大容量向量相似度TOPK搜索
基本描述: 在图像异常检测应用中,通过特征提取网络提取了大量的特征向量,通过将提取的特征向量与之前存储的不同类别的特征向量集进行相似度比对,寻早到最为相似的前TOPk个向量,然后根据这些topk向量归属的类别将提取的特征向量进行类别划分,以实现整个图像的分类判断,进而实现异常的检测。
解决这一问题的常用的算法
学术话题
这一问题引发了大量的研究,统称为向量检索 。
-
向量检索的定义: 在一个给定向量数据集中,按照某种度量方式,检索出与查询向量相近的k个向量(KNN),但由于KNN计算量过大,通常使用近似近邻问题进行替代。
-
度量方法: 欧式距离、余弦距离、内积、海明距离。 欧式用于图片检索、余弦用于人脸识别、内积用于推荐、海明用于大规模视频检索。
-
评估向量检索效果的几个维度: 召回率、速度、内存损耗。
召回率的计算方法:
给定向量q,其在数据集上的K近邻为N(向量集),通过检索召回的K个近邻集合为M,其中 K=|N| (K等于N的模)。
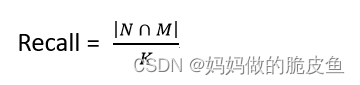
解决向量检索问题的2个切入点
- 减少候选向量集----为了避免在左右候选集上进行计算,引入了索引结构。
- 降低单个向量计算的复杂度-----对向量进行量化处理。
索引结构
- 暴力搜索方法-----召回率100%,内存消耗大、速度慢。
- 基于树结构的方法。速度较慢
- 局部敏感哈希方法–不是适用于所有的度量方法。
- 基于倒排的方法(inverted file structure)
- 基于图的方法–KGraph、NSG、HNSW、NGT等图索引方法。基本检索步骤:step1—选好入口点、step2—遍历图、step3----收敛。
向量量化
定义: 将高纬度的向量映射到低纬度的向量空间上。
- PQ(OPQ、LOPQ)和二值处理。
- 聚类方法(K-means\k-means++、one pass k-means\Yin Yang k-means)
- 内积转换可以直接用于图索引结构。
向量检索方法选择
- 量化图: 基于图的索引结构,同时引入向量量化操作减少处理的向量数据。 特点:速度快,缺点是内存空间消耗较大。
- 图+倒排: 索引结构空间消耗小、且速度和召回率很好的均衡。
Faiss超大矩阵计算框架
几种开源的向量检索开源库或框架
Faiss能够做什么?
- 返回与查询向量最相近的k个检索向量。
- 同时支持多个向量的搜索,速度更快。
- 支持使用精度换取时间和内存空间,以10%的精度损失获取10倍的时间或空间。
- 执行最大内积搜索,而不是最小欧几里得搜索。对其他距离的支持也是有限的,比如L1,Linf。
- 返回查询点半径范围内的所有元素(范围搜索)。
- 存储索引在硬盘上而不是在内存上。(降低了内存需求)
Faiss的核心搜索算法来源
- 内积量化方法(PQ),这是一种高维向量的一种有损压缩技术,它能够实现在压缩的向量中进行相对准确的重建和距离计算。论文地址
- 三级量化方法(IVFADC-R),论文地址
- 优化的内积量化方法(OPQ),此方法可以看作是向量空间的线性变换,使其更适合使用乘积量化器进行索引。论文地址
- 内计量化器的距离预过滤方法。该方法在计算PQ距离之前会先执行一个二进制的滤波处理。论文地址
- GPU实现了更快的k搜索。论文地址
- HNSW索引方法-论文地址
所有内积量化以及相关方法的论文综述地址------内积量化
最新的基于GPU实现的图结构的近似最近邻算法(GGNN)
github源码地址
论文地址:https://arxiv.org/abs/1912.01059
论文提出的相关算法的执行顺序
-
多层图构建过程
-
多层图查询过程
-
源代码中的api的相关参数
相关参数的含义:
// 用于创建距离计算和结果保存模板类的输入数据类型的设置 KeyT = int32_t // 数据索引的类型,这里应该是groudtruth数据中存储的向量类型,其实就是base中的index BaseT = float // 支撑数据集向量元素的数据类型 ValueT = float // 向量之间的距离值类型 BAddrT = uint32_t // 用于访问数据集向量 GAddrT = uint32_t // 用来访问领域向量的地址类型 // 数据集的配置 FLAGS_tau FLAGS_refinement_iterations 表示执行细化操作的迭代次数 D 数据的特征维度384维 measure 表示距离准则需要使用余弦距离,Cosine或Euclidean KBuild 表示构建图时,图中每个节点的邻居数 KF 图中每个节点的最大逆向链接数,其中必须满足: KBuild - KF < S ? S 构件图时将图划分成的子集块数推荐为32 L 构建几层图,推荐为4 KOuery 在查询过程中要检索的最近的邻居的数量,需要具体分析,时间与精度平衡 // 具体的核心代码执行流程及功能 GGNN类模板类<measure, KeyT, ValueT, GAddrT, BaseT, BAddrT, D, KBuild, KF, KQuery, S> GGNN类的初始化:GGNN m_ggnn{FLAGS_base_filename, FLAGS_query_filename, FLAGS_groundtruth_filename, L, static_cast<float>(FLAGS_tau)}; // 传递搜索数据集、查询数据集、真实数据集、图构建松弛参数 GGNN实例对象调用ggnnMain(FLAGS_graph_filename, FLAGS_refinement_iterations)函数构建搜索图,传入图文件和图细化迭代次数 // ggnnMain函数首先判断传递的图文件是否存在,不存在执行构建操作,存在的话判断当前文件是否存在,并导出保存供下次调用 // 执行build函数,主要完成merge操作和对称链路 // 执行图细化操作 // 下面开始执行向量检索操作 // 将查询松弛参数tau_query写入到CUDA中 // 执行m_ggnn.queryLayer<32, 200, 256, 64>()进行分层查询操作,传入的参数表示每层的批次数量 // 获取分层查询的结果数据 // 查询结果分为:明确一点-----输出结果的存储一定在queryLayer中发生。 // 结果保存在GGNNResults结构体实例对象的KeyT* h_sorted_ids_gpu和ValueT* h_sorted_dists_gpu的地址上。其他重要参数:num_result结果数量; 如何存储的呢?? // 结果数据的获取,直接查看ggnn_result.evaluateResults()函数是比较快的方式。 // 查询结果展示: -
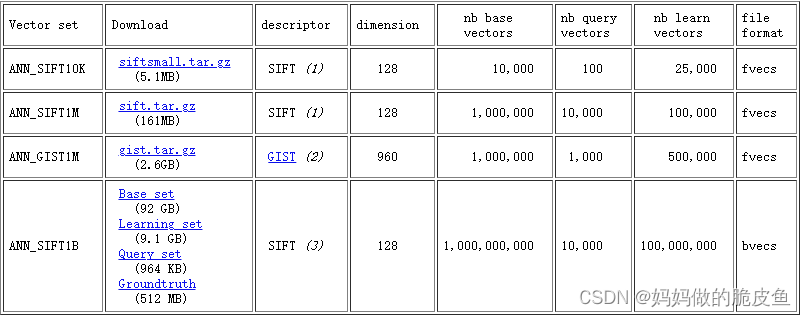
开源数据集SIFTIM格式介绍数据集地址
SIFT共有4个不同大小的数据集。其中ANN_SIFT10K-----ANN_GTST1M中包含4个子数据集,具体的如下图所示:(注意:对于ANN_SIFT1B采用的是.bvecs格式存储)
在下面数据集中: groundtruth.ivecs存储的shape为(10000,100)其中100指的是查询向量中的索引值、sift_query.fvecs的数据shape为:(10000, 128)
-
上面几种数据集格式读取的python代码(注意下面的代码仅仅适用于sift开源数据集):



def fvecs_write(filename, arr): # 保存为浮点数的向量,输入的arr的形式是什么
N, D = arr.shape
with open(filename, 'wb') as fp:
for row in arr:
d = struct.pack('I', D)
fp.write(d)
for x in row:
fp.write(struct.pack('f', float(x)))
def ivecs_write(filename, arr): # 保存为整数型号的向量
N, D = arr.shape
with open(filename, 'wb') as fp:
for row in arr:
d = struct.pack('I', D)
fp.write(d)
for x in row:
fp.write(struct.pack('I', int(x)))
def fvecs_read(filename, c_contiguous=True): # 浮点型向量的读取
