1. 概述
本文主要是参照 B 站 UP 主 霹雳吧啦Wz 的视频学习笔记,参考的相关资料在文末参照栏给出,包括实现代码和文中用的一些图片。
整个工程已经上传个人的 github https://github.com/lovewinds13/QYQXDeepLearning ,下载即可直接测试,数据集文件因为比较大,已经删除了,按照下文教程下载即可。
论文下载:Going Deeper with Convolutions
2. GoogLeNet
GoogLeNet 在 2014 年由 Google 团队提出, 斩获当年 ImageNet 竞赛中 Classification Task (分类任务) 第一名。
GoogLeNet 虽然深度只有 22 层,但大小却比 AlexNet 和 VGG 小很多,GoogleNet 参数为 500 万个,AlexNet 参数个数是 GoogleNet 的 12 倍,VGGNet 参数又是 AlexNet 的 3 倍。因此在内存或计算资源有限时,GoogleNet 是更好的选择。
网络中的亮点:
(1)引入了 Inception 结构(融合不同尺度的特征信息);
(2)使用 1x1 的卷积核进行降维以及映射处理;
(3) 添加两个辅助分类器帮助训练;
(4)舍弃全连接层, 使用平均池化层(极大减少模型参数)。
2.1 网络框架
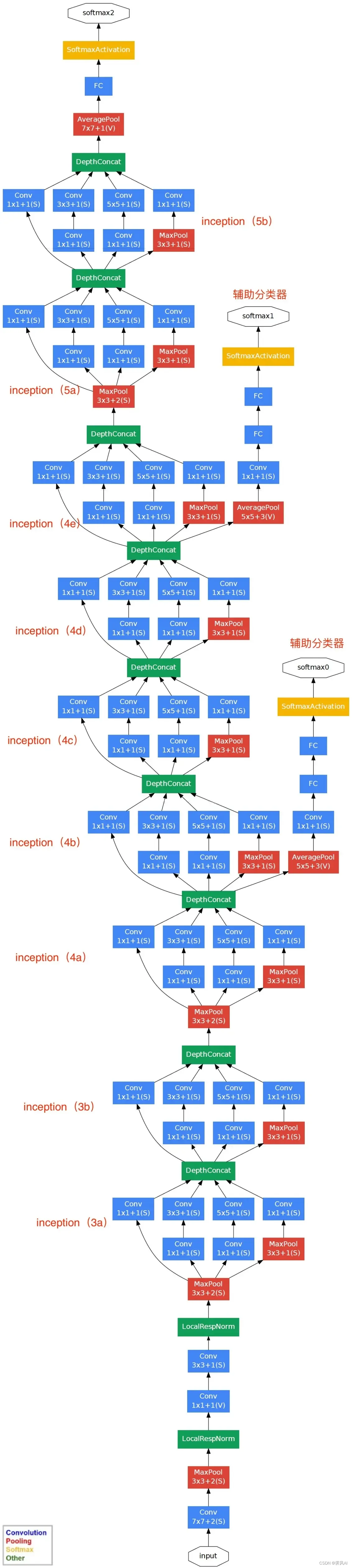
GoogLeNet 网络结果说明:
(1)GoogLeNet 采用了模块化的结构(Inception 结构),方便增添和修改;
(2)网络最后采用了 average pooling(平均池化)来代替全连接层,该想法来自 NIN(Network in Network),事实证明这样可以将准确率提高 0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便对输出进行灵活调整;
(3)移除了全连接,网络使用 Dropout 失活神经元 ;
(4)为了避免梯度消失,网络额外增加了 2 个辅助的 softmax 用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,有利于整个网络训练,实际测试中,这两个额外的 softmax 将会被去掉。
补充:
2.1.1 Inception 结构
GoogLeNet 提出了一种并联结构,下图即为 inception 初始结构,将特征矩阵同时输入到多个分支进行处理,并将输出的特征矩阵按深度进行拼接,得到最终输出,这样可以增加网络深度和宽度,同时减少参数。
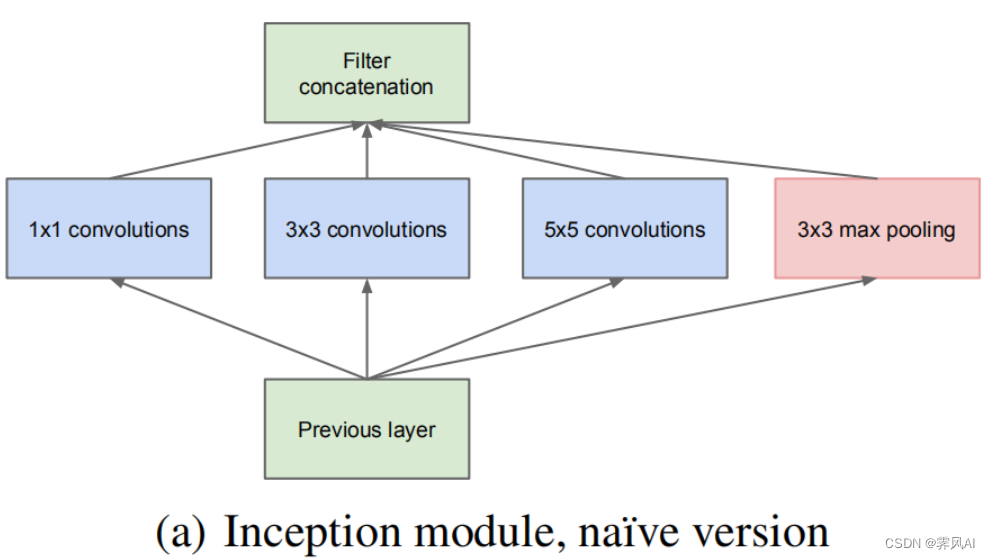
需要注意的是:每个分支所得特征矩阵的高和宽必须相同 [ 通过调整 stride 和 padding 得到],以保证输出特征能在深度上进行拼接。
Inception —> 降维
在实现 Inception 的基础上,还可增加降维结构,在原始 Inception 结构之上,在分支 2、3、4 上加入了卷积核大小为 1x1 的卷积层,从而完成降维(减小深度,即改变输出特征 channel 数),减少模型训练参数和计算量。
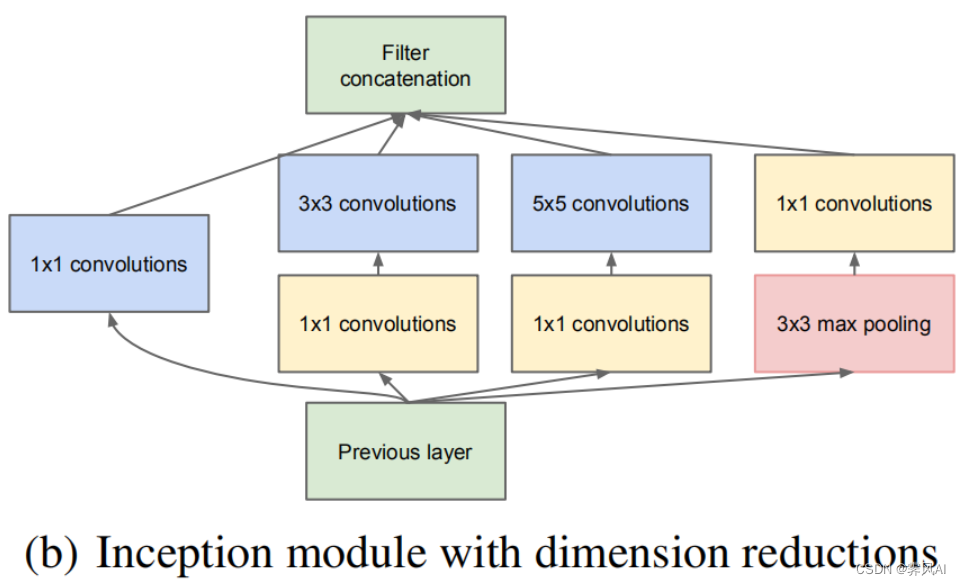
2.1.2 使用 1x1 卷积核降维
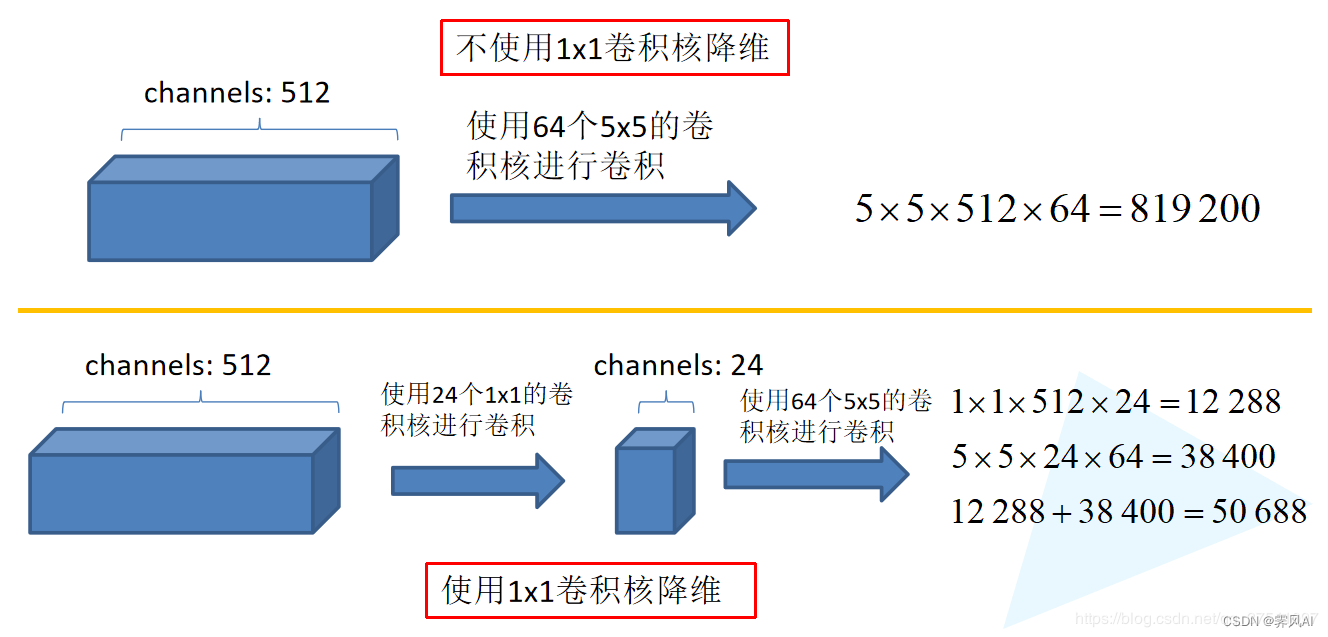
针对一个深度为 512 的特征矩阵使用 64 个大小为 5x5 的卷积核进行卷积,是否加入 1x1 的卷积参数对比如下:
