1. RNN存在的问题
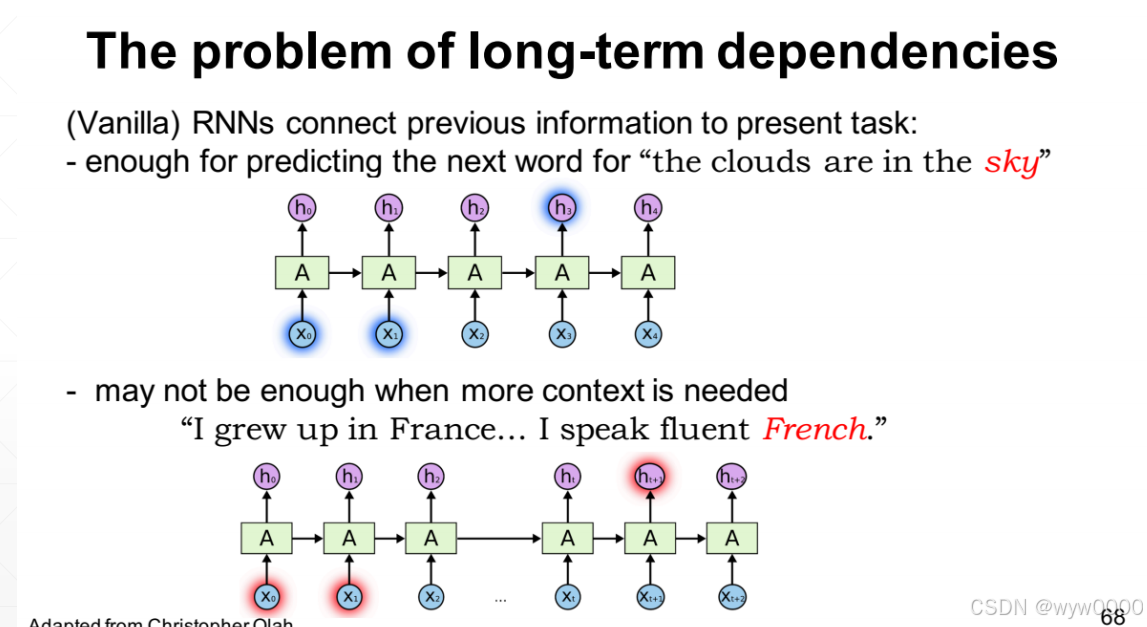
如下图:RNN能满足预测下一个单词,但是对于获取更多的上下文信息就做不到了。
2. LSTM的由来
RNN能做到短时记忆即short time memory,而LSTM相对RNN能够处理更长的时间序列,因此被称为LSTM即long