fv = np.fromfile(filename, dtype=np.float32)
if fv.size == 0:
return np.zeros(0, 0)
dim = fv.view(np.int32)[0]
assert dim > 0
fv = fv.reshape(-1, 1 + dim)
if not all(fv.view(np.int32)[:, 0] == dim):
raise IOError("Non-uniform vector sizes in " + filename)
fv = fv[:, 1:]
if c_contiguous:
fv = fv.copy()
return fv
# 从文件名称中创建np数据
def ivecs_read(filename, c_contiguous=True):
fv = np.fromfile(filename, dtype=np.int32)
if fv.size == 0:
return np.zeros(0, 0)
dim = fv.view(np.int32)[0] # 更改数据类型为int32,且查看该数组的第一个维度
assert dim > 0
fv = fv.reshape(-1, 1 + dim) #
if not all(fv.view(np.int32)[:, 0] == dim):
raise IOError("Non-uniform vector sizes in " + filename)
fv = fv[:, 1:]
if c_contiguous:
fv = fv.copy()
return fv
# 阅读.bvecs格式的文件
def bvecs_read(filename, c_contiguous=True):
fv = np.fromfile(filename, dtype=np.byte)
if fv.size == 0:
return np.zeros(0, 0)
dim = fv.view(np.int32)[0] # 更改数据类型为int32,且查看该数组的第一个维度
assert dim > 0
fv = fv.reshape(-1, 4+dim) #
if not all(fv.view(np.int32)[:, 0] == dim):
raise IOError("Non-uniform vector sizes in " + filename)
fv = fv[:, 4:]
if c_contiguous:
fv = fv.copy()
return fv
- 使用c++读取fvecs和ivecs格式的数据,以及一些基本的数据操作
// CreatData.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。
//
#include <windows.h>
#include <iostream>
#include <fstream>
#include <vector>
#include <ctime>
#include <algorithm>
#include <string>
#include <cmath>
using namespace std;
/*
@brif 在指定范围内生成随机的数字
*/
float getRand(int min, int max)
{
return (rand() % (max - min + 1)) + min;
}
/*
@ brif: 将单维向量数据保存到.txt文件
@param len 表示向量的总长度
@param dim 表示每个向量的长度
@param over 是否覆盖之前的数据
*/
template<typename T>
void writeTxt(string savePath, T data, size_t len, size_t dim, bool over=false)
{
ofstream f;
if (!over)
{
f.open(savePath, ios::trunc | ios::out);
}
else f.open(savePath, ios::app | ios::out);
int j = 0;
for (j; j < len; j++)
{
if ((j+1) % (dim) == 0) // && j > 0
{
f << *(data+j) << "\n";
}
else f << *(data+j) << ",";
}
f.close();
return;
}
/*
@ brif: 将2维向量数据保存到.txt文件
*/
template<typename T>
void writeTxt2dim(string savePath, vector<vector<T>> data, bool over=true)
{
size_t len = data.size();
for (int i = 0; i < len; i++)
{
writeTxt(savePath, &data[i][0], data[i].size(), data[i].size(), over);
}
return;
}
/*
@brif 只找最好的一个
@param dim = true_dim + 2, 384+2=386,
@param baseNum表示查询向量条数1
@param queryNum基础向量数据的向量条数5
@param baseNum 表示基础向量集的条数
@param dim 表示真实的存储维度
// @param knn 后续再进行修改
*/
vector<vector<float>> ComputerDis(float* query, float* base, int queryNum, int baseNum, int dim)
{
vector<vector<float>> distances;
distances.clear();
if (query == nullptr || base == nullptr)
{
return distances;
}
for (int query_id=0; query_id < queryNum; query_id++)
{
vector<float> temDis;
for (int base_id = 0; base_id < baseNum; base_id++)
{
// 计算两者之间的距离
float* ptrStartQuery = query + query_id * dim; // 记录每个查询向量的起始指针
float* ptrStartBase = base + base_id * dim;
float computerDis = 0;
for (int i = 0; i < dim; i++)
{
if (i > 1)
{
computerDis += (*ptrStartQuery) * (*ptrStartBase); // 不能将0和1索引值加上去
}
ptrStartQuery++;
ptrStartBase++;
}
temDis.push_back(computerDis);
}
distances.push_back(temDis);
}
return distances;
}
/*
@brif 直接获取最佳的匹配向量的索引,以及向量值、距离值。一般是在执行ComputerDis函数之后。
@param distances是查询向量与基础向量之间的距离,
@param baseVector是基础向量,
@param indexBestVector是最佳索引,
@param disBestVector是最佳距离值,
@param BestMatchVector最佳匹配向量,
@param dim: 向量的维度,这里的维度还是真实存储的维度而不是计算时所需的维度。
*/
void findBestMatchVector(vector<vector<float>>& distances, float* baseVector, vector<size_t>& indexBestVector, vector<float>& disBestVector, vector<vector<float>>& BestMatchVector, size_t dim,size_t baseDataNum)
{
size_t numObject = 0;
indexBestVector.clear();
disBestVector.clear();
BestMatchVector.clear();