| 初始特征矩阵 | 1x1 卷积核 | 参数 |
|---|---|---|
| 深度为 512 的特征矩阵 | 无 | 5x5x512x64 = 819 200 |
| 深度为 512 的特征矩阵 | 有 | 1x1x512x24+5x5x24x64 = 50 688 |
CNN 参数个数
= 卷积核尺寸 x 卷积核深度 x 卷积核组数
= 卷积核尺寸 x 输入特征矩阵深度 x 输出特征矩阵深度
如上图所示,如果不使用 1x1 卷积核降维,共需要 819200 个参数,使用 1x1 卷积核进行降维后需要 50688 个参数,减少了 819200 - 50688 = 768512 个参数。
2.1.3 Auxiliary Classifier(辅助分类器)
前面学习的 LeNet,AlexNet 和 VGG 都只有 1 个输出层,而 GoogLeNet 有 3 个输出层,其中,有两个是辅助分类层。
两个辅助分类器一模一样,在训练模型时,将两个辅助分类器的损失乘以权重(论文中为 0.3),然后加到网络的整体损失上,再进行反向传播。
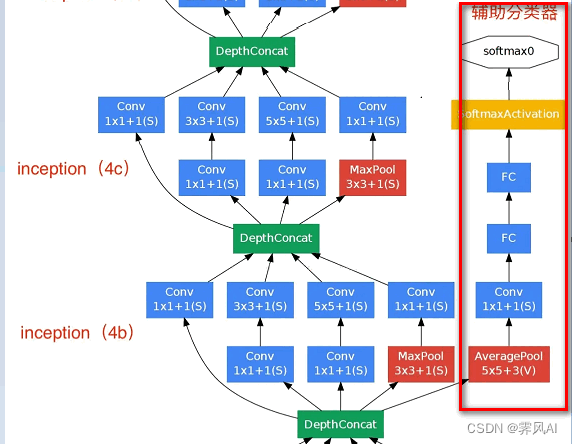
辅助分类器的作用:
(1)可以将其看做 Inception 网络中的一个小细节,确保了即便是隐藏单元和中间层也参与了特征计算,也能预测图片的类别,在 Inception 网络中起到一种调整的效果,并且能防止网络发生过拟合;
(2)针对给定深度相对较大的网络,有效传播梯度反向通过所有层的能力是一个问题。通过将辅助分类器添加到这些中间层,可以期望较低阶段分类器的判别力。在训练期间,它们的损失以折扣权重(辅助分类器损失的权重是 0.3)加到网络的整个损失上。
2.2 GoogLeNet 的网络结构参数
在 Inception 模块中,需要使用的参数有 #1x1, #3x3reduce, #3x3,#5x5reduce, #5x5, pool proj 6个参数,分别对应着所使用的卷积核个数。
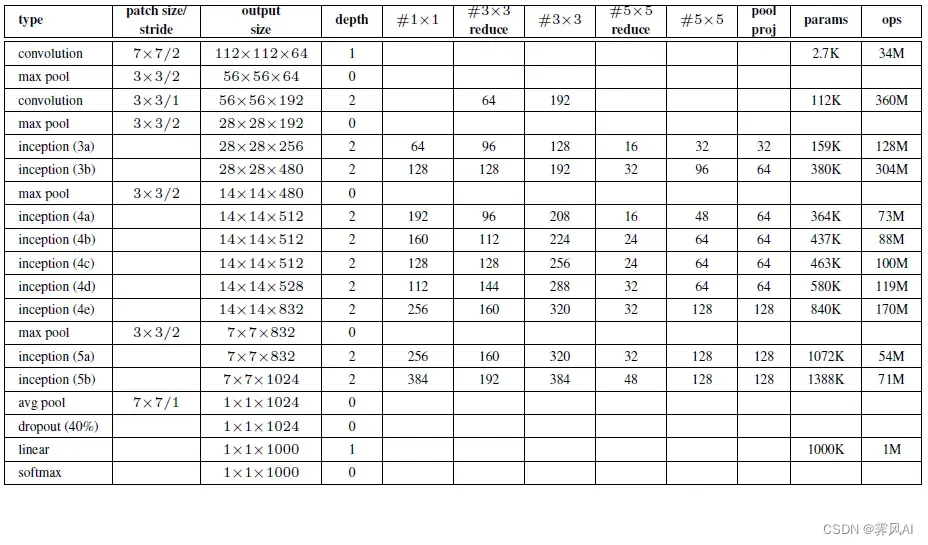
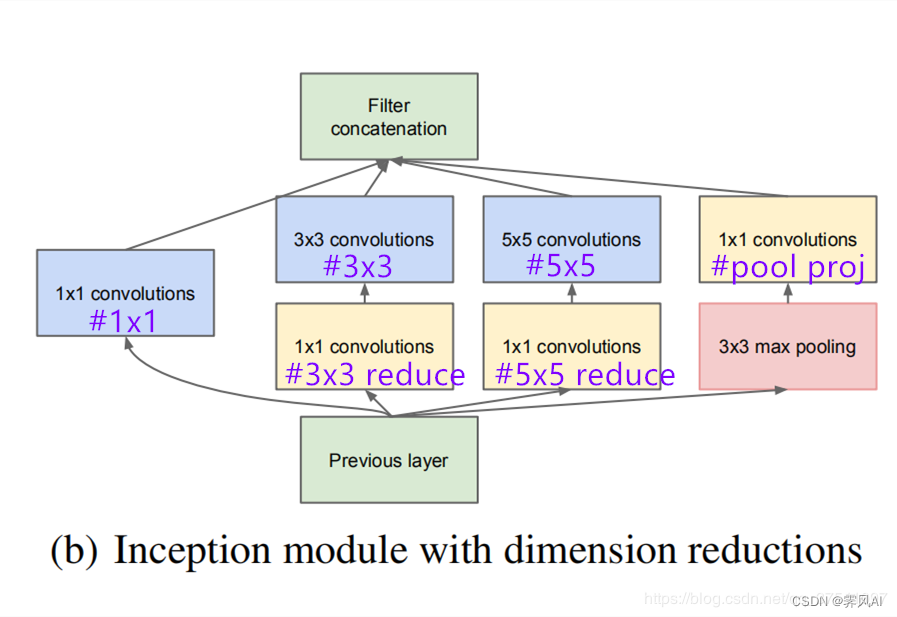
| 卷积核 | 分支 |
|---|---|
| #1x1 | 分支1上1x1的卷积核个数 |
| #3x3reduce | 着分支2上1x1的卷积核个数 |
| #3x3 | 分支2上3x3的卷积核个数 |
| #5x5reduce | 分支3上1x1的卷积核个数 |
| #5x5 | 分支3上5x5的卷积核个数 |
| pool proj | 分支4上1x1的卷积核个数 |
3. demo 实现
3.1 数据集
本文使用花分类数据集,下载链接: 花分类数据集——http://download.tensorflow.org/example_images/flower_photos.tgz

数据集划分参考这个pytorch图像分类篇:3.搭建AlexNet并训练花分类数据集
3.2 model.py
"""
模型
"""
"""
VGG模型
"""
import torch.nn as nn
import torch
import torch.nn.functional as F
"""
# 定义卷积+激活函数操作模板
"""
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
"""
# 定义 Iception 辅助分类器模板
"""