short time memory
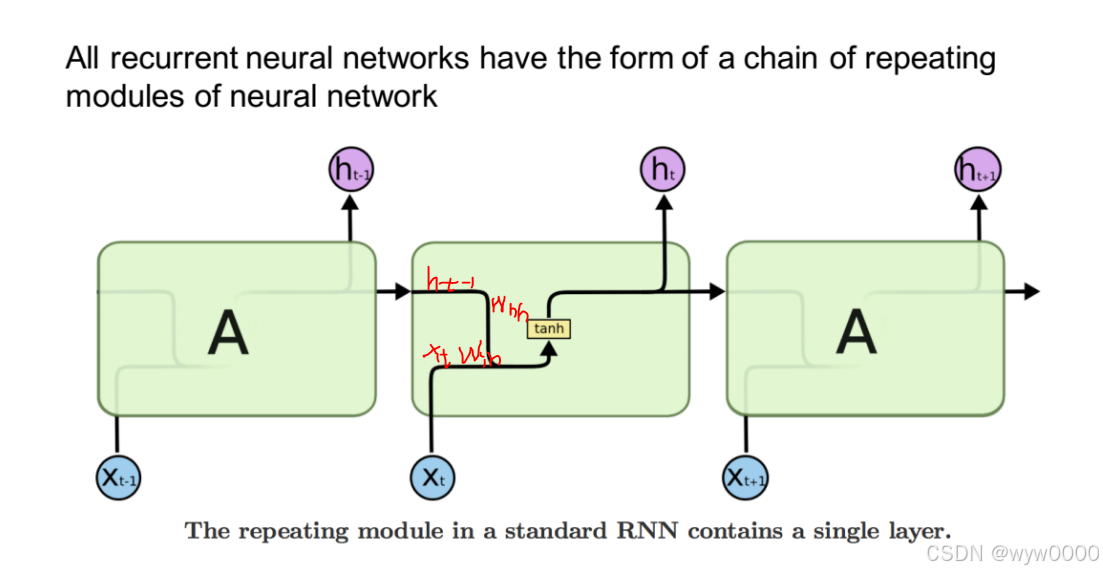
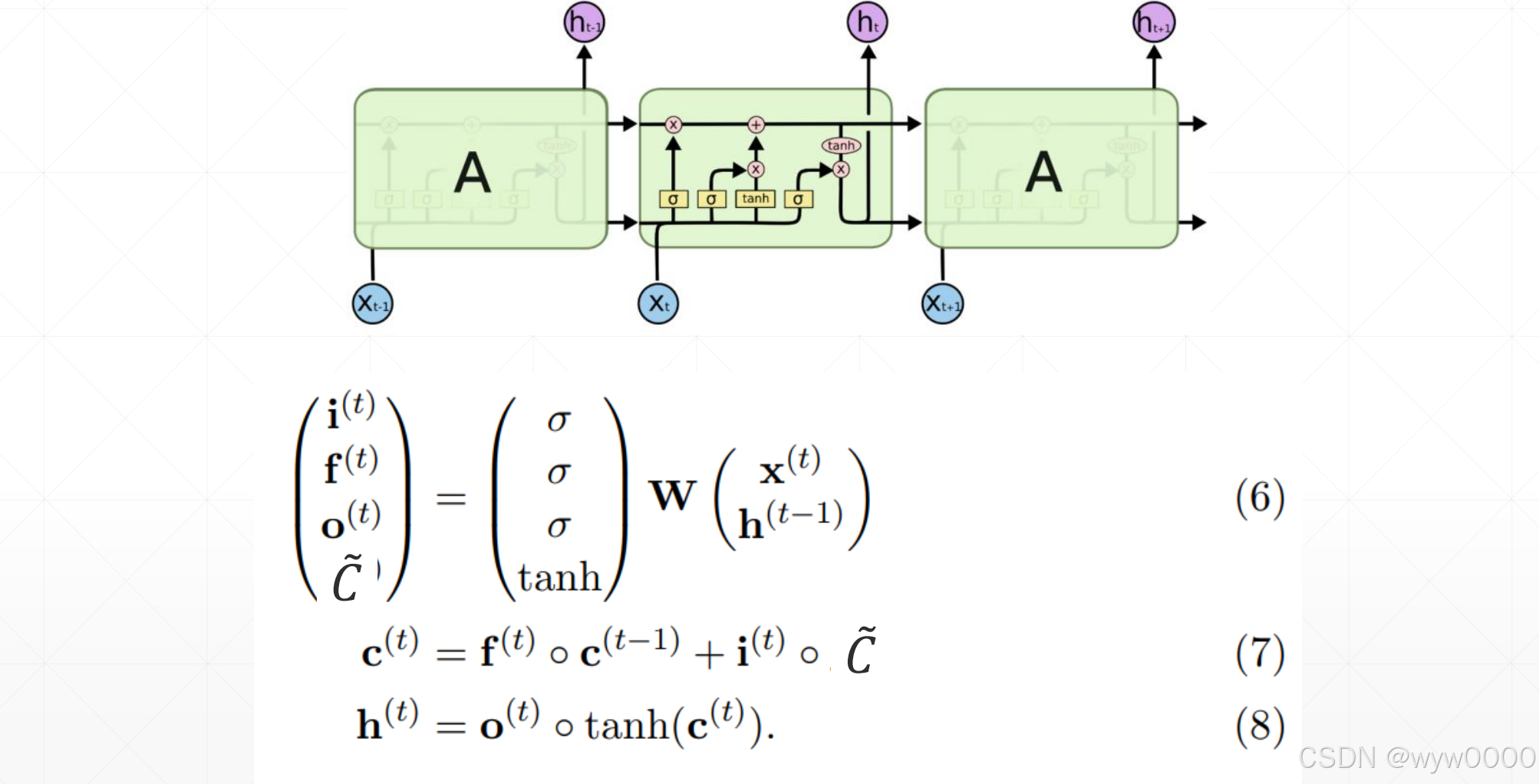
RNN有一串重复的模块,这些模块使用统一的权重Whh和Wih
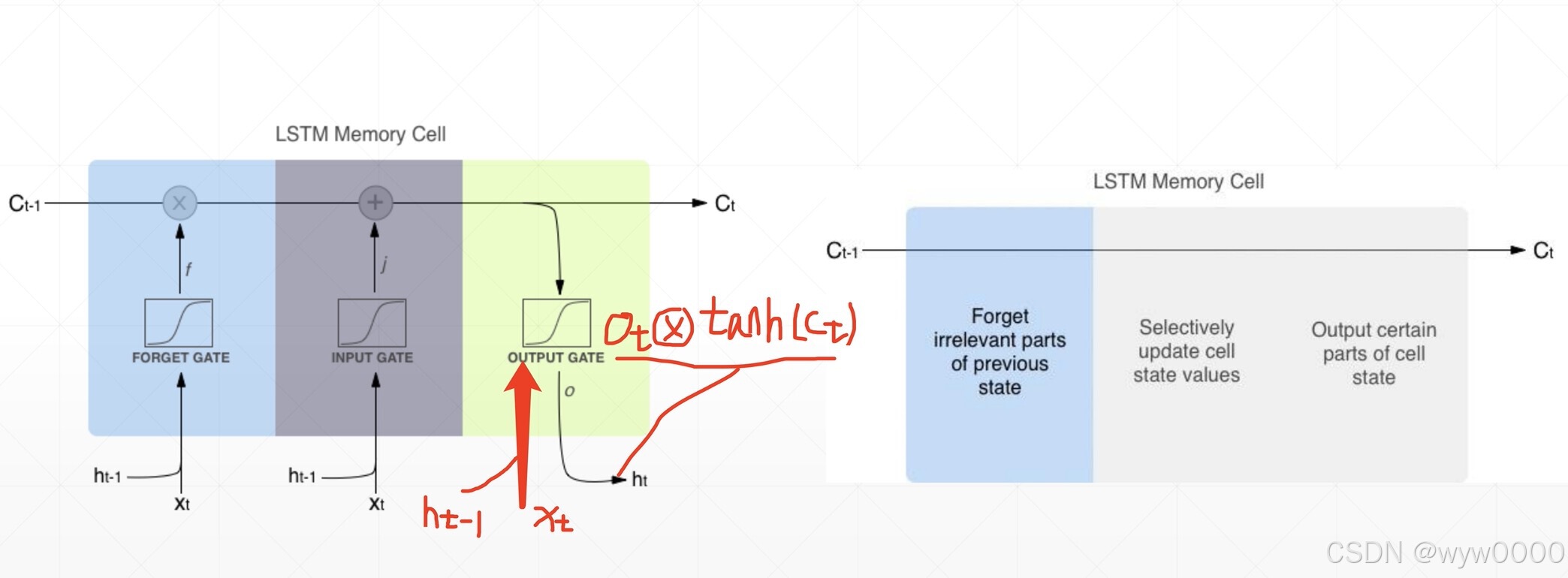
