前言
Xorbits Inference(Xinference)是一个功能强大、用途广泛的库,旨在为语言、语音识别和多模态模型提供服务。借助Xorbits Inference,您只需使用一个命令即可轻松部署和维护您的或最先进的内置模型。无论您是研究人员、开发人员还是数据科学家,Xorbits Inference都能让您充分发挥尖端人工智能模型的潜力。
主要特点:
简化模型服务:简化服务大型语言、语音识别和多模态模型的过程。您可以使用单个命令设置和部署用于实验和生产的模型。
⚡️ 最先进的模型:使用单个命令尝试尖端的内置模型。推理提供了对最先进的开源模型的访问!
🖥 异构硬件利用率:使用ggml充分利用您的硬件资源。Xorbits推理智能地利用异构硬件,包括GPU和CPU,来加速您的模型推理任务。
⚙️ 灵活的API和接口:提供多个与模型交互的接口,支持OpenAI兼容的RESTful API(包括函数调用API)、RPC、CLI和WebUI,实现无缝的模型管理和交互。
🌐 分布式部署:在分布式部署场景中使用Excel,允许在多个设备或机器之间无缝分布模型推理。
🔌 与第三方库的内置集成:Xorbits Inference与流行的第三方库无缝集成,包括LangChain、LlamaIdex、Dify和Chatbox。
一、平台环境准备
卡选择:MLU370系列
驱动选择:5.10.29以上
镜像选择:SDK版本>v24.0 pytorch >= 2.1
本次操作镜像如下:
cambricon_pytorch_container:v24.09-torch2.4.0-catch1.22.2-ubuntu22.04-py310
二、代码下载
git clone https://github.com/xorbitsai/inference
三、安装部署
提示:在这里我们回顾一下之前的章节,在章节中我们提到新版的pytorch镜像只需要使用2行代码就能运行,但是在这里我们不推荐这个方法!!!因为inference是一个部署得工具包我们需要直接通过命令行进行启动,所以我们这边采取转换的方法
#转mlu
python /torch/src/torch_mlu/tools/torch_gpu2mlu/torch_gpu2mlu.py -i ./inference/
会在同级目录下生成一个inference_mlu得文件