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = BasicConv2d(in_channels, 128, kernel_size=1) # output = [batch, 128, 4, 4]
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
# aux1: N*512*14*14, aux2: N*528*14*14
x = self.averagePool(x)
# aux1: N*512*4*4, aux2: N*528*4*4
x = self.conv(x)
# N*128*4*4
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
# N*2048
x = F.relu(self.fc1(x), inplace=True)
x = F.dropout(x, 0.5, training=self.training)
# N*1024
x = self.fc2(x)
# N*num_classes
return x
"""
# Inception 模板
"""
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1) # 保证输出大小等于输入大小
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
# 官方 3x3, https://github.com/pytorch/vision/issues/906
BasicConv2d(ch5x5red, ch5x5, kernel_size=5, padding=2) # 输出大小=输入大小
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1) # 拼接数据
"""
# GoogLeNet 模型
"""
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N*3*224*224
x = self.conv1(x)
# N*64*112*112
x = self.maxpool1(x)
# N*64*56*56
x = self.conv2(x)
# N*64*56*56
x = self.conv3(x)
# N*192*56*56
x = self.maxpool2(x)
# N*192*28*28
x = self.inception3a(x)
# N*256*28*28
x = self.inception3b(x)
# N*480*28*28
x = self.maxpool3(x)
# N*480*14*14
x = self.inception4a(x)
# N*512*14*14
if self.training and self.aux_logits: # eval model lose this layer
aux1 = self.aux1(x)
x = self.inception4b(x)
# N*512*14*14
x = self.inception4c(x)
# N*512*14*14
x = self.inception4d(x)
# N*528*14*14
if self.training and self.aux_logits: # eval model lose this layer
aux2 = self.aux2(x)