LSTM也有一连串的类似结构,但是重复模块是不同的结构,它用四个单层的神经网络替代,并以指定的方式相互作用。它有三个门,分别是遗忘门、输入门和输出门。
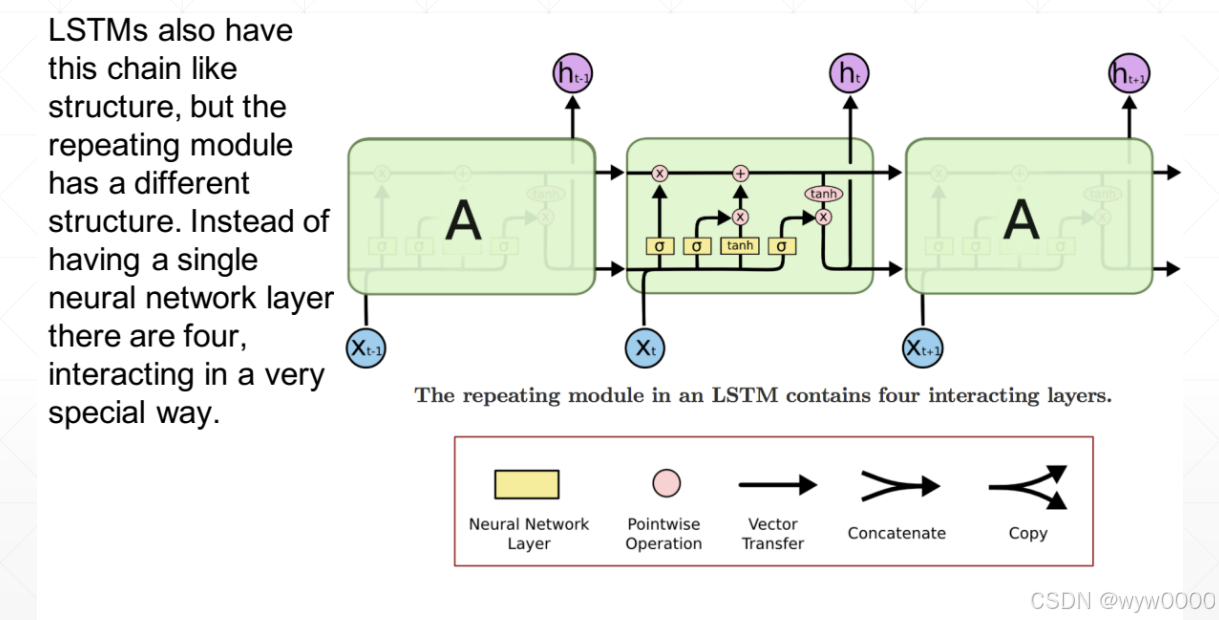
3. LSTM门
