一、K近邻算法
K最近邻(k-Nearest Neighbor,KNN) 分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的。
K 近邻算法使用的模型实际上对应于对特征空间的划分。K 值的选择,距离度量和分类决策规则是该算法的三个基本要素:
1.K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,使预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最优的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
2.该算法中的分类决策规则往往是多数表决,即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别
3.距离度量一般采用 Lp 距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化,这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大。
二、鸢尾花数据
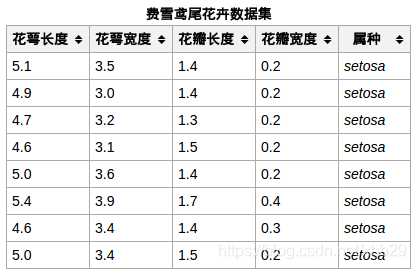
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。
通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
iris的每个样本都包含了品种信息,即目标属性(第5列,也叫target或label)。
样本数据集截图
将样本中的4个特征两两组合(任选2个特征分别作为横轴和纵轴,用不同的颜色标记不