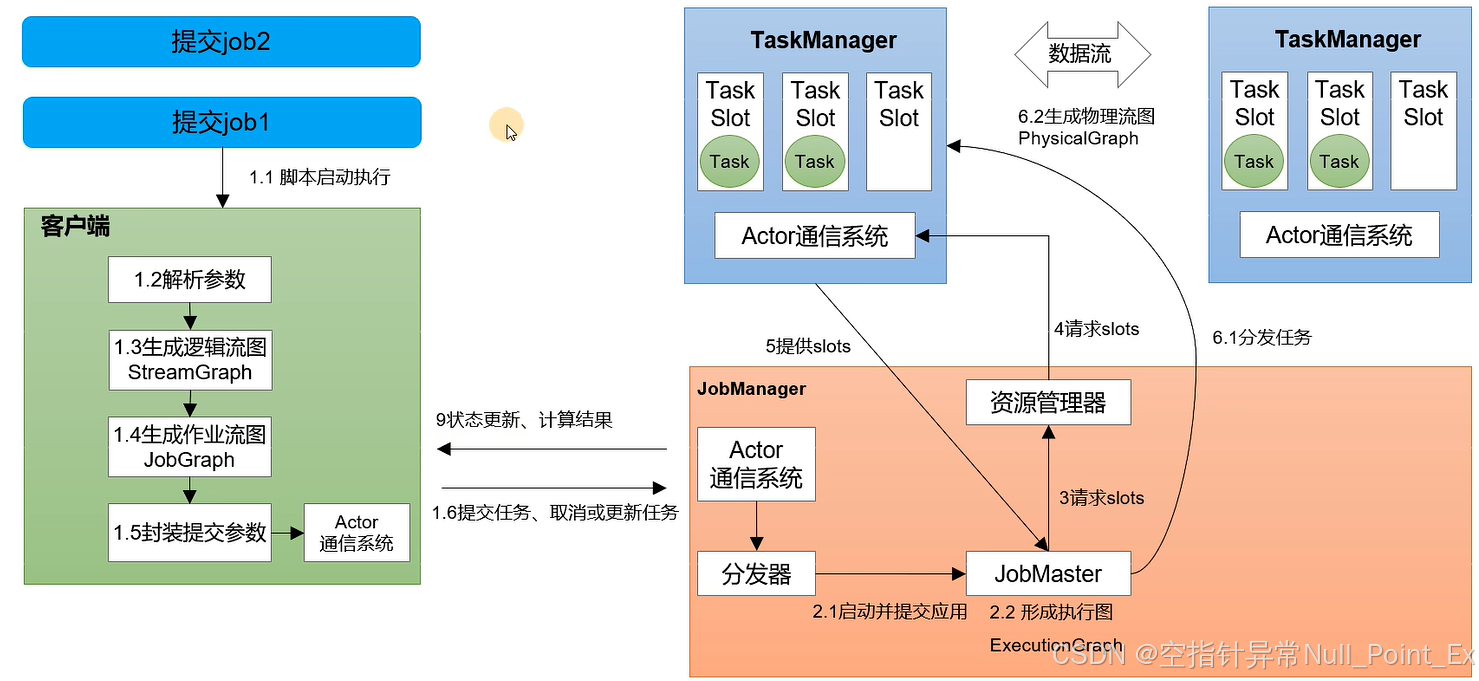
作业管理器(JobManager)
JobManager是一个Flink集群任务管理和调度的核心,是控制应用执行的主进程,每个应用都有一JobManager。JobMaster是JobManager中最核心的组件,负责处理单独作业。JobMaster和job一一对应,多个job可运行在同一集群中,每个job有一个对应的JobMaster。
-
资源管理器
负责资源的分配和管理。资源主要指TaskManager的任务槽(task slot)。任务槽为flink集群中资源调配单元,包含执行计算的cpu和内存。每个task要分配到一个slot上执行。
-
分发器
负责提供rest接口,用来提交应用并且负责为每一个新提交的作业启动一个新的JobMaster,也会启动webUI
-
任务管理器(TaskManager)
TaskManager是flink中的工作进程,负责数据流的具体计算。flink集群中必须至少有一个TaskManager,每个TaskManager包含一定数量的task slot。slot为资源调度的最小单位,slot的数量限制了TaskManager能够并行处理的任务数量
7、核心概念
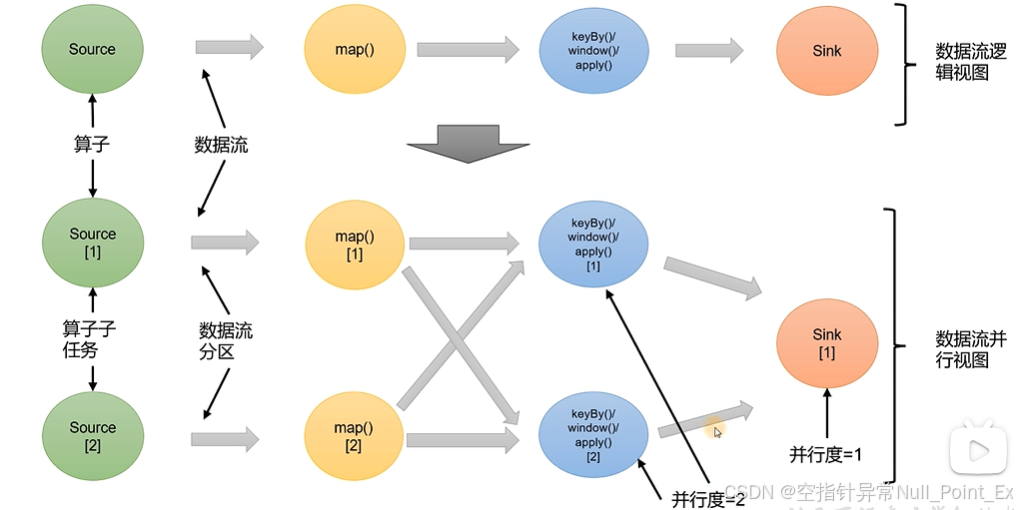
7.1、并行度
当要处理大量数据时,可以把算子操作“复制”多分,每个算子都可执行计算任务。一个任务就拆分成多个子任务,实现了并行计算。flink执行过程中,每个算子包含一个或多个子任务,这些子任务在不同的线程、不同的物理机或不同容器中执行。
一个算子的子任务个数为其并行度。一个流程序并行度是其所有算子中最大的并行度。
可通过代码设置并行度(优先度最高),默认为电脑CPU的线程数。
算子.setParallelism(并行度)
全局环境设置并行度
env.setParallelism(并行度)
通过web页面/命令行提交时设置并行度(优先度低)
flink的yaml配置文件配置并行度(优先度最低)
优先级:算子指定>env指定>提交时设置>配置文件配置
7.2、算子链
-
一对一one-to-one(forwarding)
这种模式数据流维护着分区以及元素的顺序。如source和map算子,source算子读取数据后直接发给map算子处理,他们之间不需要重新分区和调整顺序,保持着一对一的关系。map、source、flatMap都是这种一对一的关系。
-
重分区redistributing
数据流的分区会发生改变。map和,keyBy/window算子之间,keyBy/window算子之间与sink算子之间都是重分区关系。
- 合并算子链:将并行度相同的一对一算子操作可以直接链接在一起形成一个子任务,被一个线程执行。
7.3、任务槽
flink每一个taskManager都是一个JVM进程,它可以启动多个独立的线程来并行执行多个子任务。为了控制并发量就需要再taskManager上对每个任务运行所占用的资源做出明确的划分,就是任务槽。
每个任务槽表示taskManager拥有计算资源的固定大小的子集。这些资源用来独立执行一个子任务。
假如一个taskManager有三个slot,就会将管理的内存均分成三份,每个slot独占一份,slot不会去争抢资源。**slot仅用来隔离内存,不隔离CPU。**建议slot数量为cpu核心数,避免争抢cpu资源。
同一作业不同算子的并行子任务可以放到同一slot上执行。