numObject = distances.size();
for (int i = 0; i < numObject; i++)
{
vector<float>::iterator biggest = max_element(distances[i].begin(), distances[i].end());
disBestVector.push_back(*biggest);
size_t temIndex = std::distance(begin(distances[i]), biggest);
indexBestVector.push_back(temIndex);
// 直接在baseVector中去查询对应的向量值
vector<float> PerBestMatchVector;
PerBestMatchVector.clear();
float* temStartPtr = baseVector + temIndex*dim;
for (int k = 0; k < dim; k++)
{
PerBestMatchVector.emplace_back(*temStartPtr);
temStartPtr += 1;
}
BestMatchVector.push_back(PerBestMatchVector);
}
return;
}
/*
@brif 直接获取最佳KNN个的匹配向量的索引,以及向量值、距离值。一般是在执行ComputerDis函数之后。
@param distances是查询向量与基础向量之间的距离,
@param baseVector是支撑向量集合,2+384dim
@param indexBestKnnVector是最佳索引,
@param disBestKnnVector是最佳距离值,
@param typeBestKnnVector是最佳类别向量
@param dim: 向量的维度,这里的维度还是真实存储的维度而不是计算时所需的维度。
@param Knn: 表示检索前k个相邻的向量, 在进行数据标注的时候是100.
@return: 返回每个查询向量的前Knn个最佳匹配的index、dis、type向量
*/
void findKnnBestMatchVector(vector<vector<float>>& distances, float* baseVector, vector<vector<int>>& IdBestKnnVector, vector<vector<int>>& indexBestKnnVector, vector<vector<float>>& disBestKnnVector, vector<vector<int>>&typeBestKnnVector, size_t dim, int Knn)
{
size_t numObject = 0;
IdBestKnnVector.clear();
disBestKnnVector.clear();
typeBestKnnVector.clear();
indexBestKnnVector.clear();
numObject = distances.size(); // 该numObject表示的是查询向量的长度,distances[i].size()表示支撑向量集的长度
for (int i = 0; i < numObject; i++)
{
vector<float> temDis(distances[i]);
// 从大到小进行排序
sort(temDis.begin(), temDis.end());
reverse(temDis.begin(), temDis.end());
if (temDis.size() < Knn)
{
cout << "查询的K近邻数量超过了基础数据集的数量" << endl;
return;
}
vector<int> indexTem;
vector<float> disTem;
vector<int> typeTem;
vector<int> IdTem;
// 逐步取出前KNN个值
for (int j = 0; j < Knn; j++)
{
float value = temDis[j];
vector<float>::iterator itr = find(distances[i].begin(), distances[i].end(),value);
int index = distance(distances[i].begin(), itr);
disTem.push_back(value); // 获取的是距离值进行保存
indexTem.push_back(index); // 获取index进行保存
IdTem.push_back((int)*(baseVector + index * dim)); // 获取的是真实的id编号,但是这样直接取值会存在问题
typeTem.push_back((int)*(baseVector + index * dim + 1)); // 根据索引获取所属类别
// cout <<"类别归属: .................." << (int)*(baseVector + index * dim + 1) << endl;
}
IdBestKnnVector.push_back(IdTem);
indexBestKnnVector.push_back(indexTem);
disBestKnnVector.push_back(disTem);
typeBestKnnVector.push_back(typeTem);
}
return;
}
/*
@brif 将生成的数据保存为适用于ggnn的基本数据格式, 注意fvecs的基本格式是dim + vectors = 4 + dim * 4
@filename 表示存储的地址
@vectorData 表示存储向量的指针地址
@vectorNum 表示向量集的数据条数
@dim 表示单个向量的维度,比实际的数据长1
*/
void SaveToGgnn(const char* filename,float* vectorData, size_t vectorNum, size_t dim)
{
float* GgnnVectorData = new float[vectorNum*(dim-1)]; // 注意这里的dim-1是因为,Anomaly中的数据比ggnn维度多一个
for (int i = 0; i < vectorNum; i++)
{
int j=0, k = 0;
float* temStartPtr = vectorData + i * dim;
for (j, k; k < dim; k++, temStartPtr+=1)
{
if (k == 0)
{
GgnnVectorData[i*(dim - 1) + j] = dim - 1; // 每一个向量的起始位存储的是向量的维度,385dim
j++;
}
else if (k == 1);
else
{
GgnnVectorData[i*(dim - 1) + j] = *temStartPtr;
j++;
}
}
}
ofstream writeFile;
// 必须保证filename以.fvecs结尾
writeFile.open(filename, ios_base::binary | ios_base::out | ios_base::trunc);
//ofstream writeFile(filename, ios_base::binary|ios_base::out|ios_base::trunc);
if (!writeFile.is_open())
{
cout << "................打开文件失败................." << endl;
return;
}
writeFile.write(reinterpret_cast<char*>(GgnnVectorData), sizeof(float)*vectorNum*(dim-1));
writeFile.close();
delete[] GgnnVectorData;
}
/*
@brif 读取存储的.fvecs数据,并将数据转换为txt文档中
@filename ggnn数据集的文件路径
@data 读取的数据保存地址
@num 向量条数保存地址
@dim 向量维度保存地址
*/
void ReadGgnnToTxt(char* filename, float*& data, unsigned& num, unsigned& dim)