x = self.inception4e(x)
# N*832*14*14
x = self.maxpool4(x)
# N*832*7*7
x = self.inception5a(x)
# N*832*7*7
x = self.inception5b(x)
# N*1024*7*7
x = self.avgpool(x)
# N*1024*1*1
x = torch.flatten(x, 1)
# N*1024
x = self.dropout(x)
x = self.fc(x)
# N*1000 (num_classes)
if self.training and self.aux_logits: # eval model lose this layer
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
"""
测试模型
"""
# if __name__ == '__main__':
# input1 = torch.rand([224, 3, 224, 224])
# model_x = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True)
# print(model_x)
# output = GoogLeNet(input1)
3.3 train.py
3.3.1 导入包
"""
训练(CPU)
"""
import os
import sys
import json
import time
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm # 显示进度条模块
from model import GoogLeNet
3.3.2 数据集预处理
data_transform = {
"train": transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪, 再缩放为 224*224
transforms.RandomHorizontalFlip(), # 水平随机翻转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]),
"val": transforms.Compose([
transforms.Resize((224, 224)), # 元组(224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
}
3.3.3 加载数据集
3.3.3.1 读取数据路径
# data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # 读取数据路径
data_root = os.path.abspath(os.path.join(os.getcwd(), "./"))
image_path = os.path.join(data_root, "data_set", "flower_data")
# image_path = data_root + "/data_set/flower_data/"
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
此处相比于 UP 主教程,修改了读取路径。
3.3.3.2 加载训练集
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"]