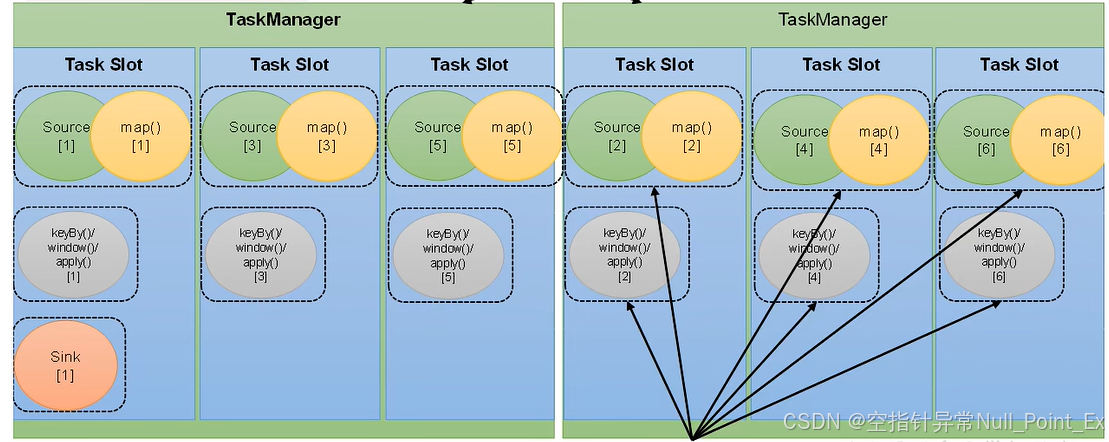
7.4、任务槽与并行度关系
任务槽是静态概念,是指taskManager具有并发执行能力;并行度是动态概念,程序运行时的实际使用的并发能力。slot的数量是最大并行度。并行度超过slot数量flink不能运行。
使用yarn动态申请资源:申请taskManager数量=并行度/每个taskManager的slot数(向上取整)
8、作业提交流程
8.1、Standalone会话模式
8.2、yarn应用模式

9、DataStream API
DataStream API是flink核心层API。一个flink程序就是对DataStream的各种转换。代码一般由几个部分组成:
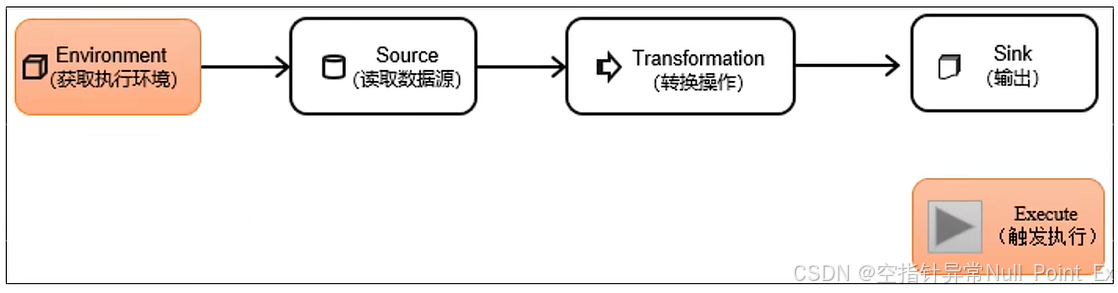
9.1、执行环境
1、创建环境
StreamExecutionEnvironment类的对象是所有flink程序的基础。最常用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2、程序执行
flink是由事件驱动的,只有等数据到来才会触发计算。需要显式调用执行环境的execute()方法来触发程序执行。execute()将一直等待作业完成返回一个执行结果(JobExecutionResult)。
env.execute();
9.2、源算子source
9.2.1、准备工作
数据模型
| 字段名 | 数据类型 | 说明 |
|---|---|---|
| id | String | 水位传感器类型 |
| ts | Long | 传感器记录时间戳 |
| vc | Integer | 水位记录 |
定义类
package bean;
import java.util.Objects;
/**
* @Title: WaterSensor
* @Author lizhe
* @Package bean
* @Date 2024/5/29 21:06
* @description: 水位类
*/
public class WaterSensor {
public String id;
public Long ts;
public Integer vc;
public String getId() {
return id;
}
public WaterSensor setId(String id) {
this.id = id;
return this;
}
public Long getTs() {
return ts;
}
public WaterSensor setTs(Long ts) {
this.ts = ts;
return this;
}
public Integer getVc() {
return vc;
}
public WaterSensor setVc(Integer vc) {
this.vc = vc;
return this;
}
@Override
public String toString() {
return "WaterSensor{" +
"id='" + id + '\'' +
", ts=" + ts +
", vc=" + vc +
'}';
}
public WaterSensor(String id, Long ts, Integer vc) {
this.id = id;