{
std::ifstream in(filename, std::ios::binary); //以二进制的方式打开文件
if (!in.is_open()) {
std::cout << "open file error" << std::endl;
exit(-1);
}
in.read((char*)&dim, 4); //读取向量维度
in.seekg(0, std::ios::end); //光标定位到文件末尾
std::ios::pos_type ss = in.tellg(); //获取文件大小(多少字节)
size_t fsize = (size_t)ss;
num = (unsigned)(fsize / (dim + 1) / 4); //数据的个数
data = new float[(size_t)num * (size_t)dim];
in.seekg(0, std::ios::beg); //光标定位到起始处
for (size_t i = 0; i < num; i++) {
in.seekg(4, std::ios::cur); //光标向右移动4个字节
in.read((char*)(data + i * dim), dim * 4); //读取数据到一维数据data中
}
for (size_t i = 0; i < num * dim; i++) { //输出数据
std::cout << (float)data[i];
if (!i) {
std::cout << " ";
continue;
}
if (i % (dim - 1) != 0) {
std::cout << " ";
}
else {
std::cout << std::endl;
}
}
in.close();
}
/*
brif 用于自动生成支撑和检索向量数据集
@param storeDataPtr 表示存储生成数据集的指针
@param ReadDim 表示真实的维度(384+2):dim + composion
@param RealNum 表示生成向量的数量
*/
void GeneratorTestData(float* storeDataPtr, size_t ReadDim, size_t RealNum)
{
for (int i = 0; i < ReadDim * RealNum; i++)
{
if (i % ReadDim == 0)
{
storeDataPtr[i] = i / (int)ReadDim;
}
else if (i % ReadDim == 1)
{
storeDataPtr[i] = 1;
}
else storeDataPtr[i] = getRand(0.1, 100);
}
double temsum = 0;
for (int i = 0; i < ReadDim * RealNum; i++)
{
if (i % ReadDim != 0 && i % ReadDim != 1)
{
temsum += storeDataPtr[i] * storeDataPtr[i];
}
}
temsum = sqrtf(temsum);
for (int i = 0; i < ReadDim * RealNum; i++)
{
if (i % ReadDim != 0 && i % ReadDim != 1)
{
storeDataPtr[i] = storeDataPtr[i] / temsum;
}
}
return;
}
/*
brif 用于保存生成的数据为Anomaly格式的二进制文件
@param saveFile 表示保存的二进制文件地址
@param DataNum 表示所有数据的条数
@param Realdim 表示实际存储过程的向量实际维度(384+2)
@param generateData 传入的存储数据的指针
*/
void SaveDataToAnomaly(const char* saveFile, size_t DataNum, size_t Realdim, float* generateData)
{
std::FILE *fp;
fopen_s(&fp, saveFile,"wb");
int m_featureN = DataNum;
int m_featureC = Realdim-2;
fwrite(&m_featureN, sizeof(int), 1, fp);
fwrite(&m_featureC, sizeof(int), 1, fp);
fwrite(generateData, sizeof(float), Realdim * DataNum, fp);
fclose(fp);
return;
}
/*
brif: 用于计算向量检索的正确率,可以实现一对一的检测,多对一,多对多,一对多
@Anomaly检测结果.txt
@GenerateLaw真实的最近邻索引.txt
@Mutile1 anomalyDetecteID对应的数据是否为单列
@lawID anomalyDetecteID对应的数据是否为单列
*/
float ComputerAccuracyOneToOne(const char* anomalyDetecteID, const char* lawID, bool Mutile1=false, bool Mutile2=false)
{
vector<size_t> anomalyIds;
vector<size_t> lawIds;
ifstream aIdfile(anomalyDetecteID);
ifstream lawIdfile(lawID);
string line;
if (aIdfile)
{
while (getline(aIdfile,line))
{
string TemValue = "";
if (Mutile1)
{
size_t index = line.find(",");
TemValue = line.substr(0,index);
}
else TemValue = line;
int temValue = atoi(TemValue.c_str());
anomalyIds.emplace_back(temValue);
}
}
aIdfile.close();
if (lawIdfile)
{
while (getline(lawIdfile, line))
{
string TemValue1 = "";
if (Mutile2)
{
size_t index = line.find(",");
TemValue1 = line.substr(0, index);
}
else TemValue1 = line;
int temValue1 = atoi(TemValue1.c_str());
lawIds.emplace_back(temValue1);
}
}
lawIdfile.close();
cout << "Anamaly检测: " << anomalyIds.size() << "标注的数据的数量: " << lawIds.size();
if (anomalyIds.size()!= lawIds.size())
{
cout << "数据有误" << endl;
return 0;
}
size_t equalNum = 0;
for (int i = 0; i< anomalyIds.size(); i++)
{
if(anomalyIds[i] == lawIds[i]) equalNum += 1;
}
return (equalNum / (float)anomalyIds.size());
}
/*
brif: 查看base.db数据集的结构,并转换为.txt文件进行保存
@baseDbPath 是存储base的.db路劲
@saveTxtPath 是存储base的.txt路劲
@saveTotxt 表示是否需要将读取的数据保存到txt中
@buf 用于缓存读取的数据
@m_Num 表示数据的条数
@m_Dim 表示数据的维度
@composion 表示数据实际存储的维度比m_Dim多几个数,默认为2
*/
float* ReadDB(const char* baseDbPath, const char* saveTxtPath, bool saveTotxt, int&m_Num, int&m_Dim, int composion=2)
{
std::FILE *fp;