门是一种信息过滤方式,他们由sigmod函数和点乘操作组成,sigmod范围是0~1,因此通过sigmod函数可以控制输出。
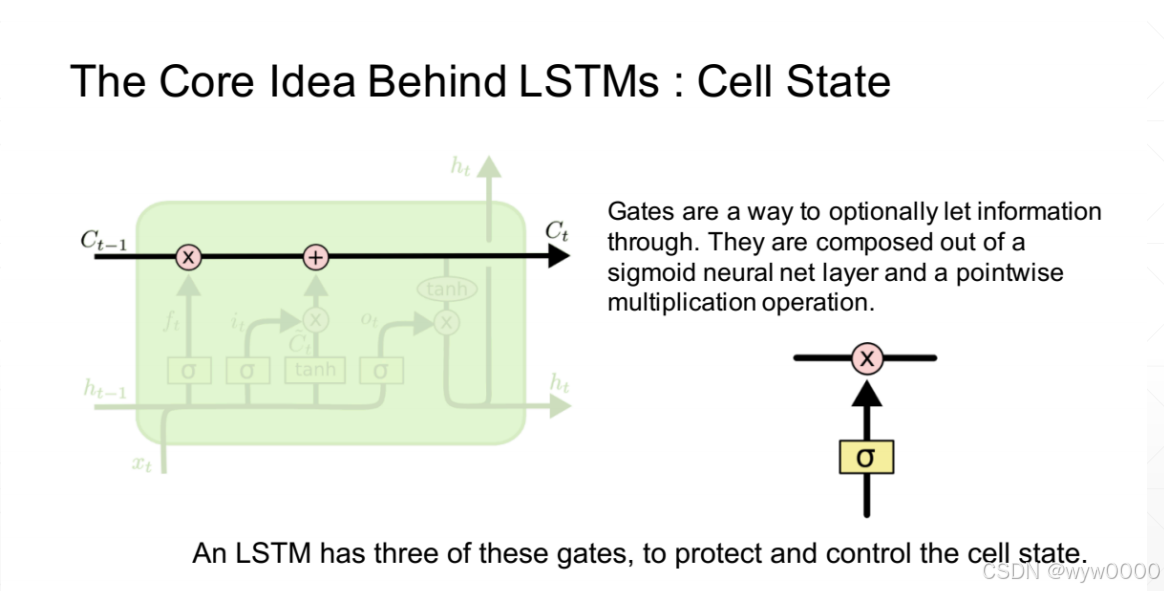
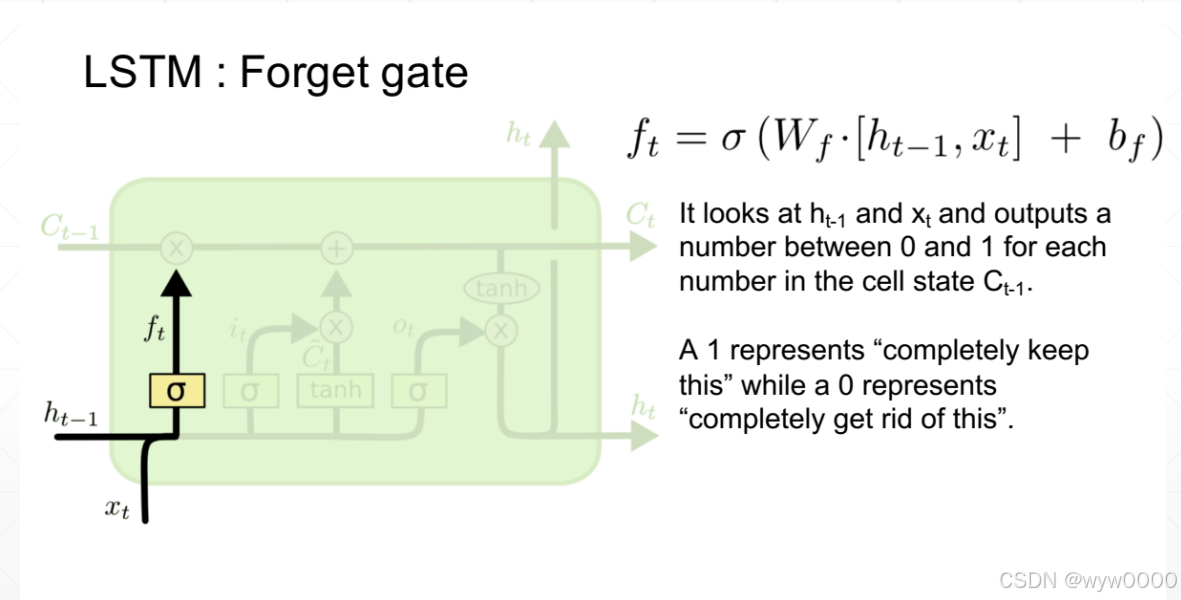
3.1 遗忘门
遗忘门ft是ht-1和xt经过一系列运算,再经过sigmod函数得到的