this.ts = ts;
this.vc = vc;
}
public WaterSensor() {
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
WaterSensor that = (WaterSensor) o;
return Objects.equals(id, that.id) &&
Objects.equals(ts, that.ts) &&
Objects.equals(vc, that.vc);
}
@Override
public int hashCode() {
return Objects.hash(id, ts, vc);
}
}
package source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* @Title: CollectionDemo
* @Author lizhe
* @Package source
* @Date 2024/5/29 22:06
* @description:
*/
public class CollectionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从数组读取数据
DataStreamSource<Integer> source = env.fromCollection(Arrays.asList(1, 22, 34));
source.print();
//直接读取数据
DataStreamSource<Integer> source1 = env.fromElements(22, 4456, 66);
source1.print();
env.execute();
}
}
9.2.2、从集合中读数据
package source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* @Title: CollectionDemo
* @Author lizhe
* @Package source
* @Date 2024/5/29 22:06
* @description:
*/
public class CollectionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从数组读取数据
DataStreamSource<Integer> source = env.fromCollection(Arrays.asList(1, 22, 34));
source.print();
//直接读取数据
DataStreamSource<Integer> source1 = env.fromElements(22, 4456, 66);
source1.print();
env.execute();
}
}
9.2.3、从文件中读数据
导入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.13.0</version>
</dependency>
package source;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.file.src.FileSource;