fopen_s(&fp, baseDbPath, "rb+");
std::fread(&m_Num, sizeof(int), 1, fp);
std::fread(&m_Dim, sizeof(int), 1, fp);
//int num = -1;
//std::fread(&m_Dim, sizeof(int), 1, fp);
size_t m_Size = m_Num * m_Dim * sizeof(float);
if (0 == m_Size)
{
m_Num = m_Dim = 0;
fclose(fp);
return nullptr;
}
// float temValue = 0;
float* buf = new float[m_Num * (m_Dim + composion)];
std::fread(buf, sizeof(float), m_Num * (m_Dim + composion), fp);
fclose(fp);
if (saveTotxt)
{
ofstream f;
f.open(saveTxtPath, ios::trunc | ios::out);
for (int j = 0; j < m_Num; j++)
{
for (int k = 0; k < m_Dim + composion; k++)
{
if (k == m_Dim + (composion-1)) f << buf[j * (m_Dim + composion) + k] << "\n";
else f << buf[j * (m_Dim + composion) + k] << ",";
}
}
f.close();
}
return buf;
}
/*
brif: 用于读取.db数据集,可选择是否转换为.txt文件。注意使用后需要释放指针, 这里相对于上面的函数做了些许调整。
*/
float* ReadDBOpt(const char* baseDbPath, const char* saveTxtPath, bool saveTotxt, int&m_Num, int&m_Dim, int composion = 2)
{
std::FILE *fp;
std::fstream db_file(baseDbPath, std::ios::in | std::ios::binary);
db_file.read((char*)&m_Num, sizeof(int));
db_file.read((char*)&m_Dim, sizeof(int));
size_t m_Size = m_Num * m_Dim * sizeof(float);
if (0 == m_Size)
{
m_Num = m_Dim = 0;
db_file.close();
return nullptr;
}
float* buf = new float[m_Num * (m_Dim + composion)];
memset(buf, 0x00, m_Num * (m_Dim + composion)*sizeof(float));
int *L = new int[386];
memset(L, 0x00, 386 * sizeof(int));
int id, type;
for (int i = 0; i < m_Num; i++)
{
db_file.read((char*)L, 386 * sizeof(int));
id = L[0];
type = L[1];
buf[i*(m_Dim + composion)] = (float)id;
buf[i*(m_Dim + composion)+1] = (float)type;
for (int j = 0; j < 384; j++)
{
buf[i*(m_Dim + composion) + j + 2] = ((float*)L + 2)[j];
}
}
db_file.close();
delete[] L;
if (saveTotxt)
{
ofstream f;
f.open(saveTxtPath, ios::trunc | ios::out);
for (int j = 0; j < m_Num; j++)
{
for (int k = 0; k < m_Dim + composion; k++)
{
if (k == m_Dim + (composion - 1)) f << buf[j * (m_Dim + composion) + k] << "\n";
else f << buf[j * (m_Dim + composion) + k] << ",";
}
}
f.close();
}
return buf;
}
int main()
{
int funId = 5;
/*
brif: 用于对比Anomaly检索结果与查询向量真实的最接近向量索引进行对比,获得anomaly检索精度。
*/
if (funId == 0)
{
string anomalyDetecteID = "D:\\GenerateData\\GenerateDataLaw\\bestMatchIndex.txt";
string lawID = "D:\\GenerateData\\AnomalyGenerateData\\AnomalyBestIndex_id.txt";
float accuracyResult = ComputerAccuracyOneToOne(anomalyDetecteID.c_str(), lawID.c_str());
cout << "................计算的准确率为: " << accuracyResult << "....................." << endl;
}
/*
brif: 查看Base.DB数据集的结构,并保存到"C:\\Users\\admin\\Desktop\\CompareTest\\BaseData\\test.txt"中
base.db: "C:\\Users\\admin\\Desktop\\CompareTest\\BaseData\\test.db"
*/
else if (funId == 1)
{
int m_Num = 0, m_Dim = 0;
float* tembuff = nullptr;
std::string baseDbPath = "C:\\Users\\admin\\Desktop\\CompareTest\\BaseData\\1516_up.db";
std::string saveTxtPath = "C:\\Users\\admin\\Desktop\\CompareTest\\BaseData\\test.txt";
tembuff = ReadDBOpt(baseDbPath.c_str(), saveTxtPath.c_str(), true, m_Num, m_Dim);
delete tembuff;
tembuff = nullptr;
//ReadDB();
}
/*
brif: 标注提取的全图特征,获得2张图全部特征对应与base特征中真实的id序号、类别号、距离值,直接保存前40个最相近的数据值.............................ok。
@step1: 加载whole.db数据以及base.db到内存
@step2: 使用暴力搜索算法计算出whole中每个向量与base.db中全部向量之间的距离。并选出前40个与base最相似的向量索引以及距离值。
@保存的数据简介: groudtrue_id(389376, 100(int)); groudtrue_dis(389376, 100(float)), groudtrue_type(389376, 100(type类型));
*/
else if (funId == 2)
{
// step1: 加载全图db和Base.db数据集
std::string baseDbPath = "C://Users//admin//Desktop//CompareTest//wholeFeatures//base1.db"; // "C:\\Users\\admin\\Desktop\\CompareTest\\BaseData\\4242_up.db";
std::string wholeDbPath = "C://Users//admin//Desktop//CompareTest//wholeFeatures//Whole12.db"; // "C://Users//admin//Desktop//CompareTest//wholeFeatures//Whole1_up.db";