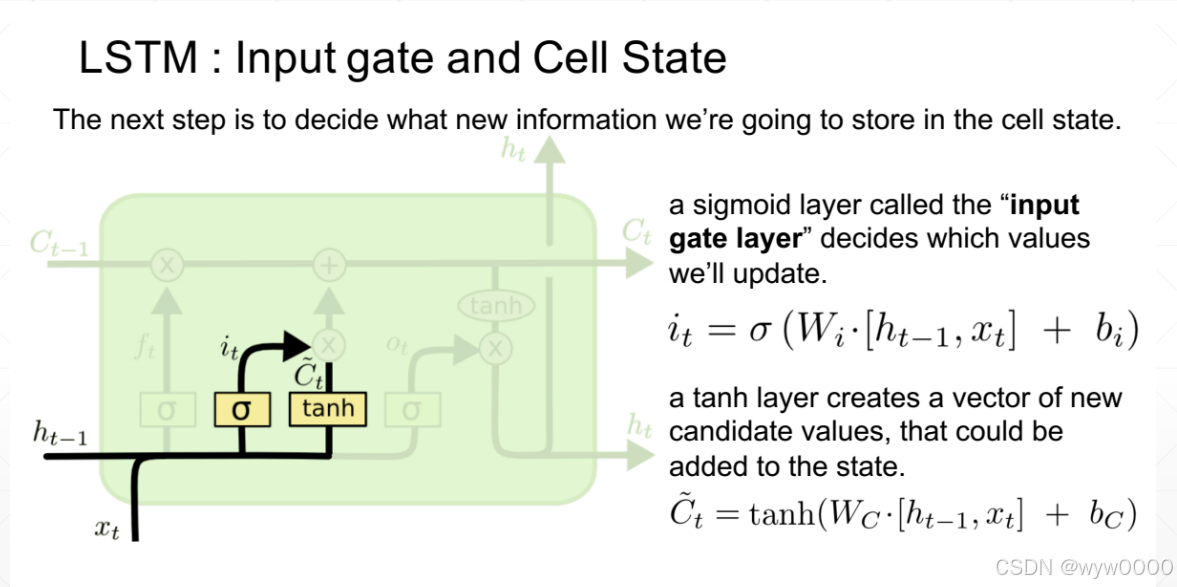
3.2 输入门
输入门由两部分组成,一个是it输入门层,它是通过ht-1和xt经过一系列运算,再经过sigmod函数得到的。
另一个是新的输入Ct’,这里没有直接使用xt作为输入,而是通过ht-1和xt经过一系列运算,再经过tanh函数得到新的输入Ct’。