import org.apache.flink.connector.file.src.reader.TextLineFormat;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @Title: FileSourceDemo
* @Author lizhe
* @Package source
* @Date 2024/5/29 22:13
* @description:
*/
public class FileSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
FileSource<String> fileSource = FileSource.forRecordStreamFormat(new TextLineFormat(), new Path("input/words.txt")).build();
env.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"filesource").print();
env.execute();
}
}
9.2.4、从Kafka读数据
官网地址:https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/connectors/datastream/kafka/
导入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.13.6</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.13.6</version>
</dependency>
启动kafka集群
编写代码

package source;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @Title: FileSourceDemo
* @Author lizhe
* @Package source
* @Date 2024/5/29 22:13
* @description:
*/
public class KafkaSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("192.168.132.100:9092,192.168.132.101:9092,192.168.132.102:9092")
.setGroupId("test")
.setTopics("test")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
.build();
env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),"filesource").print();
env.execute();
}
}
9.2.5、flink数据类型
查看TypeInformation(实现序列化)。TypeInformation类是flink中所有类型描述符的基类。涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化、反序列化、比较器。
- 基本类型:java基本类型及其包装类,还有void、string、date、bigDecimal、bigInteger
- 数组类型:基本类型数组和对象数组
- 复合数据类型:元组类型(Tuple)
- 辅助类型:List、Map
- 泛型