/*std::string baseDbPath = "C://Users//admin//Desktop//CompareTest//wholeFeatures//base1.db";
std::string wholeDbPath = "C://Users//admin//Desktop//CompareTest//wholeFeatures//Whole12.db";*/
int m_NumBase = 0, m_DimBase = 0, m_NumWhole = 0, m_DimWhole = 0;
float* Base = ReadDBOpt(baseDbPath.c_str(), NULL, false, m_NumBase, m_DimBase);
float* Whole = ReadDBOpt(wholeDbPath.c_str(), NULL, false, m_NumWhole, m_DimWhole);
// step2:计算whole向量与base向量之间的距离(考虑使用opencv的CUDA变成提速)
vector<vector<float>> WholeAndBaseDistance;
WholeAndBaseDistance = ComputerDis(Whole, Base, m_NumWhole, m_NumBase, m_DimBase + 2);
if (WholeAndBaseDistance.size() == 0)
{
return 0;
}
delete[] Whole; Whole = nullptr;
// step3: 算出每个查询向量最佳匹配值的前100个dis以及对应的索引值.需要将数据进行保存
vector<vector<int>> groudTrue_id;
vector<vector<int>> groudTrue_Index;
vector<vector<float>> groudTrue_dis;
vector<vector<int>> groudTrue_type;
// 直接获取前100个最近邻的数据,包括index\id\type\distance
int Knn = 100;
findKnnBestMatchVector(WholeAndBaseDistance, Base, groudTrue_id, groudTrue_Index, groudTrue_dis, groudTrue_type, m_DimBase + 2, Knn);
cout << "类别id的长度: " << groudTrue_type.size() << "Knn: " << groudTrue_type[0].size() << groudTrue_type[0][0];
delete[] Base; Base = nullptr;
// 将所得结果保存到.txt文件;
string trueIdTxtPath = "C:\\Users\\admin\\Desktop\\CompareTest\\MarkingGlobalFeatures\\trueIdMark.txt"; // (389376, 100) 保存id
string trueIdexTxtPath = "C:\\Users\\admin\\Desktop\\CompareTest\\MarkingGlobalFeatures\\trueIndexMark.txt"; // (389376, 100) 保存index
string trueDisTxtPath = "C:\\Users\\admin\\Desktop\\CompareTest\\MarkingGlobalFeatures\\trueDiMark.txt"; // (389376, 100) 保存距离
string trueTypeTxtPath = "C:\\Users\\admin\\Desktop\\CompareTest\\MarkingGlobalFeatures\\trueTypeMark.txt"; // (389376, 100) 保存类别
writeTxt2dim(trueIdTxtPath, groudTrue_id, true);
writeTxt2dim(trueIdexTxtPath, groudTrue_Index, true);
writeTxt2dim(trueTypeTxtPath, groudTrue_type, true);
writeTxt2dim(trueDisTxtPath, groudTrue_dis, true);
groudTrue_dis.clear();
groudTrue_type.clear();
groudTrue_id.clear();
// 将knn的索引进行保存,主要是前100个
auto add = [](vector<vector<int>>& idVector, const char* dbPath, int Knn)
{
std::FILE *fp;
fopen_s(&fp, dbPath, "wb");
int m_featureDim = Knn;
for (int i = 0; i < idVector.size(); i++)
{
fwrite(&Knn, sizeof(int), 1, fp);
fwrite(&idVector[i][0], sizeof(int), idVector[i].size(), fp);
}
fclose(fp);
return;
};
string groudTrueIndexIvecs = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNBaseData\\GroundTruthBig.ivecs";
add(groudTrue_Index, groudTrueIndexIvecs.c_str(), Knn);
groudTrue_Index.clear();
}
/*
brif: 将whole和base数据集转换为适用于GGNN数据的输出数据。........................................................ok
*/
else if (funId == 3)
{
string queryWholeFvecs = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNBaseData\\Query.fvecs";
string BaseFvecs = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNBaseData\\Base.fvecs";
// 读取数据Whole和Base数据集到vector
int m_Num_base = 0, m_Dim_base = 0;
int m_Num_query = 0, m_Dim_query = 0;
std::string baseDbPath = "C://Users//admin//Desktop//CompareTest//wholeFeatures//base1.db";
std::string wholeDbPath = "C://Users//admin//Desktop//CompareTest//wholeFeatures//Whole12.db";
std::string baseTxt = "C:\\Users\\admin\\Desktop\\CompareTest\\BaseData\\base1.txt";
std::string wholeTxt = "C://Users//admin//Desktop//CompareTest//wholeFeatures//Whole12.txt";
float* BaseDataPtr = ReadDBOpt(baseDbPath.c_str(), baseTxt.c_str(), true, m_Num_base, m_Dim_base);
float* QueryDataPtr = ReadDBOpt(wholeDbPath.c_str(), wholeTxt.c_str(), true, m_Num_query, m_Dim_query);
auto add = [](const char*savePath, float* idVector, int num, int dim)
{
std::FILE *fp;