最后输出Ct = ft*Ct-1 + it*Ct’
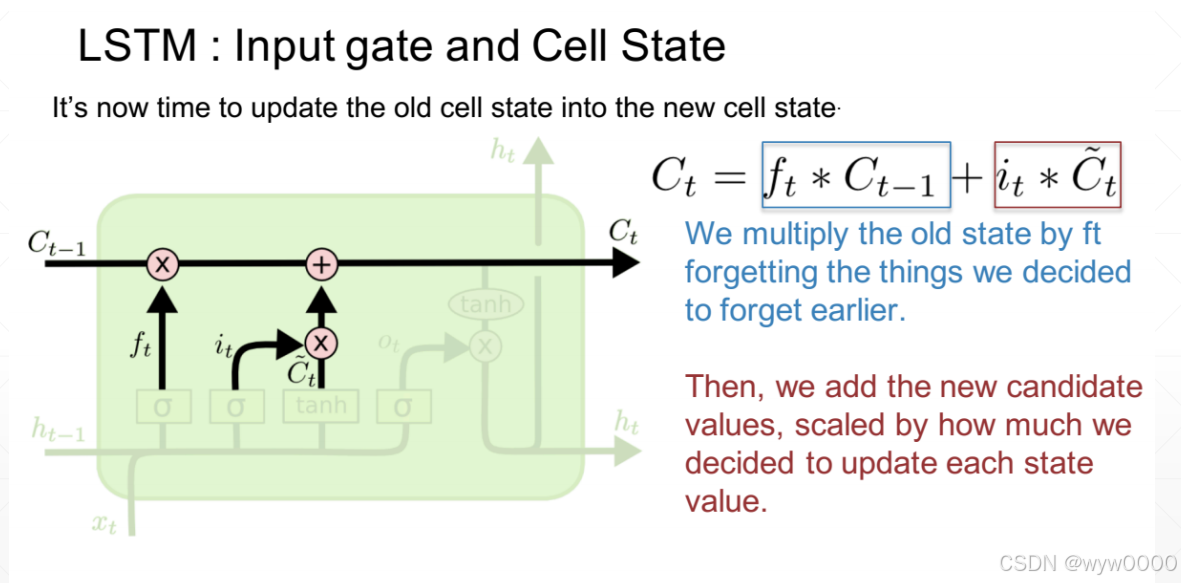
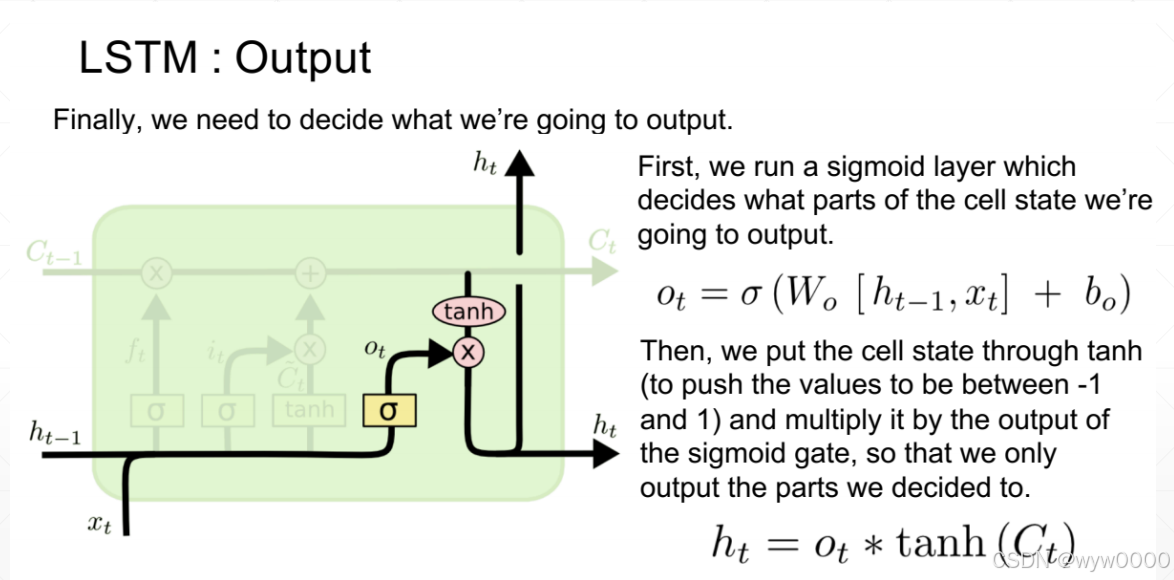
3.3 输出门
输出门ot也是通过ht-1和xt经过一系列运算,再经过sigmod函数得到的。