那么这里问到了,什么时候适合用下面两行代码呢?
import torch_mlu
from torch_mlu.utils.model_transfer import transfer
这两行代码适合我们在运行python文件的时候加在头文件处,如果像inference以及下一章节的langchain-chatchat新版本,建议先转换在做操作哦!
回归正题,我们继续!!!
1.正常pip 安装
pip install gradio==4.42.0
pip install -e ./inference_mlu/
四、运行结果展示
运行命令:
xinference-local
会生成一个端口直接点击就会有个UI界面,如果你报错了请往下看
1.如果界面404或没有东西请这样做
我们提供两种修复方法:
#1先卸载重装
pip uninstall xinference
pip install -e ./inference_mlu/
#2启动
xinference-local
#若上述方法不行,且/inference_mlu/xinference/web/ui目录下不生成有内容的build和node_modules的前端文件夹,则在/web/ui目录下使用手动命令生成
apt install npm
npm install
npm run build
#此时仍有可能构建项目失败,提示缺失react-scripts,需要运行下面的命令安装
npm install react-scripts
#重新启动即可,注意使用vscode远程ssh连接,直接在平台网页运行不可以
#webui界面如下
2.运行效果
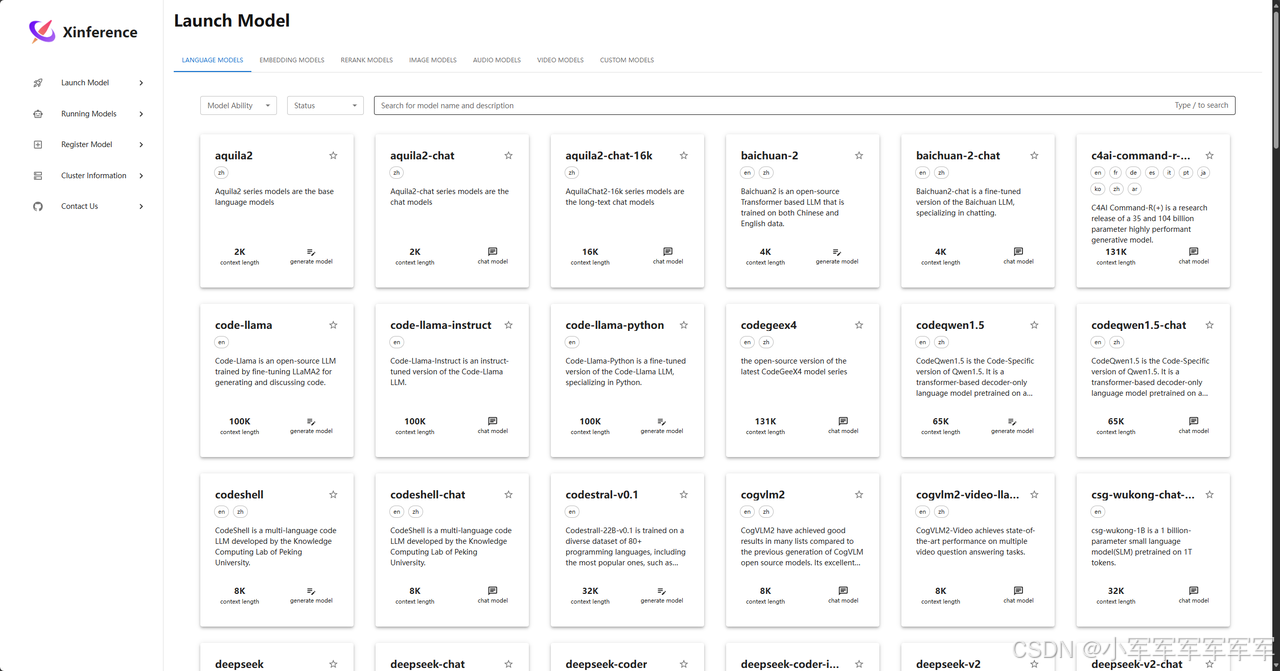
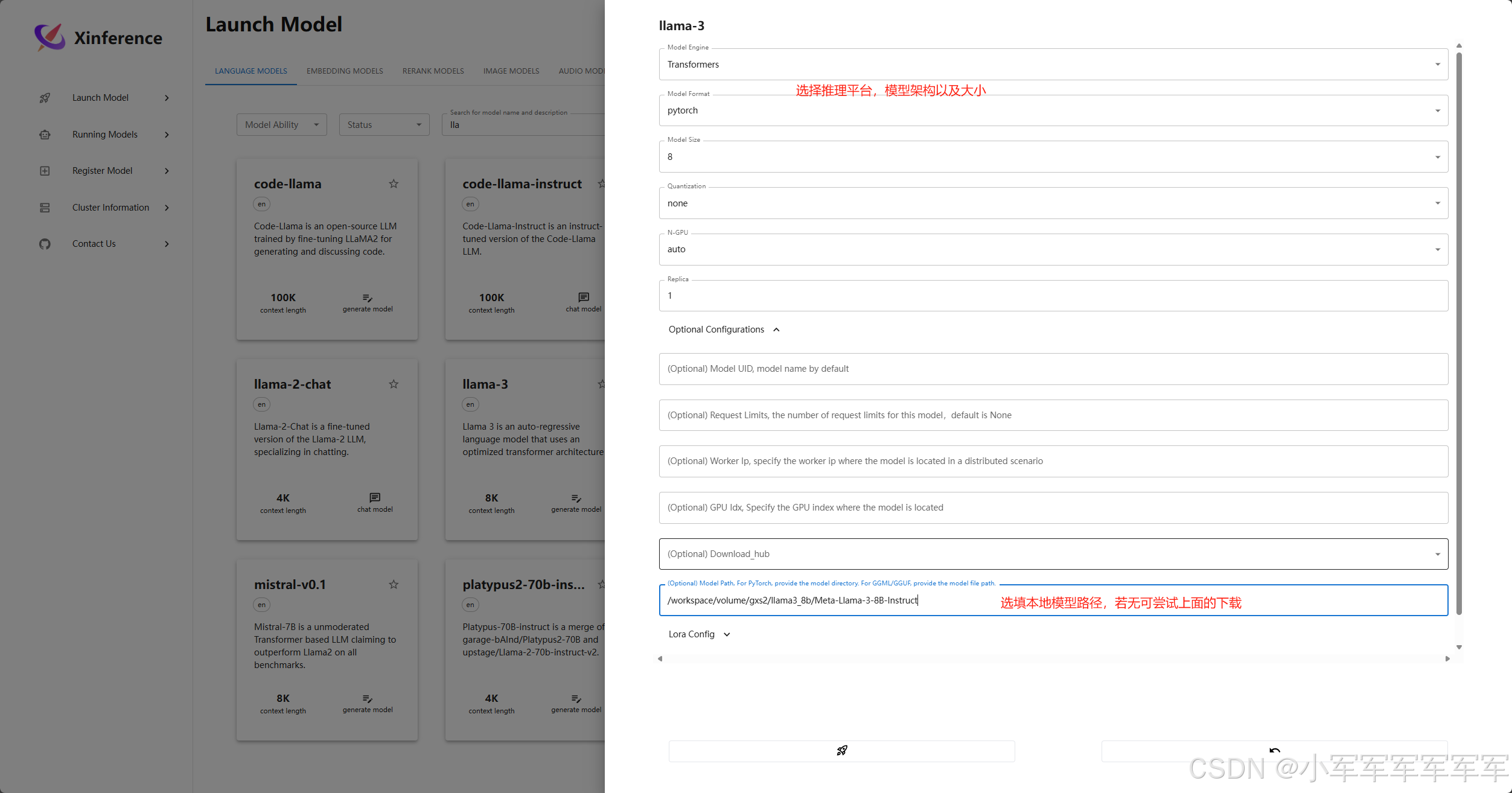
加载模型
寻找指定模型选择模型参数进行加载
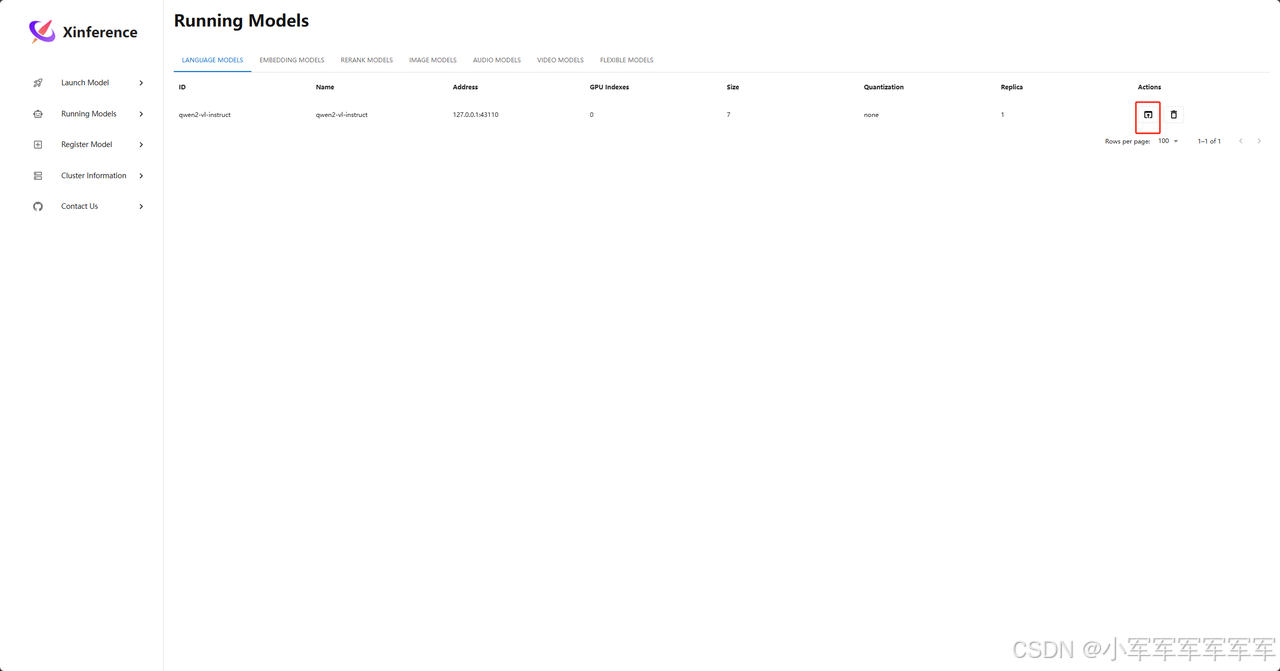
左侧run model中对已加载模型进行启动,gui进行推理
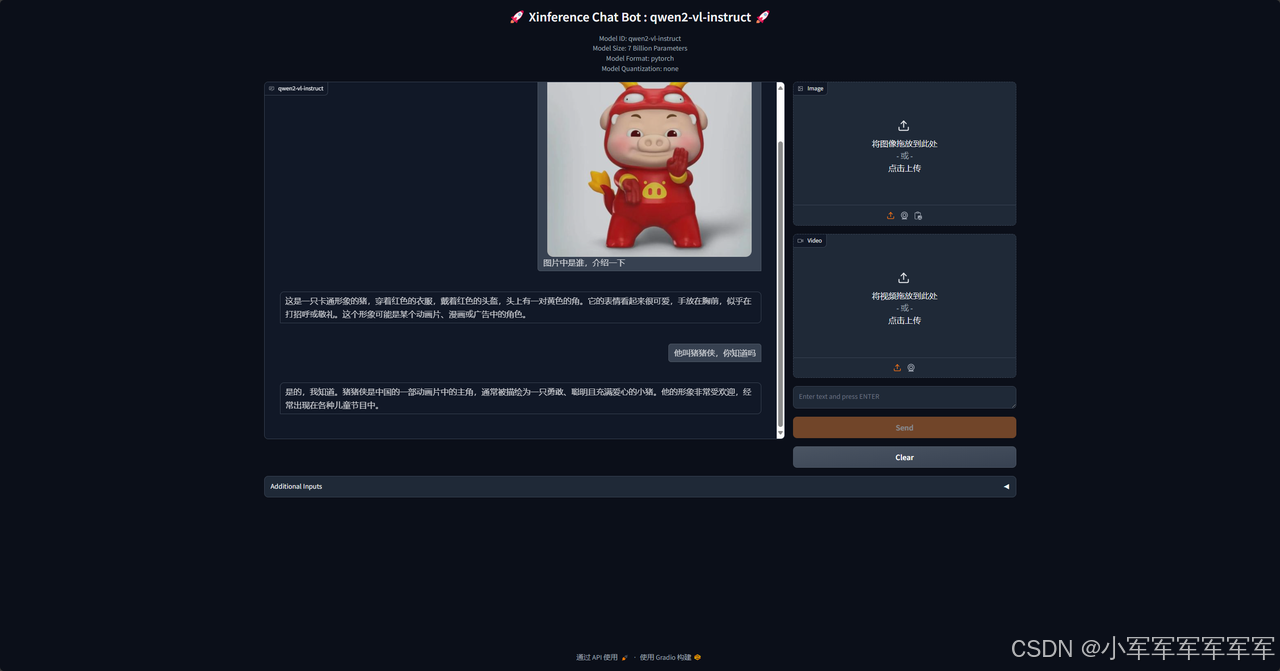
这里仅展示qwen2-vl模型,我们也测试了qwen2及知识库模型,并接入到新版本的langchain-chathchat中效果都是很棒的,下期想看什么,请留言或私信,谢谢!!