fopen_s(&fp, savePath, "wb");
float* temPtr = nullptr;
for (int i = 0; i < num; i++)
{
temPtr = idVector + i * (dim + 2) + 2;
fwrite(&dim, sizeof(int), 1, fp);
fwrite(temPtr, sizeof(float), dim, fp);
if (i == 0) // 用于查看query和base数据集都是进行了归一化处理
{
for (int j = 0; j < 40; j++)
{
cout << *(temPtr + j) << ",";
}
cout << endl << endl;
}
}
fclose(fp);
return;
};
add(BaseFvecs.c_str(), BaseDataPtr, m_Num_base, m_Dim_base);
add(queryWholeFvecs.c_str(), QueryDataPtr, m_Num_query, m_Dim_query);
delete[] BaseDataPtr;
delete[] QueryDataPtr;
}
/*
brif: 查看ivecs以及fvecs数据集
*/
else if (funId == 4)
{
int m_Num = 4006, m_Dim = 385;
float* tembuff = nullptr;
std::string baseDbPath = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNBaseData\\WholeQuery.fvecs";
std::string saveTxtPath = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNBaseData\\GroundTruth.txt";
std::FILE *fp;
fopen_s(&fp, baseDbPath.c_str(), "rb");
int Dim = 0;
tembuff = new float[m_Num * (m_Dim + 1)];
for (int i = 0; i < m_Num * (m_Dim + 1); i++)
{
std::fread(&Dim, sizeof(uint32_t), 1, fp);
tembuff[i] = Dim;
}
fclose(fp);
ofstream f;
f.open(saveTxtPath, ios::trunc | ios::out);
for (int j = 0; j < m_Num; j++)
{
for (int k = 0; k < (m_Dim + 1); k++)
{
if (k == m_Dim) f << tembuff[j * (m_Dim + 1) + k] << "\n";
else f << tembuff[j * (m_Dim + 1) + k] << ",";
}
}
f.close();
delete[] tembuff;
tembuff = nullptr;
}
/*
brif: 统计Anomaly和GGNN的 index检索正确率以及分类正确率
*/
else if(funId == 5)
{
string AnomalyIndex = "C:\\Users\\admin\\Desktop\\CompareTest\\AnomalyResult\\AnomalyBestIndex_id.txt";
string MarkingIndex = "C:\\Users\\admin\\Desktop\\CompareTest\\MarkingGlobalFeatures\\trueIndexMark.txt";
string GGNNIndex = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNresult\\GgnnBeseKnnIndex.txt";
string AnomalyType = "C:\\Users\\admin\\Desktop\\CompareTest\\AnomalyResult\\AnomalyBestType.txt";
string MarkingType = "C:\\Users\\admin\\Desktop\\CompareTest\\MarkingGlobalFeatures\\trueTypeMark.txt";
string GGNNType = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNresult\\GGnnBestType.txt";
// index准确率
float accuaracyIndex1 = ComputerAccuracyOneToOne(AnomalyIndex.c_str(), MarkingIndex.c_str(), false, true);
float accuaracyIndex2 = ComputerAccuracyOneToOne(GGNNIndex.c_str(), MarkingIndex.c_str(), true, true);
// 分类准确率
//float accuaracyIndex3 = ComputerAccuracyOneToOne(AnomalyType.c_str(), MarkingType.c_str(), false, true);
//float accuaracyIndex4 = ComputerAccuracyOneToOne(GGNNType.c_str(), MarkingType.c_str(), false, true);
cout << "Anomaly检索准确率: " << accuaracyIndex1 << " GGNN检索准确率: " << accuaracyIndex2 << endl;
//cout << "Anomaly分类准确率: " << accuaracyIndex3 << " GGNN分类准确率: " << accuaracyIndex4 << endl;
}
/*
brif: 更具Anomaly检测的数据去查询对应的id和类别信息
*/
else if (funId == 6)
{
// 读取Base数据集
string BaseData = "C:\\Users\\admin\\Desktop\\CompareTest\\BaseData\\4242_up.db";
int m_Num_base = 0, m_Dim_base = 0;
float* BaseDataPtr = ReadDBOpt(BaseData.c_str(), "", false, m_Num_base, m_Dim_base);
// 读取anomaly的检索结果.txt数据去获取id和type
vector<size_t> anomalyIndexs;
string AnomalyTxt = "C:\\Users\\admin\\Desktop\\CompareTest\\GGNNresult\\GgnnBeseKnnIndex.txt";
ifstream lawIdfile(AnomalyTxt.c_str());
string line;
if (lawIdfile)
{
while (getline(lawIdfile, line))
{
int temValue = atoi(line.substr(0, line.find(",")).c_str());
anomalyIndexs.emplace_back(temValue);
}
}
lawIdfile.close();
vector<size_t> anomalyIds;
vector<size_t> anomalyTypes;
for (int i = 0; i < m_Num_base; i++)
{
anomalyIds.push_back(*(BaseDataPtr + i*(m_Dim_base+2)));
anomalyTypes.push_back(*(BaseDataPtr + i * (m_Dim_base + 2)+1));
}
delete[] BaseDataPtr;
BaseDataPtr = nullptr;
// 将数据写入到指定文件txt
ofstream index, type;