最后的输出ht = ot*tanh(Ct)
注意:LSTM中ht已经不是memory了,而是输出,Ct才是memory
可以看出每个门的运算都与ht-1和xt相关,并且通过sigmod函数来控制门的开度,最后的输出ht使用了tanh
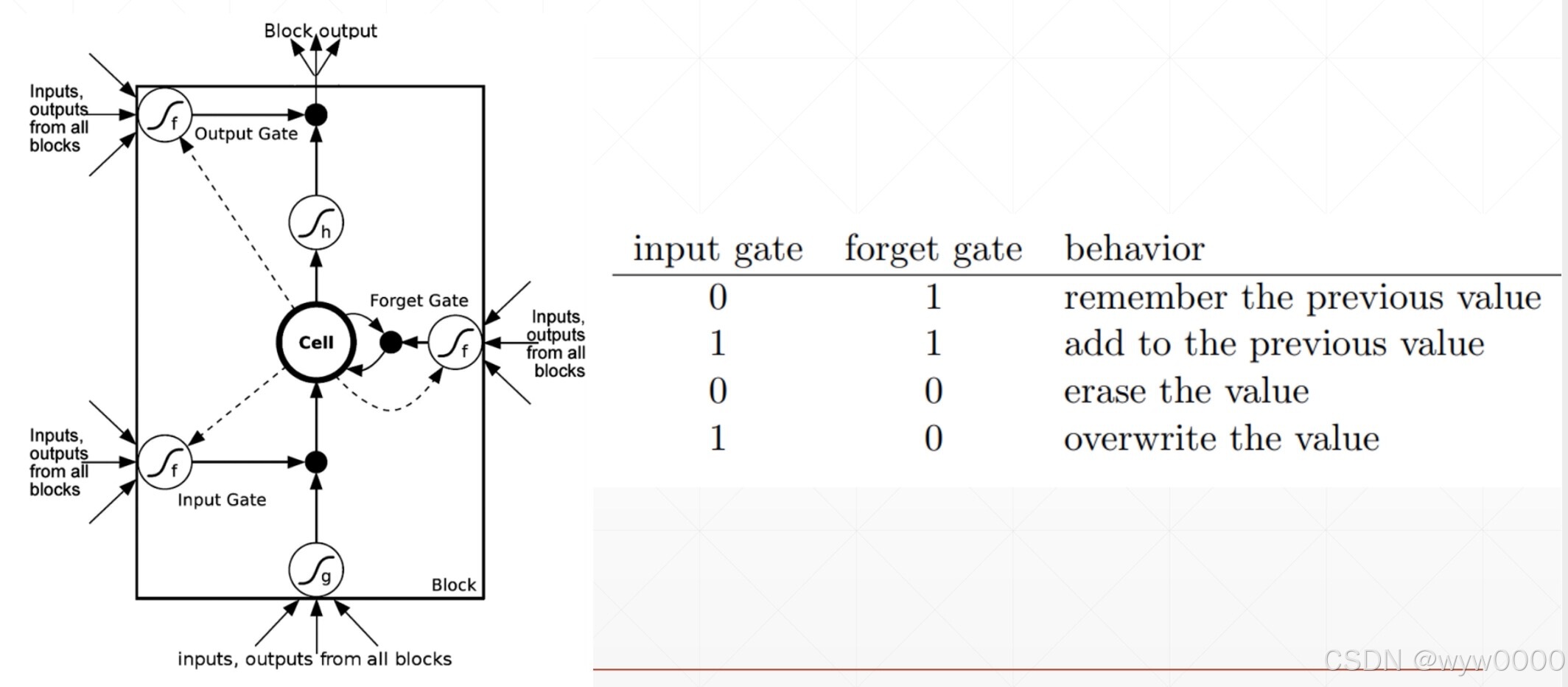