)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=nw
)
3.3.3.3 加载验证集
val_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"]
)
val_num = len(val_dataset)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=4,
shuffle=False,
num_workers=nw
)
3.3.3.4 保存数据索引
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open("calss_indices.json", 'w') as json_file:
json_file.write(json_str)
3.3.4 训练过程
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True) # 实例化网络(5分类)
# net.to(device)
net.to("cpu") # 直接指定 cpu
loss_function = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 优化器(训练参数, 学习率)
epochs = 10 # 训练轮数
save_path = "./GoogLeNet.pth"
best_accuracy = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
net.train() # 开启Dropout
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout) # 设置进度条图标
for step, data in enumerate(train_bar): # 遍历训练集,
images, labels = data # 获取训练集图像和标签
optimizer.zero_grad() # 清除历史梯度
logits, aux_logits2, aux_logits1 = net(images)
loss0 = loss_function(logits, labels)
loss1 = loss_function(aux_logits1, labels)
loss2 = loss_function(aux_logits2, labels)
loss = loss0 + loss1 * 0.3 + loss2 * 0.3 # 计算损失值
loss.backward() # 方向传播
optimizer.step() # 更新优化器参数
running_loss += loss.item()
train_bar.desc = "train epoch [{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss
)
# 验证
net.eval() # 关闭Dropout
acc = 0.0
with torch.no_grad():
val_bar = tqdm(val_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels).sum().item()
val_accuracy = acc / val_num
print("[epoch %d ] train_loss: %3f val_accurancy: %3f" %