// //"C:\\Users\\admin\\Desktop\\CompareTest\\GGNNresult\\GgnnBeseKnnIndex.txt"
index.open("C:\\Users\\admin\\Desktop\\CompareTest\\GGNNresult\\GGnnBestId.txt", ios::trunc | ios::in | ios::out);
type.open("C:\\Users\\admin\\Desktop\\CompareTest\\GGNNresult\\GGnnBestType.txt", ios::trunc | ios::in | ios::out);
for (int i = 0; i < anomalyIds.size(); ++i)
{
if (i< anomalyIds.size()-1)
{
index << anomalyIds[i] << "\n";
type << anomalyTypes[i] << "\n";
}
else
{
index << anomalyIds[i];
type << anomalyTypes[i];
}
}
index.close();
type.close();
}
/*
brif: 使用随机生成函数,生成适用于Anomaly和GGNN测试的数据集,
并保存为.txt文件和.db文件以及.fvecs文件。包括标注文件
*/
else if (funId == 7)
{
/*
step1: 生成自定义的anomaly数据集
@dim: 表示向量真实数据的维度
@composion 表示idx和type所占用的位置数
@queryNum 表示查询向量的条数
@baseNum 表示支撑向量的条数
@baseData 存储支撑向量数据指针
@queryData 存储查询向量指针
*/
srand(time(0));
size_t dim = 384;
int composion = 2;
size_t queryNum = 16384; // 389376;
size_t baseNum = 250000; //
float* baseData = new float[(dim + composion) * baseNum];
float* queryData = new float[(dim + composion) * queryNum];
/*
step2: 下面是用于生成支撑向量数据集,并对数据进行归一化处理
*/
GeneratorTestData(baseData, dim + composion, baseNum);
/*
step3: 生成检索数据集,并进行归一化处理
*/
GeneratorTestData(queryData, dim + composion, queryNum);
/*
step4: 将上面生成的baseData和queryData数据保存为txt文件
@ "D:\\NewAnomaly\\buildTestData\\CreatData\\base.txt" 存储支撑数据集
@ "D:\\NewAnomaly\\buildTestData\\CreatData\\query.txt" 存储查询数据集
*/
/*writeTxt("D:\\GenerateData\\GenerateDataLaw\\Aomalybase.txt", baseData, (dim + composion) * baseNum, (dim + composion));
writeTxt("D:\\GenerateData\\GenerateDataLaw\\Anomalyquery.txt", queryData, (dim + composion)* queryNum, (dim + composion));*/
/*
step5: 将生成的DB数据保存到指定的二进制文件中
@param baseDb 表示基础数据集
@param queryDb 表示查询数据集
*/
std::string baseDb = "D:\\GenerateData\\GenerateDataLaw\\AnomalyBaseDB.db";
std::string queryDb = "D:\\GenerateData\\GenerateDataLaw\\AnomalyQueryDB.db";
SaveDataToAnomaly(baseDb.c_str(), baseNum, dim+ composion, baseData);
SaveDataToAnomaly(queryDb.c_str(), queryNum, dim + composion, queryData);
/*
step6: 将生成的数据转换为GGNN项目需要的数据格式
@1: 使用ComputerDis函数计算查询向量到支撑集向量之间的距离
@2: findBestMatchVector将@1中的计算结果用于获取每一个查询向量与支撑集向量最近似的向量之间的距离、索引值、真实的向量数据
@3: 将检索的结果保存到二进制文件以及txt文件中
@param baseVector 是生成的支撑向量集
@param indexBestVector 存储查询向量对应的最佳索引
@param disBestVector 存储查询向量对应最佳向量的距离
@param BestMatchVector 存储查询向量最佳匹配向量
*/
/*vector<vector<float>> AllDisQueryAndBase;
AllDisQueryAndBase = ComputerDis(queryData, baseData, queryNum, baseNum, dim + composion);*/
// vector<float> baseVector;
/*vector<size_t> indexBestVector;
vector<float> disBestVector;
vector<vector<float>> BestMatchVectorValue;
findBestMatchVector(AllDisQueryAndBase, baseData, indexBestVector, disBestVector, BestMatchVectorValue, dim + composion, baseNum);*/
/*
brif: 相当于获取到了查询向量的grundTrue数据
@1 BestMatchIndex 存储索引
@2 BestMatchDistance 存储最佳向量的距离
@3 BestMatchVector 存储最佳向量
*/
std::string BestMatchIndex = "D:\\GenerateData\\GenerateDataLaw\\bestMatchIndex.txt";
std::string BestMatchDistance = "D:\\GenerateData\\GenerateDataLaw\\bestMatchDis.txt";
std::string BestMatchVector = "D:\\GenerateData\\GenerateDataLaw\\bestMatchVector.txt";
writeTxt(BestMatchIndex, &indexBestVector[0], queryNum, 1);
writeTxt(BestMatchDistance, &disBestVector[0], queryNum, 1);
writeTxt2dim(BestMatchVector, BestMatchVectorValue);
/*
@1 再将生成的数据存储为适合GGNN输入的数据格式
*/
std::string GGnnQueryPath = "D:\\GenerateData\\GenerateDataLaw\\GGNNQuery.fvecs";
std::string GGnnBasePath = "D:\\GenerateData\\GenerateDataLaw\\GGNNBase.fvecs";
SaveToGgnn(GGnnQueryPath.c_str(), queryData, queryNum, dim + composion);
SaveToGgnn(GGnnBasePath.c_str(), baseData, baseNum, dim + composion);
/*
释放内存
*/
delete[] baseData; baseData = nullptr;
delete[] queryData; queryData = nullptr;
}
}