输入们和遗忘门门的组合,会得到不同的值,如下图:
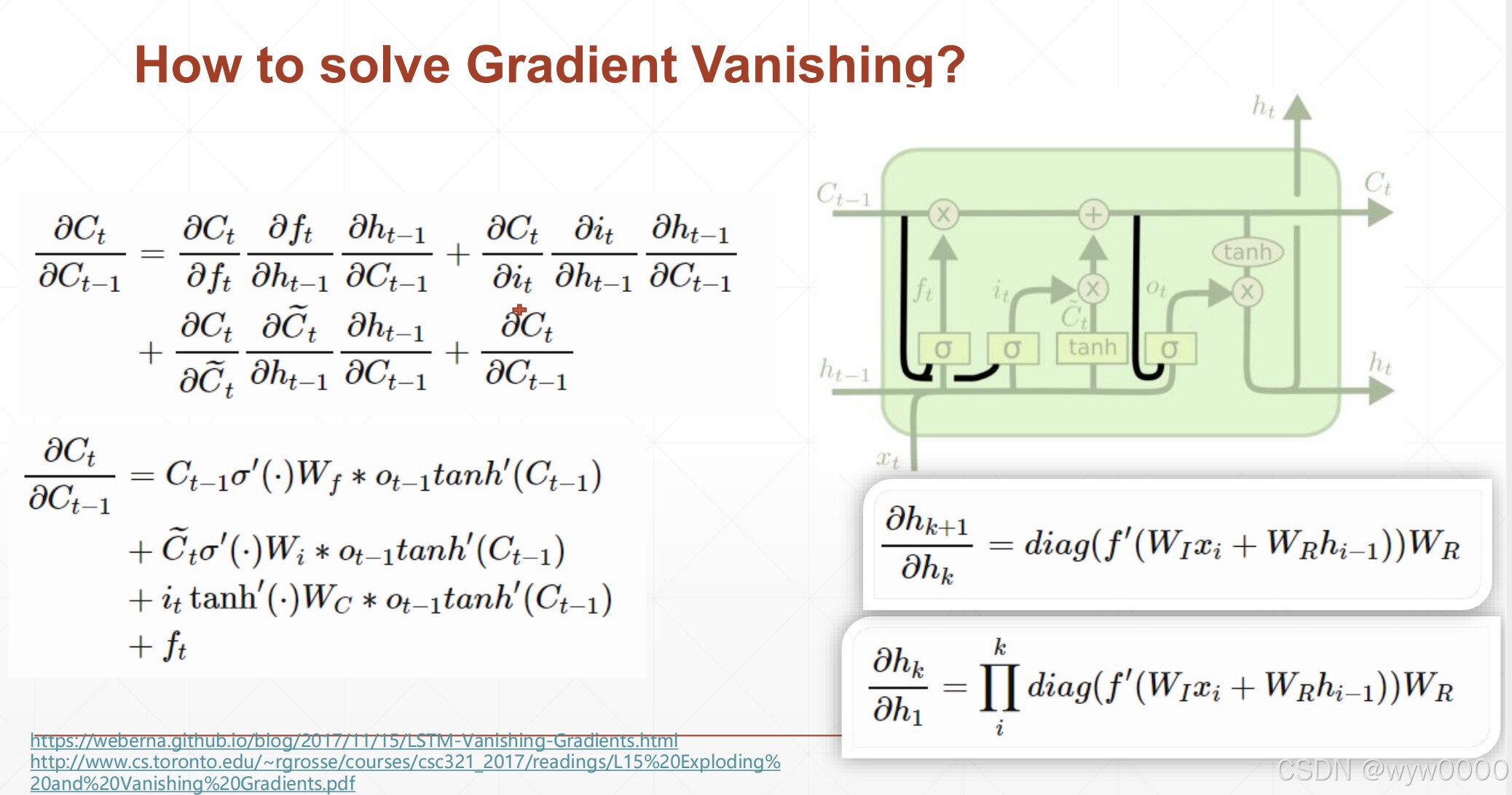
4. LSTM是如何减轻梯度弥散问题
从梯度计算公式可以知道,RNN的梯度中有Whh的累乘,当Whh<1时,就可能出现梯度弥散,而LSTM梯度由几项累加得到,即使W很小也很难出现梯度弥散。