(epoch + 1, running_loss / train_steps, val_accuracy))
if val_accuracy > best_accuracy: # 保存准确率最高的
best_accuracy = val_accuracy
torch.save(net.state_dict(), save_path)
print("Finshed Training.")
训练过程可视化信息输出:
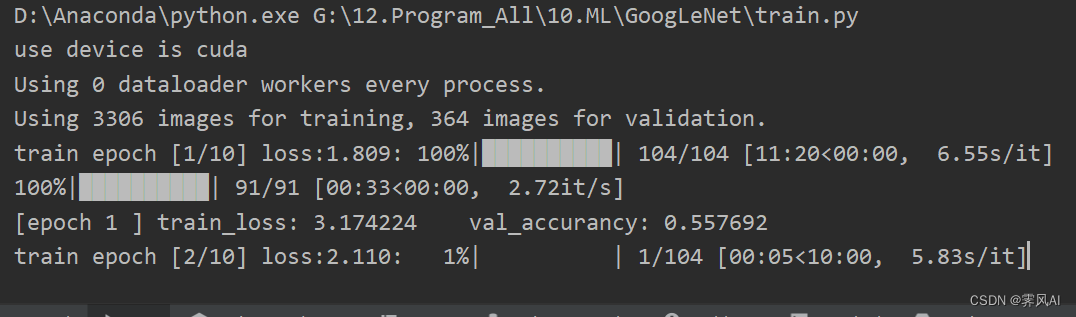
注意:
GoogLeNet 的网络输出 loss 分为三个部分,分别是主干输出 loss、两个辅助分类器输出loss(权重0.3)。
logits, aux_logits2, aux_logits1 = net(images)
loss0 = loss_function(logits, labels)
loss1 = loss_function(aux_logits1, labels)
loss2 = loss_function(aux_logits2, labels)
loss = loss0 + loss1 * 0.3 + loss2 * 0.3 # 计算损失值
GPU 训练代码: 仅在 CPU 训练的基础上做了数据转换处理。
"""
训练(GPU)
"""
import os
import sys
import json
import time
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import GoogLeNet
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"use device is {device}")
data_transform = {
"train": transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]),
"val": transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
}
# data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # 读取数据路径
data_root = os.path.abspath(os.path.join(os.getcwd(), "./"))
image_path = os.path.join(data_root, "data_set", "flower_data")
# image_path = data_root + "/data_set/flower_data/"
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"]
)
train_num = len(train_dataset)
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
json_str = json.dumps(cla_dict, indent=4)
with open("calss_indices.json", 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # 线程数计算
nw = 0
print(f"Using {nw} dataloader workers every process.")
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=nw
)
val_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"]
)
val_num = len(val_dataset)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=4,
shuffle=False,
num_workers=nw
)
print(f"Using {train_num} images for training, {val_num} images for validation.")
# test_data_iter = iter(val_loader)
# test_image, test_label = next(test_data_iter)
""" 测试数据集图片"""
# def imshow(img):
# img = img / 2 + 0.5
# np_img = img.numpy()
# plt.imshow(np.transpose(np_img, (1, 2, 0)))
# plt.show()
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = GoogLeNet(num_classes=5, aux_logits=True, init_weights=True) # 实例化网络(5分类)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 10
save_path = "./VGGNet_GPU.pth"
best_accuracy = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits, aux_logits2, aux_logits1 = net(images.to(device))
loss0 = loss_function(logits, labels.to(device))
loss1 = loss_function(aux_logits1, labels.to(device))
loss2 = loss_function(aux_logits2, labels.to(device))
loss = loss0 + loss1 * 0.3 + loss2 * 0.3
loss.backward()
optimizer.step()
running_loss += loss.item()
train_bar.desc = "train epoch [{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss
)
# 验证
net.eval()
acc = 0.0
with torch.no_grad():
val_bar = tqdm(val_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accuracy = acc / val_num
print("[epoch %d ] train_loss: %3f val_accurancy: %3f" %
(epoch + 1, running_loss / train_steps, val_accuracy))
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
torch.save(net.state_dict(), save_path)
print("Finshed Training.")
if __name__ == '__main__':
main()
3.3.5 结果预测
"""
预测
"""
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import GoogLeNet
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
image_path = "./daisy01.jpg"
img = Image.open(image_path)
plt.imshow(img)
img = data_transform(img) # [N, C H, W]
img = torch.unsqueeze(img, dim=0) # 维度扩展
# print(f"img={img}")
json_path = "./calss_indices.json"
with open(json_path, 'r') as f:
class_indict = json.load(f)
# model = AlexNet(num_classes=5).to(device) # GPU
# model = vgg(model_name="vgg16", num_classes=5) # CPU
model = GoogLeNet(num_classes=5, aux_logits=False)
weights_path = "./GoogLeNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
# model.load_state_dict(torch.load(weights_path))
missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path), strict=False)
model.eval() # 关闭 Dorpout
with torch.no_grad():
# output = torch.squeeze(model(img.to(device))).cpu() #GPU
output = torch.squeeze(model(img)) # 维度压缩
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
# for i in range(len(predict)):
# print("class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
# predict[predict_cla].numpy()))
plt.show()
if __name__ == '__main__':
main()
预测结果如下:

注意:
GoogLeNet 实例化模型时不需要辅助分类器。因为在加载训练好的模型参数时,其中包含有辅助分类器,需要设置参数 strict=False。
model = GoogLeNet(num_classes=5, aux_logits=False)
weights_path = "./GoogLeNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
# model.load_state_dict(torch.load(weights_path))
missing_keys, unexpected_keys = model.load_state_dict(torch.load(weights_path), strict=False)